Bonnes pratiques pour un Model Serving à QPS élevé sur Databricks
Alimentez des applications de ML en temps réel en mode natif au sein du Lakehouse
par Tejas Sundaresan, Anshul Gupta, Arjun DCunha et Mike Del Balso
- Le Model Serving prend en charge des points de terminaison en temps réel qui montent en charge jusqu'à plus de 300 000 QPS (CPU), avec un moteur amélioré spécialisé dans le ML en temps réel à faible latence.
- Les clients utilisent le Model Serving pour alimenter des applications de ML en temps réel à QPS élevé telles que les systèmes de recommandation, la détection de fraude, la recherche et d'autres cas d'utilisation.
- Utilisez des endpoints à routage optimisé, les bonnes pratiques relatives aux endpoints et des optimisations côté client pour atteindre des objectifs de haute performance lors du service de vos modèles.
Les clients attendent des réponses instantanées à chaque interaction, qu'il s'agisse d'une recommandation affichée en quelques millisecondes, d'une transaction frauduleuse bloquée avant sa validation ou d'un résultat de recherche qui semble immédiat pour l'utilisateur. Pour monter en charge, la fourniture de ces expériences dépend de systèmes de diffusion de modèles qui restent rapides, stables et prévisibles, même sous une charge soutenue et inégale.
Lorsque le trafic atteint des dizaines ou des centaines de milliers de requêtes par seconde, de nombreuses équipes sont confrontées aux mêmes défis. La latence devient irrégulière, les coûts d'infrastructure augmentent et les systèmes nécessitent un réglage constant pour gérer les pics et les baisses de la demande. Les pannes deviennent également plus difficiles à diagnostiquer à mesure que de nouveaux composants sont assemblés, ce qui détourne les équipes de l'amélioration des modèles pour les amener à se concentrer sur le maintien en fonctionnement des systèmes de production.
Cet article explique comment Model Serving sur Databricks prend en charge les charges de travail en temps réel à QPS élevé et présente les meilleures pratiques concrètes que vous pouvez appliquer pour obtenir une faible latence, un débit élevé et des performances prévisibles en production.
Databricks Model Serving : simple et évolutif pour les charges de travail à QPS élevé
Databricks Model Serving fournit une infrastructure de service entièrement gérée et évolutive, directement au sein de votre lakehouse Databricks. Il vous suffit de prendre un modèle existant dans votre registre de modèles, de le déployer et d'obtenir un endpoint REST sur une infrastructure gérée, hautement évolutive et optimisée pour un trafic à QPS élevé.
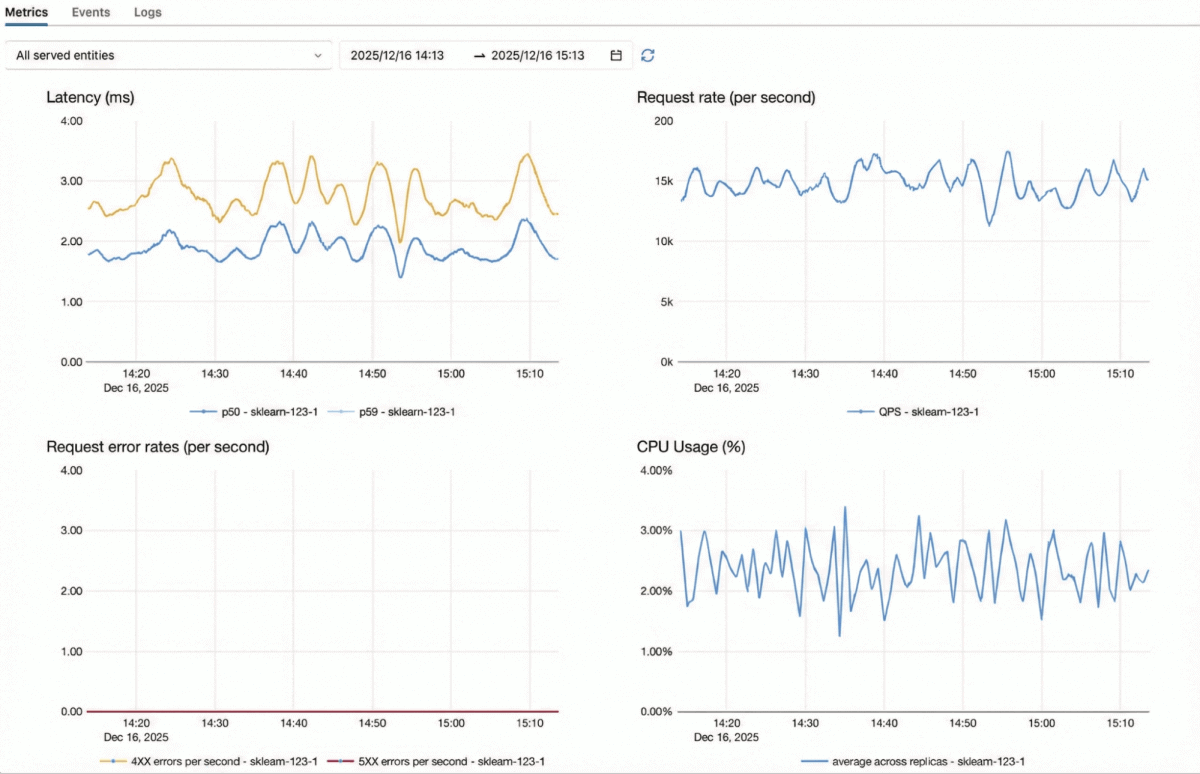
Le Model Serving de Databricks est optimisé pour les charges de travail critiques à QPS élevé :
- Moteur adaptatif en temps réel – Un serveur de modèles auto-optimisé qui s'adapte à la charge de travail de chaque modèle, permettant d'obtenir un débit et une utilisation des Ressources plus élevés à partir du même matériel.
- Architecture entièrement évolutive horizontalement – Notre serveur d'inférence, notre couche d'authentification, notre proxy et notre limiteur de débit sont tous conçus pour Monter en charge horizontalement de manière indépendante, ce qui permet au système de supporter des volumes de requêtes très élevés.
- Mise à l'échelle élastique rapide – Les serveurs d'inférence peuvent monter et descendre en charge, en s'adaptant aux pics ou aux baisses soudaines de trafic sans surprovisionnement.
- Intégration native du Magasin de fonctionnalités : le Feature Serving de Databricks s'intègre parfaitement au Model Serving, vous permettant de déployer des fonctionnalités et des modèles ensemble en tant qu'application unique et complète.
- Natif du Lakehouse : les clients peuvent centraliser les fonctionnalités, l'entraînement, le MLOps via MLFlow, le service et le monitoring en temps réel de leurs systèmes de ML en production dans une seule pile unifiée, ce qui permet de réduire la complexité des opérations et d'accélérer les déploiements.
Le Model Serving de Databricks permet à notre équipe de déployer des modèles de machine learning avec la fiabilité et la montée en charge requises pour les applications en temps réel. Il est conçu pour gérer les charges de travail à QPS élevé tout en maximisant l'utilisation du matériel. De plus, Databricks fournit une solution de Magasin de fonctionnalités de pointe avec des recherches ultra-rapides nécessaires pour de telles charges de travail. Grâce à ces capacités, nos ingénieurs ML peuvent se concentrer sur l'essentiel : affiner les performances du modèle et améliorer l'expérience utilisateur. —Bojan Babic, ingénieur de recherche, You.com
Meilleures pratiques pour atteindre des performances QPS élevées lors du Model Serving
Une fois cette base en place, l'étape suivante consiste à optimiser vos Endpoints, vos modèles et vos applications clientes pour atteindre de manière constante un throughput élevé et une faible latence, en particulier lorsque le trafic augmente. Les bonnes pratiques suivantes s'appuient sur des déploiements clients réels qui exécutent des millions à des milliards d'inférences chaque jour.
Veuillez consulter notre guide des bonnes pratiques pour plus de détails.
Meilleure pratique 1 : réduire la latence à l'aide d'Endpoints à routage optimisé
Une première étape clé pour garantir que la couche réseau est optimisée pour un throughput/QPS élevé et une faible latence. Le Model Serving le fait pour vous via des points de terminaison à routage optimisé. Lorsque vous activez l'optimisation des routes sur un point de terminaison, Databricks Model Serving optimise le réseau et le routage pour les requêtes d'inférence, ce qui se traduit par une communication plus rapide et plus directe entre votre client et le modèle. Cela réduit considérablement le temps nécessaire à une requête pour atteindre le modèle, et est particulièrement utile pour les applications à faible latence comme les systèmes de recommandation, la recherche et la détection de fraude.

{kind=link}
Meilleure pratique n°2 : optimiser le modèle et rendre les points de terminaison efficaces
Dans les scénarios à haut throughput, la réduction de la complexité du modèle, le déchargement du traitement depuis le endpoint de service et le choix des bonnes cibles de simultanéité aident votre endpoint à Monter en charge à des volumes de requêtes importants avec la juste quantité de compute nécessaire. De cette façon, vos Endpoints sont rentables, tout en pouvant monter en charge pour atteindre les objectifs de performance.
- Taille et complexité du modèle : les modèles plus petits et moins complexes permettent généralement d'obtenir des temps d'inférence plus rapides et un QPS plus élevé. Envisagez des techniques telles que la quantification ou l'élagage de modèle si votre modèle est volumineux.
- Prétraitement et post-traitement : déchargez les étapes complexes de prétraitement et de post-traitement du point de terminaison de service chaque fois que possible. Cela garantit que votre endpoint de service de modèle n'effectue que l'étape cruciale de l'inférence.
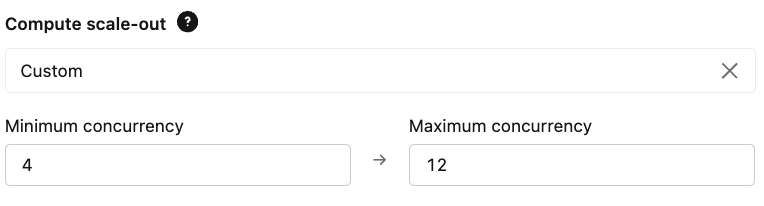
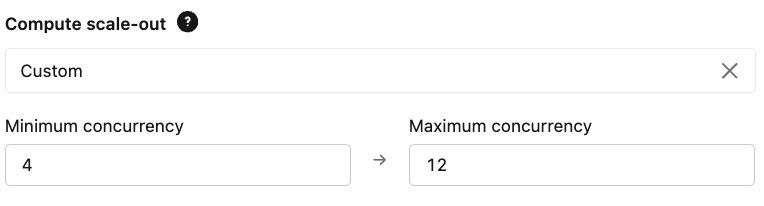
- Mise à l'échelle : configurez vos limites de simultanéité provisionnées en fonction de votre QPS attendu et de vos exigences en matière de latence. Cela garantit que l'endpoint est suffisant pour gérer la charge de base et que le maximum permet de répondre aux pics de demande.
{kind=link}
Avec Databricks Model Serving, nous pouvons gérer des charges de travail à QPS élevé telles que la personnalisation et les recommandations en temps réel. Cette solution offre à nos marques la capacité à monter en charge et la vitesse nécessaires pour proposer des expériences de contenu sur mesure à nos millions de lecteurs. —Oscar Celma, vice-président senior de Data Science et d'analytique produit chez Conde Nast
Bonne pratique n° 3 : Optimiser le code côté client
L'optimisation du code côté client garantit un traitement rapide des requêtes et une utilisation complète de vos instances de compute d'endpoint, ce qui se traduit par un meilleur throughput de QPS, des économies de coûts et une latence plus faible.
- Pooling de connexions : Utilisez le pooling de connexions côté client pour réduire la surcharge liée à l'établissement de nouvelles connexions pour chaque requête. Le SDK Databricks utilise toujours les meilleures pratiques de connexion. Toutefois, si vous devez utiliser votre propre client, soyez attentif à la stratégie de gestion des connexions.
- Taille de la charge utile : maintenez les charges utiles des requêtes et des réponses aussi petites que possible pour minimiser le temps de transfert sur le réseau.
- Traitement par lots côté client : si votre application peut envoyer plusieurs requêtes en un seul appel, activez le traitement par lots côté client. Cela peut réduire considérablement le surcoût par prédiction.
Regrouper les requêtes batch lors de l'appel des Endpoints de Databricks Model Serving
Commencez dès aujourd'hui
- Essayez le Model Serving de Databricks ! Commencez à déployer des modèles de ML en tant qu'API REST.
- Pour aller plus loin : veuillez consulter la documentation de Databricks pour le Model Serving personnalisés.
- Guide sur les QPS élevées : Veuillez consulter le guide des bonnes pratiques pour le service à QPS élevées sur Databricks Model Serving sur Databricks.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.