Conception découplée : recherche vectorielle à l'échelle du milliard
par Zero Qu, Erik Lindgren, Sheng Zhan, Ankit Vij, Sergei Tsarev et Dima Kotlyarov
Introduction
La recherche vectorielle est devenue une infrastructure fondamentale pour les applications d'IA, de la recherche au sein des produits aux systèmes de recommandation, en passant par la résolution d'entités et la génération augmentée par la récupération. Mais à mesure que les datasets passent de millions à des milliards de vecteurs, les systèmes conçus pour les servir commencent à présenter des défaillances coûteuses : les coûts de mémoire explosent, l'ingestion bloque le service, et la mise à l'échelle nécessite de tout répliquer.
Chez Databricks, nous avons rencontré ces limites avec notre offre initiale de recherche vectorielle. Nous sommes donc revenus aux principes de base et l'avons entièrement repensée. Aujourd'hui, Databricks AI Search propose deux options de déploiement : les Endpoints Standard, qui conservent les vecteurs en pleine précision entièrement en mémoire pour une latence de l'ordre de la dizaine de millisecondes, et les Endpoints optimisés pour le stockage, qui séparent le stockage du compute pour servir des milliards de vecteurs à une fraction du coût — avec des latences de query de l'ordre de la centaine de millisecondes, un compromis délibéré pour les charges de travail où le coût et la montée en charge sont plus importants que des temps de réponse de quelques millisecondes.
La recherche vectorielle optimisée pour le stockage a été façonnée par trois décisions d'ingénierie fondamentales :
- Séparer le stockage du calcul. Les index vectoriels se trouvent dans le stockage d'objets cloud et ne sont chargés en mémoire que pour le service des requêtes. L'ingestion s'exécute sur des clusters Spark serverless éphémères, complètement isolés du chemin des requêtes.
- Développez des algorithmes d'indexation distribuée sur Spark. Plutôt que de nous fier à des bibliothèques d'indexation monomachine, nous avons développé les nôtres — clustering distribué, compression de vecteurs et layout des données alignées sur les partitions — en tant que Jobs Spark natifs qui montent en charge de manière linéaire à la taille du cluster.
- Servez les requêtes depuis un moteur Rust avec une architecture à double exécution. Un moteur de requête spécialement conçu utilise des pools de threads distincts pour les E/S asynchrones et le calcul vectoriel lié au processeur, de sorte qu'aucun n'affame l'autre.
Le résultat : des indexes d'un milliard de vecteurs créés en moins de 8 heures, une indexation 20 fois plus rapide et des coûts de service jusqu'à 7 fois inférieurs.
Cet article est le récit technique de sa construction.
Le problème avec les bases de données vectorielles traditionnelles
Les limites du couplage fort
De nombreuses bases de données vectorielles de production, y compris notre AI Search Standard, suivent une architecture sans partage (shared-nothing) empruntée à la recherche par mots-clés distribuée. Chaque nœud possède un fragment aléatoire du dataset et maintient un graphe HNSW (Hierarchical Navigable Small World) indépendant en mémoire sur des vecteurs en pleine précision. Le HNSW offre une excellente qualité de recherche, mais le graphe lui-même doit résider entièrement en mémoire, ce qui en fait l'un des composants les plus coûteux à monter en charge. Cette conception offre une faible latence et prend en charge les mises à jour transactionnelles. Elle fonctionne bien jusqu'à des centaines de millions de vecteurs.
À l'échelle du milliard, elle s'effondre.
Le problème fondamental est le couplage. L'index, les données brutes et le compute qui les sert sont tous liés au même nœud. La mise à l'échelle implique de tout répliquer : plus de vecteurs nécessitent plus de mémoire, ce qui requiert plus de nœuds, chacun contenant une copie complète de l'index et des données de son shard. Il n'y a aucun moyen de monter en charge le stockage indépendamment du compute.
Le couplage s'étend à l'ingestion. La construction de l'index se fait au sein même du moteur de recherche — les mêmes compute ressources qui traitent les queries gèrent également la réorganisation des données, la reconstruction des index et le compactage. Sous des charges de travail lourdes en écriture, la latence des requêtes se dégrade. Sous des charges de travail lourdes en queries, l'ingestion ralentit considérablement. Pire encore, chaque modification de données — un upsert, une suppression, un compactage — déclenche des reconstructions de sous-index, consommant des cycles CPU pour la maintenance plutôt que pour le traitement des requêtes.
Les index en mémoire sont coûteux
Cette résidence en mémoire est ce qui rend l'architecture rapide — et ce qui la rend coûteuse. Avec 768 dimensions et des flottants 32 bits, 100 millions de vecteurs consomment environ 286 Gio de RAM, uniquement pour les vecteurs, avant tout surcoût lié à l'index. Un milliard de vecteurs nécessiterait des téraoctets. Contrairement au stockage sur disque ou au stockage d'objets, où le coût par gigaoctet est négligeable, la mémoire est la ressource la plus chère de la stack. Chaque vecteur ajouté augmente directement la facture de RAM.
Le sharding aléatoire aggrave le problème. Comme les vecteurs sont distribués sans tenir compte de la similarité sémantique, chaque query doit être diffusée à tous les shards et rassembler les résultats, quelle que soit la pertinence de chaque shard. Le CPU, la surcharge réseau et la latence de queue augmentent tous avec le nombre de shards. Ajouter des vecteurs signifie ajouter des shards, et chaque nouveau shard possède son propre index résidant en mémoire.
Découplé par conception
La solution n'est pas d'optimiser au sein de cette architecture — il s'agit de rompre le couplage lui-même.
La recherche vectorielle optimisée pour le stockage part d'un principe unique : toutes les données résident dans le stockage d'objets cloud et les nœuds de requête sont sans état. Cela divise le système selon deux axes (le stockage et le compute, afin que les nœuds de query ne possèdent pas les données ; l'ingestion et le service, afin que la création d'index n'entre jamais en concurrence avec les query en direct) et donne naissance à une architecture à trois couches :
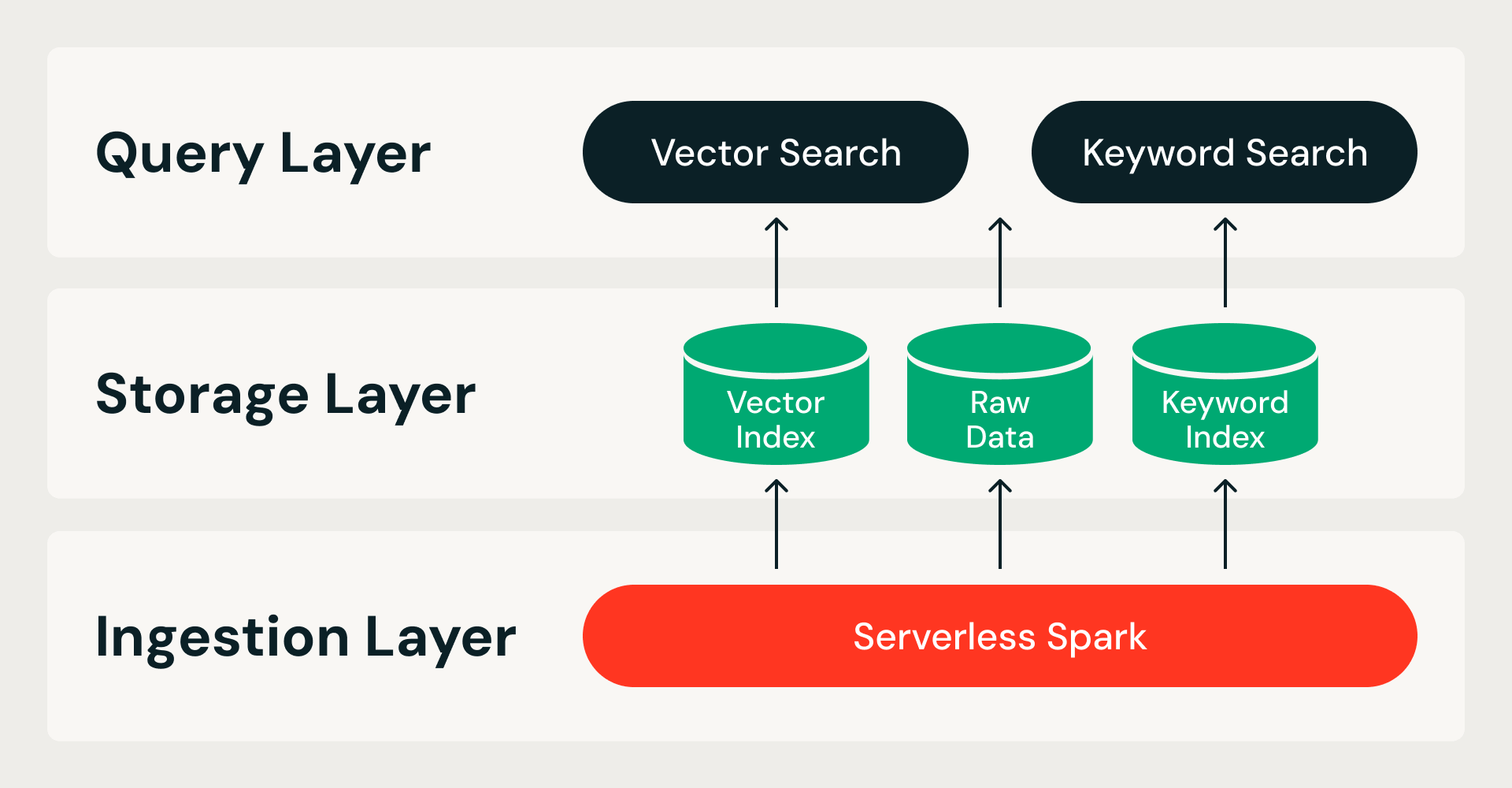
- Couche d'ingestion. Un pipeline distribué sur Serverless Spark gère toute la construction d'index, des données brutes à l'index final. Chaque exécution est idempotente et peut être relancée.
- Couche de stockage. Un format de stockage personnalisé et natif du cloud sert de système d'enregistrement. Il combine un format de fichier en colonnes pour les données brutes et les indexes vectoriels avec un format d'index inversé pour la recherche par mots-clés, le tout dans le cadre de transactions ACID avec des fragments de données immuables.
- Query layer. Deux services sans état gèrent les lectures. Le service de recherche vectorielle conserve un index compressé en mémoire et récupère des données en pleine précision depuis le stockage d'objets sur demande. La recherche par mot-clé fournit des index inversés pour le filtrage des métadonnées et la recherche par mot-clé. Les deux services montent en charge indépendamment, de sorte que les Ressources peuvent être adaptées à la charge de travail.
Une structure d'index pour le stockage d'objets
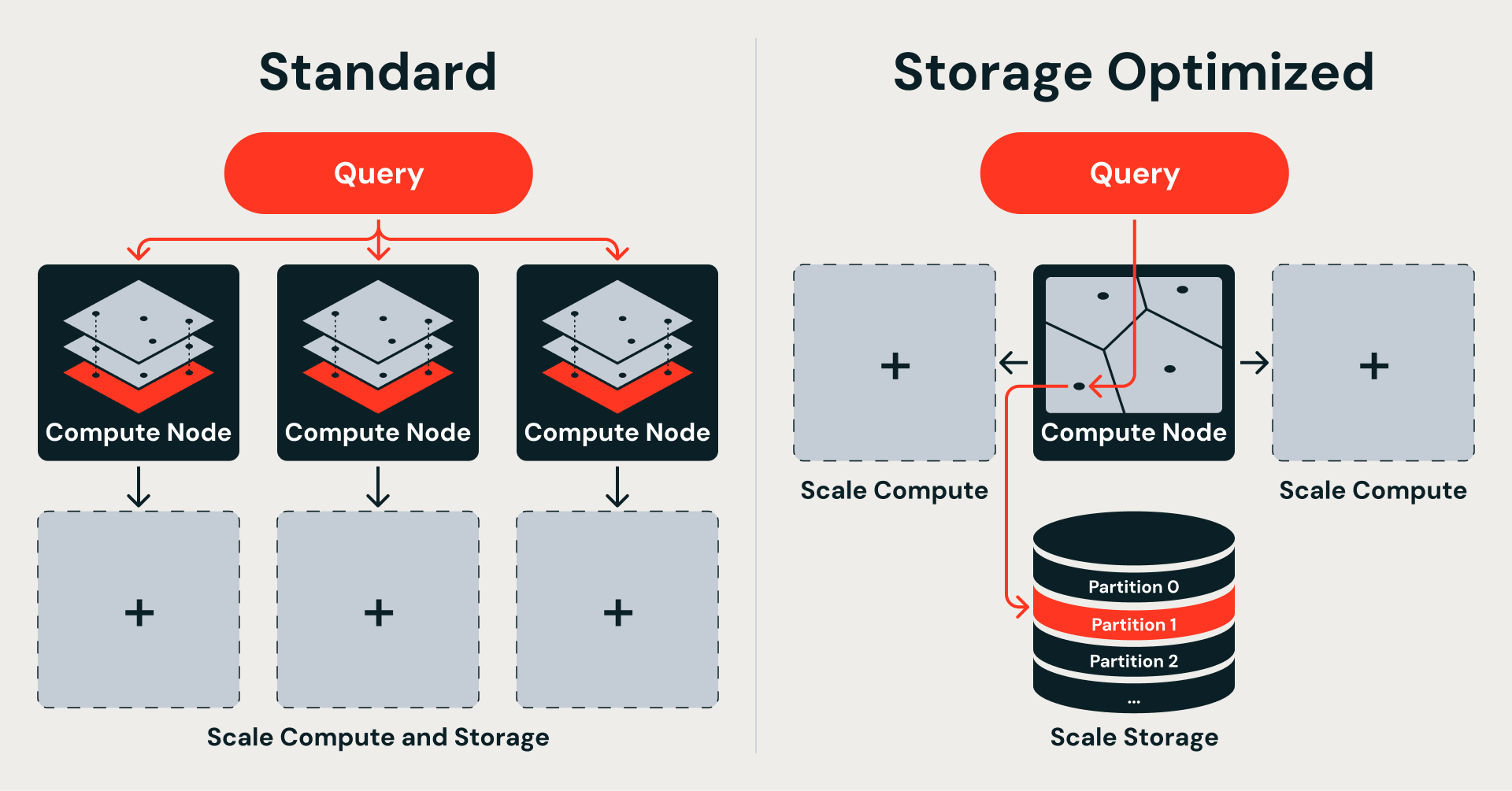
Si les données se trouvent dans un stockage d'objets, l'index doit être partitionnable. Le moteur de query ne doit récupérer que les tranches pertinentes, et non charger l'ensemble de la structure en mémoire.
Les graphes HNSW n'ont pas cette propriété. Chaque saut de recherche peut aller n'importe où dans le graphe, de sorte que la structure complète doit résider en mémoire pour traiter une seule query. Il n'existe aucun moyen naturel de diviser un graphe HNSW en fragments correspondant à des fichiers de stockage d'objets.
L'IVF (Inverted File Index) adopte une approche différente : il regroupe les vecteurs par proximité autour de centroïdes appris et ne recherche que les clusters les plus proches au moment de la query. Chaque cluster correspond directement à un fragment de données sur le stockage d'objets, récupérable indépendamment, sans charger le reste de l'index.
Ce choix d'algorithme découle directement de l'emplacement des données. La recherche vectorielle standard conserve l'index complet en mémoire pour plus de vitesse, ce qui lie le stockage et le compute. L'option de stockage optimisé déplace les données vers le stockage d'objets pour monter en charge, ce qui les libère — mais nécessite un index qui se décompose en partitions autonomes et récupérables. L'IVF fournit exactement cela :
Indexation vectorielle distribuée sur Spark
L'IVF nous fournit la bonne structure d'index pour un stockage séparé. Le défi d'ingénierie consiste à le construire à monter en charge. La plupart des bibliothèques d'indexation vectorielle — FAISS, ScaNN, Annoy — partent du principe que toutes vos données tiennent sur une seule machine. Cela fonctionne pour des dizaines de millions de vecteurs. Avec un milliard de vecteurs et des embeddings à 768 dimensions, vous avez affaire à des téraoctets de données brutes en virgule flottante avant même de start à construire un index. Aucune machine seule ne peut gérer cela efficacement, et même si c'était le cas, votre temps d'ingestion deviendrait un goulot d'étranglement en série qui s'allonge avec chaque nouvelle ligne.
Nous avions besoin d'une indexation qui puisse monter en charge horizontalement. Nous avons donc implémenté chaque algorithme d'indexation à partir de zéro — K-means distribué, Product Quantization et layout des données alignée sur les partitions — en tant que Jobs PySpark natives s'exécutant sur des clusters Spark serverless éphémères. Aucune bibliothèque d'indexation pour machine unique sur le chemin critique. L'ajout d'exécuteurs supplémentaires réduit de manière linéaire le temps des étapes les plus coûteuses.
Le pipeline d'ingestion
Chaque exécution d'ingestion s'exécute sous la forme d'un graphe orienté acyclique d'étapes, encapsulée dans une transaction ACID.
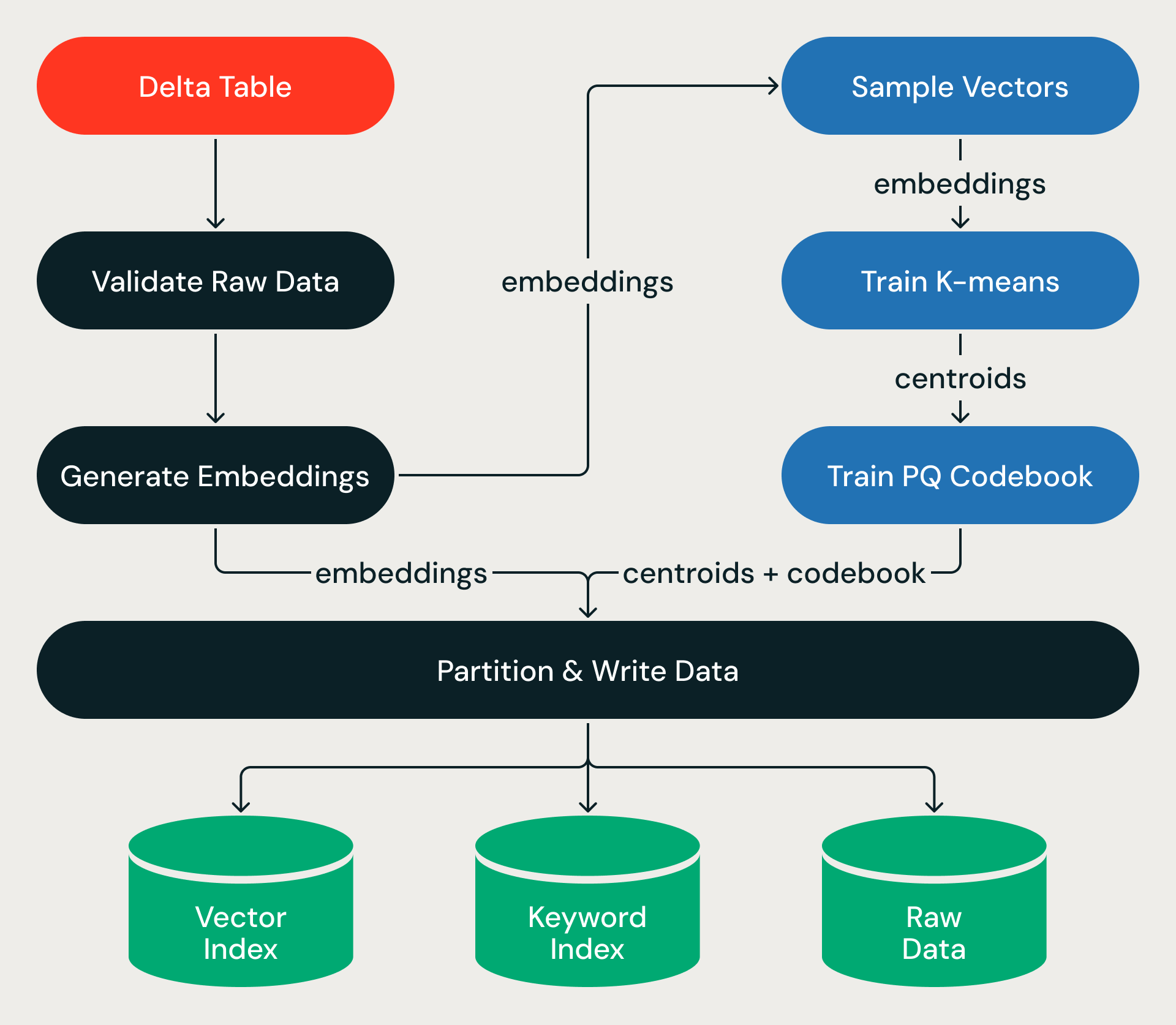
Le pipeline démarre à partir d'une Delta Table source. Pour les index basés sur du texte source (plutôt que sur des vecteurs pré-calculés), après avoir validé les données source, le pipeline appelle Databricks Model Serving pour générer des plongements vectoriels pour les lignes nouvelles ou mises à jour — transformant ainsi des milliards d'enregistrements textuels en vecteurs de grande dimension à très grande échelle.
À partir de là, le pipeline s'entraîne sur un petit échantillon (apprenant ainsi la structure de l'espace vectoriel), puis applique cette structure au dataset complet, en assignant chaque vecteur à une partition, en le compressant et en écrivant les résultats dans le stockage d'objets. L'entraînement est peu coûteux ; le passage sur le dataset complet, qui mélange des téraoctets de données entre les exécuteurs, est l'étape qui prend le plus de temps d'exécution.
K-means : partitionnement à la montée en charge
Le clustering k-moyennes partitionne l'espace vectoriel en régions : les partitions IVF qui permettent aux requêtes de rechercher une fraction des données au lieu de leur totalité. Pour un ensemble de données d'un milliard de lignes, nous créons environ 32 000 partitions. La question est : comment exécuter K-means à cette échelle lorsque les implémentations standard supposent que toutes les données tiennent sur une seule machine ?
Vous le construisez de zéro sur Spark.
Notre implémentation utilise un modèle hybride : Spark gère le déplacement de données distribué, tandis que JAX — une bibliothèque de calcul numérique avec une algèbre linéaire accélérée par le matériel — gère les calculs mathématiques à l'intérieur de chaque exécuteur. Chaque itération K-means est un pipeline Spark en trois étapes :
- Assigner — chaque exécuteur calcule les distances entre son batch local de vecteurs et tous les centroïdes actuels, trouvant ainsi les clusters les plus proches pour chaque vecteur.
- Shuffle — Spark repartitionne les données par ID de centroïde, colocalisant tous les vecteurs assignés au même cluster.
- Agréger — chaque exécuteur calcule les nouvelles positions des centroïdes à partir de ses vecteurs colocalisés.
Le calcul de la distance est la boucle critique. JAX le compile en une seule opération matricielle par batch par exécuteur, calculant ainsi la matrice de distance complète batch par centroïde en une seule fois plutôt que d'itérer sur des vecteurs individuels.
L'entraînement s'effectue sur un échantillon, et non sur le dataset complet — pour un milliard de lignes, environ 8 millions de vecteurs (~0,8 % des données). Ce n'est pas arbitraire : le coût de K-means par itération est de O(n × k × d), où n est la taille de l'échantillon, k le nombre de clusters et d la dimension. Le fait de définir n et k comme étant proportionnels à √N rend le coût total de l'entraînement O(N × d) — linéaire par rapport à la taille du dataset, quelle que soit l'échelle.
Ce choix est également statistiquement fondé : la théorie des coresets montre que O(k) échantillons suffisent pour un clustering k-means de haute qualité sur des données bien distribuées, et comme k évolue avec √N, la taille de notre échantillon est prouvée comme étant adéquate. L'entraînement se termine en quelques itérations et enregistre les checkpoints des centroïdes dans le stockage d'objets pour les étapes en aval du pipeline.
Quantification de produit : Compression de mémoire 64x
K-means nous donne des partitions grossières. La quantification de produit (PQ) compresse les vecteurs afin que nous puissions réellement effectuer des recherches à l'intérieur à grande échelle. L'idée : diviser chaque vecteur de 768 dimensions en 48 sous-vecteurs de 16 dimensions chacun, et remplacer chaque sous-vecteur par un seul octet pointant vers l'entrée la plus proche dans un dictionnaire de codes (codebook) appris. Un vecteur de 3 072 octets devient 48 octets, soit un taux de compression de 64x. Pour un milliard de vecteurs de 768 dimensions, cela réduit près de 3 Tio de données brutes à environ 45 Gio.
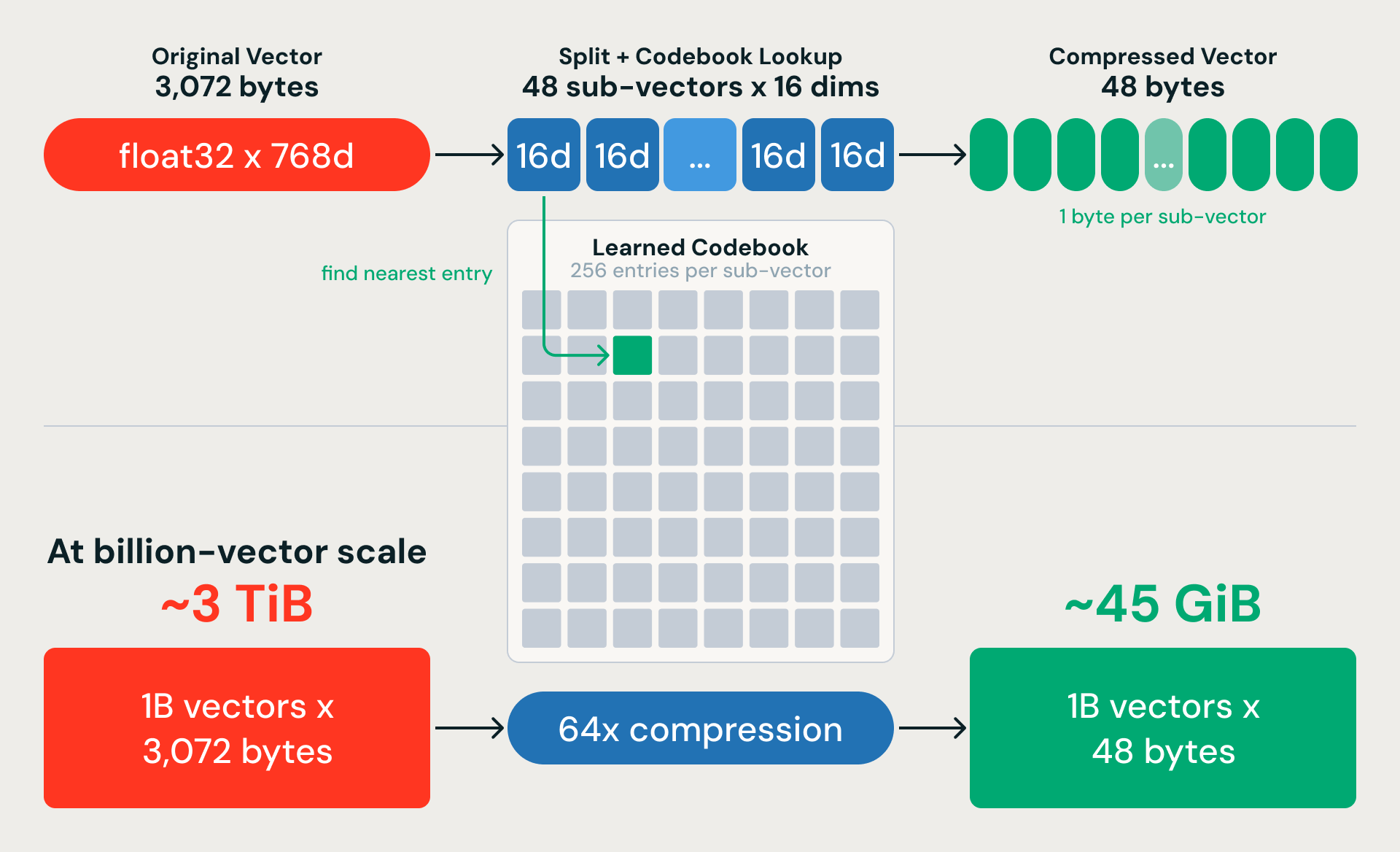
La compression est avec perte, mais un choix de conception clé permet de récupérer la majeure partie de la précision : nous entraînons PQ sur des vecteurs résiduels (la différence entre chaque embedding et son centroïde K-means le plus proche) plutôt que sur les embeddings bruts. K-means capture la structure à grande échelle ; PQ n'a besoin que de coder la variation fine au sein de chaque partition.
De l'entraînement au stockage
Avec les centroïdes et les carnets de codes PQ entraînés sur l'échantillon, le pipeline traite désormais chaque ligne — attribuant à chaque vecteur un ID de partition (son centroïde le plus proche) et un code PQ compressé. Pour un ensemble de données d'un milliard de lignes, c'est l'étape la plus gourmande en données du pipeline : une tâche Spark sur l'ensemble des données qui calcule les distances et les encodages sur chaque exécuteur.
Vient ensuite le shuffle. Le pipeline repartitionne l'ensemble du dataset par ID de partition, colocalisant physiquement les vecteurs de la même partition IVF dans les mêmes fragments de données sur le stockage d'objets. Ce processus est coûteux — des téraoctets de données se déplacent entre les exécuteurs — mais c'est ce qui rend les queries rapides. Sans colocalisation, l'interrogation d'une seule partition IVF disperserait les lectures sur des milliers de fichiers. Avec elle, la même interrogation n'atteint qu'une poignée de fragments contigus.
L'écriture produit trois sorties, chacune optimisée pour un chemin de requête différent :
- Index vectoriel — codes PQ compressés et métadonnées de partition, écrits dans un format que le moteur de requête charge en mémoire pour une recherche ANN rapide.
- Index de mots-clés — fichiers d'index inversés pour le filtrage des métadonnées et la recherche hybride par mots-clés.
- Données brutes — embeddings en pleine précision stockés dans un format colonnaire optimisé à la fois pour les analyses séquentielles et l'accès aléatoire, récupérés à la demande lors du re-classement.
Toutes les trois sont écrites sous forme de fragments immuables : une fois écrits, ils ne sont jamais modifiés. Lorsque l'écriture est terminée, un manifeste de version publie le nouvel index de manière atomique. C'est le contrat entre l'ingestion et le service : un ensemble de fragments de données immuables et alignés sur les partitions sur le stockage d'objets, prêts à être lus directement par le moteur de requêtes.
Ingestion à l'échelle de la montée en charge
La version optimisée pour le stockage prend en charge les index de plus d'un milliard de vecteurs à 768 dimensions — une avancée majeure par rapport à la recherche vectorielle standard, qui est limitée à 320 millions de vecteurs.
Comme l'ingestion s'exécute sur des clusters Spark éphémères, entièrement découplée du service, la mise à l'échelle consiste simplement à ajouter des exécuteurs. En pratique, cela se traduit par des améliorations d'un ordre de grandeur sur les créations d'index en production :

Une fois l'index écrit et publié de manière atomique sur le stockage d'objets, la question suivante est : comment servir les requêtes sur cet index assez rapidement pour la production ?
Un moteur de requête pour le stockage d'objets
La séparation du stockage et du compute résout le problème de coût. Mais cela en introduit un nouveau : chaque query implique désormais des allers-retours réseau vers le stockage d'objets. L'index compressé, suffisamment petit pour tenir en mémoire, est chargé au startup, mais les embeddings en pleine précision restent dans le stockage blob et sont récupérés à la demande ou servis à partir d'un cache de disque local. La couche de service doit être suffisamment rapide pour que le déplacement des données hors du nœud ne compromette pas la latence des requêtes.
Anatomie d'une query
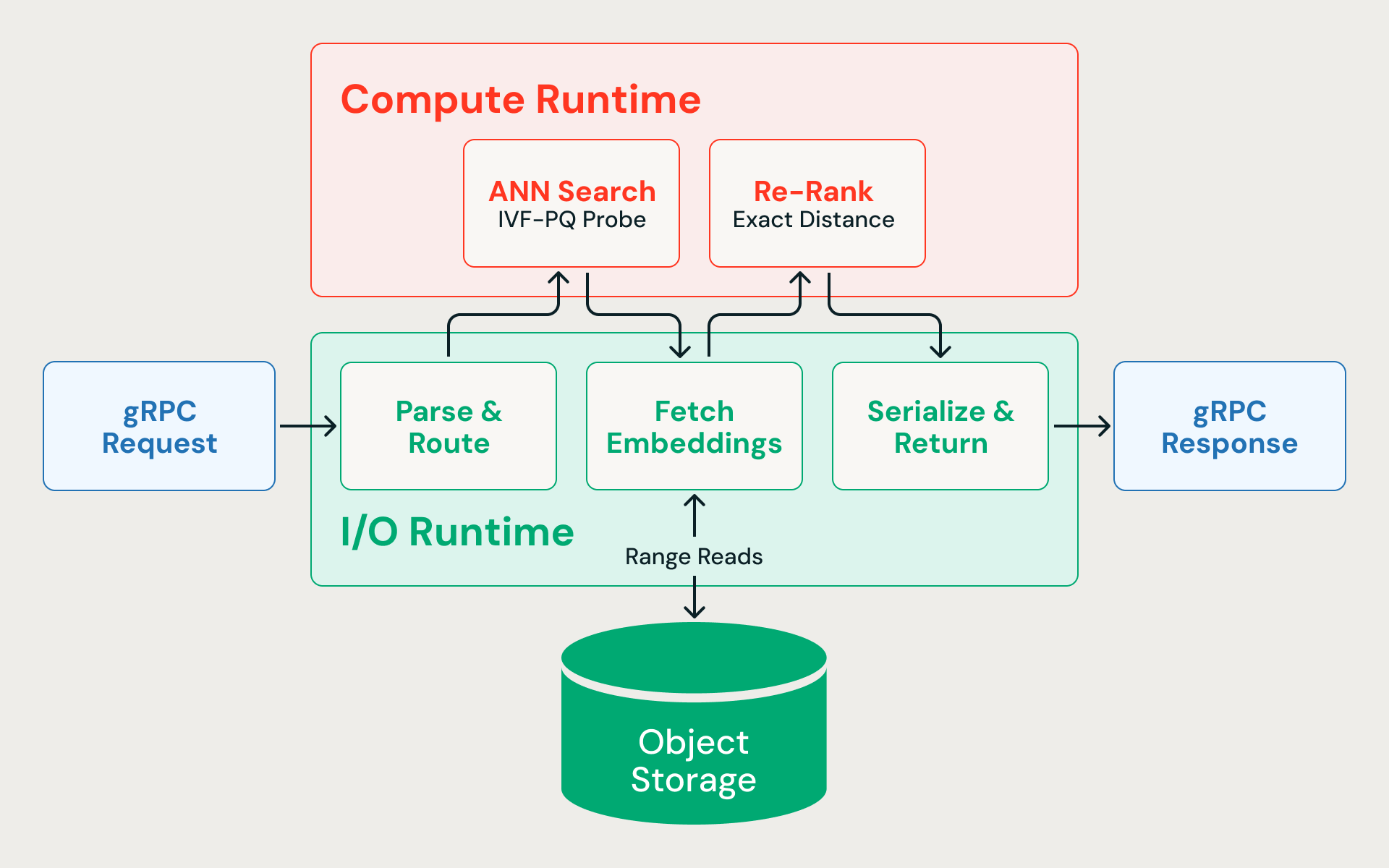
Voici ce qui se passe lorsqu'une recherche des plus proches voisins atteint le moteur :
- Analyse et routage (I/O). La requête gRPC arrive sur l'environnement d'exécution I/O asynchrone, est désérialisée et routée vers le bon index.
- Recherche ANN (CPU). Le vecteur de query est comparé aux centroïdes des clusters IVF pour identifier les partitions les plus pertinentes. Seules ces partitions sont sondées, analysant les vecteurs compressés pour calculer des distances approximatives. La recherche récupère délibérément plus de candidats que nécessaire — par exemple, 400 lorsque l'appelant en demande 10 — car les distances quantifiées sont approximatives et un filet initial plus large améliore le rappel final après le re-classement.
- Récupération des vecteurs en pleine précision (E/S). Les lectures simultanées de plages d'octets récupèrent les embeddings bruts pour chaque candidat depuis le stockage cloud. Comme le pipeline d'ingestion colocalise les lignes de la même partition IVF dans le même fragment de données, ces lectures sont élaguées par partition, ciblant un petit nombre de fichiers au lieu d'accéder de manière aléatoire à l'ensemble du jeu de données. Cette étape est la principale cause de la latence de bout en bout.
- Reclassement (CPU). Les embeddings pleine précision sont évalués à l'aide d'un calcul de distance exact, récupérant ainsi la précision perdue lors de la compression.
- Sérialisation et retour (E/S). Les N meilleurs résultats finaux sont sérialisés avec leurs métadonnées associées et renvoyés à l'appelant.
Chaque query alterne entre des E/S asynchrones et des calculs dépendants du CPU. Si les calculs de distance bloquent le runtime asynchrone, les lectures de stockage en attente s'accumulent et la latence augmente en flèche.
Deux environnements d'exécution
La solution est de ne jamais les laisser se disputer les mêmes threads. Le query engine — écrit en Rust pour une latence prévisible sans pauses GC — répartit l'exécution sur deux pools de threads dédiés : un pour les E/S asynchrones, un pour les calculs vectoriels liés au CPU. Aucune des charges de travail ne peut prendre le pas sur l'autre.
Le runtime d'E/S s'exécute sur l'exécuteur asynchrone Tokio et gère l'analyse des requêtes gRPC, les lectures de plages du stockage blob, la communication inter-services et la sérialisation des réponses. Comme les lectures du stockage constituent le goulot d'étranglement de la latence, ce runtime doit maintenir des centaines de requêtes simultanées en cours sans blocage.
Le runtime de compute exécute les calculs de distance vectorielle, le sondage de partition et le reclassement sur son propre pool de threads. Un sous-ensemble des cœurs de CPU est explicitement réservé pour le runtime d'E/S — compute n'est jamais autorisé à consommer toutes les ressources de la machine.
Fusion des lectures
Au-delà de l'isolation des threads, le chemin d'E/S lui-même nécessitait un ajustement. Le profilage initial a révélé que le moteur émettait de nombreuses petites lectures de plage à vecteur unique vers le stockage d'objets. Chaque appel entraîne une surcharge par requête et une variabilité de la latence — avec de longues traînes atteignant des centaines de millisecondes — de sorte que de nombreuses petites requêtes signifiaient une variance de latence par query élevée.
La solution a été le regroupement des lectures : au lieu d'effectuer une lecture de plage par vecteur, la couche de stockage trie les requêtes de plage d'octets en attente par décalage de fichier et fusionne toutes celles qui se trouvent dans une fenêtre de taille de bloc configurable en une seule lecture. Moins de requêtes, mais plus volumineuses, signifie moins de surcharge par appel, mais chaque lecture fusionnée récupère également des octets dont la requête n'a pas besoin, ce qui entraîne une amplification de lecture. Le compromis a nécessité un réglage empirique.
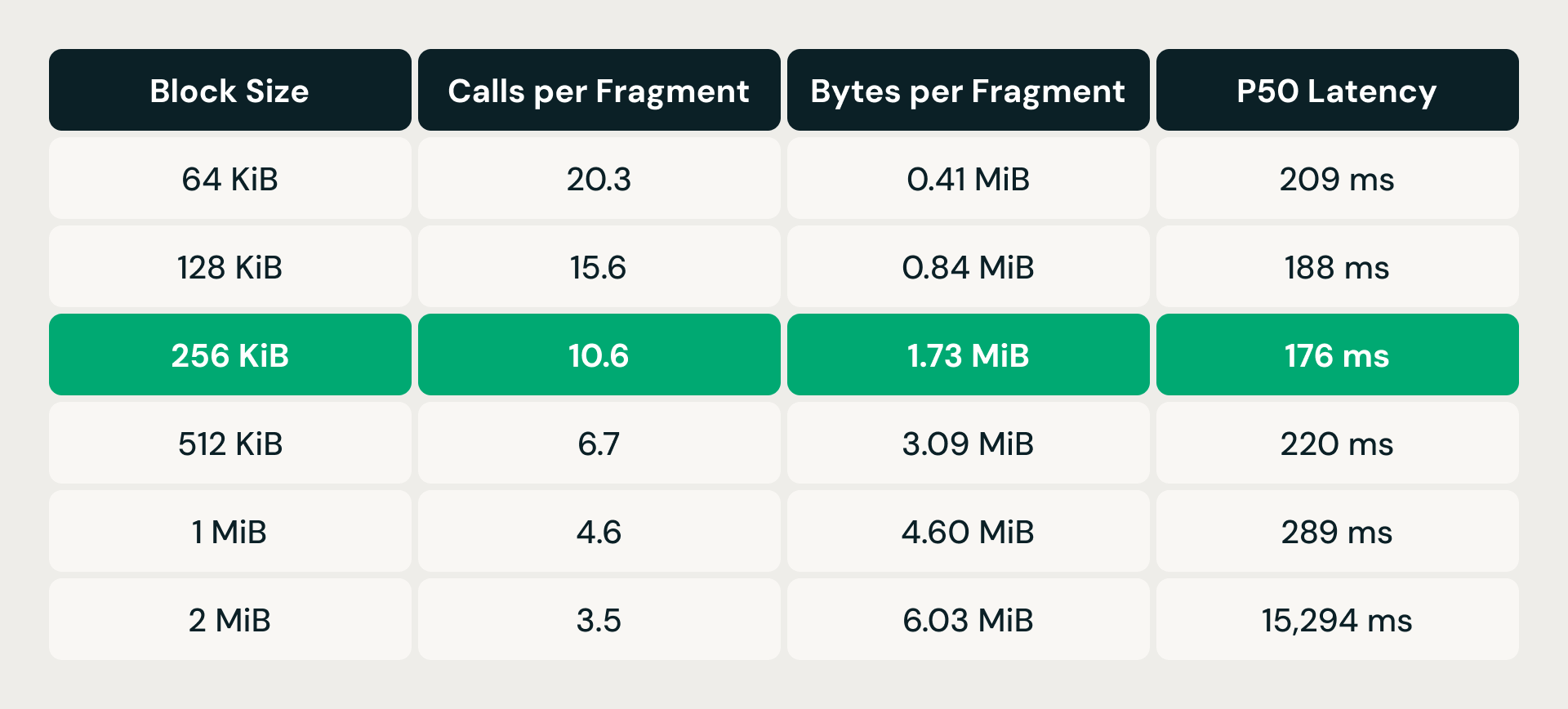
À 64 KiB, chaque fragment de données nécessitait plus de 20 appels de stockage, mais récupérait moins d'un demi-mégaoctet — la surcharge par requête était prédominante. Le doublement de la taille du bloc a réduit régulièrement le nombre d'appels, et la latence s'est améliorée jusqu'à 256 KiB. Mais au-delà de ce point, l'amplification de lecture a pris le dessus : à 512 KiB, la latence est remontée au-dessus du niveau de référence de 64 KiB, malgré un nombre d'appels bien inférieur. À 2 MiB, elle a explosé pour dépasser les 15 secondes. Le point idéal de 256 KiB a réduit les appels de près de moitié tout en maintenant l'amplification de lecture sous 2 MiB par fragment, offrant ainsi la latence p50 la plus faible de toutes les configurations testées.
Synthèse
Dans cette architecture, tout est un compromis entre la latence des requêtes, la scalabilité et le coût. Pour 768 dimensions et les 10 meilleurs résultats, le rappel (la fraction des plus proches voisins réels retournés) reste supérieur à 94 % à 10 millions de vecteurs, supérieur à 91 % à 100 millions, et se maintient à 90 % même à un milliard : l'étape de reclassement, qui récupère les vecteurs en pleine précision depuis le stockage d'objets et recalcule les distances exactes, récupère la précision que les codes compressés seuls perdraient à grande échelle. Cet aller-retour de reclassement est également ce qui domine le temps de query — les queries renvoient une réponse en environ 300 millisecondes pour 10 millions de vecteurs et environ 500 millisecondes pour un milliard, contre 20 à 50 millisecondes sur les Endpoints Standard, qui conservent tout en mémoire.
Ce que vous obtenez pour ces quelques millisecondes supplémentaires : la création d'index à l'échelle du milliard de vecteurs s'effectue en moins de 8 heures, soit 20 fois plus rapidement que la version Standard sur les grands ensembles de données. La quantification de produit compresse l'empreinte mémoire de plus d'un ordre de grandeur, l'ingestion s'exécute sur des clusters Spark éphémères qui libèrent les Ressources après chaque construction, et le découplage du stockage et du service évite le sur-provisionnement de part et d'autre. Le résultat est un coût jusqu'à 7 fois inférieur pour les clients, à échelle égale.
Pour de nombreuses charges de travail — recherche sémantique, pipelines de recommandation, génération augmentée par la récupération — cet arbitrage favorise clairement la montée en charge et le coût. Les étapes post-récupération (classement, filtrage, génération LLM) dominent souvent le temps de bout en bout, rendant la diff�érence entre 40 et 400 millisecondes invisible pour l'utilisateur final. Pour le service sensible à la latence où chaque milliseconde compte, la recherche vectorielle standard reste le meilleur outil. Les deux options sont complémentaires — des outils différents pour des charges de travail différentes.
Ce que nous avons appris
Créer un système de recherche vectorielle à partir de zéro, plutôt que d'optimiser celui que nous avions, nous a obligés à faire une série de paris qui ne sont payants que s'ils sont combinés.
La séparation du stockage et du calcul ne fonctionne que si le moteur de requête est suffisamment rapide. Déplacer les données hors du nœud permet de faire des économies, mais cela ajoute des E/S à chaque query — qu'il s'agisse d'allers-retours réseau vers un stockage d'objets ou de lectures depuis un cache disque local. Le moteur Rust à double runtime existe spécifiquement pour absorber cette latence : les E/S asynchrones maintiennent des centaines de lectures en cours pendant que les threads CPU gèrent le calcul des distances sans blocage. Sans ce moteur, l'architecture fournirait un stockage bon marché et des queries lentes — ce qui n'est pas un compromis convaincant.
L'indexation distribuée ne fonctionne que si le format d'index la prend en charge. Le développement de K-means et de PQ sur Spark nous offre une montée en charge horizontale pour l'ingestion, mais la sortie doit pouvoir être servie directement par le moteur de query depuis le stockage d'objets, sans étape de reconstruction. Le format de stockage personnalisé (fragments de données immuables, manifestes de transactions séparés, sémantique ACID sur le stockage cloud) boucle la boucle. L'ingestion écrit directement dans le format lu par le moteur de requête.
La compression est le levier économique. La quantification de produit ne réduit pas seulement le coût de la mémoire. Elle change la viabilité de l'architecture. Sans ce niveau de compression, le stockage en mémoire de codes quantifiés pour un milliard de vecteurs nécessiterait encore des téraoctets de RAM, et l'avantage en termes de coût par rapport à la recherche vectorielle standard s'évaporerait. La PQ permet de conserver la phase de recherche ANN en mémoire tout en transférant tout le reste vers le stockage d'objets.
Il ne s'agit pas d'optimisations indépendantes. Supprimez-en une seule, et le système devient trop coûteux, trop lent à construire ou trop lent à servir pour être utilisable en pratique.
Conclusion
Les problèmes difficiles à venir découlent directement de ces compromis. Améliorer encore les performances des requêtes — réponses plus rapides, débit plus élevé, meilleure simultanéité — grâce à une mise en cache plus intelligente, un stockage hiérarchisé et des représentations en mémoire plus denses. Rendre les mises à jour quasi temps réel à l'échelle du milliard. Aller au-delà de la distance vectorielle brute comme signal de classement final — vers un classement appris à plusieurs étapes qui combine la similarité vectorielle, la pertinence des mots-clés et le contexte du domaine pour obtenir des résultats qui ne sont pas seulement les plus proches, mais les plus utiles.
Nous pensons que la prochaine génération de produits d'IA sera construite sur une infrastructure qui n'a pas encore été inventée, et que les ingénieurs qui la construiront façonneront ce que l'IA peut faire. Si vous voulez en faire partie, venez construire avec nous!
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.