Amélioration de la récupération et du RAG avec le réglage fin des modèles d'intégration
par Jacob Portes, Andrew Drozdov, Erica Ji Yuen, Vincent Chen, Sean Kulinski, Milo Cress, Colton Peltier, Sam Havens, Michael Carbin, Vitaliy Chiley et Connor Jennings
- Comment le réglage fin des modèles d'intégration améliore la précision de la récupération et du RAG
- Gains de performance clés sur les benchmarks
- Démarrer avec le réglage fin des intégrations sur Databricks
Affiner les modèles d'intégration pour une meilleure récupération et RAG
En bref : Affiner un modèle d'intégration sur des données spécifiques au domaine peut améliorer considérablement la recherche vectorielle et la précision de la génération augmentée par récupération (RAG). Avec Databricks, il est facile d'affiner, de déployer et d'évaluer des modèles d'intégration pour optimiser la récupération pour votre cas d'utilisation spécifique, en tirant parti de données synthétiques sans étiquetage manuel.
Pourquoi c'est important : Si votre système de recherche vectorielle ou RAG ne renvoie pas les meilleurs résultats, affiner un modèle d'intégration est un moyen simple mais puissant d'améliorer les performances. Que vous traitiez des documents financiers, des bases de connaissances ou de la documentation de code interne, l'affinage peut vous donner des résultats de recherche plus pertinents et de meilleures réponses LLM en aval.
Ce que nous avons trouvé : Nous avons affiné et testé deux modèles d'intégration sur trois ensembles de données d'entreprise et avons constaté des améliorations majeures des métriques de récupération (Recall@10) et des performances RAG en aval. Cela signifie que l'affinage peut changer la donne pour la précision sans nécessiter d'étiquetage manuel, en utilisant uniquement vos données existantes.
Vous voulez essayer l'affinage d'intégration ? Nous fournissons une solution de référence pour vous aider à démarrer. Databricks facilite la recherche vectorielle, la RAG, le reranking et l'affinage d'intégration. Contactez votre responsable de compte Databricks ou votre architecte de solutions pour plus d'informations.
{kind=link}
Pourquoi affiner les intégrations ?
Les modèles d'intégration alimentent les systèmes modernes de recherche vectorielle et RAG. Un modèle d'intégration transforme le texte en vecteurs, ce qui permet de trouver du contenu pertinent basé sur le sens plutôt que sur de simples mots-clés. Cependant, les modèles prêts à l'emploi ne sont pas toujours optimisés pour votre domaine spécifique, c'est là qu'intervient l'affinage.
L'affinage d'un modèle d'intégration sur des données spécifiques au domaine aide de plusieurs manières :
- Améliorer la précision de la récupération : les intégrations personnalisées améliorent les résultats de recherche en s'alignant sur vos données.
- Améliorer les performances RAG : une meilleure récupération réduit les hallucinations et permet des réponses d'IA générative plus fondées.
- Améliorer le coût et la latence : un modèle affiné plus petit peut parfois surpasser des alternatives plus grandes et plus coûteuses.
Dans cet article de blog, nous montrons que l'affinage d'un modèle d'intégration est un moyen efficace d'améliorer les performances de récupération et RAG pour des cas d'utilisation d'entreprise spécifiques à une tâche.
Résultats : l'affinage fonctionne
Nous avons affiné deux modèles d'intégration (gte-large-en-v1.5 et e5-mistral-7b-instruct) sur des données synthétiques et les avons évalués sur trois ensembles de données de notre Domain Intelligence Benchmark Suite (DIBS) (FinanceBench, ManufactQA et Databricks DocsQA). Nous les avons ensuite comparés à text-embedding-3-large d'OpenAI.
Points clés à retenir :
- L'affinage a amélioré la précision de la récupération sur tous les ensembles de données, surpassant souvent de manière significative les modèles de base.
- Les intégrations affinées ont donné des résultats égaux ou meilleurs que le reranking dans de nombreux cas, montrant qu'elles peuvent être une solution autonome solide.
- Une meilleure récupération a conduit à de meilleures performances RAG sur FinanceBench, démontrant des avantages de bout en bout.
Performances de récupération
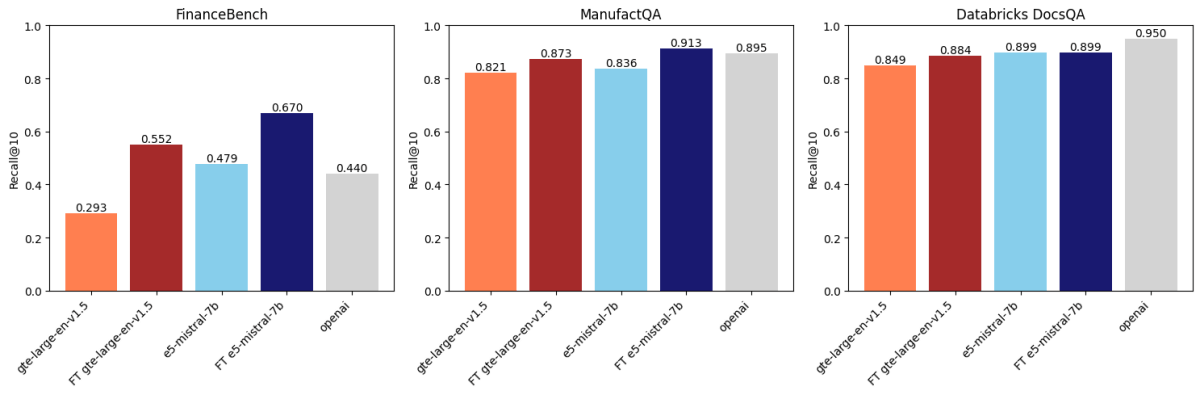
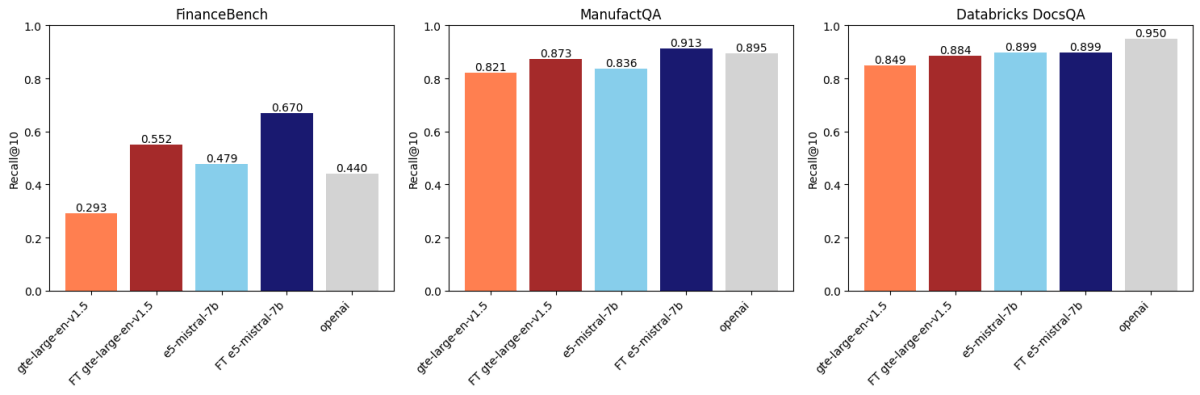
Après comparaison sur trois ensembles de données, nous avons constaté que l'affinage des intégrations améliore la précision sur deux de ces ensembles de données. La figure 1 montre que pour FinanceBench et ManufactQA, les intégrations affinées ont surpassé leurs versions de base, battant parfois même le modèle API d'OpenAI (gris clair). Pour Databricks DocsQA, cependant, la précision de text-embedding-3-large d'OpenAI surpasse tous les modèles affinés. Il est possible que ce soit parce que le modèle a été entraîné sur la documentation publique de Databricks. Cela montre que si l'affinage peut être efficace, il dépend fortement de l'ensemble de données d'entraînement et de la tâche d'évaluation.
Affinage vs. Reranking
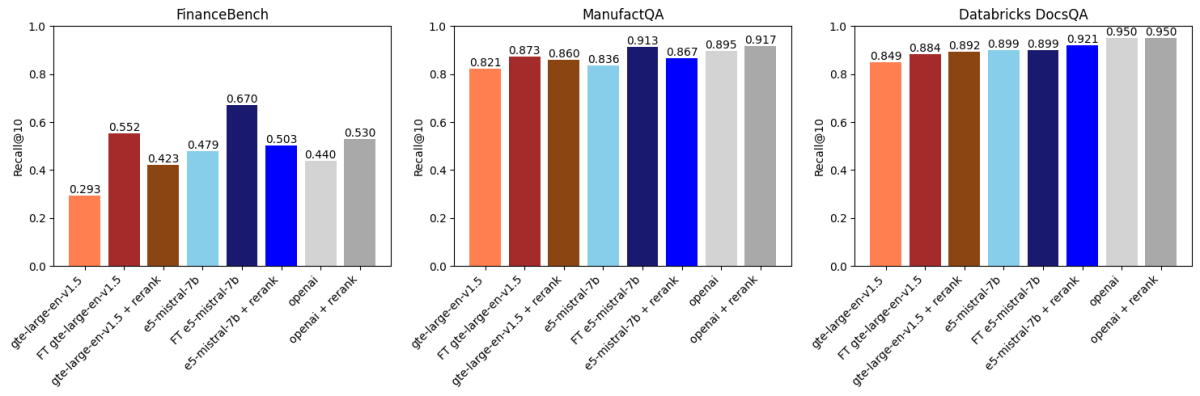
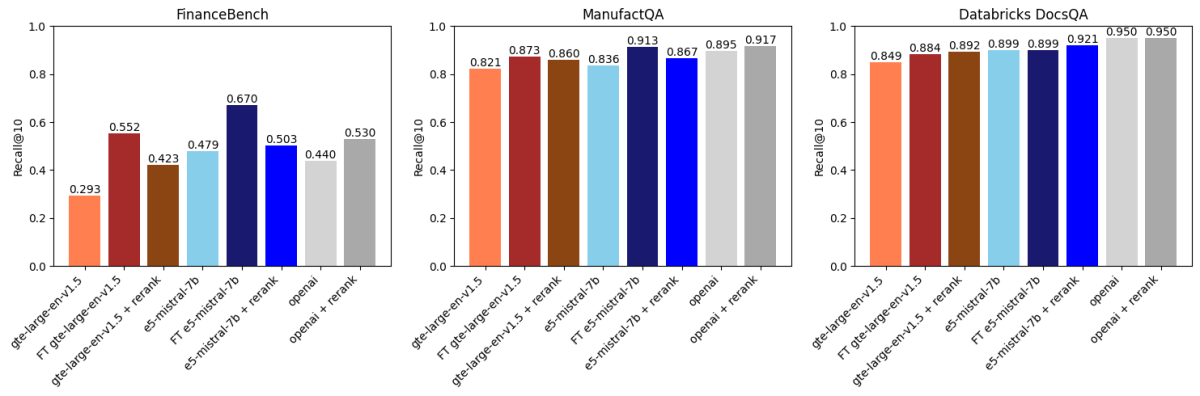
Nous avons ensuite comparé les résultats ci-dessus avec le reranking basé sur API en utilisant voyageai/rerank-1 (Figure 2). Un reranker prend généralement les k meilleurs résultats récupérés par un modèle d'intégration, réordonne ces résultats par pertinence par rapport à la requête de recherche, puis renvoie les k meilleurs réordonnés (dans notre cas k=30 suivi de k=10). Cela fonctionne car les rerankers sont généralement des modèles plus grands et plus puissants que les modèles d'intégration et modélisent également l'interaction entre la requête et le document d'une manière plus expressive.
{kind=link}
Ce que nous avons trouvé :
- L'affinage de gte-large-en-v1.5 a surpassé le reranking sur FinanceBench et ManufactQA.
- text-embedding-3-large d'OpenAI a bénéficié du reranking, mais les améliorations ont été marginales sur certains ensembles de données.
- Pour Databricks DocsQA, le reranking a eu un impact plus faible, mais l'affinage a tout de même apporté des améliorations, montrant la nature dépendante des données de ces méthodes.
Les rerankers entraînent généralement une latence d'inférence et un coût supplémentaires par requête par rapport aux modèles d'intégration. Cependant, ils peuvent être utilisés avec des bases de données vectorielles existantes et peuvent dans certains cas être plus rentables que la ré-intégration de données avec un modèle d'intégration plus récent. Le choix d'utiliser un reranker dépend de votre domaine et de vos exigences en matière de latence/coût.
L'affinage améliore les performances RAG
Pour FinanceBench, une meilleure récupération s'est traduite directement par une meilleure précision RAG lorsqu'elle était combinée avec GPT-4o (voir l'annexe). Cependant, dans les domaines où la récupération était déjà forte, comme Databricks DocsQA, l'affinage n'a pas ajouté grand-chose, soulignant que l'affinage fonctionne mieux lorsque la récupération est un goulot d'étranglement évident.
Comment nous avons affiné et évalué les modèles d'intégration
Voici quelques détails plus techniques sur notre génération de données synthétiques, notre affinage et notre évaluation.
Modèles d'intégration
Nous avons affiné deux modèles d'intégration open-source :
- gte-large-en-v1.5 est un modèle d'intégration populaire basé sur BERT Large (434 millions de paramètres, 1,75 Go). Nous avons choisi d'exécuter des expériences sur ce modèle en raison de sa taille modeste et de sa licence ouverte. Ce modèle d'int�égration est également actuellement pris en charge sur l'API de modèles fondamentaux Databricks.
- e5-mistral-7b-instruct appartient à une nouvelle classe de modèles d'intégration construits sur de puissants LLM (dans ce cas Mistral-7b-instruct-v0.1). Bien que e5-mistral-7b-instruct soit meilleur sur les benchmarks d'intégration standard tels que MTEB et soit capable de gérer des invites plus longues et plus nuancées, il est beaucoup plus grand que gte-large-en-v1.5 (car il a 7 milliards de paramètres) et est légèrement plus lent et plus cher à servir.
Nous les avons ensuite comparés à text-embedding-3-large d'OpenAI.
Ensembles de données d'évaluation
Nous avons évalué tous les modèles sur les ensembles de données suivants de notre Domain Intelligence Benchmark Suite (DIBS) : FinanceBench, ManufactQA et Databricks DocsQA.
| Ensemble de données | Description | # Requêtes | # Corpus |
|---|---|---|---|
| FinanceBench | Questions sur les documents SEC 10-K générées par des experts humains. La récupération s'effectue sur des pages individuelles d'un surensemble de 360 dépôts SEC 10-K. | 150 | 53 399 |
| ManufactQA | Questions et réponses échantillonnées à partir de forums publics d'un fabricant d'appareils électroniques. | 6 787 | 6 787 |
| Databricks DocsQA | Questions basées sur la documentation Databricks publiquement disponible, générées par des experts Databricks. | 139 | 7 561 |
Nous rapportons le rappel@10 comme métrique de récupération principale ; cela mesure si le document correct se trouve dans les 10 meilleurs documents récupérés.
La référence absolue pour la qualité des modèles d'intégration est le benchmark MTEB, qui intègre des tâches de récupération comme BEIR ainsi que de nombreuses autres tâches de non-récupération. Bien que des modèles comme gte-large-en-v1.5 et e5-mistral-7b-instruct obtiennent de bons résultats sur MTEB, nous étions curieux de voir comment ils se comportaient sur nos tâches d'entreprise internes.
Données d'entraînement
Nous avons entraîné des modèles distincts sur des données synthétiques adaptées à chacun des benchmarks ci-dessus :
| Ensemble d'entraînement | Description | # Échantillons uniques |
|---|---|---|
| FinanceBench synthétique | Requêtes générées à partir de 2 400 documents SEC 10-K | ~6 000 |
| Databricks Docs QA synthétique | Requêtes générées à partir de la documentation publique Databricks. | 8 727 |
| ManufactQA | Requêtes générées à partir de PDF de fabrication électronique | 14 220 |
Afin de générer l'ensemble d'entraînement pour chaque domaine, nous avons pris des documents existants et généré des requêtes d'échantillons basées sur le contenu de chaque document à l'aide de LLM tels que Llama 3 405B. Les requêtes synthétiques ont ensuite été filtrées pour la qualité par un LLM-as-a-judge (GPT4o). Les requêtes filtrées et leurs documents associés ont ensuite été utilisés comme paires contrastives pour le réglage fin. Nous avons utilisé des négatifs en lot pour l'entraînement contrastif, mais l'ajout de négatifs difficiles pourrait améliorer davantage les performances (voir Annexe).
Réglage des hyperparamètres
Nous avons effectué des balayages sur :
- Taux d'apprentissage, taille du lot, température softmax
- Nombre d'époques (1 à 3 époques testées)
- Variations des invites de requête (par exemple, "Requête :" vs. invites basées sur des instructions)
- Stratégie de regroupement (regroupement moyen vs. regroupement du dernier jeton)
Tout le réglage fin a été effectué à l'aide des bibliothèques open source mosaicml/composer, mosaicml/llm-foundry et mosaicml/streaming sur la plateforme Databricks.
Comment améliorer la recherche vectorielle et le RAG sur Databricks
Le réglage fin n'est qu'une approche pour améliorer les performances de la recherche vectorielle et du RAG ; nous listons quelques approches supplémentaires ci-dessous.
Pour une meilleure récupération :
- Utilisez un meilleur modèle d'intégration : De nombreux utilisateurs travaillent sans le savoir avec des intégrations obsolètes. Le simple remplacement par un modèle plus performant peut apporter des gains immédiats. Consultez le tableau de classement MTEB pour les meilleurs modèles.
- Essayez la recherche hybride : Combinez les intégrations denses avec la recherche par mots-clés pour une précision améliorée. Databricks AI Search facilite cela avec une solution en un clic.
- Utilisez un reranker : Un reranker peut affiner les résultats en les réorganisant en fonction de leur pertinence. Databricks propose cela comme fonctionnalité intégrée (actuellement en aperçu privé). Contactez votre responsable de compte pour l'essayer.
Pour un meilleur RAG :
- Optimisez vos invites : De petites modifications dans les invites LLM peuvent améliorer considérablement les réponses. DSPy peut aider à automatiser ce processus (voir Créer des applications genAI avec DSPy sur Databricks).
- Mettez à niveau votre LLM : Si la récupération est bonne mais les réponses faibles, envisagez d'utiliser un meilleur modèle génératif.
- Réglez finement un LLM : Si votre domaine est unique et que vous disposez de suffisamment de données, le réglage fin d'un modèle comme Llama 3 peut encore améliorer la qualité du RAG. Voir Formation de modèles Databricks : Réglez finement votre LLM sur Databricks pour des tâches et des connaissances spécifiques pour plus de détails.
Commencez le réglage fin sur Databricks
Le réglage fin des intégrations peut être un gain facile pour améliorer la récupération et le RAG dans vos systèmes d'IA. Sur Databricks, vous pouvez :
- Réglez finement et servez des modèles d'intégration sur une infrastructure évolutive.
- Utilisez des outils intégrés pour la recherche vectorielle, le reranking et le RAG.
- Testez rapidement différents modèles pour trouver ce qui convient le mieux à votre cas d'utilisation.
Prêt à essayer ? Nous avons créé une solution de référence pour faciliter le réglage fin — contactez votre responsable de compte Databricks ou votre architecte de solutions pour y accéder.
Annexe
Tableau 1 : Comparaison de gte-large-en-v1.5, e5-mistral-7b-instruct et text-embedding-3-large. Mêmes données que la Figure 1.
Génération de données d'entraînement synthétiques
Pour tous les jeux de données, les requêtes de l'ensemble d'entraînement n'étaient pas les mêmes que celles de l'ensemble de test. Cependant, dans le cas de Databricks DocsQA (mais pas FinanceBench ni ManufactQA), les documents utilisés pour générer des requêtes synthétiques étaient les mêmes que ceux utilisés dans l'ensemble d'évaluation. L'objectif de notre étude est d'améliorer la récupération sur des tâches et des domaines spécifiques (par opposition à un modèle d'intégration généralisable en zero-shot) ; nous considérons donc cette approche comme valide pour certains cas d'utilisation en production. Pour FinanceBench et ManufactQA, les documents utilisés pour générer des données synthétiques n'ont pas chevauché le corpus utilisé pour l'évaluation.
Il existe différentes manières de sélectionner des passages négatifs pour l'entraînement contrastif. Ils peuvent être sélectionnés aléatoirement ou pré-définis. Dans le premier cas, les passages négatifs sont sélectionnés à partir du lot d'entraînement ; ceux-ci sont souvent appelés "in-batch negatives" ou « soft negatives ». Dans le second cas, l'utilisateur présélectionne des exemples de texte sémantiquement difficiles, c'est-à-dire qu'ils sont potentiellement liés à la requête mais légèrement incorrects ou non pertinents. Ce second cas est parfois appelé "hard negatives". Dans ce travail, nous avons simplement utilisé des "in-batch negatives" ; la littérature indique que l'utilisation de "hard negatives" conduirait probablement à de meilleurs résultats encore.
Détails du finetuning
Pour toutes les expériences de finetuning, la longueur maximale de séquence est fixée à 2048. Nous avons ensuite évalué tous les checkpoints. Pour toute la comparaison de performances, les documents du corpus ont été tronqués à 2048 tokens (pas découpés), ce qui était une contrainte raisonnable pour nos jeux de données spécifiques. Nous avons choisi les meilleures bases de référence sur chaque benchmark après avoir balayé les invites de requête et la stratégie de pooling.
Amélioration des performances RAG
Un système RAG se compose à la fois d'un récupérateur et d'un modèle génératif. Le récupérateur sélectionne un ensemble de documents pertinents pour une requête particulière, puis les transmet au modèle génératif. Nous avons sélectionné les meilleurs modèles gte-large-en-v1.5 finetunés et les avons utilisés pour la première étape de récupération d'un système RAG simple (en suivant l'approche générale décrite dans Long Context RAG Performance of LLMs et The Long Context RAG Capabilities of OpenAI o1 and Google Gemini). En particulier, nous avons récupéré k=10 documents, chacun d'une longueur maximale de 512 tokens, et utilisé GPT4o comme LLM génératif. La précision finale a été évaluée à l'aide d'un LLM-as-a-judge (GPT4o).
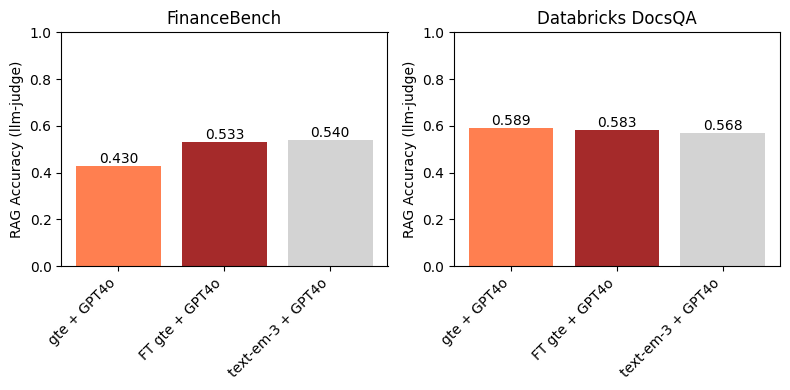
Sur FinanceBench, la Figure 3 montre que l'utilisation d'un modèle d'intégration finetuné améliore la précision RAG en aval. De plus, il est compétitif avec text-embedding-3-large. Ceci est attendu, puisque le finetuning de gte a conduit à une amélioration significative du Recall@10 par rapport à la base de référence gte (Figure 1). Cet exemple souligne l'efficacité du finetuning du modèle d'intégration sur des domaines et des jeux de données spécifiques.
Sur le jeu de données Databricks DocsQA, nous ne trouvons aucune amélioration lors de l'utilisation du modèle gte finetuné par rapport à la base de référence gte. Ceci est quelque peu attendu, étant donné que les marges entre les modèles de base et finetunés dans les Figures 1 et 2 sont faibles. Fait intéressant, même si text-embedding-3-large a un Recall@10 (légèrement) plus élevé que n'importe lequel des modèles gte, il n'entraîne pas une précision RAG en aval plus élevée. Comme le montre la Figure 1, tous les modèles d'intégration avaient un Recall@10 relativement élevé sur le jeu de données Databricks DocsQA ; cela indique que la récupération n'est probablement pas le goulot d'étranglement pour RAG, et que le finetuning d'un modèle d'intégration sur ce jeu de données n'est pas nécessairement l'approche la plus fructueuse.
Nous tenons à remercier Quinn Leng et Matei Zaharia pour leurs commentaires sur ce billet de blog.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.