Équilibrez intelligemment l'optimisation des coûts et la fiabilité sur Databricks
Plongez dans l'intersection de la gestion financière et du cloud computing sur la plateforme d'intelligence de données Databricks
par Vuong Nguyen et Wasim Ahmad
La plateforme Databricks Data Intelligence offre une flexibilité inégalée, permettant aux utilisateurs d’accéder à des ressources de calcul quasi instantanées et évolutives horizontalement. Cette facilité de création peut entraîner des coûts cloud incontrôlés si elle n’est pas gérée correctement.
Implémenter l'observabilité pour suivre et refacturer les coûts
Comment utiliser efficacement l'observabilité pour suivre et refacturer les coûts dans Databricks
Lorsque l'on travaille avec des écosystèmes techniques complexes, comprendre de manière proactive les inconnues est essentiel pour maintenir la stabilité de la plateforme et maîtriser les coûts. L'observabilité permet d'analyser et d'optimiser les systèmes en fonction des données qu'ils génèrent. Ceci est différent de la surveillance, qui se concentre sur l'identification de nouveaux modèles plutôt que sur le suivi des problèmes connus.
Fonctionnalités clés pour le suivi des coûts dans Databricks
Balises : Utilisez des balises pour catégoriser les ressources et les frais. Cela permet une allocation des coûts plus granulaire.
Tables système : Exploitez les tables système pour le suivi automatisé des coûts et la refacturation. Outils de surveillance des coûts natifs au cloud : Utilisez ces outils pour obtenir des informations sur les coûts de toutes les ressources.
Que sont les tables système et comment les utiliser
Databricks offre d'excellentes capacités d'observabilité à l'aide des tables système. Les tables système sont des magasins analytiques hébergés par Databricks des données opérationnelles d'un compte client, trouvées dans le catalogue système. Elles offrent une observabilité historique sur l'ensemble du compte et incluent des informations tabulaires conviviales sur la télémétrie de la plateforme. Des informations clés comme les données d'utilisation de la facturation sont disponibles dans les tables système (cela inclut actuellement uniquement le prix catalogue des DBU), chaque enregistrement d'utilisation représentant un agrégat horaire de l'utilisation facturable d'une ressource.
Comment activer les tables système
Les tables système sont gérées par Unity Catalog et nécessitent un espace de travail activé pour Unity Catalog pour y accéder. Elles incluent des données de tous les espaces de travail mais ne peuvent être interrogées qu'à partir d'espaces de travail activés. L'activation des tables système se fait au niveau du schéma - l'activation d'un schéma active toutes ses tables. Les administrateurs doivent activer manuellement les nouveaux schémas en utilisant l'API.

Que sont les balises Databricks et comment les utiliser
Le balisage Databricks vous permet d'appliquer des attributs (paires clé-valeur) aux ressources pour une meilleure organisation, recherche et gestion. Pour le suivi des coûts et la refacturation, les équipes peuvent baliser leurs tâches Databricks et leur calcul (Clusters, entrepôts SQL), ce qui peut les aider à suivre l'utilisation, les coûts et à les attribuer à des équipes ou des unités spécifiques.
Comment appliquer des balises
Les balises peuvent être appliquées aux ressources Databricks suivantes pour le suivi de l'utilisation et des coûts :
- Calcul Databricks
- Tâches Databricks
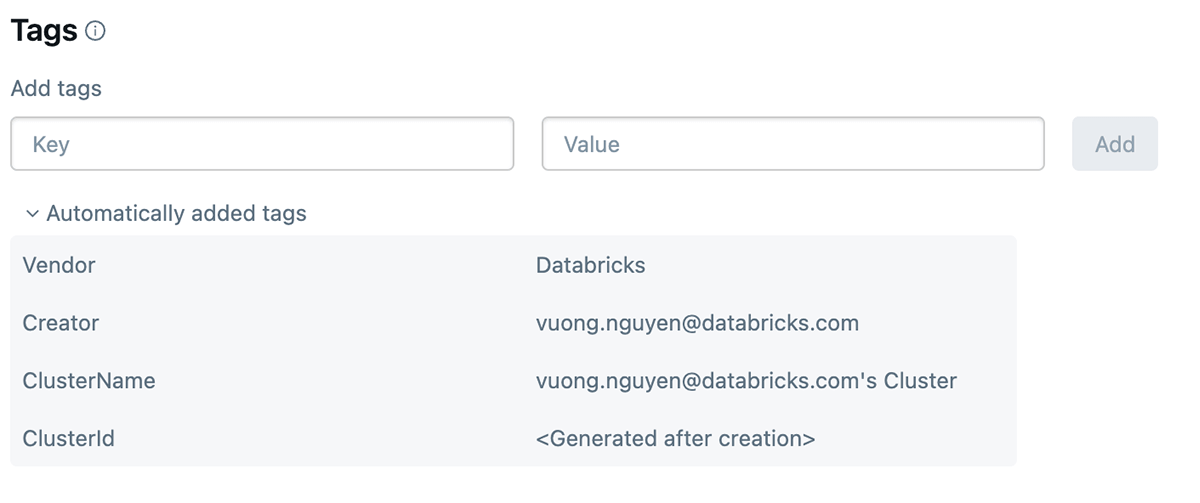
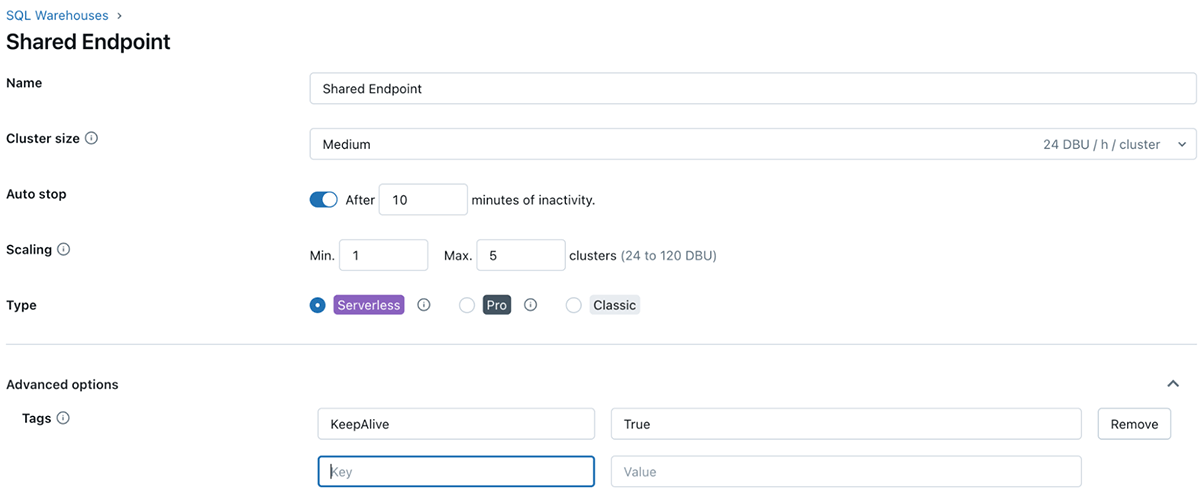
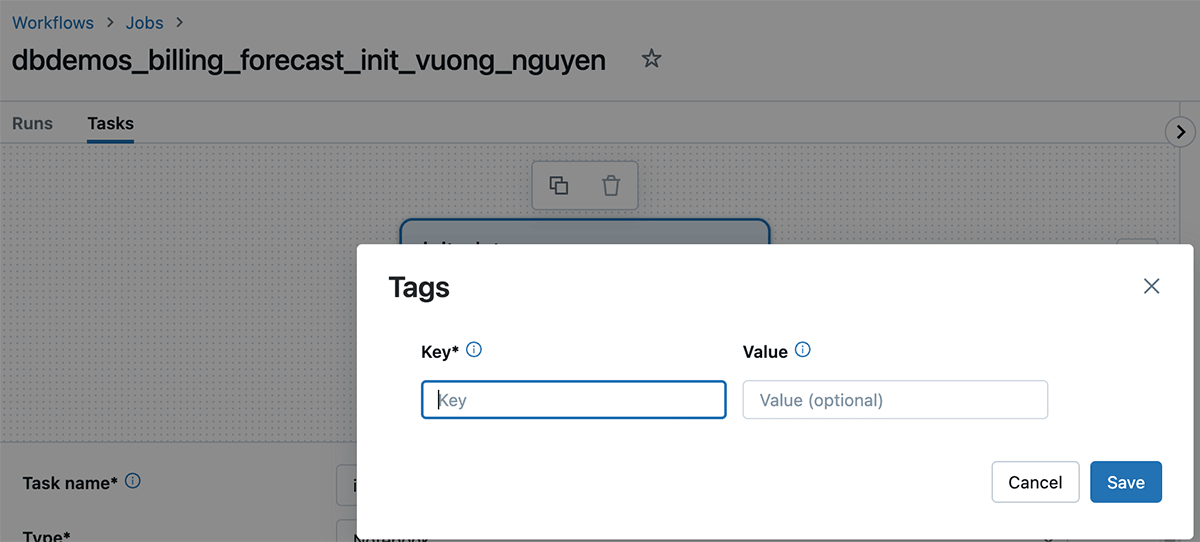
Une fois ces balises appliquées, une analyse détaillée des coûts peut être effectuée à l'aide des tables système d'utilisation facturable.
Comment identifier les coûts à l'aide des outils natifs du cloud
Pour surveiller les coûts et attribuer avec précision l'utilisation de Databricks aux unités commerciales et aux équipes de votre organisation (pour la refacturation, par exemple), vous pouvez baliser les espaces de travail (et les groupes de ressources gérés associés) ainsi que les ressources de calcul.
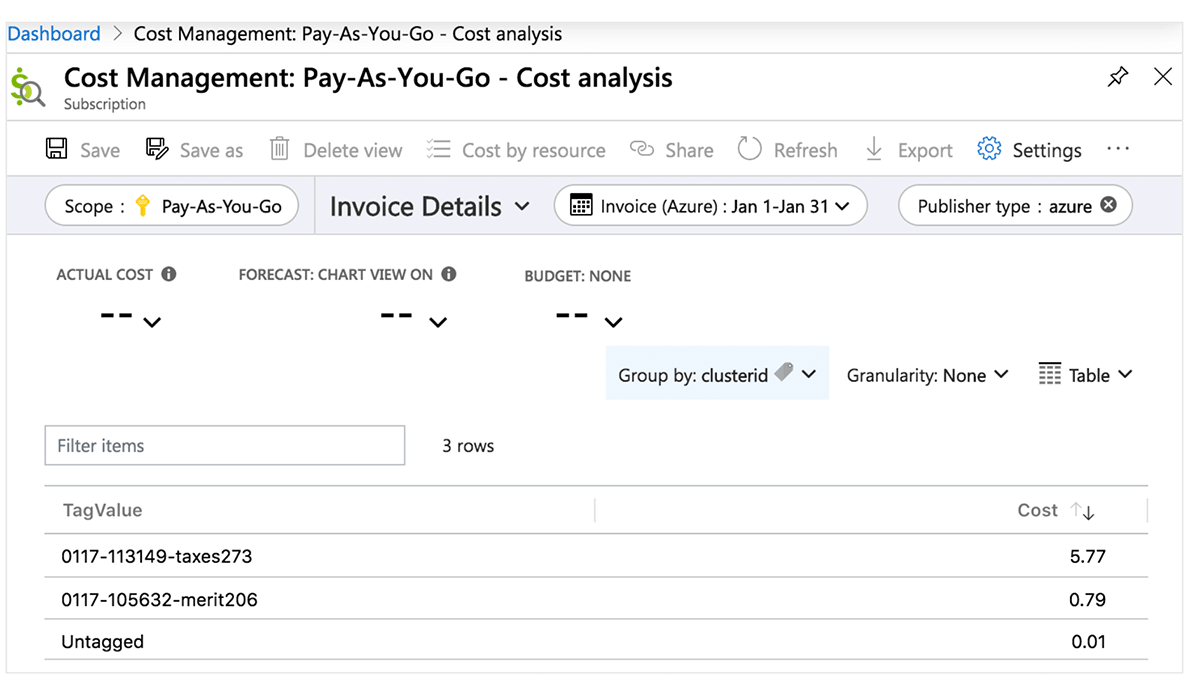
Centre de coûts Azure
Le tableau suivant détaille les objets Azure Databricks où des balises peuvent être appliquées. Ces balises peuvent se propager à des rapports d'analyse des coûts détaillés auxquels vous pouvez accéder dans le portail et à la table système d'utilisation facturable. Trouvez plus de détails sur la propagation des balises et les limitations dans Azure.
| Objet Azure Databricks | Interface de balisage (UI) | Interface de balisage (API) |
|---|---|---|
| Espace de travail | Portail Azure | API des ressources Azure |
| Pool | UI des pools dans l'espace de travail Azure Databricks | API des pools d'instances |
| Calcul tout usage et tâches | UI du calcul dans l'espace de travail Azure Databricks | API des clusters |
| Entrepôt SQL | UI de l'entrepôt SQL dans l'espace de travail Azure Databricks | API des entrepôts |
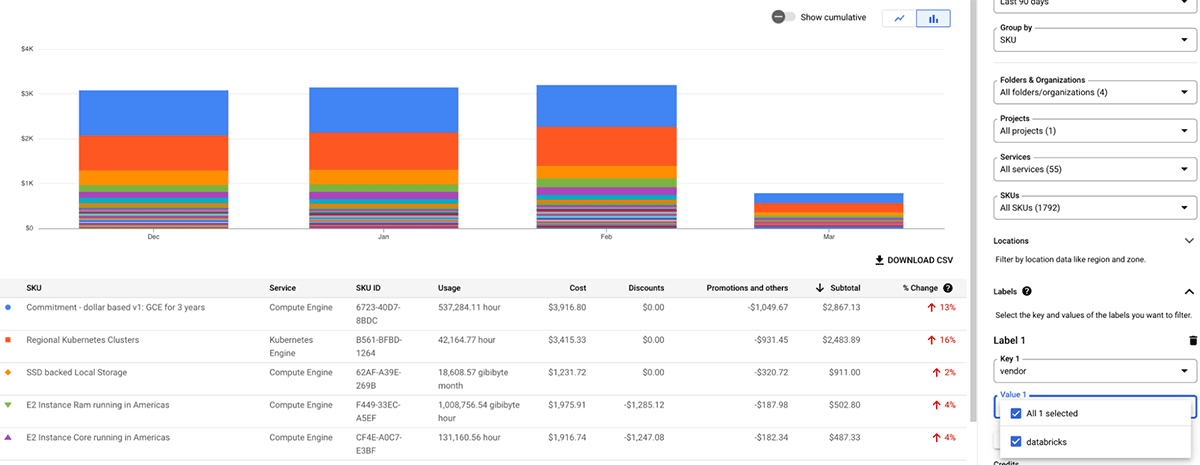
AWS Cost Explorer
Le tableau suivant détaille les objets AWS Databricks où des balises peuvent être appliquées. Ces balises peuvent se propager aux journaux d'utilisation et aux instances AWS EC2 et AWS EBS pour l'analyse des coûts. Databricks recommande d'utiliser les tables système (Aperçu public) pour afficher les données d'utilisation facturable. Trouvez plus de détails sur la propagation des balises et les limitations dans AWS.
| Objet AWS Databricks | Interface de balisage (UI) | Interface de balisage (API) |
|---|---|---|
| Espace de travail | N/A | API de compte |
| Pool | UI des pools dans l'espace de travail Databricks | API des pools d'instances |
| Calcul tout usage et tâches | UI du calcul dans l'espace de travail Databricks | API des clusters |
| Entrepôt SQL | UI de l'entrepôt SQL dans l'espace de travail Databricks | API des entrepôts |
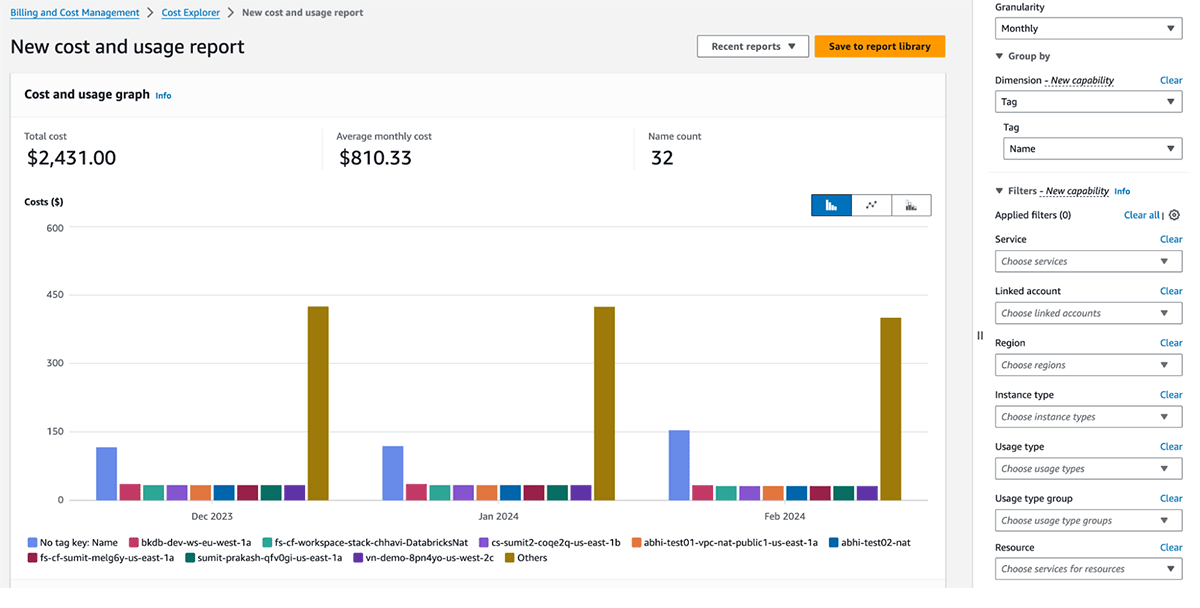
Gestion des coûts et facturation GCP
Le tableau suivant détaille les objets Databricks GCP où des balises peuvent être appliquées. Ces balises/étiquettes peuvent être appliquées aux ressources de calcul. Trouvez plus de détails sur la propagation des balises/étiquettes et les limitations dans GCP.
Les graphiques d'utilisation facturable de Databricks dans la console de compte peuvent agréger l'utilisation par balise individuelle. Les rapports CSV d'utilisation facturable téléchargés depuis la même page incluent également des balises par défaut et personnalisées. Les balises se propagent également aux étiquettes GKE et GCE.
| Objet Databricks GCP | Interface de balisage (UI) | Interface de balisage (API) |
|---|---|---|
| Pool | UI des pools dans l'espace de travail Databricks | API des pools d'instances |
| Calcul pour tous les usages et tâches | Interface utilisateur de calcul dans l'espace de travail Databricks | API Clusters |
| Entreposage SQL | Interface utilisateur d'entrepôt SQL dans l'espace de travail Databricks | API Entrepôts |
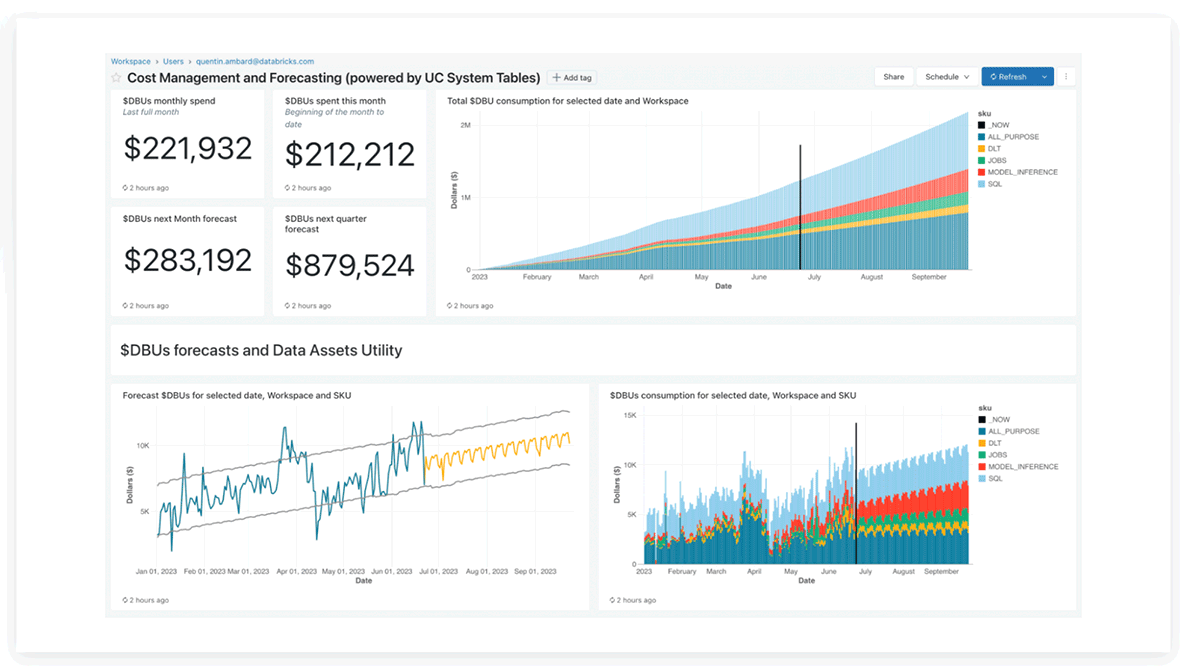
Tableaux de bord Lakeview des tables système Databricks
L'équipe produit Databricks a fourni des tableaux de bord Lakeview précréés pour l'analyse des coûts et la prévision à l'aide des tables système, que les clients peuvent également personnaliser.
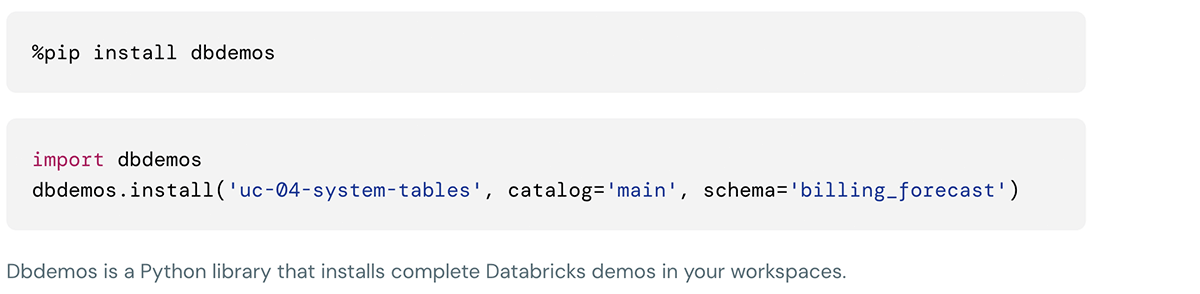
Cette démo peut être installée en utilisant les commandes suivantes dans la cellule des notebooks Databricks :
Meilleures pratiques pour maximiser la valeur
Lors de l'exécution de charges de travail sur Databricks, le choix de la bonne configuration de calcul améliorera considérablement les métriques de coût/performance. Voici quelques techniques pratiques d'optimisation des coûts :
Utiliser le bon type de calcul pour la bonne tâche
Pour les charges de travail SQL interactives, l'entrepôt SQL est le moteur le plus rentable. Encore plus efficace pourrait être le calcul Serverless, qui offre un temps de démarrage très rapide pour les entrepôts SQL et permet un temps de terminaison automatique plus court.
Pour les charges de travail non interactives, les clusters de tâches coûtent considérablement moins cher que les clusters tout usage. Les flux de tâches multitâches peuvent réutiliser les ressources de calcul pour toutes les tâches, réduisant encore plus les coûts.
Choisir le bon type d'instance
L'utilisation de la dernière génération de types d'instances cloud apportera presque toujours des avantages en termes de performances, car ils offrent les meilleures performances et les dernières fonctionnalités. Sur AWS, les instances Amazon EC2 basées sur Graviton2 peuvent offrir jusqu'à 3 fois meilleures performances par rapport au prix que des instances Amazon EC2 comparables.
En fonction de vos charges de travail, il est également important de choisir la bonne famille d'instances. Quelques règles empiriques sont :
- Optimisé pour la mémoire pour le ML, les charges de travail avec beaucoup de mélange et de dépassement
- Optimisé pour le calcul pour les charges de travail Structured Streaming, les tâches de maintenance (par exemple, Optimize & Vacuum)
- Optimisé pour le stockage pour les charges de travail qui bénéficient de la mise en cache, par exemple, l'analyse de données ad hoc et interactive
- Optimisé pour GPU pour les charges de travail ML et DL spécifiques
- Usage général en l'absence d'exigences spécifiques
Choisir le bon Runtime
Le dernier Databricks Runtime (DBR) offre généralement des performances améliorées et sera presque toujours plus rapide que le précédent.
Photon est un moteur de requête vectorisé natif Databricks haute performance qui exécute vos charges de travail SQL et vos appels d'API DataFrame plus rapidement pour réduire votre coût total par charge de travail. Pour ces charges de travail, l'activation de Photon pourrait entraîner des économies significatives.
Tirer parti de l'autoscaling dans Databricks Compute
Databricks offre une fonctionnalité unique d'autoscaling de cluster, ce qui facilite l'obtention d'une utilisation élevée du cluster car vous n'avez pas besoin de provisionner le cluster pour correspondre à une charge de travail. Ceci est particulièrement utile pour les charges de travail interactives ou les charges de travail par lots avec une charge de données variable. Cependant, l'autoscaling classique ne fonctionne pas avec les charges de travail Structured Streaming, c'est pourquoi nous avons développé l'Autoscaling amélioré dans Delta Live Tables pour gérer les charges de travail de streaming qui sont sporadiques et imprévisibles.
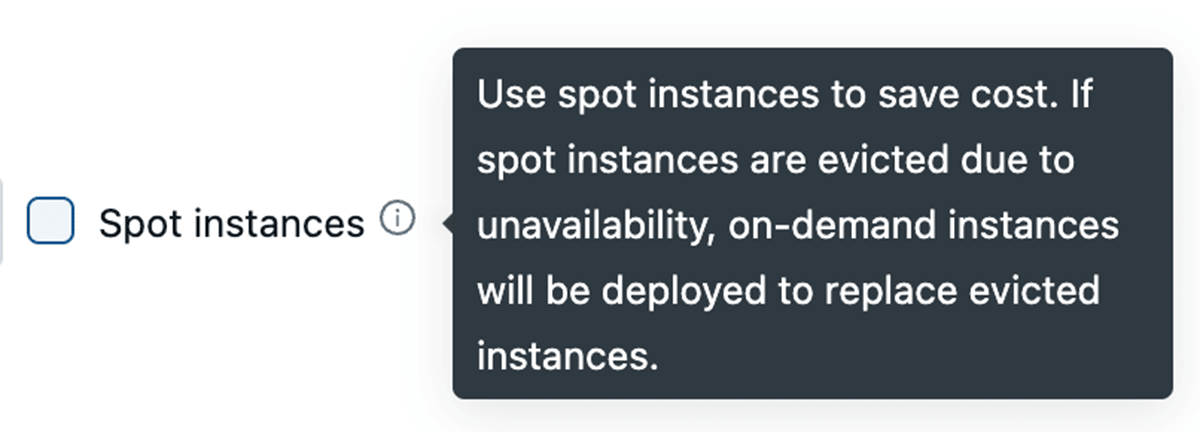
Tirer parti des instances Spot
Tous les principaux fournisseurs de cloud proposent des instances Spot qui vous permettent d'accéder à la capacité inutilisée de leurs centres de données pour jusqu'à 90 % de moins que les instances à la demande classiques. Databricks vous permet de tirer parti de ces instances Spot, avec la possibilité de revenir automatiquement aux instances à la demande en cas de résiliation pour minimiser les perturbations. Pour la stabilité du cluster, nous recommandons d'utiliser des nœuds pilotes à la demande.
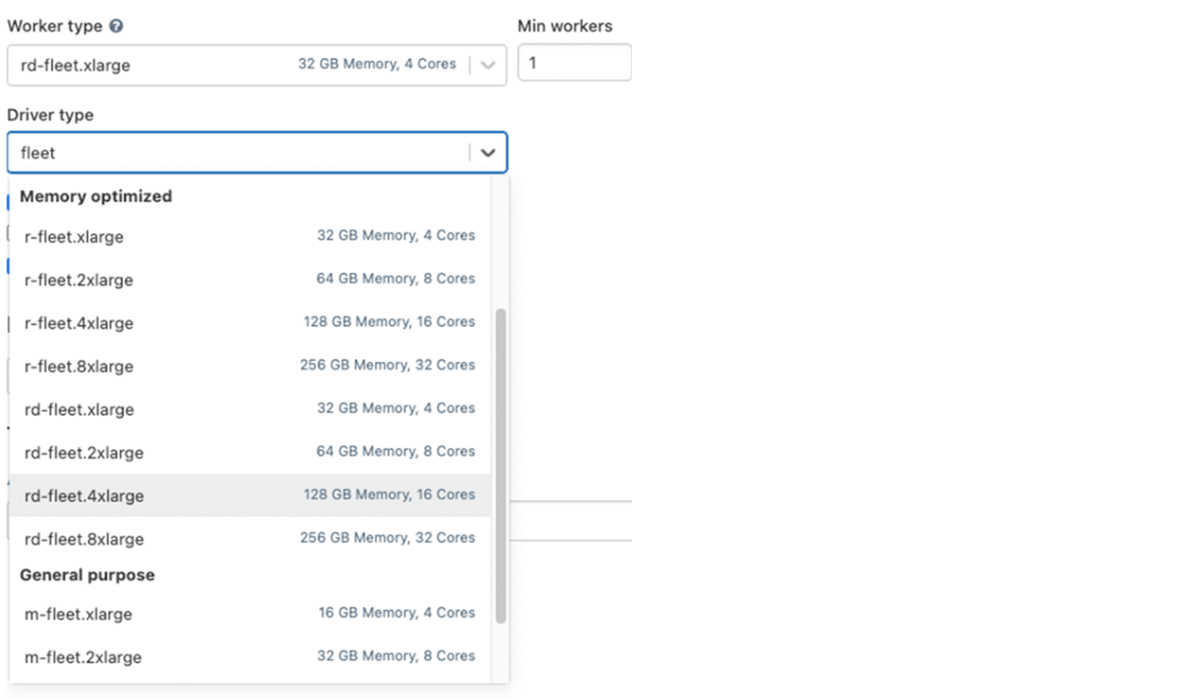
Tirer parti du type d'instance Fleet (sur AWS)
Sous le capot, lorsqu'un cluster utilise l'un de ces types d'instances Fleet, Databricks sélectionnera les types d'instances AWS physiques correspondants avec le meilleur prix et la meilleure disponibilité à utiliser dans votre cluster.
Politique de cluster
L'utilisation efficace des politiques de cluster permet aux administrateurs d'appliquer des restrictions spécifiques aux coûts pour les utilisateurs finaux :
- Activez la résiliation automatique du cluster avec une valeur raisonnable (par exemple, 1 heure) pour éviter de payer pour les temps d'inactivité.
- Assurez-vous que seules des instances de VM rentables peuvent être sélectionnées
- Appliquez des tags obligatoires pour la refacturation des coûts
- Contrôlez le profil de coût global en limitant le coût maximum par cluster, par exemple, le nombre maximum de DBUs par heure ou les ressources de calcul maximum par utilisateur
Optimisation des coûts basée sur l'IA
La plateforme Databricks Data Intelligence intègre des fonctionnalités d'IA avancées qui optimisent les performances, réduisent les coûts, améliorent la gouvernance et simplifient le développement d'applications d'IA d'entreprise. L'I/O prédictive et le clustering liquide améliorent la vitesse des requêtes et l'utilisation des ressources, tandis que la gestion intelligente des charges de travail optimise l'autoscaling pour l'efficacité des coûts. Dans l'ensemble, la plateforme Databricks offre une suite complète d'outils d'IA pour stimuler la productivité et les économies tout en permettant des solutions innovantes pour des cas d'utilisation spécifiques à l'industrie.
Clustering liquide
Le clustering liquide de Delta Lake remplace le partitionnement de table et ZORDER pour simplifier les décisions de disposition des données et optimiser les performances des requêtes. Le clustering liquide offre la flexibilité de redéfinir les clés de clustering sans réécrire les données existantes, permettant à la disposition des données d'évoluer avec les besoins analytiques au fil du temps.
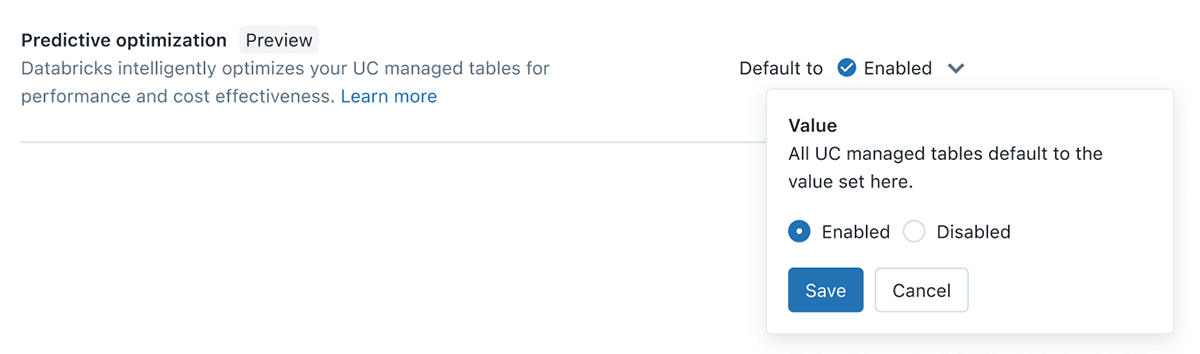
Optimisation prédictive
Les ingénieurs de données sur le lakehouse connaîtront le besoin d'optimiser et de vider régulièrement leurs tables, cependant, cela crée des défis constants pour trouver les bonnes tables, le calendrier approprié et la bonne taille de calcul pour que ces tâches s'exécutent. Avec l'Optimisation prédictive, nous exploitons Unity Catalog et Lakehouse AI pour déterminer les meilleures optimisations à effectuer sur vos données, puis nous exécutons ces opérations sur une infrastructure serverless spécialement conçue. Tout cela se produit automatiquement, garantissant les meilleures performances sans gaspillage de calcul ni effort de réglage manuel.
Vue matérialisée avec actualisation incrémentielle
Dans Databricks, les Vues Matérialisées (VM) sont des tables gérées par Unity Catalog qui permettent aux utilisateurs de précalculer des résultats basés sur la dernière version des données dans les tables sources. Construites sur Delta Live Tables & serverless, les VM réduisent la latence des requêtes en précalculant des calculs lents et fréquemment utilisés. Lorsque possible, les résultats sont mis à jour de manière incrémentielle, mais les résultats sont identiques à ceux qui seraient obtenus par un recalcul complet. Cela réduit les coûts de calcul et évite la nécessité de maintenir des clusters séparés
Fonctionnalités serverless pour les cas d'usage de Model Serving & Gen AI
Pour mieux prendre en charge les cas d'usage de déploiement de modèles et de Gen AI, Databricks a introduit plusieurs capacités sur notre infrastructure serverless qui s'adapte automatiquement à vos flux de travail sans avoir besoin de configurer d'instances et de types de serveurs.
- AI Search : Index vectoriel qui peut être synchronisé à partir de n'importe quelle table Delta en 1 clic - pas besoin de pipelines d'ingestion/synchronisation de données complexes et personnalisés.
- Online Tables : Tables entièrement serverless qui adaptent automatiquement la capacité de débit à la charge des requêtes et offrent un accès à faible latence et à haut débit aux données de toute échelle
- Model Serving : Service hautement disponible et à faible latence pour le déploiement de modèles. Le service s'adapte automatiquement à la hausse ou à la baisse pour répondre aux changements de demande, ce qui permet d'économiser les coûts d'infrastructure tout en optimisant les performances de latence
Predictive I/O pour les mises à jour et les suppressions
Avec ces fonctionnalités basées sur l'IA, Databricks SQL peut désormais analyser les modèles historiques de lecture et d'écriture pour construire intelligemment des index et optimiser les charges de travail. Predictive I/O est un ensemble d'optimisations Databricks qui améliorent les performances des interactions avec les données. Les capacités de Predictive I/O sont regroupées dans les catégories suivantes :
- Les lectures accélérées réduisent le temps nécessaire pour scanner et lire les données. Il utilise des techniques d'apprentissage profond pour y parvenir. Plus de détails peuvent être trouvés sur cette documentation
- Les mises à jour accélérées réduisent la quantité de données qui doivent être réécrites lors des mises à jour, suppressions et fusions. Predictive I/O exploite les deletion vectors pour accélérer les mises à jour en réduisant la fréquence des réécritures complètes de fichiers lors de la modification des données sur les tables Delta. Predictive I/O optimise les opérations
DELETE,MERGEetUPDATE. Plus de détails peuvent être trouvés sur cette documentation
Predictive I/O est exclusif au moteur Photon sur Databricks.
Gestion intelligente des charges de travail (IWM)
L'un des principaux points faibles des administrateurs de plateformes techniques est de gérer différents entrepôts pour les petites et grandes charges de travail et de s'assurer que le code est optimisé et peaufiné pour s'exécuter de manière optimale et tirer parti de la pleine capacité de l'infrastructure de calcul. L'IWM est une suite de fonctionnalités qui aide à relever ces défis et permet d'exécuter ces charges de travail plus rapidement tout en maîtrisant les coûts. Il y parvient en analysant les modèles en temps réel et en s'assurant que les charges de travail disposent de la quantité de calcul optimale pour exécuter les instructions SQL entrantes sans perturber les requêtes déjà en cours.
La bonne base FinOps - via le tagging, les politiques et le reporting - est cruciale pour la transparence et le ROI de votre plateforme d'intelligence de données. Elle vous aide à réaliser plus rapidement la valeur commerciale et à construire une entreprise plus prospère.
Utilisez serverless et DatabricksIQ pour une configuration rapide, une efficacité des coûts et des optimisations automatiques qui s'adaptent à vos modèles de charge de travail. Cela conduit à un TCO plus faible, une meilleure fiabilité et des opérations plus simples et plus rentables.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.