Instructed Retriever : Activer le raisonnement au niveau du système dans les agents de recherche
Les agents basés sur la recherche sont au cœur de nombreux cas d'usage critiques en entreprise. Les clients attendent d'eux qu'ils effectuent des tâches de raisonnement qui nécessitent de suivre des instructions utilisateur spécifiques et de fonctionner efficacement sur des sources de connaissances hétérogènes. Cependant, le plus souvent, la génération augmentée par la recherche (RAG) traditionnelle ne parvient pas à traduire l'intention précise de l'utilisateur et les spécifications des sources de connaissances en requêtes de recherche précises. La plupart des solutions existantes ignorent ce problème, en utilisant des outils de recherche prêts à l'emploi. D'autres sous-estiment considérablement le défi, en s'appuyant uniquement sur des modèles personnalisés pour l'embedding et le reranking, qui sont fondamentalement limités dans leur expressivité. Dans ce blog, nous présentons l'Instructed Retriever, une nouvelle architecture de recherche qui répond aux limites de RAG et réinvente la recherche pour l'ère des agents. Nous illustrons ensuite comment cette architecture permet de créer des agents basés sur la recherche plus performants, y compris des systèmes comme Agent Bricks: Knowledge Assistant, qui doivent raisonner sur des données d'entreprise complexes et respecter strictement les instructions de l'utilisateur.
Par exemple, prenons l'exemple de la figure 1, où un utilisateur pose une question sur l'autonomie de la batterie d'un produit fictif FooBrand. De plus, les spécifications du système incluent des instructions sur la récence, les types de documents à prendre en compte et la longueur de la réponse. Pour suivre correctement les spécifications du système, la requête de l'utilisateur doit d'abord être traduite en requêtes de recherche structurées qui contiennent les filtres de colonne appropriés en plus des mots-clés. Ensuite, une réponse concise basée sur les résultats de la requête doit être générée en fonction des instructions de l'utilisateur. Un suivi d'instructions aussi complexe et délibéré n'est pas réalisable par un simple pipeline qui se concentre uniquement sur la requête de l'utilisateur.
![Figure 1. Exemple de workflow d'extraction sur instructions pour la query [Quelle est l'espérance de vie de la batterie des produits FooBrand]. Les instructions de l'utilisateur sont traduites en (a) deux requêtes d'extraction structurées, extrayant à la fois les avis récents et une description officielle du produit, (b) une réponse courte, basée sur les résultats de recherche.](https://www.databricks.com/sites/default/files/inline-images/image7_24.png)
Les pipelines RAG traditionnels reposent sur une récupération en une seule étape en utilisant uniquement la query de l'utilisateur et n'intègrent pas de spécifications système supplémentaires telles que des instructions spécifiques, des exemples ou des schémas de source de connaissances. Cependant, comme nous le montrons dans la Figure 1, ces spécifications sont essentielles pour le bon suivi des instructions dans les systèmes de recherche agentiques. Pour surmonter ces limites et accomplir avec succès des tâches telles que celle décrite dans la Figure 1, notre architecture Instructed Retriever permet la transmission des spécifications du système à chacun de ses composants.
Même au-delà de RAG, dans les systèmes de recherche agentiques plus avancés qui permettent une exécution itérative de la recherche, le suivi des instructions et la compréhension du schéma de la source de connaissances sous-jacente sont des capacités clés qui ne peuvent pas être obtenues en exécutant simplement RAG comme un outil en plusieurs étapes, comme l'illustre le Tableau 1. Ainsi, l'architecture Instructed Retriever fournit une alternative très performante à RAG, lorsqu'une faible latence et une faible empreinte du modèle sont requises, tout en permettant des agents de recherche plus efficaces pour des scénarios tels que la recherche approfondie.
Génération augmentée de récupération (RAG) | Retriever Instruit | Agent multi-étapes (RAG) | Agent multi-étapes (Retriever instruit) | |
Nombre d'étapes de recherche | Unique | Unique | Multiple | Multiple |
Capacité à suivre les instructions | ✖️ | ✅ | ✖�️ | ✅ |
Compréhension de la source de connaissances | ✖️ | ✅ | ✖️ | ✅ |
Faible latence | ✅ | ✅ | ✖️ | ✖️ |
Faible empreinte du modèle | ✅ | ✅ | ✖️ | ✖️ |
Raisonnement sur les sorties | ✖️ | ✖️ | ✅ | ✅ |
Tableau 1. Un résumé des capacités du RAG traditionnel, de l'Instructed Retriever et d'un agent de recherche multi-étapes mis en œuvre en utilisant l'une ou l'autre de ces approches comme outil
Pour démontrer les avantages de l'Instructed Retriever, la Figure 2 présente ses performances par rapport aux modèles de référence basés sur RAG sur une suite d'ensembles de données de questions-réponses d'entreprise1. Sur ces points de référence complexes, l'Instructed Retriever améliore les performances de plus de 70 % par rapport à un RAG traditionnel. L'Instructed Retriever surpasse même un agent multi-étapes basé sur RAG de 10 %. L'intégrer en tant qu'outil dans un agent multi-étapes apporte des gains supplémentaires, tout en réduisant le nombre d'étapes d'exécution par rapport au RAG.
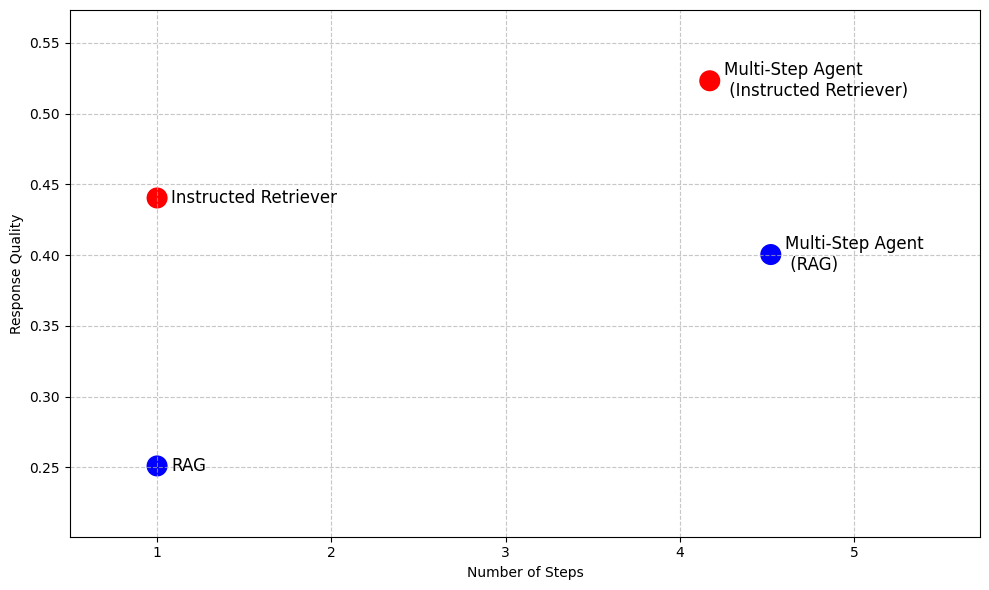
Dans la suite de ce billet de blog, nous abordons la conception et l'implémentation de cette nouvelle architecture de Retriever Instruit. Nous démontrons que l'Instructed Retriever permet un suivi précis et robuste des instructions à l'étape de la génération de query, ce qui se traduit par des améliorations significatives du rappel de recherche. De plus, nous montrons que ces capacités de génération de queries peuvent être débloquées même dans des modèles de petite taille grâce à l'apprentissage par renforcement hors ligne. Enfin, nous décomposons plus en détail les performances de bout en bout de l'Instructed Retriever, à la fois dans des configurations agentiques à une seule étape et à plusieurs étapes. Nous montrons qu'il permet d'améliorer de manière significative et constante la qualité des réponses par rapport aux architectures RAG traditionnelles.
Architecture de Retriever Instruit
Pour relever les défis du raisonnement au niveau du système dans les systèmes de recherche agentiques, nous proposons une nouvelle architecture Instructed Retriever, illustrée à la figure 3. L'Instructed Retriever peut être appelé dans un flux de travail statique ou exposé comme un outil à un agent. L'innovation clé est que cette nouvelle architecture offre un moyen simplifié non seulement de traiter la requête immédiate de l'utilisateur, mais aussi de propager l'intégralité des spécifications du système aux composants du système de recherche et de génération. Il s'agit d'un changement fondamental par rapport aux pipelines RAG traditionnels, où les spécifications du système peuvent (au mieux) influencer la requête initiale, mais sont ensuite perdues, forçant le retriever et le générateur de réponses à fonctionner sans le contexte vital de ces spécifications.
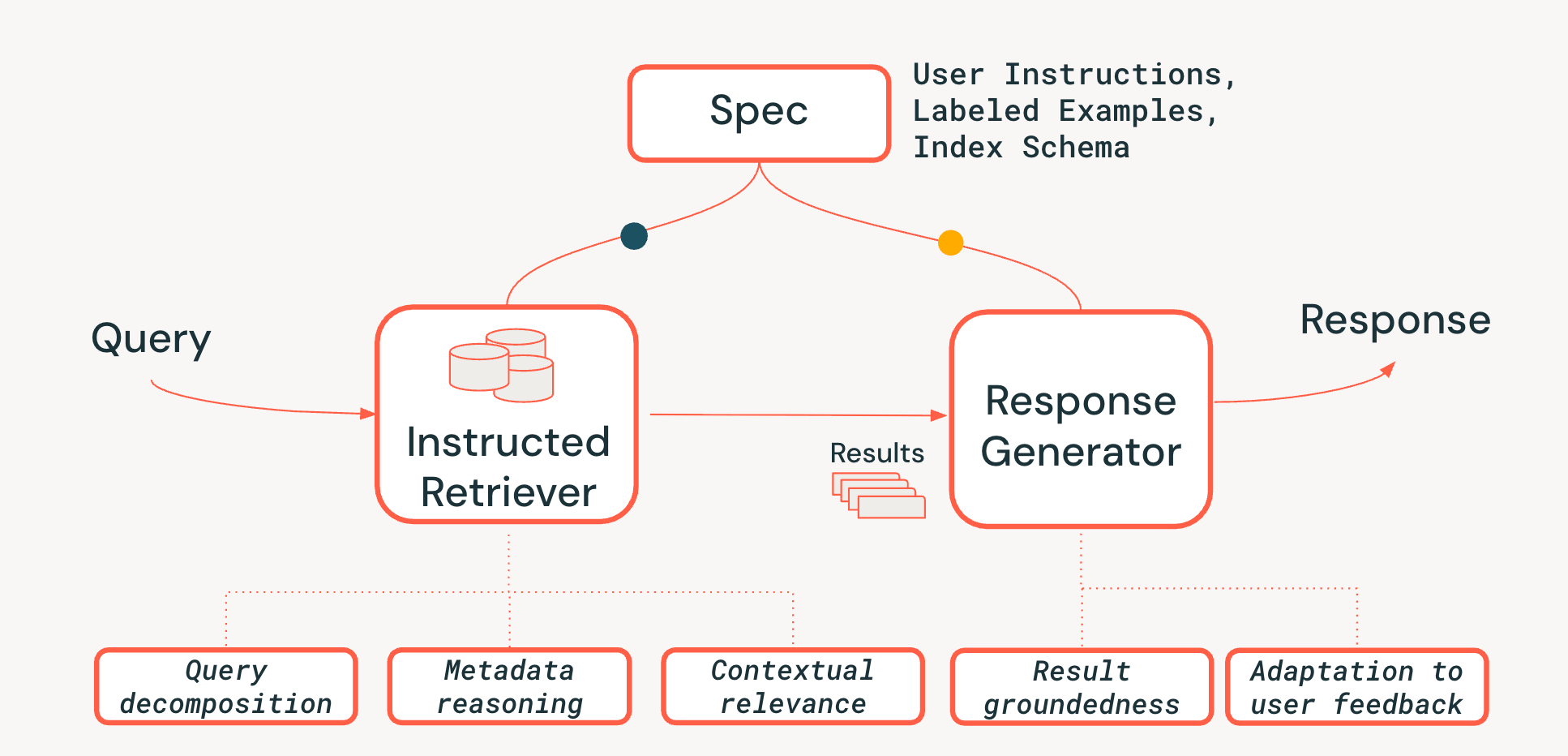
Les spécifications système sont donc un ensemble de principes directeurs et d'instructions que l'agent doit suivre pour répondre fidèlement à la demande de l'utilisateur, pouvant inclure :
- Instructions utilisateur : Préférences générales ou contraintes, comme "se concentrer sur les avis des dernières années" ou "Ne pas afficher de produits FooBrand dans les résultats".
- Exemples étiquetés : des échantillons concrets de paires <query, document> pertinentes/non pertinentes qui aident à définir ce à quoi ressemble une recherche de haute qualité qui suit les instructions pour une tâche spécifique.
- Descriptions de l'index : Un schéma qui indique à l'agent quelles métadonnées sont réellement disponibles à extraire (par ex., product_brand, doc_timestamp, dans l'exemple de la Figure 1).2
Pour assurer la persistance des spécifications tout au long du pipeline, nous ajoutons trois fonctionnalités essentielles au processus de recherche :
- Décomposition de la query : Capacité à décomposer une requête complexe en plusieurs parties ("Trouvez-moi un produit FooBrand, mais uniquement de l'année dernière, et pas un modèle « lite »") en un plan de recherche complet, contenant plusieurs recherches par mots-clés et des instructions de filtrage.
- Pertinence contextuelle : Aller au-delà de la simple similarité textuelle pour une véritable compréhension de la pertinence dans le contexte de la query et des instructions du système. Cela signifie que le reclasseur, par exemple, peut utiliser les instructions pour valoriser les documents qui correspondent à l'intention de l'utilisateur (par exemple, la « récence»), même si les mots-clés correspondent moins bien.
- Raisonnement sur les métadonnées : L'un des principaux différenciateurs de notre architecture Instructed Retriever est sa capacité à traduire des instructions en langage naturel ("de l'année dernière") en filtres de recherche précis et exécutables ("doc_timestamp > TO_TIMESTAMP('2024-11-01')").
Nous nous assurons également que l'étape de génération de réponses est cohérente avec les résultats extraits, les spécifications du système et l'historique ou les retours précédents de l'utilisateur (comme décrit plus en détail dans ce blog).
Le respect des instructions dans les agents de recherche est un défi, car les besoins d'information des utilisateurs peuvent être complexes, vagues, voire contradictoires, souvent accumulés au fil de nombreuses séries de retours en langage naturel. Le retriever doit également être conscient du schéma — c'est-à-dire capable de traduire le langage de l'utilisateur en filtres, champs et métadonnées structurés qui existent réellement dans l'index. Enfin, les composants doivent fonctionner ensemble de manière transparente pour satisfaire ces contraintes complexes, parfois à plusieurs niveaux, sans en omettre ou en mal interpréter aucune. Une telle coordination nécessite un raisonnement holistique au niveau du système. Comme le démontrent nos expérimentations dans les deux sections suivantes, l'architecture Instructed Retriever constitue une avancée majeure pour débloquer cette capacité dans les workflows et les agents de recherche.
Évaluation du suivi des instructions dans la génération de requêtes
La plupart des benchmarks de recherche d'informations existants ne tiennent pas compte de la manière dont les modèles interprètent et exécutent les spécifications en langage naturel, en particulier celles qui impliquent des contraintes structurées basées sur le schéma d'index. C'est pourquoi, pour évaluer les capacités de notre architecture de Retriever Instruit, nous avons étendu le jeu de données StaRK (Semi-Structured Retrieval Benchmark) et conçu un nouveau benchmark de recherche suivant des instructions, StaRK-Instruct, en utilisant son sous-ensemble de e-commerce, STaRK-Amazon.
Pour notre dataset, nous nous concentrons sur trois types courants d'instructions utilisateur qui exigent que le modèle raisonne au-delà de la simple similarité textuelle :
- Instructions d'inclusion – sélectionner les documents qui doivent contenir un certain attribut (p. ex., « trouvez une veste de la marque FooBrand la mieux notée par temps froid »).
- Instructions d'exclusion – filtrer les éléments qui ne doivent pas apparaître dans les résultats (par ex., « recommandez-moi un SUV économe en carburant, mais j'ai eu de mauvaises expériences avec FooBrand, alors évitez tous leurs produits »).
- Renforcement de la récence – préférer les éléments plus récents lorsque des métadonnées temporelles sont disponibles (par ex., « Quels ordinateurs portables FooBrand ont bien vieilli ? Donnez la priorité aux avis des 2 à 3 dernières années — les avis plus anciens sont moins pertinents en raison des changements d'OS »).
Pour construire StaRK-Instruct, tout en pouvant réutiliser les jugements de pertinence existants de StaRK-Amazon, nous nous appuyons sur des travaux antérieurs sur le suivi d'instructions en recherche d'information, et synthétisons les requêtes existantes en requêtes plus spécifiques en incluant des contraintes supplémentaires qui affinent les définitions de pertinence existantes. Les ensembles de documents pertinents sont ensuite filtrés par programme pour garantir l'alignement avec les requêtes réécrites. Grâce à ce processus, nous avons synthétisé 81 requêtes StaRK-Amazon (19,5 documents pertinents par requête) en 198 requêtes dans StaRK-Instruct (11,7 documents pertinents par requête, pour les trois types d'instructions).
Pour évaluer les capacités de génération de requêtes d'Instructed Retriever à l'aide de StaRK-Instruct, nous évaluons les méthodes suivantes (dans une configuration de recherche en une seule étape).
- Requête brute – comme référence, nous utilisons la requête utilisateur d'origine pour la recherche, sans aucune étape supplémentaire de génération de requêtes. Cela s'apparente à une approche RAG traditionnelle.
- GPT5-nano, GPT5.2, Claude4.5-Sonnet – nous utilisons chacun des modèles respectifs pour générer une query, en utilisant à la fois les queries utilisateur originales, les spécifications du système, y compris les instructions utilisateur, et le schéma d'index.
- InstructedRetriever-4B – Bien que les modèles de pointe comme GPT5.2 et Claude4.5-Sonnet soient très efficaces, ils peuvent aussi être trop coûteux pour des tâches comme la génération de requêtes et de filtres, en particulier pour les déploiements à grande échelle. Par conséquent, nous appliquons le mécanisme Test-time Adaptive Optimization (TAO), qui s'appuie sur le calcul au moment du test et l'apprentissage par renforcement hors ligne (RL) pour apprendre à un modèle à mieux effectuer une tâche en se basant sur des exemples d'entrées passés. Plus précisément, nous utilisons le sous-ensemble de requêtes « synthétisées » de StaRK-Amazon, et générons des requêtes de suivi d'instructions supplémentaires à l'aide de ces requêtes synthétisées. Nous utilisons directement le rappel comme signal de récompense pour affiner un petit modèle de 4 milliards de paramètres, en échantillonnant des appels d'outils candidats et en renforçant ceux qui obtiennent des scores de rappel plus élevés.
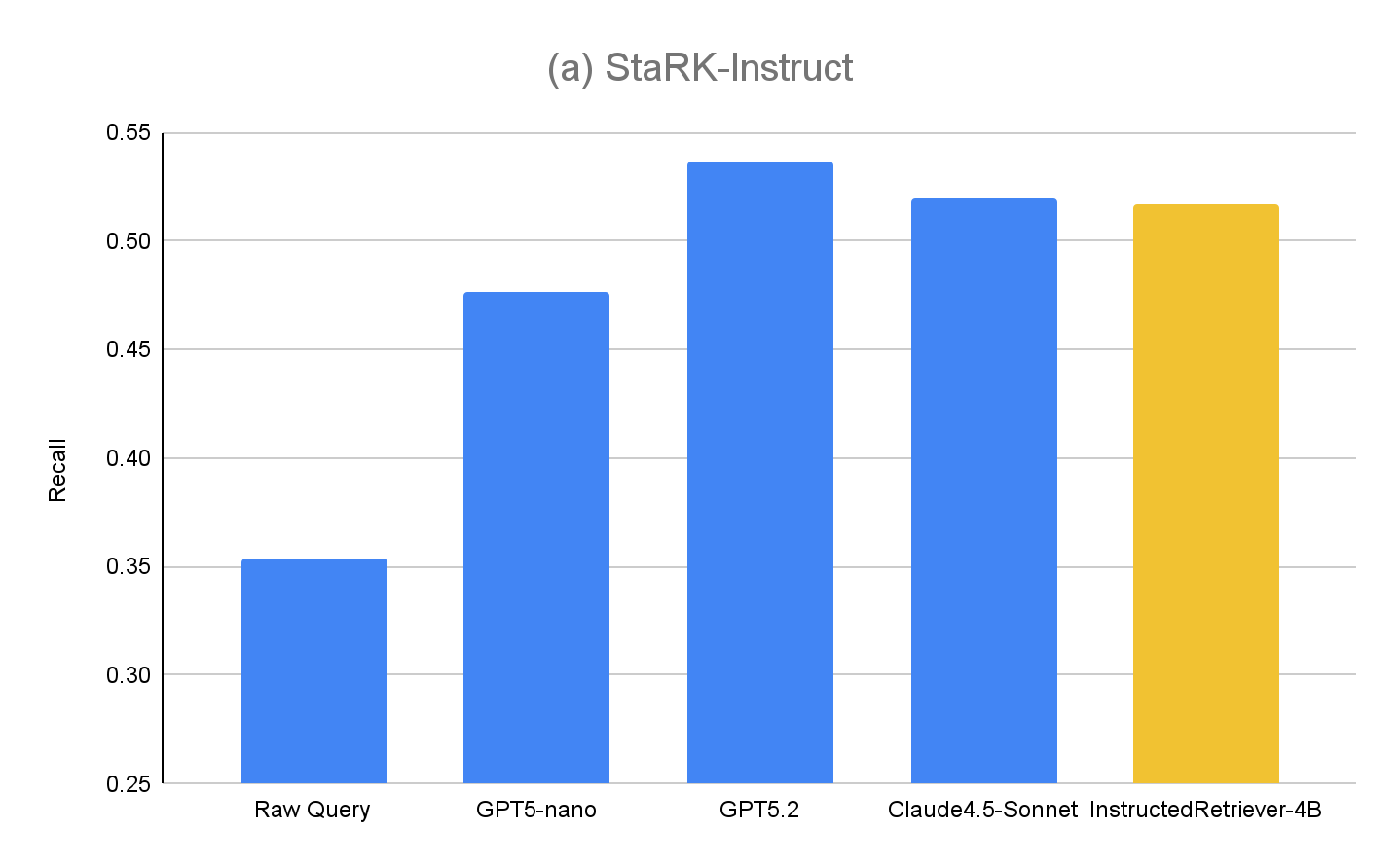
Les résultats pour StaRK-Instruct sont présentés à la figure 4(a). La génération de requêtes avec instructions atteint un rappel de35 à 50 % supérieur sur le benchmark StaRK-Instruct par rapport à la référence Raw query. Les gains sont constants quelle que soit la taille des modèles, ce qui confirme qu'une analyse efficace des instructions et une formulation de requêtes structurées peuvent apporter des améliorations mesurables, même avec des budgets de calcul serrés. Les modèles plus grands présentent généralement des gains encore plus importants, ce qui suggère l'évolutivité de l'approche avec la capacité du modèle. Cependant, notre modèle affiné InstructedRetriever-4B atteint presque les performances de modèles de pointe beaucoup plus grands et surpasse le modèle GPT5-nano, ce qui démontre que l'alignement peut améliorer considérablement l'efficacité du suivi des instructions dans les systèmes de recherche agentiques, même avec des modèles plus petits.
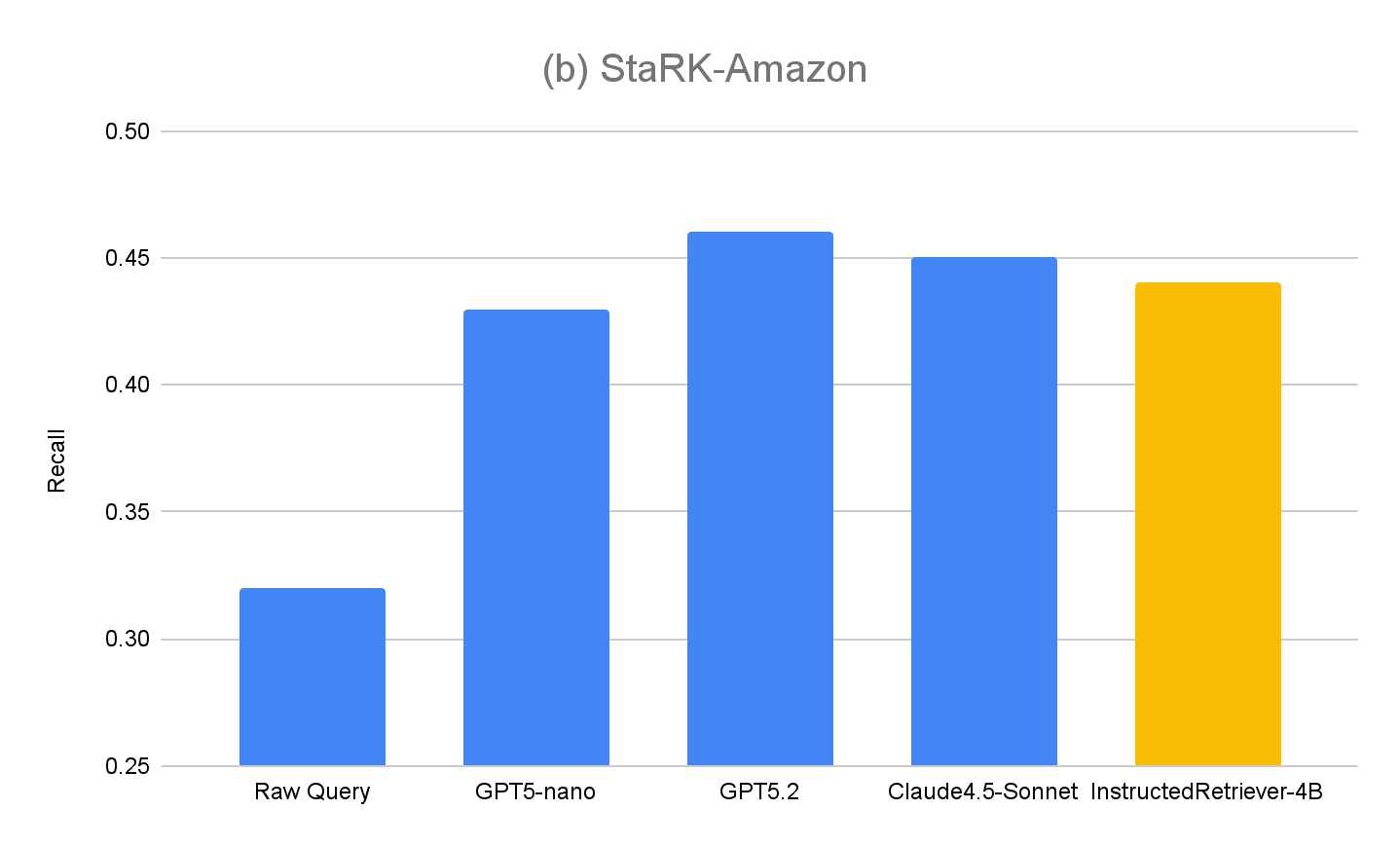
Pour évaluer plus en détail la généralisation de notre approche, nous mesurons également les performances sur l' ensemble d'évaluation d'origine, StaRK-Amazon, où les requêtes ne contiennent pas d'instructions explicites liées aux métadonnées. Comme le montre la figure 4(b), toutes les méthodes de génération de requêtes guidées par instructions dépassent le rappel de Raw Query sur StaRK-Amazon d'environ 10 %, ce qui confirme que le suivi d'instructions est également bénéfique dans les scénarios de génération de requêtes non contraints. Nous ne constatons également aucune dégradation des performances d'InstructedRetriever-4B par rapport aux modèles non affinés, ce qui confirme que la spécialisation dans la génération de requêtes structurées ne nuit pas à ses capacités générales de génération de requêtes.
Déploiement de Retriever instruit dans Agent Bricks
Dans la section précédente, nous avons démontré les gains significatifs en matière de qualité de recherche qui peuvent être obtenus grâce à la génération de requêtes qui suivent des instructions. Dans cette section, nous explorons plus en détail l'utilité d'un retriever instruit en tant que partie d'un système de recherche agentique de niveau production. En particulier, Instructed Retriever est déployé dans l'assistant de connaissances Agent Bricks, un chatbot de questions-réponses (QA) auquel vous pouvez poser des questions et recevoir des réponses fiables basées sur les connaissances spécialisées fournies.
Nous considérons deux solutions RAG « maison » comme modèles de référence :
- RAG Nous transmettons les meilleurs résultats extraits de notre recherche vectorielle très performante à un grand modèle de langage de pointe pour la génération.
- RAG + Rerank Nous faisons suivre l'étape de recherche d'une étape de reranking, qui a permis d'augmenter la précision de la recherche de 15 points de pourcentage en moyenne lors de tests antérieurs. Les résultats rerankés sont fournis à un grand modèle de langage de pointe pour la génération.
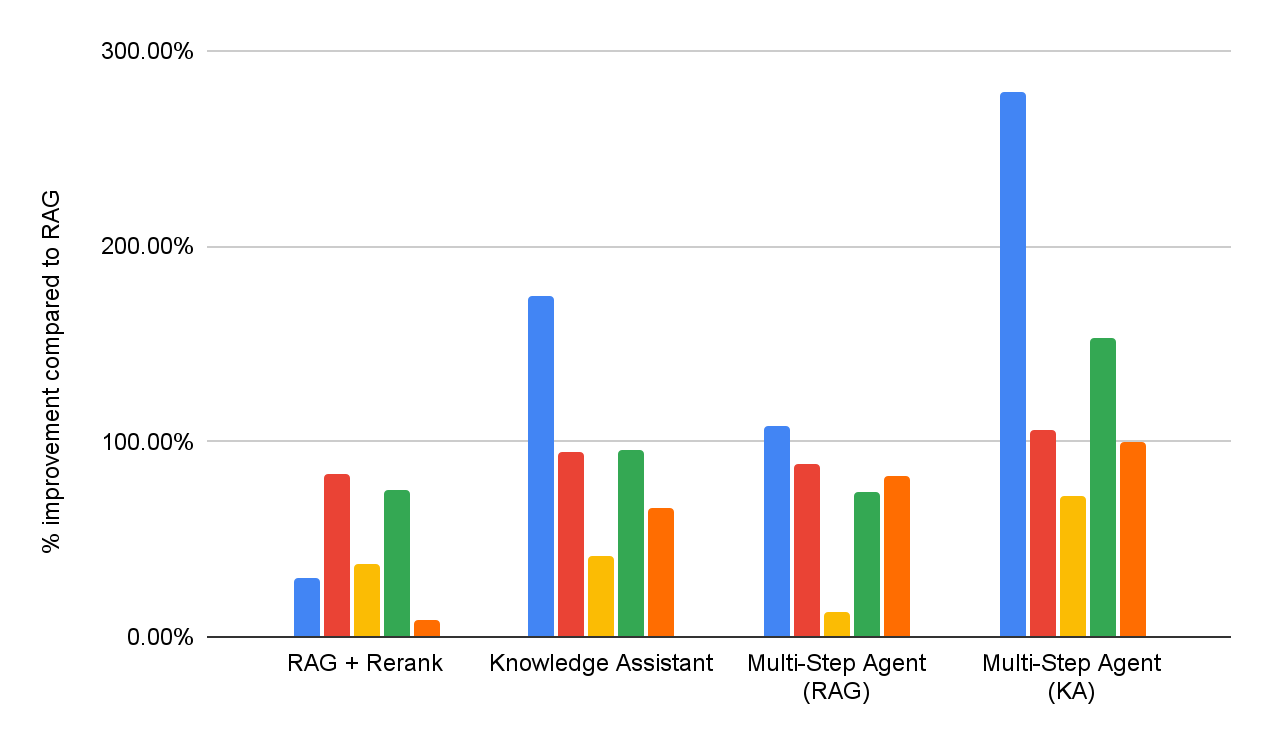
Pour évaluer l'efficacité des solutions DIY RAG et de Knowledge Assistant, nous effectuons une évaluation de la qualité des réponses sur la même suite de benchmarks de questions-réponses d'entreprise que celle présentée à la figure 1. De plus, nous implémentons deux agents à plusieurs étapes qui ont respectivement accès à RAG ou à Knowledge Assistant comme outil de recherche. Les performances détaillées pour chaque dataset sont présentées à la figure 5 (en pourcentage d'amélioration par rapport à la référence RAG).
Dans l'ensemble, nous pouvons constater que tous les systèmes surpassent systématiquement la référence RAG simple sur tous les datasets, reflétant son incapacité à interpréter et à appliquer de manière cohérente les spécifications en plusieurs parties. L'ajout d'une étape de reclassement améliore les résultats, démontrant un certain avantage de la modélisation de la pertinence post-hoc. Knowledge Assistant, implémenté à l'aide de l'architecture Instructed Retriever, apporte de nouvelles améliorations, ce qui souligne l'importance de conserver les spécifications du système (contraintes, exclusions, préférences temporelles et filtres de métadonnées) à chaque étape de la recherche et de la génération.
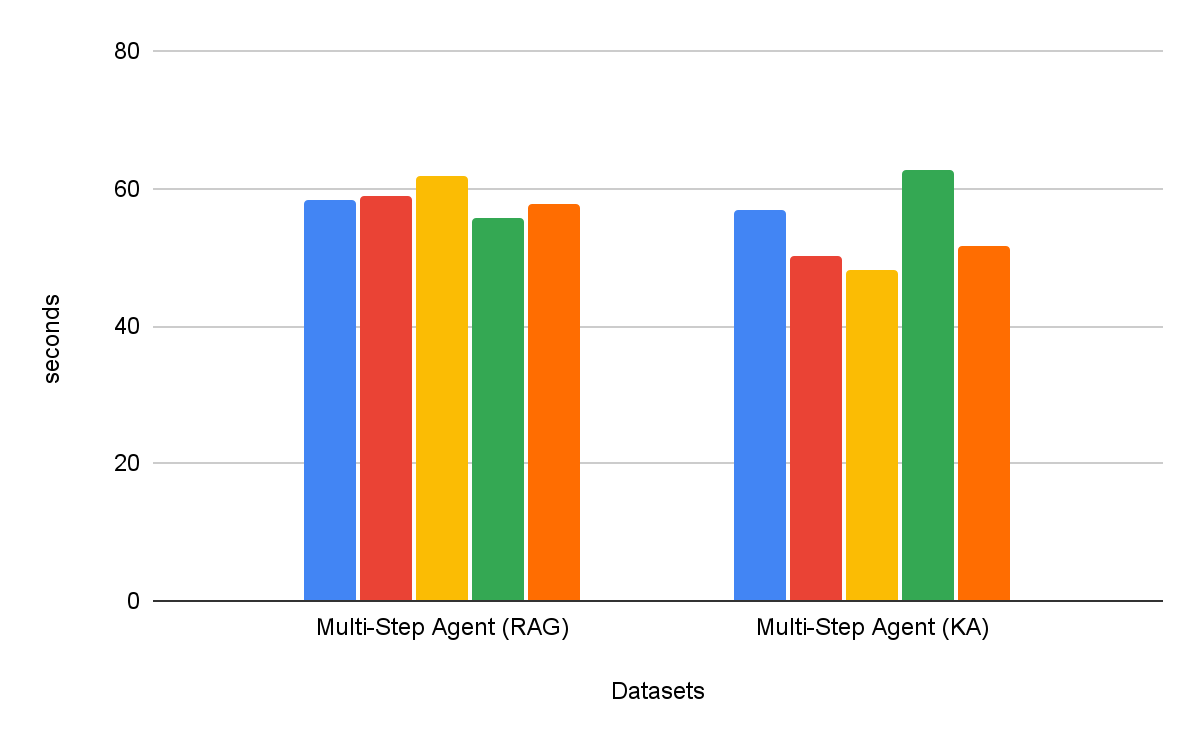
Les agents de recherche multi-étapes sont systématiquement plus efficaces que les workflows d'extraction en une seule étape. De plus, le choix de l'outil est important – Knowledge Assistant en tant qu'outil surpasse RAG en tant qu'outil de plus de 30 %, avec une amélioration constante sur tous les datasets. Fait intéressant, il n'améliore pas seulement la qualité, mais il réduit également le temps de réalisation des tâches sur la plupart des datasets, avec une réduction moyenne de 8 % (Figure 6).
Conclusion
La création d'agents d'entreprise fiables nécessite un suivi complet des instructions et un raisonnement au niveau du système lors de la récupération à partir de sources de connaissances hétérogènes. À cette fin, dans ce blog, nous présentons l'architecture Instructed Retriever, dont l'innovation principale consiste à propager des spécifications système complètes — des instructions aux exemples et au schéma d'index — à travers chaque étape du pipeline de recherche.
Nous avons également présenté un nouveau StaRK-Instruct dataset, qui évalue la capacité d'un agent de recherche à gérer des instructions du monde réel telles que l'inclusion, l'exclusion et la récence. Sur ce benchmark, l'architecture Instructed Retriever a permis des gains substantiels de 35 à 50 % en rappel de recherche, démontrant de manière empirique les avantages d'une prise en compte des instructions à l'échelle du système pour la génération de queries. Nous montrons également qu'un modèle petit et efficace peut être optimisé pour égaler les performances de suivi des instructions de modèles propriétaires plus grands, faisant d'Instructed Retriever une architecture agentique rentable et adaptée aux déploiements en entreprise dans le monde réel.
Une fois intégrée à un Agent Bricks Knowledge Assistant, l'architecture Instructed Retriever se traduit directement par des réponses de meilleure qualité et plus précises pour l'utilisateur final. Sur notre suite complète de benchmarks de haute difficulté, elle permet des gains supérieurs à 70 % par rapport à une solution RAG simpliste, et une amélioration de la qualité de plus de 15 % par rapport à des solutions DIY plus sophistiquées qui intègrent le reclassement. De plus, lorsqu'il est intégré comme outil pour un agent de recherche multi-étapes, Instructed Retriever peut non seulement améliorer les performances de plus de 30 %, mais aussi réduire le temps d'exécution des tâches de 8 %, par rapport à l'utilisation de RAG comme outil.
Instructed Retriever, ainsi que de nombreuses innovations publiées précédemment comme l'optimisation des prompts, ALHF, TAO et RLVR, est désormais disponible dans le produit Agent Bricks. Le principe fondamental d'Agent Bricks est d'aider les entreprises à développer des agents qui raisonnent avec précision sur leurs données propriétaires, apprennent en continu à partir des retours et atteignent une qualité et une rentabilité de pointe sur des tâches spécifiques à un domaine. Nous encourageons nos clients à essayer l'Assistant de connaissances et d'autres produits Agent Bricks pour construire des agents pilotables et efficaces pour leurs propres cas d'usage en entreprise.
Auteurs : Cindy Wang, Andrew Drozdov, Michael Bendersky, Wen Sun, Owen Oertell, Jonathan Chang, Jonathan Frankle, Xing Chen, Matei Zaharia, Elise Gonzales, Xiangrui Meng
1 Notre suite contient un mélange de cinq benchmarks propriétaires et académiques qui testent les capacités suivantes : le suivi d'instructions, la recherche spécifique à un domaine, la génération de rapports, la génération de listes et la recherche dans des PDF aux Layouts complexes. Chaque benchmark est associé à un évaluateur de qualité personnalisé, basé sur le type de réponse.
2 Les descriptions d'index peuvent être incluses dans l'instruction spécifiée par l'utilisateur, ou construites automatiquement via des méthodes de liaison de schémas souvent employées dans les systèmes de text-to-SQL, p. ex. pour l'extraction de valeurs.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.