La convergence des formats de table ouverts et des catalogues ouverts : Catalog Commits est généralement disponible
Les validations de catalogue sont la prochaine évolution du lakehouse ouvert
par Benjamin Mathew, Michelle Leon, Lukas Rupprecht et Ryan Johnson
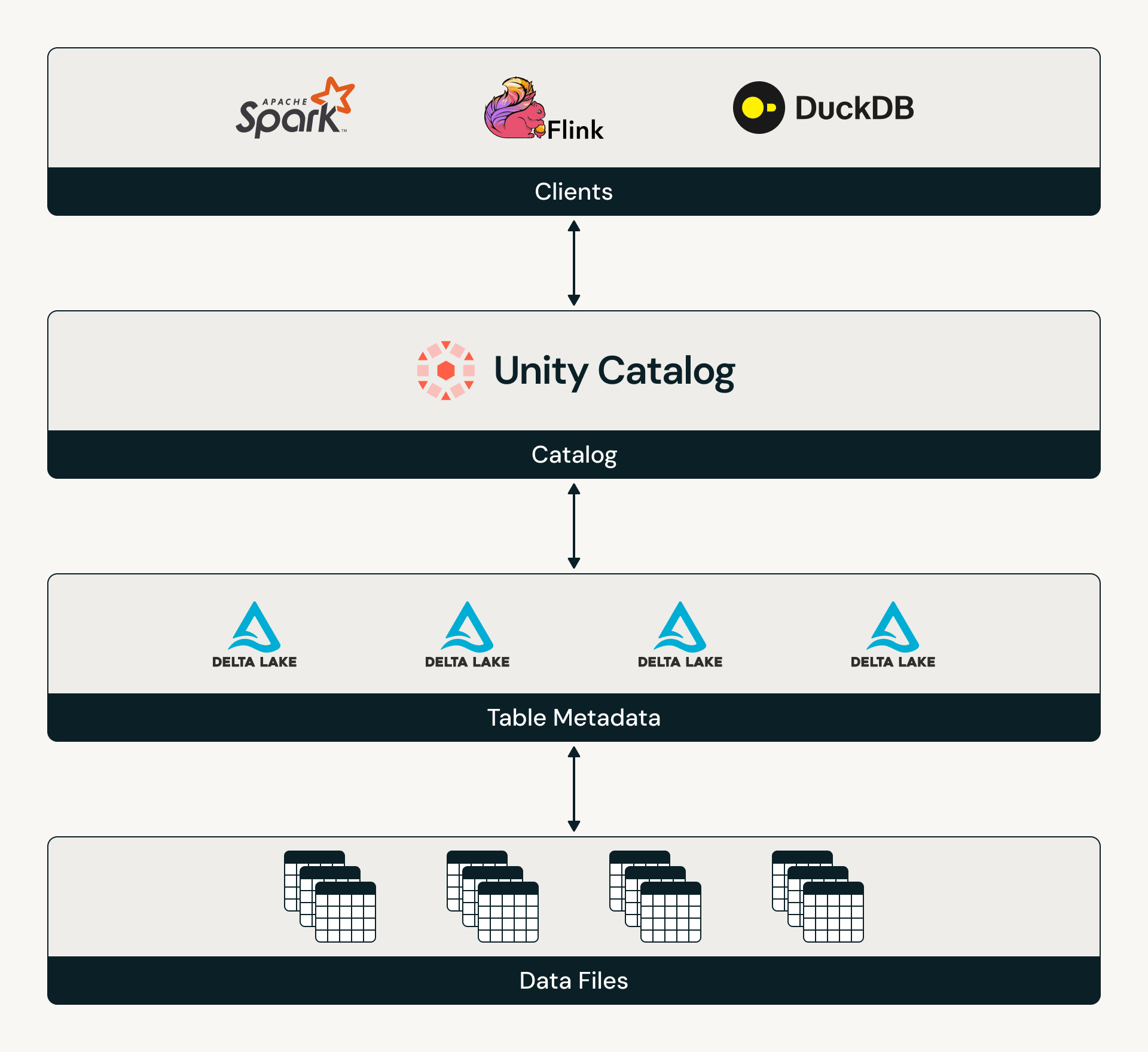
Catalog Commits fait un grand pas vers l'unification du lakehouse en alignant Delta sur le modèle orienté catalogue d'Iceberg. Avec Catalog Commits, les catalogues deviennent le système de coordination pour les tables Delta, gérant la découverte, l'accès et l'état des tables entre les moteurs.
Aujourd'hui, nous sommes ravis d'annoncer la Disponibilité Générale de Catalog Commits pour les tables gérées UC. Il s'agit d'une mise à niveau majeure de la plateforme qui étend l'interopérabilité des tables gérées UC, renforce les capacités de gouvernance d'UC et débloque de nouvelles fonctionnalités, notamment les transactions multi-instructions et multi-tables.
Dans ce blog, nous aborderons…
- Comment Delta et Unity Catalog co-évoluent
- Les problèmes que Catalog Commits résout
- Comment fonctionne Catalog Commits
- Comment activer Catalog Commits sur les tables gérées Unity Catalog
L'évolution de Delta Lake et Unity Catalog
Lorsque Delta Lake a été créé, le lakehouse avait d'abord besoin de transactions fiables sur le stockage cloud ouvert. À l'époque, les catalogues n'étaient pas conçus pour coordonner les charges de travail de données modernes, alors Delta a fait un choix architectural révolutionnaire : il a apporté les garanties ACID directement aux systèmes de fichiers du data lake. Cette base a rendu le lakehouse possible.
Alors que le lakehouse devenait le système d'enregistrement pour de plus en plus d'équipes, de moteurs et de charges de travail d'IA, le besoin d'une gouvernance unifiée à travers ces différents actifs est devenu essentiel. Unity Catalog a fourni cette couche de gouvernance manquante : un endroit unique pour découvrir, sécuriser, auditer et coordonner l'accès aux données et aux actifs d'IA à travers les clouds, les formats et les moteurs.
Ensemble, Delta Lake et Unity Catalog ont formé la base du lakehouse moderne. Cependant, ils fonctionnaient côte à côte - Delta gérant l'état transactionnel au niveau de la couche de stockage, et Unity Catalog gouvernant l'accès au niveau de la couche de catalogue. Cette architecture était suffisante au début, mais à mesure que les organisations évoluaient sur plus de moteurs et de charges de travail, cette conception a entraîné de nouveaux défis de coordination.
Les défis actuels de coordination entre les tables et les catalogues
L'architecture originale orientée système de fichiers de Delta était puissante pour apporter des transactions aux data lakes, mais elle n'a pas été conçue pour un monde où le catalogue doit coordonner de manière cohérente l'identité, l'accès et l'état des tables sur de nombreux moteurs. Alors que les organisations imposent des exigences plus strictes à leurs données, le manque de coordination des catalogues a révélé trois défis persistants :
- Le problème du "split-brain" : les moteurs externes écrivant directement dans les tables Delta dans le stockage objet entraînent une divergence silencieuse des métadonnées du catalogue, comme les schémas, par rapport à l'état réel de la table.
- Prolifération de l'accès multi-moteurs et multi-agents : chaque moteur, outil et agent peut accéder aux tables différemment, ce qui entraîne une découverte de tables fragmentée, une auditabilité incohérente et aucune application standardisée des contrôles au niveau des lignes ou des colonnes entre les systèmes.
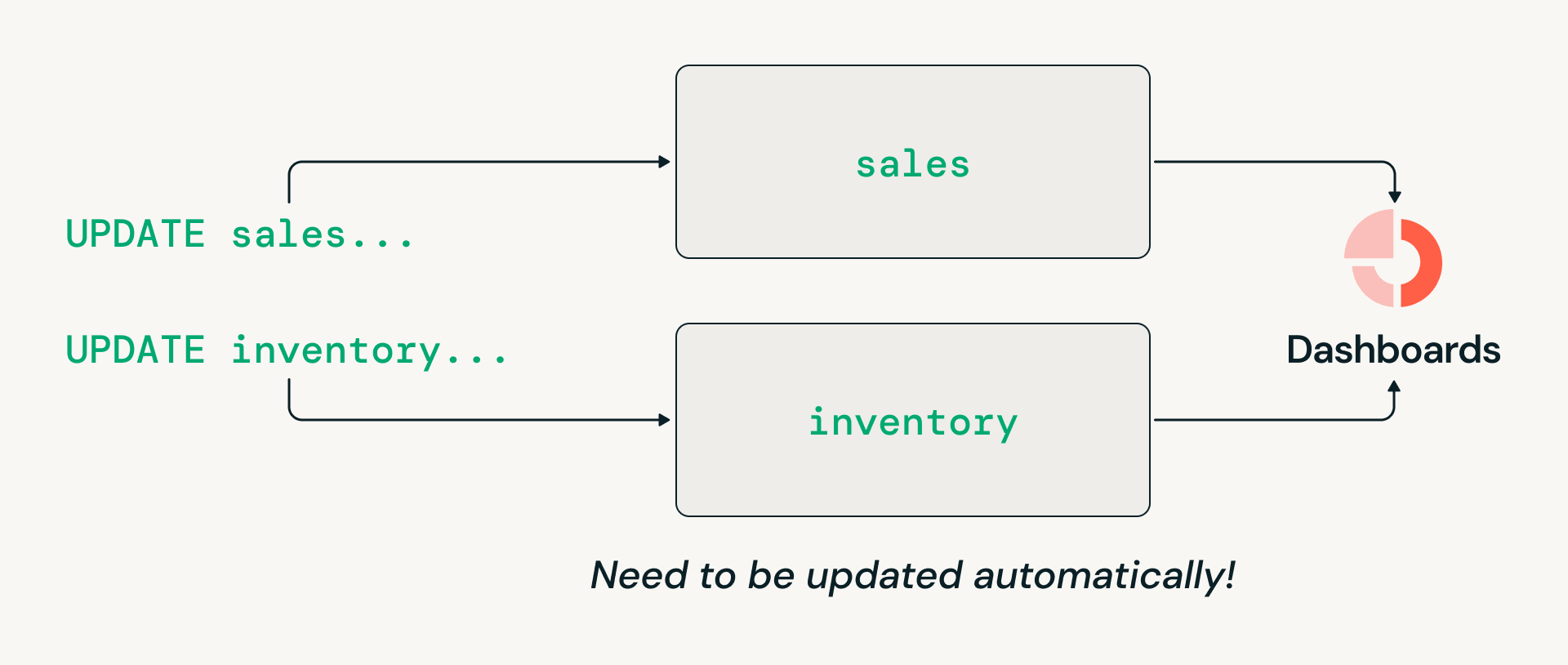
- Coordination des transactions multi-tables : les architectures de lakehouse ouvertes n'ont historiquement pas pris en charge les écritures atomiques couvrant plusieurs tables, de sorte que les organisations ont été contraintes de maintenir des entrepôts de données hérités spécifiquement pour les charges de travail transactionnelles.
Défi n°1 : Problème de "split-brain" – maintenir la synchronisation des catalogues et des tables de gouvernance
Aujourd'hui, les catalogues ne sont pas sur le chemin de lecture ou d'écriture des moteurs Delta. Ainsi, si un moteur comme Apache Flink souhaite apporter une modification de schéma à une table en écrivant directement dans la couche de stockage, le catalogue n'est pas informé de ces modifications, créant un état de "split-brain" où les métadonnées du catalogue et l'état réel de la table divergent. Cela peut entraîner une dérive silencieuse des métadonnées et des échecs de pipelines en aval.
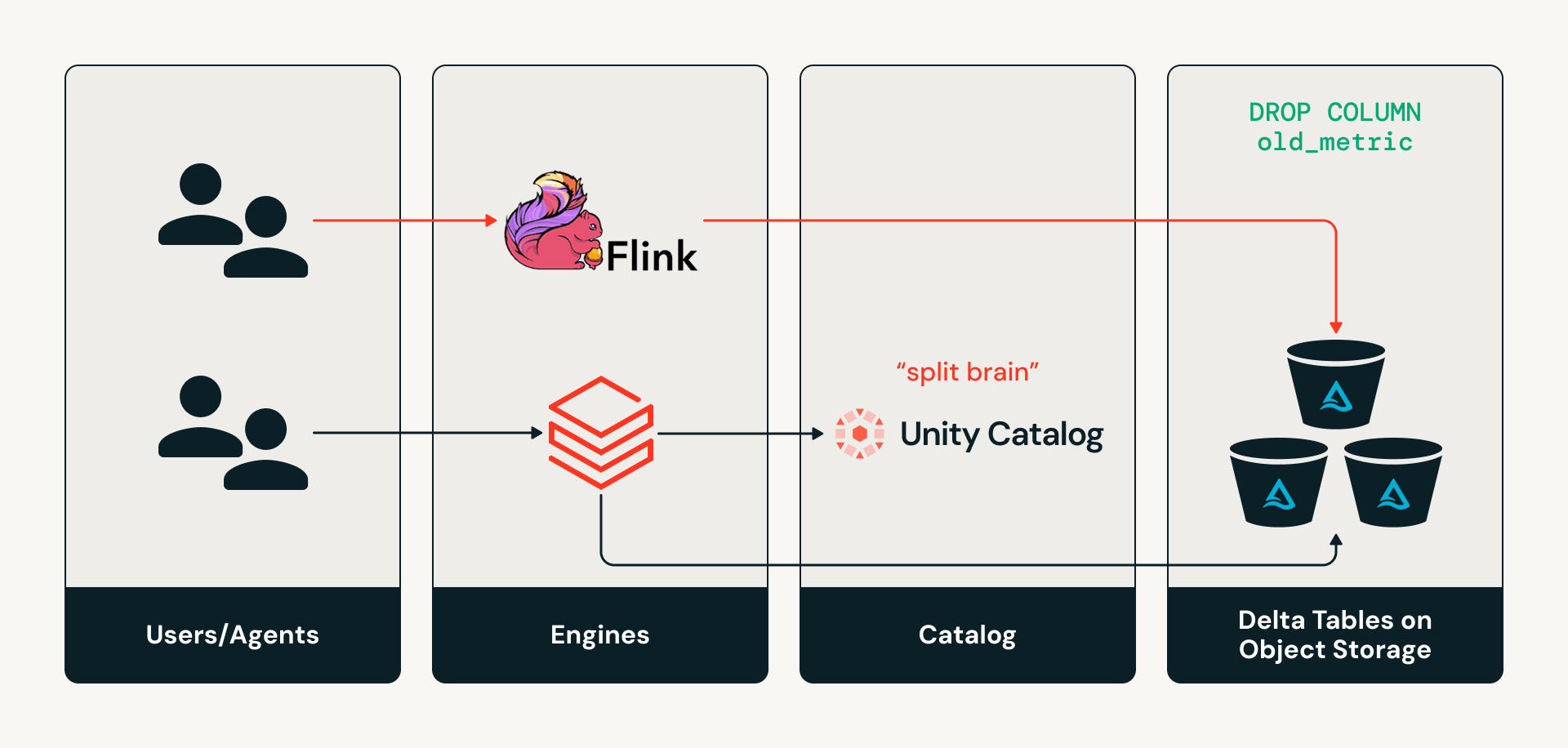
Défi n°2 : Prolifération de l'accès multi-moteurs et multi-agents
Les organisations modernes utilisent de nombreux moteurs et outils pour analyser les données, construire des pipelines et alimenter l'IA. Historiquement, ces systèmes accédaient aux données directement depuis le stockage objet en utilisant des chemins statiques. Cela couple étroitement les charges de travail au stockage physique, rendant les tables difficiles à découvrir. De plus, comme chaque moteur lit les tables Delta directement depuis la couche de stockage, qui ne prend généralement en charge que des permissions granulaires, il est très difficile d'appliquer une gouvernance cohérente au niveau des lignes/colonnes sur tous les moteurs. De même, l'audit de l'accès aux données reste fragmenté car il n'y a pas de couche d'accès cohérente pour capturer l'activité entre les moteurs, de sorte que les administrateurs peuvent avoir une vision incohérente de la manière dont les données sont réellement utilisées.
Les organisations ont besoin d'un lieu central pour découvrir, gouverner et auditer leurs données. Ce besoin devient encore plus urgent à mesure que les agents d'IA émergent comme un consommateur principal des données d'entreprise.
Défi n°3 : Coordination des transactions sur plusieurs tables
Les charges de travail d'entrepôt de données nécessitent souvent des transactions multi-tables, telles que la mise à jour atomique des tables des ventes et des inventaires afin que les lecteurs en aval voient toujours une vue cohérente. Cependant, la conception historique orientée système de fichiers de Delta Lake limitait les transactions aux tables individuelles. Par conséquent, même si de nombreuses organisations souhaitent consolider l'architecture du lakehouse, elles ont dû maintenir des entrepôts de données hérités spécifiquement pour ces charges de travail.
Catalog Commits est la prochaine évolution du lakehouse ouvert
Catalog Commits est la norme ouverte pour que les tables Delta s'intègrent à un catalogue, rendant le catalogue responsable de la coordination de l'accès aux tables et du suivi de l'état le plus récent de la table. Maintenant que Delta et Iceberg sont tous deux orientés catalogue, les clients peuvent compter sur leurs tables pour avoir un modèle standardisé de découverte et de gouvernance des tables. Pour en savoir plus sur la spécification Catalog Commits, lisez le protocole Delta et consultez l'implémentation de référence de Catalog Commits par Unity Catalog.
Sur Databricks, Catalog Commits peut être activé sur les tables Delta gérées par UC. Une fois activé, Unity Catalog gère tous les accès aux tables, créant un modèle de découverte et d'autorisation cohérent pour n'importe quel moteur. Cela permet aux organisations de centraliser véritablement la gouvernance de leurs domaines.
Catalog Commits résout les défis de longue date liés au "split-brain", à la prolifération multi-moteurs et à la coordination multi-tables.
1. Élimination du problème de "split-brain" : L'état de la table et le catalogue restent synchronisés car tous les moteurs accèdent aux tables via les mêmes API, éliminant tout risque de dérive silencieuse des métadonnées.
Permet aux moteurs externes d'écrire dans les tables Delta gérées par Unity Catalog
"Historiquement, l'intégration de données en streaming dans un lakehouse gouverné impliquait de réconcilier les métadonnées du catalogue hors bande et d'espérer que rien ne dérive. Catalog Commits élimine complètement cet écart. Avec le service Kafka natif de StreamNative, alimenté par Ursa pour l'architecture sans disque et sans leader de Kafka, les données sont transmises et validées directement via Unity Catalog, de sorte que chaque enregistrement est une ligne gouvernée immédiatement interrogeable par n'importe quel moteur."—Sijie Guo, Co-fondateur et PDG, StreamNative
2. Résolution de la prolifération de l'accès multi-moteurs : Étant donné que chaque moteur et agent passe par des API de catalogue standardisées pour résoudre les tables, les organisations n'ont plus besoin de coder en dur les chemins de stockage ni de gérer des permissions de niveau système de fichiers grossières.
Permet une gouvernance cohérente et améliorée sur tous les moteurs
3. Permet les charges de travail d'entrepôt traditionnelles sur le lakehouse : Le moteur Databricks et Unity Catalog peuvent coordonner des écritures atomiques qui s'étendent sur plusieurs tables. Cela apporte des sémantiques ACID multi-tables au lakehouse, débloquant ainsi les charges de travail traditionnelles d'entrepôt de données.
Permet d'effectuer des transactions multi-tables sur Databricks
“Les transactions, combinées à toutes les nouvelles fonctionnalités SQL telles que le scripting SQL et les procédures stockées, nous permettent de migrer en toute confiance nos charges de travail d'entrepôt les plus critiques vers Databricks. Ces charges de travail sous-tendent des analyses essentielles dans notre entreprise, et disposer de garanties transactionnelles robustes sur le lakehouse change la donne.” —Gal Doron, Head of Data, AnyClip
En plus de cela, l'activation des validations de catalogue sur les tables gérées par UC débloque également :
- Auditabilité holistique : Unity Catalog centralise les métadonnées des tables et les politiques d'accès, permettant aux équipes d'inspecter les autorisations et la propriété des tables via une interface de catalogue cohérente plutôt que de s'appuyer uniquement sur des journaux de stockage de bas niveau.
- Optimisations automatisées des tables : Unity Catalog tire parti de sa visibilité sur tous les accès aux tables pour organiser de manière optimale les données des organisations en fonction de leurs modèles de requêtes spécifiques, via Liquid Clustering et Predictive Optimization.
- Fondations pour de meilleures performances : Unity Catalog peut informer directement les moteurs des métadonnées au niveau de la table sans que le moteur ait besoin de récupérer les métadonnées du stockage cloud, éliminant ainsi une source majeure de latence des métadonnées.
Ensemble, ces capacités font des tables gérées par UC avec validations de catalogue la base la plus ouverte, gouvernée et performante pour le lakehouse moderne.
Activez les validations de catalogue sur vos tables dès aujourd'hui
Les validations de catalogue sur Databricks sont généralement disponibles dès aujourd'hui ! En activant les validations de catalogue sur les tables gérées par Unity Catalog, les fonctionnalités suivantes sont débloquées :
- Interopérabilité améliorée : Écritures de moteurs externes sur des tables Delta gérées par UC
- Gouvernance plus forte : Débloque une gouvernance cohérente et améliorée sur tous les moteurs
- Nouvelles fonctionnalités : Transactions multi-instructions et multi-tables
Les produits Databricks qui lisent ou écrivent sur des tables gérées par UC, de l'ingestion à la consommation de niveau or, prennent désormais en charge les validations de catalogue. Il s'agit notamment de Streaming Tables, Delta Sharing, Zerobus, Lakeflow Connect, AI Gateway, MLflow et Lakeflow Job Triggers. De même, les validations de catalogue sont actuellement prises en charge par des moteurs de l'écosystème, notamment Delta Spark, Delta Flink, Starburst Trino, DuckDB et StreamNative.
Il est également facile pour tout moteur de prendre en charge les validations de catalogue en s'intégrant à Delta Kernel, une bibliothèque partagée d'API qui abstrait les détails au niveau du protocole. Delta Kernel permet aux connecteurs de prendre en charge facilement les dernières fonctionnalités Delta avec de simples mises à niveau de version.
La création d'une table Delta gérée par UC avec les validations de catalogue activées est facile. En utilisant Databricks Runtime 16.4+, exécutez :
Pour mettre à niveau une table Delta gérée par UC existante afin d'activer les validations de catalogue, utilisez Databricks Runtime 18.0+ et exécutez :
Commencez avec les validations de catalogue et rejoignez-nous au Data and AI Summit pour en savoir plus sur notre travail de construction du lakehouse ouvert !
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.