Connectez n'importe quelle source de données, une plateforme unique
Enrichissez vos agents d'IA avec un contexte d'entreprise complet.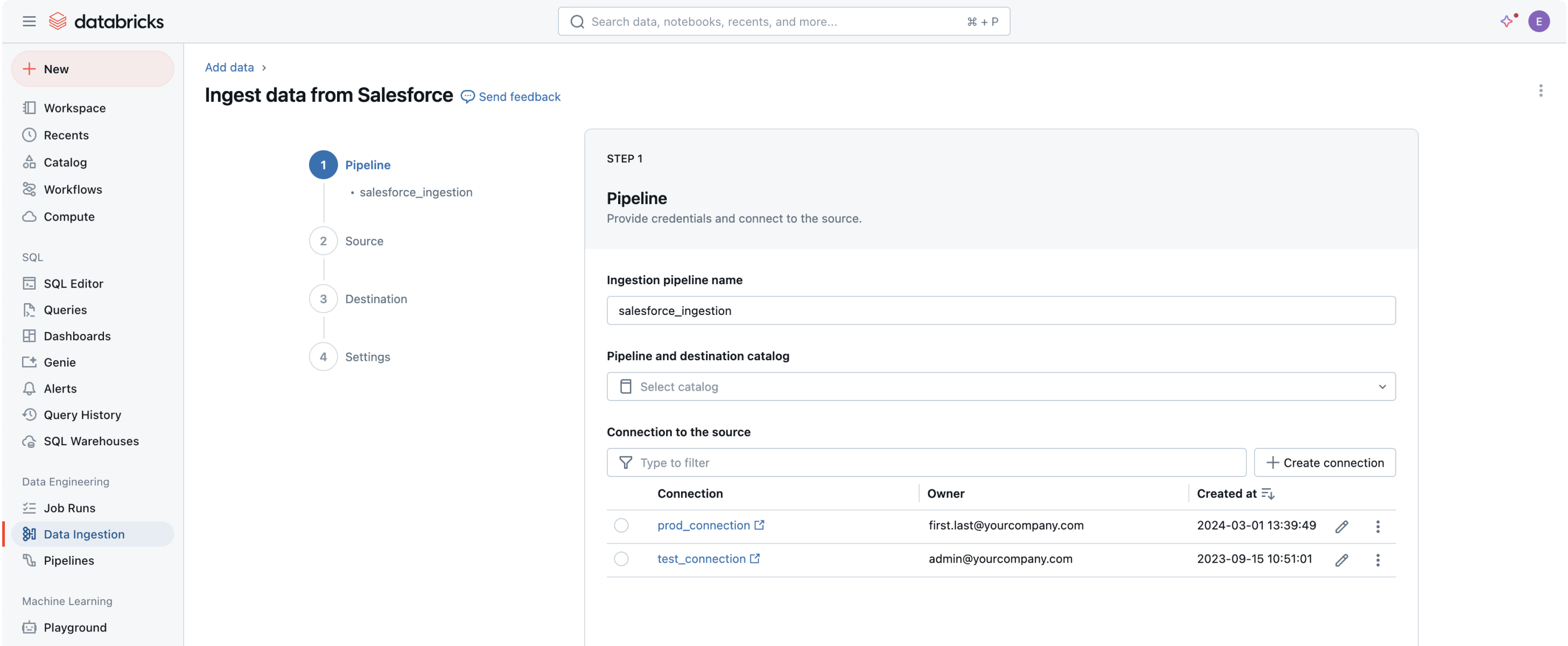

Connectez n'importe quelle source de données, une plateforme unique
Plus de 100 connecteurs intégrés pour les applications d'entreprise, les bases de données et les sources de fichiers fournissent à vos agents d'IA un contexte complet et fiable.Flexible et facile
Les connecteurs entièrement managés fournissent une UI et une API simples pour une configuration facile et démocratisent l'accès aux données. Les fonctionnalités automatisées permettent également de simplifier la maintenance du pipeline avec une surcharge minimale.
Connecteurs intégrés
L'ingestion de données est entièrement intégrée à la Plateforme d'intelligence des données. Créez des pipelines d'ingestion avec la gouvernance d'Unity Catalog, l'observabilité de Lakehouse Monitoring et une orchestration fluide avec des workflows pour l'analytique, le machine learning et la BI.
Intégration directe avec les agents d'IA
Alimentez vos projets d'IA et de BI en aval avec un contexte d'entreprise de haute fidélité. Éliminez les silos et alimentez vos agents d'IA avec une logique métier complète pour un raisonnement fiable.
Fonctionnalités d'ingestion robustes pour les sources de données populaires
Importer toutes vos données dans la Plateforme d'intelligence des données est la première étape pour en extraire de la valeur et vous aider à résoudre les problèmes de données les plus complexes de votre organisation.Une interface utilisateur (UI) sans code ou une API simple permet aux professionnels des données de travailler en autonomie, leur économisant des heures de programmation.
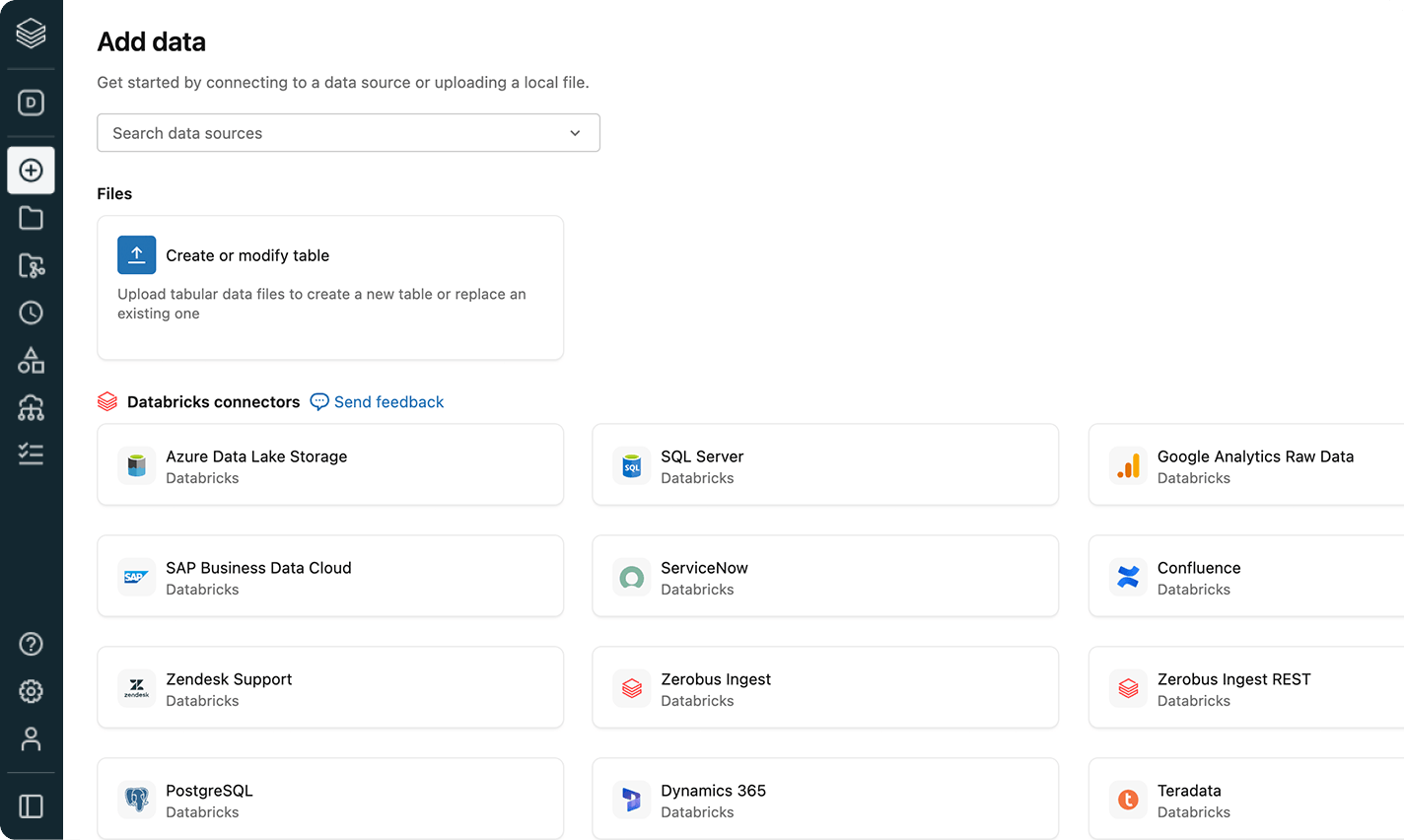
N'importez que les nouvelles données ou les mises à jour de tables, ce qui rend l'ingestion de données rapide, évolutive et efficace sur le plan opérationnel.

Ingérez des données dans un environnement 100 % serverless qui offre un startup rapide et une mise à l'échelle automatique de l'infrastructure.

L'intégration approfondie avec Databricks Unity Catalog offre des fonctionnalités robustes, notamment en matière de lignage et de qualité des données.

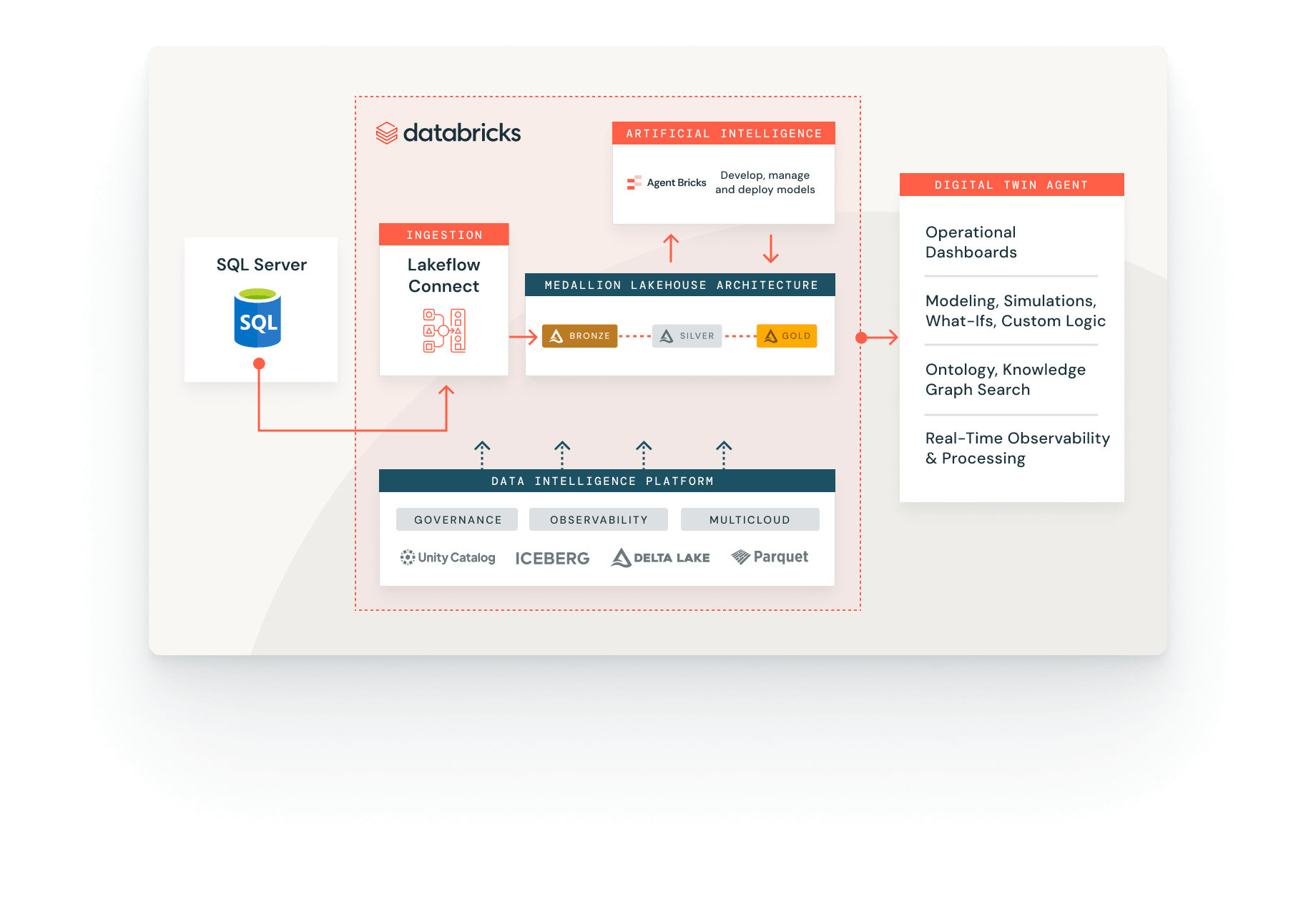
Ingestion de données avec Databricks
Résoudre les problèmes des clients dans un grand nombre de Secteurs d'activité

Mesurez les performances des campagnes et cartographiez le parcours client
Consolidez les données publicitaires et de campagne fragmentées provenant de Meta, Google Ads et TikTok Ads. Capturez les états historiques de la plateforme pour effectuer une analyse précise à un instant T et créer un parcours client unifié.





Les tarifs basés sur l'utilisation permettent de maîtriser les dépenses
Ne payez que les produits que vous utilisez, à la seconde près.En savoir plus
Explorez d'autres offres intelligentes et intégrées sur la Data Intelligence Platform.
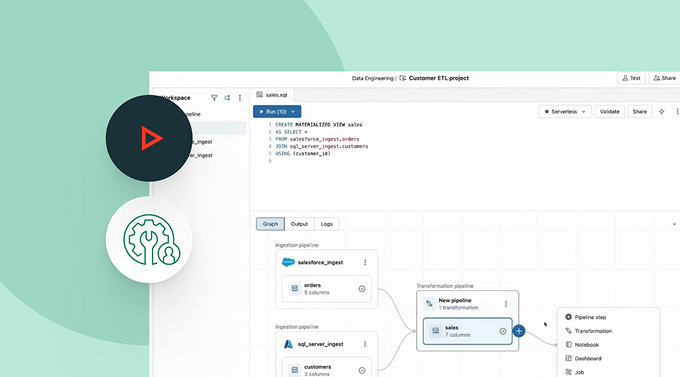
Tâches Lakeflow
Donnez aux équipes les moyens de mieux automatiser et orchestrer tous les workflows d'ETL, d'analytique et d'IA grâce à une observabilité approfondie, une haute fiabilité et la prise en charge d'un large éventail de tâches.
Pipelines déclaratifs Apache Spark™
Simplifiez l'ETL par batch et en streaming grâce à la qualité de données automatisée, la change data capture (CDC), l'acquisition et la transformation des données, ainsi que la gouvernance unifiée.

Unity Catalog
Encadrez sans problème tous vos assets de données avec la seule solution de gouvernance unifiée et ouverte de l'industrie pour les données et l'IA, intégrée à la Databricks Data Intelligence Platform

Delta Lake
Unifiez les données du lakehouse, quels que soient leur format et leur type, pour les mettre à disposition de toutes vos charges d'analytique et d'IA.

Genie Code
Créez et gérez des pipelines de données avec une IA agentique qui comprend vos données.
Démarrer
Explorez la documentation sur l'ingestion de données
Ingérez des données de diverses sources, sur plusieurs clouds et via Lakeflow Connect.
Découvrir Lakeflow Connect
Lakeflow Connect est désormais en disponibilité générale pour Salesforce, Workday et SQL Server.
Pour un accès en avant-première à d'autres connecteurs, veuillez contacter votre équipe de compte Databricks.



FAQ sur l'ingestion de données
Prêts à devenir une entreprise axée sur les données et l'IA ?
Faites le premier pas de votre transformation data