Meilleures pratiques de modélisation de données et mise en œuvre sur un Lakehouse moderne
par Leo Mao, Abhishek Dey, Justin Breese et Soham Bhatt
Un grand nombre de nos clients migrent leurs entrepôts de données existants vers le Lakehouse Databricks, car cela leur permet non seulement de moderniser leur entrepôt de données, mais leur donne également un accès instantané à une plateforme mature de streaming et d'analyse avancée. Le Lakehouse peut tout faire car c'est une plateforme unique pour tous vos besoins en streaming, ETL, BI et IA - et il aide vos équipes métier et de données à collaborer sur une seule plateforme.
En aidant nos clients sur le terrain, nous constatons que beaucoup recherchent les meilleures pratiques en matière de modélisation de données appropriée et d'implémentations de modèles de données physiques dans Databricks.
Dans cet article, nous visons à approfondir la meilleure pratique de la modélisation dimensionnelle sur la plateforme Databricks Lakehouse et à fournir un exemple concret d'implémentation de modèle de données physique en utilisant nos meilleures pratiques de création de tables et de DDL.
Voici les sujets généraux que nous aborderons dans ce blog :
- L'importance de la modélisation des données
- Techniques courantes de modélisation des données
- Implémentation DDL de la modélisation d'entrepôt de données
- Meilleures pratiques et recommandations pour la modélisation des données sur le Databricks Lakehouse
L'importance de la modélisation des données pour l'entrepôt de données
Les modèles de données sont au cœur de la construction d'un entrepôt de données. Généralement, le processus commence par la défense du modèle d'information sémantique métier, puis d'un modèle de données logique, et enfin d'un modèle de données physique (PDM). Tout commence par une phase appropriée d'analyse et de conception de systèmes où un modèle d'information métier et des flux de processus sont créés en premier, et les entités métier clés, les attributs et leurs interactions sont capturés conformément aux processus métier au sein de l'organisation. Le modèle de données logique est ensuite créé, représentant comment les entités sont liées les unes aux autres, et c'est un modèle indépendant de la technologie. Enfin, un PDM est créé sur la base de la plateforme technologique sous-jacente pour garantir que les écritures et les lectures peuvent être effectuées efficacement. Comme nous le savons tous, pour l'entreposage de données, les styles de modélisation conviviaux pour l'analyse tels que le schéma en étoile et le Data Vault sont très populaires.
Meilleures pratiques pour la création d'un modèle de données physique dans Databricks
Basé sur le problème métier défini, l'objectif de la conception du modèle de données est de représenter les données d'une manière simple pour la réutilisabilité, la flexibilité et la scalabilité. Voici un modèle de données typique en schéma étoile qui montre une table de faits de ventes qui contient chaque transaction et diverses tables de dimensions telles que les clients, les produits, les magasins, la date, etc., par lesquelles vous pouvez segmenter les données. Les dimensions peuvent être jointes à la table de faits pour répondre à des questions métier spécifiques telles que quels sont les produits les plus populaires pour un mois donné ou quels magasins sont les plus performants pour le trimestre. Voyons comment l'implémenter dans Databricks.
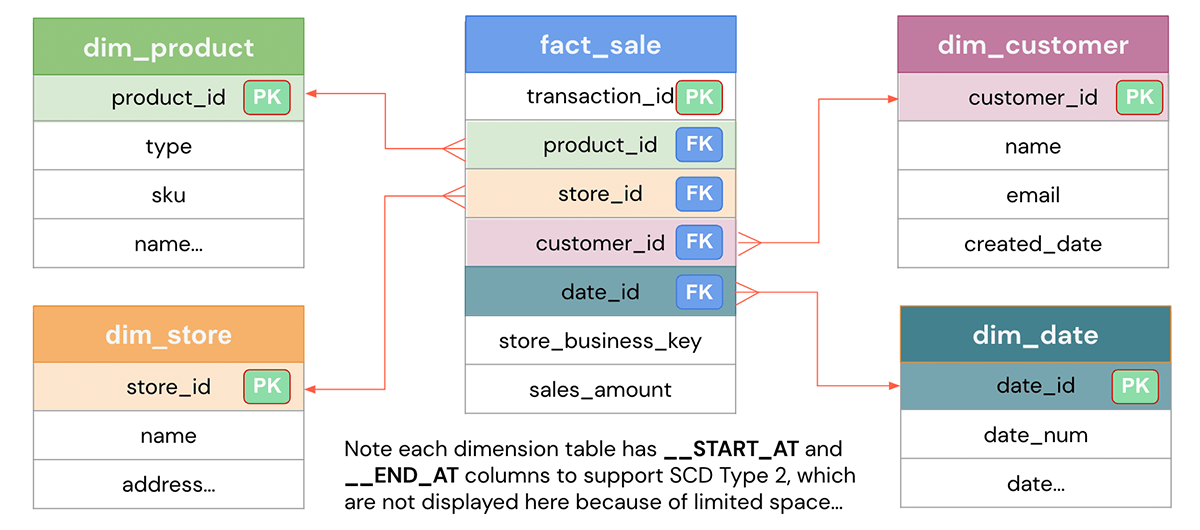
Implémentation DDL de la modélisation d'entrepôt de données sur Databricks
Dans les sections suivantes, nous allons démontrer ce qui suit à l'aide de nos exemples.
- Création d'un catalogue, d'une base de données et d'une table à 3 niveaux
- Définitions de clés primaires et étrangères
- Colonnes d'identité pour les clés substituts
- Contraintes de colonne pour la qualité des données
- Index, optimisation et analyse
- Techniques avancées
1. Unity Catalog - Espace de noms à 3 niveaux
Unity Catalog est une couche de gouvernance Databricks qui permet aux administrateurs Databricks et aux responsables des données de gérer les utilisateurs et leur accès aux données de manière centralisée sur tous les espaces de travail d'un compte Databricks en utilisant un seul Metastore. Les utilisateurs de différents espaces de travail peuvent partager l'accès aux mêmes données, en fonction des privilèges accordés centralement dans Unity Catalog. Unity Catalog a un espace de noms à 3 niveaux (catalog.schema(database).table) qui organise vos données. Apprenez-en davantage sur Unity Catalog ici.
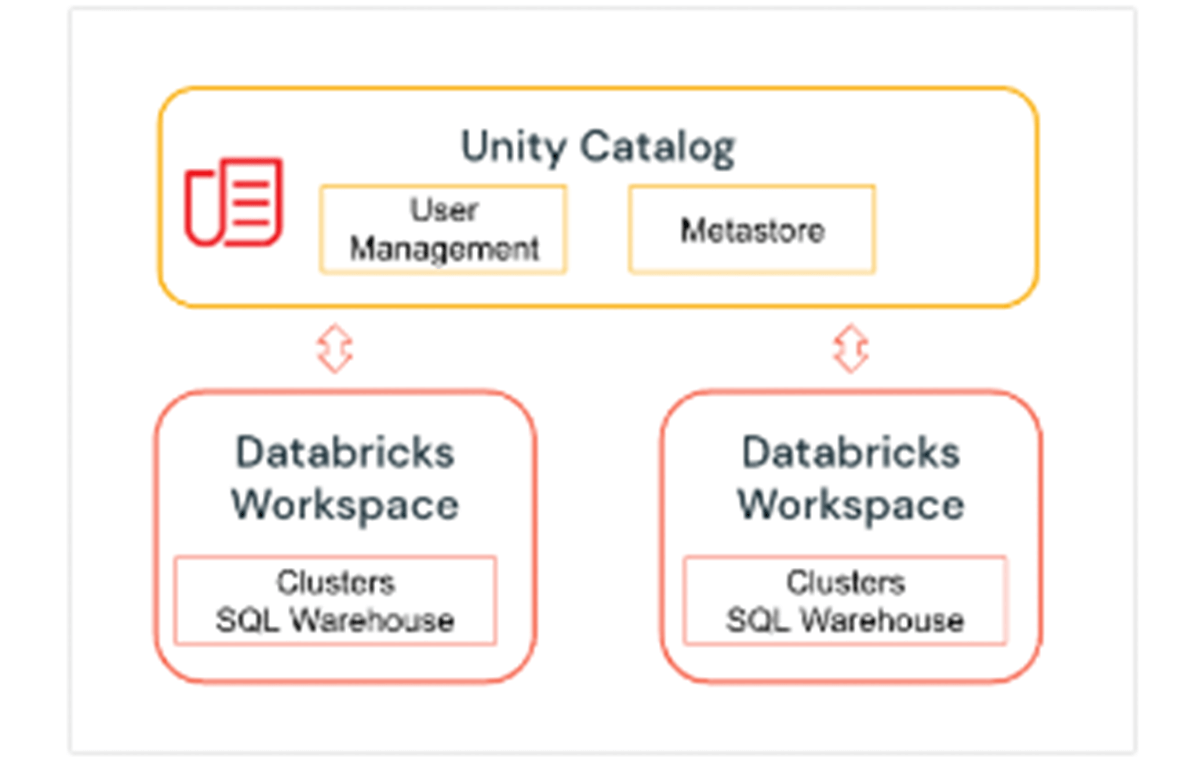
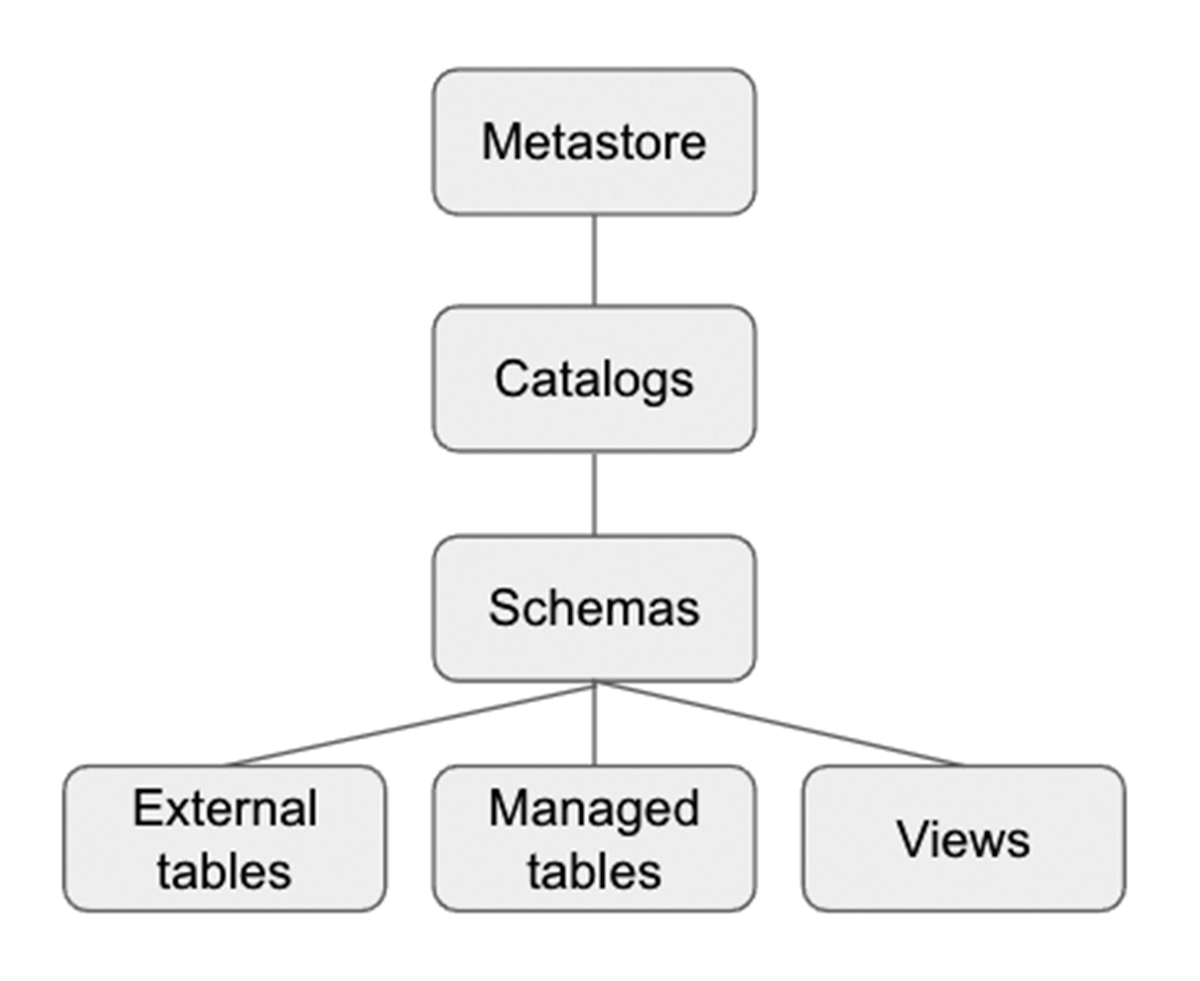
Voici comment configurer le catalogue et le schéma avant de créer des tables dans la base de données. Pour notre exemple, nous créons un catalogue US_Stores et un schéma (base de données) Sales_DW comme ci-dessous, et nous les utilisons pour la suite de la section.
Configuration du catalogue et de la base de données
Voici un exemple de requête sur la table fact_sales avec un espace de noms à 3 niveaux.
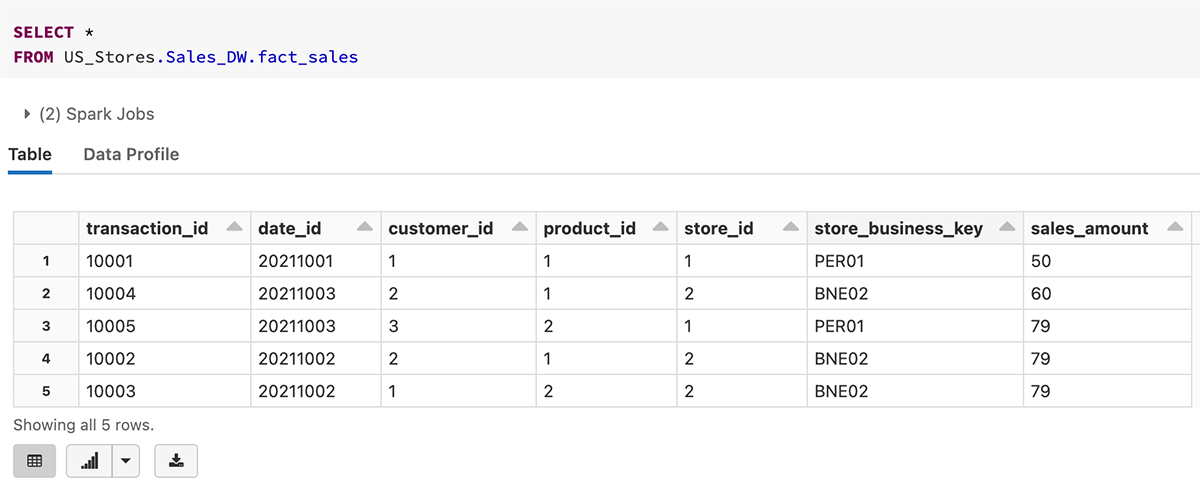
2. Définitions de clés primaires et étrangères
Les définitions de clés primaires et étrangères sont très importantes lors de la création d'un modèle de données. La capacité de prendre en charge la définition PK/FK rend la définition du modèle de données très facile dans Databricks. Cela aide également les analystes à identifier rapidement les relations de jointure dans Databricks SQL Warehouse afin qu'ils puissent écrire des requêtes efficacement. Comme la plupart des autres entrepôts de données Massively Parallel Processing (MPP), EDW et Cloud Data Warehouses, les contraintes PK/FK sont purement informatives. Databricks ne prend pas en charge l'application de la relation PK/FK, mais donne la possibilité de la définir pour faciliter la conception du modèle de données sémantique.
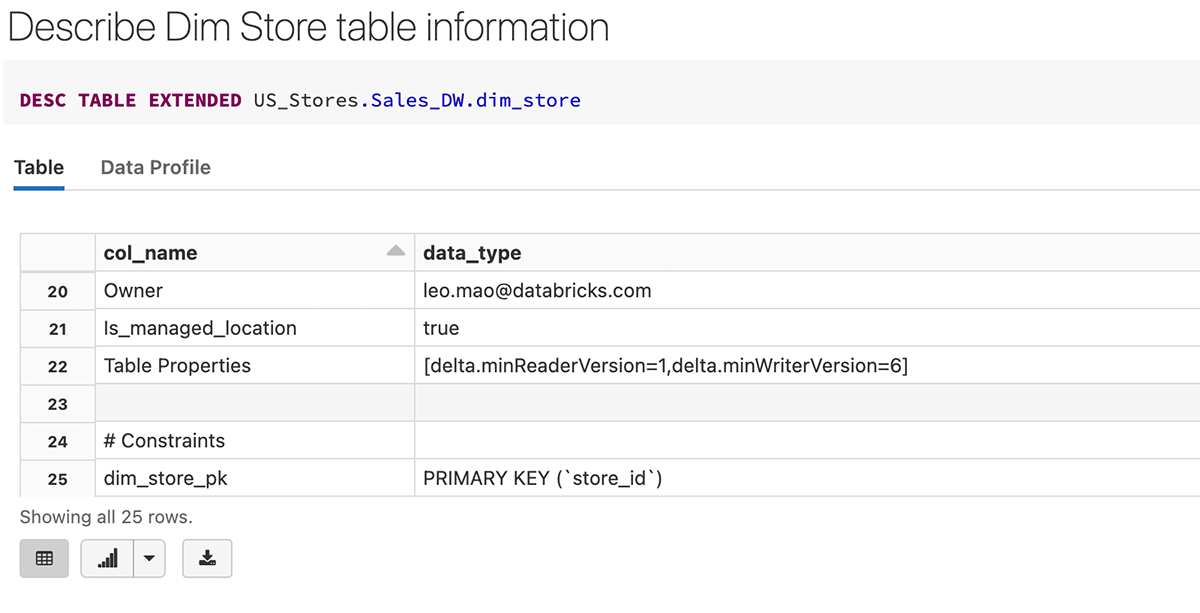
Voici un exemple de création de la table dim_store avec store_id comme colonne d'identité et elle est également définie comme clé primaire en même temps.
Implémentation DDL pour la création de la dimension magasin avec définitions de clés primaires
Après la création de la table, nous pouvons voir que la clé primaire (store_id) est créée comme une contrainte dans la définition de la table ci-dessous.
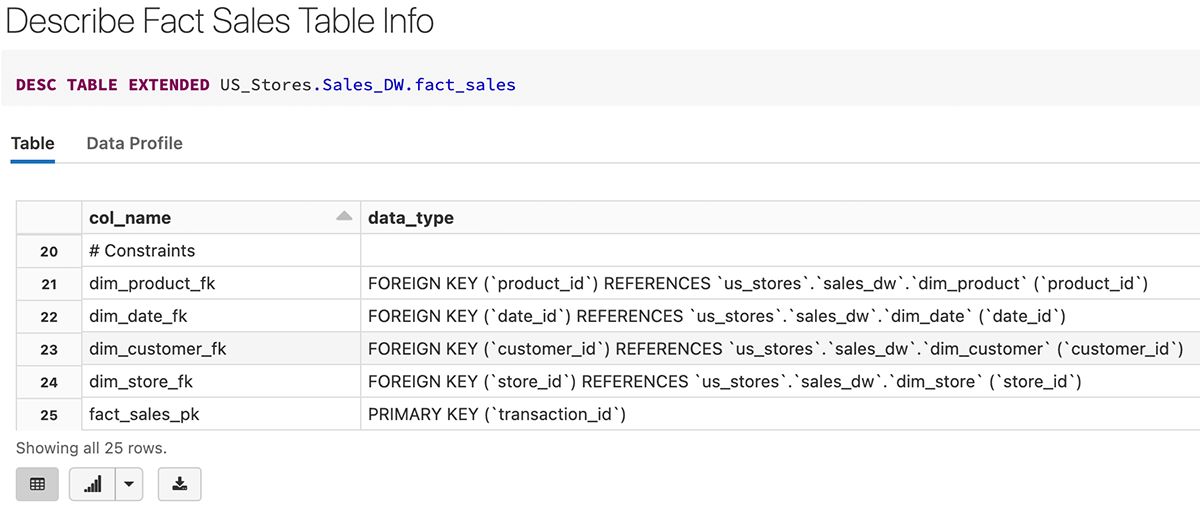
Voici un exemple de création de la table fact_sales avec transaction_id comme clé primaire, ainsi que des clés étrangères référençant les tables de dimensions.
Implémentation DDL pour la création de faits de ventes avec définitions de clés étrangères
Après la création de la table de faits, nous pouvons voir que la clé primaire (transaction_id) et les clés étrangères sont créées comme contraintes dans la définition de la table ci-dessous.
3. Colonnes d'identité pour les clés substituts
Une colonne d'identité est une colonne dans une base de données qui génère automatiquement un numéro d'identification unique pour chaque nouvelle ligne de données. Celles-ci sont couramment utilisées pour créer des clés substituts dans les entrepôts de données. Les clés substituts sont des clés générées par le système, sans signification, afin que nous n'ayons pas à nous fier à diverses clés primaires naturelles et à des concaténations sur plusieurs champs pour identifier l'unicité de la ligne. Généralement, ces clés substituts sont utilisées comme clés primaires et étrangères dans les entrepôts de données. Les détails sur les colonnes d'identité sont discutés dans ce blog. Ci-dessous un exemple de création d'une colonne d'identité customer_id, avec des valeurs attribuées automatiquement à partir de 1 et incrémentées de 1.
Implémentation DDL pour la création de la dimension client avec une colonne d'identité
4. Contraintes de colonnes pour la qualité des données
En plus des contraintes informationnelles de clés primaires et étrangères, Databricks prend également en charge les contraintes de vérification de la qualité des données au niveau des colonnes, qui sont appliquées pour garantir la qualité et l'intégrité des données ajoutées à une table. Les contraintes sont vérifiées automatiquement. De bons exemples sont les contraintes NOT NULL et les contraintes de valeur de colonne. Contrairement aux autres entrepôts de données cloud, Databricks est allé plus loin pour fournir des contraintes de vérification de valeurs de colonne, qui sont très utiles pour garantir la qualité des données d'une colonne donnée. Comme nous pouvons le voir ci-dessous, la contrainte de vérification valid_sales_amount vérifiera que toutes les lignes existantes satisfont la contrainte (c'est-à-dire sales amount > 0) avant de l'ajouter à la table. Plus d'informations peuvent être trouvées ici.
Voici des exemples pour ajouter des contraintes pour dim_store et fact_sales respectivement afin de s'assurer que store_id et sales_amount ont des valeurs valides.
Ajouter une contrainte de colonne à des tables existantes pour garantir la qualité des données
5. Indexation, Optimisation et Analyse
Les bases de données traditionnelles ont des index b-tree et bitmap, Databricks a une forme d'indexation beaucoup plus avancée : l'indexation clusterisée Z-order multidimensionnelle et nous prenons également en charge l'indexation par filtre Bloom. Tout d'abord, le format de fichier Delta utilise le format de fichier Parquet, qui est un format de fichier compressé et colonne par colonne, il est donc déjà très efficace pour l'élagage de colonnes et, en plus, l'utilisation de l'indexation z-order vous donne la capacité de parcourir des données à l'échelle du pétaoctet en quelques secondes. L'indexation Z-order et l'indexation par filtre Bloom réduisent considérablement la quantité de données qui doivent être analysées pour répondre à des requêtes très sélectives sur de grandes tables Delta, ce qui se traduit généralement par des améliorations d'ordres de grandeur en termes de temps d'exécution et d'économies de coûts. Utilisez Z-order sur vos clés primaires et clés étrangères qui sont utilisées pour les jointures les plus fréquentes. Et utilisez une indexation supplémentaire par filtre Bloom si nécessaire.
Optimiser fact_sales sur customer_id et product_id pour une meilleure performance
Créer un index Bloomfilter pour activer le saut de données sur une colonne donnée
Et comme tout autre entrepôt de données, vous pouvez ANALYZE TABLE pour mettre à jour les statistiques afin de garantir que l'optimiseur de requêtes dispose des meilleures statistiques pour créer le meilleur plan de requête.
Collecter les statistiques pour toutes les colonnes afin d'améliorer le plan d'exécution des requêtes
6. Techniques avancées
Bien que Databricks prenne en charge des techniques avancées comme le partitionnement de table, veuillez utiliser ces fonctionnalités avec parcimonie, uniquement lorsque vous avez plusieurs Téraoctets de données compressées - car la plupart du temps, nos index OPTIMIZE et Z-ORDER vous donneront le meilleur élagage de fichiers et de données, ce qui rend le partitionnement d'une table par date ou par mois presque une mauvaise pratique. Il est cependant une bonne pratique de s'assurer que vos DDL de table sont configurés pour l'optimisation automatique et la compaction automatique. Celles-ci garantiront que vos données fréquemment écrites dans de petits fichiers sont compactées dans des formats compressés colonnes plus grands de Delta.
Vous cherchez à exploiter un outil de modélisation de données visuel ? Notre partenaire erwin Data Modeler par Quest peut être utilisé pour la rétro-ingénierie, la création et l'implémentation de schémas en étoile, de Data Vaults et de tout modèle de données industriel dans Databricks en quelques clics.
Exemple de notebook Databricks
Avec la plateforme Databricks, on peut facilement concevoir et implémenter divers modèles de données avec aisance. Pour voir tous les exemples ci-dessus dans un flux de travail complet, veuillez consulter cet exemple.
Consultez également notre article de blog connexe - Cinq étapes simples pour implémenter un schéma en étoile dans Databricks avec Delta Lake.
Commencez à construire vos modèles dimensionnels dans le Lakehouse
Essayez Databricks gratuitement pendant 14 jours.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.