Comment Zalando a construit une base de données unifiée pour l'IA et l'analytique sur Databricks
Zalando sépare la création des données de leur consommation, standardise les définitions de métriques et permet des requêtes fiables en langage naturel sur les tableaux de bord et l'IA.
par Fabian Halkivaha, Mukrram Ur Rahman, Maria Vedenina et Timur Yüre
- Zalando a construit une base de données unifiée sur Databricks avec Unity Catalog, Metric Views et Genie pour gouverner les données, standardiser les métriques et permettre l'analyse en langage naturel.
- Ils ont centralisé la logique métier en utilisant Metric Views (« métriques en tant que code »), résolvant les définitions de métriques incohérentes entre les tableaux de bord, SQL et les pipelines.
- En ancrant Genie dans cette couche sémantique, Zalando fournit des requêtes fiables en langage naturel, réduisant le temps de réponse aux nouvelles questions et améliorant la confiance dans les résultats.
Chez Zalando, une plateforme en ligne leader en Europe pour la mode et le style de vie, nous orchestrons un écosystème numérique massif qui connecte plus de 50 millions de clients actifs avec plus de 7 000 marques et partenaires à travers l'Europe. Chaque interaction client (navigation, commande, retour, etc.) génère une impulsion de données qui guide nos décisions, des recommandations personnalisées à l'optimisation de la logistique.
Opérer à cette échelle présente un ensemble unique de défis. Notre paysage de données est vaste et complexe, alimenté par une architecture de microservices qui transmet des téraoctets d'événements vers notre lac de données central. Bien que cette architecture nous ait permis de croître rapidement, elle a également rendu la gouvernance difficile et brouillé la distinction entre les Données Transactionnelles (opérations commerciales quotidiennes) et les Données Analytiques (informations pour la prise de décision).
Pendant des années, nous avons recherché une approche distribuée pour résoudre ce problème en décentralisant la propriété, afin que les équipes de domaine (comme "Paiements" ou "Logistique") puissent gérer leurs propres produits de données. Une structure de gouvernance centralisée est cruciale dans cette configuration pour assurer une charge gérable sur les équipes et prévenir les risques commerciaux. De plus, sans une couche unifiée pour définir la vérité, nous sommes confrontés au défi de la divergence des métriques : Pourquoi le tableau de bord Marketing affiche-t-il un "Chiffre d'affaires net" différent de celui du rapport Finance ? Comme les métriques vivent en silos, il est difficile de les gouverner et de s'assurer qu'elles sont découvrables et fiables pour être réutilisées tout au long de leur cycle de vie.
Dans cet article, nous partagerons comment Zalando y parvient en tirant parti de toute la puissance de la plateforme Databricks. Nous examinerons comment nous construisons une Couche Sémantique Unifiée qui comble le fossé entre les Données Transactionnelles et les Données Analytiques. Plus précisément, nous aborderons :
- Les Fondations : Comment Unity Catalog permet une gouvernance fédérée et un partage sécurisé entre des centaines d'équipes.
- La Couche Sémantique : Comment les Sémantiques Métier d'Unity Catalog, alimentées par les Vues Métriques, nous permettent de définir la logique métier une fois et de la servir partout.
- L'Analyse Conversationnelle par IA : Comment nous exploitons la couche sémantique via Genie, une interface alimentée par l'IA générative qui permet aux utilisateurs d'interroger les données en langage naturel sans avoir besoin d'expertise en SQL, nous aidant ainsi à prendre des décisions plus rapides et basées sur les données.
Les Fondations – Démocratiser la Gouvernance avec Unity Catalog
Pour gérer efficacement notre vaste paysage de données, nous avons décidé de nous éloigner du contrôle d'accès basé sur les ressources. Dans ce modèle, chaque nouvel ensemble de données ou consommateur nécessitait des rôles IAM sur mesure, des politiques de compartiment S3 et une gestion des exceptions. Mais nous avons identifié des défis : les autorisations étaient fragmentées sur des milliers de ressources, fastidieuses à examiner et sujettes à dérive. Par conséquent, nous sommes passés à une approche de gouvernance basée sur l'identité. Les décisions d'accès sont exprimées sous forme de politiques réutilisables liées aux personnes et aux groupes. Elles sont évaluées de manière cohérente sur les ensembles de données et appliquées de manière centralisée. Cela rend l'accès plus facile à exploiter, auditer et faire évoluer à mesure que les équipes et les données changent. Nous avons construit cette base en utilisant Databricks Unity Catalog et mis en œuvre un cadre de contrôle d'accès fédéré par-dessus.
L'Architecture
Nous avons conçu un modèle de double catalogue qui sépare strictement la création des données de leur consommation, garantissant que l'agilité ne se fait pas au détriment du contrôle :
- Catalogues Privés pour l'Autonomie : Chaque équipe de domaine crée son propre Catalogue Privé à l'aide d'une solution interne en libre-service. Dans cet environnement privé, l'équipe peut créer des schémas, ingérer des données brutes et construire des tables à son propre rythme sans attendre l'approbation centrale. Cela sert d'"usine", optimisée pour le développement et l'itération sans restriction. La seule limitation qu'ils rencontrent est que tous les objets créés ici ne sont accessibles qu'à l'équipe elle-même, plus un nombre limité de contributeurs associés. Cela signifie que les cas d'utilisation construits sur ces catalogues ne sont pas destinés à une utilisation à l'échelle de l'entreprise.
- Le Catalogue Partagé Central pour la Gouvernance : Pour les cas d'utilisation où diverses équipes de toute l'entreprise ont besoin d'utiliser ces ensembles de données, nous avons introduit un catalogue partagé central. Il agit comme le "showroom" de l'entreprise. Toutes les données partagées au sein de l'organisation doivent y être exposées via des Vues Dynamiques, où elles tombent sous une gouvernance centrale stricte. Dès que les données y arrivent, elles sont instantanément découvrables via Unity Catalog.
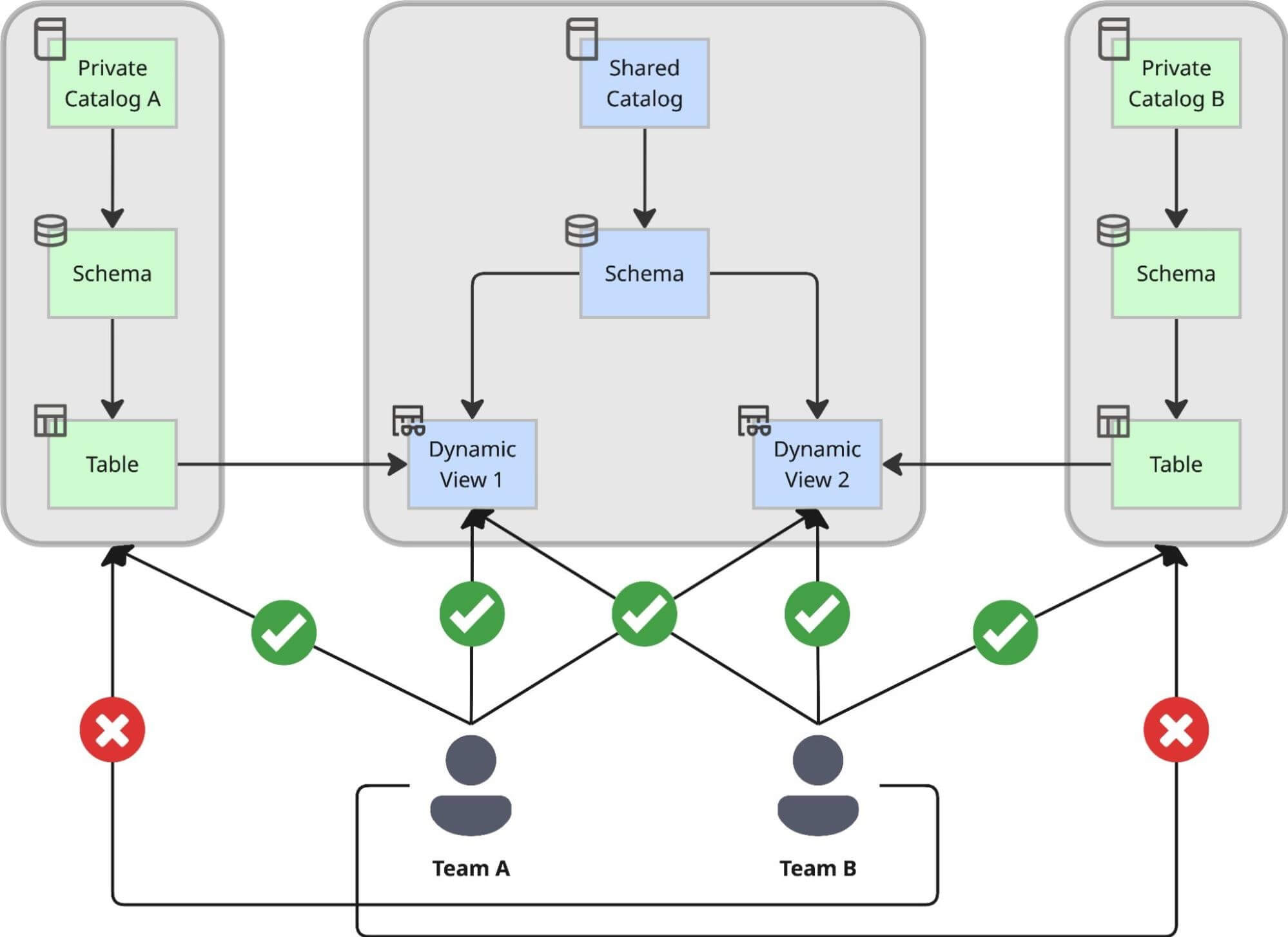
Pourquoi des Vues Dynamiques ? Contrôle Centralisé et Auditabilité
Nous avons pris la décision stratégique d'exposer les données dans le catalogue partagé exclusivement via des Vues Dynamiques, plutôt que des pointeurs de table directs. Cette approche nous permet d'appliquer un processus d'accès centralisé capable de gérer des règles de conformité complexes.
En utilisant les Vues Dynamiques comme couche de service, nous avons obtenu :
- Règles de Processus Personnalisées pour le RGPD : Nous injectons une logique personnalisée directement dans la définition de la vue à l'aide de fonctions comme is_account_group_member(). Cela garantit un contrôle d'accès robuste en vérifiant si les utilisateurs répondent aux exigences antitrust et sont autorisés à accéder aux données sensibles (comme l'e-mail).
- Accès Interne Conforme par Défaut : En raison d'un processus de classification automatisé, chaque colonne est classifiée. Toutes les colonnes non sensibles sont accessibles par défaut à une grande variété d'utilisateurs, ce qui accélère la démocratisation des données et la prise de décision.
- Auditabilité Complète : Comme tous les accès inter-équipes transitent par ces vues gérées centralement, nous maintenons une piste d'audit complète des décisions d'accès. Nous savons exactement quelle politique a accordé à un utilisateur l'accès à une ligne ou une colonne spécifique.
- Informations Fiables : Pour éviter la génération de données incorrectes ou de chiffres trompeurs dus à une agrégation partielle, toute requête tentant d'accéder à une colonne sensible sans l'autorisation spécifique nécessaire échouera explicitement avec une erreur de permission refusée.
La Gouvernance en tant que Code : Le Workflow de Partage
Pour maintenir l'efficacité de ce processus, nous avons automatisé le workflow de partage à l'aide d'une approche GitOps :
- Pull Request pour Partager : Lorsqu'une équipe est prête à partager un ensemble de données de son catalogue privé vers le catalogue partagé, elle ne dépose pas de ticket. Elle ouvre une Pull Request (PR) dans un dépôt central avec un fichier de configuration pointant vers sa table source.
- Règles d'Approbation : La Pull Request est vérifiée pour les critères de partage, l'unicité et d'autres facteurs de décision importants.
- Validation et Provisionnement Automatisés : Une fois la PR approuvée et fusionnée, notre service de plateforme génère automatiquement la Vue Dynamique correspondante dans le catalogue partagé central et classe automatiquement les colonnes.
Cette configuration nous permet de maintenir l'agilité des équipes distribuées tout en appliquant une norme de gouvernance centralisée et entièrement auditable qui maintient nos données facilement découvrables, sécurisées et conformes.
La Couche Sémantique – Définir "La Vérité" avec les Vues Métriques
Avec la base sécurisée que nous avons établie pour accéder aux données, nous nous concentrons maintenant sur la garantie d'une interprétation cohérente des données.
Nous centralisons activement la logique métier qui était auparavant fragmentée dans la pile de données :
- Outils BI : Définitions de métriques intégrées dans des tableaux de bord individuels
- Scripts SQL : Logique dupliquée dans les notebooks et les pipelines
- Tables matérialisées : Métriques pré-calculées liées à des cas d'utilisation spécifiques
Nous unifions des milliers de définitions de métriques dans une seule couche gouvernée. Cela nous permet de briser le "verrouillage logique" : la définition de la "Valeur Brute des Marchandises" (NMV) dans un outil de tableau de bord devient entièrement accessible à un scientifique des données travaillant dans un notebook ou à un bot IA répondant à la question d'un utilisateur.
Pour ce faire, nous adoptons les Databricks Metric Views comme notre couche sémantique unifiée. Cela découple de manière décisive la définition d'une métrique de sa consommation, garantissant que les utilisateurs obtiennent exactement le même résultat calculé, qu'ils interrogent via un éditeur SQL, un tableau de bord ou un agent IA. En pratique, cela garantit que les utilisateurs techniques et non techniques utilisent les mêmes définitions de métriques.
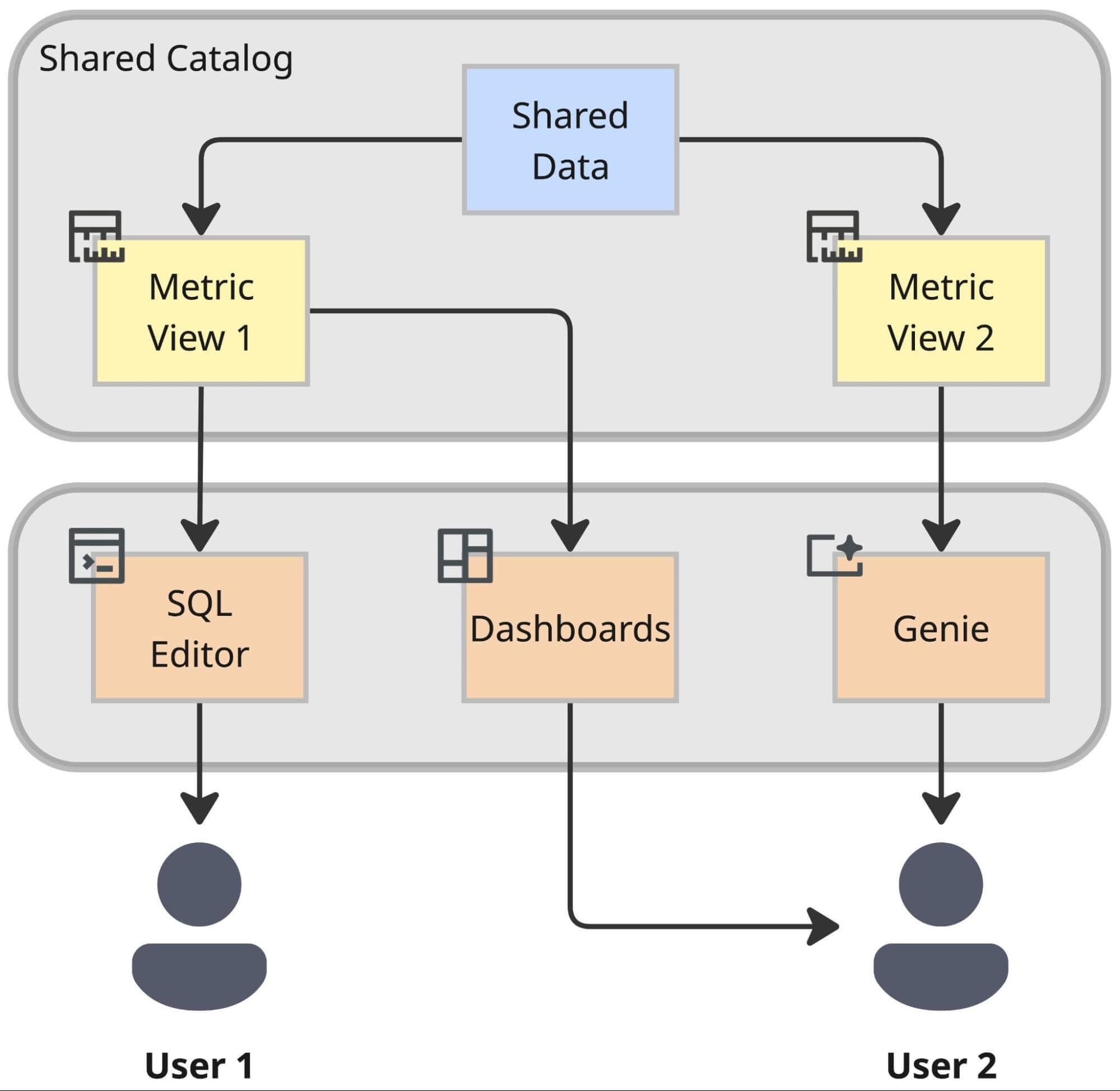
Métrique en tant que Code : Le Cycle de vie de la Métrique
Nous mettons en œuvre une approche rigoureuse de « Métrique en tant que Code » pour notre couche sémantique, tout comme nous utilisons GitOps pour le partage de données dans Unity Catalog. Nous assurons la cohérence entre toutes les équipes en centralisant et en standardisant chaque définition d'indicateur clé de performance (ICP).
Notre architecture gère le cycle de vie complet d'une métrique :
- Définition en YAML : Les métriques sont définies dans le code (fichiers YAML) stockés dans un référentiel central. Cela capture non seulement la logique d'agrégation (par exemple, SUM(amount)) et les relations entre les tables, les faits et les métriques, mais aussi les métadonnées critiques comme la propriété, la description et le formatage.
- Validation Automatisée : Avant qu'une métrique ne puisse être fusionnée en production, notre pipeline CI/CD exécute une suite de vérifications automatisées. Celles-ci comprennent :
- Unicité : S'assurer qu'aucune métrique portant le même nom ou la même définition n'existe déjà.
- Conformité : Appliquer les conventions de nommage (par exemple, snake_case) pour assurer la découvrabilité.
- Propriété : Vérifier qu'un identifiant d'équipe valide est attaché à la métrique pour la responsabilité.
- Humain dans la boucle : Grâce au principe des 4 yeux, chaque Pull Request est examiné par des experts du domaine.
- Environnements de Développement Individuels : Pour permettre aux équipes d'itérer rapidement tout en testant dans un environnement très proche de la production, chaque Pull Request déploie les Metric Views dans un environnement de test séparé. Cette configuration permet de vérifier immédiatement les implications du changement.
Construction d'un Schéma en Étoile pour le Lakehouse
Sous le capot, nous nous appuyons sur des principes établis de modélisation dimensionnelle. Chaque Metric View dans notre environnement de production agit comme une interface standard, correspondant généralement 1 pour 1 avec nos tables de faits tout en héritant des attributs des tables de dimensions conformes.
Cette configuration est cruciale pour notre échelle. En imposant que les Metric Views soient construites sur les données de confiance de notre Catalogue Partagé (de la Section 1), nous nous assurons que la couche sémantique hérite de tous les avantages de sécurité et de conformité de la plateforme sous-jacente. Un utilisateur interrogeant une vue de métrique est toujours soumis aux mêmes règles de sécurité au niveau des lignes et des colonnes, et aux règles d'accès que nous avons définies dans la couche Unity Catalog. Nous améliorerons également cette configuration plus tard cette année avec une couche d'autorisation supplémentaire via les Metric Views, afin que les utilisateurs n'aient plus besoin d'un accès aux données brutes, mais seulement d'un accès au niveau des métriques et des dimensions.
Le Résultat : Interopérabilité
Le bénéfice de cette architecture est l'interopérabilité. En sortant la logique métier des outils BI propriétaires et en la plaçant dans la couche sémantique du Lakehouse, nous nous préparons pour l'avenir. Une métrique définie une fois dans cette couche devient instantanément disponible pour :
- Databricks Dashboards pour le reporting standard.
- Genie pour l'analyse assistée par IA dans une interface conversationnelle utilisant le langage naturel.
- Outils et Applications Externes via des connecteurs standardisés.
Cette centralisation est la clé de notre prochaine étape majeure : permettre aux entreprises de « parler » à leurs données.
L'Analyse Conversationnelle Assistée par IA
Les tableaux de bord sont essentiels pour répondre aux questions quotidiennes et récurrentes. Cependant, la vitesse des affaires dépasse souvent la capacité du reporting standard à tout capturer. Par exemple, un Category Manager pourrait avoir besoin de savoir : « Quelles marques de baskets ont eu un taux de clics élevé mais ne se sont pas classées parmi les 10 premières par nombre d'articles vendus en Allemagne la semaine dernière ? » Répondre à des questions nouvelles comme celle-ci, non couvertes par les rapports standard existants, nécessitait fréquemment la création d'un nouveau tableau de bord. Même avec des outils en libre-service, un décalage significatif en termes de « temps d'obtention de l'information » persistait. Les utilisateurs devaient trouver le bon jeu de données, configurer des widgets et appliquer des filtres avant de pouvoir obtenir une réponse. Cela entraînait souvent des tableaux de bord ponctuels, contribuant à la prolifération des tableaux de bord et à une réduction de la découvrabilité.
Pour optimiser l'expérience utilisateur, nous avons évalué plusieurs solutions « Parler aux Données » offrant des interfaces conversationnelles basées sur les LLM, souvent appelées chatbots IA. Genie a obtenu les meilleurs résultats car il est ancré dans une couche sémantique unifiée, tandis que les solutions sans cette couche peinaient à générer du SQL complexe pour la logique métier.
C'est pourquoi l'introduction des Metric Views s'est avérée déterminante pour l'analyse conversationnelle assistée par IA comme Genie. En orientant Genie vers les Metric Views préétablies (comme détaillé dans la Section 2), nous avons réalisé une avancée critique : des réponses cohérentes et fiables ancrées dans des définitions métier gouvernées.
Pourquoi Metric Views augmente considérablement la précision de l'IA
Le plus grand obstacle à l'adoption de l'IA dans l'analyse est la confiance. Si un LLM génère une requête SQL erronée, les chiffres seront faux et les utilisateurs perdront confiance.
Genie résout ce problème en travaillant avec notre couche sémantique dans les Metric Views.
- Pas de conjectures : Lorsqu'un utilisateur demande la « VNM » (Valeur Nette Marchande), Genie n'essaie pas de la calculer à partir des tables brutes. Il reconnaît la « VNM » comme une métrique gouvernée dans notre vue de métrique et interroge simplement la logique prédéfinie. Ainsi, la vue de métrique réduit la complexité de la génération d'une instruction SQL, conduisant à une plus grande précision.
- Conscient du Contexte : Nous avons beaucoup investi dans l'enrichissement des métadonnées de notre Unity Catalog, en ajoutant des descriptions, des synonymes et des exemples de requêtes. Genie utilise ce contexte pour comprendre que lorsqu'un utilisateur dit « Annulations », il fait spécifiquement référence aux commandes annulées avant l'expédition, conformément à notre définition interne.
Autonomisation de la Ligne de Front
Nous avons testé Genie avec des équipes non techniques, telles que des merchandisers, des acheteurs et des analystes de prix, qui s'appuyaient historiquement sur des exportations Excel ou des outils BI. Les retours ont été immédiats : les utilisateurs pouvaient obtenir des réponses rapides à des questions granulaires (par exemple, la performance d'un marché spécifique associée à un type d'appareil spécifique) sans avoir besoin de connaître une seule ligne de SQL ni de passer du temps à créer une vue de rapport personnalisée.
L'introduction du nouveau Mode Agent a considérablement amélioré l'expérience utilisateur. Le Mode Agent analyse automatiquement les données pour identifier la cause profonde des résultats d'analyse, permettant aux utilisateurs de simplement demander « pourquoi » quelque chose s'est produit. Chez Zalando, cela pourrait réduire le temps de préparation de nos réunions de performance régulières — où des décisions de pilotage critiques sont prises — de plusieurs heures à quelques minutes seulement.
Cependant, avec ses fonctionnalités étendues, Genie peut également devenir coûteux s'il n'est pas configuré correctement, par exemple, sur des tables et des vues non agrégées. C'est pourquoi il est essentiel de sélectionner soigneusement les données et le contexte utilisés par Genie. De plus, nous reconnaissons le potentiel d'amélioration, comme l'avantage d'introduire une gestion complète des versions de Genie et de permettre des mises à jour programmatiques des configurations de Genie, sur lesquelles Databricks travaille déjà et qui est actuellement partiellement prise en charge.Mise à l'échelle de Genie pour l'adoption en entreprise
Nous ne traitons pas Genie comme une simple expérience en bac à sable ; nous l'intégrons dans nos opérations d'entreprise. Nos domaines d'intervention pour la mise à l'échelle comprennent :
- Établir la gouvernance : Les espaces Genie sélectionnés seront soutenus par des vues métriques gouvernées et correctement entretenues.
- Assurer la fiabilité des données : Nous collaborons avec les équipes propriétaires des données pour établir des espaces Genie sélectionnés. Ces espaces offriront des représentations analytiques de leurs données via des vues métriques, garantissant que la qualité des données est maintenue par les propriétaires des données eux-mêmes.
- Intégration avec Agent Bricks ou utilisation de Genies dans Databricks One : Nous prévoyons d'orchestrer ces espaces Genie sélectionnés en utilisant soit Agent Bricks, soit les Genies dans Databricks One. Cette approche garantit que les utilisateurs disposent d'un point d'entrée unique et unifié pour toutes leurs demandes de données.
En combinant la gouvernance d'Unity Catalog, la standardisation de la logique métier via les vues métriques et l'intelligence de Genie, nous construisons une culture de données où « interroger les données » est aussi simple que de demander à un collègue.
Merci à Merve Karali, Tobias Efinger, et Roberto Bruno Martins pour leur contribution à cet article.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.