Annonce du parcours d'apprentissage pour les ingénieurs analytiques Databricks
Un nouveau parcours qui enseigne aux praticiens SQL comment modéliser les données, construire des pipelines, définir des métriques et déployer des espaces Genie sur Databricks
par Maroua Lazzarou et Pratyarth Rao
- Des analyses et une IA fiables dépendent de fondations de données bien construites, et les praticiens SQL sont ceux qui construisent les pipelines, les modèles et les métriques qui les alimentent.
- Un nouveau parcours d'apprentissage pour les praticiens SQL qui couvre les compétences nécessaires pour utiliser la boîte à outils ETL SQL complète sur Databricks - modélisation de données, pipelines SQL déclaratifs pour des transformations légères ou des flux de travail de bout en bout gouvernés, couches sémantiques cohérentes et agents conversationnels.
- Les cours sont disponibles dès maintenant sur Databricks Academy, en formats auto-appris et dirigés par un instructeur, afin que vous puissiez commencer à apprendre dès aujourd'hui. Également inclus avec tout abonnement Databricks Learning actif.
Aujourd'hui, nous lançons le nouveau Parcours d'apprentissage pour les ingénieurs analytiques Databricks. Ce programme vous enseigne comment transformer des données brutes en modèles sémantiques gouvernés et prêts pour l'IA modèles sémantiques et vues métriques, la base de confiance qui alimente l'analytique, les tableaux de bord et les agents IA sur le lakehouse. Le parcours s'adresse aux praticiens SQL prêts à assumer davantage de responsabilités sur les données dont leurs équipes dépendent.
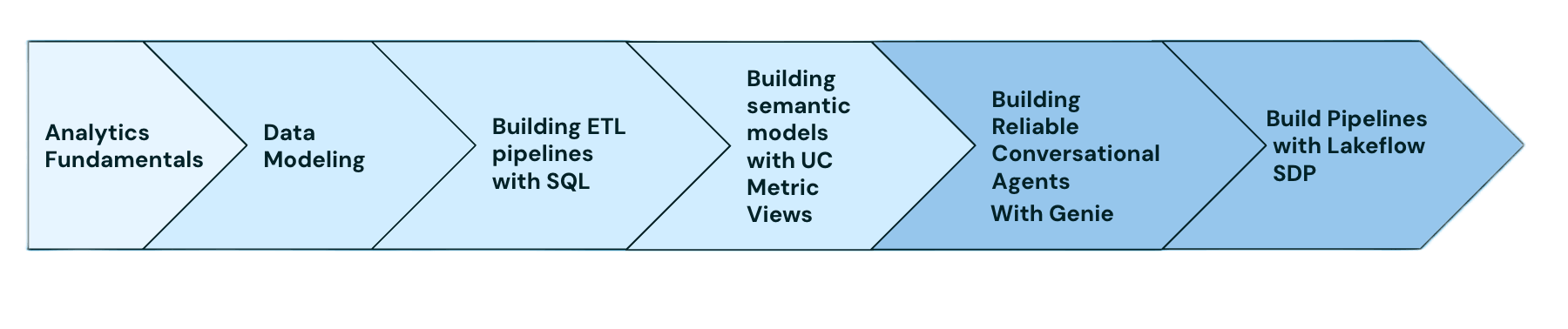
Pourquoi l'ingénierie analytique devient essentielle
SQL a toujours été le fondement de l'analytique moderne. Mais le travail qui s'appuie sur lui s'élargit — vers la modélisation, les pipelines, les métriques et les couches de données dont dépendent désormais les agents et les tableaux de bord.
Une analytique et une IA fiables reposent sur la même base : des données qui sont gouvernées, modélisées et fiables. Construire cette base est plus difficile qu'auparavant. Les données résident dans davantage de sources et alimentent plus de consommateurs en aval. Les équipes de données traditionnellement responsables de la préparation des données sont débordées. Selon un récent rapport Economist Enterprise, près des deux tiers des organisations dépendent entièrement des ingénieurs de données pour chaque aspect de la création de pipelines, et près de la moitié de ces ingénieurs passent la majeure partie de leur temps à configurer et à réparer les connexions aux sources de données. Il y a une capacité limitée à absorber le nouveau travail. De plus en plus, cela incombe aux praticiens les plus proches des affaires : ceux qui travaillent avec SQL.
Les praticiens SQL sont plus proches des affaires et comprennent les questions posées, les données sous-jacentes et les métriques qui intéressent les équipes. L'ingénierie analytique est la discipline qui consiste à utiliser ce contexte pour construire des modèles, des pipelines et des métriques sur lesquels l'entreprise peut compter. Les outils pour ce travail sont désormais natifs SQL. Le jugement nécessaire pour bien les utiliser est ce que ce parcours enseigne.
À l'intérieur du parcours
Le parcours d'ingénierie analytique se compose de cours pratiques qui couvrent la boîte à outils complète ETL SQL sur Databricks. Commencez par les Fondamentaux de l'analytique pour vous familiariser avec le fonctionnement de l'analytique sur le lakehouse. À partir de là, le reste du programme approfondit chaque partie des compétences en ingénierie analytique enseignées par des experts Databricks et construit autour d'exemples pratiques.
1. Fondamentaux de l'analytique: Apprenez comment l'analytique fonctionne sur Databricks : sémantique unifiée, tableaux de bord IA/BI et Genie. Un cours d'introduction d'une heure.
2. Stratégies de modélisation de données: Apprenez à concevoir des modèles de données qui tiennent en production sur le lakehouse.
- Aligner l'organisation des données et la conception des modèles sur les exigences commerciales
- Définir des architectures de données à l'aide de Delta Lake et Unity Catalog
- Comprendre le cycle de vie des produits de données sur le lakehouse
- Appliquer des techniques d'intégration et de partage de données
3. Construire des pipelines ETL avec SQL: Apprenez à construire des pipelines ETL SQL de production avec des vues matérialisées, des tables de streaming et des tâches Lakeflow
- Utiliser les tables de streaming, les vues matérialisées et AUTO CDC pour des pipelines déclaratifs.
- Implémenter l'ingestion incrémentielle et les transformations dans l'architecture médaillon.
- Gérer les dimensions à changement lent (SCD) de type 1 et 2 avec AUTO CDC.
- Orchestrer les pipelines à l'aide de tâches Lakeflow et de flux de travail basés sur SQL
4. Construire des modèles sémantiques avec les vues métriques UC: Apprenez à définir et à gouverner les métriques commerciales en SQL, puis à rendre accessibles des chiffres fiables partout où ils sont consommés.
- Définir et gérer les vues métriques dans Unity Catalog
- Modéliser des métriques avancées, y compris des mesures fenêtrées et semi-additives
- Intégrer avec les tableaux de bord Databricks, les espaces Genie et les flux de travail SQL
- Appliquer les pratiques de gouvernance, de sécurité et de maintenance
5. Construire des agents conversationnels fiables avec Genie: Apprenez à concevoir, déployer et améliorer continuellement des espaces Genie auxquels les utilisateurs métier peuvent faire confiance.
- Configurer les espaces Genie avec des tables Unity Catalog, des entrepôts SQL et des benchmarks
- Curater le Knowledge Store avec des synonymes, des descriptions et des fonctionnalités de correspondance de prompts
- Encoder la logique métier en SQL avec des expressions dérivées, des jointures et des instructions
- Gouverner l'accès avec les permissions Unity Catalog et les politiques ABAC
- Itérer en utilisant des benchmarks, les retours des utilisateurs et les sorties observées
6. Construire des pipelines avec les pipelines déclaratifs Spark Lakeflow: Apprenez à construire des pipelines SQL de bout en bout et gouvernés à l'aide de l'éditeur de pipelines déclaratifs Spark.
- Comprendre les tables de streaming, les vues matérialisées et les vues temporaires
- Appliquer la qualité des données avec des attentes intégrées
- Gérer les dimensions à changement lent avec AUTO CDC INTO
- Analyser l'exécution des pipelines via les journaux d'événements et les métriques
Chaque cours est disponible en formats auto-rythmé et dirigé par un instructeur. L'ensemble du parcours est également inclus dans tout abonnement d'apprentissage Databricks actif.
Commencez votre parcours dès aujourd'hui
Le parcours d'apprentissage pour ingénieurs analytiques est disponible dès maintenant sur Databricks Academy. À la fin, vous modéliserez des données brutes, déploierez des pipelines et définirez les métriques qui alimentent les tableaux de bord et l'IA.
Si vous dirigez une équipe, le parcours est également le moyen le plus rapide pour que votre équipe fournisse des informations sur lesquelles les utilisateurs métier s'appuient pour prendre des décisions.
Commencez à explorer avec les Fondamentaux de l'analytique dès aujourd'hui, et visitez Databricks Academy pour continuer à développer vos compétences sur le reste du parcours.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.