Construction d'un cadre d'analyse de tests A/B pour les jeux mobiles sur Databricks
Comment HARDlight a mis à l'échelle l'analyse des expériences avec une modélisation statistique automatisée, des informations gouvernées, un tableau de bord actualisé quotidiennement et des résumés générés par LLM.
par Sanjay Ashok, Jack Holdsworth, Tingting Wan, Joel Dias, Richard Carr et Monika Kolodziejczyk
- De la donnée à la décision : comment Sega HARDlight a automatisé l'analyse des tests A/B sur Databricks grâce à l'ingestion standardisée des expériences, à la modélisation statistique et à la publication des résultats — réduisant les flux de travail manuels et permettant une augmentation de 2× de la capacité d'expérimentation mensuelle sans personnel supplémentaire.
- Des informations pour chaque public : surveillance quotidienne avec un résumé LLM et des métriques, diagnostics et actions recommandées de plus en plus granulaires qui démocratisent l'accès à des informations exploitables dans toute l'organisation.
- La confiance par la transparence : une inférence statistique cohérente et des vues IA/BI accessibles ont aidé les équipes à comprendre les résultats, à renforcer leur confiance et à adopter une approche scientifique partagée de l'expérimentation.
Introduction
Les studios de jeux mobiles dépendent de l'expérimentation continue pour affiner le gameplay, la monétisation et les opérations en direct. À mesure que l'expérimentation s'intensifie, l'analyse devient souvent le facteur limitant. Les résultats sont souvent assemblés manuellement, les approches statistiques varient selon l'analyste et les informations arrivent des jours après l'émergence des signaux clés. Au fil du temps, cela crée des frictions : itération plus lente, conclusions incohérentes et perte de confiance dans les tests A/B en tant qu'outil de décision fiable.
Le Défi
Chez HARDlight, le défi n'était pas seulement la vitesse, mais la confiance. Des approches différentes menaient à des interprétations différentes, rendant l'alignement plus difficile et affaiblissant la confiance dans l'expérimentation en tant qu'outil de décision scientifique. Certains parties prenantes avaient besoin d'un simple statut quotidien, d'autres voulaient comprendre le comportement des joueurs ou l'impact commercial, et un groupe plus restreint nécessitait une validation approfondie de leviers de jeu spécifiques. Les tableaux de bord et les rapports existants peinaient à répondre efficacement à l'ensemble de ces besoins. Pour que l'expérimentation puisse évoluer, HARDlight avait besoin d'un moyen de standardiser l'inférence, de rendre les résultats accessibles à différents niveaux de profondeur et de rétablir la confiance dans les tests A/B en tant que processus de décision scientifique partagé.
Pour y remédier, HARDlight a construit un framework d'analyse de tests A/B natif à Databricks qui automatise le cheminement des données expérimentales vers des informations prêtes à la décision. L'analyse statistique a été effectuée en amont de manière répétable et transparente, et Databricks AI/BI a mis en évidence les résultats grâce à une expérience de rafraîchissement quotidien qui a commencé par un résumé généré par un LLM et permet une exploration plus approfondie avec des vues de plus en plus granulaires. À la fin de chaque expérience, les résultats ont été figés et conservés, garantissant que les décisions, le contexte et les apprentissages restent disponibles longtemps après la fin du test.
La Solution : Tests A/B Automatisés sur Databricks
Le framework de HARDlight automatise l'expérimentation, de l'ingestion au support de décision. Au sein de Databricks, les définitions d'expériences et la télémétrie sont standardisées, la modélisation statistique est appliquée de manière cohérente et les résultats sont publiés dans un tableau de bord multicouche qui se rafraîchit quotidiennement pendant la fenêtre d'exécution. Un résumé LLM en haut fournit une vue accessible de l'état de l'expérience, tandis que des sections plus approfondies exposent les KPIs, les diagnostics et les actions recommandées pour les utilisateurs experts.
Le choix de Databricks permet la gouvernance et la répétabilité entre les équipes. Unity Catalog fournit un plan de contrôle unique pour les permissions et la lignée des actifs expérimentaux ; Spark Declarative Pipelines orchestre des pipelines fiables pour l'ingestion et les transformations expérimentales ; et MLflow prend en charge le suivi des expériences et le packaging des modèles pour une analyse reproductible. Ensemble, ces capacités maintiennent les données et les analyses gouvernées, cohérentes et faciles à exploiter dans le Lakehouse.
Une innovation clé est le « tableau de bord figé » à la fin de l'exécution. Au lieu de passer au rafraîchissement suivant, le framework préserve l'instantané final et les décisions prises, ainsi que les actions recommandées. Cela institutionnalise les apprentissages des expériences passées et permet aux parties prenantes de revoir les résultats sans ambiguïté.
Architecture Technique
Le framework d'expérimentation est construit comme un système natif à Databricks qui sépare le traitement des données, l'inférence statistique et la consommation, tout en gardant toutes les sorties gouvernées et reproductibles par défaut. Cette conception garantit que la rigueur analytique s'intensifie sans augmenter la charge opérationnelle ni fragmenter l'interprétation entre les équipes.
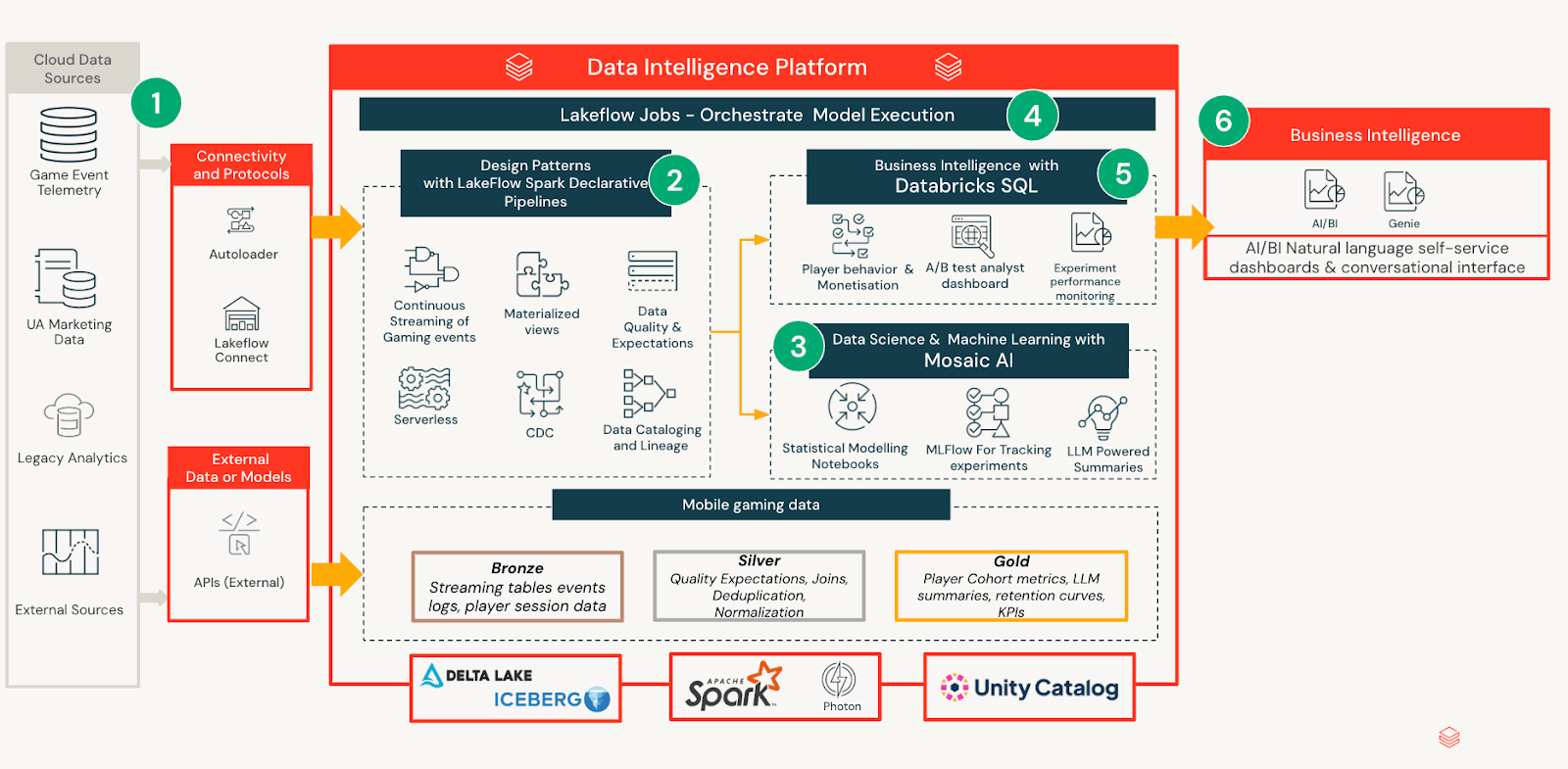
Ingestion & Modélisation des Données
Les définitions d'expériences, la télémétrie des joueurs et les métriques de résultats sont ingérées à partir de pipelines internes et organisées en tables gouvernées avec des schémas cohérents. Cette standardisation permet aux analystes et aux équipes produit de raisonner sur les expériences de manière cohérente, quelle que soit la conception ou la durée du test. Les notebooks sont utilisés pour calculer des modèles statistiques qui estiment les tailles d'effet, les incertitudes et les impacts au niveau des segments au fil du temps. Plutôt que d'intégrer la logique dans les tableaux de bord ou les rapports, toutes les sorties analytiques sont matérialisées dans un modèle d'analyse d'expériences unifié. Cela crée une couche sémantique stable sur laquelle les consommateurs en aval peuvent s'appuyer sans avoir à réexécuter l'analyse ou à réinterpréter les résultats.
Livraison d'Informations Alimentée par l'IA/BI
Au-dessus de cette couche d'analyse gouvernée, Databricks AI/BI fournit une interface accessible pour consommer les résultats des expériences. Chaque rafraîchissement quotidien génère un résumé concis par LLM destiné aux parties prenantes non techniques, traduisant les sorties statistiques validées en langage naturel. Le tableau de bord utilise la divulgation progressive : les utilisateurs peuvent s'arrêter au résumé lorsqu'ils sont satisfaits, ou explorer des couches plus approfondies de métriques, de diagnostics et d'analyses de segments à mesure que leur curiosité augmente. Cette expérience multicouche permet un balayage rapide tout en gardant la profondeur analytique disponible pour la validation par les experts.

Cycle de Vie et Persistance de l'Expérience
Pendant la phase active, le tableau de bord se rafraîchit quotidiennement afin que les équipes puissent suivre la trajectoire et réagir aux signaux. À la conclusion, le tableau de bord est figé pour préserver les résultats, les décisions et les actions recommandées. Ce cycle de vie crée un enregistrement auditable qui accélère l'intégration et réduit la duplication des analyses pour les expériences futures.
Couches du Tableau de Bord Expliquées
Le tableau de bord est conçu pour guider les utilisateurs à travers les résultats d'une expérience dans une séquence claire et délibérée. Il commence par la simplicité et dévoile progressivement plus de détails pour ceux qui souhaitent explorer davantage. Chaque section répond à une question différente, et il est tout à fait acceptable de s'arrêter une fois que le lecteur a obtenu les informations nécessaires.
Résumé de l'expérience généré par LLM : En haut du tableau de bord se trouve un résumé généré par LLM. Tant qu'une expérience est active, cela donne une vue simple et de haut niveau de la situation, soulignant les signaux précoces sans tirer de conclusions hâtives.
Une fois l'expérience terminée, le résumé change de rôle. Il devient une explication claire de ce qui s'est passé, mettant en évidence les métriques qui ont évolué avec une grande confiance, par ordre de priorité et en langage clair. L'objectif est d'aider les équipes à comprendre rapidement le résultat et pourquoi il est important.
Résultats confirmés et impact statistique : Pour les publics plus techniques, la section suivante présente une vue structurée des résultats statistiquement significatifs. Les métriques clés telles que la valeur vie client (LTV) et la rétention sont listées aux côtés des tailles d'effet et des niveaux de confiance, ce qui permet de valider facilement les conclusions sans avoir à examiner l'analyse brute.
Impact estimé sur la valeur vie client : Le tableau de bord montre ensuite l'impact estimé sur la valeur vie client pour les groupes de contrôle et les variantes. L'incertitude et les marges d'erreur sont indiquées explicitement, renforçant le fait qu'il s'agit d'estimations éclairées, et non de prévisions absolues.
Impact des revenus par source : Les résultats sont ventilés par flux de revenus, y compris les publicités, les achats intégrés et le revenu total. Cela aide les équipes à comprendre si les changements sont généralisés ou s'ils sont dus à des canaux de monétisation spécifiques.
Engagement et comportement des joueurs : Au-delà des revenus, les métriques d'engagement telles que la rétention et le comportement des sessions sont mises en évidence pour garantir que les gains commerciaux sont pris en compte aux côtés de l'expérience joueur et de la santé à long terme.
Analyse au niveau des segments : La segmentation est au cœur de la conception et de l'évaluation des expériences par HARDlight. Cette section montre comment différents segments de joueurs réagissent à un changement, qu'ils soient définis par la rétention, la progression ou d'autres traits comportementaux. Elle aide les équipes à confirmer que les expériences ciblées fonctionnent comme prévu, sans nuire à d'autres parties de la base de joueurs.
Mécanismes de monétisation et économie du jeu : Des couches plus approfondies explorent comment les expériences affectent les systèmes de jeu, y compris les performances publicitaires par emplacement, les performances des achats intégrés par catégorie de produits et les changements dans les flux de devises fortes et faibles entre les sources et les puits.
Boucles de gameplay principales et annexes : Au niveau le plus profond, des graphiques et des tableaux détaillés couvrent les mécanismes de gameplay tels que les courses, les personnages et les objets, ainsi que des visuels statistiques de support. Cette couche est destinée aux utilisateurs experts qui souhaitent une transparence totale ou qui ont besoin de réutiliser les informations dans des travaux futurs.
Ensemble, ces couches permettent aux informations de se dévoiler naturellement. Les équipes peuvent avancer rapidement lorsque la réponse est claire, ou approfondir lorsque des questions se posent, tout en travaillant à partir de la même source de données gouvernée et fiable.
Cette structure est rendue possible par Databricks AI/BI, qui permet de présenter des sorties analytiques complexes de manière claire sans intégrer de code personnalisé ou de workflows réservés aux analystes dans les tableaux de bord. Les résultats statistiques, les projections et les analyses au niveau des segments sont calculés en amont dans des notebooks et matérialisés dans des tables gouvernées, tandis qu'AI/BI fournit une couche de présentation flexible au-dessus. Cela élimine le besoin d'exécuter Python dans les tableaux de bord, simplifie la maintenance et permet à une équipe restreinte d'itérer et d'améliorer le système au fil du temps.
Plus important encore, AI/BI permet de servir des publics très différents à partir des mêmes données sous-jacentes. Les résumés narratifs, les résultats tabulaires, les graphiques et les diagnostics approfondis peuvent coexister sans dupliquer la logique ni fragmenter l'interprétation. Ce fut un changement clé par rapport aux approches antérieures, où les contraintes d'outillage obligeaient à des compromis entre la profondeur analytique, l'accessibilité et la durabilité.
Impact et résultats
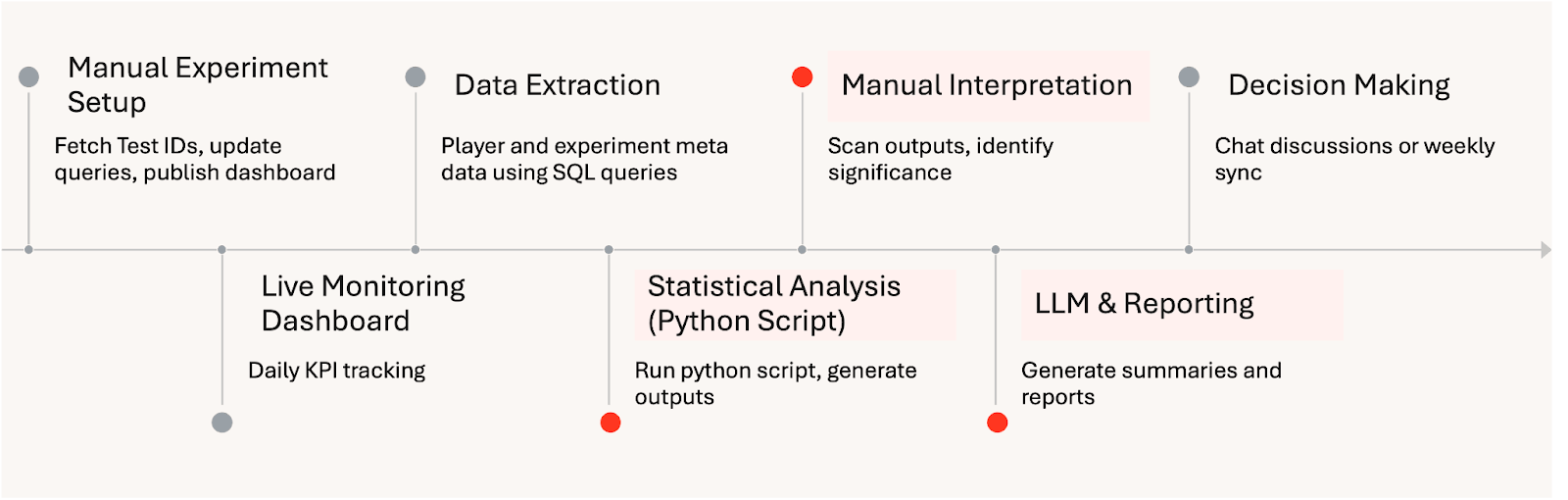
Ce framework a fondamentalement changé la façon dont l'expérimentation fonctionne chez HARDlight. En automatisant l'analyse et en standardisant l'inférence statistique, l'équipe de données a réduit l'effort manuel de plus de huit heures par semaine. En standardisant les exécutions d'expériences avec Databricks Workflows, l'équipe a éliminé une grande partie du travail de configuration manuelle précédemment requis pour chaque analyse. Cela permet d'économiser environ une journée par expérience et a permis une augmentation ciblée de deux fois la capacité mensuelle de tests A/B sans augmenter les effectifs.
Flux de travail d'analyse d'expériences manuelles :
Livraison automatisée d'informations sur les expériences sur Databricks :
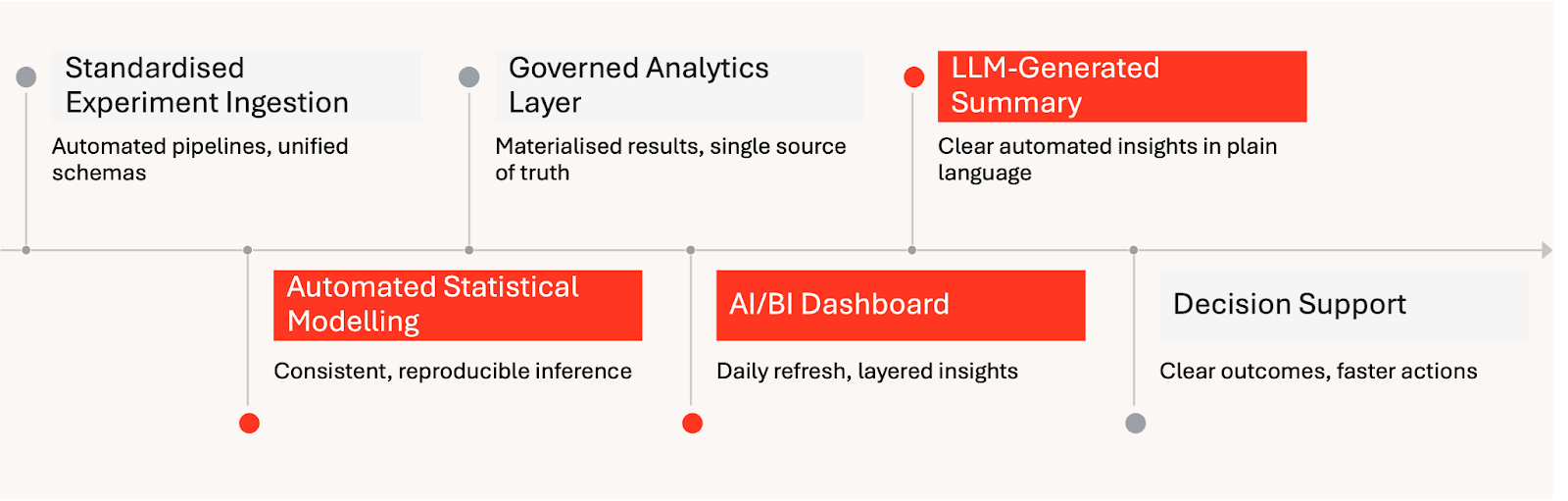
Au-delà des gains d'efficacité, le système a amélioré la cohérence et la confiance dans les résultats. L'archive de tableaux de bord figée sert désormais de source de vérité durable pour les expériences terminées, réduisant les analyses répétées et permettant aux équipes de revoir plus facilement les décisions passées avec un contexte complet. Cela a considérablement réduit les frais généraux liés au maintien des connaissances historiques entre les équipes.
Plus important encore, ce framework a changé la façon dont les informations sont consommées dans le studio. Avec plusieurs expériences exécutées en parallèle, les équipes reçoivent désormais des mises à jour quotidiennes, activées par l'IA/BI, qui remplacent l'agrégation et l'interprétation manuelles de plusieurs jours. Genie sera activé directement sur le tableau de bord, permettant aux utilisateurs de poser des questions sur ce qu'ils voient et d'explorer les résultats avec leurs propres mots, sans avoir besoin de comprendre le modèle de données sous-jacent. Ensemble, des résumés clairs, des métriques gouvernées, des sorties statistiques transparentes et un accès conversationnel ont contribué à renforcer la confiance entre les équipes produit, LiveOps et ingénierie, renforçant l'expérimentation comme une façon de travailler partagée et scientifique.
Prochaines étapes
HARDlight prévoit d'étendre ce framework avec une application de prévision, étendant le framework de l'analyse descriptive et inférentielle à des conseils prospectifs. La vision plus large est l'expérimentation prédictive et l'optimisation en boucle fermée — en utilisant le Lakehouse pour automatiser davantage le cycle, de l'hypothèse au déploiement, tout en préservant la gouvernance et la cohérence avec Unity Catalog, Spark Declarative Pipelines et MLflow. Cette approche axée sur les tableaux de bord peut avoir un impact significatif pour d'autres studios ayant des besoins similaires, en superposant des résumés LLM sur des métriques gouvernées et des diagnostics pour faire évoluer l'expérimentation en toute confiance sur Databricks.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.