Meilleures pratiques pour la gestion des coûts sur Databricks
par Tomasz Bacewicz et Greg Wood
Ce blog fait partie de notre série Admin Essentials, où nous nous concentrerons sur les sujets importants pour ceux qui gèrent et maintiennent les environnements Databricks. Gardez un œil sur les blogs supplémentaires sur d'autres sujets, et consultez nos blogs précédents sur les meilleures pratiques d'organisation fonctionnelle de l'espace de travail sur Databricks et d'administration de l'espace de travail !
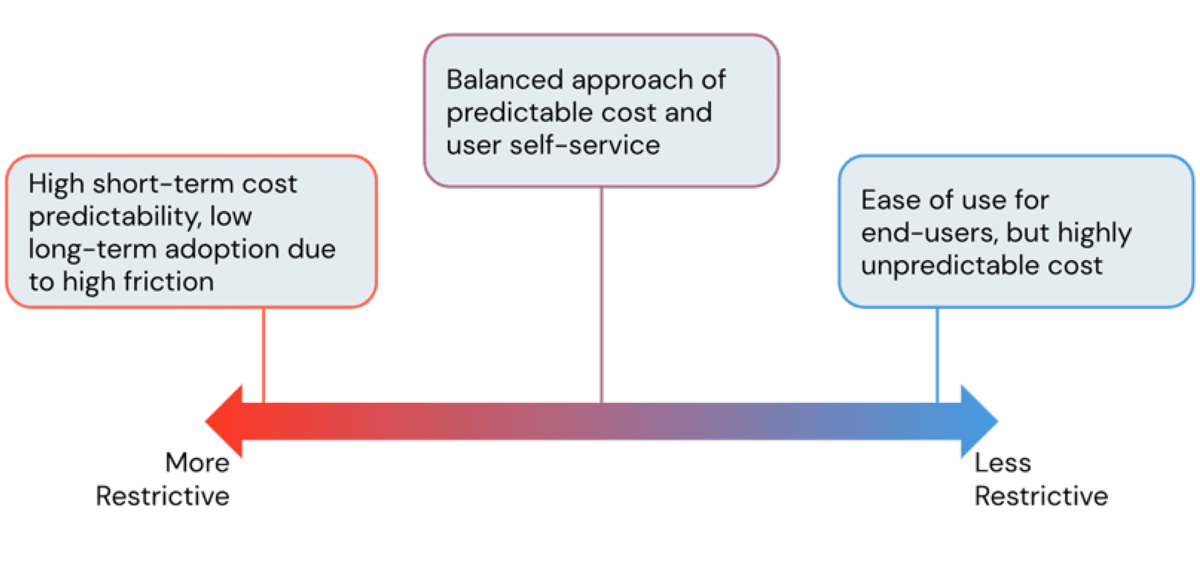
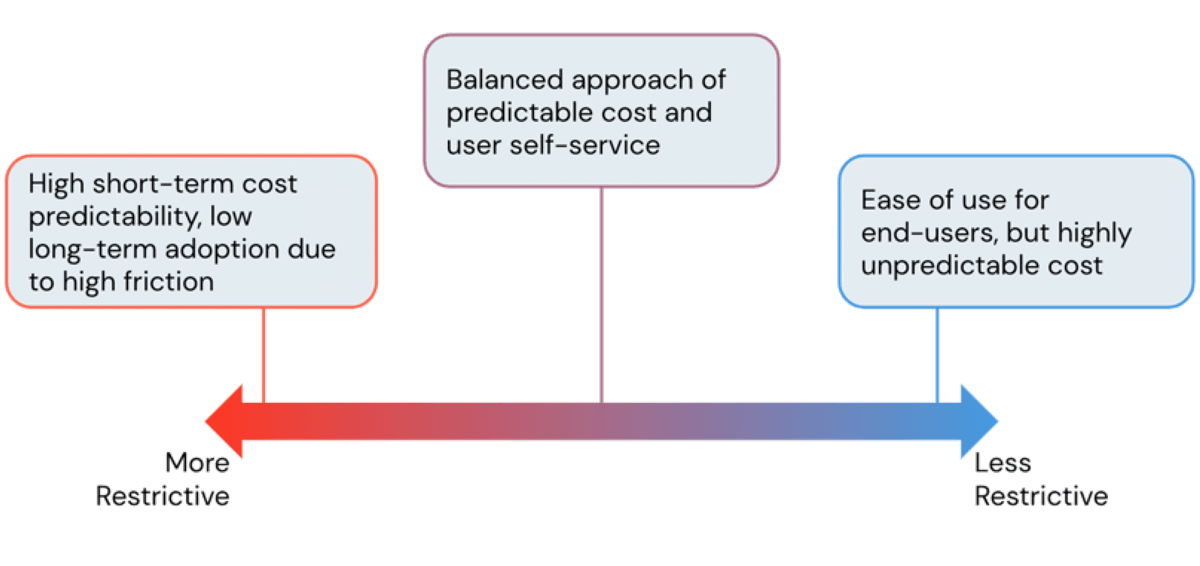
L'un des principaux avantages de l'utilisation d'une plateforme cloud est sa flexibilité. La plateforme Databricks Lakehouse offre aux utilisateurs un accès facile à une puissance de calcul quasi instantanée et évolutive horizontalement. Cependant, cette facilité de création de ressources de calcul comporte un risque de coûts cloud incontrôlables lorsqu'elle n'est pas gérée et sans garde-fous. En tant qu'administrateurs, nous cherchons toujours à trouver le juste équilibre entre éviter des coûts d'infrastructure exorbitants tout en permettant aux utilisateurs de travailler sans friction inutile. Dans ce blog, nous discuterons des outils d'administration Databricks pour trouver cet équilibre et contrôler les coûts sans ralentir la productivité des utilisateurs.
{kind=link}
Qu'est-ce qu'un DBU ?
Avant de plonger dans les contrôles de coûts disponibles sur la plateforme Databricks, il est important de comprendre d'abord la base de coût de l'exécution d'une charge de travail. Une Unité Databricks (DBU) est l'unité de consommation sous-jacente au sein de la plateforme. À l'exception d'un SQL Warehouse, la quantité de DBUs consommée est basée sur le nombre de nœuds et la puissance de calcul des types d'instances de VM sous-jacentes qui font partie du cluster respectif (les entrepôts SQL étant essentiellement un groupe de clusters, le taux de DBU est la somme des taux de DBU des clusters composant le point de terminaison). Au plus haut niveau, chaque cloud aura des taux de DBU légèrement différents pour des clusters similaires (les types de nœuds variant selon les clouds), mais le site Web de Databricks propose des calculateurs de DBU pour chaque fournisseur de cloud pris en charge (AWS | Azure | GCP).
Pour convertir l'utilisation des DBU en montants en dollars, vous aurez besoin du taux de DBU du cluster, ainsi que du type de charge de travail qui a généré le DBU respectif (par exemple, Job Automatisé, Calcul Tout Usage, Delta Live Tables, Calcul SQL, Calcul Serverless) et du niveau du plan d'abonnement (Standard et Premium pour Azure et GCP ; Standard, Premium et Enterprise pour AWS). Par exemple, un espace de travail Databricks Enterprise a un taux DBU de Jobs de 20 cents/DBU sur AWS. Avec un type d'instance fonctionnant à 3 DBU/heure, un cluster de jobs à 4 nœuds serait facturé 2,40 $ (0,2 $ * 3 * 4) pour une heure. Les calculateurs de DBU peuvent être utilisés pour calculer les charges totales et les prix catalogue sont résumés dans une matrice spécifique au cloud incluant le SKU et le niveau (AWS | Azure | GCP).
Étant donné que les coûts sont calculés par l'utilisation des ressources de calcul, et plus spécifiquement des clusters, il est essentiel de gérer les espaces de travail Databricks par le biais de politiques de cluster. La section suivante discutera de la manière dont les différents attributs des politiques de cluster peuvent restreindre la consommation de DBU et gérer efficacement les coûts de la plateforme. Les sections suivantes passeront également en revue certains des coûts cloud sous-jacents à considérer, ainsi que la manière de surveiller l'utilisation et la facturation de Databricks.
Gestion des coûts via les politiques de cluster
Que sont les politiques de cluster ?
Une politique de cluster permet à un administrateur de contrôler l'ensemble des configurations disponibles lors de la création d'un nouveau cluster, et ces politiques peuvent être attribuées à des utilisateurs individuels ou à des groupes d'utilisateurs. Par défaut, tous les utilisateurs disposent du droit "autoriser la création de cluster sans restriction" dans un espace de travail. Cette permission doit rarement être utilisée car elle permet à l'utilisateur de créer des clusters sans aucune restriction en dehors des politiques attribuées, ce qui peut entraîner des coûts incontrôlés et débridés.
Dans une politique, un administrateur peut restreindre chaque paramètre de configuration par une valeur fixe immuable, une plage de valeurs plus permissive et un regex, ou une valeur par défaut complètement ouverte. Les politiques limitent efficacement la quantité de DBUs qui peuvent être consommés par un seul cluster grâce à des restrictions allant de paramètres plus granulaires tels que les types d'instances de VM à des attributs "synthétiques" plus généraux tels que le nombre maximum de DBUs autorisés par heure ou les types de charges de travail du cluster.
Bien qu'à première vue, il puisse sembler que des clusters plus restrictifs entraînent des coûts inférieurs, ce n'est pas toujours le cas. Des politiques très restrictives conduisent à des clusters qui ne peuvent pas terminer les tâches en temps voulu, entraînant des coûts plus élevés dus à des jobs de longue durée. Il est donc impératif d'adopter une approche axée sur les cas d'utilisation lors de la formulation des politiques de cluster, en donnant aux équipes la bonne quantité de puissance de calcul pour leurs charges de travail. Pour ce faire, Databricks fournit des fonctionnalités de performance telles que des runtimes Apache Spark optimisés et, plus particulièrement, le moteur Photon, entraînant des économies de coûts grâce à un temps de traitement plus rapide. Nous discuterons des politiques pour les runtimes dans une section ultérieure, mais commençons d'abord par les politiques qui gèrent la mise à l'échelle horizontale.
Limites du nombre de nœuds, mise à l'échelle automatique et arrêt automatique
Une préoccupation courante concernant les coûts de calcul concerne les clusters sous-utilisés ou inactifs. Databricks fournit des fonctionnalités de mise à l'échelle automatique et d'arrêt automatique pour atténuer ces préoccupations de manière dynamique et sans intervention directe de l'utilisateur. Ces fonctionnalités peuvent être appliquées via des politiques sans entraver les ressources de calcul disponibles pour l'utilisateur.
Limites du nombre de nœuds et mise à l'échelle automatique
Les politiques peuvent imposer que la fonctionnalité de mise à l'échelle automatique du cluster soit activée avec un nombre minimum de nœuds de travail. Par exemple, une politique telle que celle ci-dessous garantira l'utilisation de la mise à l'échelle automatique et permettra à un utilisateur d'avoir un cluster avec jusqu'à 10 nœuds de travail, mais uniquement lorsqu'ils sont nécessaires :
Comme le type de contrainte est "range" sur le nombre maximum de travailleurs, il peut être modifié à une valeur inférieure à 10 lors de la création. Le nombre minimum de travailleurs, cependant, est défini par "fixed" à une valeur de un, de sorte que le cluster se réduira toujours à un seul travailleur lorsqu'il est sous-utilisé, garantissant ainsi des économies de coûts sur le calcul. Un champ supplémentaire montré ici est "defaultValue" qui, comme son nom l'indique, définit une valeur par défaut du nombre maximum de travailleurs dans la page de configuration du cluster. Ceci est utile pour réduire le nombre maximum de travailleurs dans un cluster par défaut, de sorte que le créateur doit être délibéré en autorisant un cluster à monter jusqu'à 10 nœuds.
Comprendre les cas d'utilisation lors de la création et de l'attribution de politiques est essentiel en ce qui concerne les limites du nombre de nœuds et la nécessité d'appliquer la mise à l'échelle automatique. Par exemple, l'application de la mise à l'échelle automatique fonctionne bien pour :
- Clusters de calcul partagés tout usage : une équipe peut partager un cluster pour l'analyse ad hoc et les jobs expérimentaux ou les charges de travail d'apprentissage automatique.
- Jobs batch de longue durée avec une complexité variable : les jobs peuvent tirer parti de la mise à l'échelle automatique afin que le cluster s'adapte au degré de ressources nécessaires.
Notez que les jobs utilisant la mise à l'échelle automatique ne doivent pas être sensibles au temps, car la mise à l'échelle du cluster peut retarder l'achèvement en raison du temps de démarrage des nœuds. Pour aider à atténuer cela, utilisez un pool d'instances chaque fois que possible.
Les charges de travail de streaming standard n'ont pas pu bénéficier historiquement de la mise à l'échelle automatique ; elles se mettaient simplement à l'échelle jusqu'au nombre maximal de nœuds et y restaient pendant la durée du travail. Une option plus prête pour la production pour les équipes travaillant sur ces types de charges de travail consiste à exploiter Delta Live Tables et l'mise à l'échelle automatique améliorée (les charges de travail DLT peuvent être appliquées avec la politique "cluster_type" discutée plus loin dans ce blog). Bien que DLT ait été développé en pensant aux charges de travail de streaming, il est tout aussi applicable aux pipelines par lots en exploitant l'option Trigger.AvailableNow permettant des mises à jour incrémentielles des tables cibles.
Une autre configuration courante des politiques de dimensionnement de cluster est la politique de nœud unique. Les clusters à nœud unique peuvent être utiles pour les nouveaux utilisateurs explorant la plateforme, les équipes de science des données qui utilisent des bibliothèques ML non distribuées, ainsi que pour tout utilisateur ayant besoin d'effectuer une analyse exploratoire légère des données. Comme indiqué dans l'exemple de politique de cluster à nœud unique, les politiques peuvent être restreintes pour exploiter un pool d'instances spécifique. Par conséquent, l'équipe assignée à cette politique aura une limite sur le nombre de clusters à nœud unique qu'elle peut créer en fonction du réglage de capacité maximale du pool.
Auto-termination
Un autre attribut qui peut être défini lors de la création d'un cluster au sein de la plateforme Databricks est le temps d'auto-termination, qui arrête un cluster après une période d'inactivité définie. Les périodes d'inactivité sont définies par l'absence de toute activité sur le cluster, telle que les travaux Spark, le streaming structuré ou les appels JDBC. Les activités qui ne sont pas considérées comme des activités sur le cluster sont la création d'une connexion SSH dans le cluster et l'exécution de commandes bash.
La fenêtre d'auto-termination la plus courante est d'une heure. À titre d'exemple, voici la politique définie sur une fenêtre fixe d'une heure :
Dans cet exemple, l'attribut "hidden" est également ajouté à ce contrôle, ce qui masque le widget de la page de configuration du cluster de l'utilisateur. Cet attribut n'est applicable qu'aux clusters tout usage, car les clusters de travaux et DLT s'arrêteront automatiquement une fois toutes les tâches qui leur sont assignées terminées.
Runtimes de cluster et Photon
Les Runtimes Databricks sont une partie importante de l'optimisation des performances sur Databricks ; les clients constatent souvent un avantage automatique en passant à un cluster exécutant un runtime plus récent sans beaucoup d'autres changements dans leur configuration. Pour un administrateur qui crée des politiques de cluster, éduquer les créateurs de cluster sur les effets de l'exécution d'un runtime plus récent est précieux pour les économies de coûts. À mesure que les utilisateurs passent à des runtimes plus récents, les runtimes plus anciens peuvent être supprimés et restreints par le biais de politiques. Pour un exemple rapide, voici l'attribut "spark_version" qui restreint les utilisateurs aux seuls runtimes DB des versions 11.0 ou 11.1.
Cependant, cette politique pourrait être rendue plus flexible en autorisant d'autres versions, des runtimes ML, des runtimes Photon ou des runtimes GPU en élargissant la liste d'autorisation ou en utilisant des expressions régulières.
L'autre fonctionnalité de runtime à considérer lors de l'optimisation des performances pour réduire les coûts est l'utilisation de notre moteur Photon vectorisé. Photon accélérera intelligemment des parties d'une charge de travail grâce à un moteur Spark vectorisé avec lequel les clients constatent une augmentation de performance de 3x à 8x. L'augmentation massive des performances entraîne des travaux plus rapides et, par conséquent, des coûts totaux plus faibles.
Types d'instances cloud et instances Spot
Lors de la création d'un cluster, les types d'instances de VM peuvent être sélectionnés séparément pour le nœud pilote et les nœuds de travail. Les types d'instances disponibles ont chacun un taux DBU calculé différent et peuvent être trouvés sur les pages d'estimation des prix Databricks pour chaque cloud respectif (AWS, Azure, GCP). Par exemple, sur AWS, le type d'instance m4.large avec deux cœurs et 8 Go de mémoire consomme 0,4 DBU par heure, tandis qu'un type d'instance m4.16xlarge avec 64 cœurs et 256 Go de mémoire consomme 12 DBU par heure en mode de calcul tout usage. Avec une si large gamme d'utilisation de DBU entre les ressources de calcul, il est crucial de restreindre cet attribut par le biais d'une politique.
Les types d'instances cloud peuvent être contrôlés plus commodément par le type "allowlist" ou autrement par le type "fixed" pour n'autoriser qu'un seul type d'instance à être utilisé. L'exemple ci-dessous montre l'attribut "node_type_id" qui définit une politique sur les types de nœuds de travail disponibles pour l'utilisateur, tandis que "driver_node_type_id" définit une politique sur le type de nœud pilote.
En tant qu'administrateur créant ces politiques, il est important d'avoir une idée du type de charges de travail que chaque équipe exécute et d'assigner les bonnes politiques de manière appropriée. Les charges de travail avec de petites quantités de données ne devraient nécessiter que des types d'instances à faible mémoire, tandis que l'entraînement de modèles d'apprentissage profond bénéficierait le plus des clusters GPU, qui consomment généralement plus de DBU. En fin de compte, restreindre les types d'instances peut être un exercice d'équilibre. Lorsqu'une équipe doit exécuter des charges de travail qui nécessitent plus de ressources que ce qui est disponible en raison de restrictions de politique, le travail peut prendre plus de temps à se terminer et, par conséquent, augmenter les coûts. Il existe quelques bonnes pratiques à suivre lors de la configuration d'un cluster pour une charge de travail définie. Par exemple, la mise à l'échelle verticale (utilisation de types d'instances plus puissants) plutôt que la mise à l'échelle horizontale (ajout de nœuds) est recommandée pour les charges de travail complexes composées de nombreuses transformations larges nécessitant un brassage de données. Cela dit, les équipes moins expérimentées devraient se voir attribuer des politiques restreintes à des types d'instances plus petits, car des VM inutilement puissantes n'apporteront pas beaucoup d'avantages pour les charges de travail plus courantes et moins complexes.
Une capacité d'économie de coûts relativement nouvelle de la plateforme Databricks est la possibilité d'utiliser des VM compatibles AWS Graviton, qui sont construites sur l'architecture de jeu d'instructions Arm64. Sur la base d'études fournies par AWS, en plus des benchmarks réalisés avec Databricks utilisant Photon, ces instances compatibles Graviton offrent certains des meilleurs rapports prix/performance disponibles dans l'ensemble des types d'instances EC2 d'AWS.
Instances Spot
Databricks propose une autre configuration qui peut permettre de réduire les coûts, en particulier sur les coûts de calcul des VM sous-jacentes, avec les instances Spot (l'option disponible via Databricks sur GCP utilise des instances préemptibles qui sont similaires aux instances Spot). Les instances Spot sont des VM de rechange proposées par le fournisseur de cloud sous-jacent, mises aux enchères sur un marché en direct. Ces instances peuvent permettre des réductions importantes, offrant parfois jusqu'à 90 % de réduction sur les coûts de calcul des instances. Le compromis avec les instances Spot est qu'elles peuvent être reprises par le fournisseur de cloud sous-jacent à tout moment avec un court préavis (2 minutes pour AWS, 30 secondes pour Azure et GCP).
Si vous utilisez AWS, une politique de cluster peut être définie qui inclut l'utilisation d'instances Spot comme suit :
Sur Azure :
Dans ces exemples, un seul nœud (spécifiquement le nœud pilote) peut être une instance à la demande, tandis que tous les autres nœuds du cluster seront des instances Spot lors de la création initiale du cluster. Comme l'option de repli est activée ici, une instance à la demande sera demandée pour remplacer une instance Spot qui a été demandée par le fournisseur de cloud. Bien que les politiques sur GCP ne puissent pas actuellement appliquer l'attribut "first_on_demand", les nœuds préemptibles peuvent toujours être appliqués comme suit :
Par défaut, seul le nœud pilote utilisera une instance à la demande au démarrage du cluster lorsque des instances préemptibles sont activées.
Lorsque vous exécutez des processus tolérants aux pannes tels que des expérimentations ou des requêtes ad hoc pour lesquels la fiabilité et la durée de l'exécution ne sont pas prioritaires, les instances Spot peuvent être un moyen simple de réduire les coûts d'instance. Par conséquent, les instances Spot conviennent mieux aux environnements de développement et de staging.
Les taux d'éviction et les prix des instances Spot peuvent varier entre les tailles et les régions cloud. Par conséquent, la planification de configurations de cluster optimales peut être facilitée par des outils des fournisseurs cloud respectifs tels que l'AWS Spot Instance Advisor, l'Azure Spot Pricing and History dans le portail du compte Azure, ou le Google Cloud Pricing Calculator.
Notez qu'Azure dispose d'un levier supplémentaire pour le contrôle des coûts : les instances réservées peuvent être utilisées par Databricks, offrant une autre remise (potentiellement importante) sans ajouter d'instabilité.
Tagging de cluster
La capacité d'observer les ressources utilisées par une équipe est permise par le tagging de cluster. Ces tags se propagent au niveau du fournisseur cloud afin que l'utilisation et les coûts puissent être attribués à la fois depuis la plateforme Databricks et les coûts cloud sous-jacents. Cependant, sans politique de cluster, un utilisateur créant un cluster n'est pas obligé d'attribuer de tags. Par conséquent, lorsqu'un administrateur crée une politique pour une équipe qui demande l'accès à la plateforme Databricks, il est essentiel que la politique inclue une application de tag de cluster spécifique à l'équipe à laquelle la politique sera attribuée.
Voici un exemple de création d'une politique avec un tag de centre de coûts personnalisé appliqué :
Une fois qu'un tag pour identifier l'équipe utilisant le cluster est attribué, les administrateurs peuvent analyser les journaux d'utilisation pour lier les DBU et les coûts générés à l'équipe qui utilise le cluster. Ces tags se propageront également au niveau de l'utilisation des VM afin que les coûts des instances du fournisseur cloud puissent également être attribués à l'équipe ou au centre de coûts. Les options de surveillance des journaux d'utilisation en général sont discutées dans une section ci-dessous.
Une distinction importante concernant les tags de cluster lors de l'utilisation d'un pool de clusters est que seuls les tags du pool de clusters (et non les tags du cluster) se propagent aux instances VM sous-jacentes. La création de pools de clusters n'est pas restreinte par les politiques de clusters et par conséquent, un administrateur doit créer des pools de clusters avec les tags appropriés avant d'attribuer des autorisations d'utilisation à une équipe. L'équipe peut alors avoir accès via des politiques pour se connecter au pool respectif lors de la création de ses clusters. Cela garantit que les tags associés à l'équipe utilisant le pool sont propagés au niveau de l'instance VM pour la facturation.
Attributs virtuels de politique
En dehors des paramètres visibles sur la page de configuration du cluster, il existe également des attributs "virtuels" qui peuvent être restreints par des politiques. Spécifiquement, les deux attributs disponibles dans cette catégorie sont "dbus_per_hour" et "cluster_type".
Avec l'attribut "dbus_per_hour", les créateurs de clusters peuvent avoir une certaine flexibilité de configuration tant que l'utilisation des DBU reste inférieure à la restriction définie dans la politique. Cet attribut en lui-même ne restreint pas directement les coûts attribués aux instances VM sous-jacentes comme les attributs précédents (bien que les taux de DBU soient souvent corrélés aux taux des instances VM). Voici un exemple de définition de politique restreignant l'utilisateur à la création de clusters utilisant moins de 10 DBU par heure :
L'autre attribut virtuel disponible est "cluster_type", qui peut être utilisé pour restreindre les utilisateurs des différents types de clusters. Les types autorisés par cet attribut sont "all-purpose", "job" et "dlt", ce dernier faisant référence à Delta Live Tables. Voici un exemple d'utilisation de cette politique :
Les restrictions de type de cluster sont particulièrement précieuses lorsque l'on travaille avec des équipes distinctes engagées dans le cycle de vie du développement et du déploiement. Une équipe travaillant sur le développement d'un nouveau pipeline ETL ou de machine learning nécessiterait généralement un accès à un cluster tout usage uniquement, tandis que les équipes d'ingénierie de déploiement utiliseraient des clusters job ou Delta Live Tables (DLT). Ces politiques peuvent appliquer les meilleures pratiques en garantissant que le bon type de cluster est utilisé pour chaque étape spécifique du cycle de vie du développement et du déploiement.
Une mauvaise pratique courante est le déploiement de charges de travail automatisées partageant un cluster tout usage. À première vue, cela peut sembler l'option la moins chère car la consommation peut être attribuée à un seul cluster. Cependant, ce type de configuration entraîne une contention de ressources qui prolonge la durée de fonctionnement du cluster, augmentant les coûts de calcul. Au lieu de cela, l'utilisation de clusters job, qui sont isolés pour exécuter un seul job à la fois, réduit la durée de calcul nécessaire pour terminer un ensemble de jobs. Cela entraîne une utilisation réduite des DBU Databricks ainsi que des coûts d'instance cloud sous-jacents inférieurs. De meilleures performances, associées aux tarifs de coûts inférieurs par DBU qu'offrent les clusters job, entraînent des économies considérables. Nous avons vu des clients économiser des dizaines de milliers de dollars en déplaçant simplement dix pour cent de leurs charges de travail des clusters tout usage vers des clusters job. La réutilisation des clusters job peut être utilisée pour garantir l'achèvement en temps voulu d'un ensemble de jobs en supprimant le temps de démarrage du cluster entre chaque tâche.
Pour formuler des politiques permettant aux équipes de créer des clusters pour la bonne charge de travail, il existe quelques meilleures pratiques à suivre. Certains modèles de politique restrictive typiques sont les clusters à nœud unique, les clusters job uniquement, ou les clusters tout usage à mise à l'échelle automatique pour le partage par les équipes. Des exemples de politiques complètes peuvent être trouvés ici.
Coûts du fournisseur cloud
Du point de vue de la consommation Databricks (DBU), tous les coûts peuvent être attribués aux ressources de calcul utilisées. Cependant, les coûts attribués au réseau et au stockage du cloud sous-jacent doivent également être pris en compte.
Stockage
L'avantage d'utiliser une plateforme comme Databricks est qu'elle fonctionne de manière transparente avec un stockage cloud relativement peu coûteux comme ADLS Gen2 sur Azure, S3 sur AWS ou GCS sur GCP. Ceci est particulièrement avantageux lors de l'utilisation du format Delta Lake car il fournit une gouvernance des données pour une couche de stockage autrement difficile à gérer, ainsi que des optimisations de performance lorsqu'il est utilisé conjointement avec Databricks.
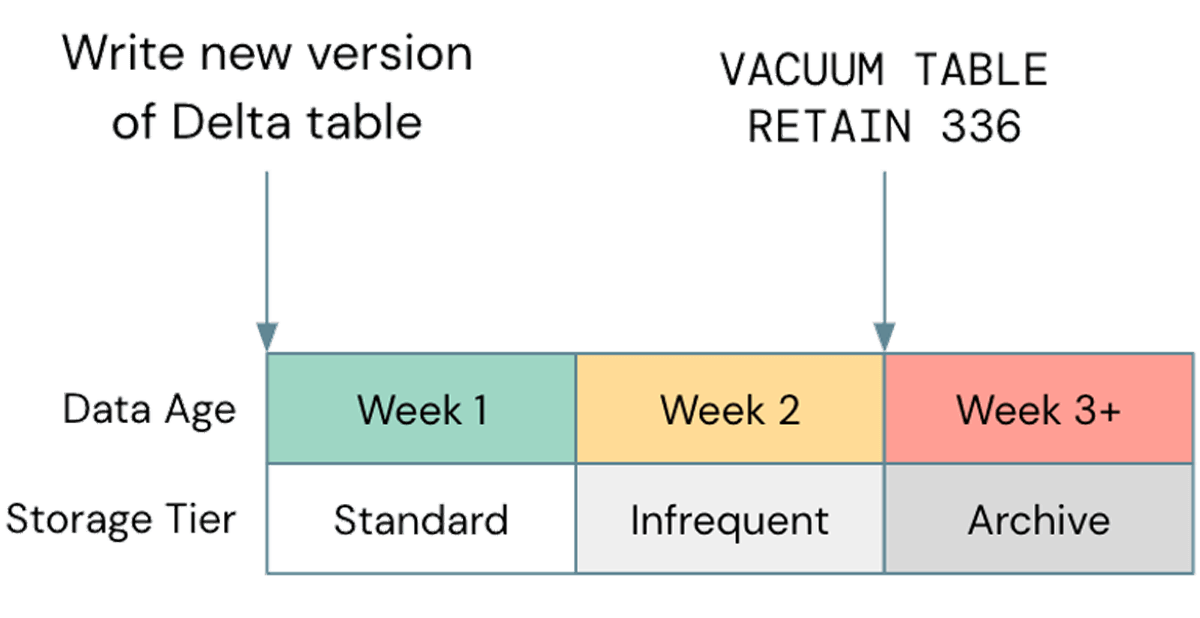
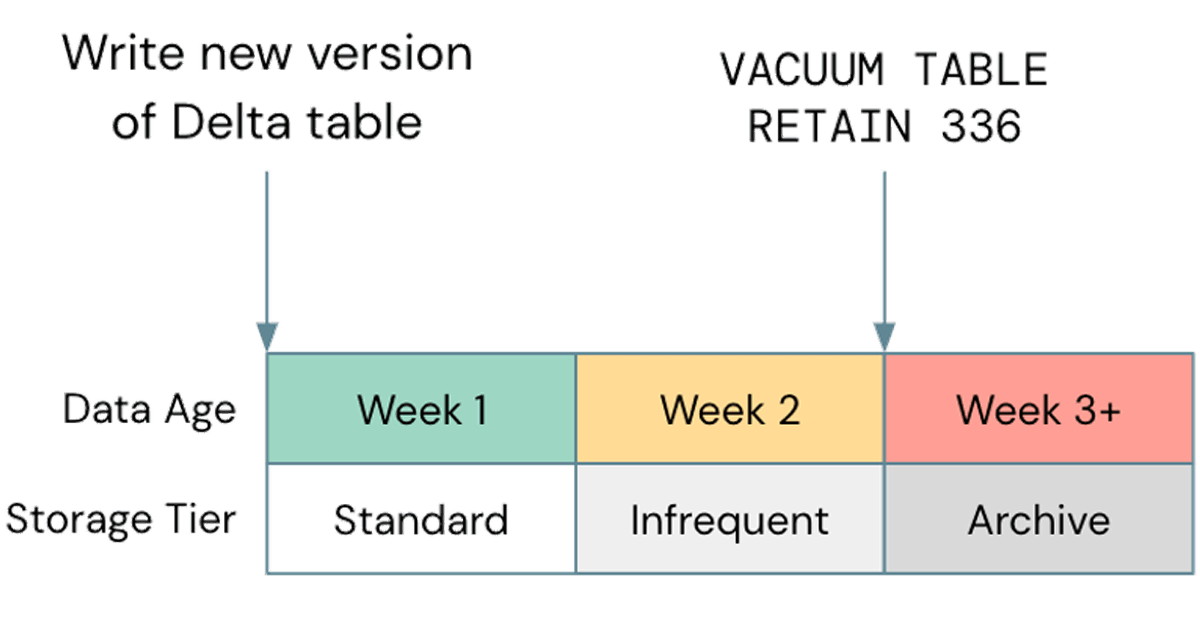
Une mauvaise optimisation courante, en ce qui concerne le stockage, est de négliger l'utilisation de la gestion du cycle de vie lorsque cela est possible ; dans un cas récent, nous avons observé un bucket S3 client d'environ 2,5 Po, dont seulement environ 800 To étaient des données réelles. Les 1,7 Po restants étaient des données versionnées qui n'apportaient aucune valeur. Bien que l'élimination des anciens objets de votre stockage cloud soit une meilleure pratique générale, il est important de l'aligner avec votre cycle Delta Vacuum. Si le cycle de vie de votre stockage élimine les objets avant qu'ils ne puissent être aspirés par Delta, vos tables peuvent se casser ; assurez-vous de tester toute politique de cycle de vie sur des données non productives avant de les implémenter plus largement. Une politique exemple pourrait ressembler à ceci :
{kind=link}
Notez que les niveaux de stockage non standard, tels que Glacier sur S3 ou Archive sur ADLS, ne sont pas pris en charge par Databricks, alors assurez-vous d'utiliser Vacuum avant que ces niveaux ne soient utilisés.
Réseau
Les données utilisées au sein de la plateforme Databricks peuvent provenir de diverses sources, des entrepôts de données aux systèmes de streaming comme Kafka. Cependant, l'utilisateur de bande passante le plus courant est l'écriture dans des couches de stockage telles que S3 ou ADLS. Pour réduire les coûts réseau, les espaces de travail Databricks doivent être déployés dans le but de minimiser la quantité de données transférées entre les régions et les zones de disponibilité. Cela inclut le déploiement dans la même région que la majorité de vos données lorsque cela est possible, et peut inclure le lancement d'espaces de travail régionaux si nécessaire.
Lorsque vous utilisez un VPC géré par le client pour un espace de travail Databricks sur AWS, les coûts de mise en réseau peuvent être réduits en tirant parti des points de terminaison VPC qui permettent la connectivité entre le VPC et les services AWS sans passerelle Internet ni périphérique NAT. L'utilisation de points de terminaison réduit les coûts engendrés par le trafic réseau et rend également la connexion plus sécurisée. Les points de terminaison de passerelle peuvent spécifiquement être utilisés pour se connecter à S3 et DynamoDB, tandis que les points de terminaison d'interface peuvent être utilisés de manière similaire pour réduire le coût des instances de calcul se connectant au plan de contrôle Databricks. Ces points de terminaison sont disponibles tant que l'espace de travail utilise la connectivité sécurisée des clusters.
De même sur Azure, Private Link ou les points de terminaison de service peuvent être configurés pour que Databricks communique avec des services tels qu'ADLS afin de réduire les coûts NAT. Sur GCP, Private Google Access (PGA) peut être utilisé afin que le trafic entre Google Cloud Storage (GCS) et Google Container Registry (GCR) utilise le réseau interne de Google plutôt que l'Internet public, contournant ainsi également l'utilisation d'un périphérique NAT.
Calcul sans serveur
Pour les charges de travail analytiques, une option à considérer est d'utiliser un entrepôt SQL avec l'option Sans serveur activée. Avec SQL sans serveur, la plateforme Databricks gère un pool d'instances de calcul prêtes à être attribuées à un utilisateur dès qu'une charge de travail est initiée. Par conséquent, les coûts des instances sous-jacentes sont entièrement gérés par Databricks plutôt que d'avoir deux frais distincts (c'est-à-dire le coût de calcul DBU et le coût de calcul cloud sous-jacent).
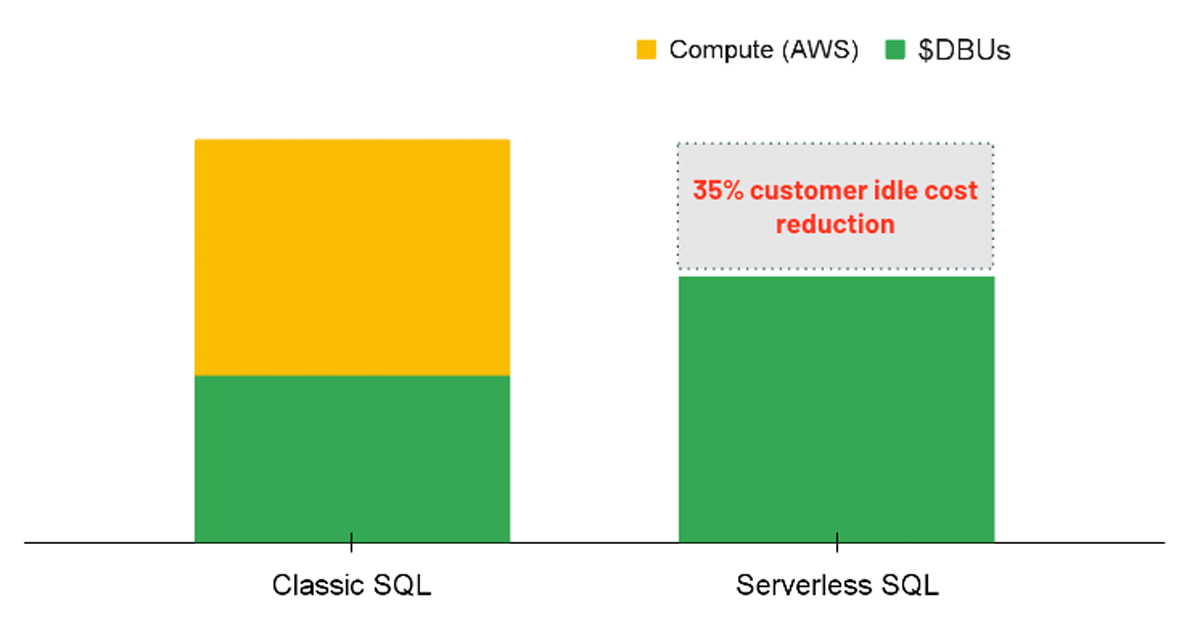
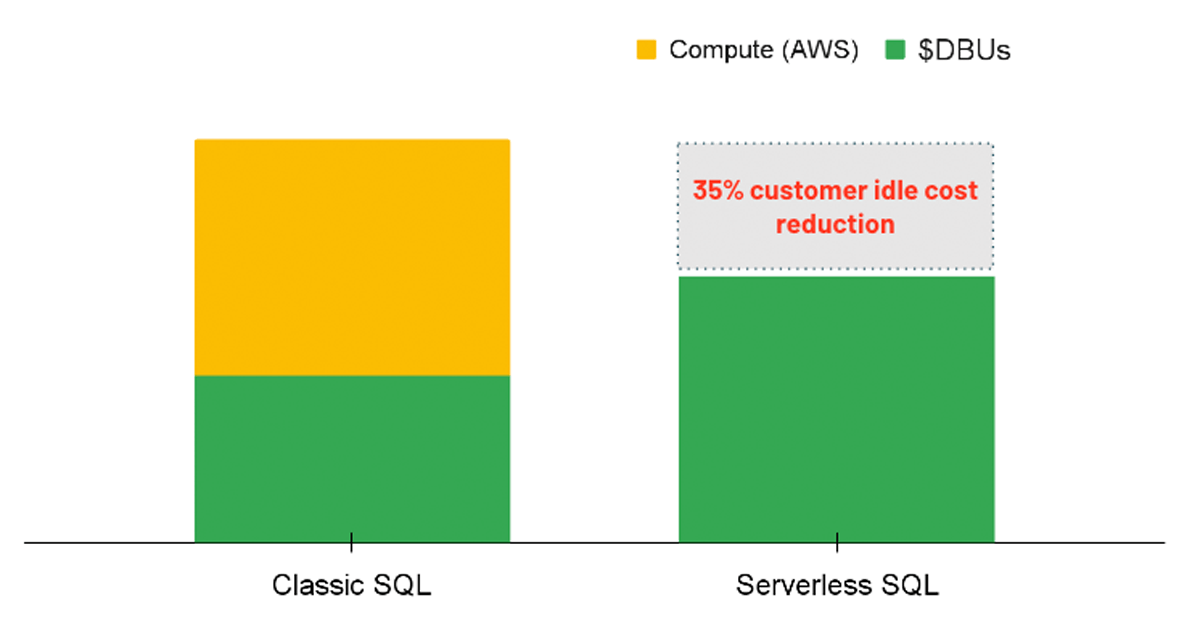{kind=link}
Le sans serveur entraîne un avantage en termes de coûts en fournissant des ressources de calcul instantanées lorsqu'une requête est exécutée, réduisant ainsi les coûts d'inactivité des clusters sous-utilisés. Dans le même ordre d'idées, le sans serveur permet une mise à l'échelle automatique plus précise afin que les charges de travail puissent être effectuées efficacement, économisant ainsi des coûts en améliorant les performances. Bien que l'option sans serveur ne soit pas encore directement applicable via une politique, les administrateurs peuvent activer l'option pour tous les utilisateurs disposant des autorisations de création d'entrepôts SQL.
Surveillance de l'utilisation
En plus de contrôler les coûts grâce aux politiques de cluster et aux configurations de déploiement d'espaces de travail, il est également important pour les administrateurs de pouvoir surveiller les coûts. Databricks offre plusieurs options pour ce faire, avec des fonctionnalités permettant d'automatiser les notifications et les alertes basées sur l'analyse de l'utilisation. Plus précisément, les administrateurs peuvent utiliser la console de compte Databricks pour un aperçu rapide de l'utilisation, analyser les journaux d'utilisation pour une vue plus granulaire et utiliser notre nouvelle API Budgets pour recevoir des notifications actives lorsque les budgets sont dépassés.
Utilisation de la console de compte
Avec l'architecture Databricks Enterprise 2.0, la console de compte comprend une page d'utilisation offrant aux administrateurs la possibilité de visualiser l'utilisation par DBU ou par montant en dollars. Le graphique peut afficher la consommation avec une vue agrégée, regroupée par espace de travail ou par SKU. Lors du regroupement par SKU, l'utilisation est affichée par clusters de tâches, clusters tout usage ou calcul SQL, par exemple. Si le graphique est segmenté par espace de travail, un groupe sera affiché pour les neuf principaux espaces de travail par consommation de DBU, le dernier regroupement étant une somme combinée de tous les autres espaces de travail. Pour comprendre les détails plus granulaires de chaque espace de travail individuellement, un tableau se trouve en bas de la page qui répertorie chaque espace de travail séparément avec les montants DBU/$USD par SKU. Cette page convient parfaitement aux administrateurs pour obtenir une vue complète de l'utilisation et des coûts de tous les espaces de travail d'un compte.
Databricks étant un service de première partie sur la plateforme Azure, l'outil Azure Cost Management peut être utilisé pour surveiller l'utilisation de Databricks (ainsi que tous les autres services sur Azure). Contrairement à la console de compte pour les déploiements Databricks sur AWS et GCP, les capacités de surveillance Azure fournissent des données jusqu'au niveau de granularité des balises. Des balises personnalisées sur Azure peuvent être créées non seulement au niveau du cluster, mais aussi au niveau de l'espace de travail. Ces balises seront affichées comme des groupes et des filtres lors de l'analyse des données d'utilisation. Dans ces rapports, l'utilisation générée par le calcul Databricks sera affichée avec l'utilisation des instances sous-jacentes de manière pratique dans la même vue. Les journaux peuvent également être livrés dans un conteneur de stockage selon un calendrier et utilisés pour une analyse et des alertes plus automatisées, comme expliqué dans la section suivante.
Les administrateurs ont la possibilité de télécharger manuellement les journaux d'utilisation depuis la page d'utilisation de la console de compte ou avec l'API de compte. Cependant, un processus plus efficace pour analyser ces journaux d'utilisation consiste à configurer la livraison automatique des journaux vers le stockage cloud (AWS, GCP). Cela génère un fichier CSV quotidien contenant l'utilisation de chaque espace de travail dans un schéma granulaire.
Une fois la livraison des journaux d'utilisation configurée dans l'un des trois clouds, une bonne pratique courante consiste à créer un pipeline de données au sein de Databricks qui ingérera ces données quotidiennement et les enregistrera dans une table Delta à l'aide d'un flux de travail planifié. Ces données peuvent ensuite être utilisées pour l'analyse de l'utilisation ou pour déclencher des alertes informant les administrateurs ou les chefs d'équipe responsables des dépenses des centres de coûts lorsque la consommation atteint un seuil défini.
API Budgets
Une fonctionnalité à venir pour faciliter la budgétisation des coûts de calcul Databricks est le nouveau point de terminaison de budget (actuellement en aperçu privé) au sein de l'API de compte. Cela permettra à toute personne utilisant un espace de travail Databricks d'être notifiée une fois qu'un seuil budgétaire est atteint sur n'importe quelle période personnalisée filtrée par espace de travail, SKU ou balise de cluster. Ainsi, un budget peut être configuré pour n'importe quel espace de travail, centre de coûts ou équipe via cette API.
Résumé
Bien que la plateforme Databricks Lakehouse couvre de nombreux cas d'utilisation et personas d'utilisateurs, nous visons à fournir un ensemble d'outils unifiés pour aider les administrateurs à équilibrer le contrôle des coûts et l'expérience utilisateur. Dans ce blog, nous avons présenté plusieurs stratégies pour aborder cet équilibre :
- Utilisez les politiques de cluster pour contrôler quels utilisateurs peuvent créer des clusters, ainsi que la taille et la portée de ces clusters
- Concevez votre environnement pour minimiser les coûts non-DBU générés par les espaces de travail Databricks, tels que les coûts de stockage et de réseau
- Utilisez des outils de surveillance pour vous assurer que vos attentes en matière de coûts sont satisfaites et que vous disposez de pratiques efficaces
Consultez nos autres blogs axés sur les administrateurs, liés tout au long de cet article, et gardez un œil sur les blogs supplémentaires à venir. Assurez-vous également d'essayer de nouvelles fonctionnalités telles que Private Link (AWS | Azure) et la budgétisation !
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.