Faire progresser le Lakehouse avec Apache Iceberg v3 sur Databricks
Databricks prend en charge Apache Iceberg v3, offrant aux clients une couche de données unifiée, performante et interopérable
par Ryan Blue, Daniel Weeks, Jason Reid, Fred Liu et Aniruth Narayanan
• Databricks prend en charge Apache Iceberg v3, permettant aux clients d'exécuter des charges de travail interopérables et gouvernées sur une seule copie de données
• Avec Iceberg v3, les vecteurs de suppression, la lignée au niveau des lignes et le type de données Variant sont désormais disponibles sur toutes les tables gérées
• Avec ces fonctionnalités, Databricks apporte la Data Intelligence Platform à tous les formats pour les meilleures performances
Databricks prend en charge Apache Iceberg v3 dans la Data Intelligence Platform, offrant aux clients une couche de données unifiée et ouverte avec des performances, une interopérabilité et une gouvernance de premier ordre.
Avec cette version, les clients Databricks exécutant des charges de travail Iceberg peuvent désormais profiter des fonctionnalités de la v3, notamment les vecteurs de suppression, la lignée au niveau des lignes et le type de données Variant. Ces fonctionnalités permettent aux équipes d'exécuter des charges de travail modernes de manière efficace et cohérente sur les plateformes. Ces fonctionnalités fonctionnent également de manière transparente sur les tables Delta et Iceberg, permettant l'interopérabilité sans réécriture des données.

Cette version renforce l'engagement de Databricks envers les normes ouvertes et aide les clients à s'appuyer sur la base du lakehouse de Delta Lake, Apache Iceberg, Apache Parquet et Apache Spark, le tout avec une gouvernance et une flexibilité complètes.
Dans ce blog, nous allons explorer :
- Une couche de données unifiée avec Iceberg v3
- Des charges de travail Iceberg v3 efficaces sur Databricks
- Faire progresser les formats de table ouverts
Une couche de données unifiée avec Iceberg v3
Delta Lake et Apache Iceberg sont devenus la base du lakehouse moderne, chacun avec de solides capacités en matière de fiabilité, de gouvernance et de gestion évolutive des données. Ils utilisent tous deux des fichiers de métadonnées pour suivre les fichiers de données Parquet et les suppressions au niveau des lignes. Cependant, des différences mineures entre les formats de ces fichiers de données et de suppression ont souvent obligé les organisations à choisir un format et ses fonctionnalités, généralement en fonction des plateformes de données qu'elles utilisaient. Ce choix était souvent irréversible, car la réécriture de pétaoctets de données est irréalisable.
Iceberg v3 comble cette lacune. Il introduit des fonctionnalités qui s'alignent étroitement avec Delta et l'écosystème ouvert plus large, tels que Parquet et Spark, permettant aux équipes d'utiliser une seule copie des données avec un comportement et des performances cohérents sur les formats.
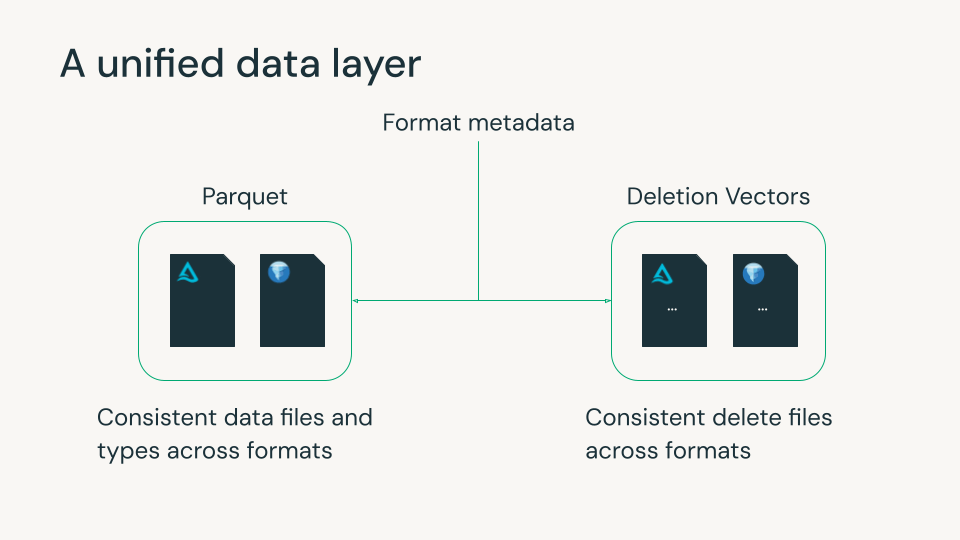
Databricks croit depuis longtemps que l'avenir du lakehouse est l'optionnalité sans fragmentation. Nos contributions à Iceberg v3 reflètent cet engagement : aider à unifier les comportements de table centraux afin que les clients puissent utiliser les moteurs et les outils qu'ils préfèrent tout en gouvernant tout de manière cohérente avec Unity Catalog.
Des charges de travail Iceberg v3 efficaces sur Databricks
Avec Iceberg v3, Databricks apporte les fonctionnalités de la Data Intelligence Platform à toutes les tables gérées par Unity Catalog.
Vecteurs de suppression pour des mises à jour plus rapides
Les vecteurs de suppression permettent de supprimer ou de mettre à jour des lignes sans réécrire les fichiers Parquet. Au lieu de cela, les suppressions sont stockées sous forme de fichiers séparés et fusionnées lors de la lecture. La plupart des charges de travail d'ingénierie de données ne modifient que quelques lignes à la fois, ce qui en fait une fonctionnalité essentielle pour des écritures efficaces.

Vous pouvez désormais profiter du prix-performance ETL de premier ordre de Databricks pour exécuter des charges de travail Iceberg à l'aide de vecteurs de suppression. Comparés aux instructions MERGE classiques, les vecteurs de suppression peuvent accélérer les mises à jour jusqu'à 10 fois. Les moteurs Iceberg peuvent lire et écrire sur des tables Iceberg gérées à l'aide des API Iceberg REST Catalog d'Unity Catalog. Comme le note Geodis :
« Maintenant que les vecteurs de suppression sont arrivés sur Iceberg, nous pouvons centraliser notre parc de données Iceberg dans Unity Catalog, tout en exploitant le moteur de notre choix et en maintenant des performances de premier ordre. » —Delio Amato, Architecte en chef et Data Officer, Geodis
Lignée au niveau des lignes pour la concurrence au niveau des lignes
La lignée au niveau des lignes donne à chaque ligne un identifiant unique, ce qui facilite le suivi des modifications au fil du temps. La lignée au niveau des lignes est requise pour toutes les tables Iceberg v3.
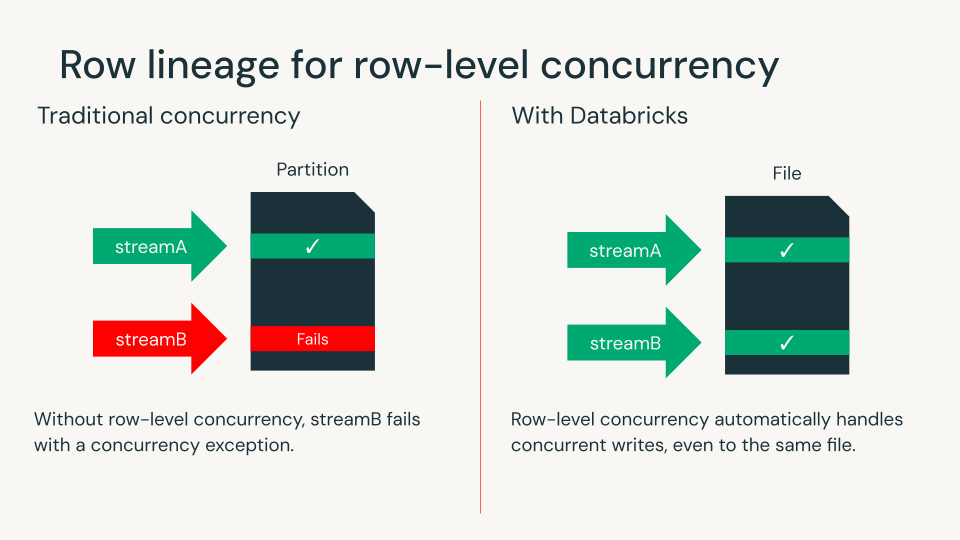
Avec les vecteurs de suppression et la lignée au niveau des lignes, les clients Databricks peuvent désormais utiliser la concurrence au niveau des lignes pour détecter les conflits d'écriture au niveau des lignes. Cela élimine la nécessité de concevoir des schémas de données complexes ou de coordonner les charges de travail pour assurer la concurrence. Databricks reste le seul moteur de lakehouse à apporter cette capacité aux formats de table ouverts.
Type de données Variant pour une ingestion flexible
Les données modernes s'intègrent rarement bien dans des lignes et des colonnes. Les journaux, les événements et les données d'application arrivent souvent au format JSON. Le type de données Variant stocke directement les données semi-structurées, offrant d'excellentes performances sans nécessiter de schémas complexes ou de pipelines fragiles.

En utilisant le type de données Variant dans Databricks, vous pouvez charger des données brutes directement dans vos tables lakehouse à l'aide de fonctions d'ingestion. Ces fonctions prennent en charge le chargement de données JSON, CSV et XML. Variant prend en charge le déchiquetage, qui extrait les champs courants en morceaux séparés pour offrir des performances de type colonne. Cela accélère les requêtes pour les pipelines de BI, de tableaux de bord et d'alertes à faible latence.
Variant fonctionne sur Delta et Iceberg. Les équipes utilisant différents moteurs peuvent interroger la même table, y compris les colonnes Variant, sans duplication de données :
« Fini le temps des données scalaires simples, en particulier pour les cas d'utilisation nécessitant des journaux de sécurité et d'application. Unity Catalog et Iceberg v3 libèrent la puissance des données semi-structurées grâce à Variant. Cela permet l'interopérabilité et la collecte de journaux à l'échelle du pétaoctet, rentable. » —Russell Leighton, Architecte en chef, Panther
Faire progresser les formats de table ouverts
Iceberg v3 marque une étape importante vers l'unification des formats de table ouverts dans la couche de données. La prochaine frontière consiste à améliorer la manière dont les formats gèrent et synchronisent les métadonnées à grande échelle. Les efforts de la communauté, tels que l'arbre de métadonnées adaptatif introduit pour la première fois au Iceberg Summit, peuvent réduire la surcharge des métadonnées et accélérer les opérations sur les tables à grande échelle.
À mesure que ces idées mûrissent, elles rapprochent les communautés Delta et Iceberg, avec des objectifs communs autour des commits plus rapides, de la gestion efficace des métadonnées et des opérations multi-tables évolutives. Databricks continue de contribuer à cette évolution, permettant aux clients d'obtenir les meilleures performances et interopérabilité sans être contraints par les différences au niveau du format.
Essayez Iceberg v3 dès aujourd'hui avec Databricks
Ces fonctionnalités d'Iceberg v3 sont désormais disponibles sur Databricks, offrant aux clients l'implémentation la plus tournée vers l'avenir de la norme, soutenue par la gouvernance d'Unity Catalog. Avec Iceberg v3, les clients Databricks peuvent tirer parti des meilleures fonctionnalités des tables Delta et Iceberg. La création d'une table gérée par Unity Catalog avec Iceberg v3 est facile :
Commencez avec Unity Catalog et Iceberg v3 et rejoignez-nous lors des prochains événements Open Lakehouse + AI pour en savoir plus sur notre travail dans l'écosystème ouvert.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.