Créer un assistant de connaissance sur le code
Évaluation des stratégies de découpage avec MLflow
par Daniel Liden
- Le RAG sur le code présente des défis de découpage uniques : diviser des fonctions au milieu de leur corps ou ignorer le contexte structurel dégrade la récupération, même lorsque vous trouvez le bon fichier.
- Nous avons utilisé le framework d'évaluation GenAI de MLflow avec des juges LLM intégrés et personnalisés pour comparer systématiquement trois stratégies de découpage utilisées avec Databricks Knowledge Assistant.
- Le processus d'évaluation lui-même a été la principale leçon : des jeux de données d'évaluation structurés, des résultats traçables et des juges LLM personnalisés alignés sur ce qui vous importe réellement rendent l'itération RAG pratique.
Lorsque les développeurs rejoignent un nouveau projet ou doivent travailler sur une base de code inconnue, les assistants de connaissance comme Databricks Knowledge Assistant les aident à se familiariser en répondant à des questions en langage naturel sur le code. Mais la qualité des réponses dépend fortement de la manière dont le code source et le contexte environnant ont été préparés et ajoutés. Un facteur clé est le chunking : la façon dont vous divisez les fichiers sources en morceaux pour l'indexation et la récupération. Le code rend cela difficile. Si vous coupez une fonction en plein milieu ou supprimez son contexte de classe, même un assistant compétent aura du mal à y répondre.
Nous avons créé trois assistants de connaissance sur notre dépôt GitHub de démonstration Casper’s Kitchens, chacun utilisant une stratégie de chunking différente, allant d'une simple base de taille fixe à une approche sensible à la structure qui analyse le code en ses composants syntaxiques. Le dépôt simule une entreprise de cuisine fantôme sur Databricks, utilisant un large éventail de fonctionnalités, y compris les pipelines Lakeflow, les agents DSPy et les Databricks Asset Bundles (DABs), avec une documentation dans des fichiers markdown et des cellules de notebook. Les dépendances inter-fichiers, les formats de fichiers mixtes et les modèles spécifiques au domaine en font le type de projet où un assistant de connaissance compétent serait d'une grande aide.
Ce post explique ce qui rend le travail avec le code différent du travail avec des documents commerciaux typiques, comment nous avons déployé chaque stratégie de chunking en tant que Databricks Knowledge Assistant, et comment nous avons utilisé le cadre d'évaluation de MLflow pour les comparer. Vous pouvez trouver tout le code ici.
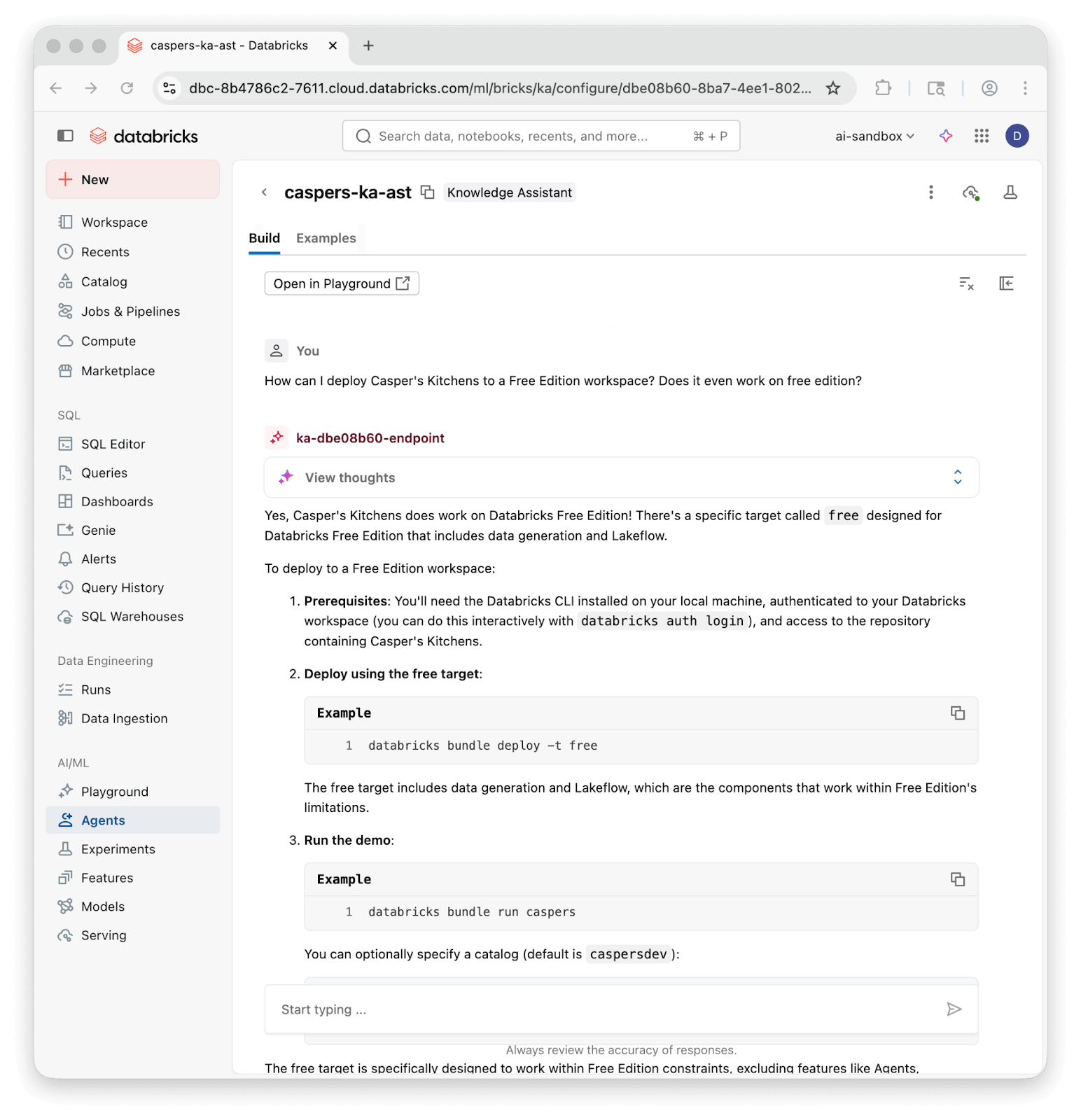
Comment fonctionnent les assistants de connaissance (et pourquoi le code est différent)
En coulisses, les assistants de connaissance utilisent diverses formes de génération augmentée par récupération (RAG). Ils récupèrent des morceaux pertinents des données sources, souvent à partir d'un index de recherche vectorielle, et les transmettent à un grand modèle linguistique comme contexte pour générer une réponse à une requête utilisateur.
Databricks Knowledge Assistant s'appuie sur cette base avec des techniques de récupération sophistiquées, y compris Instructed Retriever, qui intègre la décomposition des requêtes, le re-classement informé par le contexte et le raisonnement sur les métadonnées des documents. Ces capacités contribuent grandement à gérer la complexité des bases de code du monde réel, et elles fonctionnent mieux lorsque les morceaux sous-jacents préservent des limites sémantiques significatives.
Les assistants de connaissance sont le plus souvent construits et évalués sur des collections de documents commerciaux, qui ont tendance à s'écouler linéairement, avec des paragraphes et des sections. Le code a des hiérarchies imbriquées : les fichiers contiennent des classes, les classes contiennent des méthodes, les méthodes contiennent des blocs de logique. L'unité sémantique dans le code est souvent une fonction complète, pas un paragraphe.
Cela crée des défis spécifiques, notamment :
- Limites sémantiques : Couper une fonction en plein milieu perd le contexte nécessaire pour comprendre ce qu'elle fait. Un morceau contenant
deletion_order = ['experiments', 'jobs'...est moins utile s'il ne montre pas que cette variable se trouve dansUCState.clear_all(). - Dépendances inter-fichiers : Le code fait référence à d'autres codes. Comprendre une fonction nécessite souvent le contexte de sa classe, de ses importations ou des fonctions connexes.
- Types de fichiers mixtes : Notre base de code contient des fichiers
.py, des notebooks.ipynb(JSON avec des cellules de code/Markdown), de la documentation.mdet de la configuration.yaml, chacun nécessitant des approches d'analyse différentes.
Étant donné que Databricks Knowledge Assistant vous permet d'utiliser votre propre index vectoriel, vous pouvez préparer les morceaux comme vous le souhaitez et simplement pointer Knowledge Assistant vers le résultat. Cela nous a permis de comparer différentes approches pour préparer notre base de code pour le RAG et de choisir la meilleure.
Stratégies de chunking
Pour voir comment les stratégies de chunking diffèrent en pratique, considérons ce qui se passe lorsque vous demandez : « Dans quel ordre le nettoyage des ressources se produit-il ? » La réponse se trouve dans une classe utilitaire qui suit les expériences, les tâches et les pipelines. Sa logique couvre l'initialisation, une liste d'ordres de suppression et des méthodes de nettoyage. Voici comment chaque méthode fonctionne et comment elle affecte le contexte récupéré sur la classe de nettoyage des ressources, UCState.
Baseline Naïve : Morceaux de caractères de taille fixe
L'approche la plus simple consiste à diviser les fichiers sources à intervalles de caractères fixes avec chevauchement, en traitant le code comme du texte brut. Ce n'est pas ce que vous choisiriez pour un système RAG prêt pour la production aujourd'hui. Il ignore la syntaxe et les limites sémantiques, donc il échoue exactement dans les domaines qui intéressent les requêtes de code. Mais il est aussi extrêmement facile à implémenter, souvent « suffisamment bon » pour des expériences rapides ou des dépôts riches en documentation, et courant comme première passe, c'est donc une base utile.
Voici ce que produit le chunking naïf pour une recherche de deletion_order dans notre base de code :
Le nom de la variable a été coupé en deux (eletion au lieu de deletion), et le morceau n'inclut pas le nom de la méthode. Si quelqu'un recherche « UCState deletion order », ce morceau ne correspondra pas bien. De plus, la liste deletion_order dans la méthode a été coupée.
Sensible au langage : Séparateurs heuristiques LangChain
Le RecursiveCharacterTextSplitter.from_language() de LangChain utilise des séparateurs spécifiques au langage (comme \nclass et \ndef pour Python) pour préférer la division aux limites logiques. Il essaie de garder les fonctions intactes mais impose toujours des limites de taille strictes. Conceptuellement, cela améliore le chunking naïf en privilégiant les divisions aux limites sémantiques probables (comme def et class) plutôt que des comptes de caractères arbitraires, de sorte que les morceaux sont plus susceptibles de contenir des unités logiques complètes.
Voici ce que cette approche a produit pour la même recherche :
Le morceau commence à une limite plus naturelle, mais il manque toujours de contexte indiquant de quel fichier ou fonction il appartient, et il se coupe juste après le début d'une boucle for.
Basé sur AST : Tree-Sitter avec en-têtes de métadonnées
Le découpage basé sur l'arbre syntaxique abstrait (AST) utilise un analyseur comme Tree-sitter pour comprendre la structure réelle du code. Un AST est une représentation arborescente du code qui capture sa structure syntaxique, c'est-à-dire comment le code est organisé selon les règles grammaticales d'un langage. Au lieu de diviser aux limites de caractères ou d'utiliser des modèles heuristiques, une stratégie de découpage basée sur l'AST analyse le code en un arbre syntaxique et découpe aux limites sémantiques, telles que les fonctions, les classes ou les blocs d'instructions. Il peut également dépasser les limites de taille si nécessaire pour conserver une unité complète, plutôt que de la diviser en milieu de fonction.
Nous avons utilisé la bibliothèque Python ASTChunk pour gérer le découpage basé sur l'AST. La bibliothèque comprend une option de développement de morceaux qui fait que chaque morceau est précédé d'un en-tête de métadonnées indiquant le chemin du fichier et la hiérarchie des classes/fonctions. Ce contexte fait partie de l'intégration, aidant la récupération à faire correspondre les requêtes à du code pertinent, même lorsque les termes de la requête n'apparaissent pas dans le corps du morceau.
Voici le morceau que cette approche a produit pour notre requête :
L'en-tête nous indique exactement où se trouve ce code : utils/uc_state/state_manager.py → class UCState: → def clear_all(...). Lorsqu'il est intégré, ce morceau a une connexion sémantique plus forte avec les requêtes concernant « UCState », « clear_all » ou « deletion order ».
À ce stade, nous avions quelques intuitions sur les méthodes qui fonctionneraient le mieux dans notre assistant de connaissances. Mais pour en être sûrs, nous devions effectuer une évaluation systématique.
Configuration de l'évaluation avec MLflow
Le framework d'évaluation GenAI de MLflow fournit une boîte à outils complète pour comparer les LLM, les agents et les systèmes de récupération. Vous lui donnez un jeu de données d'évaluation, une fonction de prédiction et des juges LLM, et il exécute chaque question à travers votre pipeline et évalue les résultats. Voici comment nous l'avons utilisé pour comparer les trois méthodes de découpage.
Le jeu de données d'évaluation
Nous avons créé 46 questions couvrant un ensemble diversifié de catégories, allant de sujets conceptuels généraux à des requêtes détaillées sur le code.
| Catégorie | Nombre | Exemple |
|---|---|---|
| Identification de valeurs spécifiques | 7 | « Quel est l'ordre de suppression exact dans UCState.clear_all() ? » |
| Récupération de définitions complètes | 8 | « Listez tous les champs et validateurs du modèle ComplaintResponse. » |
| Compréhension des flux système | 6 | « Comment le pipeline de réclamations fonctionne-t-il de bout en bout, de la génération à la synchronisation Lakebase ? » |
| Comparaison des implémentations d'applications | 13 | « Comment parse_agent_response diffère-t-il entre complaints-manager et refund-manager ? » |
| Comparaison des frameworks et modèles | 12 | « Quel framework ML chaque agent utilise-t-il ? Comment leurs modèles de gestion des erreurs et de streaming diffèrent-ils ? » |
Nous avons délibérément pondéré le jeu de données vers des questions de désambiguïsation où la base de code contient du code structurellement similaire dans différents contextes, comme deux applications avec des noms de fonctions qui se chevauchent, des schémas de base de données parallèles ou des fichiers de configuration qui diffèrent de manière subtile. Ce sont les requêtes qui exposent le plus clairement les faiblesses du découpage. Si vos morceaux manquent de métadonnées sur l'emplacement du code, le système de récupération aura du mal à faire la différence entre des classes et des fonctions similaires qui existent dans des contextes différents.
Les juges LLM
Nous avons utilisé trois juges LLM principaux, chacun capturant un aspect différent de la qualité :
RetrievalSufficiency(intégré) : Les morceaux récupérés contiennent-ils suffisamment d'informations pour répondre à la question ? C'est la métrique clé pour comparer les stratégies de découpage car elle mesure la qualité de la récupération indépendamment de la génération.RetrievalGroundedness(intégré) : La réponse est-elle basée sur le contexte récupéré, ou introduit-elle des informations qui ne sont pas présentes dans les morceaux ?answer_correctness(personnalisé) : Ce score personnalisé classe chaque réponse comme correcte, partiellement correcte ou incorrecte, ce qui la rend un peu plus nuancée qu'un juge de correction strict oui/non. Compte tenu de la possibilité d'un *contexte* fragmenté ou incomplet, nous voulons surveiller les réponses qui pourraient manquer de détails ou présenter de petites inexactitudes.
Exécution de l'évaluation
Pour maintenir la comparaison équitable, toutes les stratégies ont utilisé la même taille de morceau cible (1 000 caractères), le même chevauchement (200 caractères) et le même modèle d'intégration (databricks-gte-large-en). En pratique, les tailles finales des morceaux diffèrent toujours (par exemple, le découpage basé sur l'AST peut s'étendre pour préserver une unité sémantique complète, tandis que les fichiers très petits produisent naturellement de petits morceaux).
Pour chaque stratégie de découpage, nous avons écrit les morceaux dans une table Delta, créé un index de recherche vectorielle avec des intégrations gérées (en utilisant le modèle d'intégration databricks-gte-large-en, comme requis par l'assistant de connaissances Databricks), et attaché l'index à un point de terminaison d'assistant de connaissances. La documentation couvre la configuration complète.
Nous avons évalué chaque stratégie de découpage en interrogeant directement son point de terminaison d'assistant de connaissances. La fonction to_predict_fn() de MLflow encapsule un point de terminaison de service comme fonction de prédiction, et comme les assistants de connaissances produisent des traces MLflow complètes, y compris les portées de récupération, les juges intégrés peuvent inspecter à la fois les morceaux récupérés et la réponse finale.
Les juges LLM appellent un juge LLM via Databricks Model Serving. Nous avons utilisé databricks-claude-opus-4-6 :
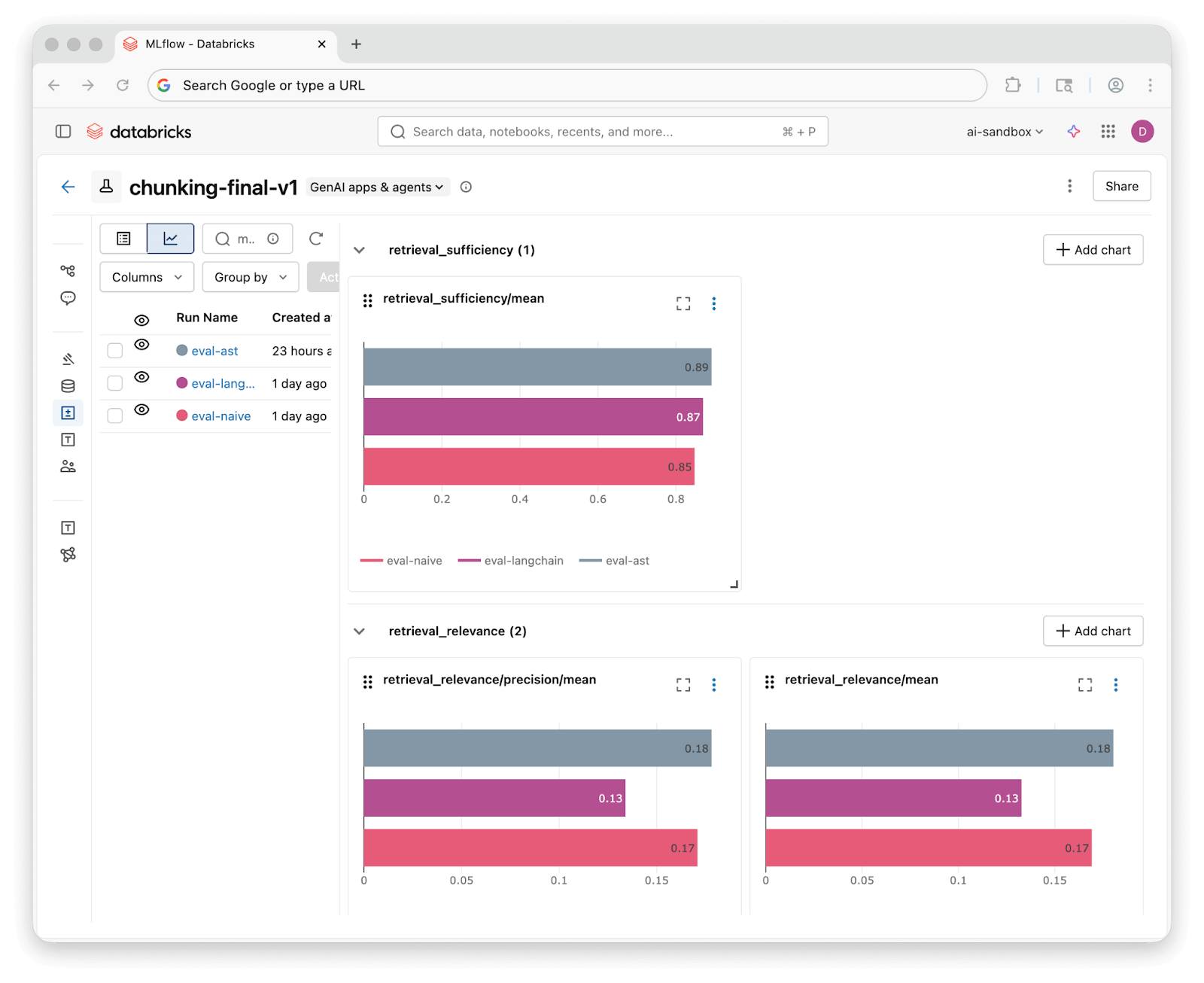
Une fois les exécutions d'évaluation terminées, l'interface utilisateur des expériences de MLflow vous permet de comparer les résultats de ces trois stratégies côte à côte :
Résultats et leçons apprises
Nous avons exécuté les 46 questions sur chaque assistant de connaissances et évalué les résultats avec nos trois juges. Voici ce que nous avons trouvé :
| Juge | Naïf | Diviseur Sensible à la Langue | AST |
|---|---|---|---|
| Suffisance de la récupération | 85% | 87% | 89% |
| Pertinence de la récupération | 76% | 72% | 76% |
| Exactitude de la réponse (personnalisée) | 59% entièrement correctes (37% partiel) | 61% entièrement correctes (37% partiel) | 70% entièrement correctes (28% partiel) |
Les trois stratégies atteignent une suffisance de récupération de 85 % et plus, ce qui signifie que les techniques de récupération de l'Assistant Connaissance trouvent le contexte pertinent, quelle que soit la manière dont le code a été découpé. Les différences au niveau de la récupération sont modestes.
Les résultats personnalisés de l'exactitude racontent une histoire plus intéressante. Le découpage basé sur l'AST produit une réponse entièrement correcte dans 70 % des cas, contre 59 % pour le Naïf et 61 % pour le Sensible à la Langue. Les trois stratégies produisent au moins une réponse partiellement correcte dans presque tous les cas. De meilleurs morceaux aident l'assistant de connaissance à répondre aux questions de manière plus complète.
L'avantage est concentré sur des types de questions spécifiques. Le découpage basé sur l'AST a excellé sur les questions de désambiguïsation, où du code structurellement similaire existe dans différents modules, grâce aux métadonnées préfixées (chemin du fichier, classe, nom de la fonction) fournissant le contexte nécessaire. Les trois stratégies étaient comparables pour la recherche de valeurs et la récupération de définitions complètes.
Les traces MLflow facilitent l'examen des questions individuelles et permettent de voir exactement quels morceaux ont été récupérés et où les réponses ont divergé :
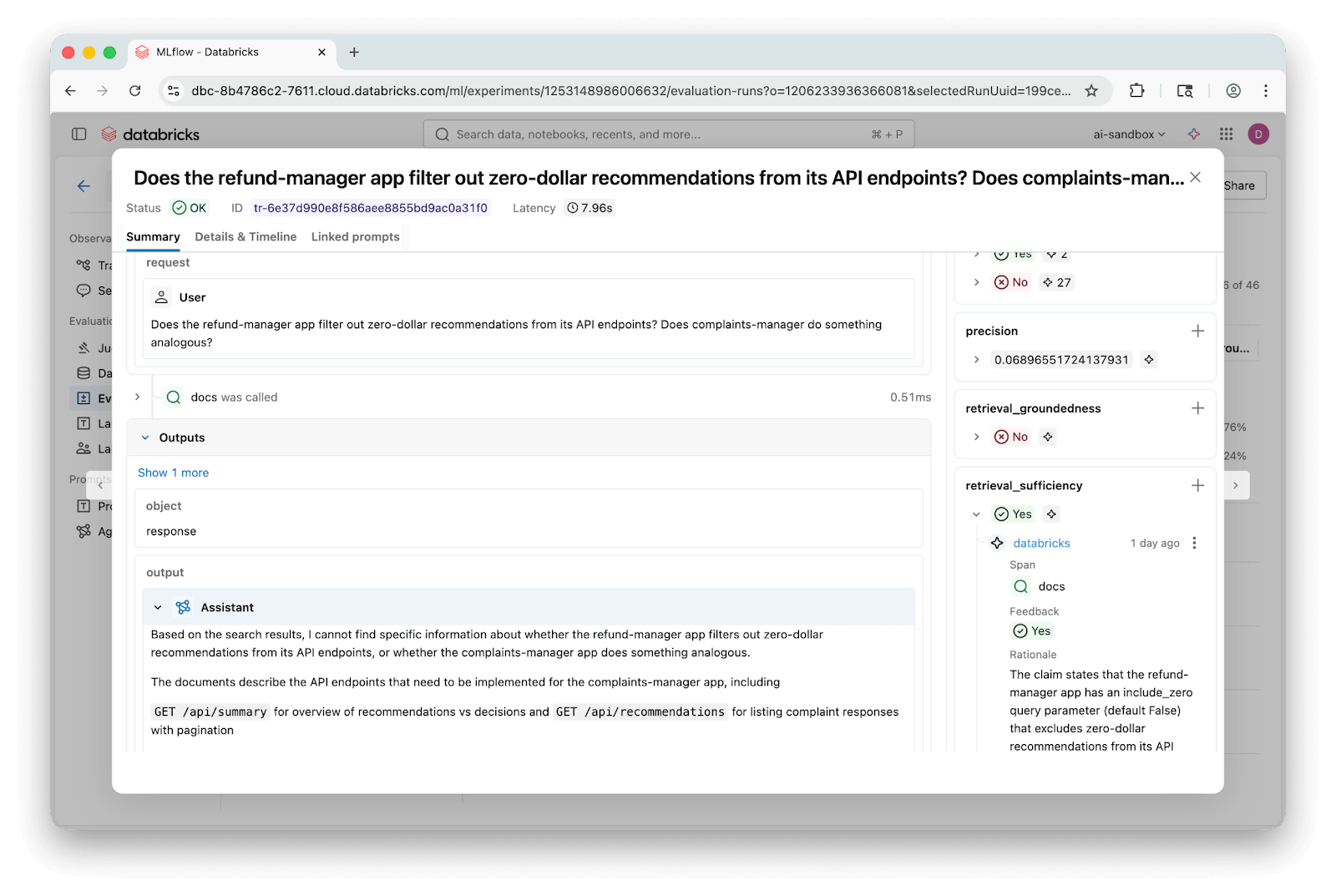
Cette investigation a laissé quelques questions sans réponse : les améliorations que nous avons constatées avec le découpage basé sur l'AST étaient-elles principalement une conséquence des tailles moyennes de morceaux plus importantes ? Dans quelle mesure les résultats dépendaient-ils du choix du modèle alimentant les juges LLM ? Nos questions d'évaluation ont-elles manqué des catégories majeures que les utilisateurs réels poseraient ?
Leçons Apprises
Databricks Knowledge Assistant est très performant dès le départ. La suffisance de la récupération était élevée pour les trois stratégies, et presque toutes les questions ont reçu au moins une réponse partiellement correcte.
La préparation des données reste importante. Le découpage basé sur l'AST a amélioré la pertinence et l'exactitude dans cette évaluation, en particulier pour les questions impliquant la désambiguïsation de code similaire. Même des améliorations marginales de la récupération et de la qualité des réponses se composent pour une équipe de développeurs posant des dizaines de questions par jour.
Les juges LLM personnalisés aident à mesurer ce qui nous importe vraiment. L'API make_judge() de MLflow facilite la création de juges LLM spécifiques à un cas d'utilisation. Notre juge personnalisé answer_correctness a pu donner une vision plus nuancée de l'exactitude qu'un simple juge d'exactitude avec succès/échec.
Les traces MLflow simplifient la boucle d'évaluation. Vous pouvez examiner des questions individuelles pour voir exactement quels morceaux ont été récupérés et où la réponse a échoué. Comme les traces persistent, vous pouvez re-noter avec différents juges sans re-interroger le point de terminaison.
Références
- Databricks Agent Bricks : Assistant Connaissance—Guide d'installation pour créer un Assistant Connaissance avec des index de recherche vectorielle personnalisés.
- Framework d'évaluation GenAI de MLflow—Documentation pour
mlflow.genai.evaluate(), les juges LLM intégrés et l'API de score personnalisé. - cAST : Amélioration de la génération augmentée par récupération de code avec découpage structurel via l'arbre de syntaxe abstraite—L'article qui a motivé notre approche de découpage AST, avec des benchmarks sur plusieurs tâches de RAG de code. Nous avons utilisé l'implémentation de la bibliothèque Python ASTChunk.
- LangChain
RecursiveCharacterTextSplitter—Référence API pour le diviseur de texte sensible à la langue que nous avons utilisé dans la comparaison.
Essayez par Vous-Même
Vous pouvez suivre cette démo dans le dépôt Casper’s Kitchens. Que vous évaluiez des stratégies de découpage pour votre propre base de code ou que vous exploriez d'autres améliorations RAG, ce framework d'évaluation vous offre un moyen reproductible de comparer les approches.
- Créez un jeu de données d'évaluation avec des questions et des réponses attendues.
- Implémentez des stratégies de découpage (ou utilisez les nôtres comme points de départ).
- Configurez les juges LLM MLflow — commencez par les options intégrées et ajoutez-en des personnalisées au fur et à mesure que vous identifiez des lacunes.
- Exécutez les évaluations avec des index frais pour chaque stratégie.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.