Mise en œuvre de la reprise après sinistre pour un espace de travail Databricks
par Ankit Shah et Lorin Dawson
Ce billet fait suite aux articles Vue d'ensemble, stratégies et évaluation de la reprise après sinistre et Automatisation et outillage de la reprise après sinistre pour un espace de travail Databricks.
La reprise après sinistre (DR) désigne un ensemble de politiques, d'outils et de procédures permettant de récupérer ou de poursuivre l'exploitation d'infrastructures et de systèmes technologiques critiques suite à une catastrophe naturelle ou d'origine humaine. Même si les fournisseurs de services cloud tels qu'AWS, Azure, Google Cloud et les entreprises SaaS intègrent des protections contre les points de défaillance uniques, des pannes surviennent. La gravité de la perturbation et son impact sur une organisation peuvent varier. Pour les charges de travail cloud natives, un schéma de reprise après sinistre clair est essentiel.
Configuration de la reprise après sinistre pour Databricks
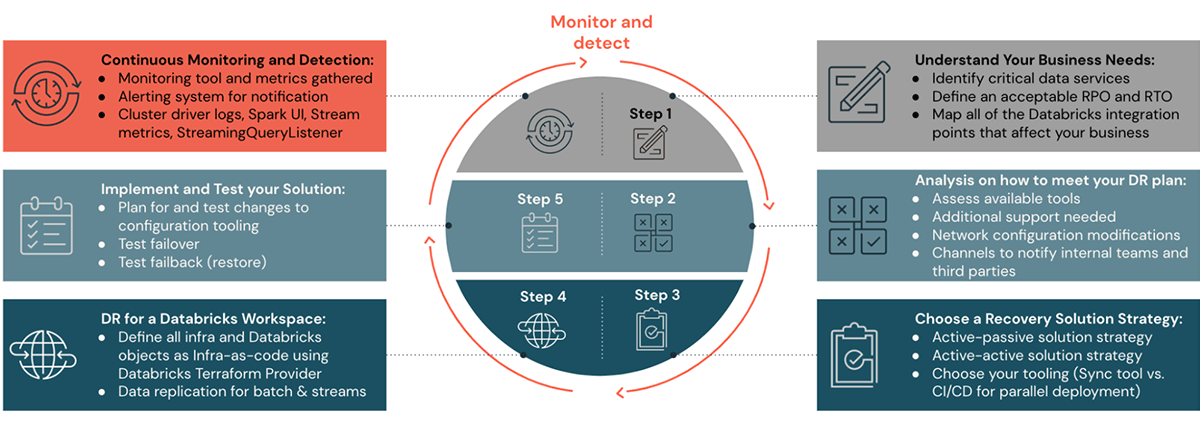
Veuillez consulter les articles de blog précédents de cette série de blogs sur la DR pour comprendre les étapes un à quatre sur la manière de planifier, de configurer une stratégie de solution DR et d'automatiser. Dans les étapes cinq et six de cet article, nous examinerons comment surveiller, exécuter et valider une configuration DR.
Solution de reprise après sinistre
Une implémentation Databricks typique comprend un certain nombre d'actifs critiques, tels que le code source des notebooks, les requêtes, les configurations de jobs et les clusters, qui doivent être récupérés en douceur pour assurer une perturbation minimale et la continuité du service aux utilisateurs finaux.
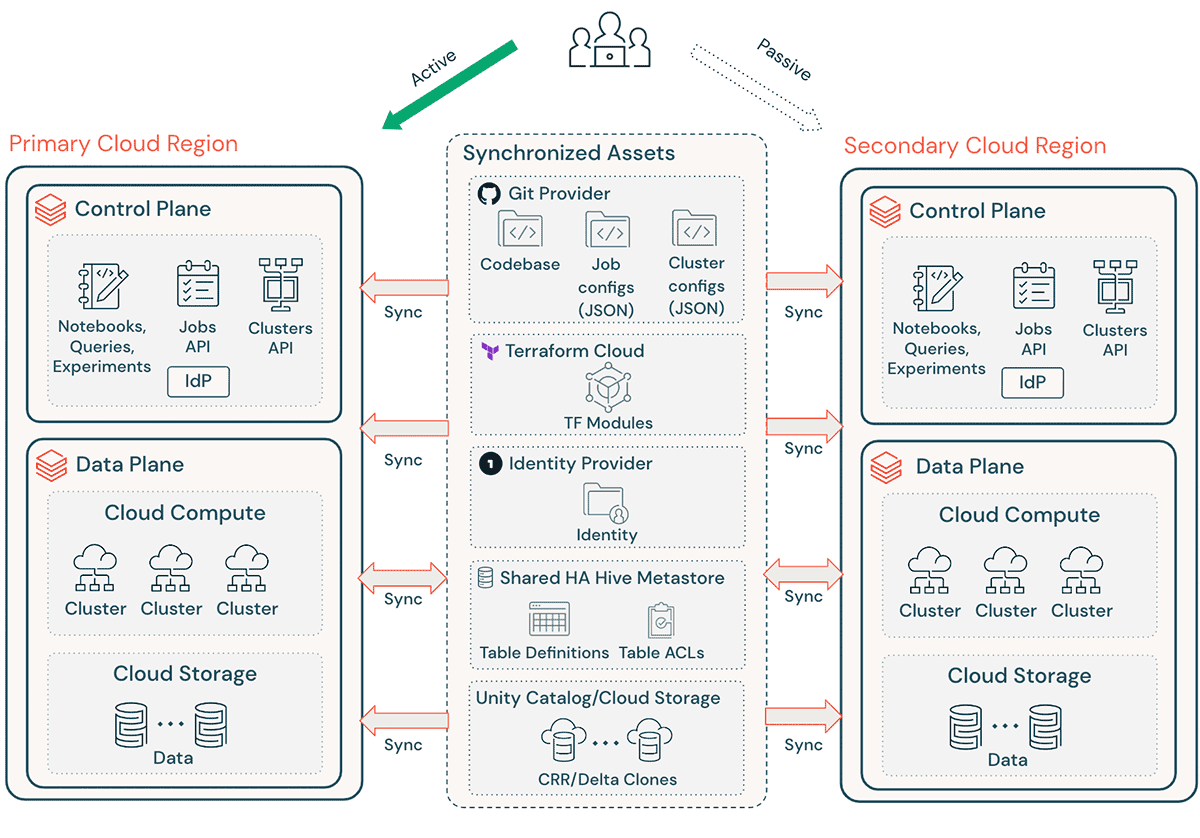
Considérations générales sur la DR :
- Assurez-vous que votre architecture est reproductible via Terraform (TF), ce qui permet de créer et de recréer cet environnement ailleurs.
- Utilisez Databricks Repos (AWS | Azure | GCP) pour synchroniser les Notebooks et le code d'application dans des fichiers arbitraires pris en charge (AWS | Azure | GCP).
- Utilisez Terraform Cloud pour déclencher des exécutions TF (planifier et appliquer) pour les pipelines d'infrastructure et d'applications tout en maintenant l'état.
- Répliquez les données des comptes de stockage cloud tels qu'Amazon S3, Azure ADLS et GCS vers la région DR. Si vous êtes sur AWS, vous pouvez également stocker des données en utilisant les points d'accès multi-régions S3 afin que les données couvrent plusieurs buckets S3 dans différentes régions AWS.
- Les définitions de clusters Databricks peuvent contenir des informations spécifiques à la zone de disponibilité. Utilisez l'attribut de cluster « auto-az » lors de l'exécution de Databricks sur AWS pour éviter tout problème lors du basculement régional.
- Gérez la dérive de configuration dans la région DR. Assurez-vous que votre infrastructure, vos données et votre configuration sont conformes aux besoins dans la région DR.
- Pour le code et les actifs de production, utilisez des outils CI/CD qui poussent simultanément les modifications vers les systèmes de production dans les deux régions. Par exemple, lors du transfert de code et d'actifs de la mise en staging/développement vers la production, un système CI/CD les rend disponibles dans les deux régions en même temps.
- Utilisez Git pour synchroniser les fichiers TF et la base de code d'infrastructure, les configurations de jobs et les configurations de clusters.
- Les configurations spécifiques à la région devront être mises à jour avant d'exécuter l'application TF dans une région secondaire.
Remarque : Certains services tels que Feature Store, les pipelines MLflow, le suivi des expériences ML, la gestion des modèles et le déploiement de modèles ne peuvent pas être considérés comme réalisables à l'heure actuelle pour la reprise après sinistre. Pour Structured Streaming et Delta Live Tables, un déploiement actif-actif est nécessaire pour maintenir les garanties exactly-once, mais le pipeline aura une cohérence éventuelle entre les deux régions.
D'autres considérations générales sont disponibles dans les articles précédents de cette série.
Surveillance et détection
Il est crucial de savoir le plus tôt possible si vos charges de travail ne sont pas dans un état sain afin de pouvoir rapidement déclarer un sinistre et récupérer d'un incident. Ce temps de réponse, associé à des informations appropriées, est essentiel pour atteindre des objectifs de récupération ambitieux. Il est essentiel de prendre en compte la détection des incidents, la notification, l'escalade, la découverte et la déclaration dans votre planification et vos objectifs pour fournir des objectifs réalistes et réalisables.
Notifications d'état du service
La page d'état Databricks fournit un aperçu de tous les services Databricks principaux pour le plan de contrôle. Vous pouvez facilement afficher l'état d'un service spécifique en consultant la page d'état. Vous pouvez également vous abonner aux mises à jour d'état sur des composants de service individuels, ce qui envoie une alerte chaque fois que l'état auquel vous êtes abonné change.
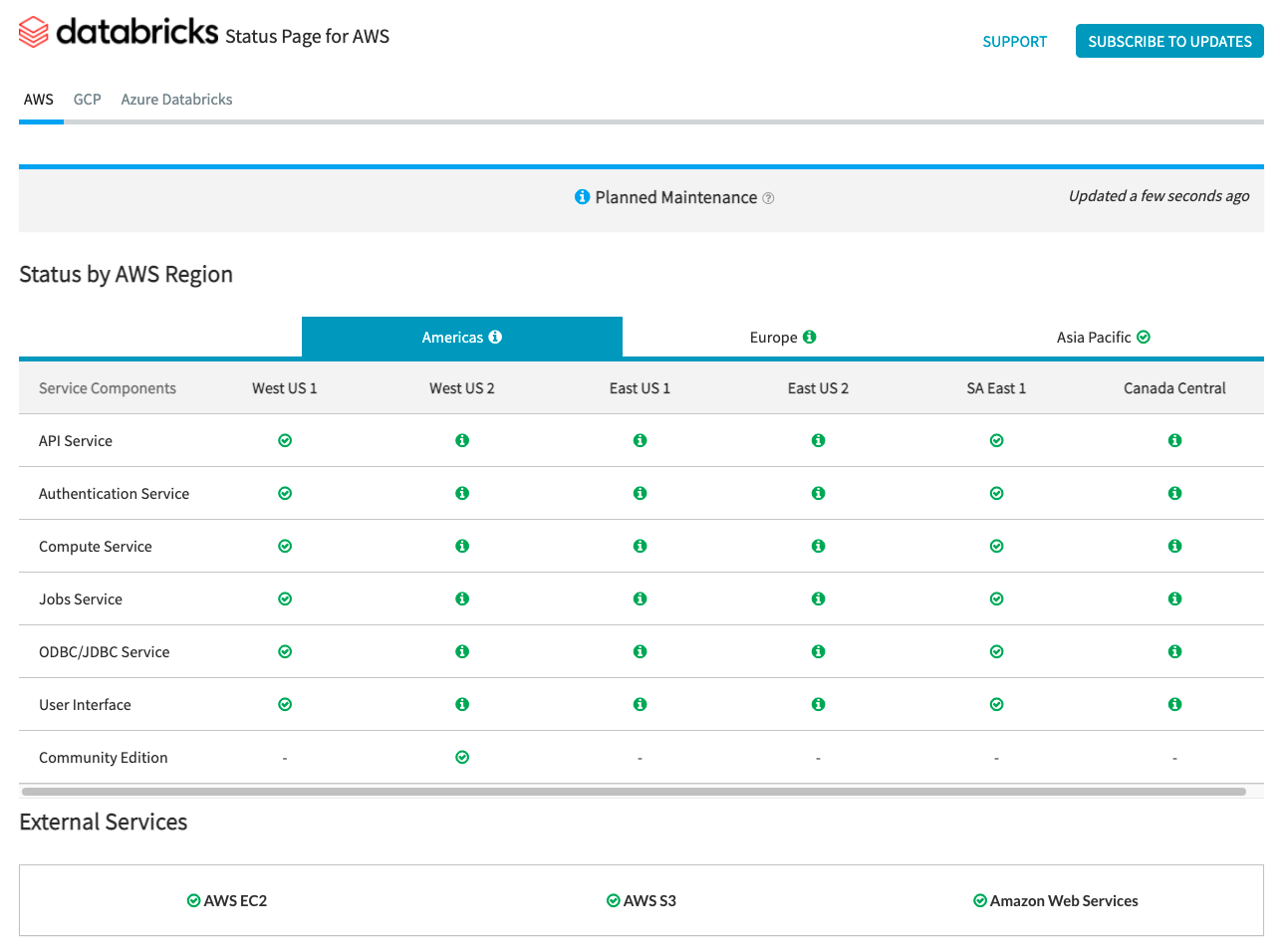
Pour les vérifications d'état concernant le plan de données, le tableau de bord AWS Health, la page d'état Azure et la page d'état des services GCP doivent être utilisées pour la surveillance.
AWS et Azure proposent des points de terminaison API que les outils peuvent utiliser pour ingérer et alerter sur les vérifications d'état.
Surveillance et alertes de l'infrastructure
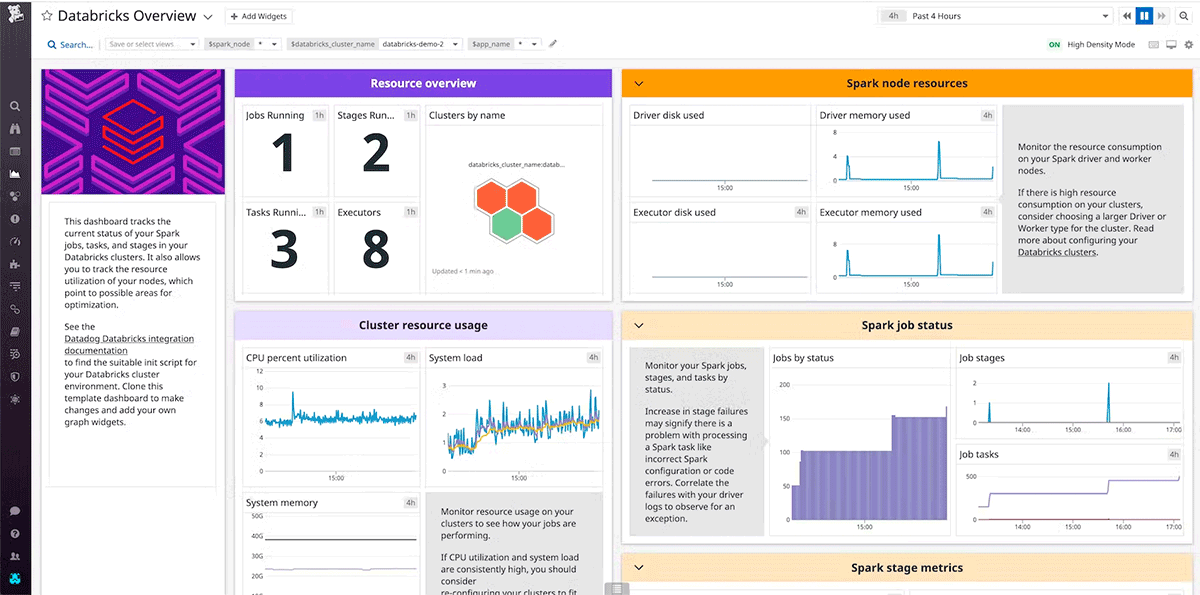
L'utilisation d'un outil pour collecter et analyser les données de l'infrastructure permet aux équipes de suivre les performances au fil du temps. Cela permet de manière proactive aux équipes de minimiser les temps d'arrêt et la dégradation des services dans l'ensemble. De plus, la surveillance au fil du temps établit une référence pour les performances maximales qui est nécessaire comme référence pour les optimisations et les alertes.
Dans le contexte de la DR, une organisation peut ne pas être en mesure d'attendre les alertes de ses fournisseurs de services. Même si les exigences RTO/RPO sont suffisamment permissives pour attendre une alerte du fournisseur de services, informer l'équipe de support du fournisseur d'une dégradation des performances à l'avance ouvrira une ligne de communication plus précoce.
DataDog et Dynatrace sont des outils de surveillance populaires qui fournissent des intégrations et des agents pour les clusters AWS, Azure, GCP et Databricks.
Vérifications de l'état
Pour les exigences RTO les plus strictes, vous pouvez implémenter un basculement automatisé basé sur des vérifications de l'état des services Databricks et d'autres services avec lesquels la charge de travail interagit directement dans le plan de données, par exemple, les magasins d'objets et les services de machines virtuelles des fournisseurs de cloud.
Concevez des vérifications de l'état qui sont représentatives de l'expérience utilisateur et basées sur des indicateurs clés de performance (KPI). Les vérifications de battement de cœur superficielles peuvent évaluer si le système fonctionne, c'est-à-dire si le cluster est en cours d'exécution. Alors que les vérifications d'état approfondies, telles que les métriques système du CPU de chaque nœud, l'utilisation du disque et les métriques Spark à travers chaque étape active ou partition mise en cache, vont au-delà des vérifications de battement de cœur superficielles pour déterminer une dégradation significative des performances. Utilisez des vérifications d'état approfondies basées sur plusieurs signaux conformément à la fonctionnalité et aux performances de référence de la charge de travail.
Faites preuve de prudence si vous automatisez entièrement la décision de basculer à l'aide de vérifications de l'état de santé. Si de faux positifs se produisent ou si une alarme est déclenchée, mais que l'entreprise peut absorber l'impact, il n'est pas nécessaire de basculer. Un faux basculement introduit des risques de disponibilité et des risques de corruption de données, et constitue une opération coûteuse en temps. Il est recommandé d'avoir un humain dans la boucle, tel qu'un responsable des incidents d'astreinte, pour prendre la décision si une alarme est déclenchée. Un basculement inutile peut être catastrophique, et l'examen supplémentaire permet de déterminer si le basculement est requis.
Exécution d'une solution de reprise après sinistre
Deux scénarios d'exécution existent à un niveau élevé pour une solution de reprise après sinistre (DR). Dans le premier scénario, le site de DR est considéré comme temporaire. Une fois le service rétabli sur le site principal, la solution doit orchestrer un basculement du site de DR vers le site principal permanent. La création de nouveaux artefacts pendant que le site de DR est actif doit être découragée car il est temporaire et complique le retour arrière dans ce scénario. Inversement, dans le second scénario, le site de DR sera promu au nouveau site principal, permettant aux utilisateurs de reprendre le travail plus rapidement car ils n'ont pas besoin d'attendre que les services soient rétablis. De plus, ce scénario ne nécessite pas de retour arrière, mais l'ancien site principal doit être préparé comme nouveau site de DR.
Dans l'un ou l'autre scénario, chaque région dans le périmètre de la solution de DR doit prendre en charge tous les services requis, et un processus qui valide que l'espace de travail cible est en bon état de fonctionnement doit exister comme mesure de sécurité. La validation peut inclure une authentification simulée, des requêtes automatisées, des appels API et des vérifications ACL.
Basculement
Lors du déclenchement d'un basculement vers le site de DR, la solution ne peut pas supposer qu'il est possible d'arrêter le système de manière fluide. La solution doit tenter d'arrêter les services en cours d'exécution sur le site principal, enregistrer l'état d'arrêt pour chaque service, puis continuer à tenter d'arrêter les services sans l'état approprié à un intervalle de temps défini. Cela réduit le risque que les données soient traitées simultanément sur les sites principal et de DR, minimisant ainsi la corruption des données et facilitant le processus de retour arrière une fois les services rétablis.
Les étapes de haut niveau pour activer le site de DR comprennent :
- Exécutez un processus d'arrêt sur le site principal pour désactiver les pools, les clusters et les travaux planifiés sur la région principale afin que si le service défaillant revient en ligne, la région principale ne commence pas à traiter de nouvelles données.
- Confirmez que l'infrastructure et les configurations du site de DR sont à jour.
- Vérifiez la date des dernières données synchronisées. Voir Terminologie de l'industrie de la reprise après sinistre. Les détails de cette étape varient en fonction de la façon dont vous synchronisez les données et de vos besoins spécifiques.
- Stabilisez vos sources de données et assurez-vous qu'elles sont toutes disponibles. Incluez toutes les sources de données externes critiques, telles que le stockage d'objets, les bases de données, les systèmes pub/sub, etc.
- Informez les utilisateurs de la plateforme.
- Démarrez les pools pertinents (ou augmentez le nombre d'instances minimales inactives au nombre pertinent).
- Démarrez les clusters, les travaux et les entrepôts SQL pertinents (s'ils ne sont pas terminés).
- Modifiez l'exécution concurrente des travaux et exécutez les travaux pertinents. Il peut s'agir d'exécutions ponctuelles ou périodiques.
- Activez les planifications de travaux.
- Pour tout outil externe qui utilise une URL ou un nom de domaine pour votre espace de travail Databricks, mettez à jour les configurations pour tenir compte du nouveau plan de contrôle. Par exemple, mettez à jour les URL pour les API REST et les connexions JDBC/ODBC. L'URL visible par le client de l'application web Databricks change lorsque le plan de contrôle change, alors informez les utilisateurs de votre organisation de la nouvelle URL.
Retour arrière
Le retour au site principal lors du retour arrière est plus facile à contrôler et peut être effectué lors d'une fenêtre de maintenance. Le retour arrière suivra un plan très similaire au basculement, avec quatre exceptions majeures :
- La région cible sera la région principale.
- Comme le retour arrière est un processus contrôlé, l'arrêt est une activité unique qui ne nécessite pas de vérifications d'état pour arrêter les services à mesure qu'ils reviennent en ligne.
- Le site de DR devra être réinitialisé si nécessaire pour les futurs basculements.
- Toutes les leçons apprises doivent être intégrées à la solution de DR et testées pour les futurs événements de sinistre.
Conclusion
Testez régulièrement votre configuration de reprise après sinistre dans des conditions réelles pour vous assurer qu'elle fonctionne correctement. Il est inutile de conserver une solution de reprise après sinistre qui ne peut pas être utilisée lorsqu'elle est nécessaire. Certaines organisations testent leur infrastructure de DR en effectuant des basculements et des retours arrière entre les régions tous les quelques mois. Régulièrement, le basculement vers le site de DR teste vos hypothèses et vos processus pour vous assurer qu'ils répondent aux exigences de récupération en termes de RPO et RTO. Cela garantit également que les politiques et procédures d'urgence de votre organisation sont à jour. Testez les changements organisationnels requis pour vos processus et configurations en général. Votre plan de reprise après sinistre a un impact sur votre pipeline de déploiement, alors assurez-vous que votre équipe est au courant de ce qui doit être maintenu en synchronisation.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.