Présentation de Databricks Lakeflow : une solution unifiée et intelligente pour l'ingénierie des données
Ingérez des données à partir de bases de données, d'applications d'entreprise et de sources cloud, transformez-les en batch et en streaming en temps réel, et déployez et exploitez en toute confiance en production.
par Michael Armbrust et Bilal Aslam
Aujourd'hui, nous sommes ravis d'annoncer Databricks Lakeflow, une nouvelle solution qui contient tout ce dont vous avez besoin pour construire et exploiter des pipelines de données de production. Elle inclut de nouveaux connecteurs natifs et hautement évolutifs pour les bases de données comme SQL Server et pour les applications d'entreprise comme Salesforce, Workday, Google Analytics, ServiceNow et SharePoint. Les utilisateurs peuvent transformer les données en mode batch et streaming en utilisant SQL et Python standard. Nous annonçons également le mode temps réel pour Apache Spark, permettant un traitement en continu à des latences ordres de grandeur plus rapides que le micro-batch. Enfin, vous pouvez orchestrer et surveiller les flux de travail et déployer en production en utilisant CI/CD. Databricks Lakeflow est natif de la plateforme d'intelligence des données, offrant une puissance de calcul serverless et une gouvernance unifiée avec Unity Catalog.

Dans cet article de blog, nous discutons des raisons pour lesquelles nous pensons que Lakeflow aidera les équipes de données à répondre à la demande croissante de données et d'IA fiables, ainsi que des capacités clés de Lakeflow intégrées dans une expérience produit unique.
Défis liés à la construction et à l'exploitation de pipelines de données fiables
L'ingénierie des données - collecter et préparer des données fraîches, de haute qualité et fiables - est un ingrédient nécessaire pour démocratiser les données et l'IA dans votre entreprise. Pourtant, y parvenir reste complexe et nécessite de relier de nombreux outils différents.
Premièrement, les équipes de données doivent ingérer des données à partir de plusieurs systèmes, chacun avec ses propres formats et méthodes d'accès. Cela nécessite de construire et de maintenir des connecteurs internes pour les bases de données et les applications d'entreprise. Le simple fait de suivre les changements d'API des applications d'entreprise peut représenter un travail à temps plein pour toute une équipe de données. Les données doivent ensuite être préparées en batch et en streaming, ce qui nécessite d'écrire et de maintenir une logique complexe pour le déclenchement et le traitement incrémental. Lorsque la latence augmente ou qu'une défaillance survient, cela signifie être alerté, un ensemble de consommateurs de données mécontents et même des perturbations de l'activité qui affectent le résultat net. Enfin, les équipes de données doivent déployer ces pipelines en utilisant CI/CD et surveiller la qualité et la lignée des actifs de données. Cela nécessite normalement de déployer, d'apprendre et de gérer un nouvel outil entièrement différent comme Prometheus ou Grafana.
C'est pourquoi nous avons décidé de construire Lakeflow, une solution unifiée pour l'ingestion, la transformation et l'orchestration des données, alimentée par l'intelligence des données. Ses trois composantes clés sont : Lakeflow Connect, Lakeflow Pipelines et Lakeflow Jobs.
Lakeflow Connect : ingestion de données simple et évolutive
Lakeflow Connect offre une ingestion de données par pointer-cliquer pour les bases de données telles que SQL Server et les applications d'entreprise telles que Salesforce, Workday, Google Analytics et ServiceNow. La feuille de route inclut également des bases de données comme MySQL, Postgres et Oracle, ainsi que des applications d'entreprise comme NetSuite, Dynamics 365 et Google Ads. Lakeflow Connect peut également ingérer des données non structurées telles que des PDF et des feuilles de calcul Excel provenant de sources comme SharePoint.
Il complète nos connecteurs natifs populaires pour le stockage cloud (par exemple, S3, ADLS Gen2 et GCS) et les files d'attente (par exemple, connecteurs Kafka, Kinesis, Event Hub et Pub/Sub), ainsi que les solutions partenaires telles que Fivetran, Qlik et Informatica.
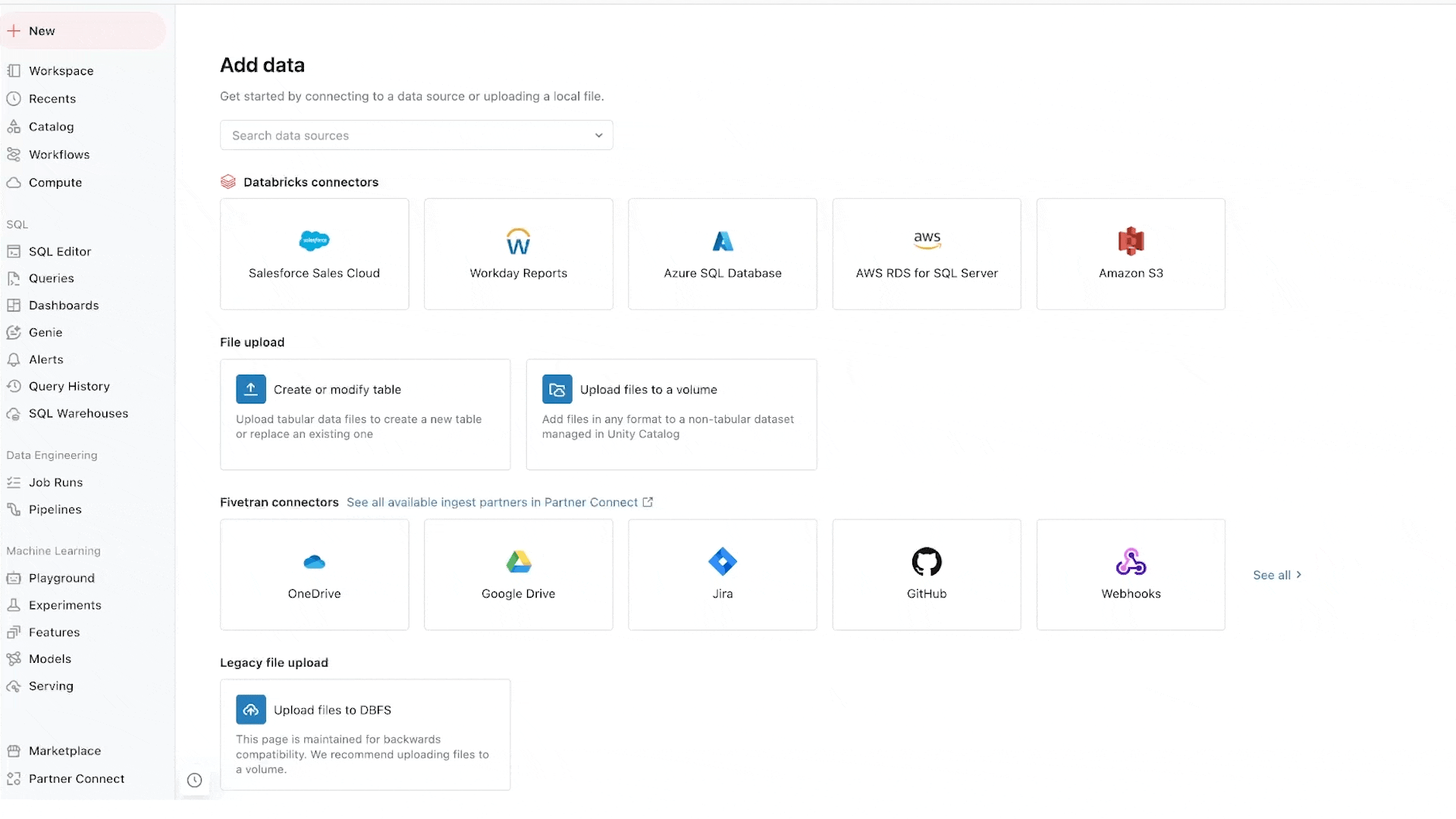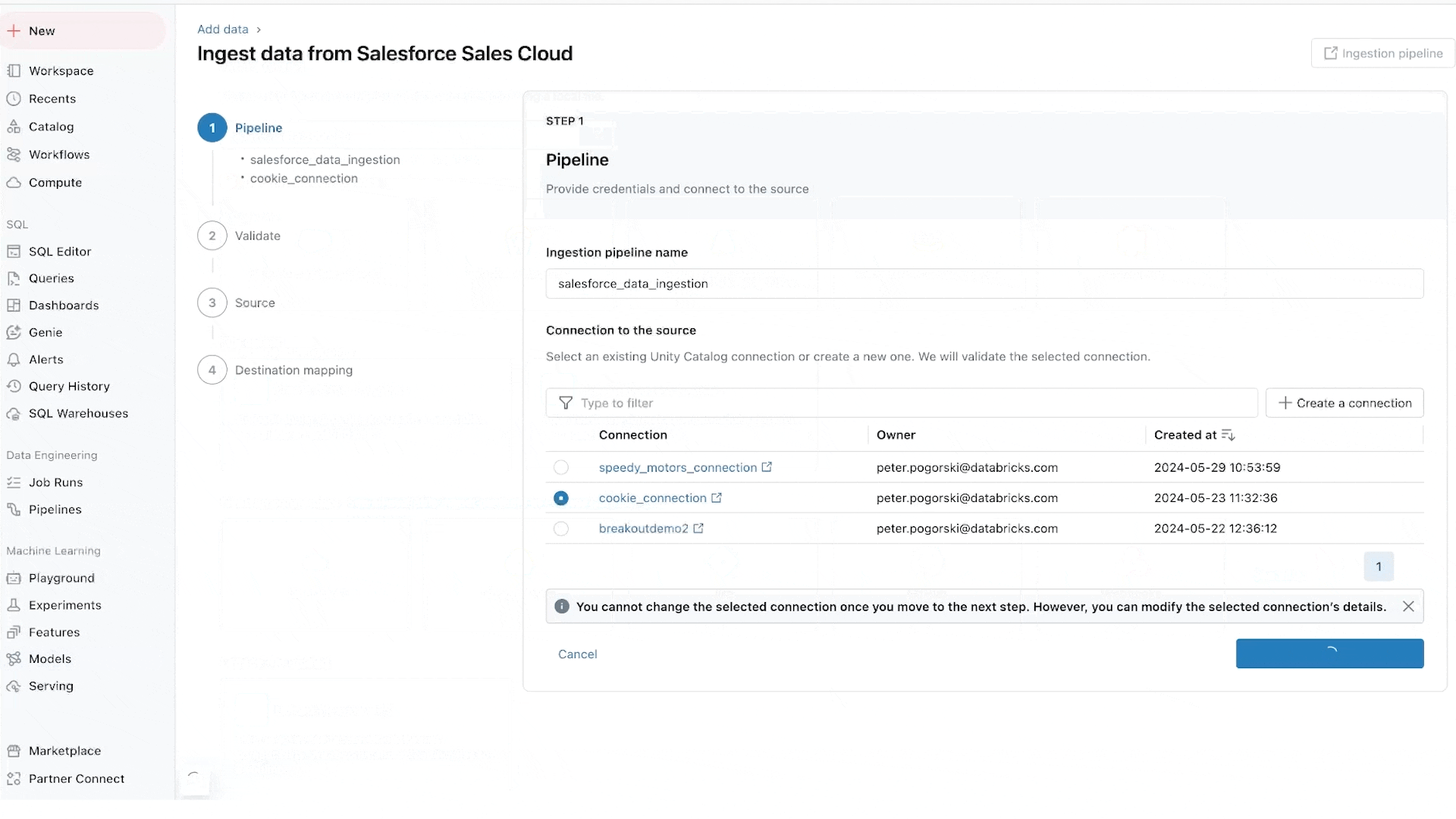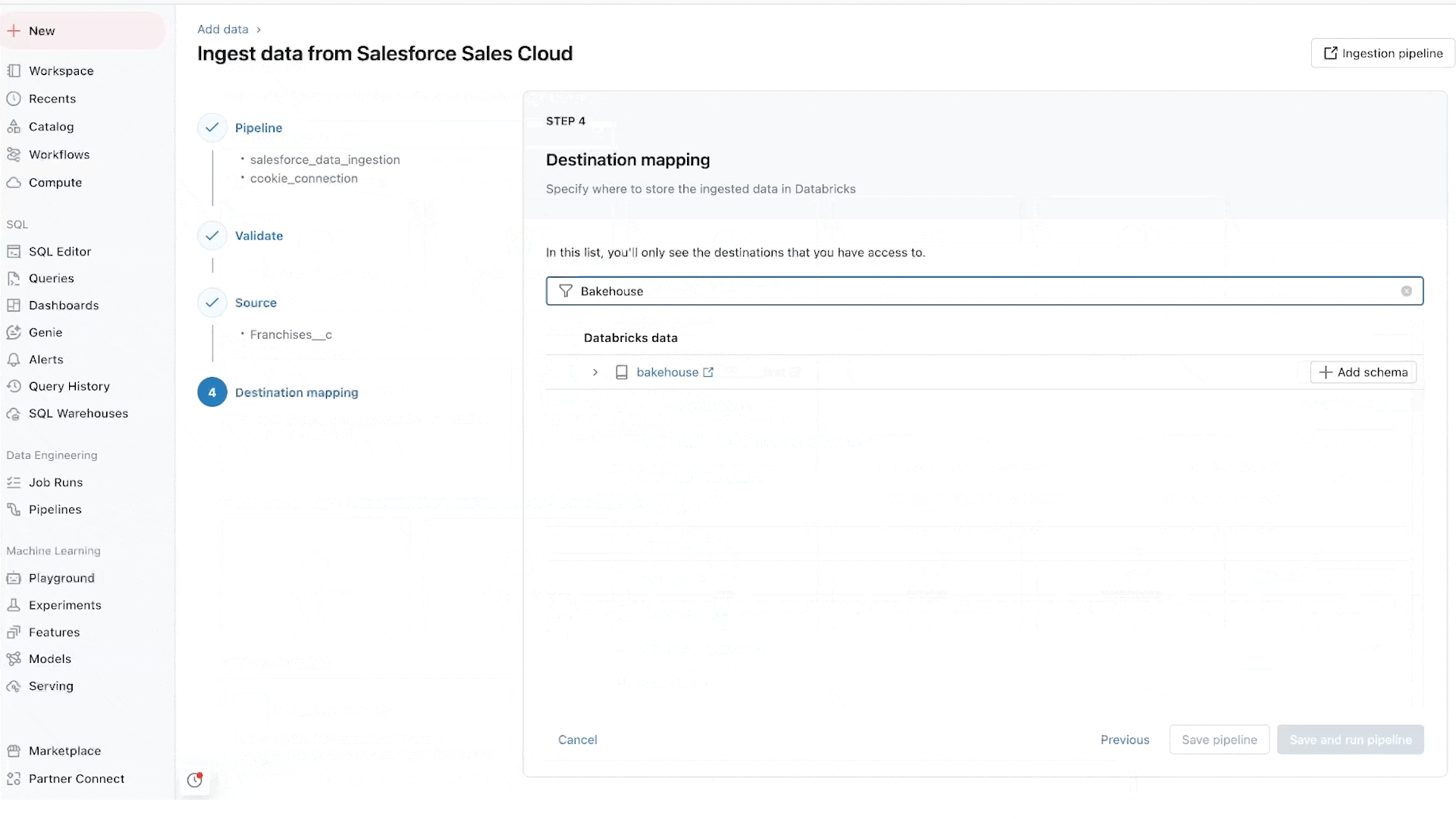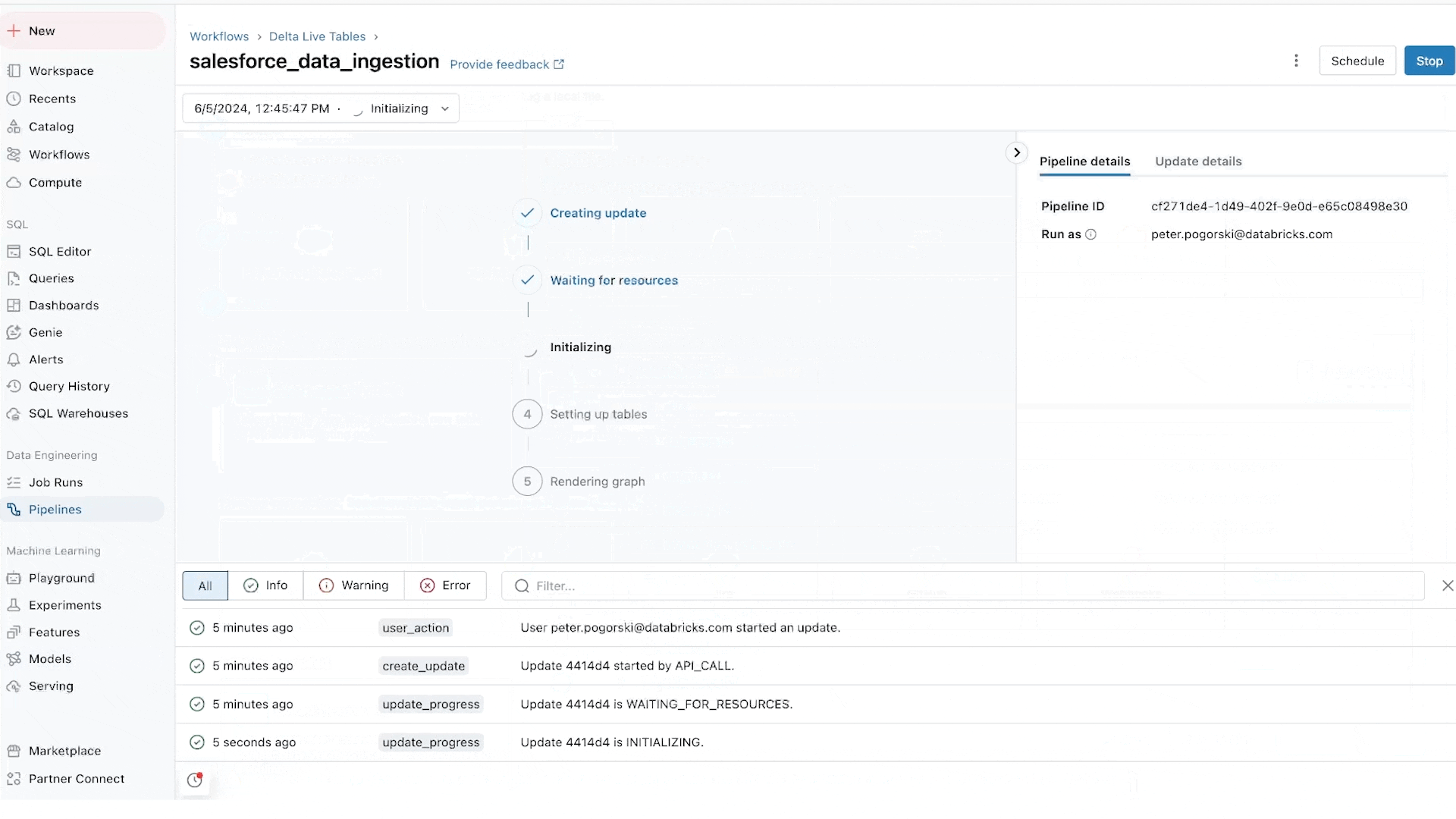
Nous sommes particulièrement enthousiastes à propos des connecteurs de base de données, qui sont alimentés par notre acquisition d'Arcion. Une quantité incroyable de données précieuses est enfermée dans les bases de données opérationnelles. Au lieu d'approches naïves pour charger ces données, qui rencontrent des problèmes opérationnels et d'évolutivité, Lakeflows utilise la technologie de capture des changements de données (CDC) pour rendre simple, fiable et opérationnellement efficace l'apport de ces données à votre lakehouse.
Les clients Databricks qui utilisent Lakeflow Connect constatent qu'une solution d'ingestion simple améliore la productivité et leur permet de passer plus rapidement des données aux informations. Insulet, un fabricant d'un système de gestion de l'insuline portable, l'Omnipod, utilise le connecteur d'ingestion Salesforce pour ingérer des données relatives aux commentaires des clients dans sa solution de données construite sur Databricks. Ces données sont mises à disposition pour analyse via Databricks SQL afin d'obtenir des informations sur les problèmes de qualité et de suivre les plaintes des clients. L'équipe a trouvé une valeur significative dans l'utilisation des nouvelles capacités de Lakeflow Connect.
"Avec le nouveau connecteur d'ingestion Salesforce de Databricks, nous avons considérablement rationalisé notre processus d'intégration des données en éliminant les middlewares fragiles et problématiques. Cette amélioration permet à Databricks SQL d'analyser directement les données Salesforce au sein de Databricks. En conséquence, nos praticiens de données peuvent désormais fournir des informations mises à jour en quasi temps réel, réduisant la latence de plusieurs jours à quelques minutes." —Bill Whiteley, Senior Director of AI, Analytics, and Advanced Algorithms, Insulet
Lakeflow Pipelines : pipelines de données déclaratifs efficaces
Lakeflow Pipelines réduit la complexité de la construction et de la gestion de pipelines de données batch et streaming efficaces. Construits sur le framework déclaratif Delta Live Tables, ils vous libèrent pour écrire la logique métier en SQL et Python, tandis que Databricks automatise l'orchestration des données, le traitement incrémental et l'autoscaling de l'infrastructure de calcul en votre nom. De plus, Lakeflow Pipelines offre une surveillance intégrée de la qualité des données et son mode temps réel vous permet d'activer une livraison à faible latence constante de jeux de données sensibles au temps sans aucune modification de code.
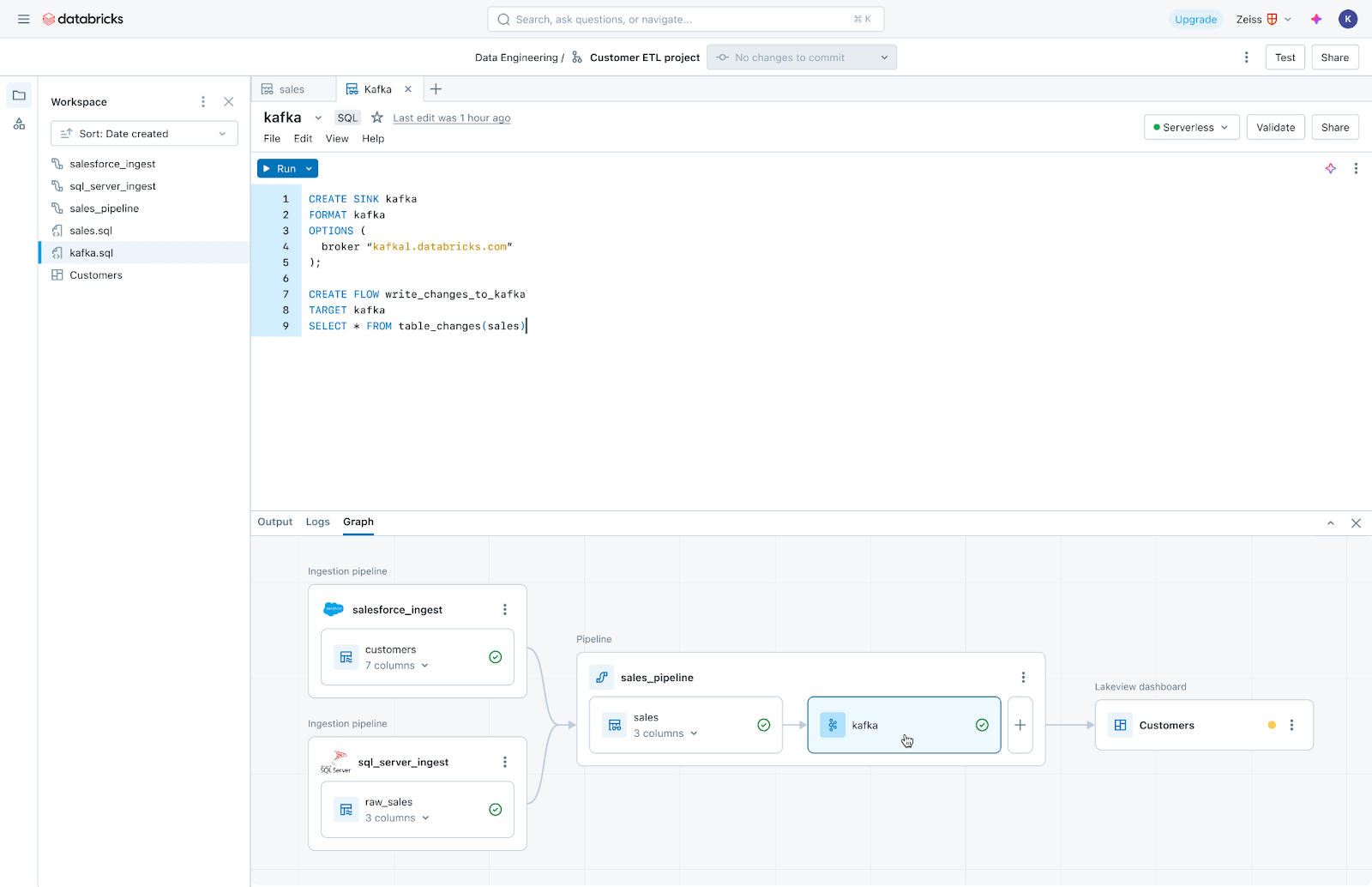
Lakeflow Jobs : orchestration fiable pour chaque charge de travail
Lakeflow Jobs orchestre et surveille de manière fiable les charges de travail de production. Construit sur les capacités avancées de Databricks Workflows, il orchestre n'importe quelle charge de travail, y compris l'ingestion, les pipelines, les notebooks, les requêtes SQL, l'entraînement de modèles d'apprentissage automatique, le déploiement de modèles et l'inférence. Les équipes de données peuvent également tirer parti des déclencheurs, du branching et du bouclage pour répondre à des cas d'utilisation complexes de livraison de données.
Lakeflow Jobs automatise et simplifie également le processus de compréhension et de suivi de la santé et de la livraison des données. Il adopte une vue axée sur les données pour la santé, offrant aux équipes de données une lignée complète, y compris les relations entre l'ingestion, les transformations, les tables et les tableaux de bord. De plus, il suit la fraîcheur et la qualité des données, permettant aux équipes de données d'ajouter des moniteurs via Lakehouse Monitoring en un clic.
Construit sur la plateforme d'intelligence des données
Databricks Lakeflow est nativement intégré à notre plateforme d'intelligence des données, qui apporte ces capacités :
- Intelligence des données : L'intelligence alimentée par l'IA n'est pas seulement une fonctionnalité de Lakeflow, c'est une capacité fondamentale qui touche tous les aspects du produit. Databricks Assistant alimente la découverte, la création et la surveillance des pipelines de données, afin que vous puissiez passer plus de temps à construire des données fiables.
- Gouvernance unifiée : Lakeflow est également profondément intégré à Unity Catalog, qui alimente la lignée et la qualité des données.
- Calcul serverless : Construisez et orchestrez des pipelines à grande échelle et aidez votre équipe à se concentrer sur le travail sans avoir à se soucier de l'infrastructure.
L'avenir de l'ingénierie des données est simple, unifié et intelligent
Nous pensons que Lakeflow permettra à nos clients de fournir des données plus fraîches, plus complètes et de meilleure qualité à leurs entreprises. Lakeflow sera bientôt disponible en avant-première, en commençant par Lakeflow Connect. Si vous souhaitez demander l'accès, inscrivez-vous ici. Au cours des prochains mois, surveillez les annonces de Lakeflow à mesure que des capacités supplémentaires seront disponibles.
Envie de le voir en action ?
Essayez la visite du produit Lakeflow pour ingérer, transformer et déployer de manière transparente des données à partir de plusieurs sources, en mode batch et en temps réel, vers la production.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.