Présentation du type de données Variant ouvert dans Delta Lake et Apache Spark
Traitement plus rapide et plus de flexibilité pour travailler avec des données semi-structurées
par Kent Marten, Gene Pang, Chenhao Li et Han Xiao
Nous sommes ravis d'annoncer un nouveau type de données appelé variant pour les données semi-structurées. Variant offre des améliorations de performance d'un ordre de grandeur par rapport au stockage de ces données sous forme de chaînes JSON, tout en conservant la flexibilité nécessaire pour prendre en charge des schémas hautement imbriqués et évolutifs.
Le traitement des données semi-structurées est depuis longtemps une capacité fondamentale du Lakehouse. La détection et la réponse des points d'extrémité (EDR), l'analyse des clics publicitaires et la télémétrie IoT ne sont que quelques-uns des cas d'utilisation populaires qui reposent sur des données semi-structurées. Alors que nous migrons de plus en plus de clients depuis des entrepôts de données propriétaires, nous avons entendu dire qu'ils s'appuient sur le type de données variant offert par ces entrepôts propriétaires, et qu'ils aimeraient voir une norme open source pour cela afin d'éviter tout verrouillage.
Le type variant ouvert est le résultat de notre collaboration avec la communauté open source Apache Spark et la communauté Linux Foundation Delta Lake :
- Le type de données Variant, les expressions binaires Variant et le format d'encodage binaire Variant sont déjà fusionnés dans Spark open source. Les détails de l'encodage binaire peuvent être consultés ici.
- Le format d'encodage binaire permet un accès et une navigation plus rapides des données par rapport aux chaînes de caractères. L'implémentation du format d'encodage binaire Variant est conditionnée dans une bibliothèque open-source, afin qu'elle puisse être utilisée dans d'autres projets.
- La prise en charge du type de données Variant est également open-sourcée pour Delta, et le protocole RFC peut être trouvé ici. La prise en charge de Variant sera incluse dans Spark 4.0 et Delta 4.0.
« Nous soutenons la communauté open source en mettant l'accent sur les données à travers notre plateforme de données open source Legend », a déclaré Neema Raphael, Chief Data Officer et Head of Data Engineering chez Goldman Sachs. « Le lancement d'Open Source Variant dans Spark est une autre grande étape pour un écosystème de données ouvert. »
Et à partir de DBR 15.3, toutes les capacités susmentionnées seront disponibles pour nos clients.
Qu'est-ce que Variant ?
Variant est un nouveau type de données pour le stockage de données semi-structurées. Dans la préversion publique de la prochaine version de Databricks Runtime 15.3, l'entrée et la sortie de données hiérarchiques via JSON seront prises en charge. Sans Variant, les clients devaient choisir entre flexibilité et performance. Pour maintenir la flexibilité, les clients stockaient le JSON dans des colonnes uniques sous forme de chaînes. Pour obtenir de meilleures performances, les clients appliquaient des approches de schématisation strictes avec des structs, ce qui nécessite des processus distincts pour maintenir et mettre à jour les changements de schéma. Avec Variant, les clients peuvent conserver la flexibilité (pas besoin de définir de schéma explicite) et bénéficier de performances considérablement améliorées par rapport à l'interrogation du JSON sous forme de chaîne.
Variant est particulièrement utile lorsque les sources JSON ont des schémas inconnus, changeants et évoluant fréquemment. Par exemple, les clients ont partagé des cas d'utilisation de détection et de réponse des points d'extrémité (EDR), avec la nécessité de lire et de combiner des journaux contenant différents schémas JSON. De même, pour les utilisations impliquant des clics publicitaires et de la télémétrie d'application, où le schéma est inconnu et change constamment, Variant est bien adapté. Dans les deux cas, la flexibilité du type de données Variant permet d'ingérer les données de manière performante sans nécessiter de schéma explicite.
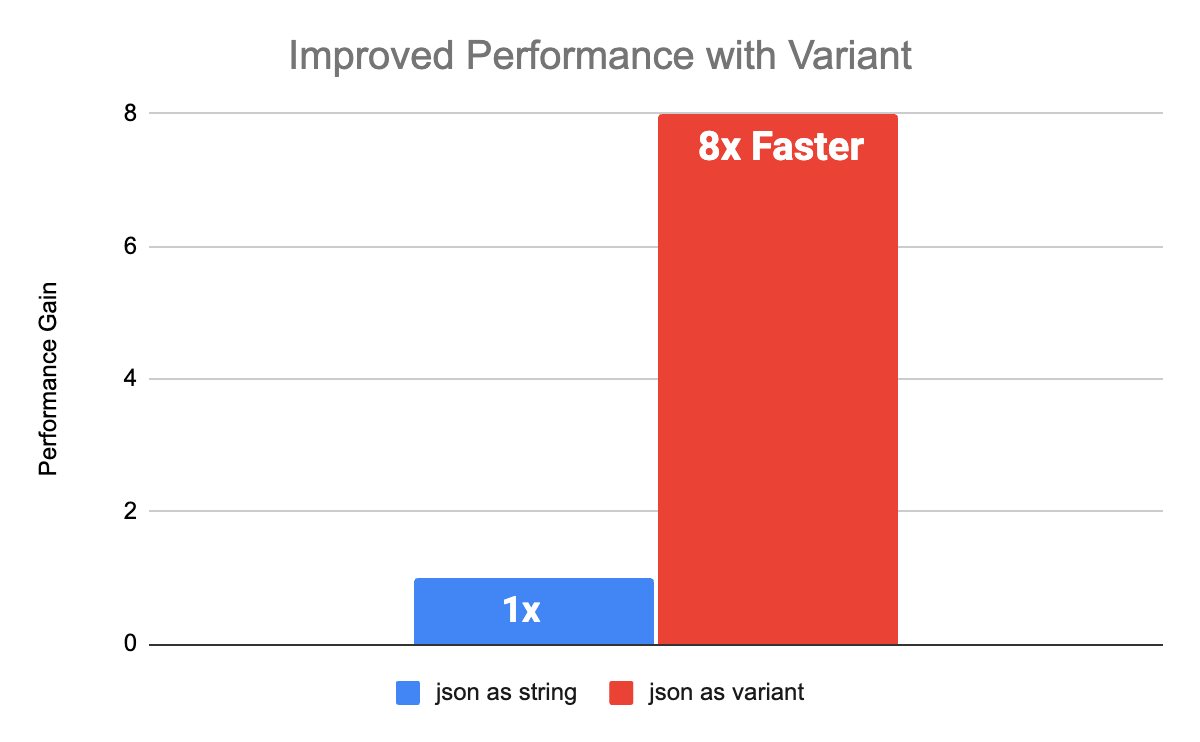
Benchmarks de performance
Variant offrira des performances améliorées par rapport aux charges de travail existantes qui maintiennent le JSON sous forme de chaîne. Nous avons effectué plusieurs benchmarks avec des schémas inspirés des données clients pour comparer les performances de String vs Variant. Pour les schémas imbriqués et plats, les performances avec Variant ont été améliorées de 8x par rapport aux colonnes String. Les benchmarks ont été réalisés avec Databricks Runtime 15.0 avec Photon activé.
Comment puis-je utiliser Variant ?
Il existe un certain nombre de nouvelles fonctions pour prendre en charge les types Variant, qui vous permettent d'inspecter le schéma d'un variant, d'exploser une colonne variant et de la convertir en JSON. La fonction PARSE_JSON() sera couramment utilisée pour retourner une valeur variant représentant l'entrée de chaîne JSON.
Pour charger des données Variant, vous pouvez créer une colonne de table avec le type Variant. Vous pouvez convertir toute chaîne formatée en JSON en Variant avec la fonction PARSE_JSON(), et l'insérer dans une colonne Variant.
Vous pouvez utiliser CTAS pour créer une table avec des colonnes Variant. Le schéma de la table créée est dérivé du résultat de la requête. Par conséquent, le résultat de la requête doit avoir des colonnes Variant dans le schéma de sortie afin de créer une table avec des colonnes Variant.
Vous pouvez également utiliser COPY INTO pour copier des données JSON dans une table avec une ou plusieurs colonnes Variant.
La navigation dans les chemins suit une syntaxe intuitive de notation par points.
Entièrement open-sourcé, pas de verrouillage propriétaire
Récapitulons :
- Le type de données Variant, les expressions binaires et le format d'encodage binaire sont déjà fusionnés dans Apache Spark. Le format d'encodage binaire peut être examiné en détail ici.
- Le format d'encodage binaire permet un accès et une navigation plus rapides des données par rapport aux chaînes de caractères. L'implémentation du format d'encodage binaire est conditionnée dans une bibliothèque open-source, afin qu'elle puisse être utilisée dans d'autres projets.
- La prise en charge du type de données Variant est également open-sourcée pour Delta, et le protocole RFC peut être trouvé ici. La prise en charge de Variant sera incluse dans Spark 4.0 et Delta 4.0.
De plus, nous prévoyons d'implémenter le déchiquetage/la sous-colonisation pour le type Variant. Le déchiquetage est une technique visant à améliorer les performances de l'interrogation de chemins spécifiques au sein des données Variant. Avec le déchiquetage, les chemins peuvent être stockés dans leur propre colonne, ce qui peut réduire les E/S et les calculs nécessaires pour interroger ce chemin. Le déchiquetage permet également l'élagage des données pour éviter des travaux supplémentaires inutiles. Le déchiquetage sera également disponible dans Apache Spark et Delta Lake.
Assistez-vous au DATA + AI Summit cette année du 10 au 13 juin à San Francisco ?
Veuillez assister à « Variant Data Type - Making Semi-Structured Data Fast and Simple ».
Variant sera activé par défaut dans Databricks Runtime 15.3 en préversion publique et dans le canal DBSQL Preview peu après. Testez vos cas d'utilisation de données semi-structurées et lancez une conversation sur les forums de la communauté Databricks si vous avez des réflexions ou des questions. Nous aimerions connaître l'avis de la communauté !
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.