Mode temps réel : streaming à très faible latence sur les Spark API sans second moteur
Traitez les données en streaming en millisecondes sur Apache Spark, sans la surcharge d'Apache Flink
par Navneeth Nair, Jerry Peng et Abhay Bothra
- Unification : découvrez comment le mode temps réel (RTM) dans Apache Spark unifie l'entraînement hors ligne et l'ingénierie des caractéristiques en ligne à très faible latence en un moteur unique et ultra-performant.
- Performances : Découvrez la nouvelle architecture qui permet une latence ultra-faible dans Spark, avec une analyse des performances comparant Apache Spark RTM à Apache Flink.
- Simplicité et adoption : RTM offre de nombreux avantages opérationnels, notamment une migration simplifiée, une API unifiée pour éviter la « dérive logique », et des cas d'utilisation clients concrets.
Apache Spark Structured Streaming alimente depuis longtemps des pipelines de données critiques à grande échelle, du streaming ETL à l'analytique et au machine learning. Mais à mesure que les cas d'utilisation opérationnels ont évolué, les équipes ont commencé à exiger quelque chose de plus : des latences inférieures à la seconde pour des applications telles que la détection de la fraude, la personnalisation, la détection d'anomalies, les alertes et les rapports en temps réel.
Historiquement, pour répondre à ces exigences de latence ultra-faible, il fallait introduire des systèmes spécialisés aux côtés de Spark. Avec l'introduction du Mode temps réel dans Spark Structured Streaming, ce compromis n'est plus nécessaire. Dans ce blog, nous explorons comment Spark simplifie l'architecture de streaming en temps réel pour des cas d'utilisation courants tels que le feature engineering, élimine la complexité opérationnelle de longue date et offre des performances de pointe.
Le streaming en temps réel ne nécessite plus l'exécution de plusieurs systèmes disparates.
La capacité de traiter les données et d'agir en temps réel est désormais une exigence fondamentale. Les applications modernes, en particulier les agents d'IA, s'appuient sur un stream continu de contexte à jour pour fonctionner. Si les données sous-jacentes sont incomplètes ou obsolètes, l'expérience utilisateur en pâtit. Les performances en temps réel ne sont pas seulement nécessaires pour les cas d'utilisation traditionnels tels que la détection de la fraude, mais pour chaque interaction courante où un utilisateur attend des réponses précises et à jour. Dans cet environnement, la latence a un impact direct sur les revenus, la confiance des clients et l'avantage concurrentiel.
Les équipes de données qui créent des applications de streaming en temps réel ont traditionnellement dû gérer deux piles de traitement de données distinctes : Apache Spark™ pour l'analytique à grande échelle et des systèmes spécialisés tels qu'Apache Flink® ou Kafka Streams pour les applications sensibles à la latence et dont le temps de réponse est inférieur à la seconde. Cette fragmentation exige des équipes qu'elles maintiennent des bases de code dupliquées, gèrent des modèles de gouvernance distincts et embauchent des talents spécialisés pour ajuster et maintenir une infrastructure spécifique au moteur.
Lancé en préversion publique en août 2025, le Mode temps réel (RTM) pour Apache Spark Structured Streaming est conçu pour éliminer cette friction. En faisant évoluer fondamentalement le moteur d'exécution Spark, nous avons éliminé le besoin d'un second système. Ce changement permet aux ingénieurs de couvrir l'ensemble des cas d'utilisation, de l'ETL à haut débit aux applications en temps réel à faible latence, en utilisant la même Spark API qu'ils connaissent déjà. Cela signifie moins de temps passé à gérer l'infrastructure et plus de temps pour se concentrer sur le cas d'utilisation métier.
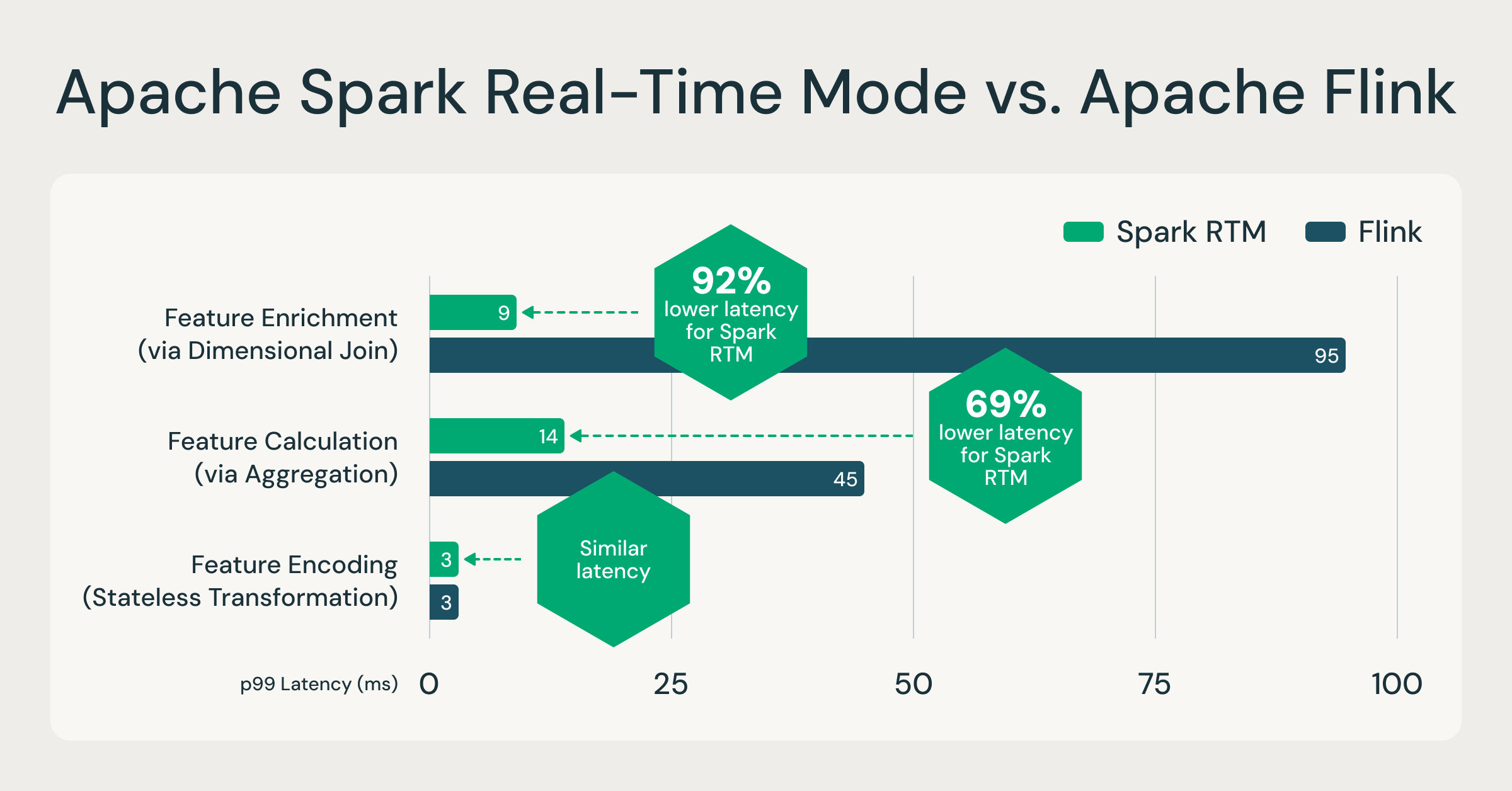
Spark peut désormais traiter des événements en quelques millisecondes, soit jusqu'à 92 % plus rapidement que Flink.
Le mode temps réel (RTM) a introduit un nouveau moteur d'exécution optimisé qui permet à Spark d'offrir des latences constantes inférieures à la seconde. Pour évaluer les performances, nous avons effectué une comparaison directe entre Spark RTM et Apache Flink. Les tests étaient basés sur des charges de travail de calcul de features en temps réel que nous observons couramment en production. Ces modèles de calcul de caractéristiques sont représentatifs de la plupart des cas d'utilisation d'ETL à faible latence, tels que la détection de la fraude, la personnalisation et l'analytique opérationnelle.
Nous avons évalué trois modèles de features courants :
- Encodage des caractéristiques (transformation sans état) : tronquer les lignes d'entrée et les encoder
- Enrichissement de fonctionnalités (via une jointure) : joindre un flux à une table statique
- Calcul des caractéristiques (via l'agrégation) : agrégation GroupBy + Count
Les résultats démontrent que l'architecture évoluée de Spark offre un profil de latence comparable à celui des frameworks de streaming spécialisés.
Cette performance est rendue possible par trois innovations techniques clés dans RTM :
- Flux de données continu : les données sont traitées à leur arrivée plutôt que par blocs périodiques et discrétisés.
- Planification du pipeline : les étapes s'exécutent simultanément sans blocage, ce qui permet aux tâches en aval de traiter les données immédiatement sans attendre la fin des étapes en amont.
- Shuffle en streaming : les données sont transmises immédiatement entre les tâches, contournant les goulots d'étranglement de latence des shuffles traditionnels basés sur le disque.
Ensemble, ils transforment Spark en un moteur haute performance et à faible latence, capable de gérer les cas d'utilisation opérationnels les plus exigeants.
Les équipes exploitent moins d'infrastructure et avancent plus vite avec Spark
Bien que la vitesse brute soit essentielle, la véritable valeur du mode temps réel réside dans sa capacité à éliminer la complexité opérationnelle qui entrave généralement la création de pipelines à très faible latence. Spark RTM simplifie considérablement votre architecture grâce à trois avantages fondamentaux. Pour rendre cela concret, nous les décrivons dans le contexte des applications de machine learning en temps réel.
Minimiser la « logic drift » entre l'entraînement et l'inférence : le ML en temps réel, comme la détection de la fraude, nécessite une transition transparente entre le batch à high-throughput (pour l'entraînement des modèles) et le streaming à faible latence (pour l'inférence en direct). Spark est le choix préféré des data scientists pour l'entraînement de modèles, et forcer le passage de Spark à Flink pour l'inférence créerait un écart de logique métier. Vous vous retrouvez avec une version de la logique dans Spark pour l'entraînement et une base de code complètement différente dans Flink pour la production. Cette réplication de la logique métier peut être source d'erreurs et entraîner une drift logique, où votre modèle est entraîné sur une réalité mais en évalue une autre. Avec Spark RTM, votre code de transformation reste identique, ce qui vous permet de mettre en production les caractéristiques plus rapidement et avec une grande précision.
Fraîcheur à la demande avec une modification d'une seule ligne de code : les exigences métier sont rarement statiques. Un pipeline de caractéristiques qui commence aujourd'hui avec un SLA d'une minute pourrait exiger demain une latence inférieure à la seconde à mesure que les besoins de fraîcheur du modèle évoluent. Inversement, pour de nombreux cas d'utilisation, « ralentir » (par exemple, avec des batchs quotidiens ou horaires) est beaucoup plus rentable lorsqu'une fraîcheur immédiate n'est pas requise. Spark vous offre la marge de manœuvre pour croître et monter en charge en même temps que votre produit. Il vous permet de faire pivoter facilement votre stratégie d'ingénierie des caractéristiques avec une modification d'une seule ligne de code. Par exemple, vous pouvez définir votre trigger sur AvailableNow pour exécuter un pipeline sur une base quotidienne ou horaire. Lorsque les besoins métier changent, vous pouvez passer au streaming continu à très faible latence simplement en passant en mode temps réel : .trigger(RealTimeTrigger.apply()). En revanche, accomplir cela dans Flink est un processus manuel. Cela vous oblige souvent à ajuster le parallélisme et à orchestrer l'arrêt et le redémarrage des ressources compute simplement pour correspondre à une nouvelle fréquence de traitement.
Accélérez le développement : RTM s'appuie sur la même API Spark que votre équipe connaît déjà. Cela élimine les frictions liées à la maintenance de plusieurs systèmes, vous permettant ainsi d'avancer plus rapidement en créant et en mettant à l'échelle des applications en temps réel au sein d'un environnement unique et cohérent.
Les clients exécutent plusieurs applications en temps réel sur Spark
Les premiers utilisateurs utilisent RTM pour alimenter une gamme d'applications à faible latence, dans divers secteurs d'activité.
Détection de la fraude : une plateforme d'actifs numériques de premier plan calcule des caractéristiques de risque dynamiques telles que des vérifications de vélocité et des schémas de dépenses agrégées à partir de flux Kafka, mettant à jour son magasin de fonctionnalités en ligne en moins de 200 millisecondes pour bloquer les transactions frauduleuses au point de vente.
Expériences personnalisées : une plateforme d'e-commerce calcule des caractéristiques d'intention en temps réel en fonction de la session actuelle d'un utilisateur, ce qui permet aux modèles d'actualiser les recommandations dès qu'un utilisateur interagit avec un produit.
IoT Monitoring : une entreprise de transport et de logistique ingère des données de télémétrie en direct pour effectuer la détection d'anomalies, passant d'une prise de décision réactive à proactive en quelques millisecondes.
DraftKings, l'un des plus grands services de paris sportifs et de ligues sportives imaginaires d'Amérique du Nord, utilise RTM pour alimenter le calcul de caractéristiques pour ses modèles de détection de la fraude.
« Dans les paris sportifs en direct, la détection de la fraude exige une vélocité extrême. L'introduction du Mode temps réel ainsi que de l'API transformWithState dans Spark Structured Streaming a changé la donne pour nous. » « Nous avons obtenu des améliorations substantielles en matière de latence et de conception de pipeline et, pour la première fois, nous avons créé des pipelines de caractéristiques unifiés pour l'entraînement de modèles de ML et l'inférence en ligne, atteignant des latences ultra-faibles qui étaient tout simplement impossibles auparavant. » —Maria Marinova, ingénieure logiciel principale senior, DraftKings
Commencez à développer avec le mode temps réel de Spark
L'époque où il fallait choisir entre « facile » et « rapide » est révolue. Pourquoi gérer deux moteurs, deux modèles de sécurité et deux ensembles de compétences spécialisées quand un seul moteur fait maintenant tout le travail ? RTM offre la vitesse inférieure à la seconde que vos applications en temps réel exigent, avec la simplicité architecturale que votre équipe mérite. En supprimant la « taxe opérationnelle », vous pouvez enfin vous concentrer sur la création de valeur plutôt que sur la gestion de l'infrastructure.
Prêt à éliminer la complexité de votre pile temps réel ?
- Plongez dans les détails : explorez la documentation RTM pour comprendre toutes les spécifications techniques, les sources et les récepteurs pris en charge, ainsi que des exemples de requêtes. Vous y trouverez tout ce dont vous avez besoin pour activer le nouveau trigger et configurer vos charges de travail de streaming.
- Découvrez-le en action : pour approfondir l'ingénierie des données derrière RTM, regardez cette session technique approfondie, qui présente en détail la conception et la mise en œuvre.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.