Construction d'un Data Mesh basé sur le Lakehouse Databricks, partie 2
par Bernhard Walter, Sharon Richardson, Guillermo Schiava D'Albano, Pawarit Laosunthara, Amr Ali et Fran Medina Castro
Dans le dernier article "Databricks Lakehouse et Data Mesh", nous avons présenté le Data Mesh basé sur le Databricks Lakehouse. Cet article explorera comment les capacités du Databricks Lakehouse prennent en charge le Data Mesh d'un point de vue architectural.
Le Data Mesh est un paradigme architectural et organisationnel, pas une technologie ou une solution que l'on achète. Cependant, pour implémenter efficacement un Data Mesh, vous avez besoin d'une plateforme flexible qui assure la collaboration entre les différents profils de données, garantit la qualité des données et facilite l'interopérabilité et la productivité sur toutes les charges de travail de données et d'IA.
Examinons comment les capacités de la plateforme Databricks Lakehouse répondent à ces besoins.
Le bloc de construction de base d'un data mesh est le domaine de données, généralement composé des éléments suivants :
- Données sources (appartenant au domaine)
- Ressources de calcul en libre-service et orchestration (au sein des Databricks Workspaces)
- Produits de données orientés domaine servis aux autres équipes et domaines
- Informations prêtes à être consommées par les utilisateurs métier
- Respect des politiques de gouvernance computationnelle fédérée
Ceci est illustré dans la figure ci-dessous :
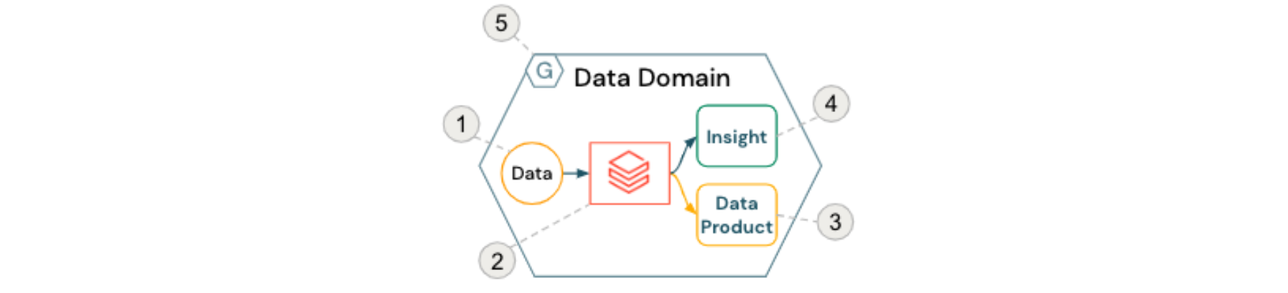
Pour faciliter la collaboration inter-domaines et l'analyse en libre-service, des services communs autour des mécanismes de contrôle d'accès et de catalogage des données sont souvent fournis de manière centralisée. Par exemple, Databricks Unity Catalog fournit non seulement des capacités de catalogage informationnelles telles que la découverte de données et la lignée, mais aussi l'application des contrôles d'accès granulaires et de l'audit souhaités par de nombreuses organisations aujourd'hui.
Le Data Mesh peut être déployé dans diverses topologies. En dehors des entreprises numériques modernes, un Data Mesh très décentralisé avec des domaines entièrement indépendants n'est généralement pas recommandé car il entraîne une complexité et une surcharge pour les équipes de domaine plutôt que de leur permettre de se concentrer sur la logique métier et des données de haute qualité. Deux exemples populaires souvent rencontrés dans les entreprises sont le Data Mesh Harmonisé et le Data Mesh Hub & Spoke.
1) Approche pour un Data Mesh harmonisé
Un data mesh harmonisé met l'accent sur l'autonomie au sein des domaines :
- Les domaines de données créent et publient des produits de données spécifiques au domaine
- La découverte des données est automatiquement activée par Unity Catalog
- Les produits de données sont consommés de manière peer-to-peer
- L'infrastructure du domaine est harmonisée via
- des modèles de plateforme, garantissant la sécurité et la conformité
- des services de plateforme en libre-service (automatisation du provisionnement des domaines, catalogage des données, publication des métadonnées, politiques sur les données et les ressources de calcul)
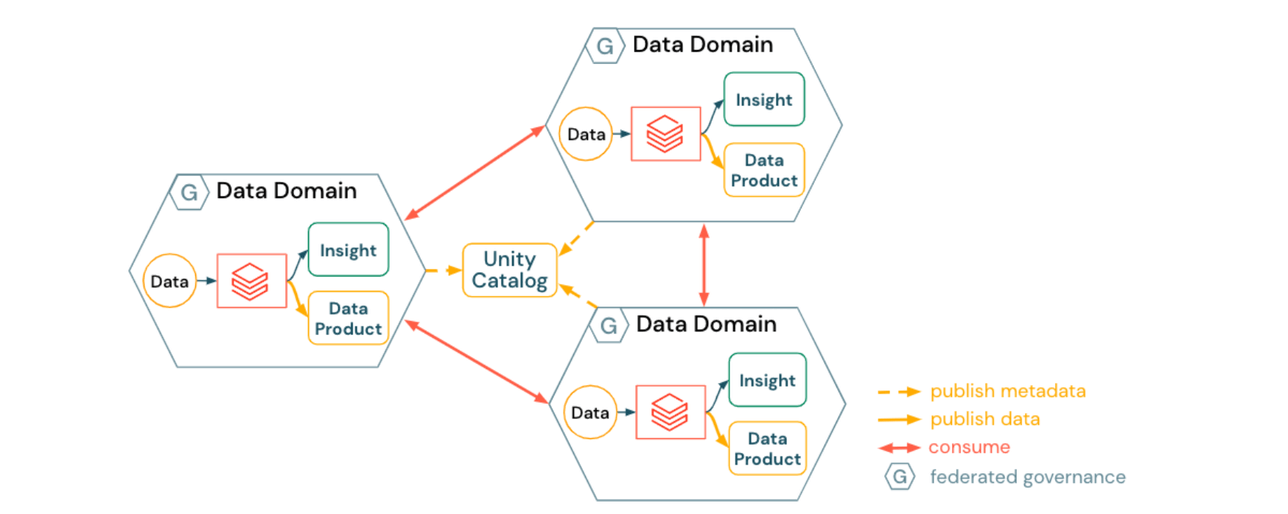
Les implications d'une approche harmonisée peuvent inclure :
- Chaque domaine de données doit adhérer aux normes et meilleures pratiques pour l'interopérabilité et la gestion de l'infrastructure
- Chaque domaine de données dépense indépendamment plus de temps et d'efforts sur des sujets tels que les contrôles d'accès, les comptes de stockage sous-jacents, ou même l'infrastructure (par exemple, les brokers d'événements pour les produits de données en streaming)
Cette approche peut être difficile dans les organisations mondiales où les différentes équipes ont des compétences variées et peuvent avoir du mal à rester pleinement synchronisées avec les dernières pratiques et politiques.
2) Approche pour un Data Mesh Hub & Spoke
Un Data Mesh Hub & Spoke intègre un emplacement centralisé pour gérer les actifs de données partageables et les données qui n'appartiennent logiquement à aucun domaine unique :
- Les domaines de données (les spokes) créent des produits de données spécifiques au domaine
- Les produits de données sont publiés dans le data hub, qui possède et gère la majorité des actifs enregistrés dans Unity Catalog
- Le data hub fournit des services génériques de plateforme pour les domaines de données tels que :
- publication de données en libre-service vers des emplacements gérés
- catalogage des données, lignée, audit et contrôle d'accès via Unity Catalog
- services de gestion des données tels que le voyage dans le temps et les processus RGPD à travers les domaines (par exemple, demandes de droit à l'oubli)
- Le data hub peut également agir comme un domaine de données. Par exemple, des pipelines ou des outils pour des ensembles de données génériques ou acquis extérieurement tels que la météo, les études de marché ou les données macroéconomiques standard.
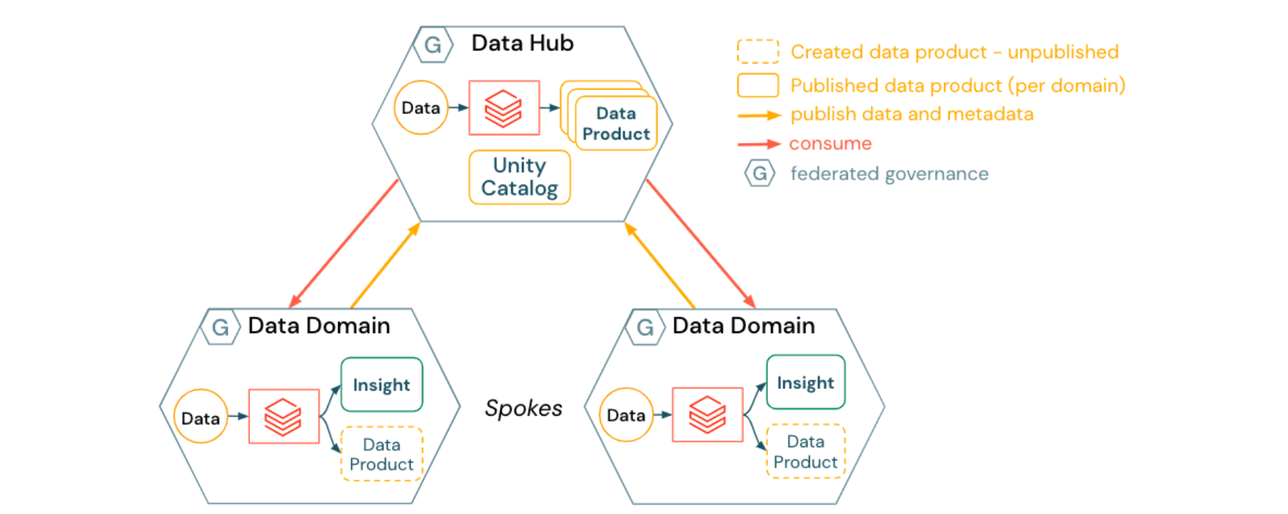
Les implications pour un Data Mesh Hub and Spoke incluent :
- Les domaines de données peuvent bénéficier de services de données développés et déployés de manière centralisée, leur permettant de se concentrer davantage sur la logique métier et la transformation des données
- L'automatisation de l'infrastructure et le calcul en libre-service peuvent aider à éviter que l'équipe du data hub ne devienne un goulot d'étranglement pour la publication des produits de données
Dans ces deux approches, les domaines peuvent également avoir des besoins communs et répétables tels que :
- Outils et connecteurs d'ingestion de données
- Frameworks, modèles ou meilleures pratiques MLOps
- Pipelines pour l'intégration continue/déploiement continu (CI/CD), la qualité des données et la surveillance
Il est également tout à fait possible d'avoir une certaine variation entre un data mesh entièrement harmonisé et un modèle hub-and-spoke. Par exemple, avoir un data hub mondial minimal pour héberger uniquement les actifs de données qui ne se situent logiquement dans aucun domaine unique et pour gérer les données acquises extérieurement qui sont utilisées dans plusieurs domaines. Unity Catalog joue un rôle central en fournissant la découverte de données authentifiée, où que les données soient g�érées au sein d'un déploiement Databricks.
Mise à l'échelle et évolution du Data Mesh
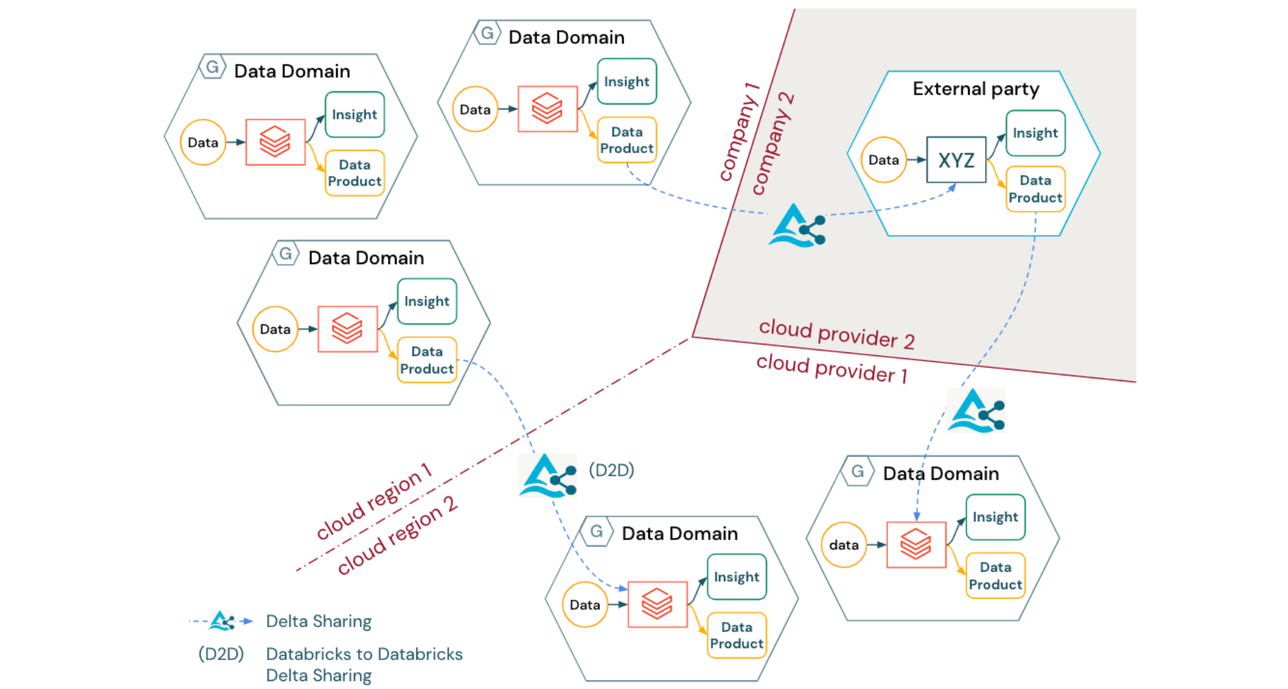
Indépendamment du type d'architecture logique de Data Mesh déployée, de nombreuses organisations seront confrontées au défi de créer un modèle opérationnel qui s'étend sur les régions cloud, les fournisseurs cloud et même les entités juridiques. De plus, à mesure que les organisations évoluent vers la productisation (et potentiellement même la monétisation) des actifs de données, le partage de données interopérable de niveau entreprise reste primordial pour la collaboration non seulement entre les domaines internes, mais aussi entre les entreprises.
Delta Sharing offre une solution à ce problème avec les avantages suivants :
- Delta Sharing est un protocole ouvert pour partager en toute sécurité des produits de données entre domaines, par-delà les frontières organisationnelles, régionales et techniques
- Le protocole Delta Sharing est indépendant des fournisseurs (y compris un large écosystème de clients), fournissant un pont entre différents domaines ou même différentes entreprises sans qu'elles aient besoin d'utiliser la même pile technologique ou le même fournisseur cloud
Remarques finales
Le Data Mesh et le Lakehouse sont tous deux nés de points de douleur et de lacunes communes des entrepôts de données d'entreprise et des lacs de données traditionnels[1][2]. Le Data Mesh articule de manière exhaustive la vision métier et les besoins pour améliorer la productivité et la valeur des données, tandis que le Databricks Lakehouse fournit une base ouverte et évolutive pour répondre à ces besoins avec une interopérabilité, une rentabilité et une simplicité maximales.
Dans cet article, nous avons mis l'accent sur deux exemples de capacités de la plateforme Databricks Lakehouse qui améliorent la collaboration et la productivité tout en prenant en charge la gouvernance fédérée, à savoir :
- Unity Catalog comme catalyseur pour la publication indépendante de données, la découverte centralisée des données et la gouvernance informatique fédérée dans le Data Mesh
- Delta Sharing pour les grandes organisations mondiales qui ont des déploiements sur plusieurs clouds et régions. Delta Sharing partage efficacement et en toute sécurité des données fraîches et à jour entre les domaines dans différentes limites organisationnelles sans duplication
Cependant, une pléthore d'autres fonctionnalités Databricks servent d'excellents catalyseurs dans le parcours Data Mesh pour différentes personnes. Par exemple :
- Workflows et Delta Live Tables pour des pipelines de données en libre-service de haute qualité prenant en charge les charges de travail par lots et de streaming
- Databricks SQL permettant des requêtes BI & SQL performantes directement sur le lac, réduisant ainsi le besoin pour les équipes de domaine de maintenir plusieurs copies/magasins de données pour leurs produits de données
- Databricks Feature Store qui favorise le partage et la réutilisation entre les équipes Data Science & Machine Learning
Pour en savoir plus sur Lakehouse pour Data Mesh :
- Matei Zaharia : Data Mesh et Lakehouse
- Zalando & Thoughtworks : Data Lakehouse et Data Mesh — Deux faces d'une même pièce
- Databricks : Meshing About with Databricks
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.