Briser la barrière des micro-lots : L'architecture du Mode temps réel d'Apache Spark
Comment nous avons fait évoluer Spark pour traiter des charges de travail ETL à haut throughput et de streaming à ultra-faible latence
par Jerry Peng, Siying Dong et Indrajit Roy
- Le mode temps réel d'Apache Structured Streaming unifie les charges de travail ETL à throughput élevé et les charges de travail opérationnelles à latence de l'ordre de la milliseconde dans un moteur unique.
- Explorez en détail le modèle d'exécution hybride, en décrivant les étapes de traitement simultané et les opérateurs non bloquants qui offrent des latences de l'ordre de la milliseconde.
- Les clients peuvent désormais atteindre une réactivité inférieure à 100 ms pour les applications à très faible latence, telles que la détection des fraudes en temps réel.
Avec le lancement du mode temps réel (RTM) dans Apache Spark 4.1, Structured Streaming offre désormais une latence de l'ordre de la milliseconde. Dans un récent billet de blog, nous avons montré comment RTM peut surpasser Flink pour de nombreuses charges de travail d'ingénierie des fonctionnalités à faible latence (voir ci-dessous).
Dans ce blog, nous aborderons les changements architecturaux qui ont permis à Structured Streaming de prendre en charge à la fois les charges de travail ETL à haut throughput et les charges de travail à très faible latence.
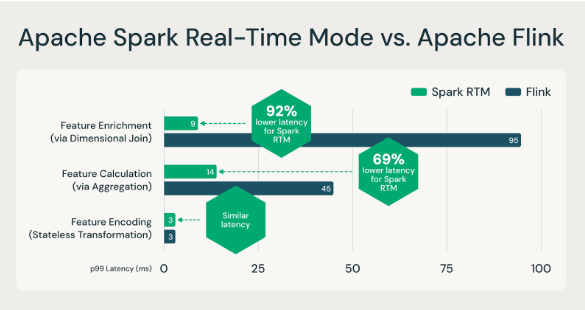
Apache Spark RTM est plus rapide que Flink pour les cas d'utilisation de Data Engineering.
Le dilemme throughput vs. latence
Jusqu'à présent, choisir un moteur de streaming impliquait de faire un compromis en optant pour des systèmes comme Apache Spark pour les workloads ETL à haut throughput, ou des systèmes comme Apache Flink pour les workloads à faible latence. Les deux systèmes ont des sémantiques et des caractéristiques de performance très différentes. Cela change avec le RTM dans Structured Streaming. Avec l'introduction du RTM, Apache Spark peut désormais prendre en charge les cas d'utilisation à haut throughput et à ultra-faible latence. Cela signifie qu'il est désormais possible de choisir un moteur unique sans nouvelle courbe d'apprentissage et d'éviter de gérer deux systèmes complètement différents.
L'architecture microbatch offre un throughput
Spark Structured Streaming utilise une architecture de micro-batchs : le système de streaming reçoit les données d'entrée et les divise en batchs discrets appelés époques, en fonction de la disponibilité des données et des configurations de taille de batch maximale. Le moteur Spark applique la logique métier au moyen de transformations telles que la projection, le filtrage et l'agrégation. Les résultats sont générés sous la forme d'un stream continu de batches. Structured Streaming excelle dans le traitement à haut throughput grâce à cette architecture de micro-lots : comme plusieurs enregistrements sont traités ensemble, les frais généraux fixes sont amortis et l'exécution vectorisée peut encore améliorer le throughput. Ces batchs sont exécutés en parallèle tout en maintenant une utilisation élevée du matériel. Le mode microlot alloue dynamiquement des créneaux de tâches sur plusieurs streams, ce qui contribue également à une utilisation et un throughput élevés. L'innovation fondamentale de Spark en matière de tolérance aux pannes basée sur le lignage garantit que ces flux sont traités avec de solides garanties de traitement unique et exact.
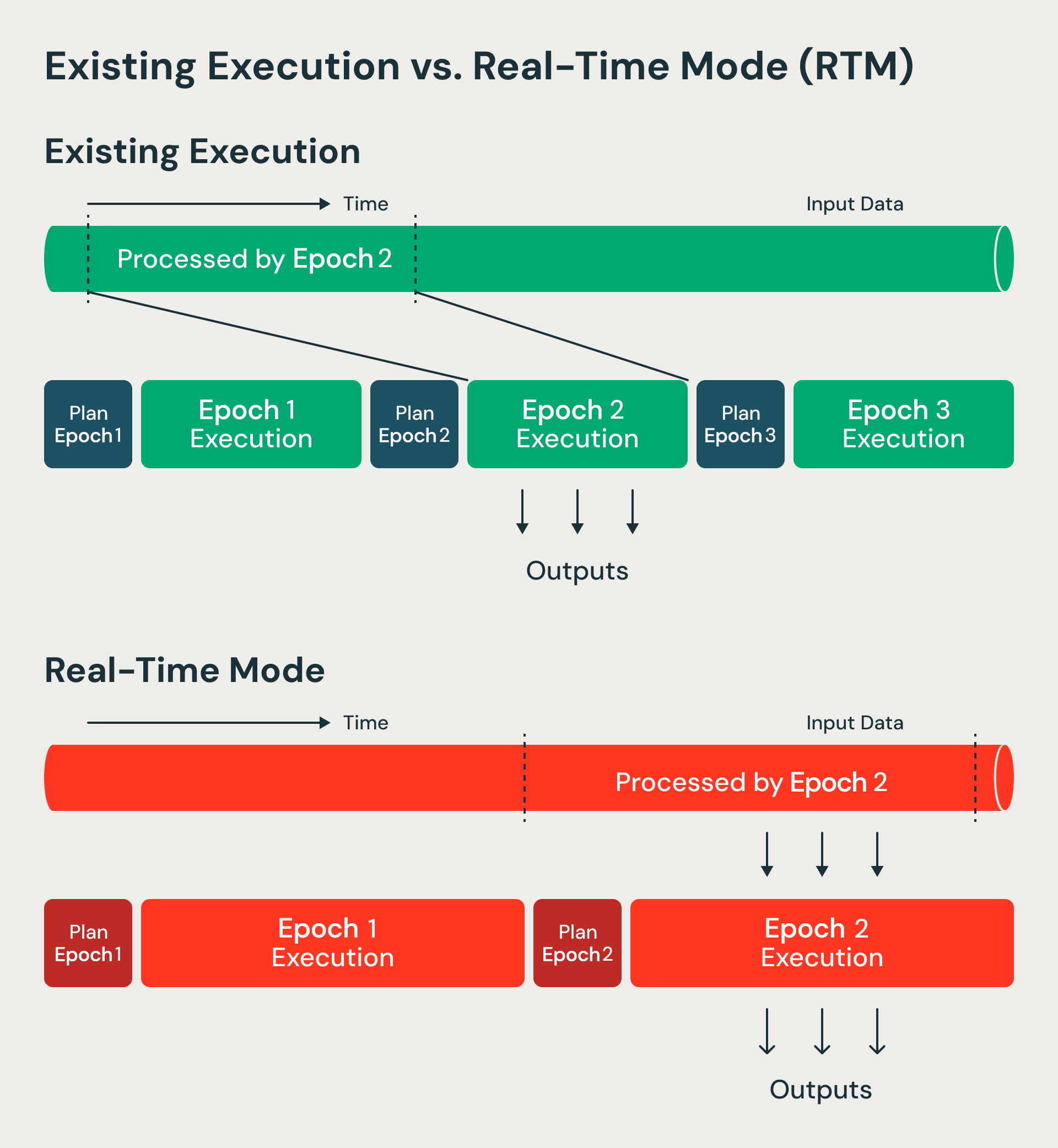
RTM traite les données de manière non bloquante par rapport au mode micro-batch.
Relever le défi de la faible latence
Bien que Structured Streaming soit très efficace pour gérer les charges de travail d'ETL et d'ingestion à l'échelle de la seconde, de nombreux cas d'usage opérationnels exigent une latence de l'ordre de la milliseconde. La détection de la fraude dans les transactions financières, les insights en temps réel dans le secteur d'activité du voyage ou l'analyse des données de télémétrie des véhicules connectés sont autant d'exemples où les clients ont besoin de réponses en quelques millisecondes.
Défi architectural : Pourquoi les batchs plus petits ne fonctionnent pas
La Solution évidente peut sembler simple : il suffit de réduire la taille des batchs. Si nous traitons un enregistrement à la fois, nous devrions obtenir des performances en temps réel. Malheureusement, ce n'est pas si simple.
Chaque micro-batch dans Structured Streaming entraîne des coûts fixes qui dominent le temps d'exécution lors du traitement de petites quantités de données. Le système écrit des Logs dans un stockage d'objets durable avant et après chaque exécution de micro-batch. De plus, les mises à jour d'état pour chaque query avec état doivent également être uploadées vers le stockage d'objets à la fin d'un micro-batch. Ce sont des étapes critiques pour garantir la sémantique de cohérence, mais elles peuvent ajouter des centaines de millisecondes, voire des secondes, au temps d'exécution. Même si nous masquons certaines de ces latences, la latence de la planification de chaque batch, la surcharge de planification logique et physique, la sérialisation des tâches et l'ordonnancement sont difficiles à réduire. Comme vous pouvez l'imaginer, la réduction de la taille des batchs atteint rapidement ses limites. La figure ci-dessous montre que lorsque les micro-batchs deviennent trop petits (barre la plus à gauche), les coûts de traitement fixes des micro-batchs dominent l'exécution et augmentent la latence de bout en bout.
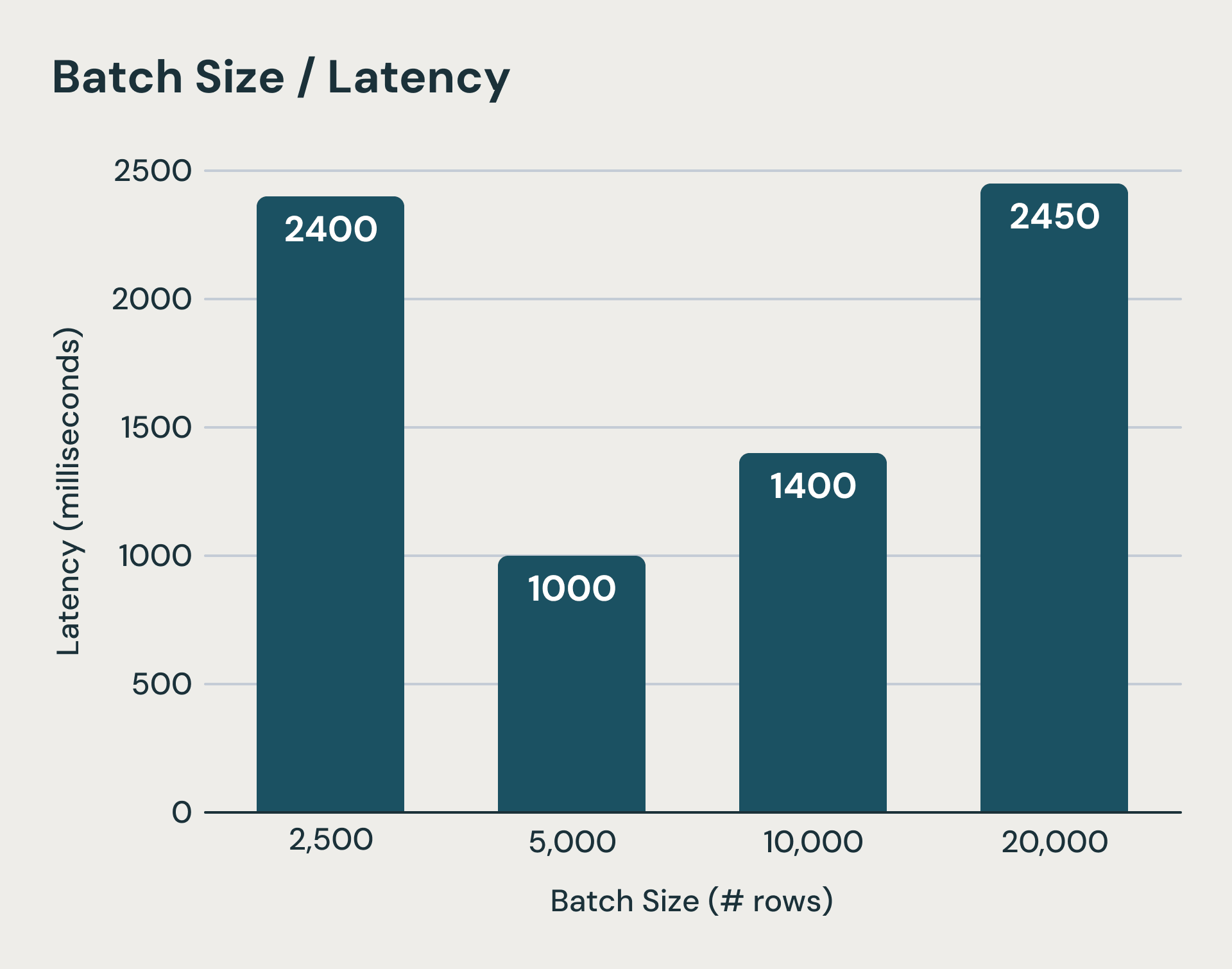
Au-delà d'un certain threshold, des tailles de batch plus petites peuvent augmenter la latence en raison de surcoûts fixes
Cela nous a confrontés à un défi architectural : nous voulons conserver les avantages en termes de coût et de tolérance aux pannes de l'architecture micro-batch, tout en atteignant la faible latence que l'on attend des modèles qui traitent les enregistrements un par un (tels qu'Apache Storm et Apache Flink). Notre principale insight est que nous pouvons faire évoluer l'architecture micro-batch pour prendre en charge les charges de travail en temps réel. Nous avons continué à utiliser de nombreuses fonctionnalités de base de l'architecture micro-batch, telles que le checkpointing pour la tolérance aux pannes. Cependant, nous avons éliminé les étapes où les données attendaient, ce qui entraînait une latence élevée. Nous décrivons ces changements ci-dessous.
Notre solution : un modèle d'exécution hybride
Voici comment nous avons amélioré la latence de Structured Streaming :
1. Époques de plus longue durée avec un flux de données continu
Le mode par micro-batchs traite des batchs de données appelés époques. Les limites d'époque sont décidées à l'avance à l'aide des décalages de start et de fin. Le mode temps réel traite plutôt des époques de plus longue durée, mais modifie la façon dont les données circulent au sein de chaque époque. Les données sont désormais diffusées en continu à travers différentes étapes et opérateurs sans blocage. Comme les époques sont de plus longue durée, les surcoûts du checkpointing et des barrières sont amortis. Aux frontières d'époque, nous utilisons toujours des barrières pour le suivi de la récupération et la replanification des tâches, ce qui permet de conserver les avantages qui rendent les architectures par micro-batch résilientes et efficaces. Nous avons essentiellement fait évoluer le micro-batch dans Structured Streaming en un intervalle de point de contrôle.
2. Étapes de traitement simultanées
Dans l'architecture Structured Streaming, les étapes de traitement s'exécutaient séquentiellement : les réducteurs attendaient que les mappeurs se terminent, ce qui créait des retards inutiles. Nous avons rendu ces étapes simultanées dans le mode temps réel. Désormais, le Driver Spark demande les décalages de source et planifie les mappers, mais les reducers peuvent start à traiter les fichiers de shuffle dès qu'ils sont disponibles, plutôt que d'attendre que tous les mappers aient terminé. Ce changement réduit considérablement la latence de bout en bout. La figure RTM ci-dessous montre que les deux étapes s'exécutent simultanément et que l'étape 2 start à traiter les lignes dès qu'elles sont traitées par l'étape 1.
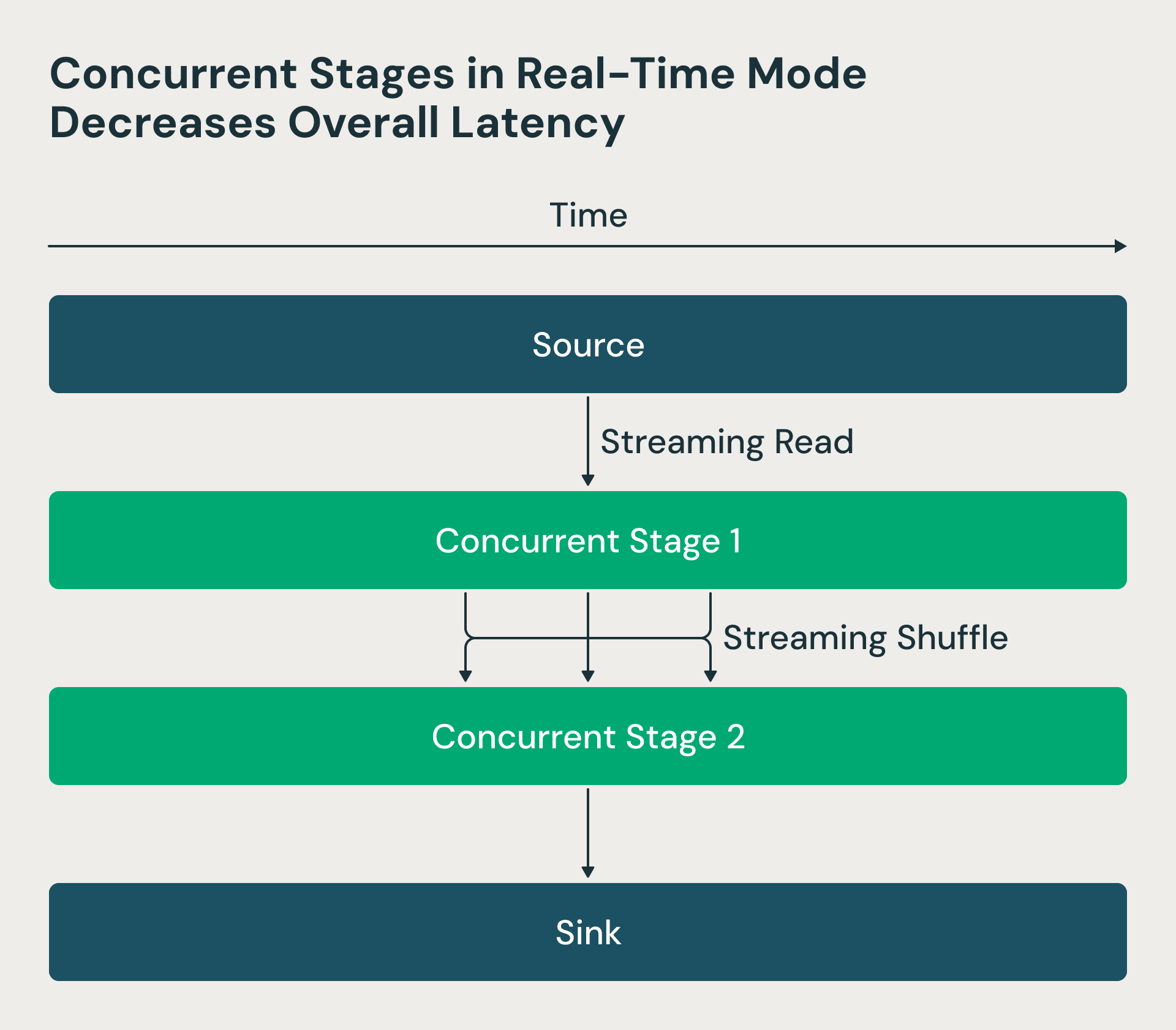
Le mode temps réel utilise des étapes concurrentes, ce qui réduit la latence
3. Opérateurs non bloquants
Nous avons restructuré des opérateurs clés comme le shuffle, qui ont été conçus pour une exécution par batch avec une mise en mémoire tampon substantielle. En mode batch, une agrégation group-by mettrait en mémoire tampon tous les enregistrements, effectuerait une pré-agrégation et n'émettrait les résultats qu'à la fin. Pour le traitement en temps réel, nous avons modifié ces opérateurs afin de minimiser la mise en mémoire tampon et de produire des résultats en continu, ce qui permet aux données de circuler dans le pipeline sans attentes inutiles.
Résumé
En utilisant des époques de plus longue durée avec un flux de données continu, des étapes de traitement concurrentes et des opérateurs non bloquants, nous avons généralisé le moteur Apache Spark Structured Streaming pour gérer à la fois un élevé throughput et les cas d'utilisation de streaming à très faible latence. Cette approche hybride supprime désormais la nécessité de choisir entre les moteurs de streaming. Les utilisateurs n'ont qu'à apprendre Apache Spark et il n'est pas nécessaire d'apprendre un autre framework dédié au streaming à très faible latence.
Le mode temps réel est déjà en production chez Databricks et utilisé par de nombreux clients, des sociétés financières de pointe aux sites de voyage. Nos clients sont en mesure d'atteindre une latence de l'ordre de la milliseconde pour leurs cas d'usage.
Bien qu'il s'agisse d'une avancée majeure dans les capacités de Spark, nous continuons d'ajouter de nouvelles fonctionnalités de streaming. Si votre organisation recherche des solutions pour les charges de travail en temps réel, essayez Apache Spark Structured Streaming !
Explorer les ressources techniques
Pour en savoir plus sur Data Engineering de RTM, regardez cette session à la demande animée par nos experts. Ils présenteront en détail la conception et l'implémentation du Mode Temps Réel.
Ou consultez le guide technique du Mode temps réel pour savoir comment démarrer. Vous trouverez tout ce dont vous avez besoin pour permettre le traitement en temps réel de vos charges de travail de streaming.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.