Comment MakeMyTrip a atteint la personnalisation en millisecondes à grande échelle avec Databricks
Découvrez comment le mode temps réel fournit des recommandations de voyage instantanées et le contexte pour les agents IA
par Sitesh Sharma, Aditya Kumar et Navneeth Nair
- Architecture de streaming unifiée : MakeMyTrip a surmonté les goulots d'étranglement de latence de l'ETL traditionnel en adoptant le mode temps réel (RTM) de Databricks, créant ainsi une architecture Spark unifiée sans nécessiter d'autres moteurs spécialisés.
- Personnalisation en millisecondes : En traitant les recherches de voyageurs à grand volume avec un flux de données continu, le RTM a permis des latences P50 inférieures à 50 ms, entraînant directement une augmentation de 7 % des taux de clics des utilisateurs.
- Logique unifiée, innovation plus rapide : En utilisant un moteur unifié, MakeMyTrip peut passer de manière transparente du traitement par lots au traitement en temps réel sans réécrire la logique métier. Cela élimine non seulement la complexité opérationnelle, mais alimente également l'innovation future, facilitant l'alimentation des agents d'IA générative avec le contexte en temps réel dont ils ont besoin pour une prise de décision précise.
Personnalisation en temps réel à grande échelle
Chaque milliseconde compte lorsque les voyageurs recherchent des hôtels, des vols ou des expériences. En tant que plus grande agence de voyages en ligne de l'Inde, MakeMyTrip mise sur la vitesse et la pertinence en temps réel. L'une de ses fonctionnalités les plus importantes est la recherche des hôtels "dernièrement recherchés" : lorsque les utilisateurs tapent dans la barre de recherche, ils s'attendent à une liste personnalisée en temps réel de leurs intérêts récents, basée sur leur interaction avec le système.
À l'échelle de MakeMyTrip, offrir cette expérience nécessite une latence inférieure à la seconde sur un pipeline de production desservant des millions d'utilisateurs quotidiens — pour les lignes d'activité de voyage grand public et d'entreprise. En implémentant le Mode Temps Réel (RTM) de Databricks — le moteur d'exécution de nouvelle génération dans Apache Spark™ Structured Streaming, MakeMyTrip a réussi à atteindre des latences de niveau milliseconde, tout en maintenant une infrastructure rentable et en réduisant la complexité de l'ingénierie.
Le Défi : Latence Ultra-Faible sans Fragmentation Architecturale
L'équipe de données de MakeMyTrip avait besoin d'une latence inférieure à la seconde pour le flux de travail des hôtels "dernièrement recherchés" sur toutes les lignes d'activité. À leur échelle, même quelques centaines de millisecondes de retard créent des frictions dans le parcours utilisateur, impactant directement les taux de clics.
Le mode micro-batch d'Apache Spark introduisait des limites de latence inhérentes que l'équipe ne pouvait pas dépasser malgré un réglage approfondi — livrant constamment une latence d'une à deux secondes, beaucoup trop lente pour leurs exigences.
Ensuite, ils ont évalué Apache Flink sur environ 10 pipelines de streaming ce qui a résolu leurs exigences de latence. Cependant, l'adoption d'Apache Flink comme second moteur aurait introduit des défis importants à long terme :
- Fragmentation architecturale : Maintenir des moteurs séparés pour le traitement en temps réel et par lots
- Duplication de la logique métier : Les règles métier devraient être implémentées et maintenues dans deux bases de code
- Coût opérationnel plus élevé : Doubler l'effort de surveillance, de débogage et de gouvernance sur plusieurs pipelines
- Risques de cohérence : Les résultats risquent de diverger entre le traitement par lots et le traitement en temps réel
- Coûts d'infrastructure : L'exécution et le réglage de deux moteurs augmentent les dépenses de calcul et la charge de maintenance
Pourquoi le Mode Temps Réel : Latence Milliseconde sur une Pile Spark Unique
Parce que MakeMyTrip n'a jamais voulu une architecture à double moteur, Apache Flink n'était pas une option viable à long terme. L'équipe a pris une décision architecturale délibérée : attendre qu'Apache Spark devienne plus rapide, plutôt que de fragmenter la pile.
Par conséquent, lorsque Apache Spark Structured Streaming a introduit le RTM, MakeMyTrip est devenu le premier client à l'adopter. Le RTM leur a permis d'atteindre une latence de niveau milliseconde sur Apache Spark — répondant aux exigences en temps réel sans introduire un autre moteur ni diviser la plateforme.
Maintenir deux moteurs signifie doubler la complexité et le risque de dérive logique entre les calculs par lots et en temps réel. Nous voulions une seule source de vérité — un pipeline basé sur Spark — plutôt que deux moteurs à maintenir. Le Mode Temps Réel nous a donné les performances dont nous avions besoin avec la simplicité que nous voulions." —Aditya Kumar, Associate Director of Engineering, MakeMyTrip
Le RTM offre un traitement continu et à faible latence grâce à trois innovations techniques clés qui fonctionnent ensemble pour éliminer les sources de latence inhérentes à l'exécution par micro-lots :
- Flux de données continu : Les données sont traitées à mesure qu'elles arrivent au lieu d'être discrétisées en morceaux périodiques.
- Planification de pipeline : Les étapes s'exécutent simultanément sans blocage, permettant aux tâches en aval de traiter les données immédiatement sans attendre que les étapes en amont soient terminées.
- Shuffle en streaming : Les données sont transmises entre les tâches immédiatement, contournant les goulots d'étranglement de latence des shuffles traditionnels basés sur disque.
Ensemble, ces innovations permettent à Apache Spark d'atteindre des pipelines à l'échelle de la milliseconde qui n'étaient auparavant possibles qu'avec des moteurs spécialisés. Pour en savoir plus sur la base technique du RTM, lisez ce blog, “Breaking the Microbatch Barrier: The Architecture of Apache Spark Real-Time Mode."
L'Architecture : Un Pipeline Temps Réel Unifié
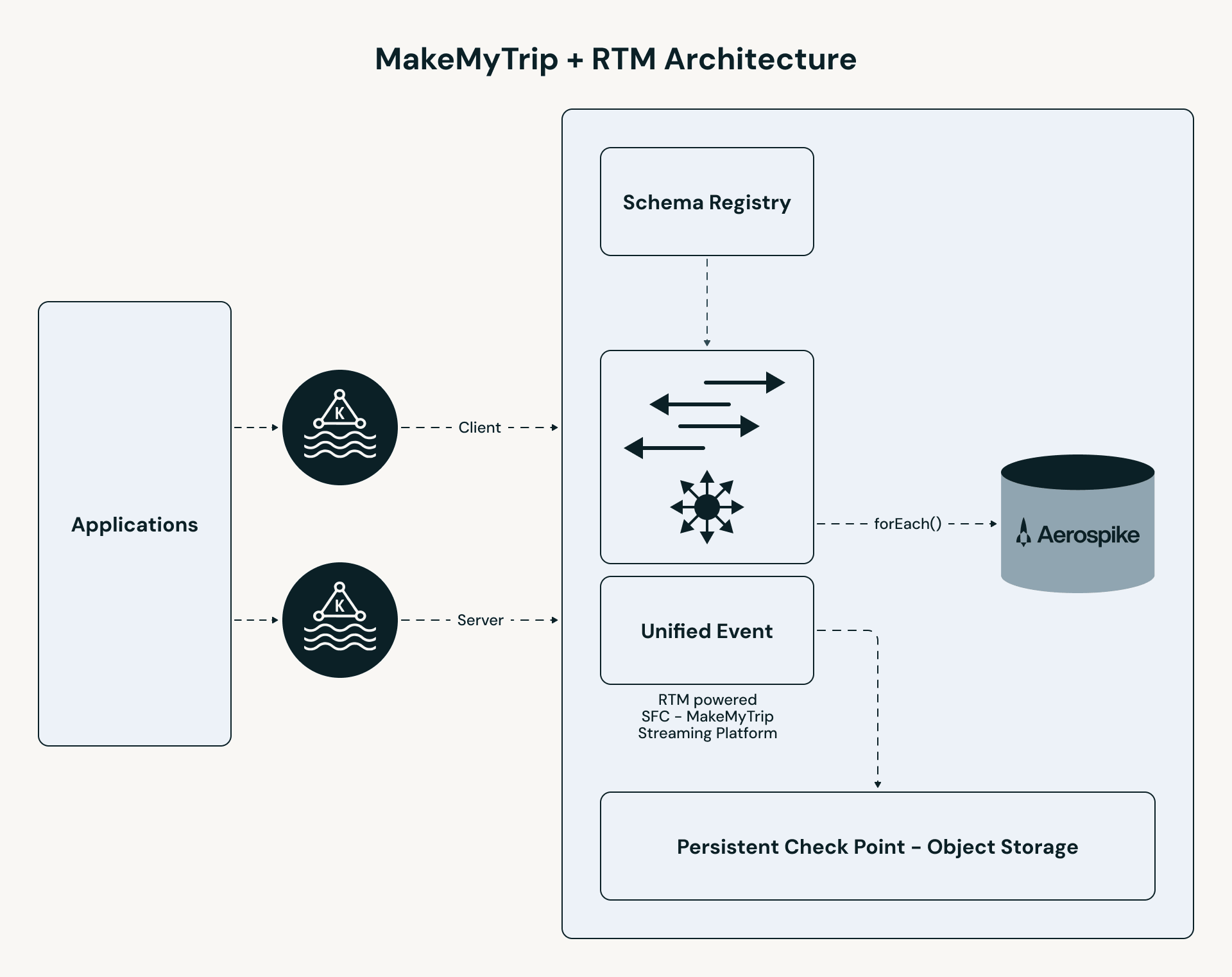
Le pipeline de MakeMyTrip suit un chemin haute performance :
- Ingestion unifiée : Les sujets de flux de clics B2C et B2B sont fusionnés en un seul flux. Toute la logique de personnalisation — enrichissement, recherche d'état et traitement d'événements — est appliquée de manière cohérente aux deux segments d'utilisateurs.
- Traitement RTM : Le moteur Apache Spark utilise la planification concurrente et le shuffle en streaming pour traiter les événements en millisecondes.
- Enrichissement d'état : Le pipeline effectue une recherche à faible latence dans Aerospike pour récupérer les "N derniers" hôtels pour chaque utilisateur.
- Service instantané : Les résultats sont envoyés vers un cache d'interface utilisateur (Redis), permettant à l'application de servir des résultats personnalisés en moins de 50 ms.
Configuration du RTM : un changement de code d'une seule ligne
L'utilisation du RTM dans votre requête de streaming ne nécessite pas de réécrire la logique métier ou de restructurer les pipelines. Le seul changement de code nécessaire est de définir le type de déclencheur sur RealTimeTrigger, comme montré dans l'extrait de code suivant :
La seule considération d'infrastructure : les slots de tâches du cluster doivent être supérieurs ou égaux au nombre total de tâches actives dans les étapes source et shuffle. L'équipe de MakeMyTrip a analysé leurs partitions Kafka, leurs partitions de shuffle et la complexité du pipeline à l'avance pour garantir une concurrence suffisante avant de passer en production.
Co-développement du RTM pour la Production
En tant que premier adoptant du RTM, MakeMyTrip a travaillé directement avec l'ingénierie Databricks pour rendre le pipeline prêt pour la production. Plusieurs capacités ont nécessité une collaboration active entre les deux équipes pour être construites, réglées et validées.
- Stream Union : Fusion de B2C et B2B en un seul Pipeline
MakeMyTrip avait besoin d'unifier deux flux de sujets Kafka distincts — flux de clics consommateur B2C et voyage d'entreprise B2B — en un seul pipeline RTM afin que la même logique de personnalisation puisse être appliquée de manière cohérente aux deux segments d'utilisateurs. Après un mois de collaboration étroite avec l'ingénierie Databricks, la fonctionnalité a été construite et livrée. Le résultat a été un pipeline unique où toute la logique métier réside au même endroit, sans risque de divergence entre les segments d'utilisateurs. - Multiplexage de Tâches : Plus de Partitions, Moins de Cœurs
Le modèle par défaut du RTM attribue un slot/cœur par partition Kafka. Avec 64 partitions dans la configuration de production de MakeMyTrip, cela se traduit par 64 slots/cœurs — non rentable à leur échelle. Pour résoudre ce problème, l'équipe Databricks a introduit l'option MaxPartitions pour Kafka, qui permet à plusieurs partitions d'être gérées par un seul cœur. Cela a donné à MakeMyTrip le levier dont ils avaient besoin pour réduire les coûts d'infrastructure sans compromettre le débit. - Durcissement du Pipeline : Checkpointing, Backpressure et Tolérance aux Pannes
L'équipe a travaillé sur un ensemble de défis opérationnels spécifiques aux charges de travail à haut débit et à faible latence : réglage de la fréquence et de la rétention des checkpoints, gestion des timeouts et gestion de la backpressure lors des pics de volume de flux de clics. En passant à 64 partitions Kafka, en activant la backpressure et en plafonnant le MaxRatePerPartition à 500 événements, l'équipe a optimisé le débit et la stabilité. Grâce à ce réglage itératif des configurations de lots, du partitionnement et du comportement de nouvelle tentative, ils ont abouti à un pipeline stable et de qualité production desservant des millions d'utilisateurs chaque jour.
Résultats
Le RTM a permis une personnalisation instantanée et une réactivité améliorée, un engagement plus élevé mesuré par les taux de clics et une simplicité opérationnelle d'un moteur unifié unique. Les métriques clés sont présentées ci-dessous.
Apache Spark comme moteur temps réel
Le déploiement de MakeMyTrip prouve que RTM sur Spark offre la latence extrêmement faible dont vos applications temps réel ont besoin. Comme RTM est basé sur les mêmes API Spark familières, vous pouvez utiliser la même logique métier pour les pipelines batch et temps réel. Vous n'avez plus besoin de maintenir une seconde plateforme ou un codebase séparé pour le traitement en temps réel, et pouvez simplement activer RTM sur Spark avec une seule ligne de code.
Le mode temps réel nous a permis de compresser notre infrastructure et de proposer des expériences en temps réel sans gérer plusieurs moteurs de streaming. Alors que nous entrons dans l'ère des agents IA, les piloter efficacement nécessite de construire un contexte temps réel à partir de flux de données. Nous expérimentons avec Spark RTM pour fournir à nos agents le contexte le plus riche et le plus récent nécessaire pour prendre les meilleures décisions possibles. —Aditya Kumar, Associate Director of Engineering, MakeMyTrip
Démarrer avec le mode temps réel
Pour en savoir plus sur le mode temps réel, regardez cette vidéo à la demande sur comment démarrer ou consultez la documentation.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.