Les agents LLM sont-ils bons pour l'optimisation de l'ordre des jointures ?
par Eric Liang, Ryan Marcus, Sid Taneja et Yuhao Zhang
- Ce que c'est : Nous explorons l'application d'agents LLM (Large Language Model) de pointe au problème classique des bases de données d'optimisation de l'ordre des jointures.
- Le Défi : Les optimiseurs de requêtes traditionnels ont souvent du mal avec l'ordre des jointures, où le nombre de plans possibles croît exponentiellement avec le nombre de tables, entraînant souvent de mauvaises performances en raison d'une cardinalité mal estimée. Les agents LLM abordent cela en agissant comme un DBA axé sur les données, raisonnant à travers les statistiques d'exécution réelles et le contexte sémantique que les heuristiques automatisées manquent souvent.
- Résultats et Objectifs : Dans des benchmarks expérimentaux, l'agent prototype a amélioré l'optimiseur Databricks dans 80 % des cas, améliorant la latence des requêtes d'un facteur de 1,3x globalement.
Introduction
Dans la plateforme d'intelligence Databricks, nous explorons et utilisons régulièrement de nouvelles techniques d'IA pour améliorer les performances du moteur et simplifier l'expérience utilisateur. Nous présentons ici des résultats expérimentaux sur l'application de modèles de pointe à l'un des plus anciens défis des bases de données : l'ordonnancement des jointures.
Ce blog fait partie d'une collaboration de recherche avec l'UPenn.
Le problème : l'ordonnancement des jointures
Depuis leur création, les optimiseurs de requêtes dans les bases de données relationnelles ont eu du mal à trouver de bons ordonnancements de jointures pour les requêtes SQL. Pour illustrer la difficulté de l'ordonnancement des jointures, considérons la requête suivante :
Combien de films ont été produits par Sony et mettaient en vedette Scarlett Johansson ?
Supposons que nous voulions exécuter cette requête sur le schéma suivant :
| Nom de la table | Colonnes de la table |
|---|---|
| Actor | actorID, actorName, actorDOB, … |
| Company | companyID, companyName, … |
| Stars | actorID, movieID |
| Produces | companyID, movieID |
| Movie | movieID, movieName, movieYear , … |
Les tables d'entités Acteur, Société et Film sont connectées via les tables de relations Produces et Stars (par exemple, via des clés étrangères). Une version de cette requête en SQL pourrait être :
Logiquement, nous voulons effectuer une opération de jointure simple : Actor ⋈ Stars ⋈ Movie ⋈ Produces ⋈ Company. Mais physiquement, comme chacune de ces jointures est commutative et associative, nous avons beaucoup d'options. L'optimiseur de requête pourrait choisir de :
- Trouver d'abord tous les films avec Scarlett Johansson, puis filtrer uniquement les films produits par Sony,
- Trouver d'abord tous les films produits par Sony, puis filtrer ces films avec Scarlett Johansson,
- En parallèle, calculer les films de Sony et les films de Scarlett Johansson, puis prendre l'intersection.
Le plan optimal dépend des données : si Scarlett Johansson a joué dans beaucoup moins de films que Sony n'en a produit, le premier plan pourrait être optimal. Malheureusement, estimer cette quantité est aussi difficile que d'exécuter la requête elle-même (en général). Pire encore, il y a normalement beaucoup plus de 3 plans à choisir, car le nombre de plans possibles croît exponentiellement avec le nombre de tables — et les requêtes analytiques joignent régulièrement 20 à 30 tables différentes.
Comment fonctionne l'ordonnancement des jointures aujourd'hui ? Les optimiseurs de requêtes traditionnels résolvent ce problème avec trois composants : un estimateur de cardinalité conçu pour deviner rapidement la taille des sous-requêtes (par exemple, pour deviner combien de films Sony a produits), un modèle de coût pour comparer différents plans potentiels, et une procédure de recherche qui navigue dans l'espace exponentiellement grand. L'estimation de la cardinalité est particulièrement difficile et a conduit à un large éventail de recherches visant à améliorer la précision de l'estimation en utilisant une large gamme d'approches [A].
Toutes ces solutions ajoutent une complexité significative à un optimiseur de requêtes, et nécessitent un effort d'ingénierie considérable pour l'intégration, la maintenance et la mise en production. Mais si les agents pilotés par LLM, avec leurs capacités d'adaptation à de nouveaux domaines par le biais de prompts, détenaient la clé pour résoudre ce problème vieux de plusieurs décennies ?
Ordonnancement de jointures agentique
Lorsque les optimiseurs de requêtes sélectionnent un mauvais ordonnancement de jointures1, les experts humains peuvent le corriger en diagnostiquant le problème (souvent une cardinalité mal estimée) et en instruisant l'optimiseur de requêtes de choisir un ordonnancement différent. Ce processus nécessite souvent plusieurs cycles de test (par exemple, l'exécution de la requête) et l'inspection manuelle des résultats intermédiaires.
Les optimiseurs de requêtes doivent généralement choisir les ordonnancements de jointures en quelques centaines de millisecondes, de sorte que l'intégration d'un LLM dans le chemin critique de l'optimiseur de requêtes, bien que potentiellement prometteuse, n'est pas possible aujourd'hui. Mais le processus itératif et manuel d'optimisation de l'ordonnancement des jointures pour une requête, qui peut prendre plusieurs heures à un expert humain, pourrait potentiellement être automatisé avec un agent LLM ! Cet agent tente d'automatiser ce processus de réglage manuel.
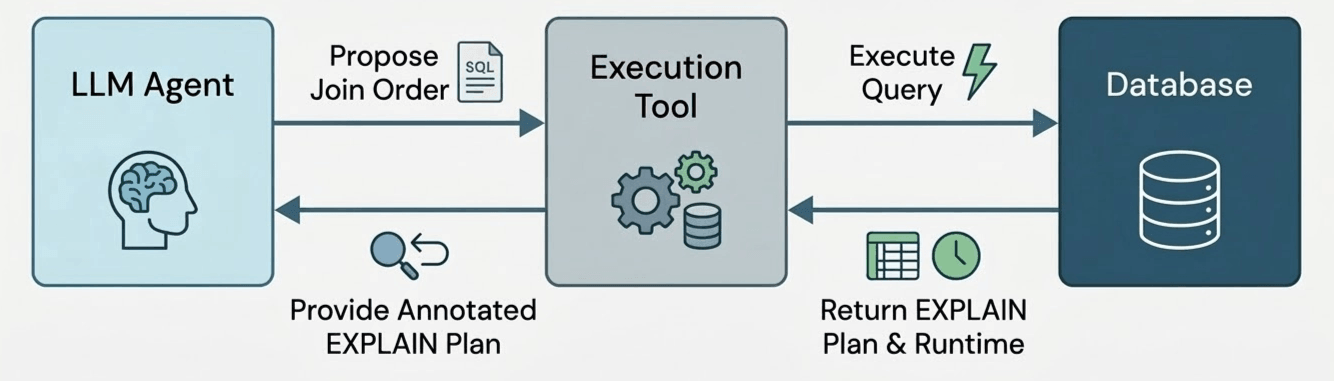
Pour tester cela, nous avons développé un prototype d'agent d'optimisation de requêtes. L'agent a accès à un seul outil, qui exécute un ordonnancement de jointures potentiel pour une requête et renvoie le temps d'exécution de l'ordonnancement de jointures (avec un délai d'attente du temps d'exécution de la requête d'origine) et la taille de chaque sous-plan calculé (par exemple, le plan EXPLAIN EXTENDED plan).
Nous avons laissé l'agent s'exécuter pendant 50 itérations, permettant à l'agent d'essayer librement différents ordonnancements de jointures. L'agent est libre d'utiliser ces 50 itérations pour tester des plans prometteurs (« exploitation ») ou pour explorer des alternatives risquées mais informatives (« exploration »). Ensuite, nous collectons le meilleur ordonnancement de jointures testé par l'agent, qui devient notre résultat final. Mais comment savoir si l'agent a choisi un ordonnancement de jointures valide ? Pour garantir la correction, chaque appel d'outil génère un ordonnancement de jointures à l'aide de sorties de modèle structurées, ce qui oblige la sortie du modèle à correspondre à une grammaire que nous spécifions pour n'admettre que des réordonnancements de jointures valides. Notez que cela diffère des travaux antérieurs [B] qui demandent au LLM de choisir un ordonnancement de jointures instantanément dans le « chemin critique » de l'optimiseur de requêtes ; au lieu de cela, le LLM agit comme un expérimentateur hors ligne qui essaie de nombreux plans candidats et apprend des résultats observés – tout comme un humain qui ajuste manuellement un ordonnancement de jointures !.
Pour évaluer notre agent dans DBR, nous avons utilisé le Join Order Benchmark (JOB), un ensemble de requêtes conçues pour être difficiles à optimiser. Comme le jeu de données utilisé par JOB, le jeu de données IMDb, n'est que d'environ 2 Go (et donc Databricks pouvait traiter même de mauvais ordonnancements de jointures assez rapidement), nous avons augmenté la taille du jeu de données en dupliquant chaque ligne 10 fois [C].
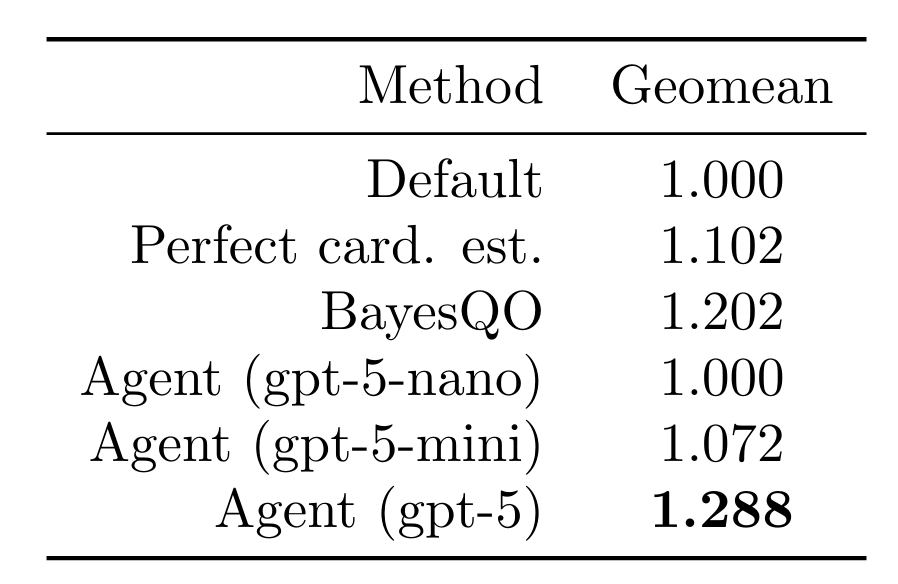
Nous avons laissé notre agent tester 15 ordonnancements de jointures (rollouts) par requête pour les 113 requêtes du benchmark d'ordonnancement de jointures. Nous rapportons les résultats sur le meilleur ordonnancement de jointures trouvé pour chaque requête. En utilisant un modèle de pointe, l'agent a pu améliorer la latence des requêtes d'un facteur de 1,288 (moyenne géométrique). Cela surpasse l'utilisation d'estimations de cardinalité parfaites (intraitable en pratique), de modèles plus petits et de l'optimiseur hors ligne récent BayesQO (bien que BayesQO ait été conçu pour PostgreSQL, pas pour Databricks).
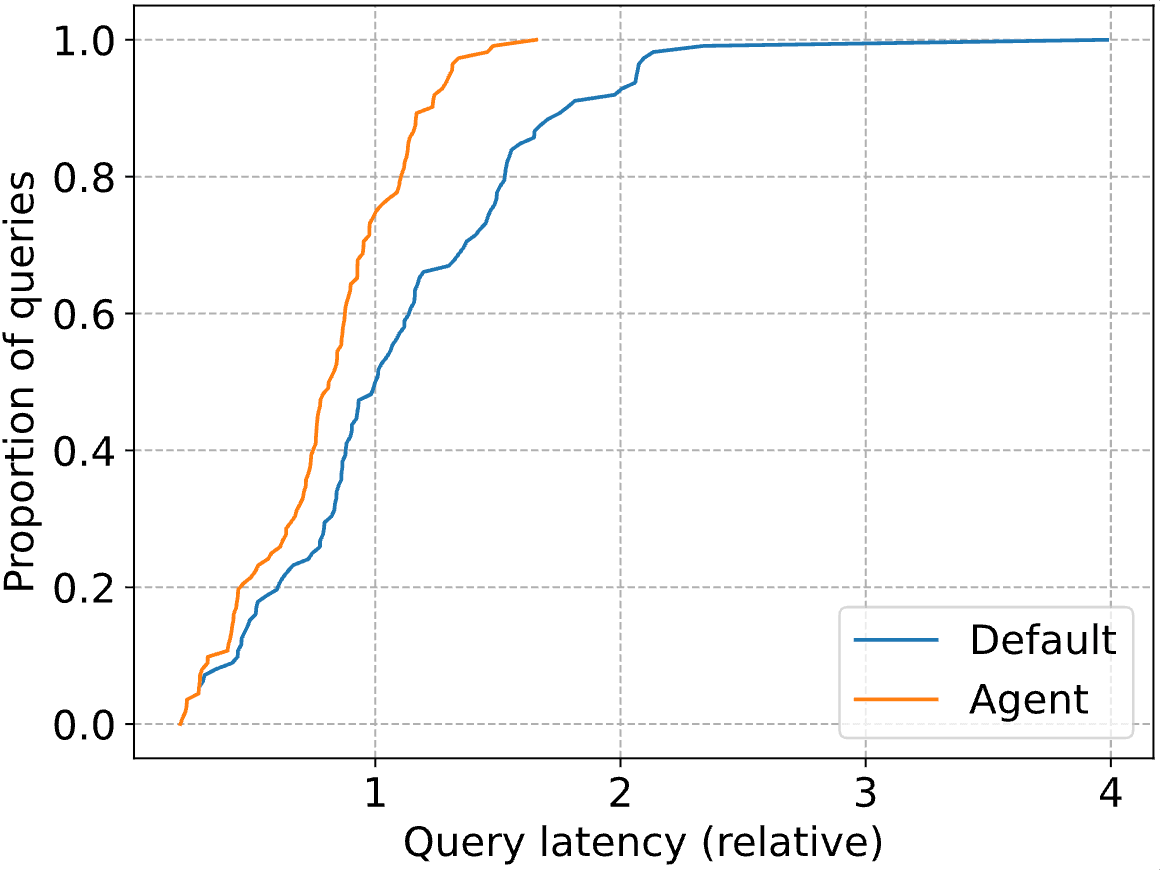
Les gains réellement impressionnants se situent dans la queue de la distribution, avec une baisse de 41 % de la latence des requêtes P90. Ci-dessous, nous traçons la CDF complète pour l'optimiseur Databricks standard (« Default ») et notre agent (« Agent »). Les latences des requêtes sont normalisées à la latence médiane de l'optimiseur Databricks (c'est-à-dire qu'à 1, la ligne bleue atteint une proportion de 0,5).
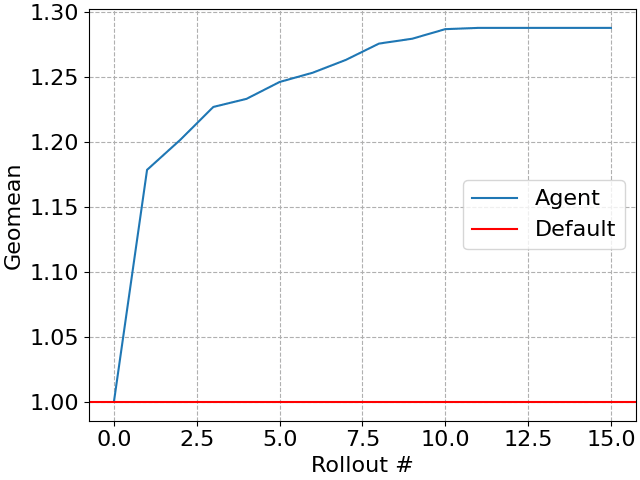
Notre agent améliore progressivement la charge de travail à chaque plan testé (parfois appelé rollout), créant un simple « algorithme à tout moment » où des budgets de temps plus importants peuvent se traduire par de meilleures performances de requête. Bien sûr, à terme, les performances des requêtes cesseront de s'améliorer.
L’une des plus grandes améliorations trouvées par notre agent concerne la requête 5b, une simple jointure à 5 voies qui recherche des sociétés de production américaines ayant publié un film post-2010 sur VHS avec une note faisant référence à 1994. L’optimiseur Databricks s’est d’abord concentré sur la recherche de sociétés de production américaines sur VHS (ce qui est en effet sélectif, ne produisant que 12 lignes). L’agent trouve un plan qui recherche d’abord les sorties VHS faisant référence à 1994, ce qui s’avère être beaucoup plus rapide. En effet, la requête utilise des prédicats LIKE pour identifier les sorties VHS, ce qui est exceptionnellement difficile pour les estimateurs de cardinalité.
Notre prototype démontre le potentiel des systèmes agentiques pour réparer et améliorer de manière autonome les requêtes de base de données. Cet exercice a soulevé plusieurs questions sur la conception des agents dans notre esprit :
- Quels outils devrions-nous donner à l’agent ? Dans notre approche actuelle, l’agent peut exécuter des ordres de jointure candidats. Pourquoi ne pas laisser l’agent émettre des requêtes de cardinalité spécifiques (par exemple, calculer la taille d’un sous-plan particulier), ou des requêtes pour tester certaines hypothèses sur les données (par exemple, pour déterminer qu’il n’y avait pas de sorties DVD avant 1995).
- Quand cette optimisation agentique devrait-elle être déclenchée ? Bien sûr, un utilisateur peut signaler manuellement une requête problématique pour intervention. Mais pourrions-nous également appliquer proactivement cette optimisation aux requêtes qui s’exécutent régulièrement ? Comment déterminer si une requête a un « potentiel » d’optimisation ?
- Pouvons-nous comprendre automatiquement les améliorations ? Lorsque l’agent trouve un meilleur ordre de jointure que celui trouvé par l’optimiseur par défaut, cet ordre de jointure peut être considéré comme une preuve que l’optimiseur par défaut choisit un ordre sous-optimal. Si l�’agent corrige une erreur systématique dans l’optimiseur sous-jacent, pouvons-nous la découvrir et l’utiliser pour améliorer l’optimiseur ?
Bien sûr, nous ne sommes pas les seuls à réfléchir au potentiel des LLM pour l’optimisation des requêtes [D]. Chez Databricks, nous sommes enthousiasmés par la possibilité d’exploiter la généralisabilité des LLM pour améliorer les systèmes de données eux-mêmes.
Si ce sujet vous intéresse, consultez également notre article de suivi sur le blog UCB à propos de "Comment les agents LLM réfléchissent aux ordres de jointure SQL ?".
Rejoignez-nous
Alors que nous regardons vers l’avenir, nous sommes impatients de continuer à repousser les limites de la façon dont l’IA peut façonner les optimisations de base de données. Si vous êtes passionné par la construction de la prochaine génération de moteurs de bases de données, rejoignez-nous !
1 Databricks utilise des techniques telles que les filtres d’exécution pour atténuer l’impact des mauvais ordres de jointure. Les résultats présentés ici incluent ces techniques.
Notes
A. Les techniques d’estimation de la cardinalité ont inclus, par exemple, le feedback adaptatif, l’apprentissage profond, la modélisation de distribution, la théorie des bases de données, la théorie de l’apprentissage, et les factorisations. Les travaux antérieurs ont également tenté de remplacer entièrement l’architecture traditionnelle d’optimisation des requêtes par l’apprentissage profond, l’apprentissage par renforcement, les multi-armed bandits, l’optimisation bayésienne, ou des algorithmes de jointure plus avancés.
B. Les approches basées sur RAG, par exemple, ont été utilisées pour construire des systèmes « LLM dans le chemin critique ».
C. Bien que rudimentaire, cette approche a été utilisée dans des travaux antérieurs.
D. D’autres chercheurs ont proposé des systèmes de réparation de requêtes basés sur RAG, des systèmes de réécriture de requêtes alimentés par LLM, et même des systèmes de base de données entiers synthétisés par des LLM.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.