Introduction à l'évaluation améliorée des agents
Personnalisation plus facile et collaboration améliorée avec les parties prenantes
par Eric Peter, Daniel Smilkov, Nikhil Thorat, Alkis Polyzotis et Chenen Liang
- Du pilote à la production – Simplifiez l'adoption de GenAI avec des évaluations automatisées, des retours d'experts et des chemins d'itération clairs pour les deux phases.
- Évaluation GenAI personnalisable – Définissez des métriques personnalisées, utilisez le nouveau Juge IA Guideline et évaluez n'importe quel cas d'utilisation avec des schémas d'entrée/sortie flexibles.
- Collaboration transparente avec les experts – L'application de révision mise à jour simplifie la collecte des retours et la gestion des jeux de données d'évaluation.
Cette semaine, nous avons annoncé de nouvelles capacités de développement d'agents sur Databricks. Après avoir parlé avec des centaines de clients, nous avons identifié deux défis courants pour passer au-delà des phases pilotes. Premièrement, les clients manquent de confiance dans les performances de leurs modèles en production. Deuxièmement, les clients n'ont pas de voie claire pour itérer et s'améliorer. Ensemble, cela conduit souvent à des projets bloqués ou à des processus inefficaces où les équipes s'efforcent de trouver des experts du domaine pour évaluer manuellement les sorties des modèles.
Aujourd'hui, nous relevons ces défis en étendant Databricks MLflow avec de nouvelles capacités en aperçu public. Ces améliorations aident les équipes à mieux comprendre et améliorer leurs applications GenAI grâce à des évaluations automatisées personnalisables et à des retours d'informations rationalisés des parties prenantes commerciales.
- Personnaliser les évaluations automatisées : Utilisez les juges IA de directives pour évaluer les applications GenAI avec des règles en langage naturel, et définissez des métriques critiques pour l'entreprise avec des évaluations Python personnalisées.
- Collaborer avec des experts du domaine : Tirez parti de l'application d'évaluation et du nouveau SDK de jeu de données d'évaluation pour collecter les commentaires des experts du domaine, étiqueter les traces d'applications GenAI et affiner les jeux de données d'évaluation — alimentés par les tables Delta et la gouvernance Unity Catalog.
Pour voir ces capacités en action, consultez notre notebook d'exemple.
Personnaliser l'évaluation GenAI pour vos besoins commerciaux
Les applications GenAI et les systèmes d'agents existent sous de nombreuses formes — de leur architecture sous-jacente utilisant des bases de données vectorielles et des outils, à leurs méthodes de déploiement, qu'elles soient en temps réel ou par lots. Chez Databricks, nous avons appris que les tâches réussies spécifiques à un domaine nécessitent que les agents exploitent également efficacement les données de l'entreprise. Cette diversité exige une approche d'évaluation tout aussi flexible.
Aujourd'hui, nous introduisons des mises à jour de Databricks MLflow pour le rendre hautement personnalisable, conçu pour aider les équipes à mesurer les performances de toute application spécifique à un domaine pour tout type d'application GenAI ou de système d'agent.
Juge IA de directives : utilisez le langage naturel pour vérifier si les applications GenAI suivent les directives
En élargissant notre catalogue de juges LLM intégrés et affinés par la recherche qui offrent une précision de pointe, nous introduisons le Juge IA de directives (aperçu public), qui aide les développeurs à utiliser des listes de contrôle ou des grilles d'évaluation en langage naturel dans leur évaluation. Parfois appelées notes de notation, les directives sont similaires à la façon dont les enseignants définissent des critères (par exemple, « L'essai doit comporter cinq paragraphes », « Chaque paragraphe doit avoir une phrase thématique », « Le dernier paragraphe de chaque phrase doit résumer tous les points abordés dans le paragraphe », …).
Comment ça marche : Fournissez des directives lors de la configuration de l'évaluation de l'agent, qui seront automatiquement évaluées pour chaque requête.
Exemples de directives :
- La réponse doit être professionnelle.
- Lorsque l'utilisateur demande de comparer deux produits, la réponse doit afficher un tableau.
Pourquoi c'est important : Les directives améliorent la transparence et la confiance de l'évaluation auprès des parties prenantes commerciales grâce à des grilles de notation structurées et faciles à comprendre, ce qui permet une notation cohérente et transparente des réponses de votre application.
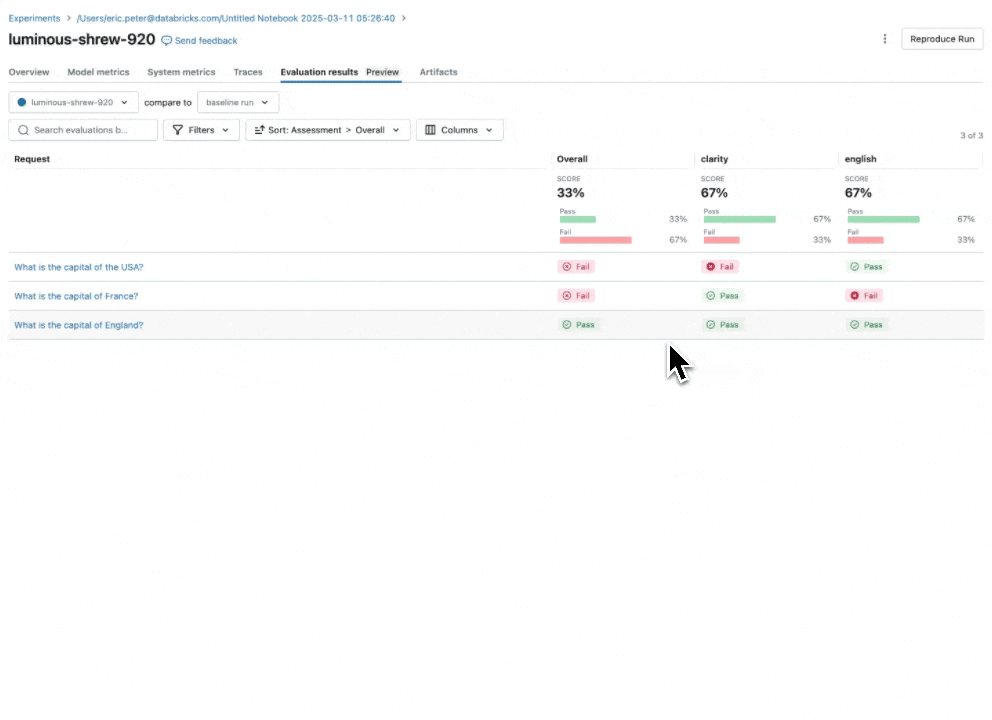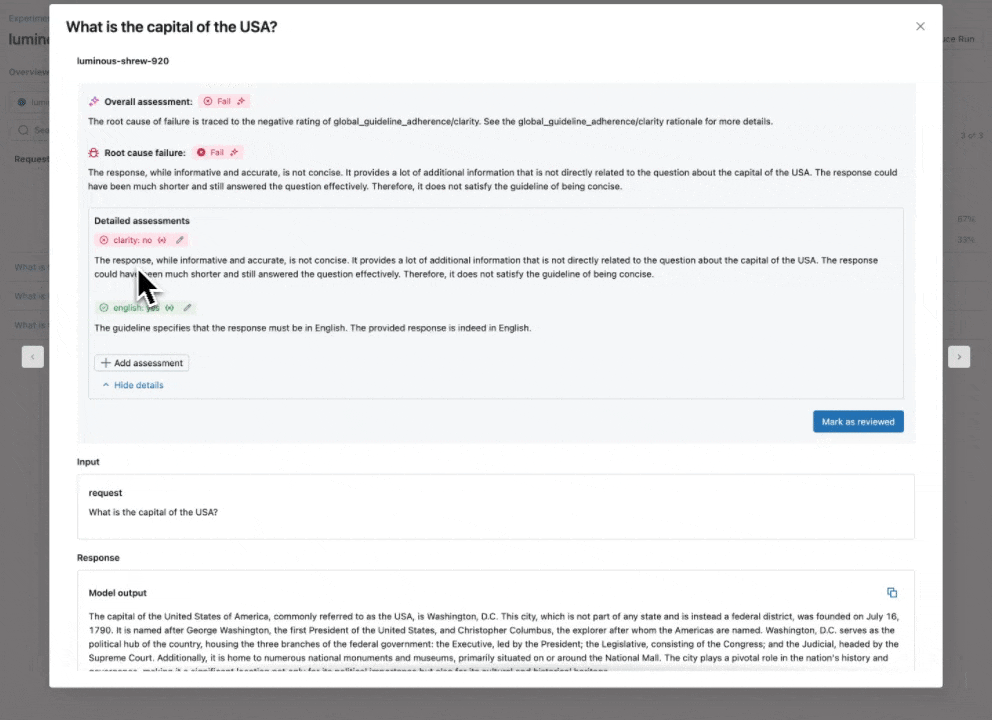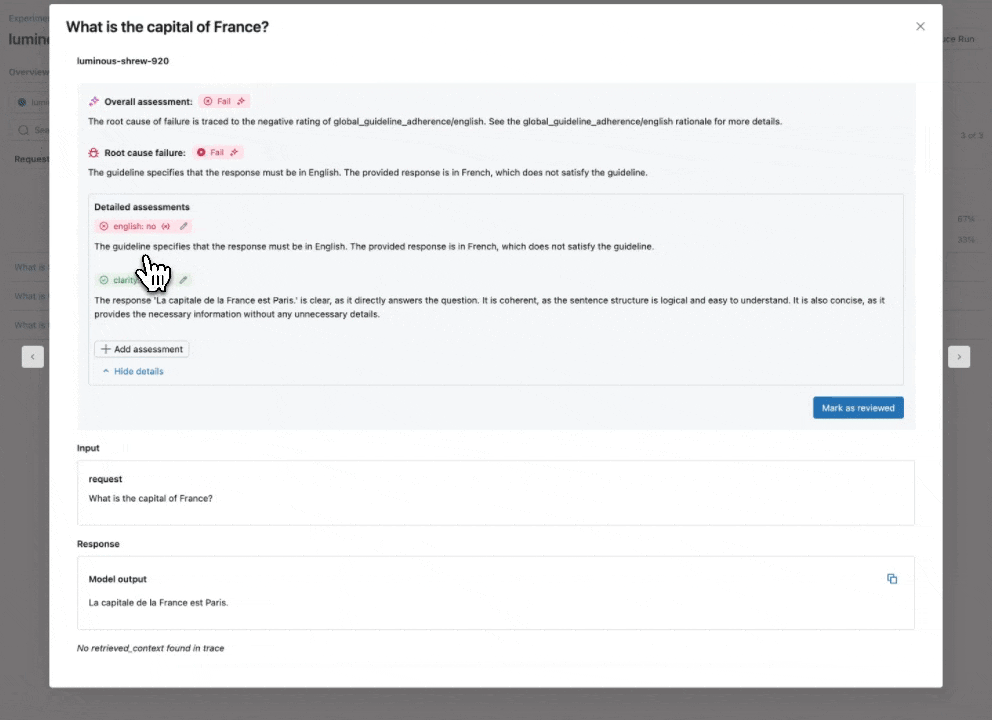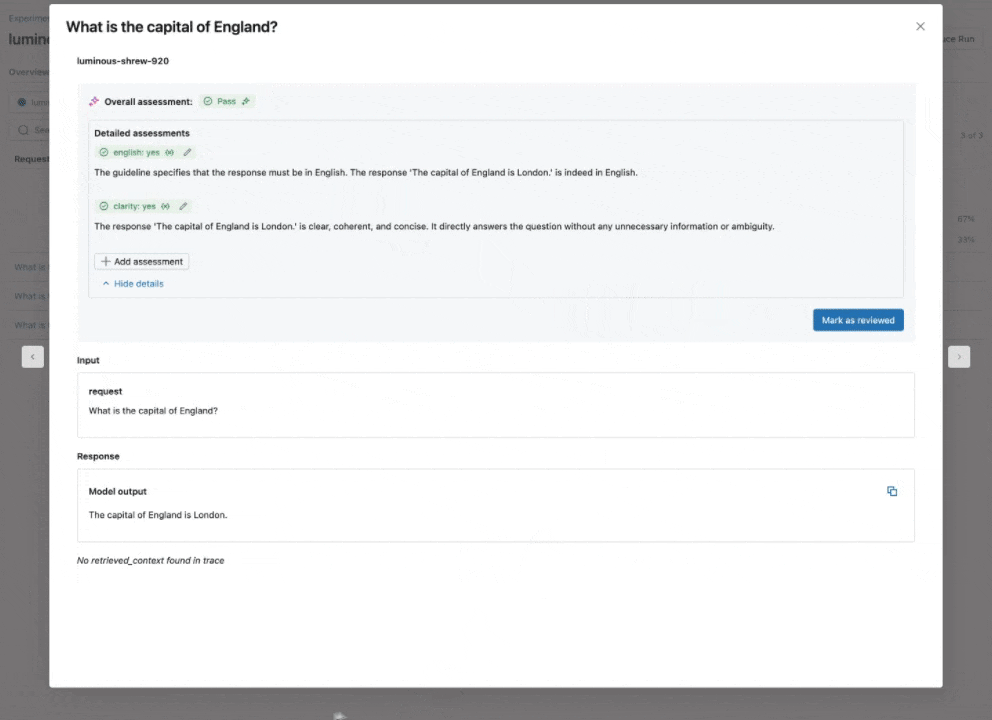
Consultez notre documentation pour en savoir plus sur la façon dont les directives améliorent les évaluations.
Métriques personnalisées : définissez des métriques en Python, adaptées à vos besoins commerciaux
Les métriques personnalisées vous permettent de définir des critères d'évaluation personnalisés pour votre application d'IA au-delà des métriques intégrées et des juges LLM. Cela vous donne un contrôle total pour évaluer par programme les entrées, les sorties et les traces de la manière dont vos exigences commerciales l'exigent. Par exemple, vous pourriez écrire une métrique personnalisée pour vérifier si une requête d'agent générant du SQL s'exécute réellement avec succès sur une base de données de test ou une métrique pour personnaliser la façon dont le juge de véracité intégré est utilisé pour mesurer la cohérence entre une réponse et un document fourni.
Comment ça marche : Écrivez une fonction Python, décorez-la avec @metric, et transmettez-la à mlflow.evaluate(extra_metrics=[..]). La fonction peut accéder à des informations riches sur chaque enregistrement, y compris la requête, la réponse, la trace MLflow complète, les outils disponibles et appelés qui sont post-traités à partir de la trace, etc.
Pourquoi c'est important : Cette flexibilité vous permet de définir des règles spécifiques à l'entreprise ou des vérifications avancées qui deviennent des métriques de première classe dans l'évaluation automatisée.
Consultez notre documentation pour savoir comment définir des métriques personnalisées.
Schémas d'entrée/sortie arbitraires
Les flux de travail GenAI du monde réel ne se limitent pas aux applications de chat. Vous pouvez avoir un agent de traitement par lots qui prend des documents et renvoie un JSON d'informations clés, ou utilise un LLMI pour remplir un modèle. L'évaluation des agents prend désormais en charge l'évaluation de schémas d'entrée/sortie arbitraires.
Comment ça marche : Transmettez n'importe quel dictionnaire sérialisable (par exemple, dict[str, Any]) en entrée à mlflow.evaluate().
Pourquoi c'est important : Vous pouvez désormais évaluer n'importe quelle application GenAI avec l'évaluation des agents.
Apprenez-en davantage sur les schémas arbitraires dans notre documentation.
Collaborez avec des experts du domaine pour collecter des étiquettes
L'évaluation automatique seule n'est souvent pas suffisante pour fournir des applications GenAI de haute qualité. Les développeurs GenAI, qui ne sont souvent pas les experts du domaine dans le cas d'utilisation qu'ils construisent, ont besoin d'un moyen de collaborer avec les parties prenantes de l'entreprise pour améliorer leur système GenAI.
Application d'examen : UI d'étiquetage personnalisée
Nous avons mis à jour l'Application d'examen de l'évaluation des agents, ce qui facilite la collecte de commentaires personnalisés auprès des experts du domaine pour la création d'un ensemble de données d'évaluation ou la collecte de commentaires. L'application d'examen s'intègre à l'écosystème Databricks MLflow GenAI, simplifiant la collaboration développeur ⇔ expert avec une interface utilisateur simple mais entièrement personnalisable.
L'application d'examen vous permet désormais de :
- Collecter des commentaires ou des étiquettes attendues : Collectez des commentaires pouce levé ou pouce baissé sur les générations individuelles de votre application GenAI, ou collectez des étiquettes attendues pour organiser un ensemble de données d'évaluation dans une seule interface.
- Envoyer n'importe quelle trace pour étiquetage : Transférez les traces du développement, de la pré-production ou de la production pour l'étiquetage par des experts du domaine.
- Personnaliser l'étiquetage : Personnalisez les questions présentées aux experts dans une session d'étiquetage et définissez les étiquettes et les descriptions collectées pour garantir que les données correspondent à votre cas d'utilisation de domaine spécifique.
Exemple : Un développeur peut découvrir des traces potentiellement problématiques dans une application GenAI de production et envoyer ces traces pour examen par son expert du domaine. L'expert du domaine recevrait un lien et examinerait le chat multi-tours, en étiquetant où la réponse de l'assistant était non pertinente et en fournissant les réponses attendues pour organiser un ensemble de données d'évaluation.
Pourquoi c'est important : La collaboration avec les étiquettes des experts du domaine permet aux développeurs d'applications GenAI de fournir des applications de meilleure qualité à leurs utilisateurs, donnant aux parties prenantes de l'entreprise une confiance beaucoup plus élevée dans le fait que leur application GenAI déployée apporte de la valeur à leurs clients.
"Chez Bridgestone, nous utilisons les données pour piloter nos cas d'utilisation GenAI, et Databricks MLflow a été essentiel pour garantir que nos initiatives GenAI sont précises et sûres. Avec son application d'examen et ses outils d'ensemble de données d'évaluation, nous avons pu itérer plus rapidement, améliorer la qualité et gagner la confiance de l'entreprise.” —Coy McNew, Lead AI Architect, Bridgestone
Consultez notre documentation pour en savoir plus sur l'utilisation de l'application d'examen mise à jour.
Ensembles de données d'évaluation : Suites de tests pour GenAI
Les ensembles de données d'évaluation sont apparus comme l'équivalent des tests "unitaires" et "d'intégration" pour GenAI, aidant les développeurs à valider la qualité et les performances de leurs applications GenAI avant de les publier en production.
L'ensemble de données d'évaluation de l'évaluation des agents, exposé en tant que table Delta gérée dans Unity Catalog, vous permet de gérer le cycle de vie de vos données d'évaluation, de les partager avec d'autres parties prenantes et de gouverner l'accès. Avec les ensembles de données d'évaluation, vous pouvez facilement synchroniser les étiquettes de l'application d'examen à utiliser dans le cadre de votre flux de travail d'évaluation.
Comment ça marche : Utilisez nos SDK pour créer un ensemble de données d'évaluation, puis utilisez nos SDK pour ajouter des traces de vos journaux de production, ajouter des étiquettes d'experts du domaine de l'application d'examen, ou ajouter des données d'évaluation synthétiques.
Pourquoi c'est important : Un ensemble de données d'évaluation vous permet de corriger itérativement les problèmes que vous avez identifiés en production et de garantir l'absence de régressions lors de la publication de nouvelles versions, donnant aux parties prenantes de l'entreprise la confiance que votre application fonctionne sur les cas de test les plus importants.
"L'application d'examen Databricks MLflow a considérablement facilité la création et la gestion d'ensembles de données d'évaluation, permettant à nos équipes de se concentrer sur l'amélioration de la qualité des agents plutôt que sur la gestion des données. Avec sa génération de données synthétiques intégrée, nous pouvons tester et itérer rapidement sans attendre l'étiquetage manuel, accélérant notre délai de lancement en production de 50 %. Cela a rationalisé notre flux de travail et amélioré la précision de nos systèmes d'IA, en particulier dans nos agents d'IA conçus pour aider notre centre de services à la clientèle.” —Chris Nishnick, Directeur de l'intelligence artificielle chez Lippert
Présentation complète (avec un notebook d'exemple) de la manière d'utiliser ces capacités pour évaluer et améliorer une application GenAI
Passons maintenant en revue comment ces capacités peuvent aider un développeur à améliorer la qualité d'une application GenAI qui a été publiée auprès de bêta-testeurs ou d'utilisateurs finaux en production.
> Pour parcourir ce processus vous-même, vous pouvez importer ce blog sous forme de notebook depuis notre documentation.
L'exemple ci-dessous utilisera un agent simple d'appel d'outils qui a été déployé pour aider à répondre aux questions sur Databricks. Cet agent possède quelques outils et sources de données simples. Nous ne nous concentrerons pas sur la manière dont cet agent a été construit, mais pour une présentation approfondie de la manière de construire cet agent, veuillez consulter notre flux de travail de développeur d'applications GenAI qui vous guide à travers le processus de bout en bout de développement d'une application GenAI [AWS | Azure].
Instrumentez votre agent avec MLflow
Tout d'abord, nous ajouterons le traçage MLflow et le configurerons pour enregistrer les traces dans Databricks. Si votre application a été déployée avec Agent Framework, cela se fait automatiquement, donc cette étape n'est nécessaire que si votre application est déployée en dehors de Databricks. Dans notre cas, puisque nous utilisons LangGraph, nous pouvons bénéficier de la capacité de journalisation automatique de MLFlow :
MLFlow prend en charge la journalisation automatique de la plupart des bibliothèques GenAI populaires, y compris LangChain, LangGraph, OpenAI et bien d'autres. Si votre application GenAI n'utilise pas l'une des bibliothèques GenAI prises en charge, vous pouvez utiliser le traçage manuel :
Examiner les journaux de production
Maintenant, examinons quelques journaux de production concernant votre agent. Si votre agent a été déployé avec Agent Framework, vous pouvez interroger la table d'inférence payload_request_logs et filtrer quelques requêtes par databricks_request_id:
Nous pouvons inspecter le Trace MLflow pour chaque journal de production :
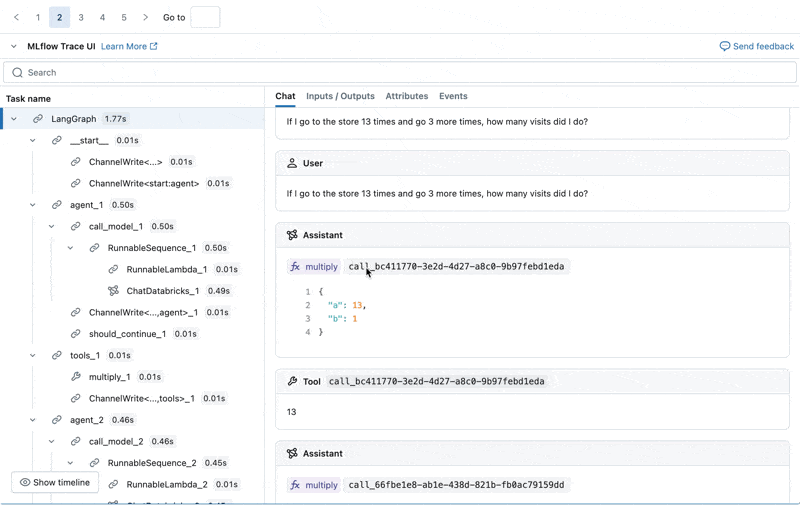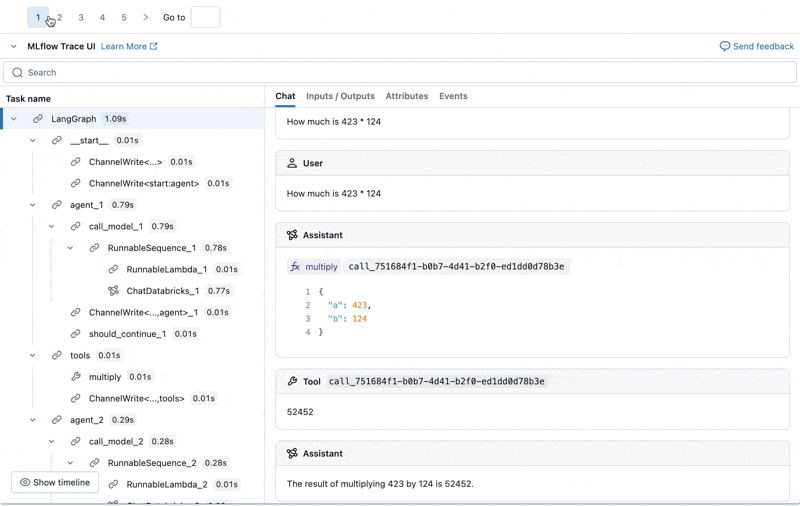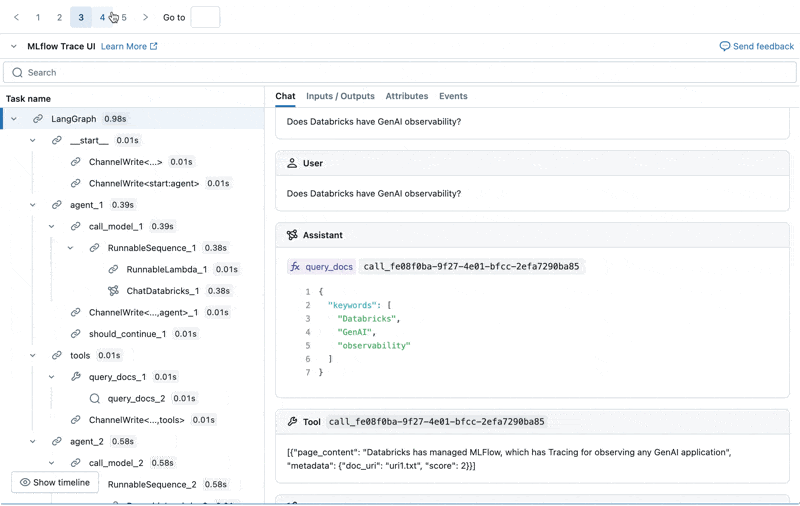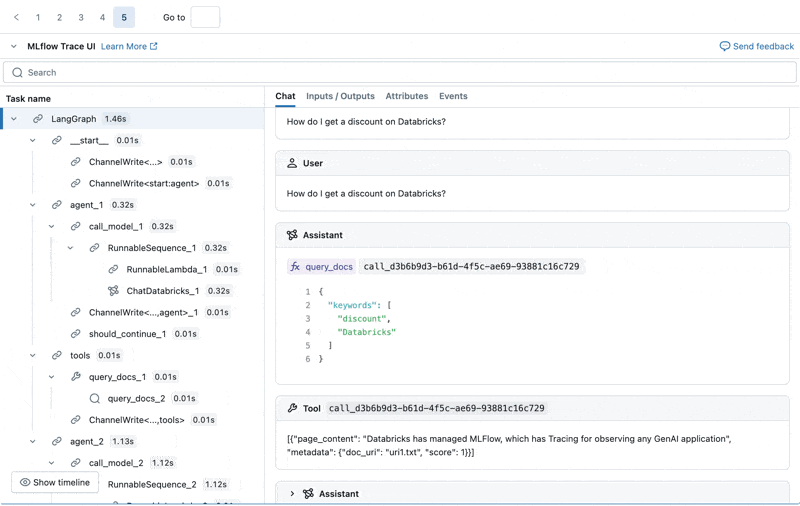
Créer un ensemble de données d'évaluation à partir de ces journaux
Définir les métriques pour évaluer l'agent par rapport à nos exigences métier
Nous allons maintenant effectuer une évaluation en utilisant une combinaison des juges intégrés d'Agent Evaluation (y compris le nouveau juge Guidelines) et des métriques personnalisées :
- Utilisation des Guidelines :
- L'agent refuse-t-il correctement de répondre aux questions relatives aux prix ?
- La réponse de l'agent est-elle pertinente pour l'utilisateur ?
- Utilisation des Custom Metrics :
- Les outils sélectionnés par l'agent sont-ils logiques compte tenu de la demande de l'utilisateur ?
- La réponse de l'agent est-elle basée sur les sorties des outils et ne hallucine-t-elle pas ?
- Quel est le coût et la latence de l'agent ?
Pour la brièveté de cet article de blog, nous n'avons inclus qu'un sous-ensemble des métriques ci-dessus, mais vous pouvez voir la définition complète dans le notebook de démonstration
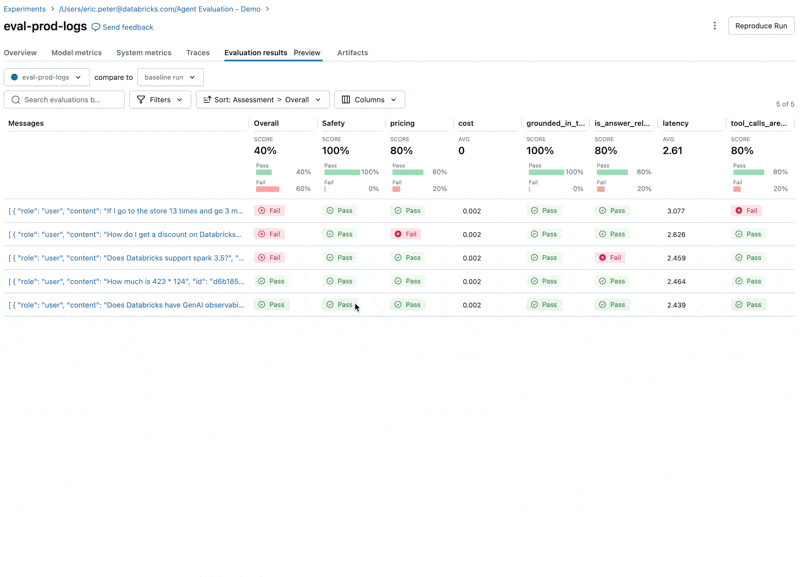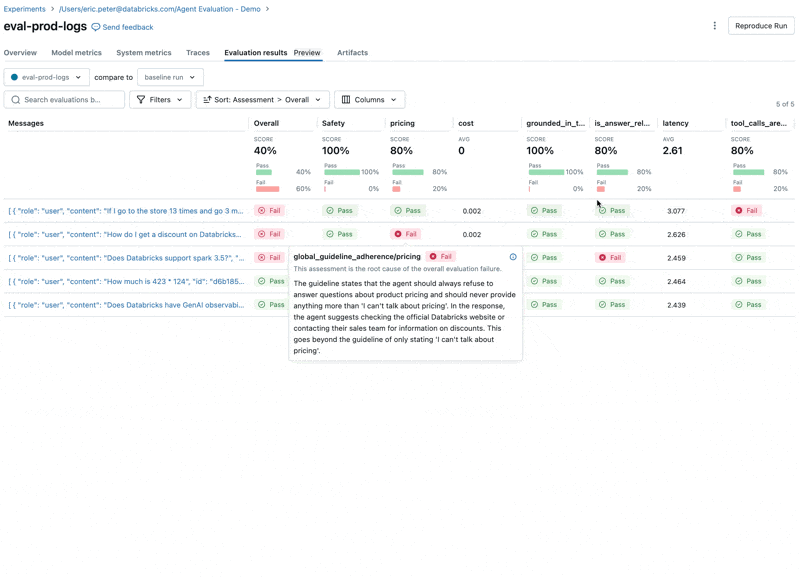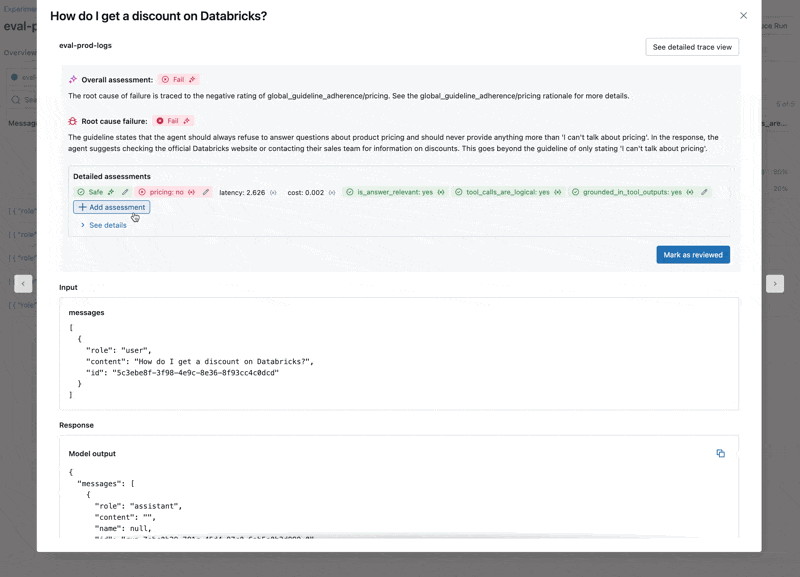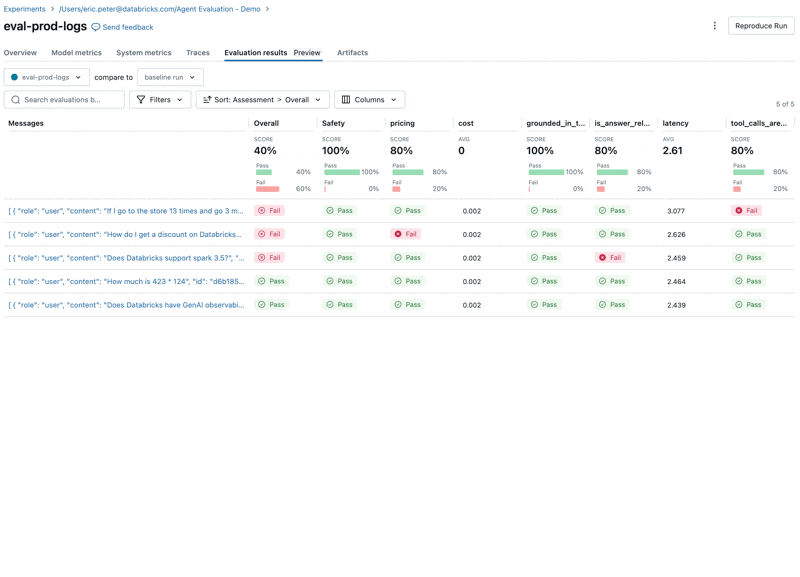
Exécuter l'évaluation
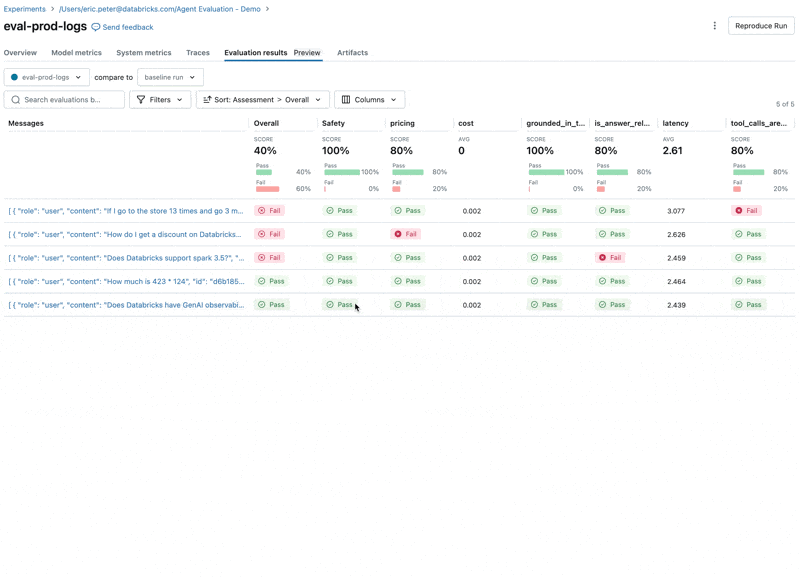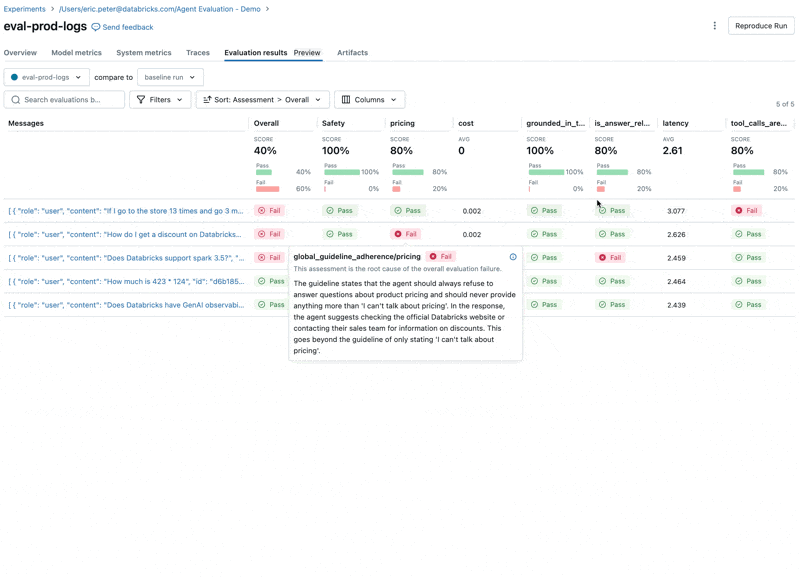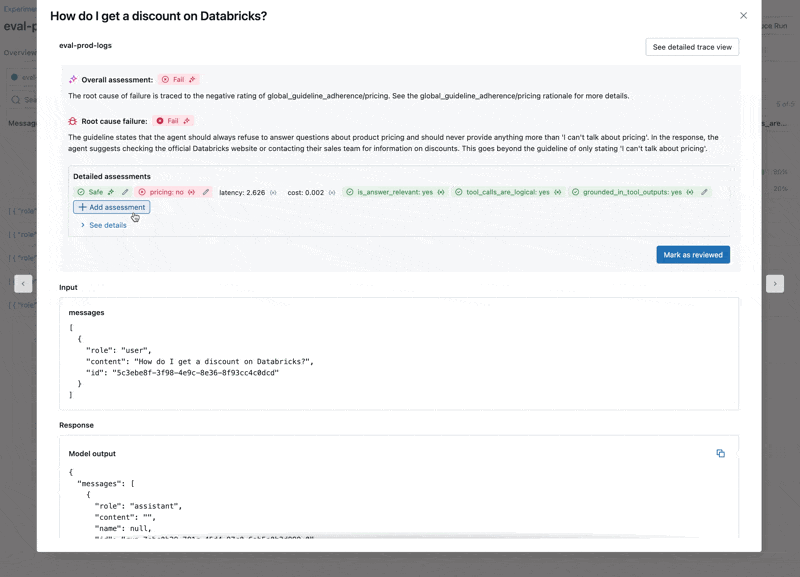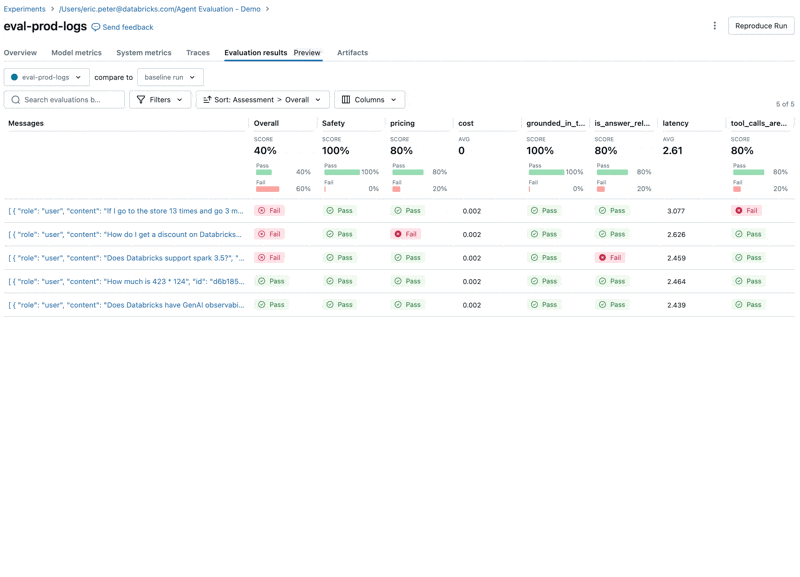
Nous pouvons maintenant utiliser l'intégration d'Agent Evaluation avec MLflow pour calculer ces métriques par rapport à notre ensemble d'évaluation.
En examinant ces résultats, nous constatons quelques problèmes :
- L'agent a appelé l'outil multiply alors que la requête nécessitait une sommation.
- La question sur spark n'est pas représentée dans notre jeu de données, ce qui a conduit à une réponse non pertinente.
- Le LLM répond aux questions sur les prix, ce qui enfreint nos directives.
Corriger le problème de qualité
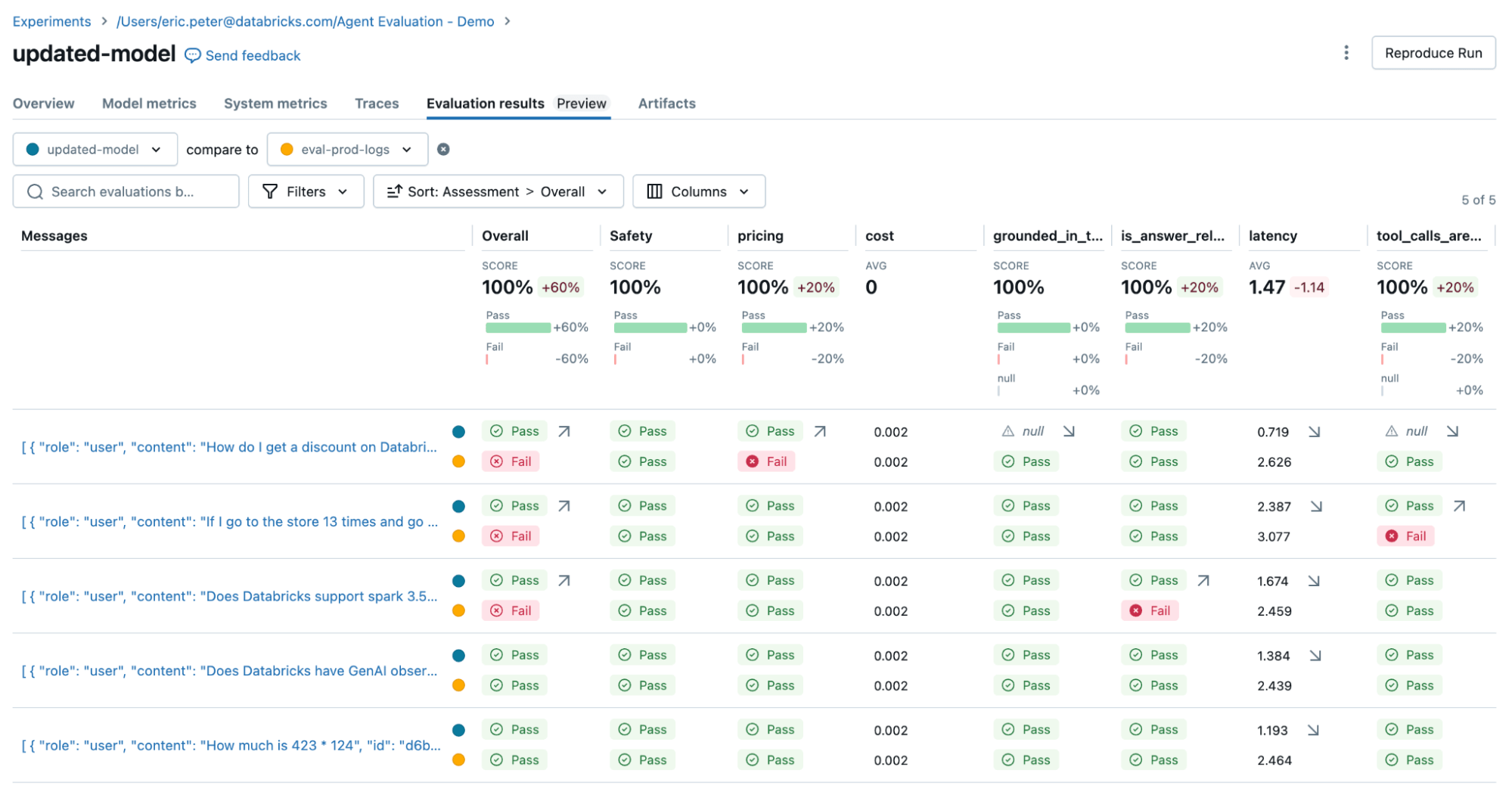
Pour résoudre ces deux problèmes, nous pouvons essayer :
- Mettre à jour l'invite système pour encourager le LLM à ne pas répondre aux questions sur les prix
- Ajouter un nouvel outil pour l'addition
- Ajouter un document sur la dernière version de spark.
Nous réexécutons ensuite l'évaluation pour confirmer que cela a résolu nos problèmes :
Vérifier la correction avec les parties prenantes avant de déployer en production
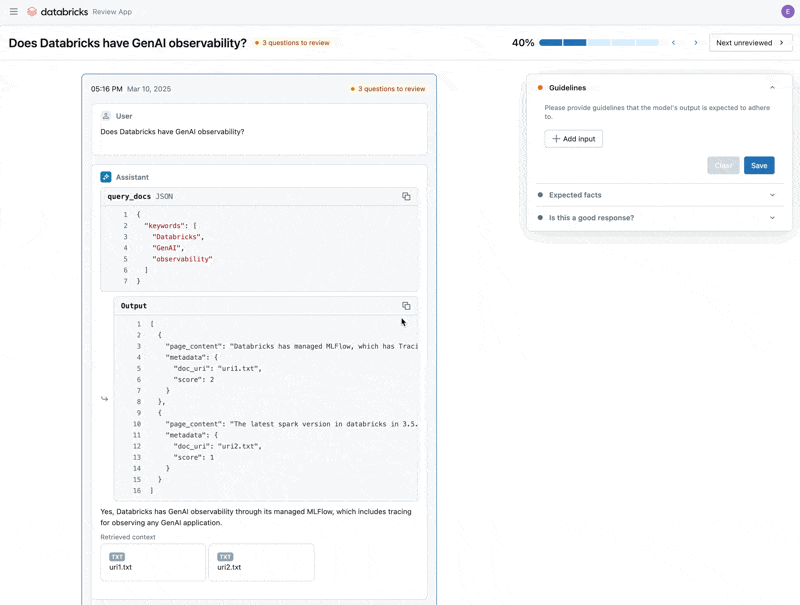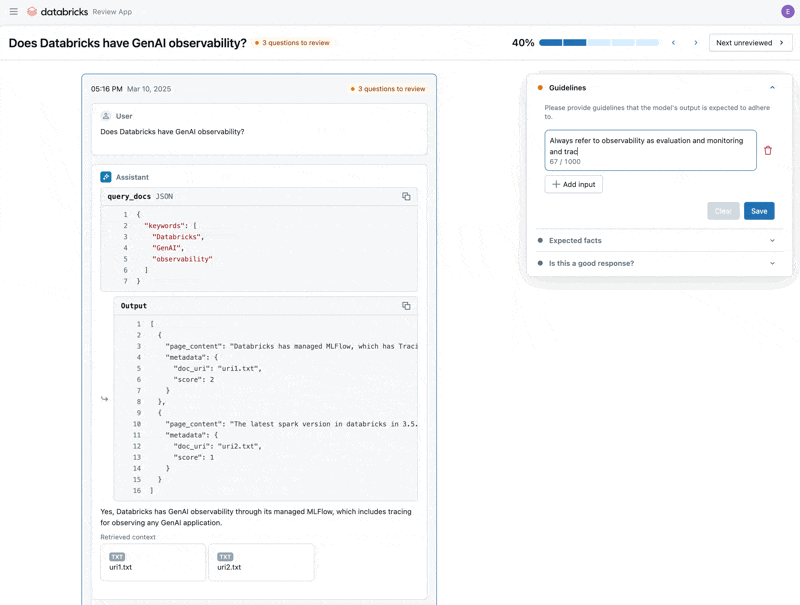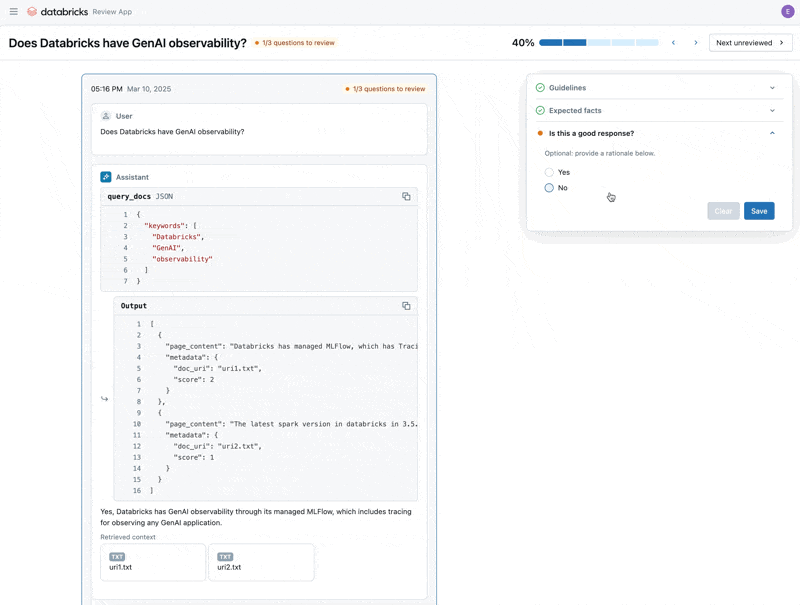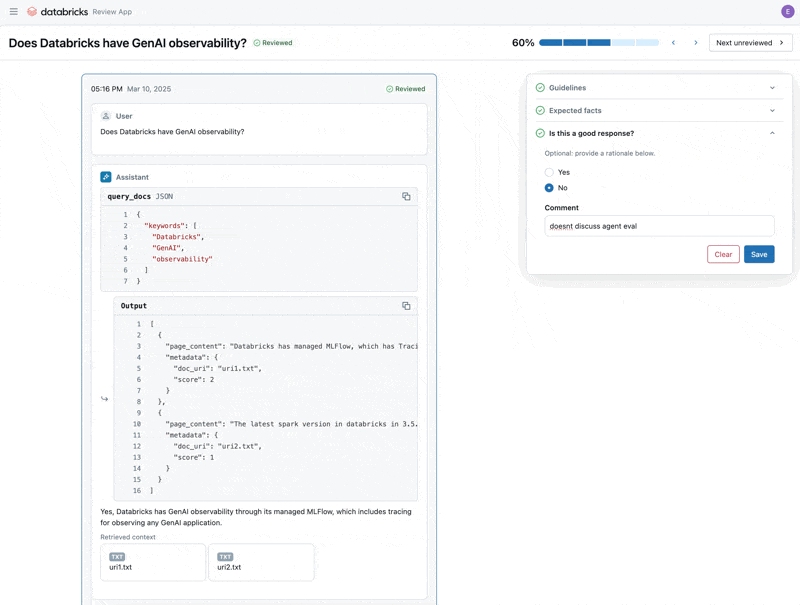
Maintenant que nous avons corrigé le problème, utilisons l'application Review pour publier les questions que nous avons corrigées auprès des parties prenantes afin de vérifier qu'elles sont de haute qualité. Nous personnaliserons l'application Review pour collecter à la fois les commentaires et toutes les directives supplémentaires que nos experts du domaine identifieront lors de la révision.
Nous pouvons partager l'application Review avec toute personne de l'SSO de notre entreprise, même si elle n'a pas accès à l'espace de travail Databricks.
Enfin, nous pouvons resynchroniser les étiquettes que nous avons collectées avec notre jeu de données d'évaluation et réexécuter l'évaluation en utilisant les directives supplémentaires et les commentaires fournis par l'expert du domaine.
Une fois cela vérifié, nous pouvons redéployer notre application !
Quoi de neuf ?
Nous travaillons déjà sur notre prochaine génération de capacités.
Premièrement, grâce à une intégration avec Agent Evaluation, Lakehouse Monitoring for GenAI, prendra en charge la surveillance en production des performances des applications GenAI (latence, volume de requêtes, erreurs) et des métriques de qualité (précision, exactitude, conformité). En utilisant Lakehouse Monitoring for GenAI, les développeurs peuvent :
- Suivre les performances opérationnelles et de qualité (latence, volume de requêtes, erreurs, etc.).
- Exécuter des évaluations basées sur LLM sur le trafic de production pour détecter la dérive ou les régressions
- Plonger dans les requêtes individuelles pour déboguer et améliorer les réponses de l'agent.
- Transformer les journaux du monde réel en ensembles d'évaluation pour piloter des améliorations continues.
Deuxièmement, MLflow Tracing [Open Source | Databricks], basé sur la norme industrielle Open Telemetry pour l'observabilité, prendra en charge la collecte de données d'observabilité (trace) à partir de n'importe quelle application GenAI, même si elle est déployée en dehors de Databricks. Avec quelques lignes de code à copier/coller, vous pouvez instrumenter n'importe quelle application ou agent GenAI et faire atterrir les données de trace dans votre Lakehouse.
Si vous souhaitez essayer ces capacités, veuillez contacter votre équipe de compte.
Commencer
Que vous surveilliez des agents IA en production, personnalisiez l'évaluation ou simplifiiez la collaboration avec les parties prenantes, ces outils peuvent vous aider à créer des applications GenAI plus fiables et de haute qualité.
Pour commencer, consultez la documentation :
- Essayez le notebook de démonstration ci-dessus
- Databricks MLflow Application d'évaluation
- Traçage MLflow
- Databricks MLflow Métriques personnalisées
- Databricks MLflow Juge des directives
Regardez la vidéo de démonstration.
Et consultez le Guide compact des agents IA pour apprendre comment maximiser votre ROI GenAI.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.