Apache Iceberg™ v3: Moving the Ecosystem Towards Unification
Apache Iceberg™ v3 contains major new features (deletion vectors, row lineage, semi-structured data, geospatial types) and unifies the data layer across formats
by Ryan Blue, Daniel Weeks and Aniruth Narayanan
- Apache Iceberg™ v3 contains new features and improvements: Deletion Vectors, Row Level Lineage, Semi-Structured Data, and Geospatial Types
- With these features, Iceberg v3 unifies the data layer across Apache Iceberg™, Delta Lake, Apache Parquet, and Apache Spark™
- Databricks is integrating Iceberg v3 into the Data Intelligence Platform and is excited for the industry to adopt Iceberg v3
Apache Iceberg™ v3, now approved by the Apache Iceberg™ community, introduces advanced new features and data types. Iceberg v3 includes major improvements such as deletion vectors, row lineage, and new types for semi-structured data and geospatial use cases. These features allow customers to efficiently process and query data. Additionally, these improvements are consistent across Delta Lake, Apache Parquet, and Apache Spark™, so customers can interoperate between Delta and Apache Iceberg™ without rewriting data or row-level delete files.
In this blog post, we cover the newest developments in Iceberg v3:
- Deletion Vectors
- Row Lineage
- Semi-Structured Data and Geospatial Types
- Interoperability across Delta Lake, Apache Parquet, and Apache Spark
Deletion Vectors
Iceberg v3 introduces a new format for row-level deletes to improve read performance: deletion vectors. Row-level deletes significantly reduce write amplification by optimizing how deleted rows are stored and tracked — leading to faster ETL and ingestion. In Iceberg v2, engines were not required to compact delete files together during writes. The intent was for customers to use asynchronous maintenance. However, many customers did not schedule maintenance services, so their tables had too many unmaintained delete files. That led to slow read performance when engines had to merge many row-level delete files on read.

Iceberg v3 introduces a new deletion vector format and new compaction requirements for delete files. This new format avoids translation between Parquet files and in-memory representations used to apply the deletes. Additionally, engines must maintain a single deletion vector per file at write time. This requirement improves performance and statistics on data files. This also makes it easy to compare previous and current deletes, which simplifies processing a table's row-level changes as a stream.
Row Lineage
Another major Iceberg v3 feature is row lineage, used to simplify incremental processing. With row lineage, engines find row-level changes by matching versions of rows across commits.
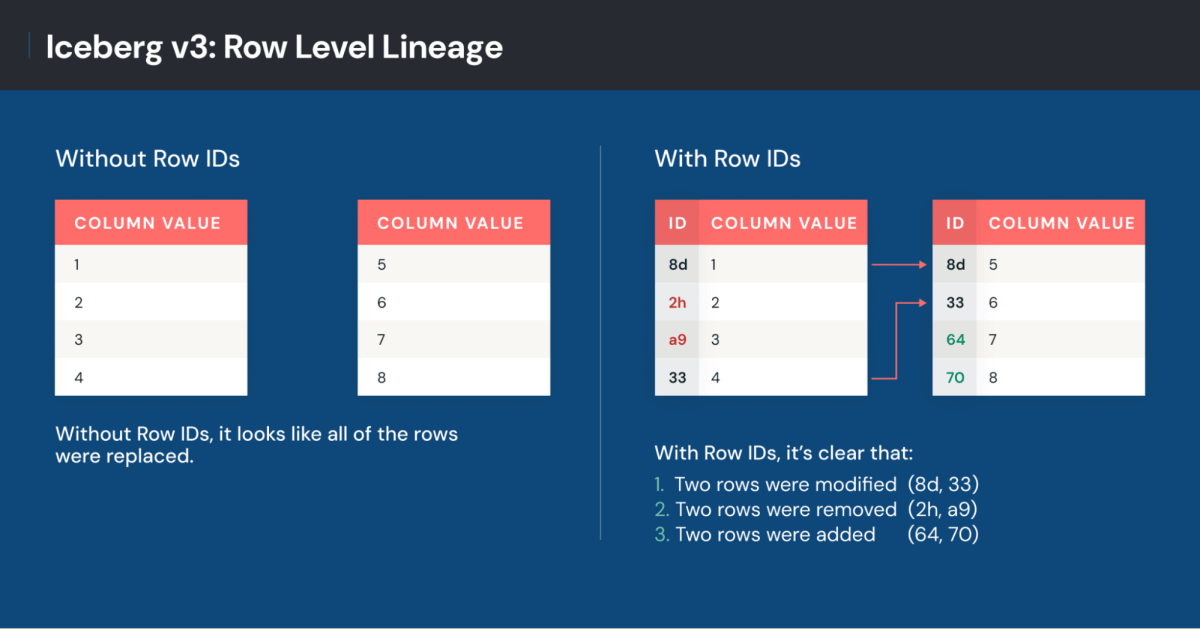
Iceberg v3 introduces row lineage using row-level metadata: a row ID and the sequence number when the row was last modified or added. The IDs identify the same row across versions. Sequence numbers annotate when rows were last changed - not just relocated between files. This allows engines to process changes selectively, simplifying downstream updates with faster and cheaper workflows.
Row ID information is especially beneficial when combined with incremental processing objects like materialized views. These objects are optimized to compute only new or changed data since the last processing cycle.
Semi-Structured Data and Geospatial Types
Iceberg v3 also adds new data types for semi-structured data and geospatial data.
Semi-structured data is hard to store because it has varying schemas, which do not fit into structured table columns. One workaround is to extract individual fields from this data into a structured format. However, this creates extremely wide tables with many columns and NULL values due to inconsistent schemas. Another alternative is to store JSON in string columns. Unfortunately, this results in poor read performance because engines must parse data from these strings. Without semi-structured data types, engines cannot push down filters, so they need to read every row in every data file. Iceberg v3 introduces VARIANT to represent semi-structured data efficiently. VARIANT encodes the structure of the data to improve performance while maintaining schema flexibility.
Similarly, geospatial data — information associated with locations on the Earth’s surface like roads, parks, or city boundaries — is also hard to work with and query efficiently. Without geospatial types, customers had to use binary columns to store geodata locations. However, this representation did not support geographic searching, since binary columns cannot be filtered to find objects within a given area. Iceberg v3 solves this problem by introducing new geometry and geography data types. Geometry types are for planar spatial data, whereas geography types are for global data accounting for the curvature of the earth. With these types, customers easily find data using bounding boxes that represent geographic regions and efficiently locate geospatial objects.

Interoperability with Delta Lake, Apache Parquet, and Apache Spark™
Iceberg v3's new features and data types expand functionality and improve performance. These Apache Iceberg features are also important because they push interoperability among lakehouse formats.
Historically, customers have been forced to choose between two of the most popular lakehouse formats: Delta Lake and Apache Iceberg. This is because most platforms support only one format. Rewriting data can be costly and impractical at scale, making this choice long-term. The formats are very similar: both are metadata layers on top of Parquet data files to provide table semantics. However, small differences in the table formats cause issues for customers.
Iceberg v3 unifies the data layer across formats. With data unification, customers can interoperate across Delta and Iceberg without needing to rewrite data or delete files. This is because Iceberg v3’s features have compatible implementations across Delta Lake, Apache Parquet, and Apache Spark:
- Deletion vectors use the same binary encodings across table formats
- Row-level lineage in Iceberg v3 is compatible with row tracking in Delta Lake
VARIANTand geodata types are being developed in the upstream Apache Parquet and Apache Spark™ communities, which extends to Apache Iceberg and Delta Lake
By having compatible features across open-source projects, Iceberg v3 avoids forcing customers into choosing a format. Instead, customers can interoperate freely between formats on one copy of their data.
Learn More About Iceberg v3
Iceberg v3 moves the entire industry forward to a more performant, capable, and interoperable world. We are integrating Iceberg v3 into the Databricks Data Intelligence Platform and look forward to other vendors adopting Iceberg v3. Open-source is a core value at Databricks, where we actively contribute features such as deletion vectors to Iceberg v3. To foster a thriving open source community, we support and encourage contributions to Apache Iceberg. For new contributors, we recommend starting with a “good first issue”.
To learn about how we plan to integrate Iceberg v3 features into our managed table offering and the future of open table formats, register for the Data and AI Summit on June 9-12, 2025.
Get the latest posts in your inbox
Subscribe to our blog and get the latest posts delivered to your inbox.