DSPy sur Databricks
Un framework pour programmer le RAG et d'autres systèmes d'IA composés
par Arnav Singhvi, Michael Carbin et Matei Zaharia
Les grands modèles de langage (LLM) suscitent un intérêt pour une interaction homme-IA efficace grâce à l'optimisation des techniques de prompting. L'« ingénierie de prompt » est une méthodologie croissante pour adapter les sorties des modèles, tandis que des techniques avancées comme la Génération Augmentée par Récupération (RAG) améliorent les capacités génératives des LLM en récupérant et en répondant avec des informations pertinentes.
DSPy, développé par le Stanford NLP Group, est devenu un framework pour construire des systèmes d'IA composés par « programmation, pas prompting, des modèles fondamentaux ». DSPy prend désormais en charge les intégrations avec les points de terminaison développeur Databricks pour Model Serving et AI Search.
Ingénierie d'IA Composée
Ces techniques de prompting signalent un passage vers des « pipelines de prompting » complexes où les développeurs d'IA intègrent des LLM, des modèles de récupération (RM) et d'autres composants lors du développement de systèmes d'IA composés.
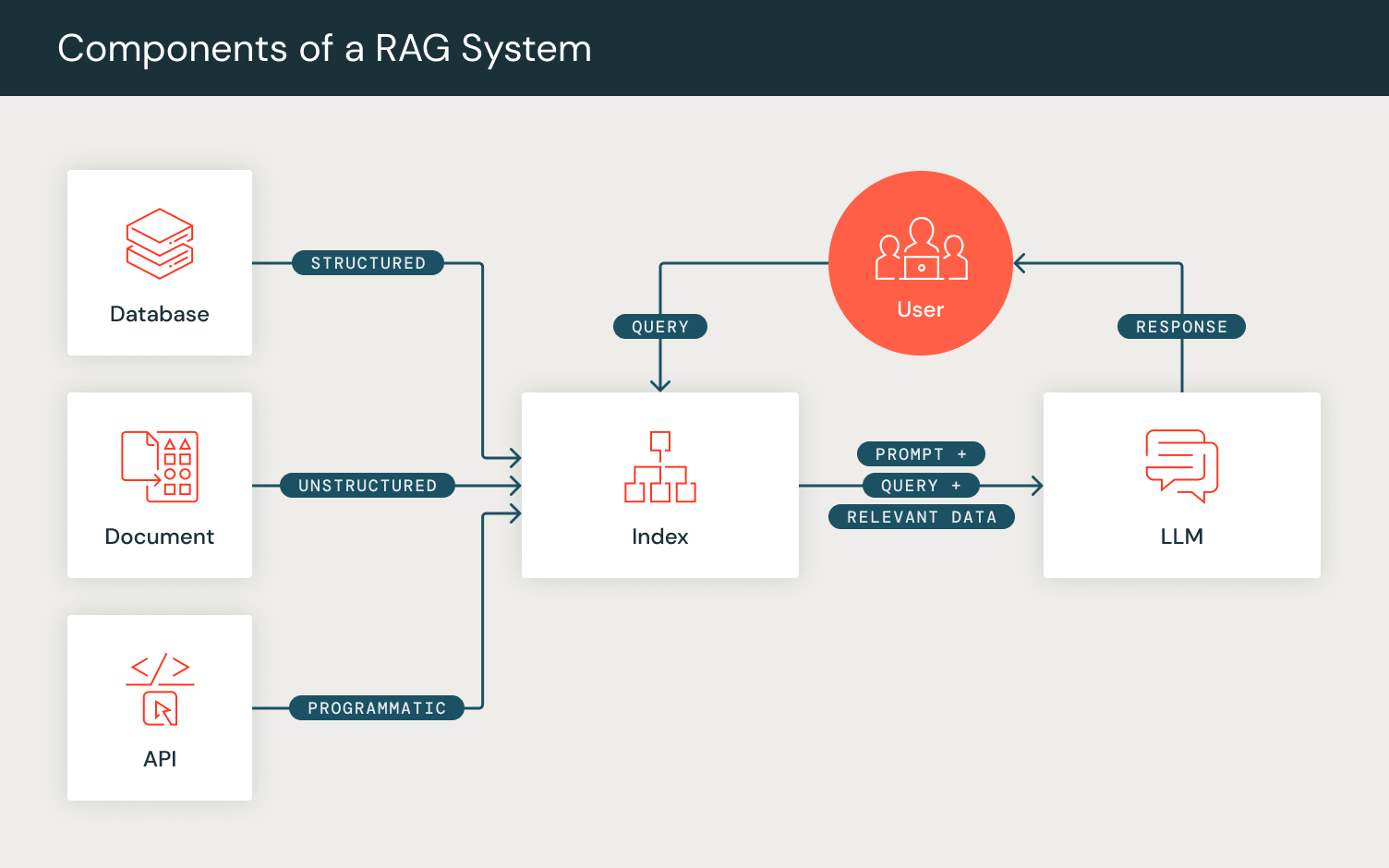
Programmation pas Prompting : DSPy
DSPy optimise les performances des systèmes pilotés par l'IA en composant des appels LLM avec d'autres outils de calcul pour des métriques de tâches en aval. Contrairement à l'« ingénierie de prompt » traditionnelle, DSPy automatise l'ajustement des prompts en traduisant les signatures en langage naturel définies par l'utilisateur en instructions complètes et en exemples de quelques coups. Reflétant l'optimisation de pipeline de bout en bout comme dans PyTorch, DSPy permet aux utilisateurs de définir et de composer des systèmes d'IA couche par couche tout en optimisant pour l'objectif souhaité.
Les programmes dans DSPy ont deux méthodes principales :
- Initialisation : Les utilisateurs peuvent définir les composants de leurs pipelines de prompting comme des couches DSPy. Par exemple, pour tenir compte des étapes impliquées dans RAG, nous définissons une couche de récupération et une couche de génération.
- Nous définissons une couche de récupération `dspy.Retrieve` qui utilise le RM configuré par l'utilisateur pour récupérer un ensemble de passages/documents pertinents pour une requête de recherche saisie.
- Nous initialisons ensuite notre couche de génération, pour laquelle nous utilisons le module `dspy.Predict`, qui prépare en interne le prompt pour la génération. Pour configurer cette couche de génération, nous définissons notre tâche RAG dans un format de signature en langage naturel, spécifié par un ensemble de champs d'entrée (« context, query ») et le champ de sortie attendu (« answer »). Ce module formate ensuite en interne le prompt pour correspondre à ce format défini, puis renvoie la génération à partir du LM configuré par l'utilisateur.
- Forward : Similaire aux passes forward de PyTorch, la fonction forward du programme DSPy permet la composition par l'utilisateur de la logique du pipeline de prompting. En utilisant les couches que nous avons initialisées, nous mettons en place le flux de calcul de RAG en récupérant un ensemble de passages étant donné une requête, puis en utilisant ces passages comme contexte avec la requête pour générer une réponse, en produisant la sortie attendue dans un objet dictionnaire DSPy.
Jetons un coup d'œil à RAG en action en utilisant le programme DSPy et la génération de DBRX.
Pour cet exemple, nous utilisons une question d'échantillon du jeu de données HotPotQA qui comprend des questions nécessitant plusieurs étapes pour déduire la bonne réponse.
Configurons d'abord notre LM et notre RM dans DSPy. DSPy offre une variété d'intégrations de modèles de langage et de récupération, et les utilisateurs peuvent définir ces paramètres pour s'assurer que tout programme défini par DSPy s'exécute selon ces configurations.
Déclarons maintenant notre programme DSPy RAG défini et passons simplement la question en entrée.
Pendant l'étape de récupération, la query est passée à la couche self.retrieve qui produit les 3 meilleurs passages pertinents, qui sont formatés en interne comme suit :
Avec ces passages récupérés, nous pouvons les passer avec notre requête au module dspy.Predict self.generate_answer, correspondant aux champs d'entrée de la signature en langage naturel « context, query ». Cela applique en interne un formatage et une formulation de base, et vous permet de diriger le modèle avec la description exacte de votre tâche sans ingénierie de prompt du LM.
Une fois le formatage déclaré, les champs d'entrée « context » et « query » sont remplis et le prompt final est envoyé à DBRX :
DBRX génère une réponse qui est renseignée dans le champ Réponse : , et nous pouvons observer cette génération d'invite en appelant :
Cela affiche la dernière génération d'invite de l'IL avec la réponse générée "Steve Yzerman", ce qui est la bonne réponse !
DSPy a été largement utilisé dans diverses tâches de modèle linguistique telles que le fine-tuning, l'apprentissage en contexte, l'extraction d'informations, l'auto-amélioration, et de nombreux autres. Cette approche automatisée surpasse le prompting few-shot standard avec des démonstrations écrites par des humains jusqu'à 46 % pour GPT-3.5 et 65 % pour Llama2-13b-chat sur des tâches de langage naturel comme le RAG multi-sauts et des benchmarks mathématiques comme GSM8K.
DSPy sur Databricks
DSPy prend désormais en charge les intégrations avec les points de terminaison développeur Databricks pour la diffusion de modèles et la recherche vectorielle. Les utilisateurs peuvent configurer les API de modèles fondamentaux hébergés par Databricks via le SDK OpenAI via dspy.Databricks. Cela garantit que les utilisateurs peuvent évaluer leurs pipelines DSPy de bout en bout sur les modèles hébergés par Databricks. Actuellement, cela prend en charge les modèles sur les points de terminaison de diffusion de modèles : chat (DBRX Instruct, Mixtral-8x7B Instruct, Llama 2 70B Chat), complétion (MPT 7B Instruct) et embedding (BGE Large (En)).
Modèles de Chat
Modèles de Complétion
Modèles d'Embedding
Modèles de Récupération/Recherche Vectorielle
De plus, les utilisateurs peuvent configurer des modèles de récupération via Databricks AI Search. Suite à la création d'un index et d'un point de terminaison de recherche vectorielle, les utilisateurs peuvent spécifier les paramètres RM correspondants via dspy.DatabricksRM :
Les utilisateurs peuvent configurer cela globalement en définissant l'IL et le RM sur les points de terminaison Databricks correspondants et en exécutant des programmes DSPy.
Avec cette intégration, les utilisateurs peuvent construire et évaluer des applications DSPy de bout en bout, telles que RAG, en utilisant les points de terminaison Databricks !
Consultez le dépôt GitHub officiel de DSPy, la documentation et Discord pour en savoir plus sur la façon de transformer les tâches d'IA générative en pipelines DSPy polyvalents avec Databricks !
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.