AiChemy : Agent de nouvelle génération avec MCP, compétences et données personnalisées pour la découverte de médicaments
AiChemy accélère la découverte de médicaments en intégrant des données personnalisées et externes (OpenTargets, PubChem, PubMed) via un système multi-agents utilisant MCP, Skills, AI Search et Genie sur Databricks
par Yen Low et Sean Zhang
- Un guide pour construire AiChemy, un système multi-agents sur Databricks qui intègre des bases de connaissances externes (OpenTargets, PubChem, PubMed) via le Model Context Protocol (MCP) avec des données structurées et non structurées sur Databricks.
- Le défi qu'il résout : Il accélère la recherche interdisciplinaire de découverte de médicaments en permettant une collaboration autonome entre divers agents IA, leur permettant de passer au crible d'énormes ensembles de données disparates et de fournir des résultats traçables et étayés par des preuves.
- Résultats : Les chercheurs peuvent identifier des cibles de maladies, évaluer des candidats médicaments, récupérer des propriétés détaillées et effectuer des évaluations de sécurité, conduisant à une découverte de médicaments et à une génération de pistes plus efficaces.
Les systèmes multi-agents accélèrent la recherche interdisciplinaire
Imaginez des systèmes d'IA multi-agents collaborant comme une équipe d'experts interdisciplinaires, analysant de manière autonome des ensembles de données massifs pour découvrir de nouveaux modèles et hypothèses. Ceci est maintenant facilement réalisable avec le Model Context Protocol (MCP), une nouvelle norme pour intégrer facilement diverses sources de données et outils. L'écosystème croissant de serveurs MCP, des bases de connaissances aux générateurs de rapports, offre des capacités infinies.
Ce que fait AiChemy
Découvrez AiChemy, un assistant multi-agents qui combine des serveurs MCP externes comme OpenTargets, PubChem et PubMed avec vos propres bibliothèques chimiques sur Databricks afin que les bases de connaissances combinées puissent être mieux analysées et interprétées ensemble. Il dispose également de compétences qui peuvent être chargées en option pour fournir des instructions détaillées pour la production de rapports spécifiques à une tâche, formatés de manière cohérente pour les besoins de recherche, réglementaires ou commerciaux.
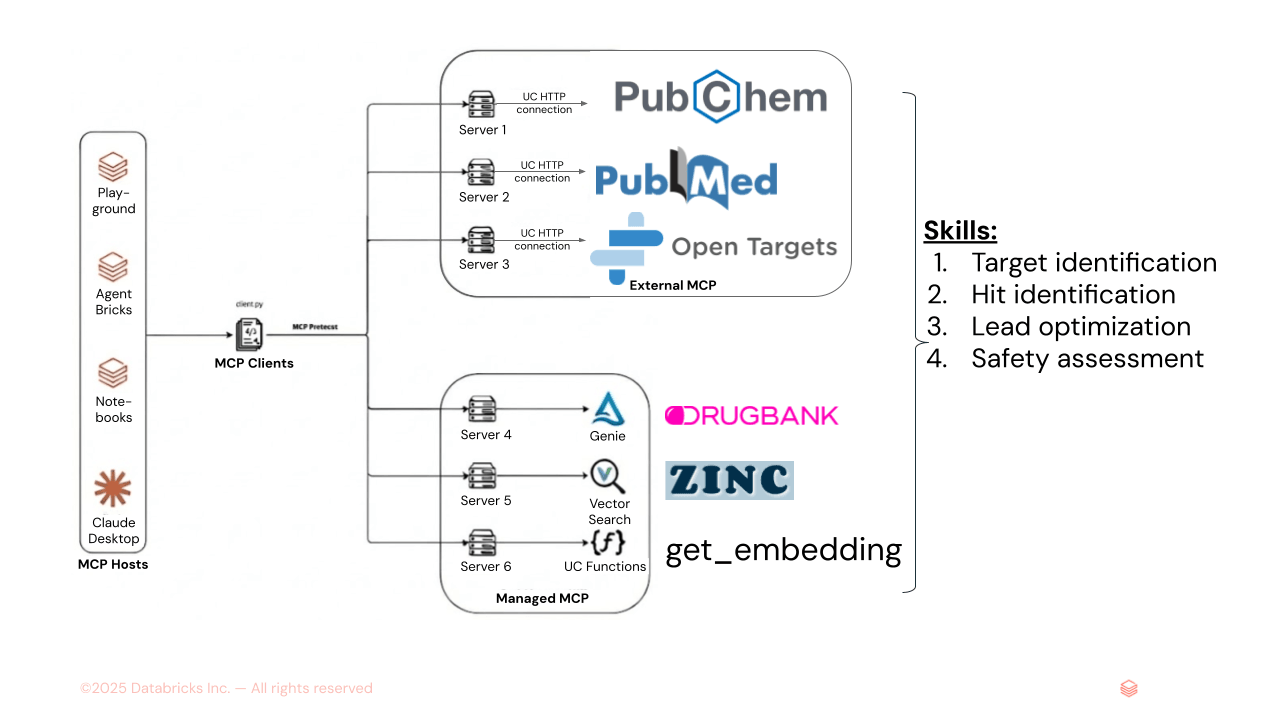
Figure 1. AiChemy est un superviseur multi-agents comprenant les serveurs MCP externes PubChem, PubMed et OpenTargets, et les serveurs MCP gérés par Databricks de Genie Space (texte-vers-SQL pour les données structurées DrugBank) et de AI Search (pour les données non structurées comme les plongements moléculaires ZINC). Des compétences peuvent également être chargées pour spécifier la séquence des tâches et le formatage et le style des rapports afin d'assurer une sortie cohérente.
Ses capacités clés incluent l'identification de cibles de maladies et de candidats médicaments, la récupération de leurs propriétés chimiques et pharmacocinétiques détaillées, et la fourniture d'évaluations de sécurité et de toxicité. Crucialement, AiChemy étaye ses conclusions par des preuves justificatives traçables à des sources de données vérifiables, ce qui le rend idéal pour la recherche.
Cas d'utilisation 1 : Comprendre les mécanismes des maladies, trouver des cibles exploitables et générer des pistes
Le panneau Tâches guidées fournit les invites et les compétences d'agent nécessaires pour effectuer les étapes clés d'un flux de travail de découverte de médicaments : maladie -> cible -> médicament -> validation par la littérature.
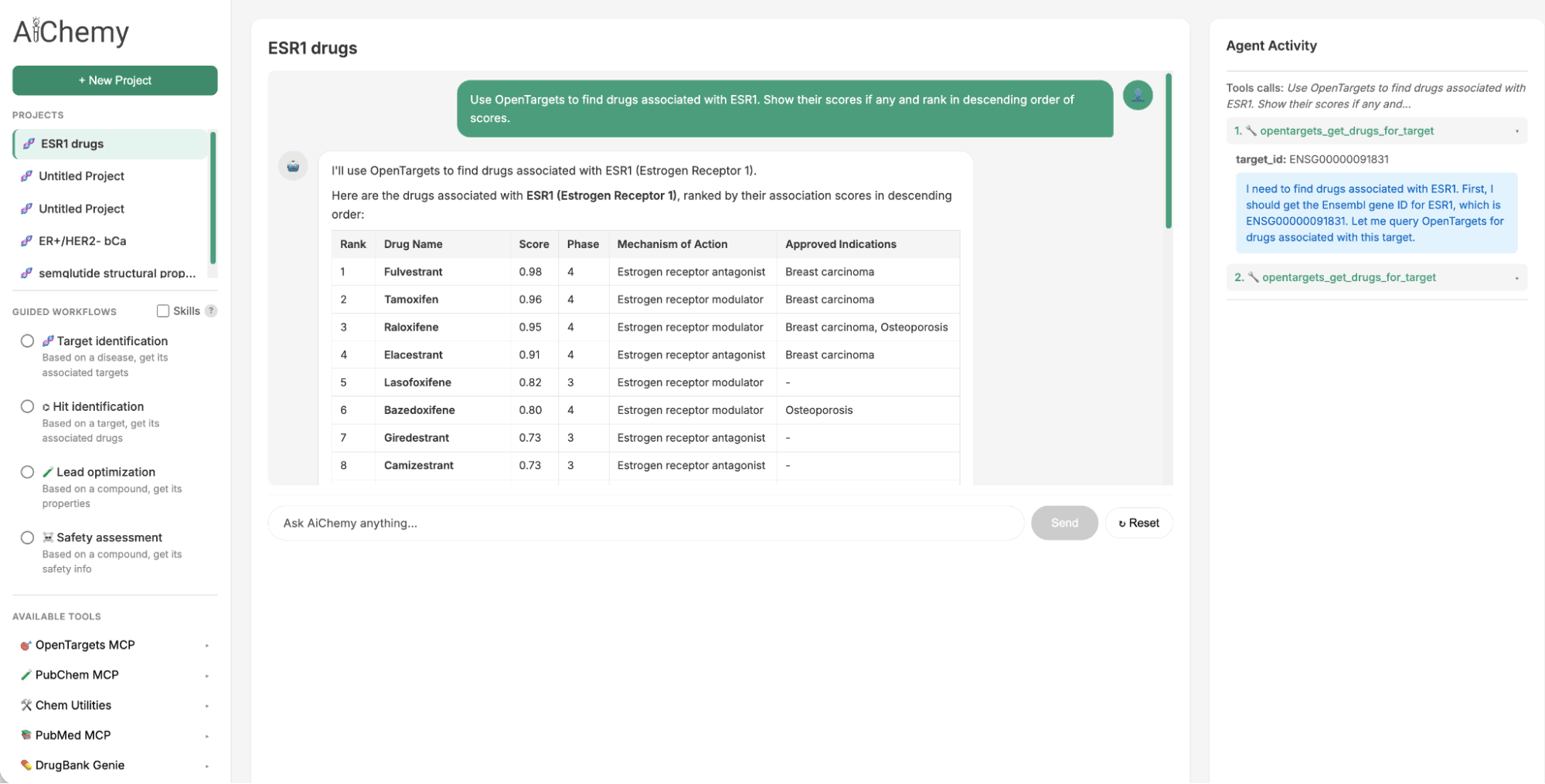
- Identifier les cibles thérapeutiques : En partant d'un sous-type de maladie spécifique, tel que le cancer du sein Estrogène-Positif (ER+)/HER2-négatif (HER2-) (où ER et HER2 sont des biomarqueurs protéiques clés), trouvez les cibles thérapeutiques associées (par exemple, ESR1).
- Trouver des médicaments associés : Utilisez la cible identifiée (par exemple, ESR1) pour trouver des candidats médicaments potentiels.
- Valider par la littérature : Pour un candidat médicament donné (par exemple, camizestrant), vérifiez la littérature scientifique pour obtenir des preuves justificatives.
Cas d'utilisation 2 : Génération de pistes par similarité chimique
Pour identifier un suivi du modulateur sélectif des récepteurs aux œstrogènes (SERM) oral approuvé en 2023, Elacestrant, nous pouvons exploiter la similarité chimique. Nous recherchons dans la grande bibliothèque chimique ZINC15 des molécules de type médicament structurellement similaires à Elacestrant, car les principes de la relation quantitative structure-activité (QSAR) suggèrent qu'elles partageront des propriétés similaires. Ceci est réalisé en interrogeant Databricks AI Search, qui utilise le plongement moléculaire Extended-Connectivity Fingerprint (ECFP) de 1024 bits d'Elacestrant (comme vecteur de requête) pour trouver les plongements les plus similaires dans l'index de 250 000 molécules de ZINC.
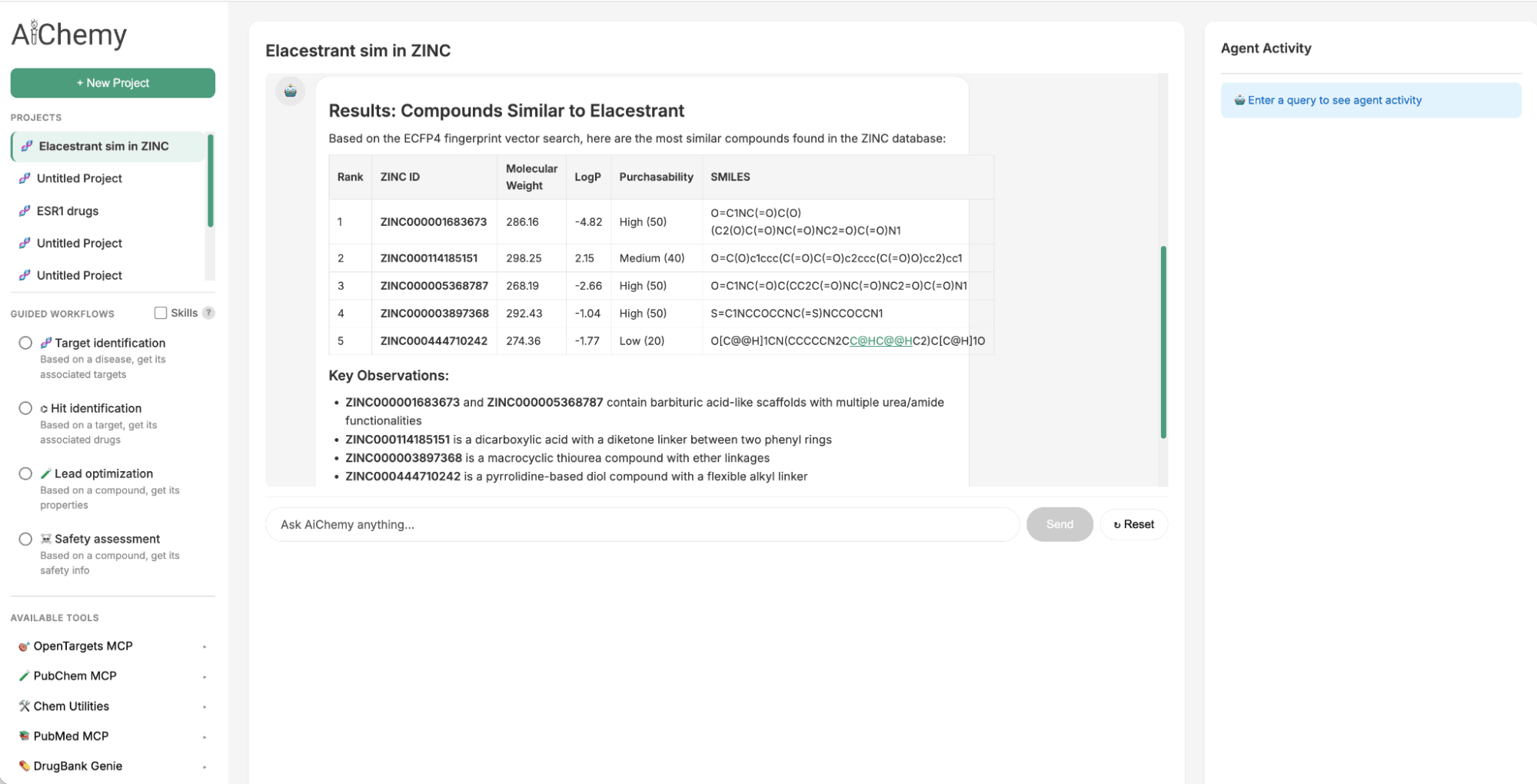
Figure 2. AiChemy inclut la recherche vectorielle de la base de données ZINC de 250 000 molécules disponibles dans le commerce. Cela nous permet de générer des composés principaux par similarité chimique. Dans cette capture d'écran, nous avons demandé à AiChemy de trouver dans la recherche vectorielle ZINC les composés les plus similaires à Elacestrant sur la base du plongement moléculaire ECFP4.
Créez votre propre superviseur multi-agents de recherche
Nous allons personnaliser un superviseur multi-agents sur Databricks en intégrant des serveurs MCP publics avec des données propriétaires sur Databricks. Pour ce faire, vous avez la possibilité d'utiliser des options sans code comme Agent Bricks ou des options de codage comme les Notebooks. Le Databricks Playground permet un prototypage et une itération rapides de vos agents.
Étape 1 : Préparer les composants requis pour le superviseur multi-agents
Le système multi-agents comporte 5 agents :
- OpenTargets : serveur MCP externe d'un graphe de connaissances maladie-cible-médicament
- PubMed : serveur MCP externe de littérature biomédicale
- PubChem : serveur MCP externe de composés chimiques
- Bibliothèque de médicaments (Genie) : Une bibliothèque chimique avec des propriétés de médicaments structurées, transformée en un espace Genie pour fournir des capacités de texte-vers-SQL.
- Bibliothèque chimique (AI Search) : Une bibliothèque propriétaire de données chimiques non structurées avec des plongements d'empreintes moléculaires, préparée comme un index vectoriel pour faciliter la recherche de similarité par plongements.
Étape 1a : Connectez-vous en toute sécurité aux serveurs MCP publics via les connexions Unity Catalog (UC) dans l'interface utilisateur ou dans un Notebook Databricks (par exemple, 4_connect_ext_mcp_opentarget.py).
Étape 1b : Assurez-vous que votre ou vos tables structurées (par exemple, DrugBank) sont transformées en un espace Genie avec fonctionnalité texte-vers-SQL en utilisant l'interface utilisateur. Voir 1_load_drugbank and descriptors.py
Étape 1c : Assurez-vous que votre bibliothèque chimique non structurée est créée comme un index vectoriel dans l'interface utilisateur ou dans un Notebook pour permettre la recherche de similarité. Voir 2_create VS zinc15.py
Étape 2 (Option facile) : Construire le superviseur multi-agents à l'aide de l'Agent Superviseur sans code en 2 minutes
Pour les assembler, essayez les Agent Bricks sans code qui créent un agent superviseur avec les composants ci-dessus via l'interface utilisateur et le déploient sur un point d'accès API REST, le tout en quelques minutes.
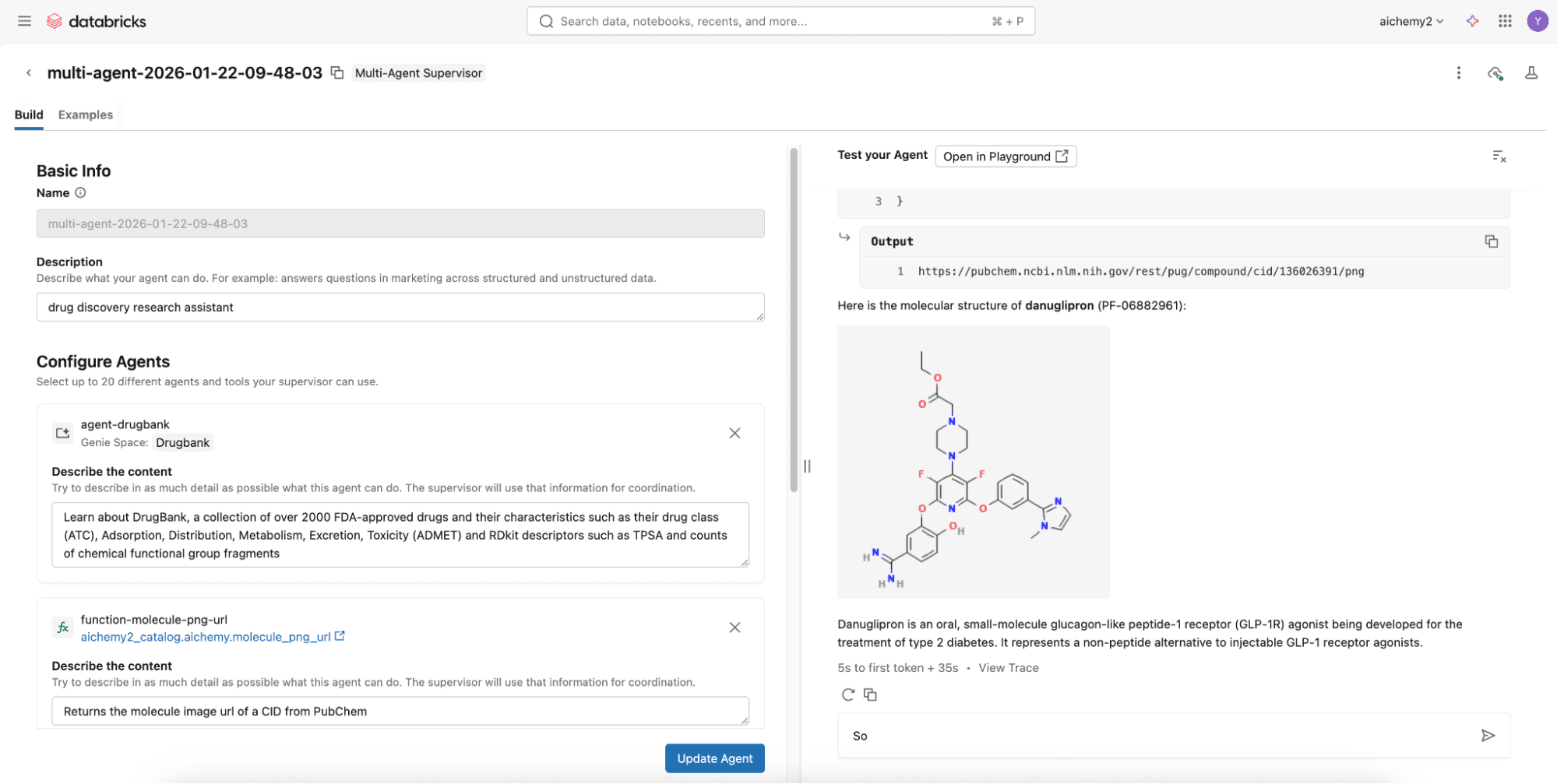
Étape 2 (Option avancée) : Créer le superviseur multi-agents à l'aide des notebooks Databricks
Pour des capacités plus avancées comme la mémoire agentique et les compétences (Skills), développez un superviseur Langgraph sur les notebooks Databricks pour l'intégrer à Lakebase, la base de données Databricks Serverless Postgres. Consultez ce dépôt de code où vous pouvez simplement définir les composants multi-agents (voir étape 1) dans le fichier config.yml.
Une fois le fichier config.yml défini, vous pouvez déployer le superviseur multi-agents en tant que MLflow AgentServer (wrapper FastAPI) avec une interface utilisateur web React (UI). Déployez-les tous les deux sur Databricks Apps via l'interface utilisateur ou la Databricks CLI. Définissez les autorisations appropriées pour que les utilisateurs puissent utiliser Databricks App et pour que le principal de service de l'application puisse accéder aux ressources sous-jacentes (par exemple, une expérience pour l'enregistrement des traces, un périmètre de secrets le cas échéant).
Étape 3 : Évaluer et surveiller votre agent
Chaque invocation de l'agent est automatiquement enregistrée et tracée vers une expérience Databricks MLflow en utilisant les normes OpenTelemetry. Cela permet une évaluation facile des réponses hors ligne ou en ligne pour améliorer l'agent au fil du temps. De plus, votre agent multi-agents déployé utilise le LLM derrière AI Gateway afin que vous puissiez bénéficier d'une gouvernance centralisée, de protections intégrées et d'une observabilité complète pour la préparation à la production.
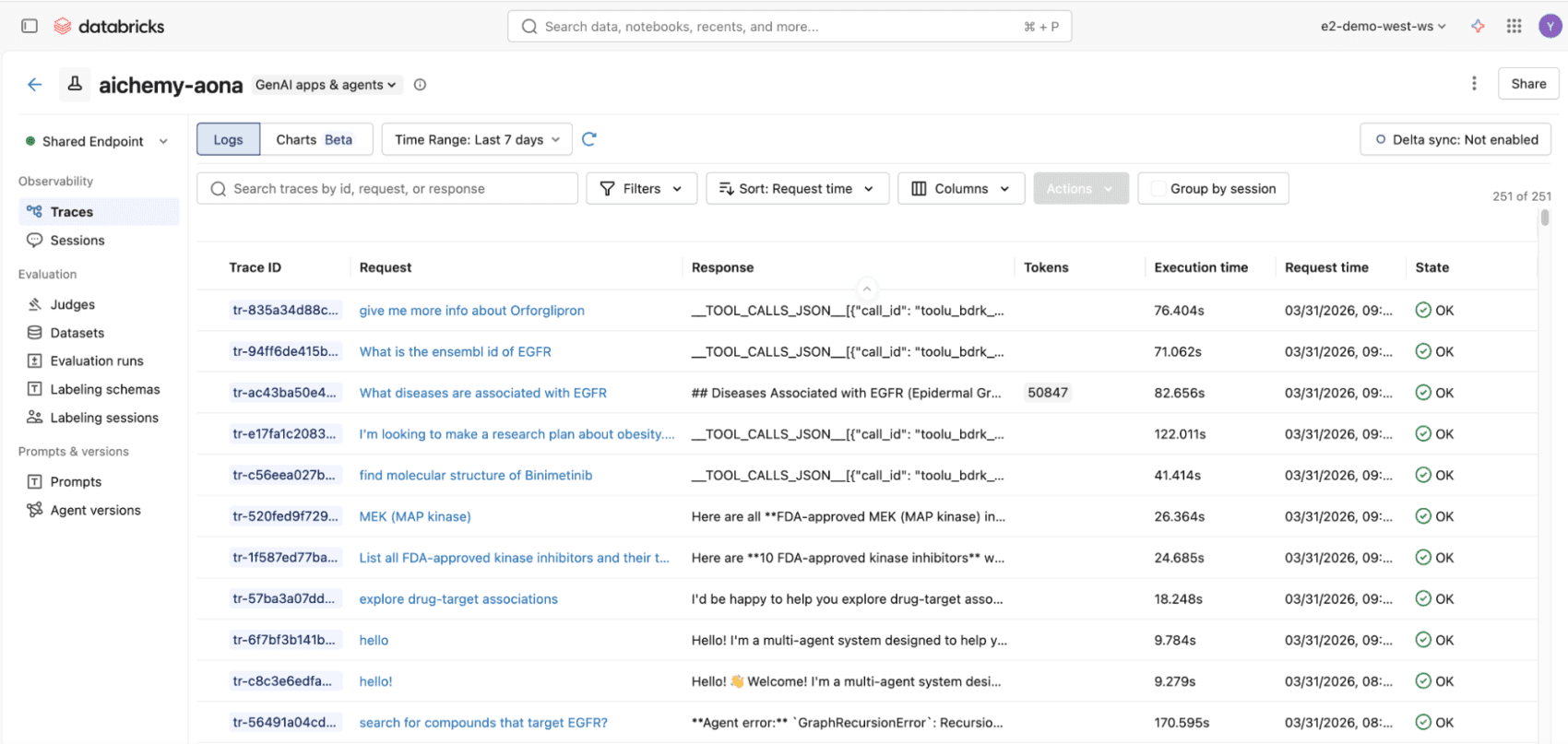
Figure 3. Toutes les invocations de l'agent multi-agents, que ce soit via l'interface utilisateur React ou l'API REST, seront enregistrées dans les traces MLflow, conformes aux normes OpenTelemetry, pour une observabilité de bout en bout.
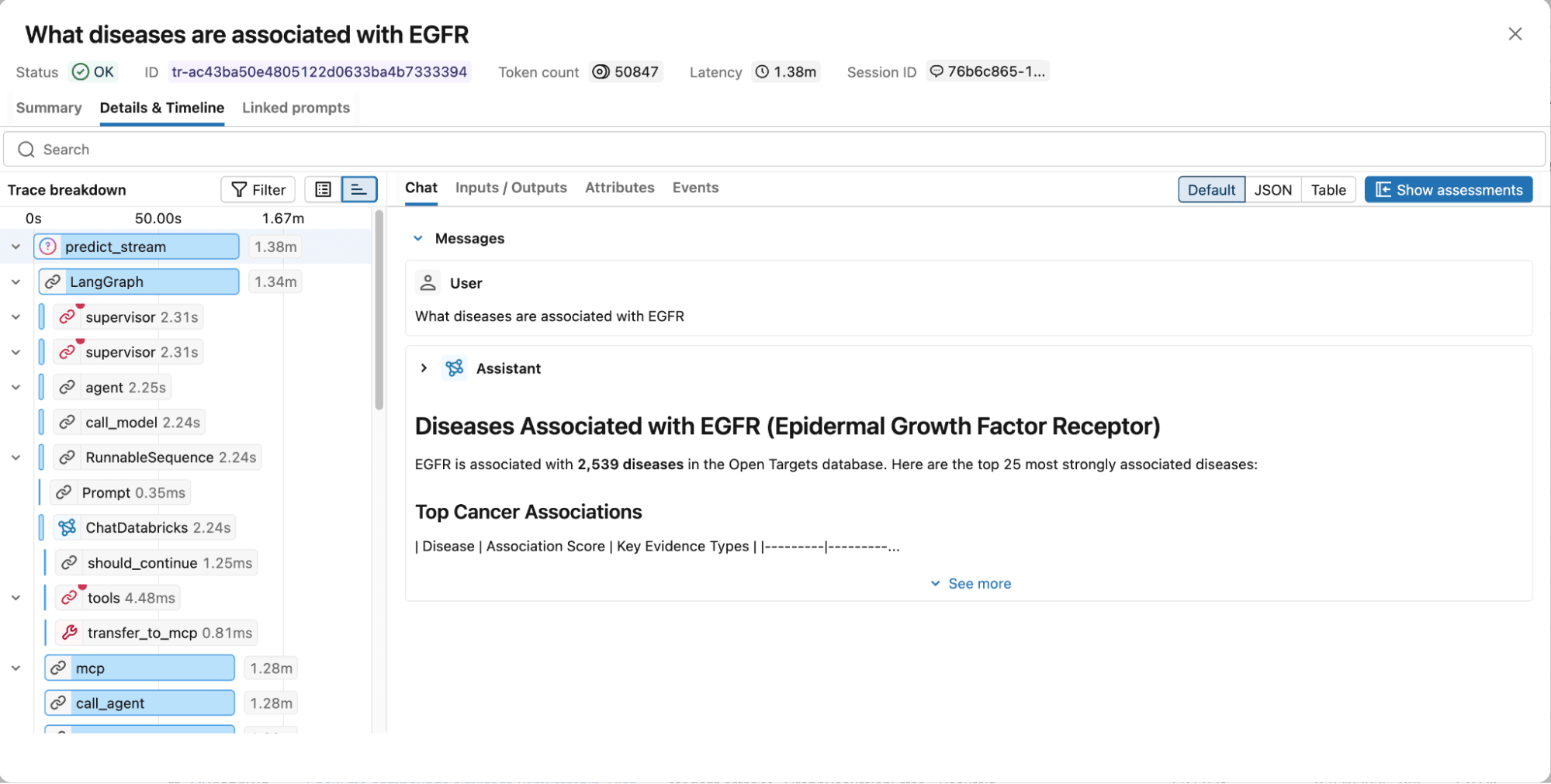
Figure 4. Les traces MLflow capturent le graphe d'exécution complet, y compris les étapes de raisonnement, les appels d'outils, les documents récupérés, la latence et l'utilisation des jetons pour faciliter le débogage et l'optimisation.
Prochaines étapes
Nous vous invitons à explorer l'application web AiChemy et le dépôt Github. Commencez à construire votre système multi-agents personnalisé avec le framework intuitif sans code Agent Bricks sur Databricks afin que vous puissiez arrêter de fouiller et commencer à découvrir !

(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.