Lakeflow Connect : Ingestion de données efficace et facile à l'aide du connecteur SQL Server
Découvrez le connecteur SQL Server entièrement géré de Databricks Lakeflow Connect pour simplifier l'ingestion et l'intégration transparentes des données avec les outils Databricks pour le traitement et l'analyse des données.
par Andrea Tardif, Prasanna Selvaraj, Hector Bustamante et Phanitha Kommareddi
- Les principales entreprises technologiques sont confrontées à des défis complexes pour extraire de la valeur de leurs données SQL Server pour l'IA et l'analyse.
- Lakeflow Connect pour SQL Server offre une ingestion incrémentielle efficace pour les bases de données sur site et dans le cloud.
- Ce blog examine les considérations architecturales, les prérequis et les instructions étape par étape pour ingérer des données SQL Server dans votre lakehouse.
Complexités de l'extraction des données SQL Server
Alors que les entreprises natives du numérique reconnaissent le rôle essentiel de l'IA dans la stimulation de l'innovation, beaucoup ont encore du mal à rendre leurs données facilement disponibles pour des utilisations en aval, telles que le développement de machine learning et l'analyse avancée. Pour ces organisations, le support des équipes métier qui dépendent de SQL Server implique de disposer de ressources d'ingénierie des données et de maintenir des connecteurs personnalisés, de préparer les données pour l'analyse et de s'assurer qu'elles sont disponibles pour les équipes de données pour le développement de modèles. Souvent, ces données doivent être enrichies avec des sources supplémentaires et transformées avant de pouvoir éclairer les décisions basées sur les données.
La maintenance de ces processus devient rapidement complexe et fragile, ralentissant l'innovation. C'est pourquoi Databricks a développé Lakeflow Connect, qui comprend des connecteurs de données intégrés pour les bases de données populaires, les applications d'entreprise et les sources de fichiers. Ces connecteurs offrent une ingestion incrémentielle efficace de bout en bout, sont flexibles et faciles à configurer, et sont entièrement intégrés à la Databricks Data Intelligence Platform pour une gouvernance, une observabilité et une orchestration unifiées. Le nouveau connecteur Lakeflow pour SQL Server est le premier connecteur de base de données avec une intégration robuste pour les bases de données sur site et cloud afin d'aider à extraire des informations à partir des données au sein de Databricks.
Dans ce blog, nous examinerons les considérations clés pour savoir quand utiliser Lakeflow Connect pour SQL Server et expliquerons comment configurer le connecteur pour répliquer les données d'une instance Azure SQL Server. Ensuite, nous examinerons un cas d'utilisation spécifique, les meilleures pratiques et comment commencer.
Considérations architecturales clés
Vous trouverez ci-dessous les considérations clés pour vous aider à décider quand utiliser le connecteur SQL Server.
Compatibilité régionale et des fonctionnalités
Lakeflow Connect prend en charge une large gamme de variations de bases de données SQL Server, y compris Microsoft Azure SQL Database, Amazon RDS pour SQL Server, Microsoft SQL Server exécuté sur des machines virtuelles Azure et Amazon EC2, et SQL Server sur site accessible via Azure ExpressRoute ou AWS Direct Connect.
Étant donné que Lakeflow Connect s'exécute sur des pipelines serverless en arrière-plan, des fonctionnalités intégrées telles que l'observabilité des pipelines, l'alerte de journal d'événements et la surveillance du lakehouse peuvent être exploitées. Si le serverless n'est pas pris en charge dans votre région, contactez votre équipe de compte Databricks pour déposer une demande afin d'aider à prioriser le développement ou le déploiement dans cette région.
Lakeflow Connect est construit sur la Data Intelligence Platform, qui offre une intégration transparente avec Unity Catalog (UC) pour réutiliser les autorisations et les contrôles d'accès établis sur de nouvelles sources SQL Server pour une gouvernance unifiée. Si vos tables et vues Databricks sont sur Hive, nous vous recommandons de les mettre à niveau vers UC pour bénéficier de ces fonctionnalités (AWS | Azure | GCP) !
Exigences relatives aux modifications de données
Lakeflow Connect peut être intégré à SQL Server avec le suivi des modifications (CT) de Microsoft ou la capture des modifications de données (CDC) de Microsoft activée pour prendre en charge une ingestion incrémentielle efficace.
La CDC fournit des informations historiques sur les modifications des opérations d'insertion, de mise à jour et de suppression, et sur la date à laquelle les données réelles ont été modifiées. Le suivi des modifications identifie les lignes qui ont été modifiées dans une table sans capturer les modifications de données elles-mêmes. Apprenez-en davantage sur la CDC et les avantages de l'utilisation de la CDC avec SQL Server.
Databricks recommande d'utiliser le suivi des modifications pour toute table avec une clé primaire afin de minimiser la charge sur la base de données source. Pour les tables sources sans clé primaire, utilisez la CDC. Apprenez-en davantage sur quand l'utiliser ici.
Le connecteur SQL Server capture un chargement initial des données historiques lors de la première exécution de votre pipeline d'ingestion. Ensuite, le connecteur suit et ingère uniquement les modifications apportées aux données depuis la dernière exécution, en tirant parti des fonctionnalités CT/CDC de SQL Server pour rationaliser les opérations et l'efficacité.
Gouvernance et sécurité du réseau privé
Lorsqu'une connexion est établie avec un SQL Server à l'aide de Lakeflow Connect :
- Le trafic entre l'interface client et le plan de contrôle est chiffré en transit à l'aide de TLS 1.2 ou version ultérieure.
- Le volume de staging, où les fichiers bruts sont stockés pendant l'ingestion, est chiffré par le fournisseur de stockage cloud sous-jacent.
- Les données au repos sont protégées conformément aux meilleures pratiques et aux normes de conformité.
- Lorsqu'il est configuré avec des points de terminaison privés, tout le trafic de données reste à l'intérieur du réseau privé du fournisseur cloud, évitant ainsi l'Internet public.
Une fois les données ingérées dans Databricks, elles sont chiffrées comme les autres jeux de données au sein de UC. La passerelle d'ingestion qui extrait les instantanés, les journaux de modifications et les métadonnées de la base de données source atterrit dans un Volume UC, une abstraction de stockage idéale pour enregistrer des jeux de données non tabulaires tels que des fichiers JSON. Ce Volume UC réside dans le compte de stockage cloud du client, au sein de ses réseaux virtuels ou de ses clouds privés virtuels.
De plus, UC applique des contrôles d'accès fins et maintient des pistes d'audit pour gouverner l'accès à ces données nouvellement ingérées. Les crédentiels de service UC et les crédentiels de stockage sont stockés en tant qu'objets sécurisables au sein de UC, garantissant une gestion sécurisée et centralisée de l'authentification. Ces crédentiels ne sont jamais exposés dans les journaux ni codés en dur dans les pipelines d'ingestion SQL, offrant une protection et un contrôle d'accès robustes.
Si votre organisation remplit les critères ci-dessus, envisagez Lakeflow Connect pour SQL Server afin de simplifier l'ingestion de données dans Databricks.
Répartition de la solution technique
Ensuite, examinez les étapes de configuration de Lakeflow Connect pour SQL Server et de réplication des données à partir d'une instance Azure SQL Server.
Configurer les autorisations Unity Catalog
Dans Databricks, assurez-vous que le calcul serverless est activé pour les notebooks, les workflows et les pipelines (AWS | Azure | GCP). Validez ensuite que l'utilisateur ou le principal de service créant le pipeline d'ingestion dispose des autorisations UC suivantes :
| Type d'autorisation | Raison | Documentation |
| CREATE CONNECTION sur le metastore | Lakeflow Connect doit établir une connexion sécurisée à SQL Server. | CREATE CONNECTION |
| USE CATALOG sur le catalogue cible | Requis car il fournit l'accès au catalogue où Lakeflow Connect déposera les tables de données SQL Server dans UC. | USE CATALOG |
| UTILISER UN SCHÉMA, CRÉER UNE TABLE et CRÉER UN VOLUME sur un schéma existant ou CRÉER UN SCHÉMA sur le catalogue cible | Fournit les droits nécessaires pour accéder aux schémas et créer des emplacements de stockage pour les tables de données ingérées. | ACCORDER DES PRIVILÈGES |
| Permissions illimitées pour créer des clusters, ou une stratégie de cluster personnalisée | Requis pour démarrer les ressources de calcul nécessaires au processus d'ingestion de la passerelle | GÉRER LES STRATÉGIES DE CLUSTER |
Configurer Azure SQL Server
Pour utiliser le connecteur SQL Server, confirmez que les exigences suivantes sont satisfaites :
- Confirmer la version SQL
- SQL Server 2012 ou une version ultérieure doit être activé pour utiliser le suivi des modifications. Cependant, 2016+ est recommandé*. Consultez les exigences de version SQL ici.
- Configurer le compte de service de base de données dédié à l'ingestion Databricks.
- Activer le suivi des modifications ou le CDC intégré
- Vous devez disposer de SQL Server 2012 ou d'une version ultérieure pour utiliser le CDC. Les versions antérieures à SQL Server 2016 nécessitent en outre l'édition Enterprise.
* Exigences à partir de mai 2025. Sujet à modification.
Exemple : Ingestion depuis Azure SQL Server vers Databricks
Ensuite, nous allons ingérer une table d'une base de données Azure SQL Server vers Databricks en utilisant Lakeflow Connect. Dans cet exemple, CDC et CT fournissent un aperçu de toutes les options disponibles. Comme la table de cet exemple a une clé primaire, CT aurait pu être le choix principal. Cependant, comme il n'y a qu'une seule petite table dans cet exemple, il n'y a pas de souci de surcharge de charge, donc CDC a également été inclus. Il est recommandé de consulter quand utiliser CDC, CT, ou les deux pour déterminer ce qui convient le mieux à vos données et à vos besoins d'actualisation.
1. [Azure SQL Server] Vérifier et configurer Azure SQL Server pour CDC et CT
Commencez par accéder au portail Azure et connectez-vous à l'aide de vos informations d'identification de compte Azure. Sur le côté gauche, cliquez sur Tous les services et recherchez SQL Servers. Trouvez et cliquez sur votre serveur, puis cliquez sur « Éditeur de requêtes » ; dans cet exemple, sqlserver01 a été sélectionné.
La capture d'écran ci-dessous montre que la base de données SQL Server a une table appelée « drivers ».
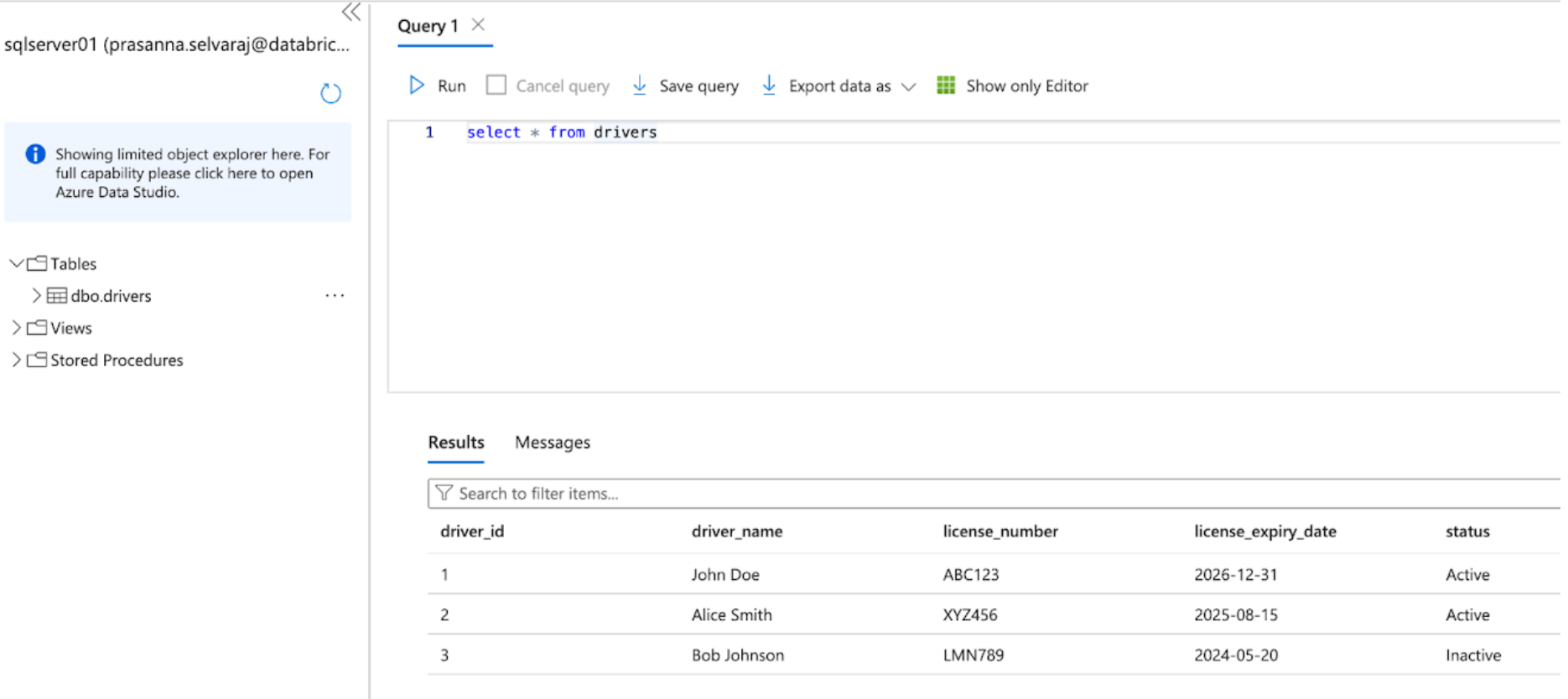
Avant de répliquer les données vers Databricks, la capture de données modifiées, le suivi des modifications, ou les deux doivent être activés.
Pour cet exemple, le script suivant est exécuté sur la base de données pour activer le CT :
Cette commande active le suivi des modifications pour la base de données avec les paramètres suivants :
- CHANGE_RETENTION = 3 DAYS : Cette valeur suit les modifications pendant 3 jours (72 heures). Une actualisation complète sera nécessaire si votre passerelle est hors ligne plus longtemps que le temps défini. Il est recommandé d'augmenter cette valeur si des interruptions plus longues sont prévues.
- AUTO_CLEANUP = ON : C'est le paramètre par défaut. Pour maintenir les performances, il supprime automatiquement les données de suivi des modifications plus anciennes que la période de rétention.
Ensuite, le script suivant est exécuté sur la base de données pour activer le CDC :
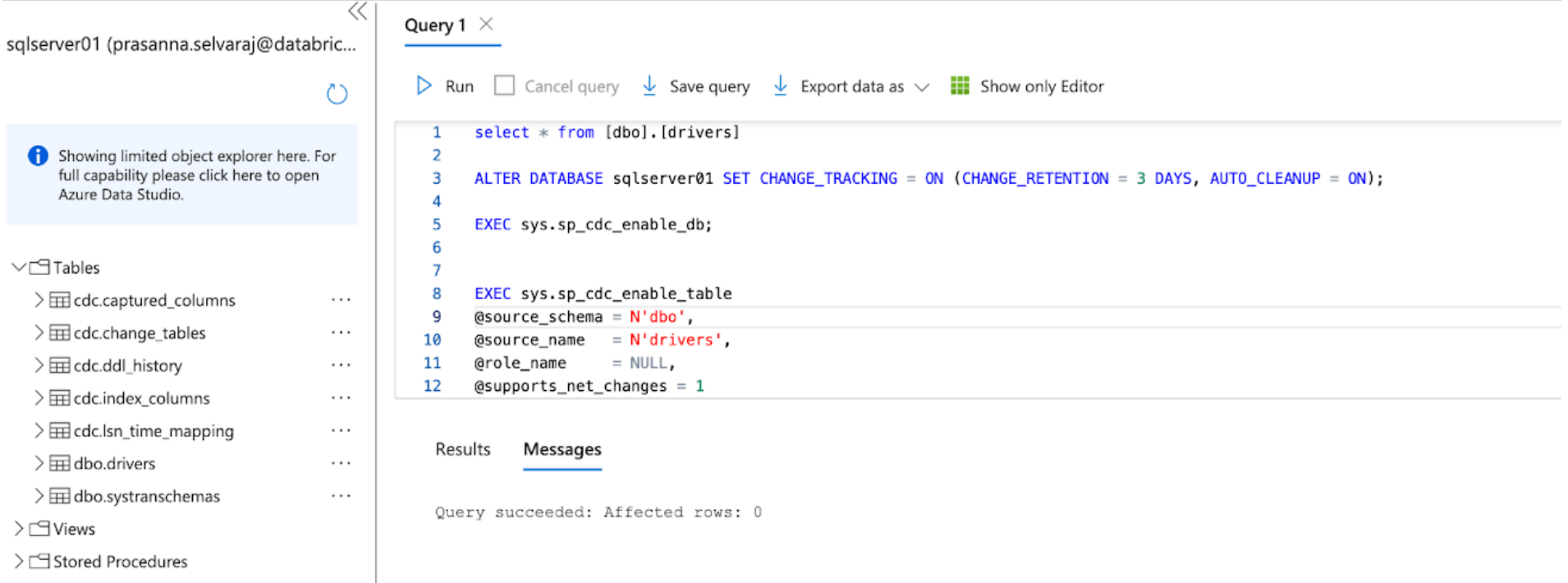
Lorsque les deux scripts ont terminé leur exécution, examinez la section des tables sous l'instance SQL Server dans Azure et assurez-vous que toutes les tables CDC et CT sont créées.
2. [Databricks] Configurer le connecteur SQL Server dans Lakeflow Connect
Dans cette prochaine étape, l'interface utilisateur Databricks sera présentée pour configurer le connecteur SQL Server. Alternativement, les Databricks Asset Bundles (DABs), une manière programmatique de gérer les pipelines Lakeflow Connect en tant que code, peuvent également être utilisés. Un exemple du script DABs complet se trouve dans l'annexe ci-dessous.
Une fois toutes les autorisations définies, comme indiqué dans la section Prérequis d'autorisation, vous êtes prêt à ingérer des données. Cliquez sur le bouton + Nouveau en haut à gauche, puis sélectionnez Ajouter ou téléverser des données.
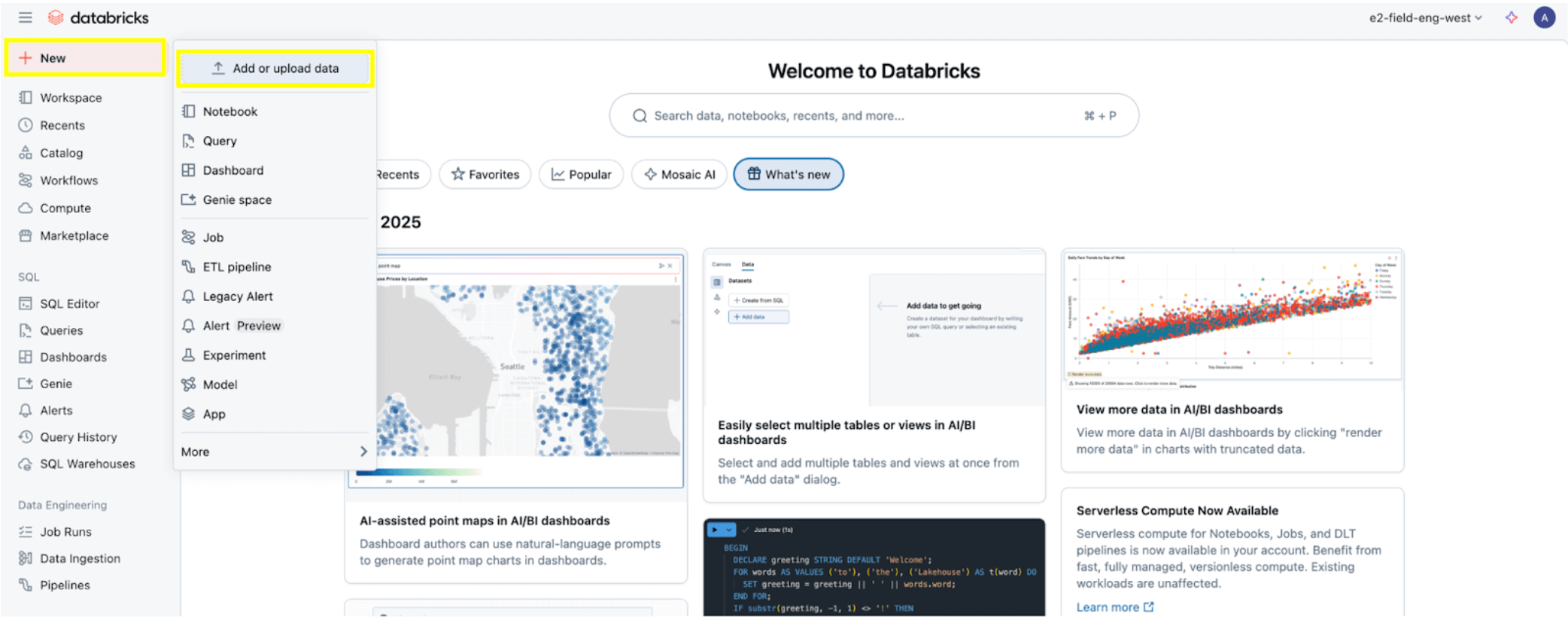
Sélectionnez ensuite l'option SQL Server.
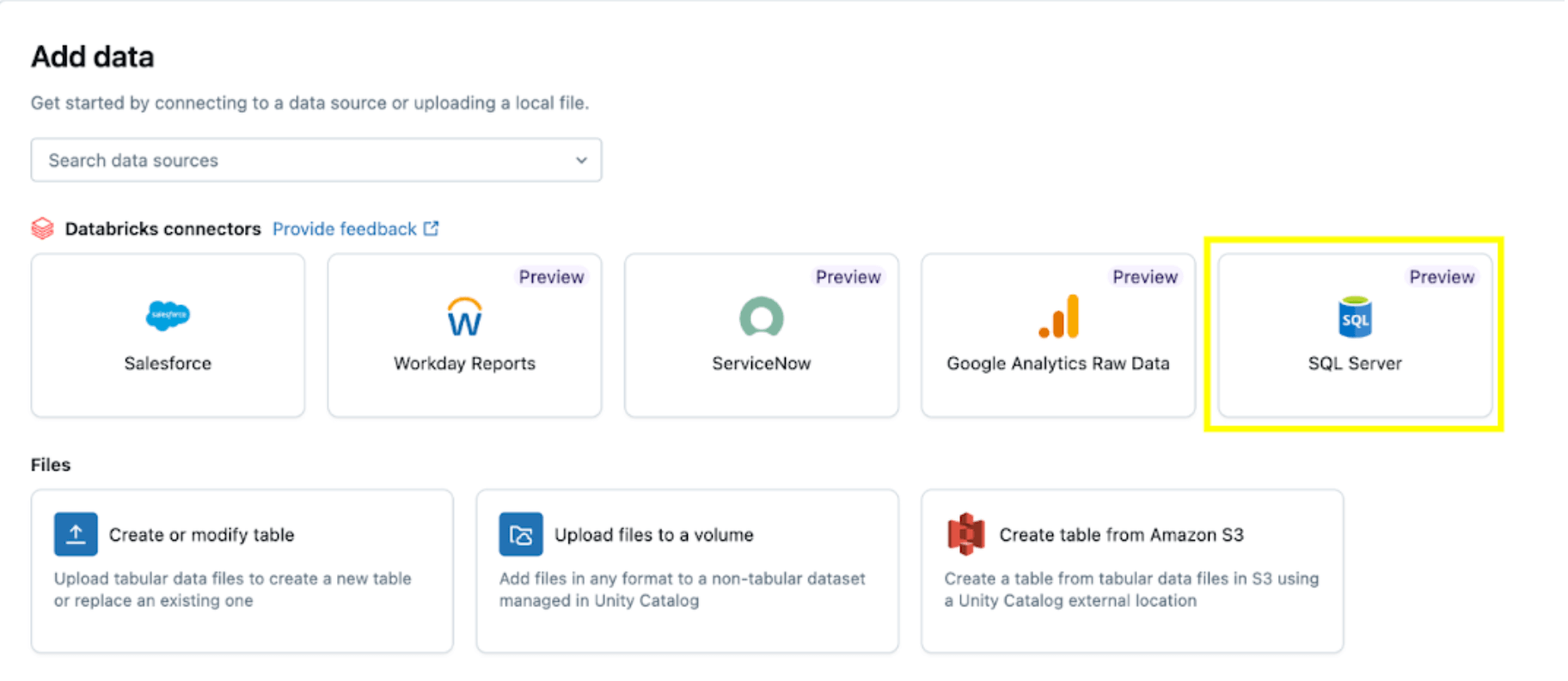
Le connecteur SQL Server est configuré en plusieurs étapes.
1. Configurez la passerelle d'ingestion (AWS | Azure | GCP). Dans cette étape, fournissez un nom pour le pipeline de passerelle d'ingestion et un catalogue et un schéma pour l'emplacement du volume UC afin d'extraire les instantanés et les données modifiées en continu de la base de données source.
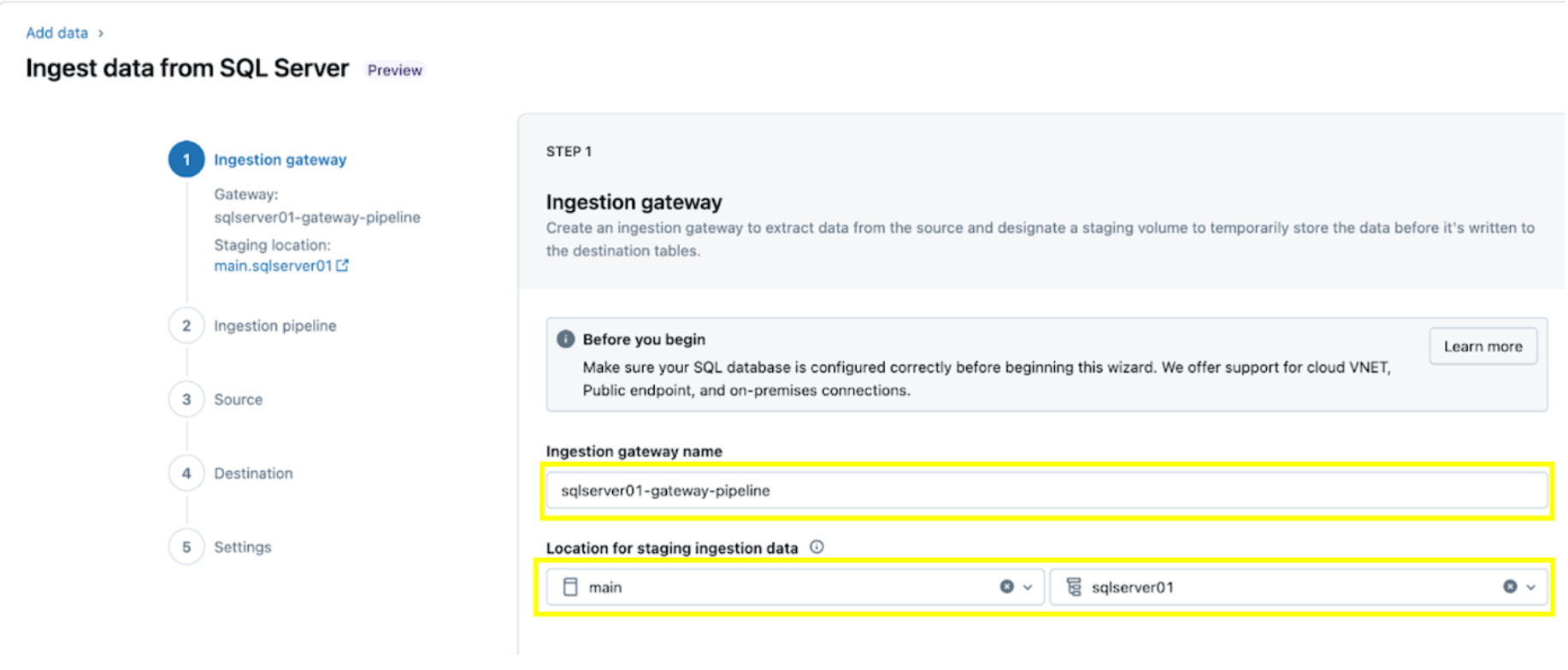
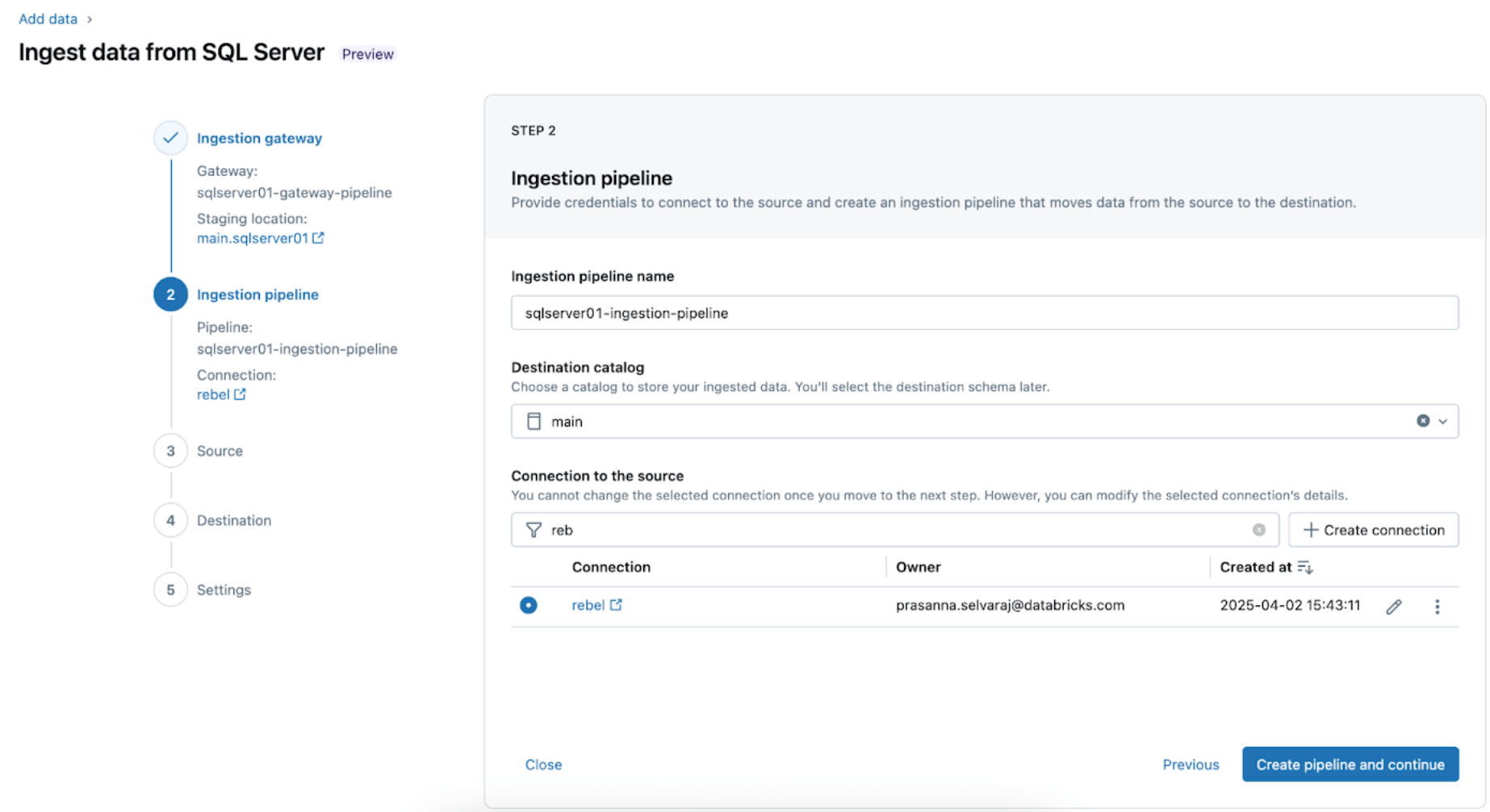
2. Configurez le pipeline d'ingestion. Cela réplique la source de données CDC/CT et les événements d'évolution de schéma. Une connexion SQL Server est requise, qui est créée via l'interface utilisateur en suivant ces étapes ou avec le code SQL suivant ci-dessous :
Pour cet exemple, nommez la connexion SQL Server rebel comme indiqué.
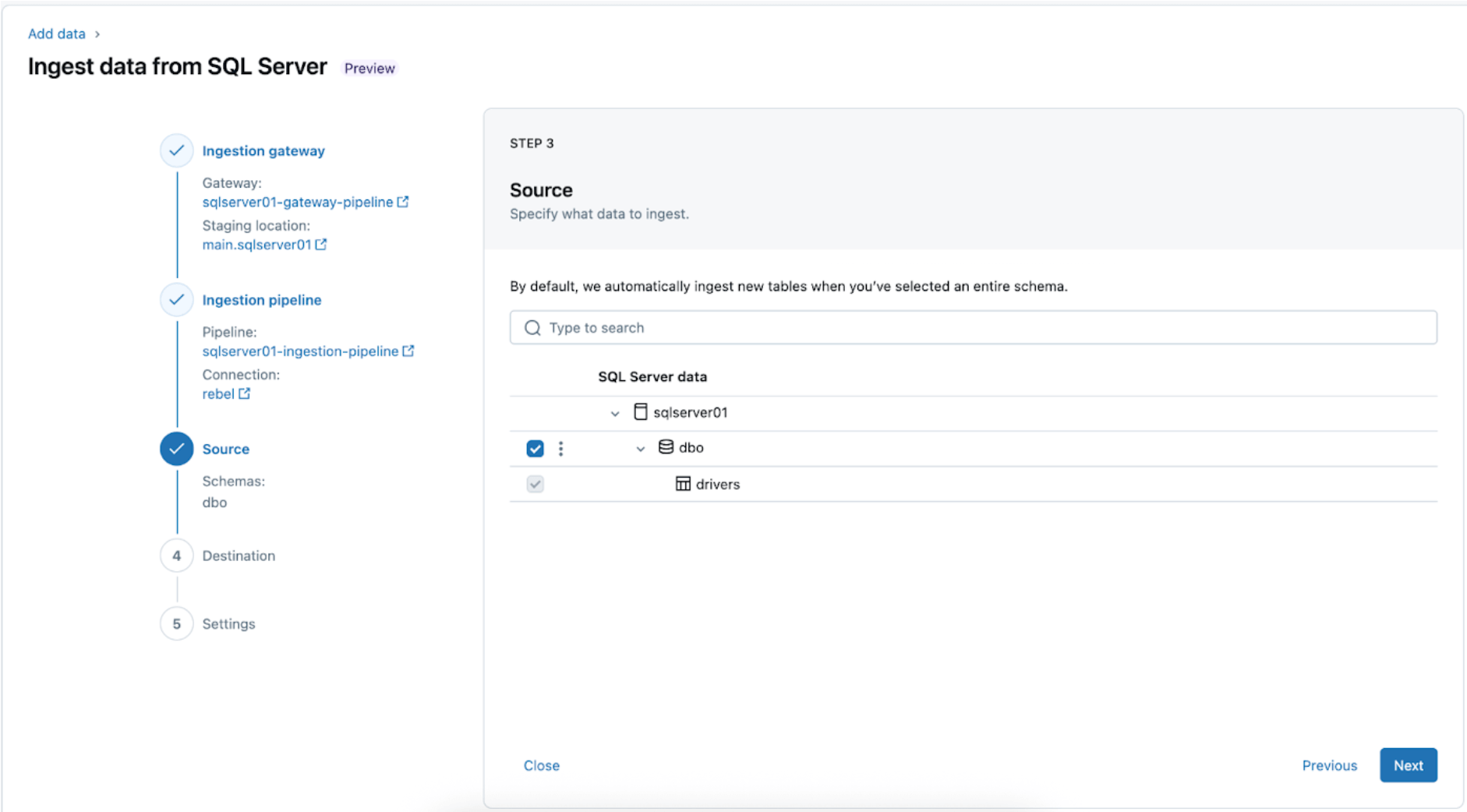
3. Sélection des tables SQL Server à répliquer. Sélectionnez tout le schéma à ingérer dans Databricks au lieu de choisir des tables individuelles à ingérer.
L'ensemble du schéma peut être ingéré dans Databricks lors de l'exploration initiale ou des migrations. Si le schéma est volumineux ou dépasse le nombre autorisé de tables par pipeline (voir les limites du connecteur), Databricks recommande de diviser l'ingestion sur plusieurs pipelines pour maintenir des performances optimales. Pour les flux de travail spécifiques à un cas d'utilisation, tels qu'un seul modèle ML, un tableau de bord ou un rapport, il est généralement plus efficace d'ingérer des tables individuelles adaptées à ce besoin spécifique, plutôt que l'ensemble du schéma.
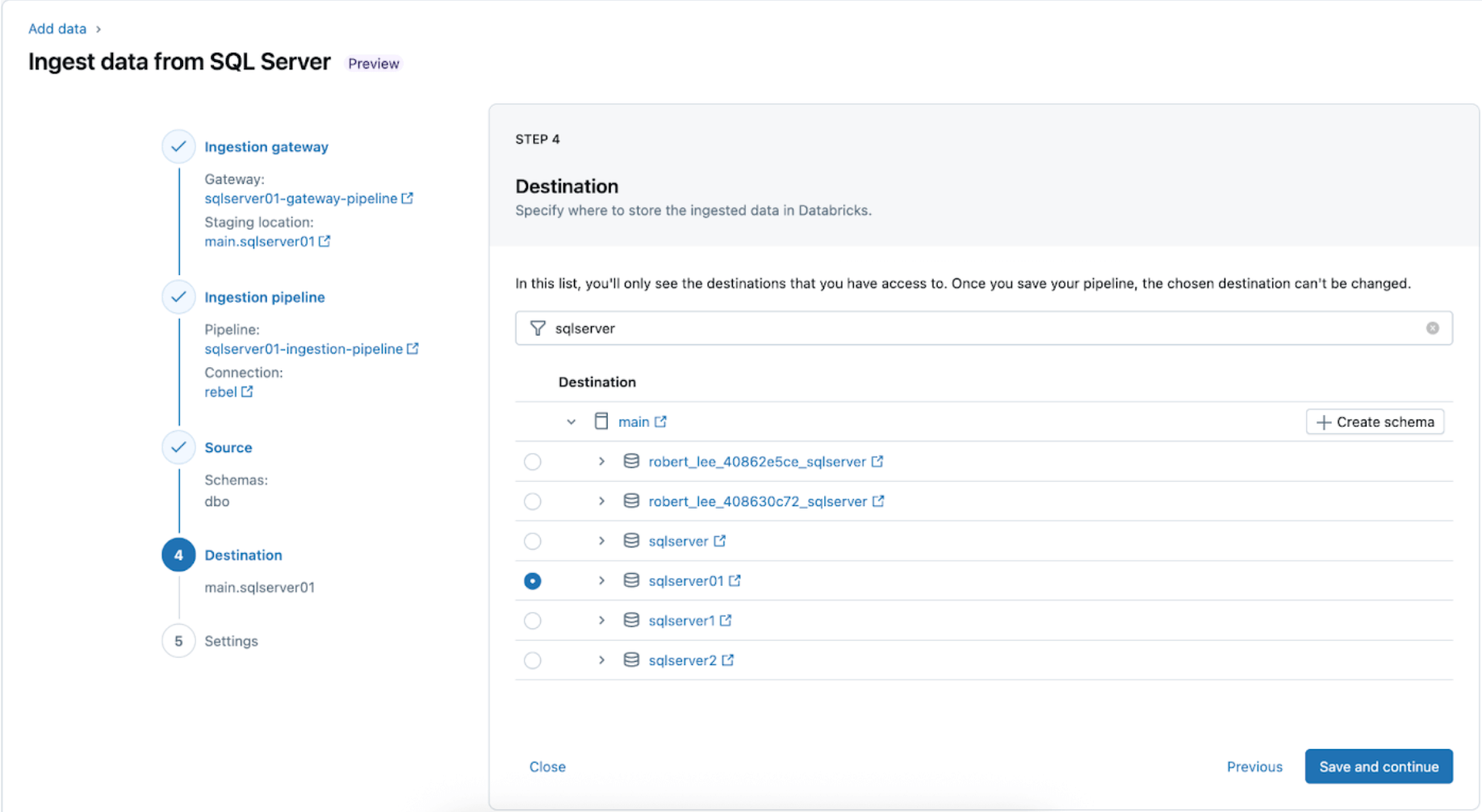
4. Configurez la destination où les tables SQL Server seront répliquées dans UC. Sélectionnez le catalogue main et le schéma sqlserver01 pour déposer les données dans UC.
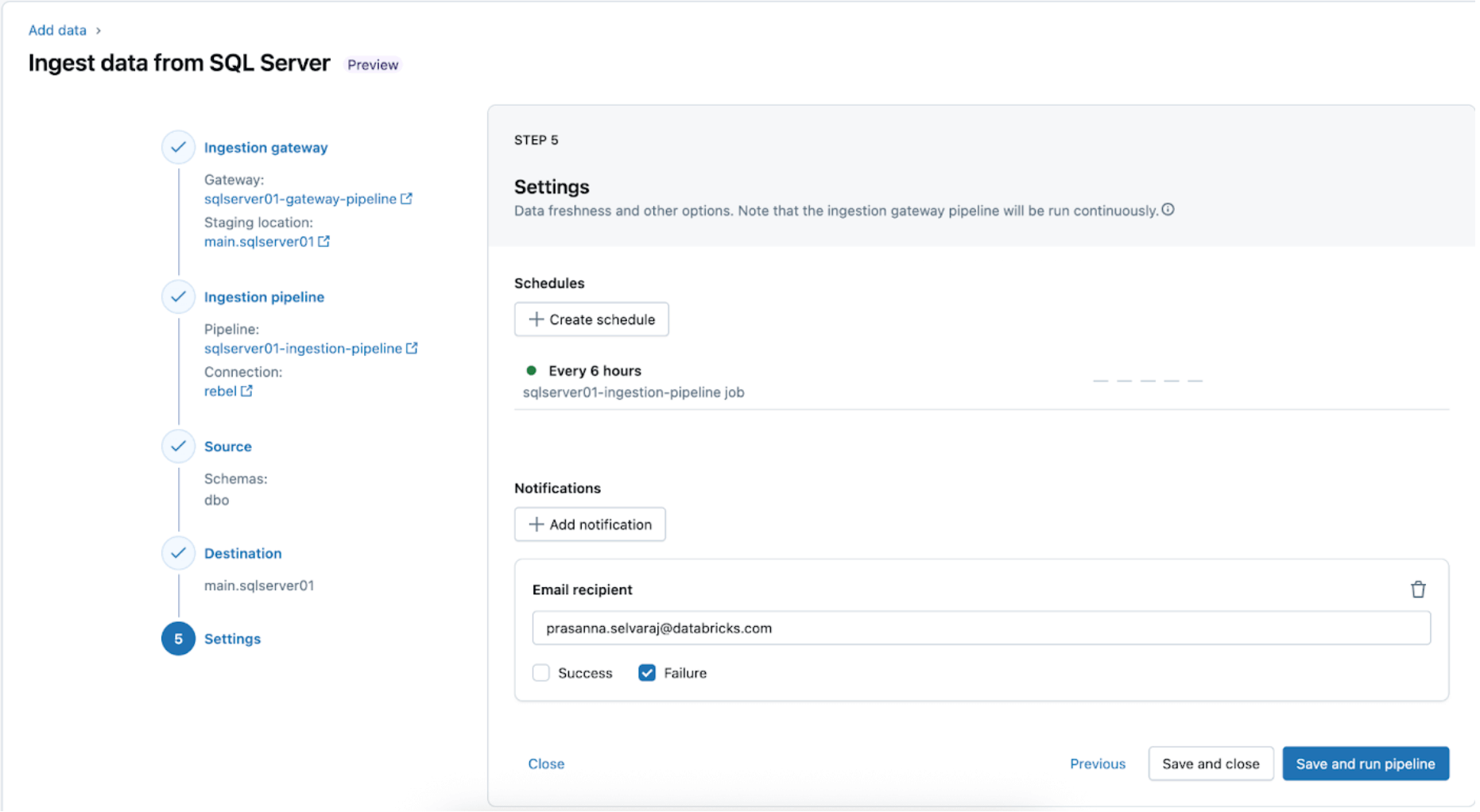
5. Configurez les planifications et les notifications (AWS | Azure | GCP). Cette dernière étape vous aidera à déterminer la fréquence d'exécution du pipeline et où les messages de succès ou d'échec doivent être envoyés. Réglez le pipeline pour qu'il s'exécute toutes les 6 heures et ne notifie l'utilisateur qu'en cas d'échecs du pipeline. Cet intervalle peut être configuré pour répondre aux besoins de votre charge de travail.
Le pipeline d'ingestion peut être déclenché selon une planification personnalisée. Lakeflow Connect créera automatiquement un travail dédié pour chaque déclencheur de pipeline planifié. Le pipeline d'ingestion est une tâche dans le travail. Facultativement, d'autres tâches peuvent être ajoutées avant ou après la tâche d'ingestion pour tout traitement en aval.
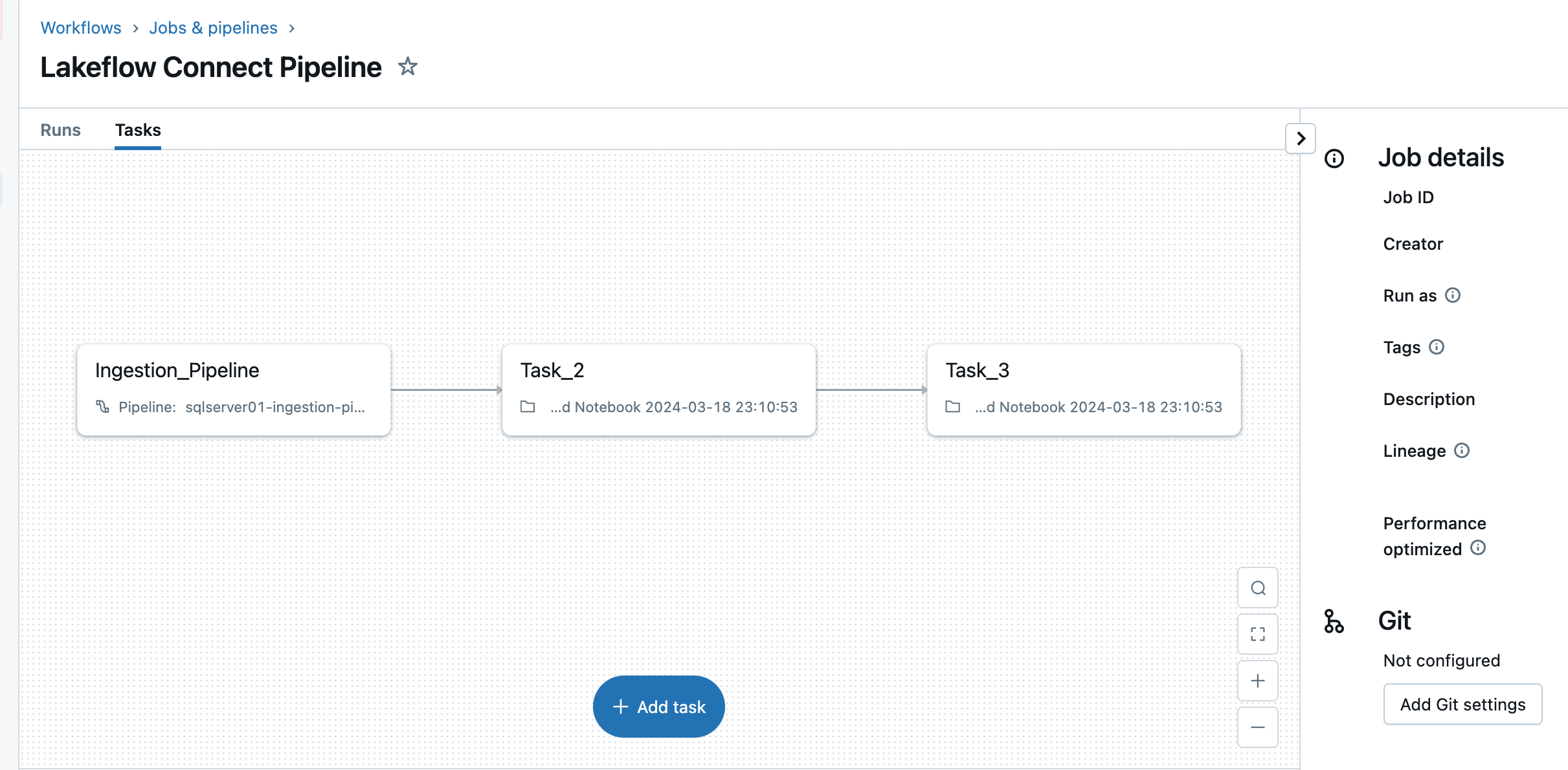
Après cette étape, le pipeline d'ingestion est enregistré et déclenché, commençant un chargement complet des données du SQL Server vers Databricks.
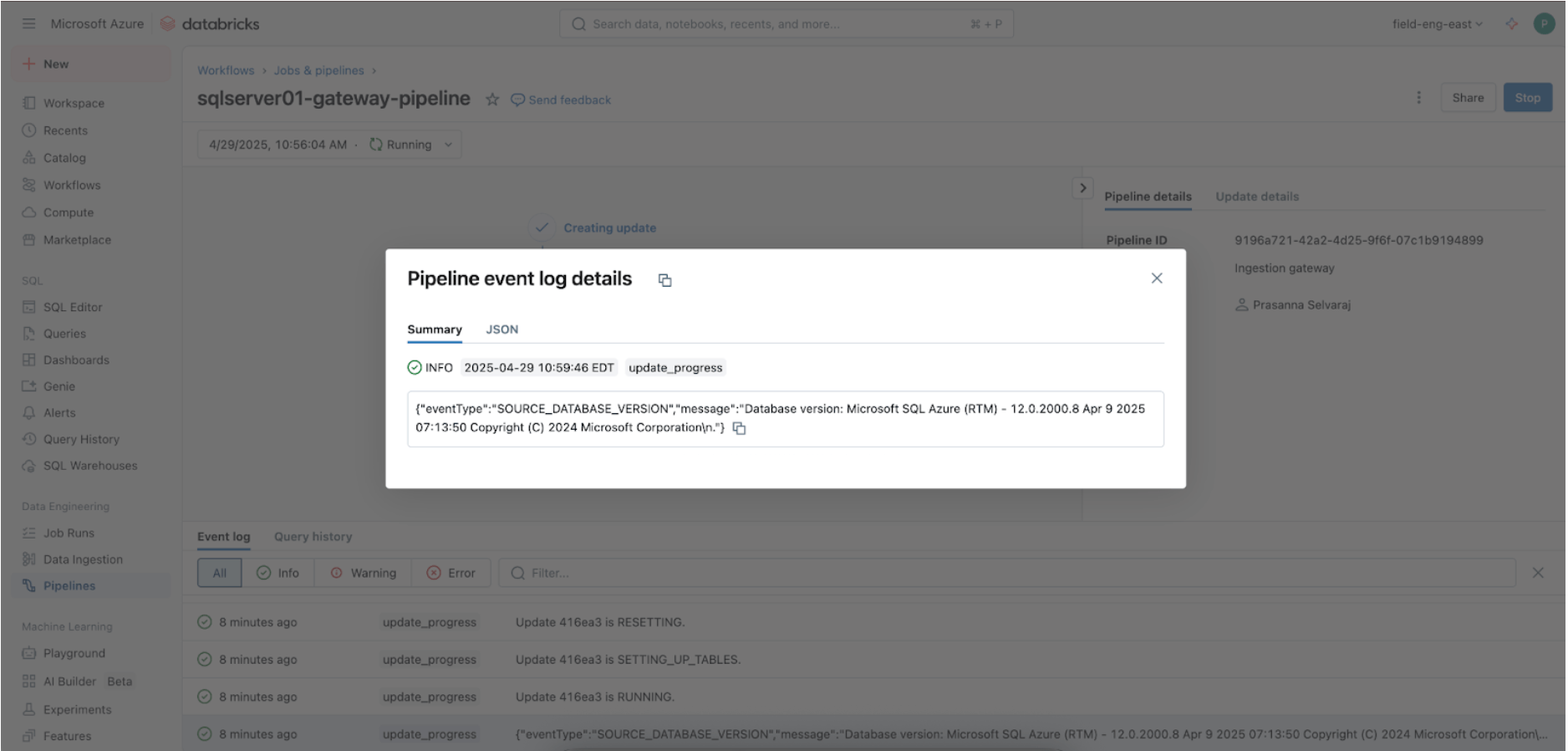
3. [Databricks] Valider les exécutions réussies des pipelines Gateway et d'ingestion
Accédez au menu Pipeline pour vérifier si le pipeline d'ingestion de la passerelle s'exécute. Une fois terminé, recherchez « update_progress » dans l'interface du journal des événements du pipeline dans le volet inférieur pour vous assurer que la passerelle ingère avec succès les données sources.
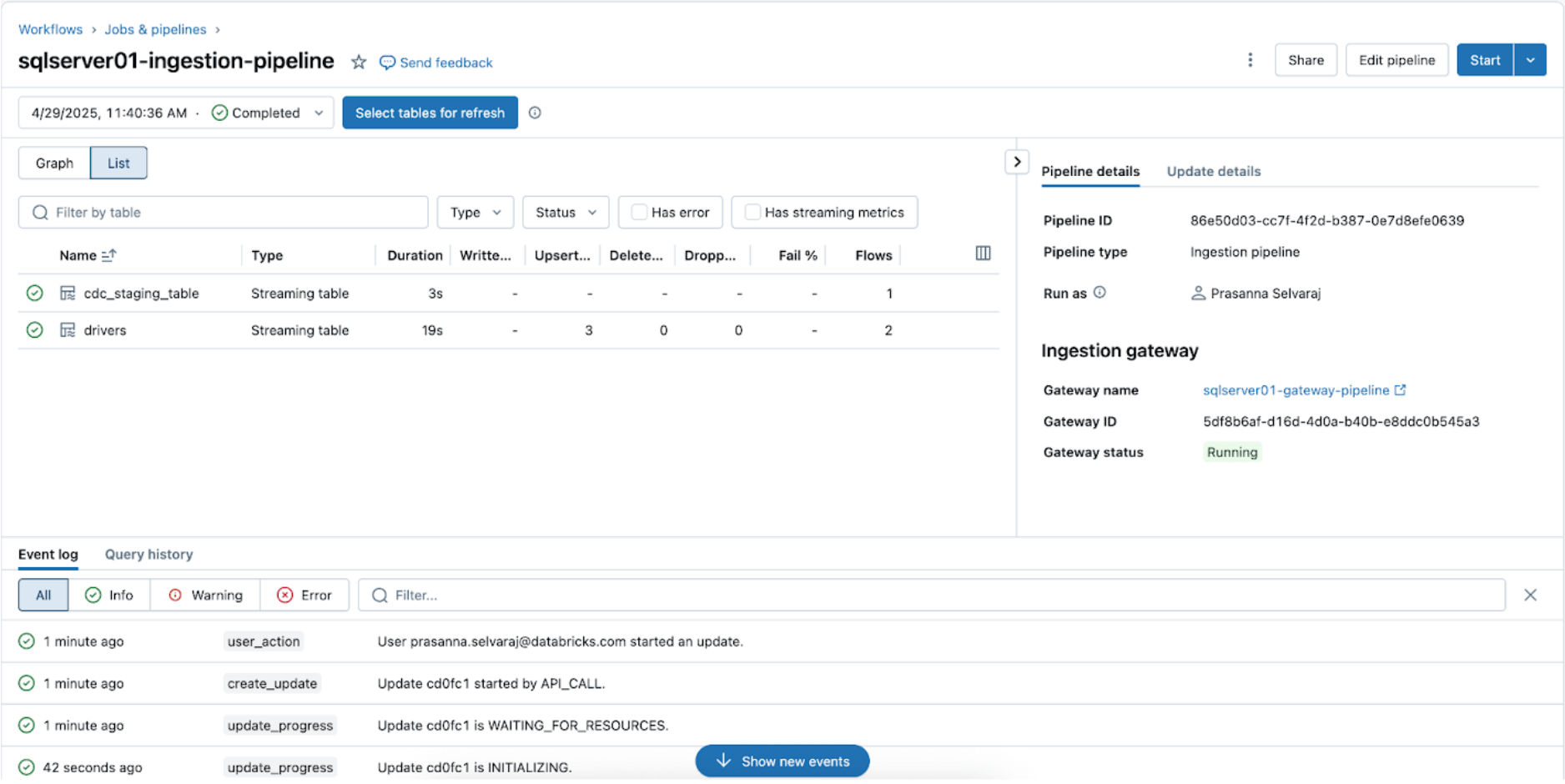
Pour vérifier l'état de la synchronisation, accédez au menu des pipelines. La capture d'écran ci-dessous montre que le pipeline d'ingestion a effectué trois opérations d'insertion et de mise à jour (UPSERT).
Accédez au catalogue cible, main, et au schéma, sqlserver01, pour afficher la table répliquée, comme indiqué ci-dessous.

4. [Databricks] Tester la CDC et l'évolution du schéma
Ensuite, vérifiez un événement CDC en effectuant des opérations d'insertion, de mise à jour et de suppression dans la table source. La capture d'écran ci-dessous du SQL Server Azure illustre les trois événements.
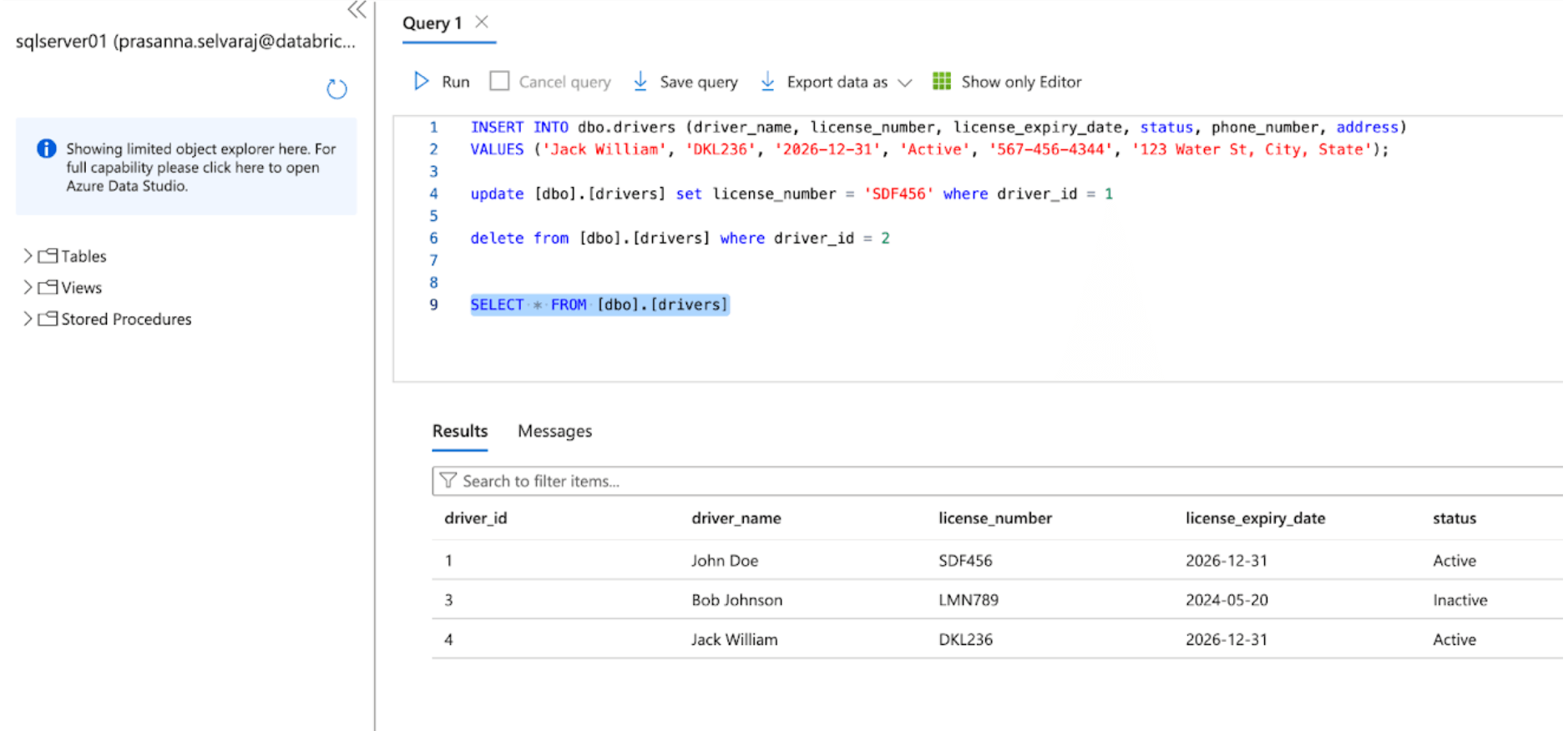
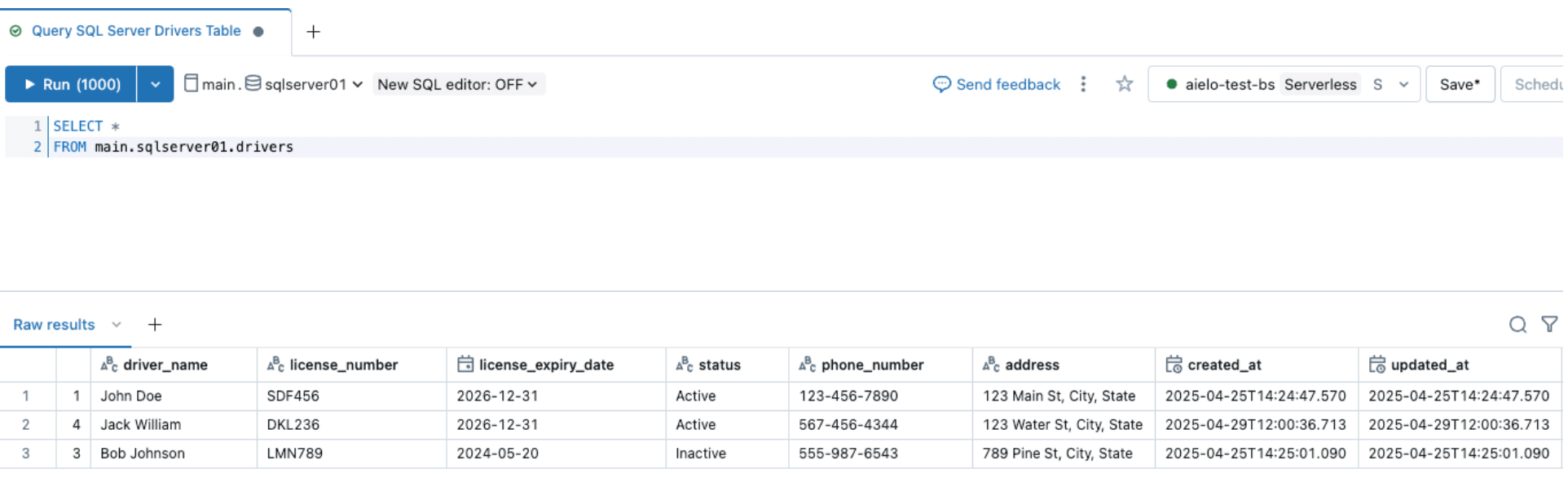
Une fois le pipeline déclenché et terminé, interrogez la table delta sous le schéma cible et vérifiez les modifications.
De même, effectuons un événement d'évolution de schéma et ajoutons une colonne à la table source SQL Server, comme indiqué ci-dessous

Après avoir modifié les sources, déclenchez le pipeline d'ingestion en cliquant sur le bouton de démarrage dans l'interface DLT de Databricks. Une fois le pipeline terminé, vérifiez les modifications en parcourant la table cible, comme indiqué ci-dessous. La nouvelle colonne email sera ajoutée à la fin de la table des pilotes.
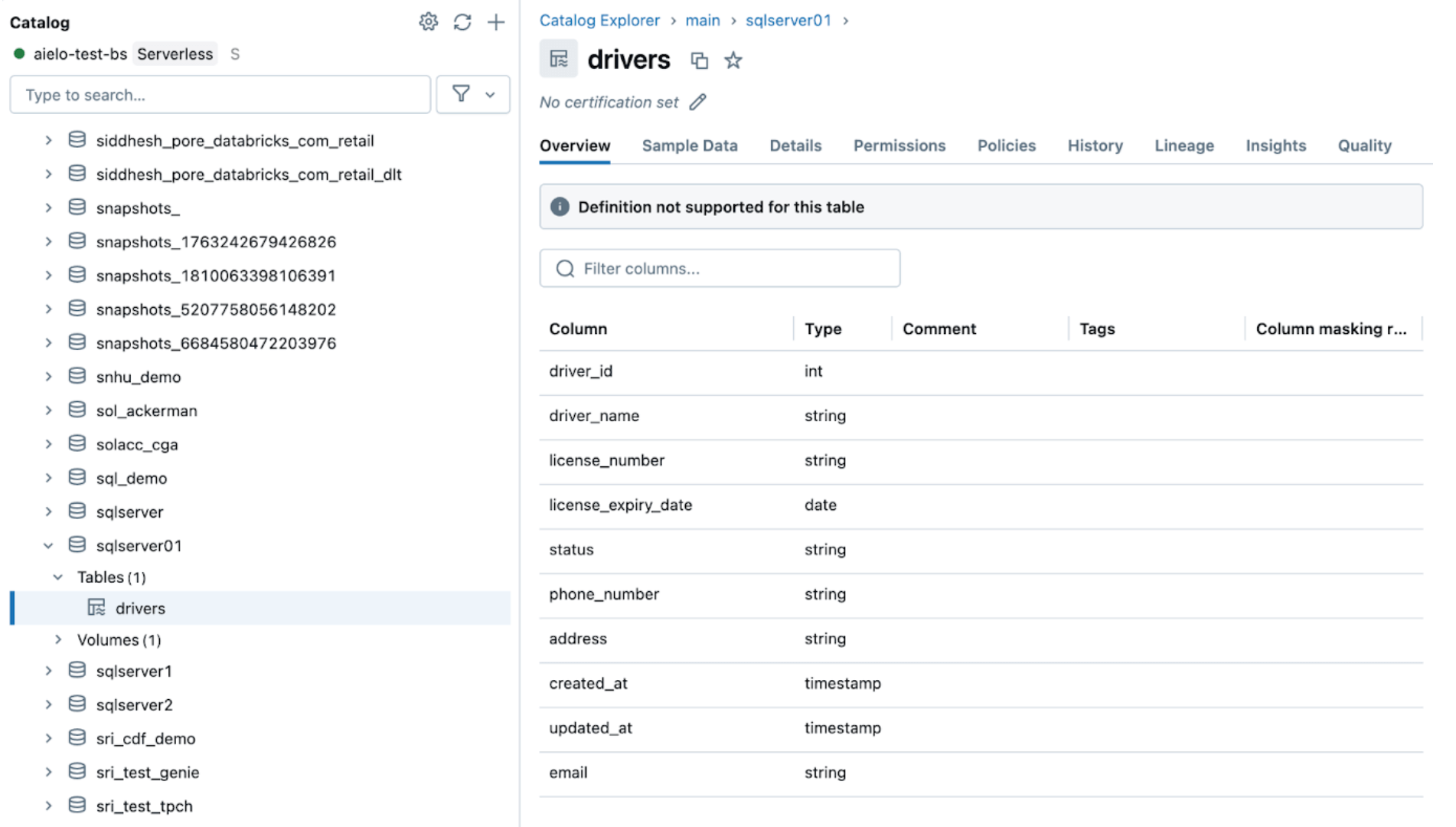
5. [Databricks] Surveillance continue des pipelines
Une fois les pipelines d'ingestion et de passerelle en cours d'exécution, il est essentiel de surveiller leur état et leur comportement. L'interface utilisateur du pipeline fournit des contrôles de qualité des données, la progression du pipeline et des informations sur la lignée des données. Pour afficher les entrées du journal d'événements dans l'interface utilisateur du pipeline, localisez le volet inférieur sous le DAG du pipeline, comme illustré ci-dessous.

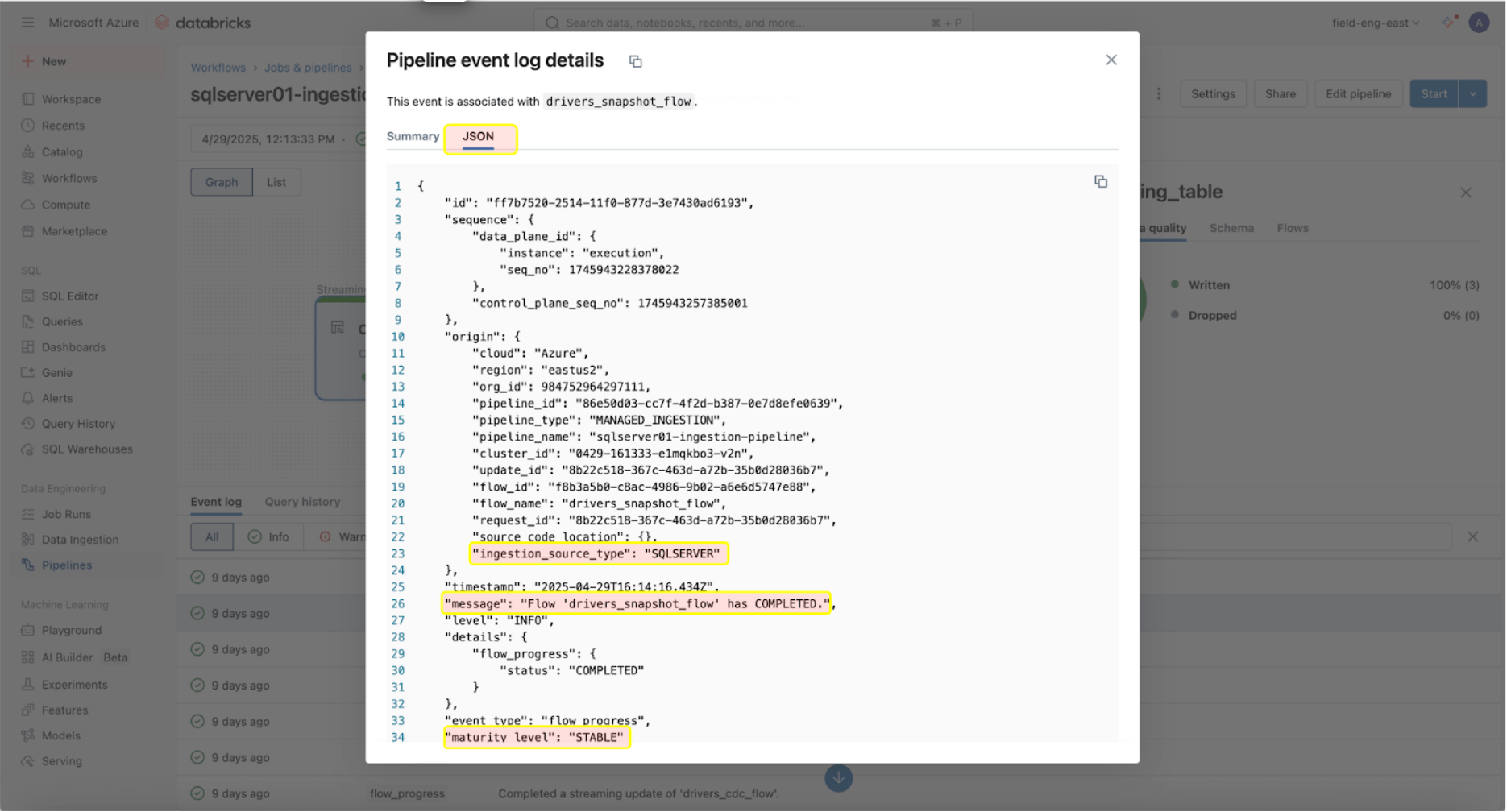
L'entrée du journal d'événements ci-dessus indique que le flux « drives_snapshot_flow » a été ingéré à partir de SQL Server et terminé. Le niveau de maturité STABLE signifie que le schéma est stable et n'a pas changé. Vous trouverez plus d'informations sur le schéma du journal d'événements ici.
Exemple concret
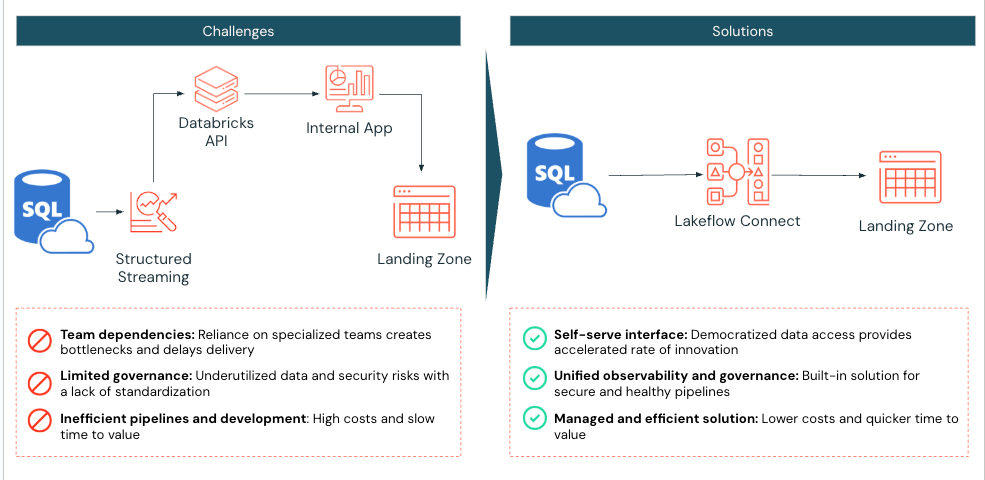
Un laboratoire de diagnostic médical à grande échelle utilisant Databricks a rencontré des difficultés pour ingérer efficacement les données SQL Server dans son lakehouse. Avant de mettre en œuvre Lakeflow Connect, le laboratoire utilisait des notebooks Databricks Spark pour extraire deux tables d'Azure SQL Server vers Databricks. Son application interagissait ensuite avec l'API Databricks pour gérer l'exécution du calcul et des tâches.
Le laboratoire de diagnostic médical a mis en œuvre Lakeflow Connect pour SQL Server, reconnaissant que ce processus pouvait être simplifié. Une fois activée, la mise en œuvre a été achevée en une seule journée, permettant au laboratoire de diagnostic médical de tirer parti des outils intégrés de Databricks pour l'observabilité avec des actualisations d'ingestion incrémentielles quotidiennes.
Considérations opérationnelles
Une fois que le connecteur SQL Server a établi avec succès une connexion à votre base de données Azure SQL, l'étape suivante consiste à planifier efficacement vos pipelines de données pour optimiser les performances et l'utilisation des ressources. De plus, il est essentiel de suivre les meilleures pratiques pour la configuration programmatique des pipelines afin d'assurer la scalabilité et la cohérence entre les environnements.
Orchestration de pipeline
Il n'y a aucune limite à la fréquence à laquelle le pipeline d'ingestion peut être planifié. Cependant, afin de minimiser les coûts et d'assurer la cohérence des exécutions de pipeline sans chevauchement, Databricks recommande un intervalle d'au moins 5 minutes entre les exécutions d'ingestion. Cela permet d'introduire de nouvelles données à la source tout en tenant compte des ressources de calcul et du temps de démarrage.
Le pipeline d'ingestion peut être configuré comme une tâche dans un job. Lorsque les charges de travail en aval dépendent de l'arrivée de données fraîches, les dépendances de tâches peuvent être définies pour garantir que l'exécution du pipeline d'ingestion se termine avant l'exécution des tâches en aval.
De plus, si le pipeline est toujours en cours d'exécution lorsque le prochain rafraîchissement est planifié, le pipeline d'ingestion se comportera de manière similaire à un job et sautera la mise à jour jusqu'à la prochaine planification, en supposant que la mise à jour en cours se termine à temps.
Suivi de l'observabilité et des coûts
Lakeflow Connect fonctionne sur un modèle de tarification basé sur le calcul, garantissant l'efficacité et la scalabilité pour divers besoins d'intégration de données. Le pipeline d'ingestion fonctionne sur un calcul serverless, ce qui permet une flexibilité de mise à l'échelle en fonction de la demande et simplifie la gestion en éliminant le besoin pour les utilisateurs de configurer et de gérer l'infrastructure sous-jacente.
Cependant, il est important de noter que si le pipeline d'ingestion peut s'exécuter sur un calcul serverless, la passerelle d'ingestion pour les connecteurs de base de données fonctionne actuellement sur un calcul classique pour simplifier les connexions à la source de données. Par conséquent, les utilisateurs peuvent voir une combinaison de frais DLT DBU classiques et serverless reflétés dans leur facturation.
Le moyen le plus simple de suivre et de surveiller l'utilisation de Lakeflow Connect est via les tables système. Voici un exemple de requête pour afficher l'utilisation d'un pipeline Lakeflow Connect particulier :

La documentation officielle sur la tarification de Lakeflow Connect (AWS | Azure | GCP) fournit des informations détaillées sur les tarifs. Des coûts supplémentaires, tels que les frais d'egress serverless (tarification), peuvent s'appliquer. Les coûts d'egress du fournisseur Cloud pour le calcul classique se trouvent ici (AWS | Azure | GCP).
Meilleures pratiques et points clés à retenir
En mai 2025, voici quelques-unes des meilleures pratiques et considérations à suivre lors de la mise en œuvre de ce connecteur SQL Server :
- Configurez chaque passerelle d'ingestion pour qu'elle s'authentifie avec un utilisateur ou une entité ayant accès uniquement à la base de données source répliquée.
- Assurez-vous que l'utilisateur dispose des autorisations nécessaires pour créer des connexions dans UC et ingérer les données.
- Utilisez les DAB pour configurer de manière fiable les pipelines d'ingestion Lakeflow Connect, en garantissant la répétabilité et la cohérence de la gestion de l'infrastructure.
- Pour les tables sources avec des clés primaires, activez le suivi des modifications pour obtenir une surcharge réduite et des performances améliorées.
- Pour les tables sources sans clé primaire, activez la CDC en raison de sa capacité à capturer les modifications au niveau des colonnes, même sans identifiants de ligne uniques.
Lakeflow Connect pour SQL Server fournit une intégration entièrement gérée et intégrée pour les bases de données sur site et cloud, permettant une ingestion incrémentielle efficace dans Databricks.
Prochaines étapes et ressources supplémentaires
Essayez le connecteur SQL Server dès aujourd'hui pour résoudre vos défis d'ingestion de données. Suivez les étapes décrites dans ce blog ou consultez la documentation. Apprenez-en davantage sur Lakeflow Connect sur la page produit, consultez une visite guidée du produit ou regardez une démonstration du connecteur Salesforce pour aider à prédire le churn client.
Les architectes de solutions de livraison (DSA) Databricks accélèrent les initiatives de données et d'IA au sein des organisations. Ils fournissent un leadership architectural, optimisent les plateformes pour le coût et les performances, améliorent l'expérience des développeurs et pilotent l'exécution réussie des projets. Les DSA comblent le fossé entre le déploiement initial et les solutions de qualité de production, en travaillant en étroite collaboration avec diverses équipes, y compris l'ingénierie des données, les chefs techniques, les cadres et d'autres parties prenantes pour assurer des solutions sur mesure et une valeur plus rapide. Pour bénéficier d'un plan d'exécution personnalisé, de conseils stratégiques et d'un soutien tout au long de votre parcours de données et d'IA de la part d'un DSA, veuillez contacter votre équipe de compte Databricks.
Annexe
Dans cette étape facultative, pour gérer les pipelines Lakeflow Connect en tant que code à l'aide de DAB, il vous suffit d'ajouter deux fichiers à votre bundle existant :
- Un fichier de workflow qui contrôle la fréquence d'ingestion des données (resources/sqlserver.yml).
- Un fichier de définition de pipeline (resources/sqlserver_pipeline.yml).
resources/sqlserver.yml :
resources/sqlserver_job.yml:
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.