Moteur ArcGIS GeoAnalytics dans Databricks
Analyse Géospatiale Évolutive dans un Flux de Travail de Science des Données
par Kent Marten et Arif Masrur
Ceci est un article collaboratif d'Esri et Databricks. Nous remercions Arif Masrur, Ph.D., ingénieur de solutions senior chez Esri, pour ses contributions.
Les avancées dans le domaine du big data ont permis aux organisations de tous les secteurs de résoudre des problèmes scientifiques, sociétaux et commerciaux critiques. Le développement d'infrastructures de big data aide les analystes, ingénieurs et scientifiques de données à relever les défis fondamentaux du travail avec le big data - volume, vélocité, véracité, valeur et variété. Cependant, le traitement et l'analyse de données géospatiales massives présentent leurs propres défis. Chaque jour, des centaines d'exaoctets de données géo-localisées sont générées. Ces ensembles de données contiennent un large éventail de connexions et de relations complexes entre des entités du monde réel, nécessitant des outils avancés capables de lier efficacement ces relations multifacettes par des opérations optimisées telles que les jointures spatiales et spatio-temporelles. Les nombreux formats géospatiaux qui doivent être ingérés, vérifiés et standardisés pour une analyse évolutive efficace ajoutent à la complexité.
Certaines des difficultés liées au travail avec des données géographiques sont abordées par le support des expressions H3 intégrées dans Databricks, récemment annoncé. Cependant, il existe de nombreux cas d'utilisation géospatiaux, dont certains sont plus complexes ou centrés sur la géométrie plutôt que sur les indices de grille. Les utilisateurs peuvent travailler avec une gamme d'outils et de bibliothèques sur la plateforme Databricks tout en profitant des nombreuses capacités de Lakehouse.
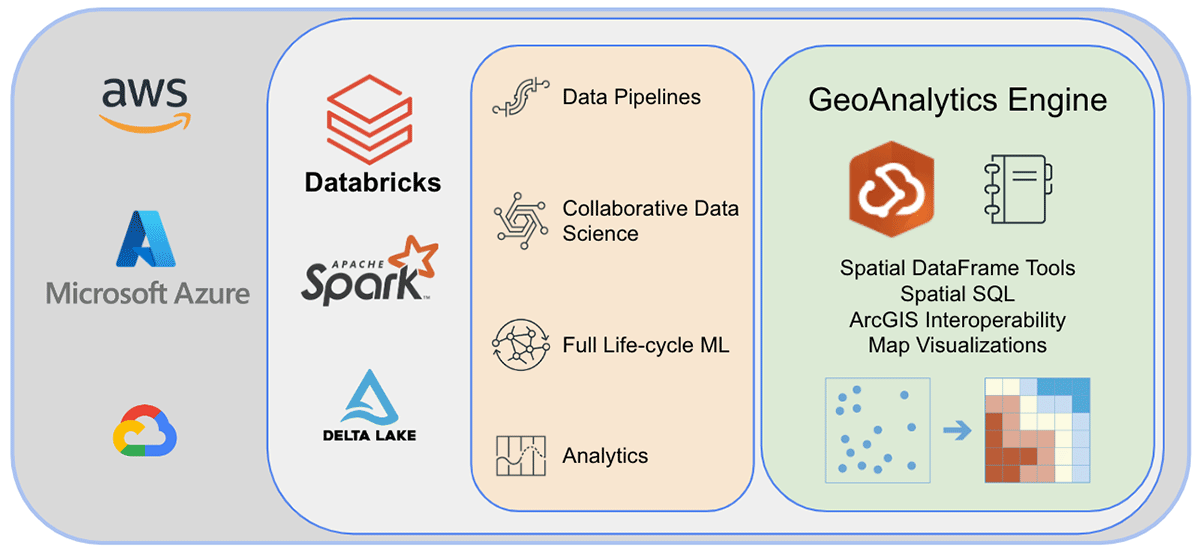
Esri, le leader mondial des logiciels SIG, propose un ensemble complet d'outils, notamment ArcGIS Enterprise, ArcGIS Pro et ArcGIS Online, pour résoudre les défis de géo-analyse mentionnés précédemment. Les organisations et les praticiens de données utilisant Databricks ont besoin d'accéder aux outils avec lesquels ils effectuent leur travail quotidien en dehors de l'environnement ArcGIS. C'est pourquoi nous sommes ravis d'annoncer la première version d'ArcGIS GeoAnalytics Engine (ci-après dénommé GA Engine), qui permet aux scientifiques, ingénieurs et analystes de données d'analyser leurs données géospatiales dans leurs environnements d'analyse de big data existants. Plus précisément, ce moteur est un plugin pour Apache Spark™ qui étend les DataFrames avec un traitement et une analyse spatiaux très rapides, prêts à être exécutés dans Databricks.
Avantages de l'ArcGIS GeoAnalytics Engine
Le GA Engine d'Esri permet aux scientifiques de données d'accéder à des fonctions et outils de géo-analyse au sein de leur environnement Databricks. Les principales caractéristiques du GA Engine sont :
- Plus de 120 fonctions SQL spatiales — Créez des géométries, testez des relations spatiales, et plus encore en utilisant la syntaxe Python ou SQL
- Puissants outils d'analyse — Exécutez des flux de travail d'analyse spatio-temporelle et statistique courants avec seulement quelques lignes de code
- Indexation spatiale automatique — Effectuez immédiatement des jointures spatiales optimisées et d'autres opérations
- Interopérabilité avec les sources de données SIG courantes — Chargez et enregistrez des données à partir de shapefiles, de services d'entités et de tuiles vectorielles
- Cloud-native et Spark-native — Testé et prêt à être installé sur Databricks
- Facile à utiliser — Créez des pipelines de big data spatialement activés avec une API Python intuitive qui étend PySpark
Fonctions SQL et outils d'analyse
Actuellement, le GA Engine fournit plus de 120 fonctions SQL et plus de 15 outils d'analyse spatiale qui prennent en charge l'analyse spatiale et spatio-temporelle avancée. Essentiellement, les fonctions du GA Engine étendent l'API Spark SQL en permettant des requêtes spatiales sur les colonnes de DataFrame. Ces fonctions peuvent être appelées avec des fonctions Python ou dans une requête PySpark SQL et permettent de créer des géométries, d'opérer sur des géométries, d'évaluer des relations spatiales, de résumer des géométries, et plus encore. Contrairement aux fonctions SQL qui opèrent ligne par ligne en utilisant une ou deux colonnes, les outils du GA Engine sont conscients de toutes les colonnes d'un DataFrame et utilisent toutes les lignes pour calculer un résultat si nécessaire. Ces larges gammes d'outils d'analyse vous permettent de gérer, enrichir, résumer ou analyser des ensembles de données entiers.
|
|
Le GA Engine est un outil d'analyse puissant. Cependant, il ne faut pas négliger la facilité avec laquelle le GA Engine permet de travailler avec les formats SIG courants. La documentation du GA Engine comprend plusieurs tutoriels pour lire et écrire depuis et vers des Shapefiles et des services d'entités. La capacité de traiter des données géospatiales à l'aide de formats SIG offre une grande interopérabilité entre Databricks et les produits Esri.
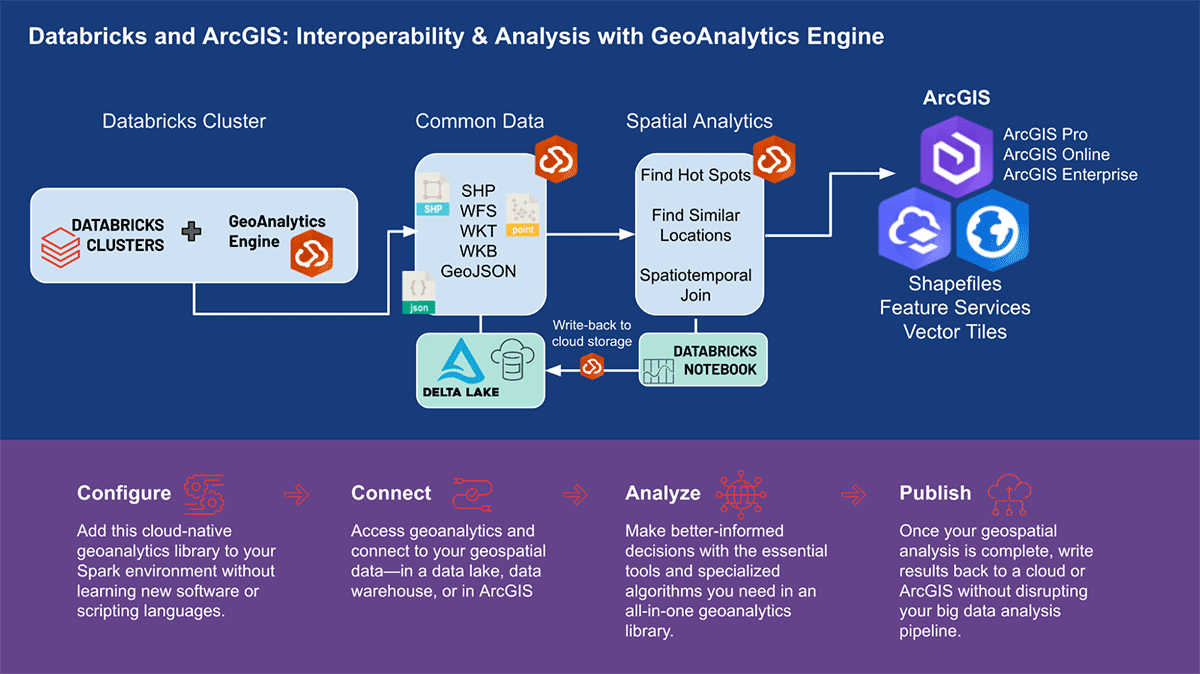
Moteur GA pour différents cas d'utilisation
Passons en revue quelques scénarios d'utilisation de diverses industries pour montrer comment le moteur GA d'ESRI gère de grandes quantités de données spatiales. Le support de l'analyse spatiale et spatio-temporelle évolutive est destiné à aider toute entreprise à prendre des décisions critiques. Dans trois domaines d'analyse de données diversifiés - mobilité, transactions de consommateurs et services publics - nous nous concentrerons sur la révélation d'informations géographiques.
Analyse des données de mobilité
Les données de mobilité sont en constante croissance et peuvent être divisées en deux catégories : le mouvement humain et le mouvement des véhicules. Les données de mobilité humaine collectées auprès des utilisateurs de smartphones dans les zones de service de téléphonie mobile offrent un aperçu plus approfondi des modèles d'activité humaine. Les données de mouvement de millions de véhicules connectés fournissent des informations riches en temps réel sur les volumes de trafic directionnel, les flux de trafic, les vitesses moyennes, la congestion, et plus encore. Ces ensembles de données sont généralement volumineux (milliards d'enregistrements) et complexes (centaines d'attributs). Ces données nécessitent une analyse spatiale et spatio-temporelle qui va au-delà de l'analyse spatiale de base, avec un accès immédiat à des outils statistiques avancés et à des fonctions de géo-analyse spécialisées.
Commençons par examiner un exemple d'analyse du mouvement humain basé sur les données Cell Analytics™ d'Ookla®, partenaire d'Esri. Ookla® collecte des big data sur les performances du service sans fil mondial, la couverture et les mesures de signal basées sur l'application Speedtest®. Les données comprennent des informations sur l'appareil source, la connectivité du réseau mobile, l'emplacement et l'horodatage. Dans ce cas, nous avons travaillé avec un sous-ensemble de données contenant environ 16 milliards d'enregistrements. Avec des outils non optimisés pour les opérations parallèles dans Apache Spark™, la lecture de ces données à haut volume et leur activation pour des opérations spatio-temporelles pourraient entraîner des heures de temps de traitement. En utilisant une seule ligne de code avec GeoAnalytics Engine, ces données peuvent être ingérées à partir de fichiers parquet en quelques secondes.
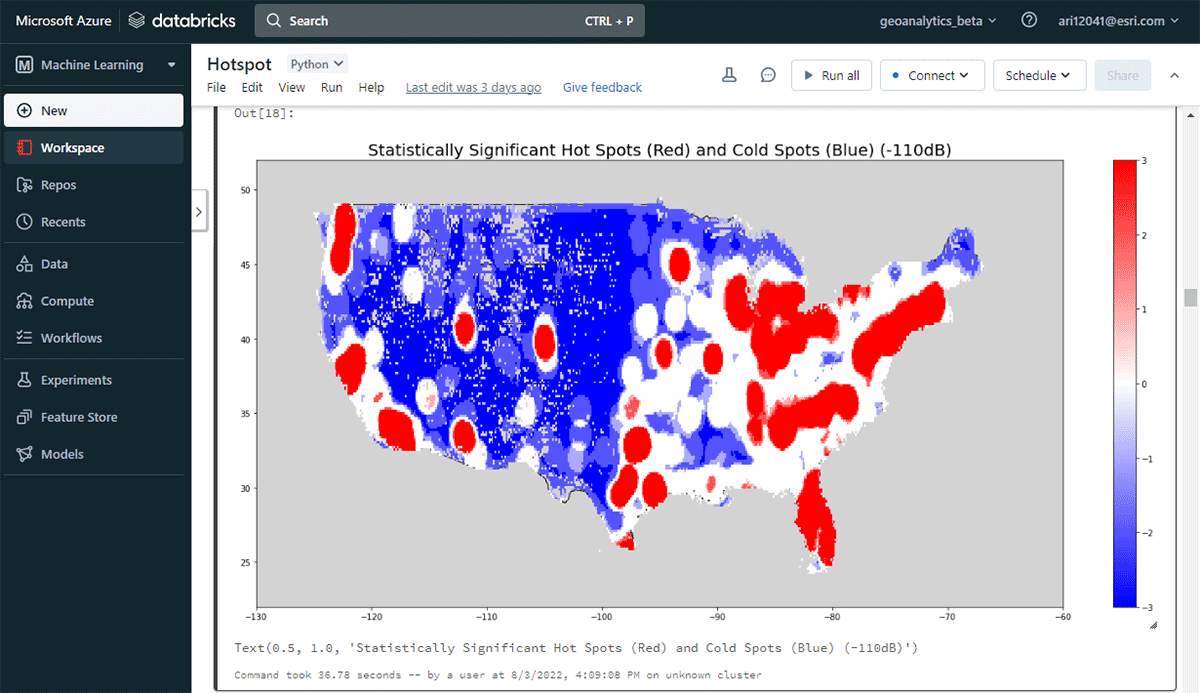
Pour commencer à tirer des informations exploitables, nous allons examiner les données avec une question simple : Quel est le schéma spatial des appareils mobiles sur les États-Unis contigus ? Cela nous permettra de commencer à caractériser la présence et l'activité humaines. L'outil FindHotSpots peut être utilisé pour identifier des clusters spatiaux statistiquement significatifs de valeurs élevées (points chauds) et de valeurs faibles (points froids).
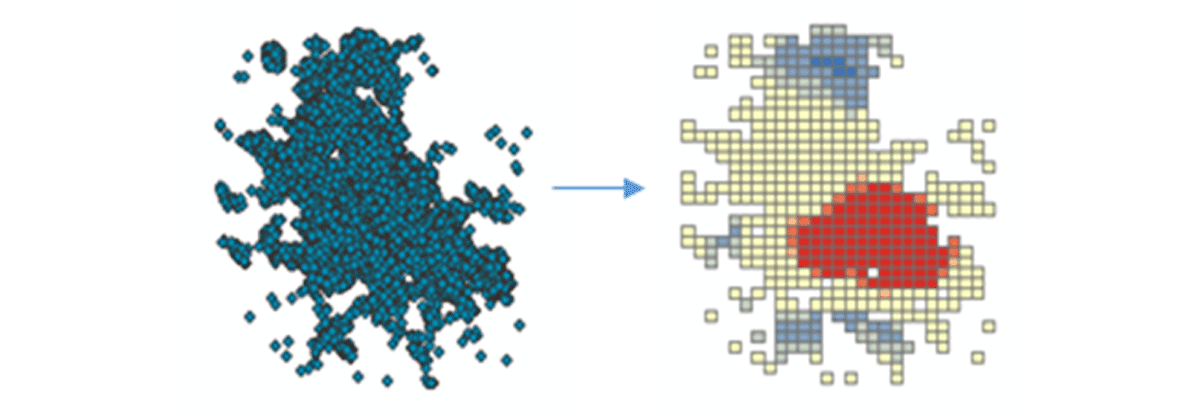
Le DataFrame résultant des points chauds a été visualisé et stylisé à l'aide de Matplotlib (Figure 2). Il a montré de nombreux enregistrements de connexions d'appareils (rouge) par rapport aux emplacements à faible densité d'appareils connectés (bleu) dans les États-Unis contigus. Sans surprise, les zones urbaines majeures ont indiqué une densité plus élevée d'appareils connectés.
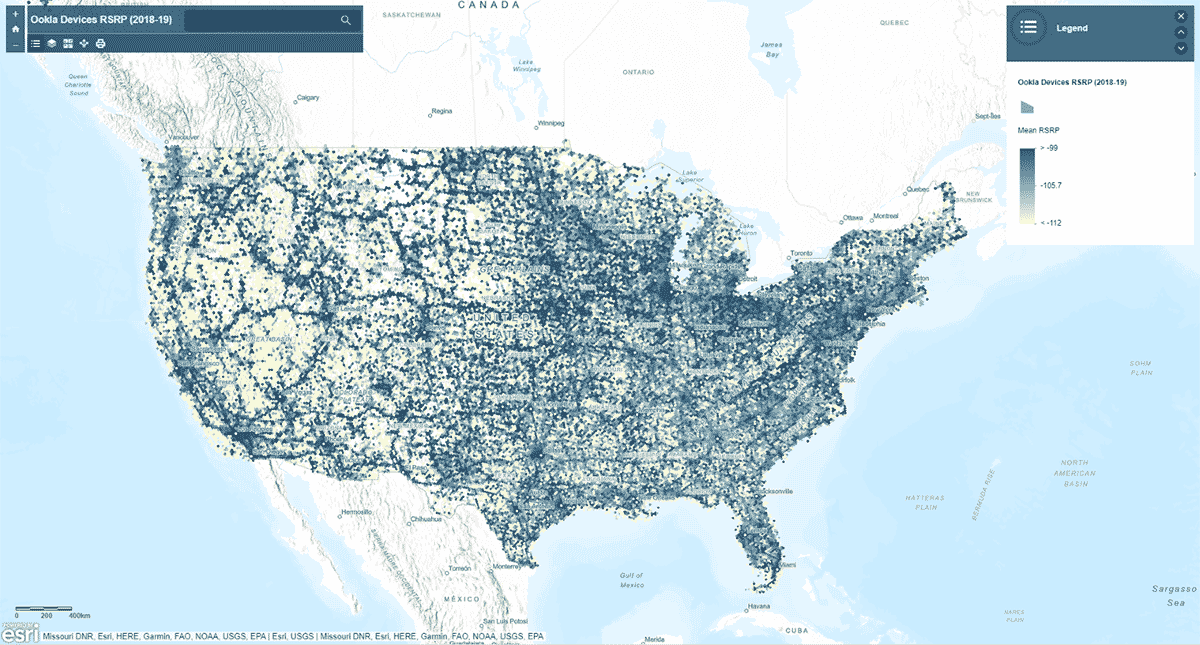
Ensuite, nous avons demandé : la force du signal du réseau mobile suit-elle un schéma homogène à travers les États-Unis ? Pour répondre à cela, l'outil AggregatePoints a été utilisé pour résumer les observations d'appareils en cellules hexagonales afin d'identifier les zones avec un service cellulaire particulièrement fort et particulièrement faible (Figure 3). Nous avons utilisé le rsrp (puissance du signal reçu de référence) – une valeur utilisée pour mesurer la force du signal du réseau mobile – pour calculer la statistique moyenne sur des cellules de 15 km. Cette analyse a révélé que la force du signal du service cellulaire n'est pas constante – elle a tendance à être plus forte le long des principaux réseaux routiers et des zones urbaines.
En plus de tracer le résultat à l'aide de st_plotting, nous avons utilisé le module arcgis, publié le DataFrame résultant en tant que couche de fonctionnalités dans ArcGIS Online, et créé une visualisation interactive basée sur une carte.
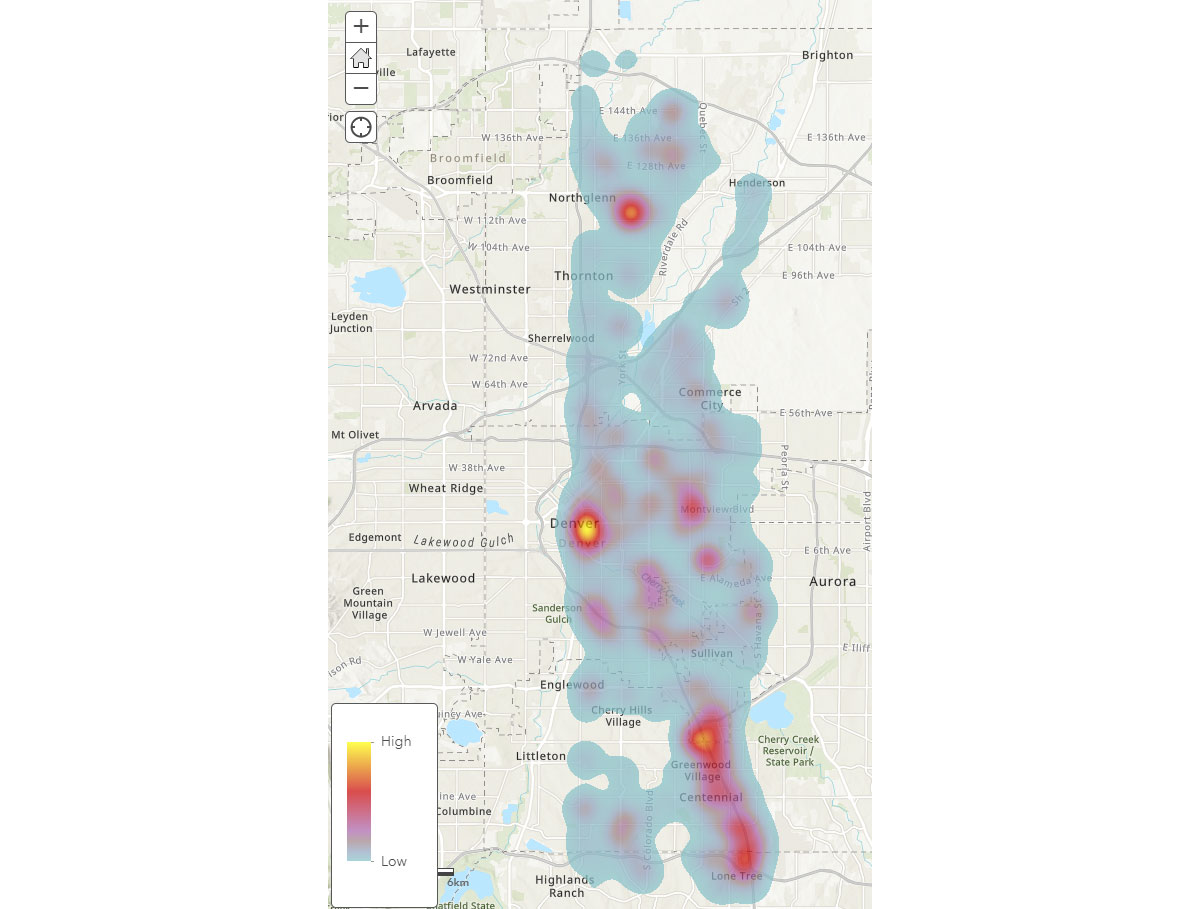
Maintenant que nous comprenons les grands schémas spatiaux des appareils mobiles, comment pouvons-nous obtenir un aperçu plus approfondi des schémas d'activité humaine ? Où les gens passent-ils leur temps ? Pour répondre à cela, nous avons utilisé FindDwellLocations pour rechercher des appareils à Denver, CO qui ont passé au moins 5 minutes dans la même zone générale le 31 mai 2019 (vendredi). Cette analyse peut nous aider à comprendre les lieux d'activité prolongée, c'est-à-dire les destinations de consommation, et à les séparer de l'activité de déplacement générale.
Le DataFrame result_dwell nous fournit les appareils ou les individus qui ont séjourné à différents endroits. La carte thermique de durée de séjour dans la Figure 4 donne un aperçu de l'endroit où les gens passent leur temps à Denver.
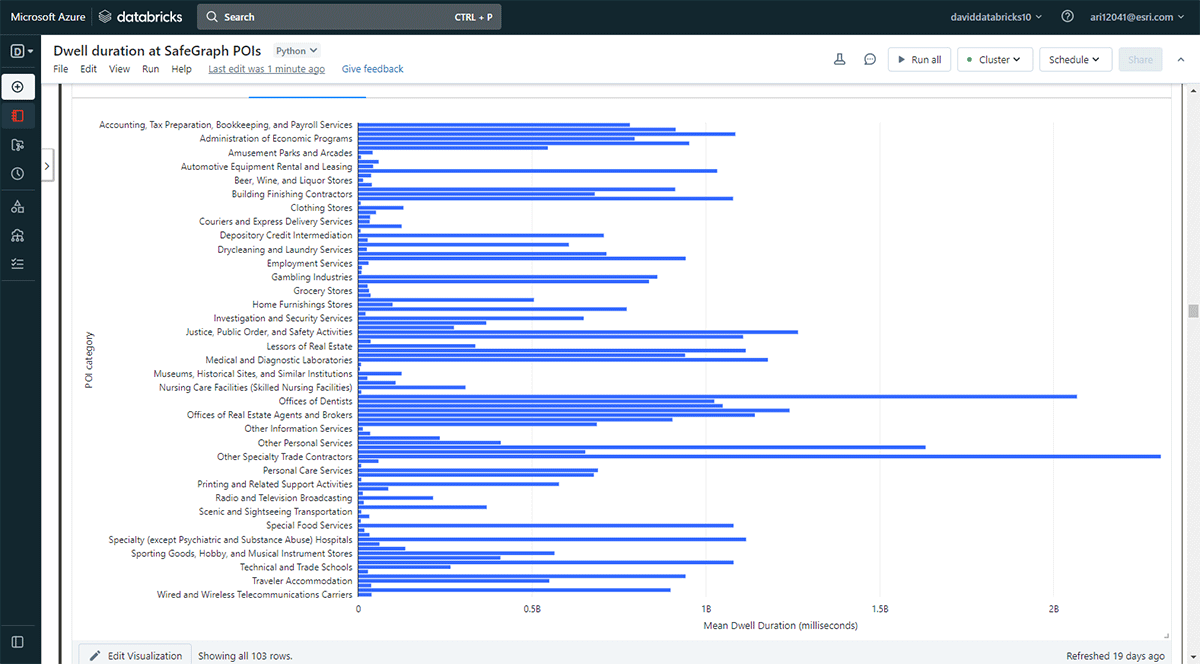
Nous voulions également explorer les lieux visités par les gens pendant de plus longues durées. Pour ce faire, nous avons utilisé Overlay pour identifier quels empreintes de points d'intérêt (POI) des données de géométrie SafeGraph Geometry ont croisé les lieux de séjour (du DataFrame result_dwell) le 31 mai 2019. En utilisant la fonction groupBy, nous avons compté les durées de séjour des appareils connectés pour chacune des catégories de POI principales. La Figure 5 met en évidence que quelques POI urbains à Denver coïncidaient avec des durées de séjour plus longues, notamment les magasins de fournitures de bureau, de papeterie et de cadeaux, ainsi que les bureaux d'entrepreneurs commerciaux.
Ce flux de travail analytique d'exemple avec des données Cell AnalyticsTM pourrait être appliqué ou réutilisé pour caractériser plus spécifiquement les activités des personnes. Par exemple, nous pourrions utiliser les données pour mieux comprendre le comportement des consommateurs autour des points de vente au détail. Quels restaurants ou cafés ces appareils ou individus ont-ils visités après avoir fait des achats chez Walmart ou Costco ? De plus, ces ensembles de données peuvent être utiles pour la gestion des pandémies et des catastrophes naturelles. Par exemple, les gens suivent-ils les directives de santé publique pendant une pandémie ? Quelles zones urbaines pourraient être les prochaines zones de points chauds de COVID-19 ou de mauvaise qualité de l'air induite par les incendies de forêt ? Voyons-nous des disparités dans les mobilités et les activités humaines dues aux inégalités de revenus à une échelle géographique plus large ?
Analyse des données de transactions
Les données de transactions agrégées sur les points d'intérêt contiennent des informations riches sur comment et quand les gens dépensent leur argent dans des lieux spécifiques. La quantité et la vélocité de ces données nécessitent des outils d'analyse spatiale avancés pour comprendre clairement le comportement de dépenses des consommateurs : Comment le comportement des consommateurs diffère-t-il selon la géographie ? Quelles entreprises ont tendance à se co-localiser pour être rentables ? Quels articles les consommateurs achètent-ils dans un magasin physique (par exemple, Walmart) par rapport aux produits qu'ils achètent en ligne ? Le comportement des consommateurs change-t-il lors d'événements extrêmes tels que le COVID-19 ?
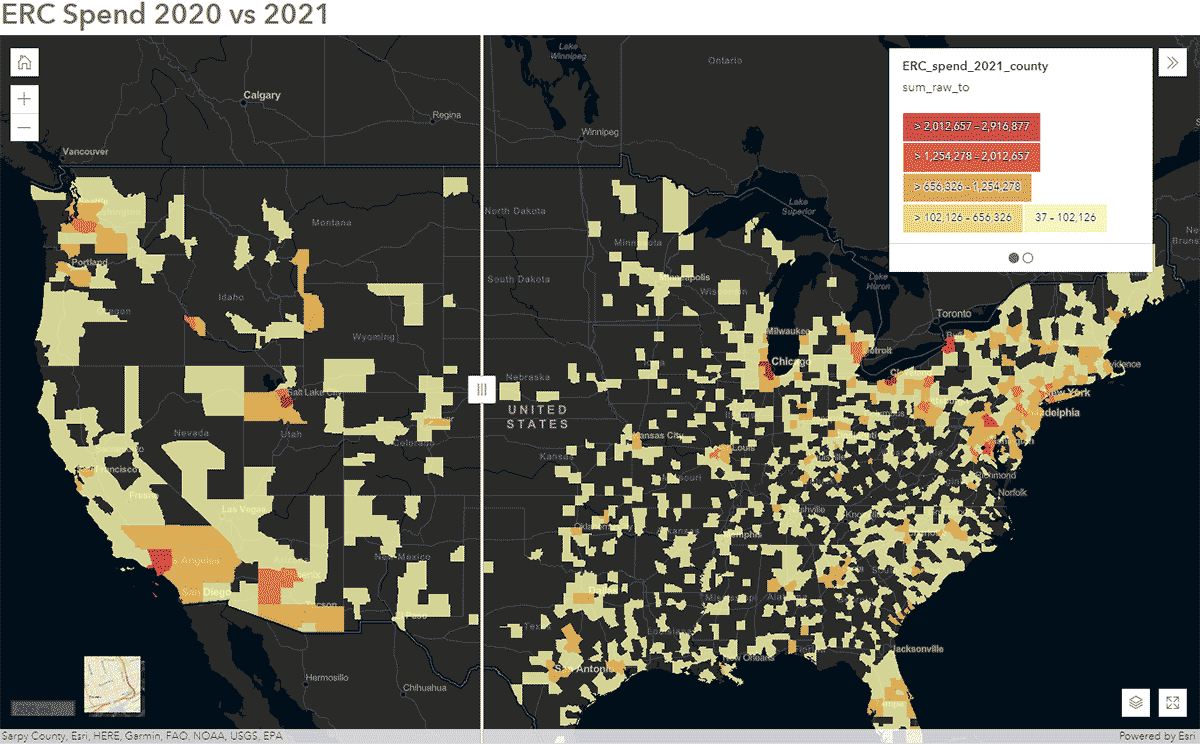
Ces questions peuvent être répondues en utilisant les données SafeGraph Spend et le GeoAnalytics Engine. Par exemple, nous avons voulu identifier comment les habitudes de déplacement des personnes ont été affectées pendant le COVID-19 aux États-Unis. Pour ce faire, nous avons analysé les données nationales de SafeGraph Spend de 2020 et 2021. Ci-dessous, nous montrons les dépenses annuelles (USD) des consommateurs pour les voitures de location d'entreprise, agrégées par comté américain. Après avoir publié le DataFrame sur ArcGIS Online, nous avons créé une carte interactive à l'aide du widget Swipe d'ArcGIS Web AppBuilder pour explorer rapidement quels comtés ont montré des changements au fil du temps (Figure 6).
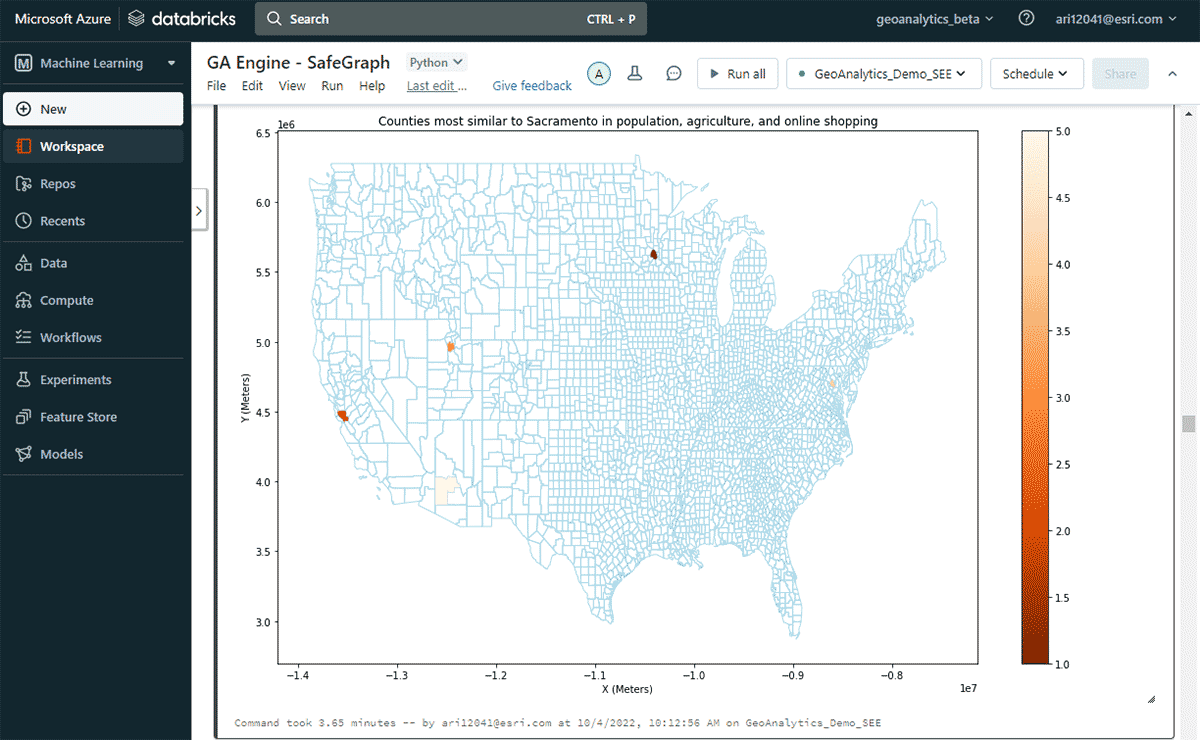
Ensuite, nous avons exploré quel comté américain avait la plus forte dépense en ligne en un an et quels autres comtés présentaient des tendances de dépenses d'achat en ligne similaires, en tenant compte des similitudes en matière de population et de modèles de vente de produits agricoles. Sur la base du filtrage par attribut du DataFrame des dépenses, nous avons identifié que Sacramento était en tête de liste des dépenses d'achat en ligne en 2020. Pour examiner des zones similaires, nous avons utilisé l'outil FindSimilarLocations pour identifier les comtés les plus similaires ou dissimilaires à Sacramento en termes d'achats et de dépenses en ligne, mais par rapport aux similitudes de population et d'agriculture (superficie totale des terres cultivées et ventes moyennes de produits agricoles) (Figure 7).
Analyse de données de services publics
Les ensembles de données de services publics, tels que les enregistrements d'appels 311, contiennent des informations précieuses sur les services non urgents fournis aux résidents. La surveillance et l'identification en temps opportun des modèles spatio-temporels dans ces données peuvent aider les gouvernements locaux à planifier et à allouer des ressources pour une résolution efficace des appels 311.
Dans cet exemple, notre objectif était de lire, traiter/nettoyer rapidement et filtrer environ 27 millions d'enregistrements de demandes de service 311 de New York de 2010 à février 2022, puis de répondre aux questions suivantes pour la région de New York:
- Quelles sont les zones avec les temps de réponse 311 moyens les plus longs?
- Existe-t-il des modèles dans les types de plaintes avec de longs temps de réponse moyens?
Pour répondre à la première question, les appels avec les temps de réponse les plus longs ont été identifiés. Ensuite, les données ont été filtrées pour inclure les enregistrements plus longs que la moyenne plus trois écarts types.
Pour répondre à la deuxième question consistant à trouver des groupes significatifs de plaintes, nous avons utilisé l'outil GroupByProximity pour rechercher des plaintes du même type qui se trouvaient à moins de 500 pieds et 5 jours l'une de l'autre. Nous avons ensuite filtré les groupes contenant plus de 10 enregistrements et créé une enveloppe convexe pour chaque groupe de plaintes, ce qui sera utile pour visualiser leurs modèles spatiaux (Figure 8). En utilisant st.plot() - une méthode de traçage légère incluse avec ArcGIS GeoAnalytics Engine - les géométries stockées dans un DataFrame peuvent être visualisées instantanément.
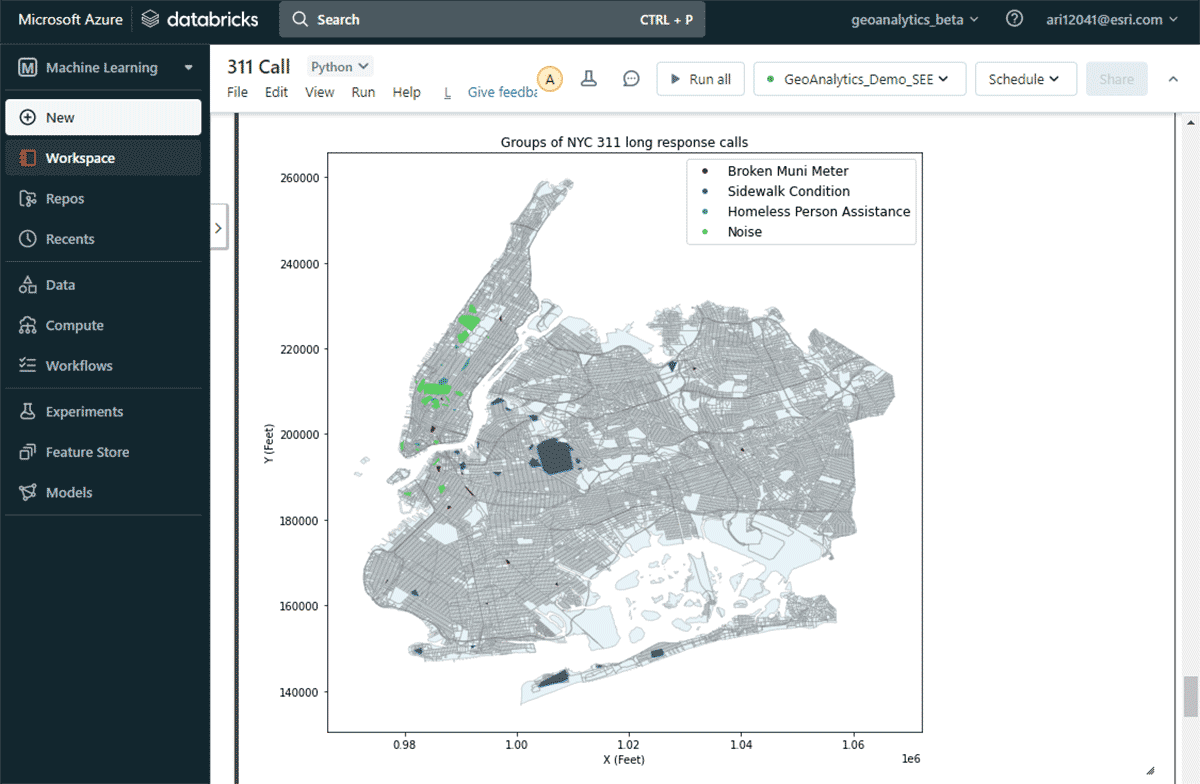
Avec cette carte, il était facile d'identifier les distributions spatiales des différents types de plaintes dans la ville de New York. Par exemple, il y avait un nombre considérable de plaintes pour nuisances sonores dans les zones du centre et du sud de Manhattan, tandis que l'état des trottoirs est une préoccupation majeure autour de Brooklyn et du Queens. Ces informations rapides basées sur les données peuvent aider les décideurs à prendre des mesures concrètes.
Benchmarks
La performance est un facteur décisif pour de nombreux clients qui essaient de choisir une solution d'analyse. Les tests de référence d'Esri ont montré que GA Engine offre des performances nettement meilleures lors de l'exécution d'analyses spatiales de big data par rapport aux packages open-source. Les gains de performance augmentent avec la taille des données, de sorte que les utilisateurs verront des performances encore meilleures pour les jeux de données plus volumineux. Par exemple, le tableau ci-dessous montre les temps de calcul pour une tâche d'intersection spatiale qui joint deux jeux de données d'entrée (points et polygones) de tailles variées allant jusqu'à des millions d'enregistrements de données. Chaque scénario de jointure a été testé sur un cluster Databricks à machine unique et multi-machines.
| Entrées d'intersection spatiale | Temps de calcul (secondes) | ||
|---|---|---|---|
| Jeu de données de gauche | Jeu de données de droite | Machine unique | Multi-machines |
| 50 polygones | 6K points | 6 | 5 |
| 3K polygones | 6K points | 10 | 5 |
| 3K polygones | 2M points | 19 | 9 |
| 3K polygones | 17M points | 46 | 16 |
| 220K polygones | 17M points | 80 | 29 |
| 11M polygones | 17M points | 515 (8.6 min) | 129 (2.1 min) |
| 11M polygones | 19M points | 1,373 (22 min) | 310 (5 min) |
Architecture et Installation
Avant de terminer, jetons un coup d'œil sous le capot de l'architecture de GeoAnalytics Engine et explorons son fonctionnement. Parce qu'il est cloud-native et Spark-native, nous pouvons facilement utiliser la bibliothèque GeoAnalytics dans un environnement Spark basé sur le cloud. L'installation du déploiement de GeoAnalytics Engine dans l'environnement Databricks nécessite une configuration minimale. Vous chargerez le module via un fichier JAR, et il s'exécutera ensuite en utilisant les ressources fournies par le cluster.
L'installation comporte 2 étapes de base qui s'appliquent à AWS, Azure et GCP :
- Préparer l'espace de travail
- Créer ou lancer un espace de travail Databricks
- Télécharger le fichier JAR GeoAnalytics dans le DBFS
- Ajouter et activer un script d'initialisation
- Créer un cluster
Après l'installation, les utilisateurs analyseront à l'aide d'un notebook Python connecté à l'environnement Spark. Vous pouvez accéder instantanément aux données de la plateforme Databricks Lakehouse et effectuer des analyses. Suite à l'analyse, vous pouvez conserver les résultats en les écrivant dans votre data lake, votre SQL Warehouse, vos services BI (Business Intelligence) ou ArcGIS.
Route à suivre
Dans ce blog, nous avons présenté la puissance de l'ArcGIS GeoAnalytics Engine sur Databricks et démontré comment nous pouvons relever ensemble les cas d'utilisation géospatiaux les plus difficiles. Référez-vous à ce Notebook Databricks pour une référence détaillée des exemples présentés ci-dessus. À l'avenir, GeoAnalytics Engine sera amélioré avec des fonctionnalités supplémentaires, notamment l'exportation GeoJSON, la prise en charge du H3 binning et des algorithmes de clustering tels que K-Nearest Neighbor.
GeoAnalytics Engine fonctionne avec Databricks sur Azure, AWS et GCP. Veuillez contacter vos équipes de compte Databricks et Esri pour plus de détails sur le déploiement de la bibliothèque GeoAnalytics dans votre environnement Databricks préféré. Pour en savoir plus sur GeoAnalytics Engine et découvrir comment accéder à ce produit puissant, veuillez visiter le site web d'Esri.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.