Améliorez facilement les performances de Text2SQL sur Databricks
par Matthew Hayes, Evion Kim, Linqing Liu, Alnur Ali, Ritendra Datta et Sam Shah
Vous voulez que votre LLM monte dans le top 10 de Spider, un benchmark largement utilisé pour les tâches de text-to-SQL ? Spider évalue la capacité des LLM à convertir des requêtes textuelles en code SQL.
Pour ceux qui ne connaissent pas le text-to-SQL, son importance réside dans la transformation de la manière dont les entreprises interagissent avec leurs données. Au lieu de s'appuyer sur des experts SQL pour écrire des requêtes, les utilisateurs peuvent simplement poser des questions sur leurs données en langage naturel et obtenir des réponses précises. Cela démocratise l'accès aux données, améliore la business intelligence et permet une prise de décision plus éclairée.
Le benchmark Spider est une norme largement reconnue pour évaluer les performances des systèmes text-to-SQL. Il met au défi les LLM de traduire des requêtes en langage naturel en instructions SQL précises, nécessitant une compréhension approfondie des schémas de base de données et la capacité de générer du code SQL syntaxiquement et sémantiquement correct.
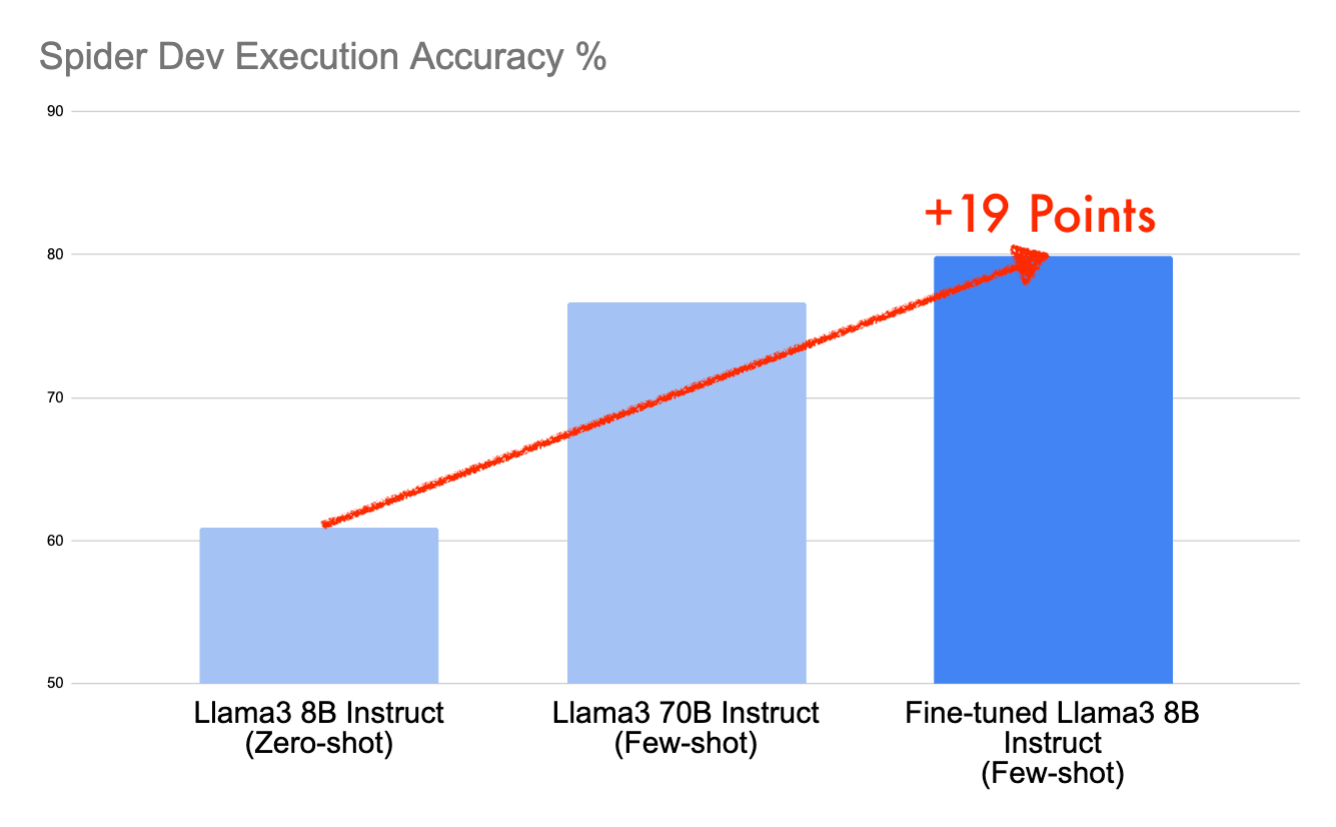
Dans cet article, nous allons expliquer comment nous avons obtenu des scores de 79,9 % sur le jeu de données de développement Spider et 78,9 % sur le jeu de données de test en moins d'une journée de travail en utilisant le modèle open-source Llama3 8B Instruct – une amélioration remarquable de 19 points par rapport à la base de référence. Cette performance nous placerait dans le top 10 du classement Spider, désormais gelé, grâce à un prompting et un fine-tuning stratégiques sur Databricks.
Prompting Zero-Shot pour les performances de base
Commençons par évaluer les performances de Meta Llama 3 8B Instruct sur le jeu de données de développement Spider en utilisant un format de prompt très simple composé des instructions CREATE TABLE qui ont créé les tables et d'une question à laquelle nous souhaitons répondre en utilisant ces tables :
Ce type de prompt est souvent appelé « zero-shot » car il n'y a pas d'autres exemples dans le prompt. Pour la première question du jeu de données de développement Spider, ce format de prompt produit :
L'exécution du benchmark Spider sur le jeu de données de développement en utilisant ce format produit un score global de 60,9 mesuré par la précision d'exécution et le décodage greedy. Cela signifie que dans 60,9 % des cas, le modèle produit un SQL qui, une fois exécuté, donne les mêmes résultats qu'une requête « gold » représentant la solution correcte.
| Easy | Medium | Hard | Extra | All | |
|---|---|---|---|---|---|
| Zero-shot | 78.6 | 69.3 | 42.5 | 31.3 | 60.9 |
Une fois le score de base établi, avant même de commencer le fine-tuning, essayons différentes stratégies de prompting pour tenter d'améliorer le score du modèle de base sur le jeu de données de développement Spider.
Prompting avec des lignes d'échantillons
L'un des inconvénients du premier prompt que nous avons utilisé est qu'il ne fournit aucune information sur les données des colonnes au-delà du type de données. Un article sur l'évaluation des capacités text-to-SQL des modèles avec Spider a révélé que l'ajout de lignes échantillonnées au prompt entraînait un score plus élevé. Essayons donc cela.
Nous pouvons mettre à jour le format du prompt ci-dessus afin que les requêtes create table incluent également les premières lignes de chaque table. Pour la même question que précédemment, nous avons maintenant un prompt mis à jour :
L'inclusion de lignes d'échantillons pour chaque table augmente le score global d'environ 6 points de pourcentage pour atteindre 67,0 :
| Easy | Medium | Hard | Extra | All | |
|---|---|---|---|---|---|
| Zero-shot with sample rows | 80.6 | 75.3 | 51.1 | 41.0 | 67.0 |
Prompting Few-Shot
Le prompting few-shot est une stratégie bien connue utilisée avec les LLM où nous pouvons améliorer les performances sur une tâche telle que la génération de SQL correct en incluant quelques exemples démontrant la tâche à effectuer. Avec un prompt zero-shot, nous avons fourni les schémas puis posé une question. Avec un prompt few-shot, nous fournissons quelques schémas, une question, le SQL qui répond à cette question, puis nous répétons cette séquence quelques fois avant d'arriver à la question réelle que nous voulons poser. Cela se traduit généralement par de meilleures performances qu'un prompt zero-shot.
Une bonne source d'exemples démontrant la tâche de génération de SQL est en fait le jeu de données d'entraînement Spider lui-même. Nous pouvons prendre un échantillon aléatoire de quelques questions de ce jeu de données avec leurs tables correspondantes et construire un prompt few-shot démontrant le SQL qui peut répondre à chacune de ces questions. Puisque nous utilisons maintenant des lignes d'échantillons comme dans le prompt précédent, nous devrions également nous assurer que l'un de ces exemples inclut également des lignes d'échantillons pour démontrer leur utilisation.
Une autre amélioration que nous pouvons apporter au prompt zero-shot précédent est d'inclure également un « system prompt » au début. Les system prompts sont généralement utilisés pour fournir des instructions détaillées au modèle qui décrivent la tâche à effectuer. Bien qu'un utilisateur puisse poser plusieurs questions au cours d'une conversation avec un modèle, le system prompt est fourni une seule fois avant même que l'utilisateur ne pose une question, établissant essentiellement les attentes quant à la manière dont le « système » doit se comporter pendant la conversation.
Avec ces stratégies à l'esprit, nous pouvons construire un prompt few-shot qui commence également par un message système représenté par un grand bloc de commentaires SQL en haut, suivi de trois exemples :
Ce nouveau prompt a abouti à un score de 70,8, ce qui représente une amélioration supplémentaire de 3,8 points de pourcentage par rapport à notre score précédent. Nous avons augmenté le score de près de 10 points de pourcentage par rapport à notre point de départ, simplement grâce à des stratégies de prompting simples.
| Easy | Medium | Hard | Extra | All | |
|---|---|---|---|---|---|
| Few-shot with sample rows | 83.9 | 79.1 | 55.7 | 44.6 | 70.8 |
Nous atteignons probablement maintenant le point de rendements décroissants en ajustant notre prompt. Affinons le modèle pour voir quelles autres améliorations peuvent être réalisées.
Affiner avec LoRA
Si nous affinons le modèle, la première question est de savoir quelles données d'entraînement utiliser. Spider inclut un jeu de données d'entraînement, donc cela semble être un bon point de départ. Pour affiner le modèle, nous utiliserons QLoRA afin de pouvoir entraîner efficacement le modèle sur un cluster GPU Databricks unique A100 80 Go tel que Standard_NC24ads_A100_v4 dans Databricks. Cela peut être réalisé en environ quatre heures en utilisant les 7k enregistrements du jeu de données d'entraînement Spider. Nous avons déjà discuté de l'affinage avec LoRA dans un article de blog précédent. Les lecteurs intéressés peuvent se référer à cet article pour plus de détails. Nous pouvons suivre des recettes d'entraînement standard en utilisant les bibliothèques trl, peft et bitsandbytes.
Bien que nous obtenions les enregistrements d'entraînement de Spider, nous devons toujours les formater d'une manière dont le modèle puisse apprendre. L'objectif est de mapper chaque enregistrement, composé du schéma (avec des exemples de lignes), de la question et du SQL, en une seule chaîne de texte. Nous commençons par effectuer un traitement sur le jeu de données brut Spider. À partir des données brutes, nous produisons un jeu de données où chaque enregistrement se compose de trois champs : schema_with_rows, question et query. Le champ schema_with_rows est dérivé des tables correspondant à la question, en suivant le format de l'instruction CREATE TABLE et les lignes utilisées dans l'invite few-shot précédente.
Ensuite, chargez le tokenizer :
Nous allons définir une fonction de mappage qui convertira chaque enregistrement de notre jeu de données d'entraînement Spider traité en une chaîne de texte. Nous pouvons utiliser apply_chat_template du tokenizer pour formater commodément le texte dans le format de chat attendu par le modèle Instruct. Bien que ce ne soit pas exactement le même format que celui que nous utilisons pour notre invite few-shot, le modèle se généralise suffisamment bien pour fonctionner même si le formatage standard des invites est légèrement différent.
Pour SYSTEM_PROMPT, nous utilisons la même invite système que celle utilisée précédemment dans l'invite few-shot. Pour USER_MESSAGE_FORMAT, nous utilisons de même :
Avec cette fonction définie, il ne reste plus qu'à transformer le jeu de données Spider traité avec elle et à l'enregistrer sous forme de fichier JSONL.
Nous sommes maintenant prêts à entraîner. Quelques heures plus tard, nous avons un Llama3 8B Instruct affiné. La réexécution de notre invite few-shot sur ce nouveau modèle a donné un score de 79.9, ce qui représente une amélioration supplémentaire de 9 points de pourcentage par rapport à notre score précédent. Nous avons maintenant augmenté le score total d'environ 19 points de pourcentage par rapport à notre base de référence simple zero-shot.
| Facile | Moyen | Difficile | Supplémentaire | Total | |
|---|---|---|---|---|---|
| Few-shot avec exemples de lignes (Llama3 8B Instruct affiné) |
91.1 | 85.9 | 72.4 | 54.8 | 79.9 |
| Few-shot avec exemples de lignes (Llama3 8B Instruct) |
83.9 | 79.1 | 55.7 | 44.6 | 70.8 |
| Zero-shot avec exemples de lignes (Llama3 8B Instruct) |
80.6 | 75.3 | 51.1 | 41.0 | 67.0 |
| Zero-shot (Llama3 8B Instruct) |
78.6 | 69.3 | 42.5 | 31.3 | 60.9 |
Vous vous demandez peut-être maintenant comment le modèle Llama3 8B Instruct et sa version affinée se comparent à un modèle plus grand comme Llama3 70B Instruct. Nous avons répété le processus d'évaluation en utilisant le modèle 70B prêt à l'emploi sur le jeu de données dev avec huit GPU A100 40 Go et avons enregistré les résultats ci-dessous.
| Few-shot avec exemples de lignes (Llama3 70B Instruct) |
89.5 | 83.0 | 64.9 | 53.0 | 76.7 |
| Zero-shot avec exemples de lignes (Llama3 70B Instruct) |
83.1 | 81.8 | 59.2 | 36.7 | 71.1 |
| Zero-shot (Llama3 70B Instruct) |
82.3 | 80.5 | 57.5 | 31.9 | 69.2 |
Comme prévu, en comparant les modèles prêts à l'emploi, le modèle 70B surpasse le modèle 8B lorsqu'il est mesuré avec le même format d'invite. Mais ce qui est surprenant, c'est que le modèle Llama3 8B Instruct affiné obtient un score supérieur au modèle Llama3 70B Instruct de 3 points de pourcentage. Lorsqu'il est concentré sur des tâches spécifiques telles que le texte-vers-SQL, l'affinage peut produire de petits modèles dont les performances sont comparables à celles de modèles beaucoup plus grands.
Déployer vers un point de terminaison de service de modèle
Llama3 est pris en charge par les API de modèles fondamentaux à débit provisionné de Databricks, nous pourrions donc même déployer notre modèle Llama3 affiné vers un point de terminaison et l'utiliser pour alimenter des applications. Tout ce que nous avons à faire est d'enregistrer le modèle affiné dans Unity Catalog, puis créer un point de terminaison en utilisant l'interface utilisateur. Une fois déployé, nous pouvons l'interroger en utilisant des bibliothèques courantes.
Conclusion
Nous avons commencé notre parcours avec Llama3 8B Instruct sur le jeu de données dev Spider en utilisant une invite zero-shot, obtenant un score modeste de 60.9. En améliorant cela avec une invite few-shot — complète avec des messages système, plusieurs exemples et des exemples de lignes — nous avons augmenté notre score à 70.8. Des gains supplémentaires sont venus de l'affinage du modèle sur le jeu de données d'entraînement Spider, nous propulsant à un impressionnant 79.9 sur Spider dev et 78.9 sur Spider test. Cette augmentation significative de 19 points par rapport à notre point de départ et une avance de 3 points sur le Llama3 70B Instruct de base met non seulement en valeur les prouesses de notre modèle, mais nous assurerait également une place convoitée dans le top 10 des résultats sur Spider.
Apprenez-en davantage sur la façon de tirer parti de la puissance des LLM open source et de la plateforme d'intelligence des données en vous inscrivant au Data+AI Summit.
Annexe
Configuration de l'évaluation
La génération a été effectuée à l'aide de vLLM, du décodage glouton (température de 0), de deux GPU A100 80 Go et de 1024 tokens nouveaux maximum. Pour évaluer les générations, nous avons utilisé la suite de tests du dépôt taoyds/test-suite-sql-eval sur Github.
Configuration de l'entraînement
Voici les détails spécifiques sur la configuration de l'affinage :
| Modèle de base | Llama3 8B Instruct |
| GPU | A100 80 Go unique |
| Étapes maximales | 100 |
| Enregistrements du jeu de données d'entraînement Spider | 7000 |
| LoRA R | 16 |
| LoRA Alpha | 32 |
| LoRA Dropout | 0.1 |
| Taux d'apprentissage | 1.5e-4 |
| Planificateur de taux d'apprentissage | Constant |
| Étapes d'accumulation de gradient | 8 |
| Point de contrôle de gradient | True |
| Taille du lot d'entraînement | 12 |
| Modules cibles LoRA | q_proj,v_proj,k_proj,o_proj,gate_proj,up_proj,down_proj |
| Modèle de réponse du collateur de données | <|start_header_id|>assistant<|end_header_id|> |
Exemple d'invite zero-shot
Ceci est le premier enregistrement de l'ensemble de données dev que nous avons utilisé pour l'évaluation, formaté comme une invite zero-shot qui inclut les schémas de table. Les tables concernées par la question sont représentées à l'aide des instructions CREATE TABLE qui les ont créées.
Exemple d'invite zero-shot avec lignes d'exemple
Ceci est le premier enregistrement de l'ensemble de données dev que nous avons utilisé pour l'évaluation, formaté comme une invite zero-shot qui inclut les schémas de table et des exemples de lignes. Les tables concernées par la question sont représentées à l'aide des instructions CREATE TABLE qui les ont créées. Les lignes ont été sélectionnées à l'aide de "SELECT * {table_name} LIMIT 3" de chaque table, les noms de colonnes apparaissant comme en-tête.
Exemple d'invite few-shot avec lignes d'exemple
Ceci est le premier enregistrement de l'ensemble de données dev que nous avons utilisé pour l'évaluation, formaté comme une invite few-shot qui inclut les schémas de table et des exemples de lignes. Les tables concernées par la question sont représentées à l'aide des instructions CREATE TABLE qui les ont créées. Les lignes ont été sélectionnées à l'aide de "SELECT * {table_name} LIMIT 3" de chaque table, les noms de colonnes apparaissant comme en-tête.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.