Développer et déployer des JARs Serverless
par Achille Negrier, Edward Feng, Giorgi Kikolashvili et Shiyu Wang
- Exécutez des JARs Serverless écrits en Scala ou Java, avec des temps de démarrage instantanés et aucune gestion de cluster.
- Développez dans votre IDE préféré en utilisant Databricks Connect, en testant avec des données réelles et des environnements similaires à la production.
- Payez uniquement pour le travail effectué avec une facturation élastique basée sur l'utilisation, et non pour le temps d'inactivité ou l'acquisition d'instances.
JARs Serverless et Databricks Connect pour Scala
Les JARs Serverless permettent aux équipes de créer et d'exécuter des tâches Spark en Scala et Java sur une infrastructure Serverless entièrement gérée. Les équipes peuvent continuer à construire des pipelines Spark de qualité production dans les langages qu'elles maîtrisent déjà, avec des mises à niveau automatisées et sans la charge opérationnelle de la gestion des clusters :
- Démarrage rapide : Avec Serverless, les tâches Scala et Java démarrent en quelques secondes au lieu de quelques minutes. Les ingénieurs peuvent exécuter et itérer sur le code immédiatement, sans attendre que les clusters démarrent.
- Mises à niveau sans version : Serverless s'exécute en continu sur la dernière version prise en charge du runtime Spark, vous n'avez donc jamais à planifier ou gérer les mises à niveau de Databricks Runtime.
- Aucune infrastructure à gérer : Pas de provisionnement de cluster, pas de planification de capacité, et pas de gestion de runtime. Databricks gère automatiquement l'infrastructure, la mise à l'échelle et l'optimisation des performances, afin que les développeurs puissent se concentrer sur l'écriture du code.
- Payez uniquement pour ce que vous utilisez : Au lieu de payer pour des clusters toujours actifs ou une capacité inactive, les équipes ne sont facturées que pour le calcul réellement utilisé.
Comment fonctionnent les JARs Serverless ?
Vous pouvez exécuter des JARs avec Lakeflow Jobs sur l'infrastructure Serverless. Les JARs Serverless sont construits sur Spark 4 (Scala 2.13) et Spark Connect, utilisant la même architecture que Python. Le découplage du code utilisateur du moteur permet des mises à niveau sans version, supprime les conflits de dépendances et permet des contrôles d'accès natifs et granulaires avec Lakeguard.
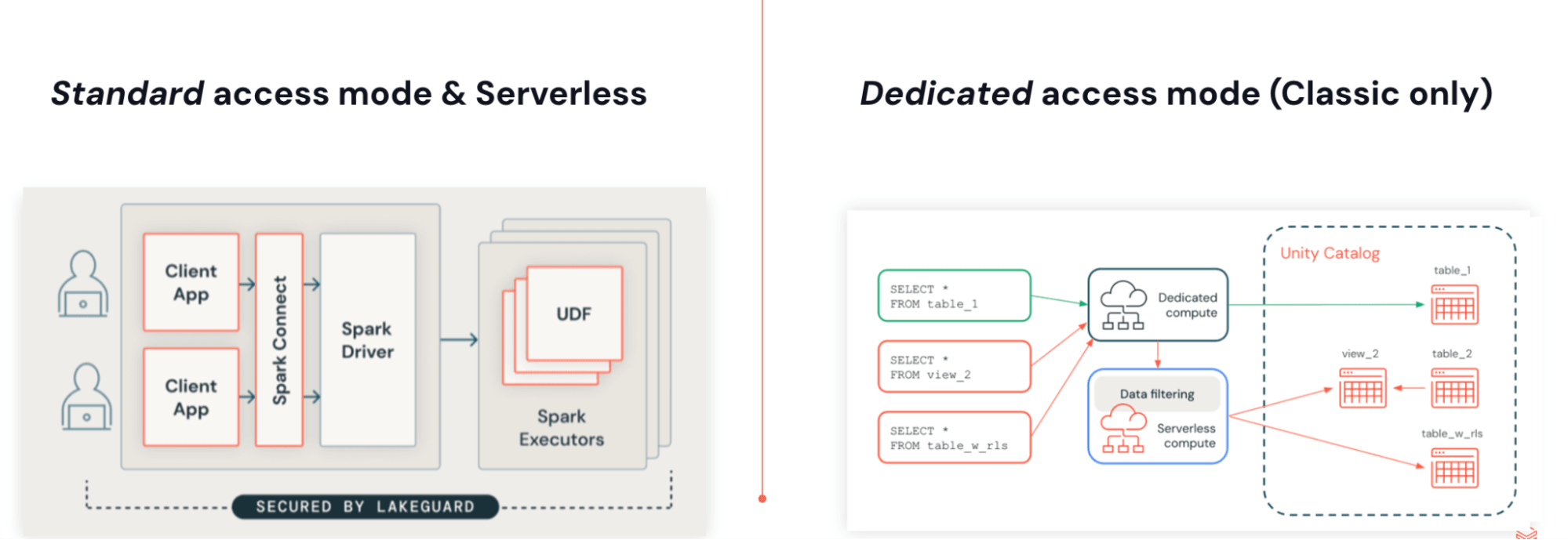
Cette architecture présente quelques avantages clés :
- Exécution sans version : Les applications ne sont plus liées à une version spécifique de Databricks Runtime. Serverless s'exécute toujours sur la dernière version prise en charge, éliminant le besoin de planifier, programmer ou gérer les mises à niveau de Databricks Runtime.
- Contrôles d'accès natifs et granulaires avec Lakeguard : Comme toute l'exécution se fait sur le serveur, Databricks peut appliquer des filtres au niveau des lignes et des contrôles d'accès basés sur les attributs (ABAC) à faible coût.
- Ensemble de dépendances léger et indépendant : L'environnement Serverless s'exécute de manière isolée de Spark, il peut donc fournir un ensemble de dépendances indépendant et réduit, ce qui élimine également les conflits de dépendances.
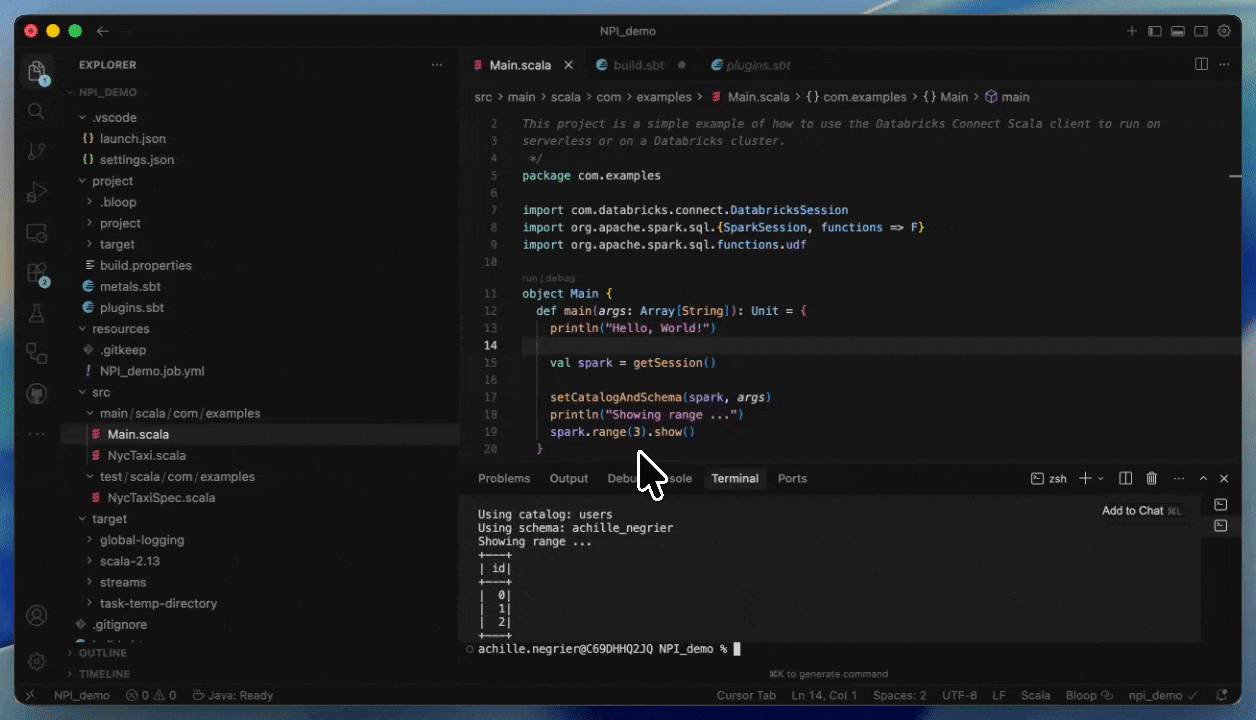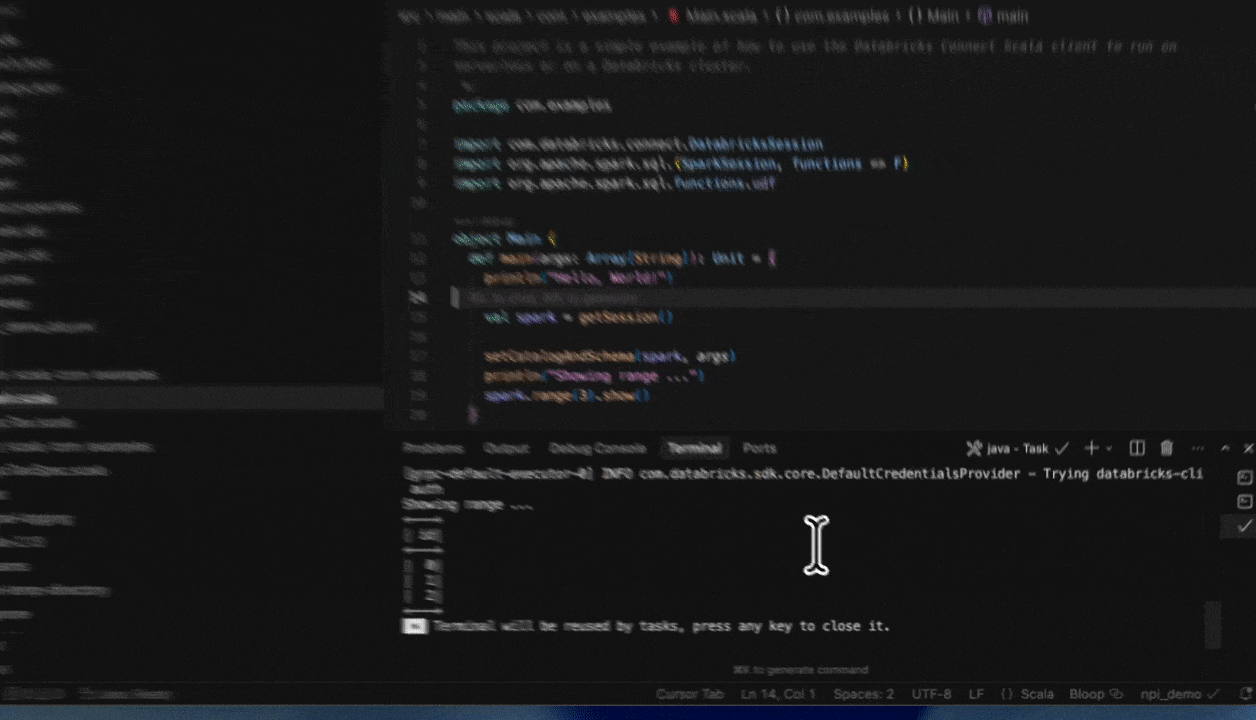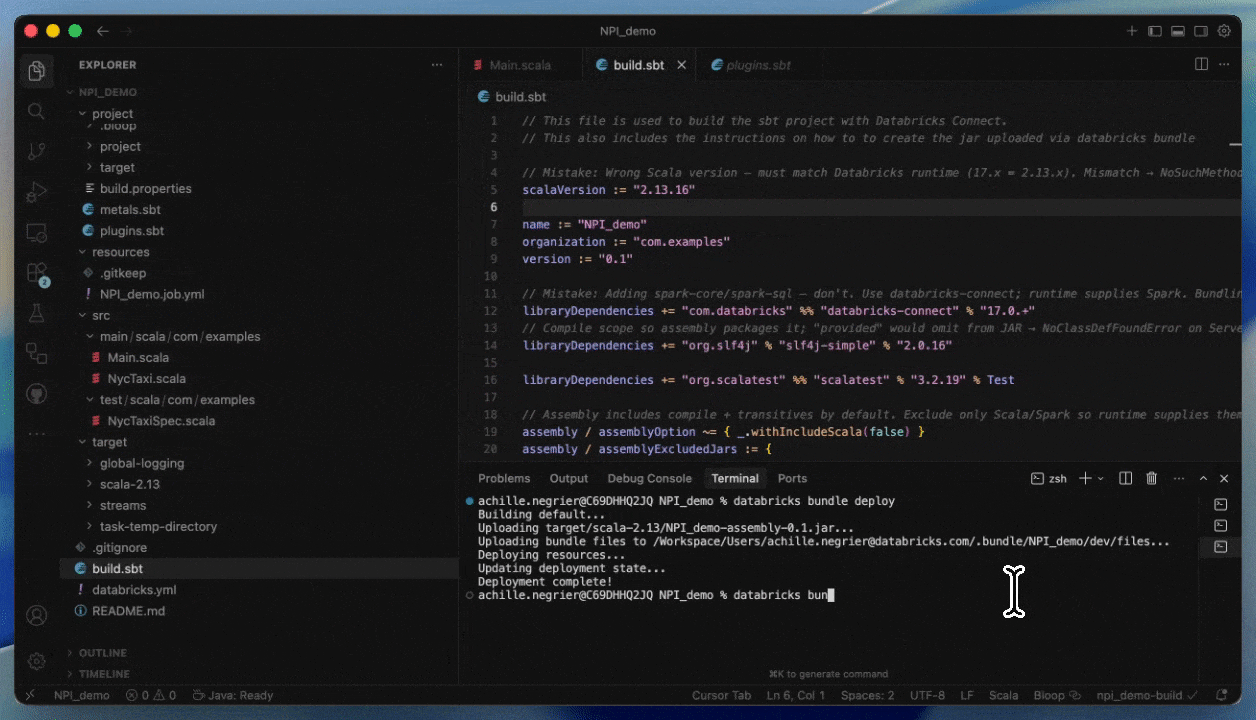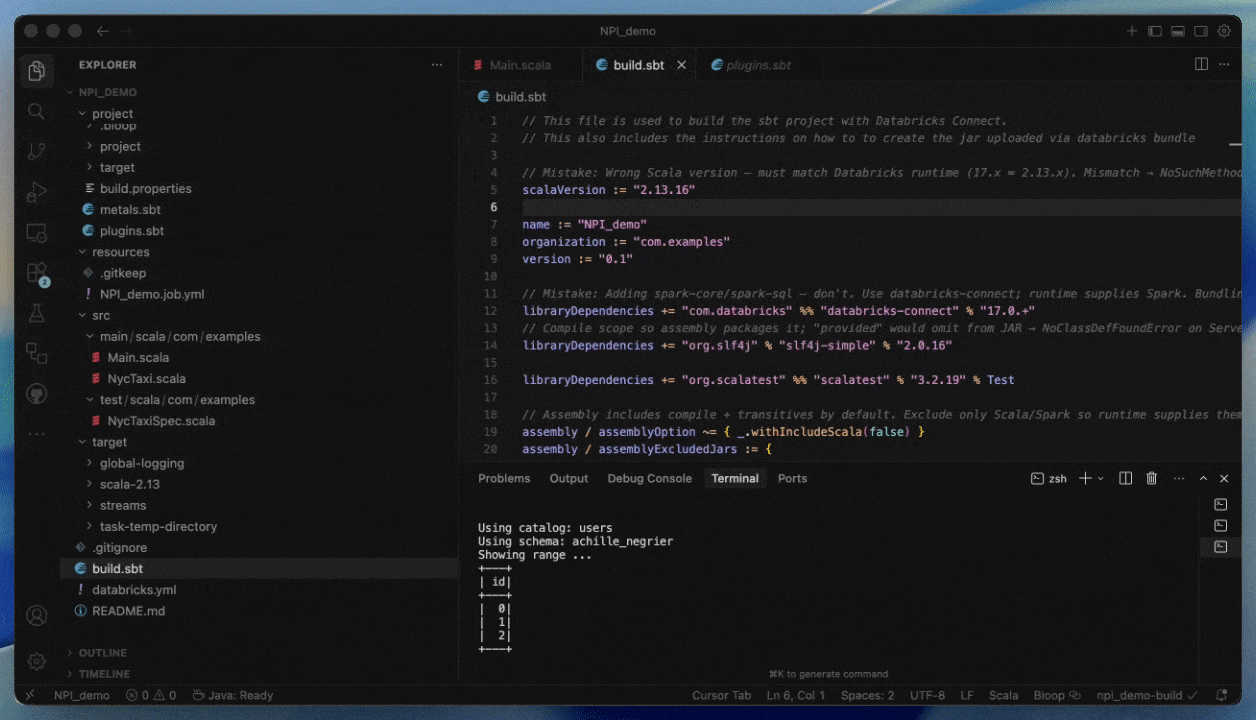
Développer avec Databricks Connect et Databricks Asset Bundles
Avec Databricks Connect, vous pouvez écrire et déboguer du code interactivement dans votre IDE préféré, comme IntelliJ ou Cursor, en utilisant l'infrastructure Serverless avec des temps de démarrage quasi instantanés.
Cela rend les cycles de développement plus rapides et plus fiables, car vous pouvez tester avec des données réelles et des environnements sans quitter votre IDE. Une fois le développement terminé, vous pouvez mettre votre tâche en production en utilisant Databricks Asset Bundles.
Comment déployer sur Serverless en fournissant un JAR
Étape 1 : Compiler votre JAR pour Serverless
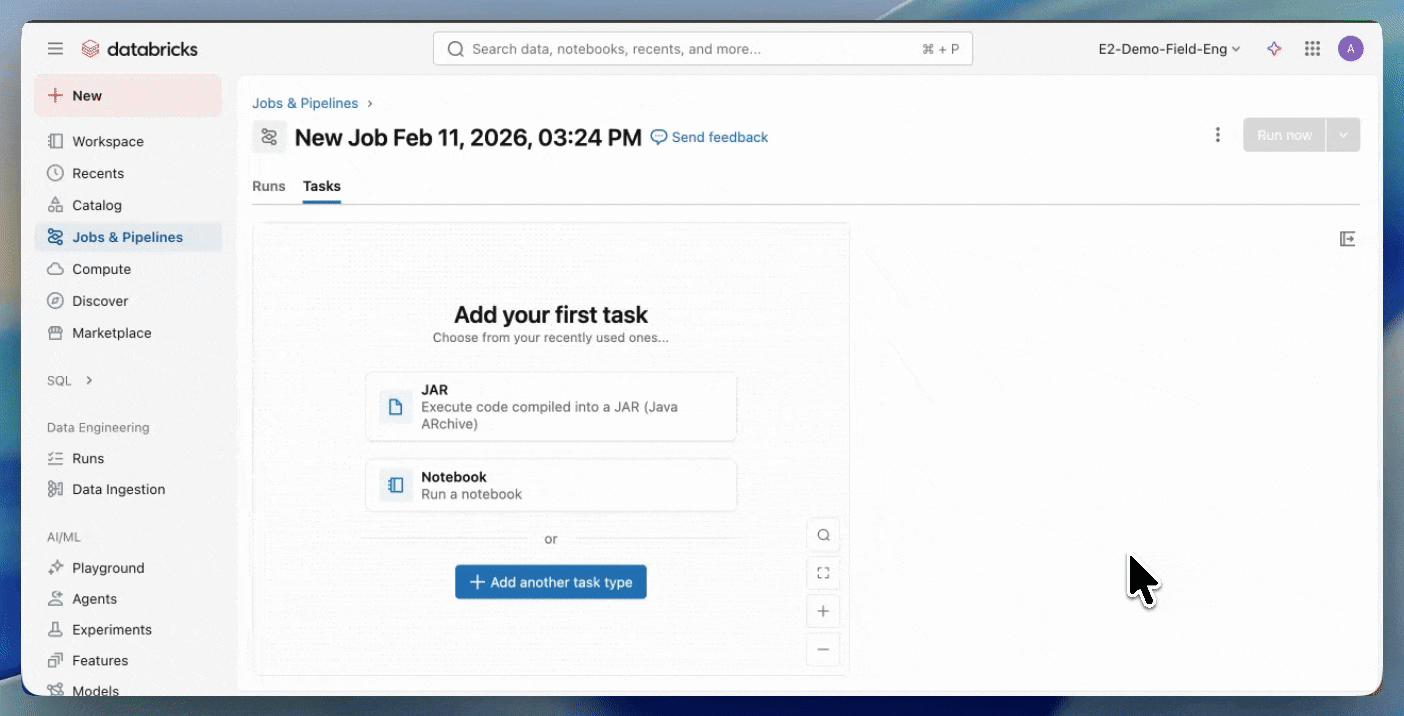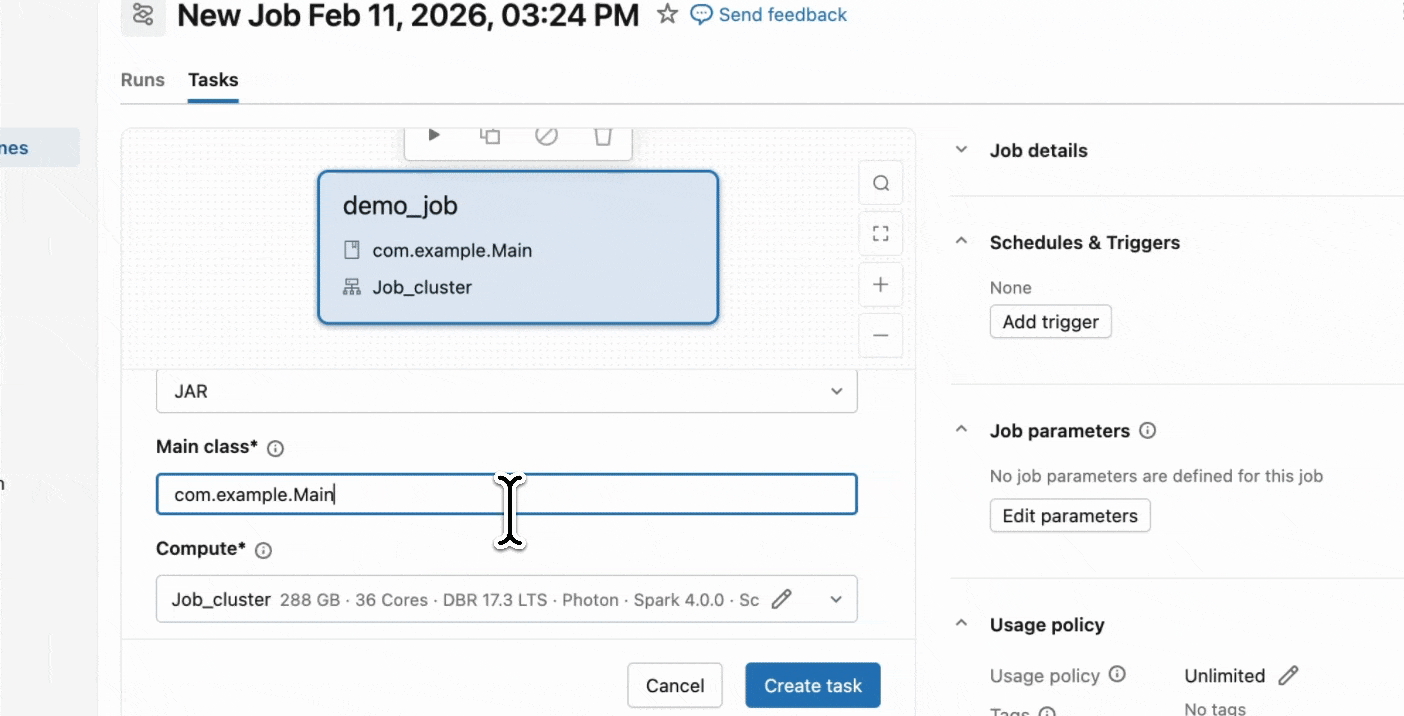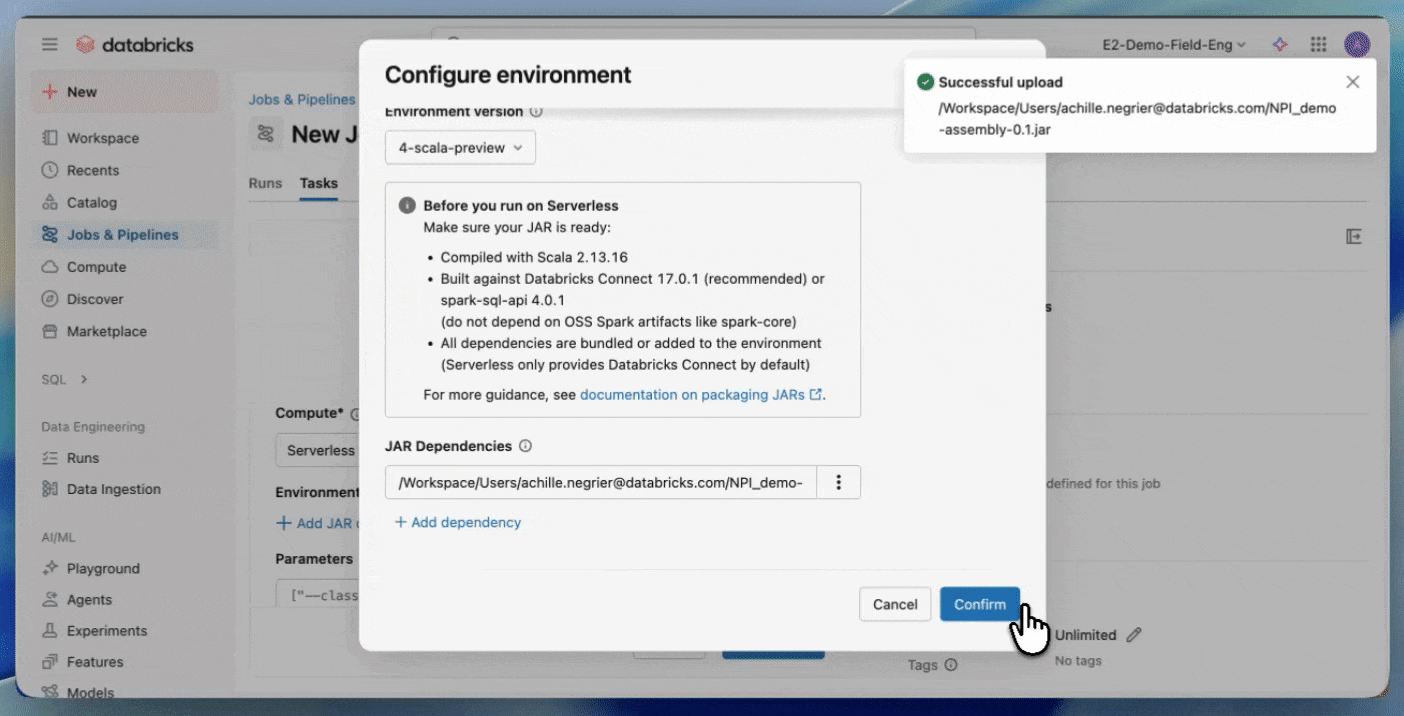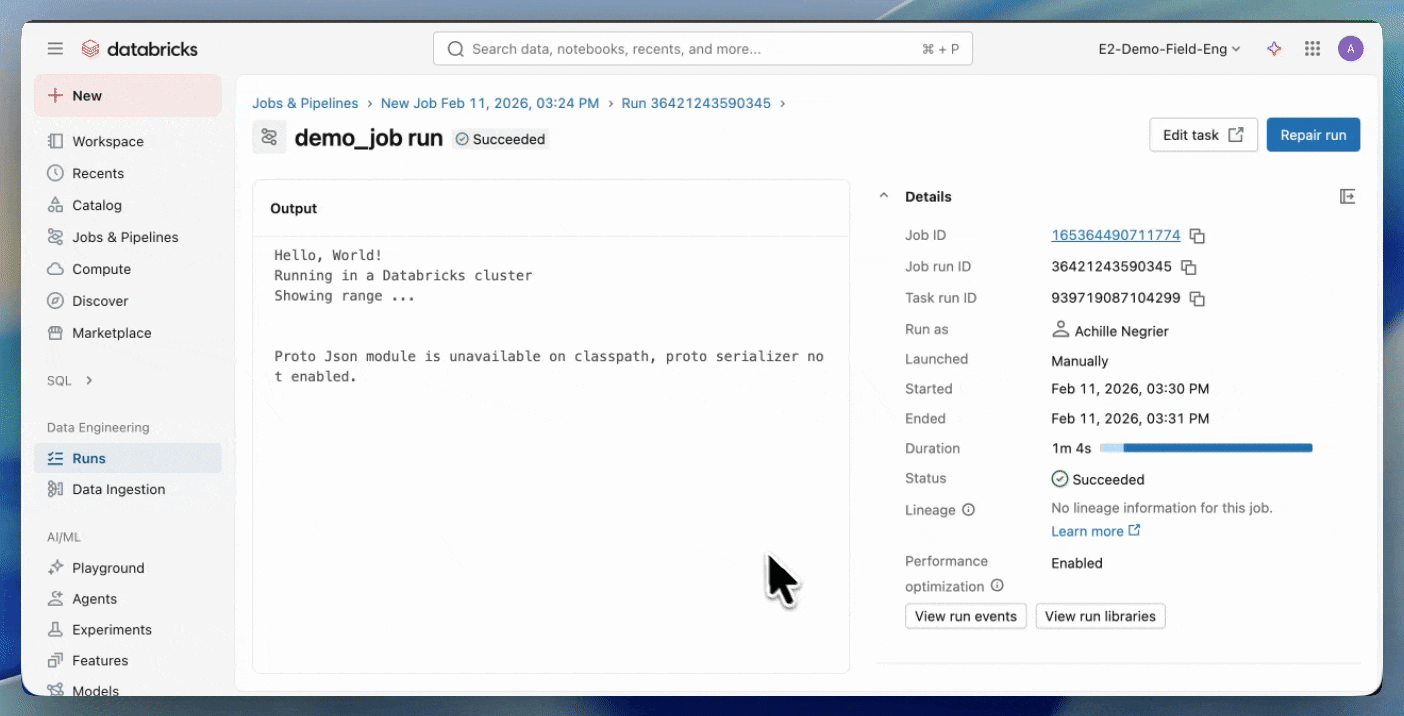
- Compilez avec Spark 4 (Scala 2.13) et Spark Connect
- Regroupez toutes les dépendances non-Spark explicitement ou fournissez-les sous forme de JARs supplémentaires
Étape 2 : Créer une tâche Serverless
- Téléchargez votre JAR dans un volume Unity Catalog ou dans un dossier de l'espace de travail UC.
- Créez une nouvelle tâche en utilisant une tâche JAR et sélectionnez Serverless comme infrastructure.
Commencez avec les JARs Serverless.
Pour commencer rapidement, suivez le tutoriel sur le développement et le déploiement de tâches Scala à l'aide du modèle Databricks Asset Bundle. Pour un tutoriel sur la compilation manuelle d'un JAR, consultez Exécuter du code Scala sur l'infrastructure Serverless.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.