Un cadre pour la prévision multi-modèles sur Databricks
par Ryuta Yoshimatsu , Puneet Jain, Tristan Nixon, Sathish Gangichetty, Michael Shtelma et Bryan Smith
Introduction
La prévision des séries chronologiques constitue la base de la gestion des stocks et de la demande dans la plupart des entreprises. En utilisant les données des périodes passées ainsi que les conditions anticipées, les entreprises peuvent prédire les revenus et les unités vendues, ce qui leur permet d'allouer des ressources pour répondre à la demande attendue. Compte tenu de la nature fondamentale de ce travail, les entreprises explorent constamment des moyens d'améliorer la précision des prévisions, leur permettant ainsi de déployer les bonnes ressources au bon endroit et au bon moment tout en minimisant les engagements de capital.
Le défi pour la plupart des organisations réside dans le large éventail de techniques de prévision à leur disposition. Les techniques statistiques classiques, les modèles additifs généralisés, les approches basées sur l'apprentissage automatique et l'apprentissage profond, et maintenant les transformeurs d'IA générative pré-entraînés offrent aux organisations un nombre écrasant de choix, dont certains fonctionnent mieux dans certains scénarios que dans d'autres.
Bien que la plupart des créateurs de modèles revendiquent une précision de prévision améliorée par rapport aux ensembles de données de référence, la réalité est que la connaissance du domaine et les exigences commerciales réduisent généralement le nombre de choix de modèles à une poignée, et seule l'application pratique et l'évaluation par rapport aux ensembles de données d'une organisation peuvent déterminer lequel fonctionne le mieux. Et ce qui est « le mieux » varie souvent d'une unité de prévision à l'autre et même au fil du temps, obligeant les organisations à effectuer des évaluations comparatives continues entre les techniques pour déterminer ce qui fonctionne le mieux à l'instant T.
Dans ce blog, nous présenterons le framework Many Model Forecasting (MMF) pour l'évaluation comparative des modèles de prévision. MMF permet aux utilisateurs d'entraîner et de prédire à l'aide de plusieurs modèles de prévision à grande échelle sur des centaines de milliers à des millions de séries chronologiques à leur granularité la plus fine. Avec la prise en charge de la préparation des données, du backtesting, de la validation croisée, de la notation et du déploiement, le framework permet aux équipes de prévision de mettre en œuvre une solution complète de génération de prévisions utilisant des modèles classiques et de pointe, en mettant l'accent sur la configuration plutôt que sur le codage, minimisant ainsi l'effort requis pour introduire de nouveaux modèles et capacités dans leurs processus. Nous avons constaté dans de nombreuses implémentations clients que ce framework :
- Réduit le délai de mise sur le marché : Avec de nombreux modèles bien établis et de pointe déjà intégrés, les utilisateurs peuvent évaluer et déployer rapidement des solutions.
- Améliore la précision des prévisions : Grâce à une évaluation approfondie et à une sélection de modèles à granularité fine, MMF permet aux organisations de découvrir efficacement des approches de prévision qui offrent une précision améliorée.
- Permet la préparation à la production : En adhérant aux meilleures pratiques MLOps, MMF s'intègre nativement à Databricks, garantissant un déploiement transparent.
Accédez à plus de 40 modèles grâce au framework
Le framework Many Model Forecasting (MMF) est livré sous forme de dépôt Github avec un code source entièrement accessible, transparent et commenté. Les organisations peuvent utiliser le framework tel quel ou l'étendre pour ajouter des fonctionnalités nécessaires à leur organisation spécifique.
MMF inclut une prise en charge intégrée de plus de 40 modèles grâce à l'intégration de certaines des bibliothèques open source de prévision les plus populaires disponibles aujourd'hui, notamment statsforecast, neuralforecast, sktime, r fable, chronos, moirai et moment. Et à mesure que nos clients explorent de nouveaux modèles, nous avons l'intention d'en prendre en charge encore plus.
Avec ces modèles déjà intégrés au framework, les utilisateurs peuvent éliminer le développement redondant de la préparation des données et de l'entraînement des modèles spécifiques à chaque modèle et se concentrer plutôt sur l'évaluation et le déploiement, accélérant ainsi considérablement le délai de mise sur le marché. Ceci est particulièrement avantageux pour les équipes de data scientists et d'ingénieurs en apprentissage automatique disposant de ressources limitées et pour les parties prenantes commerciales désireuses d'obtenir des résultats.
En utilisant MMF, les équipes de prévision peuvent évaluer plusieurs modèles simultanément, permettant à la fois à la logique intégrée et à la logique personnalisée de sélectionner le meilleur modèle pour chaque série chronologique et d'améliorer la précision globale de la solution de prévision. Déployé sur un cluster Databricks, MMF exploite toutes les ressources mises à sa disposition pour accélérer l'entraînement et l'évaluation des modèles grâce au parallélisme automatisé. Les équipes configurent simplement les ressources qu'elles souhaitent utiliser pour l'exercice de prévision et MMF s'occupe du reste.
Concentrez-vous sur les sorties de modèle et les évaluations comparatives
La clé de MMF est la standardisation des sorties du modèle. Lors de l'exécution des prévisions, MMF génère deux tables UC : evaluation_output et scoring_output. La table evaluation_output (Figure 1) stocke tous les résultats d'évaluation de chaque période de backtesting, pour toutes les séries chronologiques et tous les modèles, offrant une vue d'ensemble complète des performances de chaque modèle. Cela inclut les prévisions aux côtés des valeurs réelles, permettant aux utilisateurs de construire des métriques personnalisées qui correspondent aux besoins spécifiques de l'entreprise. Bien que MMF offre plusieurs métriques prêtes à l'emploi, telles que MAE, MSE, RMSE, MAPE et SMAPE, la flexibilité de créer des métriques personnalisées facilite l'évaluation détaillée et la sélection ou l'assemblage de modèles, garantissant des résultats de prévision optimaux.
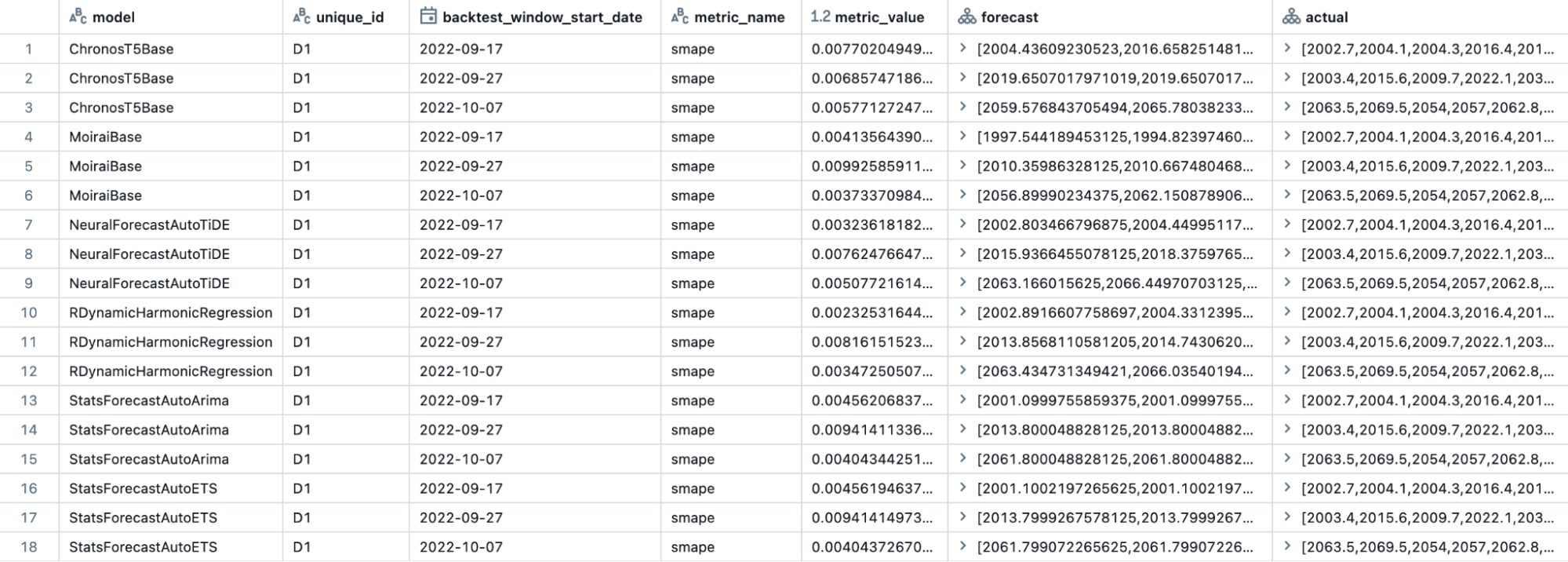
La deuxième table, scoring_output (Figure 2), contient les prévisions pour chaque série chronologique de chaque modèle. En utilisant les résultats d'évaluation complets stockés dans la table evaluation_output, vous pouvez sélectionner les prévisions du modèle le plus performant ou d'une combinaison de modèles. En choisissant les prévisions finales parmi un pool de modèles concurrents ou un assemblage de modèles sélectionnés, vous pouvez obtenir une précision et une stabilité supérieures par rapport à la dépendance à l'égard d'un seul modèle, améliorant ainsi la précision et la stabilité globales de votre solution de prévision à grande échelle.

Facilitez la gestion des modèles grâce à l'automatisation
Construit sur la plateforme Databricks, MMF s'intègre de manière transparente aux capacités de Databricks, en fournissant la journalisation automatisée des paramètres, des métriques agrégées et des modèles (pour les modèles globaux et fondamentaux) à MLflow (Figure 3). Sécurisé dans le cadre de Unity Catalog de Databricks, les équipes de prévision peuvent employer un contrôle d'accès granulaire et une gestion appropriée de leurs modèles, pas seulement de leurs sorties de modèle.

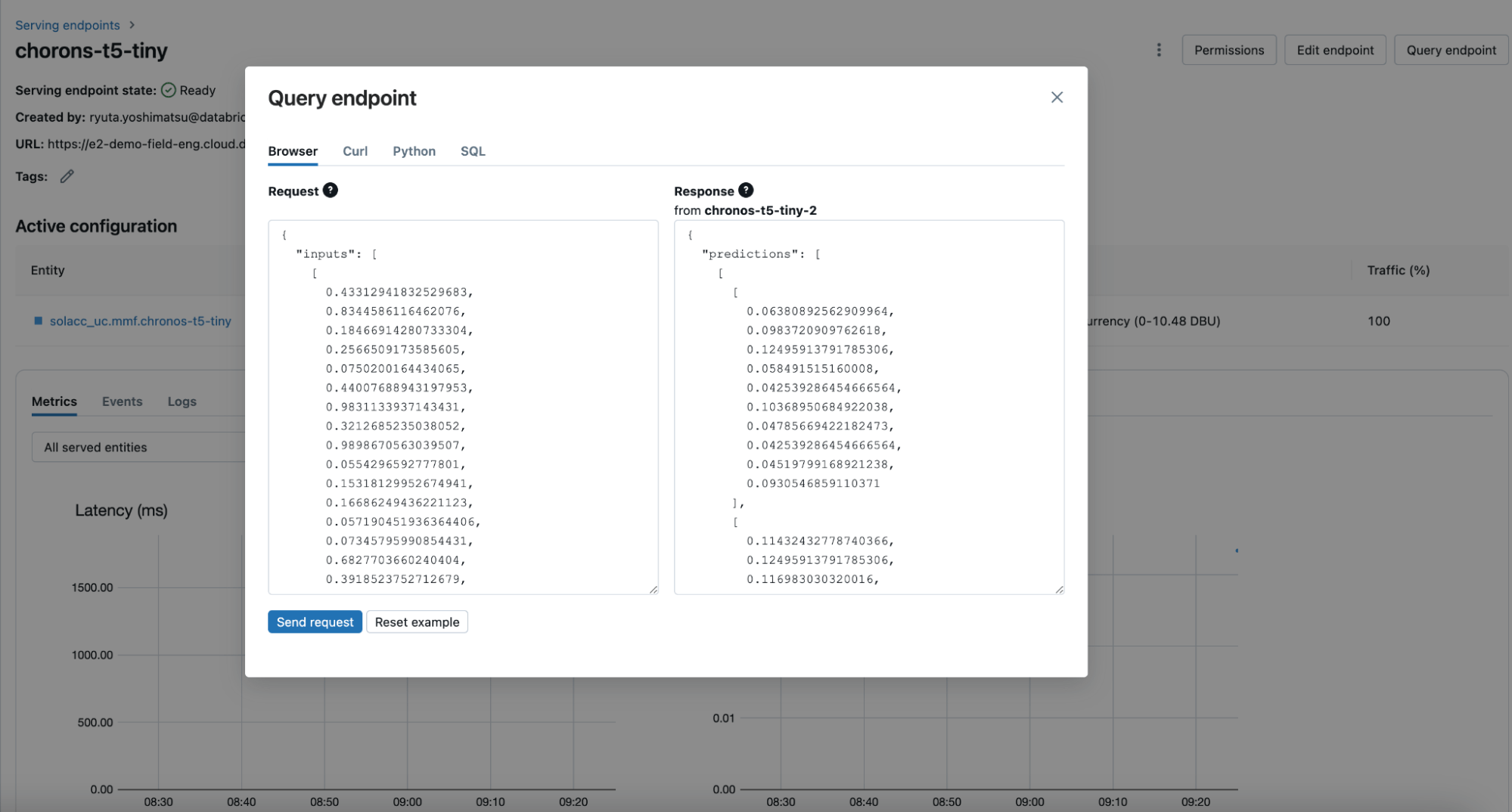
Si une équipe a besoin de réutiliser un modèle (comme c'est courant dans les scénarios d'apprentissage automatique), elle peut simplement le charger sur son cluster en utilisant la méthode load_model de MLflow ou le déployer derrière un point de terminaison en temps réel en utilisant Databricks Model Serving (Figure 4). Avec les modèles fondamentaux de séries chronologiques hébergés dans Model Serving, vous pouvez générer des prévisions à plusieurs étapes à l'avance à tout moment, à condition de fournir l'historique à la bonne résolution. Cette capacité améliore considérablement les applications de prévision à la demande, de surveillance en temps réel et de suivi.
Commencez dès maintenant
Chez Databricks, la génération de prévisions est l'un des cas d'utilisation clients les plus populaires. La nature fondamentale de la prévision pour de nombreux processus métier signifie que les organisations recherchent constamment des améliorations dans la précision des prévisions.
Avec ce framework, nous espérons offrir aux équipes de prévision un accès facile aux fonctionnalités les plus évolutives, robustes et étendues nécessaires pour soutenir leur travail. Grâce au MMF, les équipes peuvent désormais se concentrer sur la production de résultats et moins sur tout le travail de développement requis pour évaluer de nouvelles approches et les rendre prêtes pour la production.
Remerciements
Nous remercions les équipes derrière statsforecast et neuralforecast (Nixtla), r fable, sktime, chronos, moirai, moment et timesfm pour leurs contributions aux communautés open source, qui nous ont donné accès à leurs outils exceptionnels.
Consultez le dépôt MMF et les notebooks d'exemple montrant comment les organisations peuvent commencer à l'utiliser dans leur environnement Databricks.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.