Annonce de la disponibilité générale du mode temps réel pour Apache Spark Structured Streaming sur Databricks
Alimentez vos charges de travail les plus critiques en temps, de la détection de fraude à la personnalisation, avec une latence inférieure à la seconde
par Navneeth Nair et Giselle Goicochea
- Latence inférieure à la seconde sur Spark : Le mode temps réel (RTM) dans Apache Spark Structured Streaming est maintenant disponible en général, offrant des performances de bout en bout de l'ordre de la milliseconde aux API Spark familières et éliminant le besoin d'un autre moteur spécialisé, tel qu'Apache Flink.
- Innovation architecturale : RTM atteint des vitesses de traitement inférieures à 100 ms grâce à trois innovations : flux de données continu, planification de pipeline et streaming shuffle.
- Prouvé à l'échelle : Des leaders de l'industrie tels que Coinbase, DraftKings et MakeMyTrip utilisent RTM pour alimenter des cas d'utilisation opérationnels critiques, certains atteignant une réduction de latence de plus de 80 %.
Depuis des années, Apache Spark Structured Streaming alimente certaines des charges de travail de streaming les plus exigeantes au monde. Cependant, pour les cas d'utilisation à latence ultra-faible, les équipes devaient maintenir des moteurs spécialisés distincts — le plus souvent Apache Flink, en plus de Spark, dupliquant les bases de code, les modèles de gouvernance et la surcharge opérationnelle. Désormais, Databricks supprime ce fardeau pour ses clients.
Aujourd'hui, nous sommes ravis d'annoncer la disponibilité générale du mode temps réel (RTM) dans Spark Structured Streaming, apportant une latence de l'ordre de la milliseconde aux API Spark que vous utilisez déjà. Qu'il s'agisse de détecter la fraude en temps réel ou de générer un contexte récent et en temps réel pour piloter vos agents IA, vous pouvez désormais utiliser Spark pour tous ces cas d'utilisation.
Alimenter des clients et des cas d'utilisation leaders de l'industrie
Le RTM a déjà été adopté par des équipes d'organisations leaders de l'industrie dans les services financiers, le commerce électronique, les médias et la technologie publicitaire pour alimenter la détection de fraude, la personnalisation en direct, le calcul de caractéristiques ML et l'attribution publicitaire.
Coinbase, l'une des principales plateformes d'échange de cryptomonnaies au monde, utilise le RTM pour faire évoluer ses moteurs de gestion des risques et de détection de fraude à haute fréquence — traitant des volumes massifs d'événements blockchain et d'échange avec la latence inférieure à 100 ms nécessaire pour sécuriser des millions de transactions d'actifs numériques.
En tirant parti du mode temps réel dans Spark Structured Streaming, nous avons obtenu une réduction de plus de 80 % des latences de bout en bout, atteignant des P99 inférieures à 100 ms, et rationalisé notre stratégie ML en temps réel à grande échelle. Ces performances nous permettent de calculer plus de 250 caractéristiques ML, le tout alimenté par un moteur Spark unifié.”—Daniel Zhou, Senior Staff Machine Learning Platform Engineer, Coinbase
DraftKings, l'une des plus grandes plateformes de paris sportifs et de fantasy sports d'Amérique du Nord, utilise le mode temps réel pour alimenter le calcul de caractéristiques pour ses modèles de détection de fraude — traitant des flux d'événements de paris à haut débit avec la latence et la fiabilité requises pour les décisions de paris en argent réel.
Dans les paris sportifs en direct, la détection de fraude exige une vitesse extrême. L'introduction du mode temps réel, associée à l'API transformWithState dans Spark Structured Streaming, a changé la donne pour nous. Nous avons obtenu des améliorations substantielles à la fois en termes de latence et de conception de pipeline, et pour la première fois, nous avons construit des pipelines de caractéristiques unifiés pour l'entraînement ML et l'inférence en ligne, atteignant des latences ultra-faibles qui n'étaient tout simplement pas possibles auparavant.”—Maria Marinova, Sr. Lead Software Engineer, DraftKings
MakeMyTrip, l'une des principales plateformes de voyage en ligne en Inde pour les hôtels, les vols et les expériences, a adopté le mode temps réel pour alimenter les expériences de recherche personnalisées. Le RTM a traité un grand volume de recherches d'utilisateurs pour fournir des recommandations en temps réel.
Dans la recherche de voyages, chaque milliseconde compte. En tirant parti du mode temps réel Spark (RTM), nous avons offert des expériences personnalisées avec des latences P50 inférieures à 50 ms, entraînant une augmentation de 7 % des taux de clics. Le RTM a également transformé nos opérations de données, permettant une architecture unifiée où Spark gère tout, de l'ETL à haut débit aux pipelines à latence ultra-faible. Alors que nous entrons dans l'ère des agents IA, les piloter efficacement nécessite de construire un contexte en temps réel à partir de flux de données. Nous expérimentons le RTM de Spark pour fournir à nos agents le contexte le plus riche et le plus récent nécessaire pour prendre les meilleures décisions possibles. —Aditya Kumar, Associate Director of Engineering, MakeMyTrip
Le RTM peut prendre en charge toutes les charges de travail qui bénéficient de la transformation des données en décisions en quelques millisecondes. Voici quelques exemples de cas d'utilisation :
- Expériences personnalisées dans le commerce de détail et les médias : Un fournisseur de streaming OTT met à jour les recommandations de contenu immédiatement après qu'un utilisateur a fini de regarder un programme. Une plateforme de commerce électronique leader recalcule les offres de produits pendant que les clients naviguent — maintenant l'engagement élevé avec des boucles de rétroaction inférieures à la seconde.
- Surveillance IoT : Une entreprise de transport et de logistique ingère des données télémétriques en direct pour piloter la détection d'anomalies, passant d'une prise de décision réactive à proactive en quelques millisecondes.
- Détection de fraude : Une banque mondiale traite les transactions par carte de crédit de Kafka en temps réel et signale les activités suspectes, le tout en moins de 200 millisecondes — réduisant les risques et le temps de réponse sans replatformage.
Qu'est-ce que le mode temps réel (RTM) ?
Le RTM est une évolution du moteur Spark Structured Streaming qui lui permet d'atteindre des performances inférieures à la seconde dans des benchmarks de charges de travail exigeantes de calcul de caractéristiques clients.
Le mode micro-batch (MBM) par défaut de Structured Streaming est comme un bus navette d'aéroport qui attend qu'un certain nombre de passagers montent avant de partir. D'autre part, le RTM fonctionne comme un tapis roulant à grande vitesse, éliminant la limitation d'attendre que la navette soit pleine. Le RTM traite chaque événement à son arrivée, fournissant une latence de bout en bout de l'ordre de la milliseconde sans quitter l'écosystème Spark.
De secondes à millisecondes : Le RTM transforme le moteur Spark en remplaçant le batching périodique par un flux de données continu, éliminant les goulots d'étranglement de latence de l'ETL traditionnel.
Les gains de performance du RTM proviennent de trois innovations architecturales clés :
- Flux de données continu : Les données sont traitées à mesure qu'elles arrivent au lieu d'être discrétisées en morceaux périodiques.
- Planification de pipeline : Les étapes s'exécutent simultanément sans blocage, permettant aux tâches en aval de traiter les données immédiatement sans attendre la fin des étapes en amont.
- Shuffle en streaming : Les données sont transmises entre les tâches immédiatement, contournant les goulots d'étranglement de latence des shuffles traditionnels basés sur disque.
Ensemble, elles transforment Spark en un moteur haute performance et à faible latence capable de gérer les cas d'utilisation opérationnels les plus exigeants.
Spark RTM : jusqu'à 92 % plus rapide que Flink, permettant aux équipes d'exploiter moins d'infrastructure et d'aller plus vite
Afin de valider les performances de Spark RTM, nous avons comparé ses performances à celles d'un moteur spécialisé populaire, Apache Flink, sur la base de charges de travail réelles de calcul de caractéristiques clients. Ces modèles de calcul de caractéristiques sont représentatifs de la plupart des cas d'utilisation ETL à faible latence, tels que la détection de fraude, la personnalisation et l'analyse opérationnelle. En comparant Spark RTM à Flink, les résultats démontrent que l'architecture évoluée de Spark offre un profil de latence comparable aux frameworks de streaming spécialisés. Pour plus d'informations sur les ensembles de données et les requêtes référencés, consultez ce dépôt GitHub.
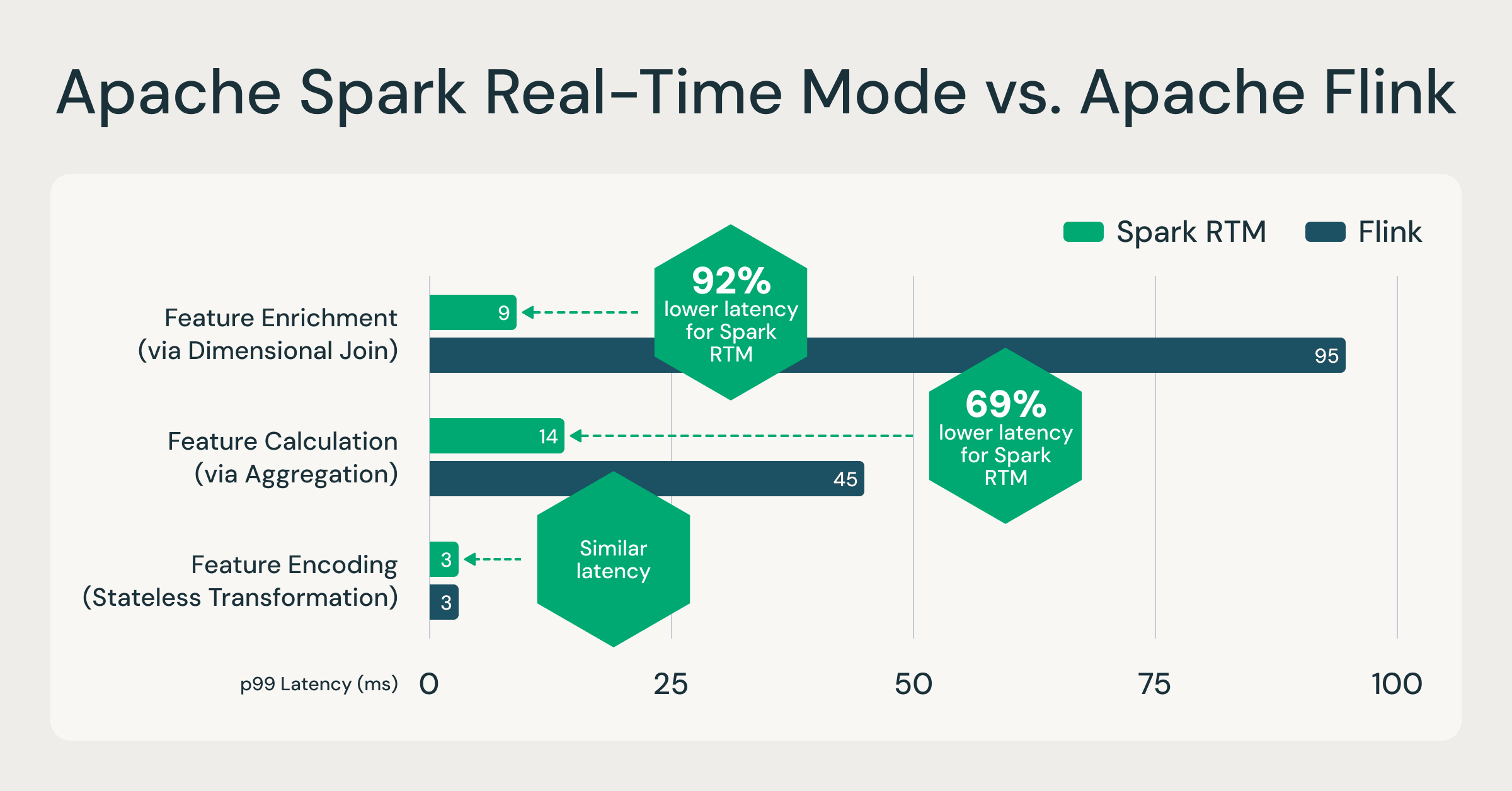
Un moteur, jusqu'à 92 % plus rapide : Le RTM surpasse les moteurs spécialisés comme Flink, prouvant que l'analyse opérationnelle de l'ordre de la milliseconde ne nécessite plus de moteur de streaming distinct. Source : Benchmarks internes basés sur des modèles de calcul de caractéristiques clients. Requêtes complètes disponibles sur GitHub.
Bien que la vitesse brute soit importante, le plus grand avantage de Spark RTM par rapport à des moteurs comme Flink réside dans la simplicité qu'il offre aux développeurs. Il permet aux équipes d'utiliser la même API Spark pour l'entraînement batch et l'inférence en temps réel, éliminant ainsi efficacement la "dérive logique" et la duplication du code. Spark RTM permet une évolutivité transparente, où un changement de code d'une seule ligne peut faire passer un pipeline de batches horaires à du streaming inférieur à la seconde sans réglage manuel de l'infrastructure. En fin de compte, en réduisant la complexité opérationnelle et le besoin de plusieurs systèmes spécialisés, les équipes peuvent développer et déployer des applications en temps réel beaucoup plus rapidement avec Spark RTM.
Démarrer avec Spark RTM
La mise en route avec le RTM est simple. Si vous utilisez déjà Structured Streaming, vous pouvez l'activer avec une seule mise à jour de configuration — aucune réécriture n'est nécessaire.
Étape 1 : Configurer votre cluster
Le RTM est actuellement disponible sur les calculs Classic, dans les modes d'accès Dédicacé et Standard. Le RTM est pris en charge sur Databricks Runtime (DBR) 16.4 et supérieur ; cependant, nous recommandons DBR 18.1 pour les dernières fonctionnalités et optimisations. Lors de la création du cluster, ajoutez la configuration Spark suivante :
Étape 2 : Utiliser le nouveau déclencheur temps réel dans votre requête de streaming
Nouveautés de Spark RTM
Depuis son lancement en aperçu public en août 2025, Databricks a continué d'étendre les capacités du RTM, en se basant sur les commentaires des clients.
Voici les nouveautés de cette version GA :
- Prise en charge de l'OSS dans Apache Spark 4.1 (transformations sans état) : Le mode temps réel (RTM) pour les transformations sans état est maintenant disponible dans Apache Spark 4.1 open-source. Les équipes qui développent sur Spark OSS peuvent profiter du mode temps réel pour les pipelines de projection, de filtrage et basés sur les UDF.
- Prise en charge du mode d'accès standard : Le mode temps réel fonctionne désormais sur les modes d'accès dédié et standard dans le calcul classique en Python, offrant ainsi plus de flexibilité aux équipes dans l'utilisation des ressources de calcul pour les charges de travail de streaming.
- Point de contrôle asynchrone de l'état et suivi de la progression : La sauvegarde de l'état et le suivi de la progression des requêtes sont désormais effectués de manière asynchrone, découplés du chemin critique de traitement des événements. Cela améliore la latence du mode temps réel pour les pipelines sans état et avec état.
- Chargement de l'état initial dans transformWithState : transformWithState est un opérateur puissant de Spark Structured Streaming pour la création de logique personnalisée avec état. Les utilisateurs peuvent désormais charger l'état initial à partir du point de contrôle d'une requête préexistante ou d'une table Delta lors de l'utilisation de transformWithState avec le mode temps réel. Cette fonctionnalité est essentielle pour l'ingénierie des caractéristiques (feature engineering) avec état, vous permettant de pré-remplir les requêtes en ligne avec le contexte historique sans « repartir de zéro ».
- Métriques et observabilité améliorées pour les UDF : Des métriques de latence plus précises pour l'exécution des UDF Python sont désormais disponibles via le listener StreamingQueryProgress.
- Améliorations des performances pour les UDF Python avec état : Des optimisations ont été ajoutées pour améliorer les performances des opérations avec état dans transformWithState en Python, spécifiquement pour les requêtes RTM.
Conclusion
Le mode temps réel (RTM) étend Apache Spark Structured Streaming à une nouvelle catégorie de charges de travail : les applications opérationnelles sensibles à la latence qui exigent une réponse immédiate aux données de streaming. En apportant une latence inférieure à la seconde aux API Spark que votre équipe utilise déjà, il élimine le besoin d'exploiter un moteur spécialisé distinct pour vos pipelines les plus critiques en termes de temps. Que vous construisiez des pipelines de détection de fraude, des moteurs de personnalisation ou des systèmes de calcul de caractéristiques ML, le mode temps réel vous offre la latence dont votre application a besoin, avec la simplicité et l'étendue de l'écosystème Spark.
Ressources techniques
Consultez les ressources suivantes pour commencer dès aujourd'hui avec le mode temps réel (RTM) :
- Documentation : Mode temps réel dans Structured Streaming
- Vidéo à la demande : Démarrage avec le mode temps réel
- Blog : Comment réaliser la détection de fraude en temps réel : Configuration de Spark RTM avec Databricks Lakebase
- Exemples de code : Exemples de mode temps réel
- Webinaire à la demande : Plongée technique dans le mode temps réel
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.