Ingénierie des performances d'inférence LLM : Bonnes pratiques
par Megha Agarwal, Asfandyar Qureshi, Nikhil Sardana, Linden Li, Julian Quevedo et Daya Khudia
Dans cet article de blog, l'équipe d'ingénierie de MosaicML partage les meilleures pratiques pour tirer parti des grands modèles de langage (LLM) open source populaires pour une utilisation en production. Nous fournissons également des directives pour le déploiement de services d'inférence construits autour de ces modèles afin d'aider les utilisateurs dans leur sélection de modèles et de matériel de déploiement. Nous avons travaillé avec plusieurs backends basés sur PyTorch en production ; ces directives sont tirées de notre expérience avec FasterTransformers, vLLM, le futur TensorRT-LLM de NVIDIA, et d'autres.
Comprendre la génération de texte par les LLM
Les grands modèles de langage (LLM) génèrent du texte en deux étapes : le « préremplissage », où les jetons de l'invite d'entrée sont traités en parallèle, et le « décodage », où le texte est généré un « jeton » à la fois de manière autorégressive. Chaque jeton généré est ajouté à l'entrée et renvoyé au modèle pour générer le jeton suivant. La génération s'arrête lorsque le LLM émet un jeton d'arrêt spécial ou lorsqu'une condition définie par l'utilisateur est remplie (par exemple, un nombre maximum de jetons a été généré). Si vous souhaitez en savoir plus sur la façon dont les LLM utilisent les blocs décodeurs, consultez cet article de blog.
Les jetons peuvent être des mots ou des sous-mots ; les règles exactes pour diviser le texte en jetons varient d'un modèle à l'autre. Par exemple, vous pouvez comparer la façon dont les modèles Llama tokenisent le texte à la façon dont les modèles OpenAI tokenisent le texte. Bien que les fournisseurs d'inférence LLM parlent souvent de performances en métriques basées sur les jetons (par exemple, jetons/seconde), ces chiffres ne sont pas toujours comparables entre les types de modèles étant donné ces variations. À titre d'exemple concret, l'équipe d'Anyscale a constaté que la tokenisation de Llama 2 est 19 % plus longue que celle de ChatGPT (mais a toujours un coût global beaucoup plus bas). Et des chercheurs de HuggingFace ont également constaté que Llama 2 nécessitait environ 20 % de jetons en plus pour s'entraîner sur la même quantité de texte que GPT-4.
Métriques importantes pour le service LLM
Alors, comment exactement devrions-nous penser à la vitesse d'inférence ?
Notre équipe utilise quatre métriques clés pour le service LLM :
- Temps jusqu'au premier jeton (TTFT) : La rapidité avec laquelle les utilisateurs commencent à voir la sortie du modèle après avoir entré leur requête. Des temps d'attente courts pour une réponse sont essentiels dans les interactions en temps réel, mais moins importants dans les charges de travail hors ligne. Cette métrique est déterminée par le temps nécessaire pour traiter l'invite, puis générer le premier jeton de sortie.
- Temps par jeton de sortie (TPOT) : Temps nécessaire pour générer un jeton de sortie pour chaque utilisateur qui interroge notre système. Cette métrique correspond à la façon dont chaque utilisateur percevra la « vitesse » du modèle. Par exemple, un TPOT de 100 millisecondes/jeton équivaudrait à 10 jetons par seconde par utilisateur, soit environ 450 mots par minute, ce qui est plus rapide qu'une personne ne peut lire normalement.
- Latence : Le temps total nécessaire au modèle pour générer la réponse complète pour un utilisateur. La latence globale de la réponse peut être calculée à l'aide des deux métriques précédentes : latence = (TTFT) + (TPOT) * (nombre de jetons à générer).
- Débit : Le nombre de jetons de sortie par seconde qu'un serveur d'inférence peut générer pour tous les utilisateurs et toutes les requêtes.
Notre objectif ? Le temps le plus rapide jusqu'au premier jeton, le débit le plus élevé et le temps le plus rapide par jeton de sortie. En d'autres termes, nous voulons que nos modèles génèrent du texte aussi rapidement que possible pour le plus grand nombre d'utilisateurs que nous pouvons prendre en charge.
Notamment, il existe un compromis entre le débit et le temps par jeton de sortie : si nous traitons 16 requêtes d'utilisateurs simultanément, nous aurons un débit plus élevé par rapport à l'exécution séquentielle des requêtes, mais nous prendrons plus de temps pour générer les jetons de sortie pour chaque utilisateur.
Si vous avez des objectifs de latence d'inférence globaux, voici quelques heuristiques utiles pour évaluer les modèles :
- La longueur de sortie domine la latence globale de la réponse : Pour la latence moyenne, vous pouvez généralement prendre votre longueur de jeton de sortie attendue/maximale et la multiplier par un temps moyen global par jeton de sortie pour le modèle.
- La longueur d'entrée n'est pas significative pour les performances mais importante pour les exigences matérielles : L'ajout de 512 jetons d'entrée augmente la latence moins que la production de 8 jetons de sortie supplémentaires dans les modèles MPT. Cependant, la nécessité de prendre en charge de longues entrées peut rendre les modèles plus difficiles à servir. Par exemple, nous recommandons d'utiliser l'A100-80 Go (ou plus récent) pour servir MPT-7B avec sa longueur de contexte maximale de 2048 jetons.
- La latence globale évolue de manière sous-linéaire avec la taille du modèle : Sur le même matériel, les modèles plus grands sont plus lents, mais le rapport de vitesse ne correspondra pas nécessairement au rapport du nombre de paramètres. La latence de MPT-30B est d'environ 2,5 fois celle de MPT-7B. La latence de Llama2-70B est d'environ 2 fois celle de Llama2-13B.
On nous demande souvent par des clients potentiels de fournir une latence d'inférence moyenne. Nous recommandons qu'avant de vous fixer des objectifs de latence spécifiques (« nous avons besoin de moins de 20 ms par jeton »), vous passiez du temps à caractériser vos longueurs d'entrée attendues et vos longueurs de sortie souhaitées.
Défis de l'inférence LLM
L'optimisation de l'inférence LLM bénéficie de techniques générales telles que :
- Fusion d'opérateurs : La combinaison de différents opérateurs adjacents entraîne souvent une meilleure latence.
- Quantification : Les activations et les poids sont compressés pour utiliser un plus petit nombre de bits.
- Compression : Sparsité ou Distillation.
- Parallélisation : Parallélisme tensoriel sur plusieurs appareils ou parallélisme de pipeline pour les modèles plus grands.
Au-delà de ces méthodes, il existe de nombreuses optimisations importantes spécifiques aux Transformers. Un excellent exemple est la mise en cache KV (clé-valeur). Le mécanisme d'Attention dans les modèles basés sur des Transformers uniquement décodeurs est coûteux en calcul. Chaque jeton assiste à tous les jetons précédemment vus, et recalcule donc de nombreuses mêmes valeurs à chaque nouveau jeton généré. Par exemple, lors de la génération du N-ième jeton, le (N-1)-ième jeton assiste aux jetons (N-2), (N-3)... 1er. De même, lors de la génération du (N+1)-ième jeton, l'attention pour le N-ième jeton doit à nouveau examiner les jetons (N-1), (N-2), (N-3)... 1er. La mise en cache KV, c'est-à-dire la sauvegarde des clés/valeurs intermédiaires pour les couches d'attention, est utilisée pour préserver ces résultats pour une réutilisation ultérieure, évitant ainsi les calculs répétés.
La bande passante mémoire est essentielle
Les calculs dans les LLM sont principalement dominés par des opérations de multiplication matrice-matrice ; ces opérations avec de petites dimensions sont généralement limitées par la bande passante mémoire sur la plupart des matériels. Lors de la génération de jetons de manière autorégressive, l'une des dimensions de la matrice d'activation (définie par la taille du lot et le nombre de jetons dans la séquence) est petite pour les petites tailles de lot. Par conséquent, la vitesse dépend de la rapidité avec laquelle nous pouvons charger les paramètres du modèle depuis la mémoire GPU vers les caches/registres locaux, plutôt que de la rapidité avec laquelle nous pouvons calculer sur les données chargées. La bande passante mémoire disponible et atteinte dans le matériel d'inférence est un meilleur prédicteur de la vitesse de génération des jetons que leurs performances de calcul maximales.
L'utilisation du matériel d'inférence est très importante en termes de coûts de service. Les GPU sont coûteux et nous avons besoin qu'ils effectuent autant de travail que possible. Les services d'inférence partagés promettent de maintenir les coûts bas en combinant les charges de travail de nombreux utilisateurs, en comblant les lacunes individuelles et en regroupant les requêtes qui se chevauchent. Pour les grands modèles comme Llama2-70B, nous n'obtenons un bon rapport coût/performance qu'à des tailles de lot importantes. Disposer d'un système de service d'inférence capable de fonctionner avec de grandes tailles de lot est essentiel pour l'efficacité des coûts. Cependant, un grand lot signifie une taille de cache KV plus grande, ce qui augmente à son tour le nombre de GPU requis pour servir le modèle. Il y a un jeu du tir à la corde ici et les opérateurs de services partagés doivent faire des compromis sur les coûts et implémenter des optimisations système.
Utilisation de la bande passante du modèle (MBU)
Dans quelle mesure un serveur d'inférence LLM est-il optimisé ?
Comme expliqué brièvement précédemment, l'inférence pour les LLM avec de petites tailles de lot — en particulier au moment du décodage — est limitée par la rapidité avec laquelle nous pouvons charger les paramètres du modèle depuis la mémoire de l'appareil vers les unités de calcul. La bande passante mémoire dicte la rapidité des transferts de données. Pour mesurer l'utilisation du matériel sous-jacent, nous introduisons une nouvelle métrique appelée Utilisation de la bande passante du modèle (MBU). La MBU est définie comme (bande passante mémoire atteinte) / (bande passante mémoire maximale) où la bande passante mémoire atteinte est ((taille totale des paramètres du modèle + taille du cache KV) / TPOT).
Par exemple, si un modèle de 7 milliards de paramètres fonctionnant avec une précision de 16 bits a un TPOT de 14 ms, cela signifie qu'il déplace 14 Go de paramètres en 14 ms, ce qui se traduit par une utilisation de la bande passante de 1 To/sec. Si la bande passante de pointe de la machine est de 2 To/sec, nous fonctionnons à un MBU de 50 %. Pour simplifier, cet exemple ignore la taille du cache KV, qui est faible pour les tailles de lot plus petites et les longueurs de séquence plus courtes. Les valeurs MBU proches de 100 % impliquent que le système d'inférence utilise efficacement la bande passante mémoire disponible. Le MBU est également utile pour comparer différents systèmes d'inférence (matériel + logiciel) de manière normalisée. Le MBU complète la métrique MFU (Model Flops Utilization ; introduite dans l'article PaLM) qui est importante dans les scénarios limités par le calcul.
La figure 1 montre une représentation picturale du MBU dans un graphique similaire à un graphique de toit (roofline plot). La ligne inclinée continue de la région ombrée en orange montre le débit maximal possible si la bande passante mémoire est entièrement saturée à 100 %. Cependant, en réalité, pour les petites tailles de lot (point blanc), les performances observées sont inférieures au maximum – la mesure de cette différence est le MBU. Pour les grandes tailles de lot (région jaune), le système est limité par le calcul, et le débit atteint en fraction du débit maximal possible est mesuré comme le MFU (Model Flops Utilization).
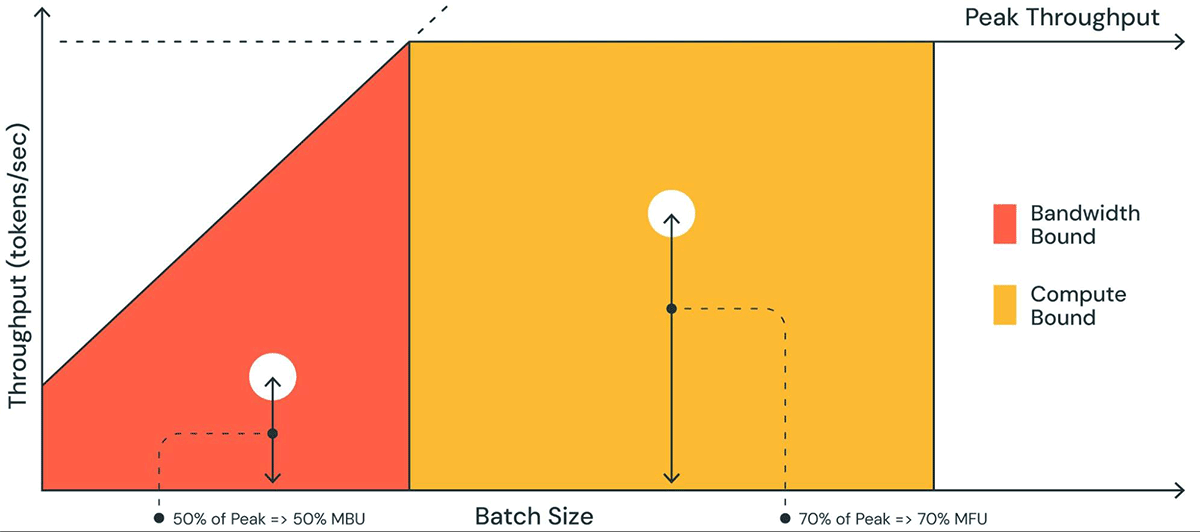
Le MBU et le MFU déterminent l'espace disponible pour accélérer davantage l'inférence sur une configuration matérielle donnée. La figure 2 montre le MBU mesuré pour différents degrés de parallélisme tensoriel avec notre serveur d'inférence basé sur TensorRT-LLM. L'utilisation maximale de la bande passante mémoire est atteinte lors du transfert de gros blocs de mémoire contigus. Lorsque des modèles plus petits comme MPT-7B sont distribués sur plusieurs GPU, nous observons un MBU plus faible car nous déplaçons des blocs de mémoire plus petits sur chaque GPU.
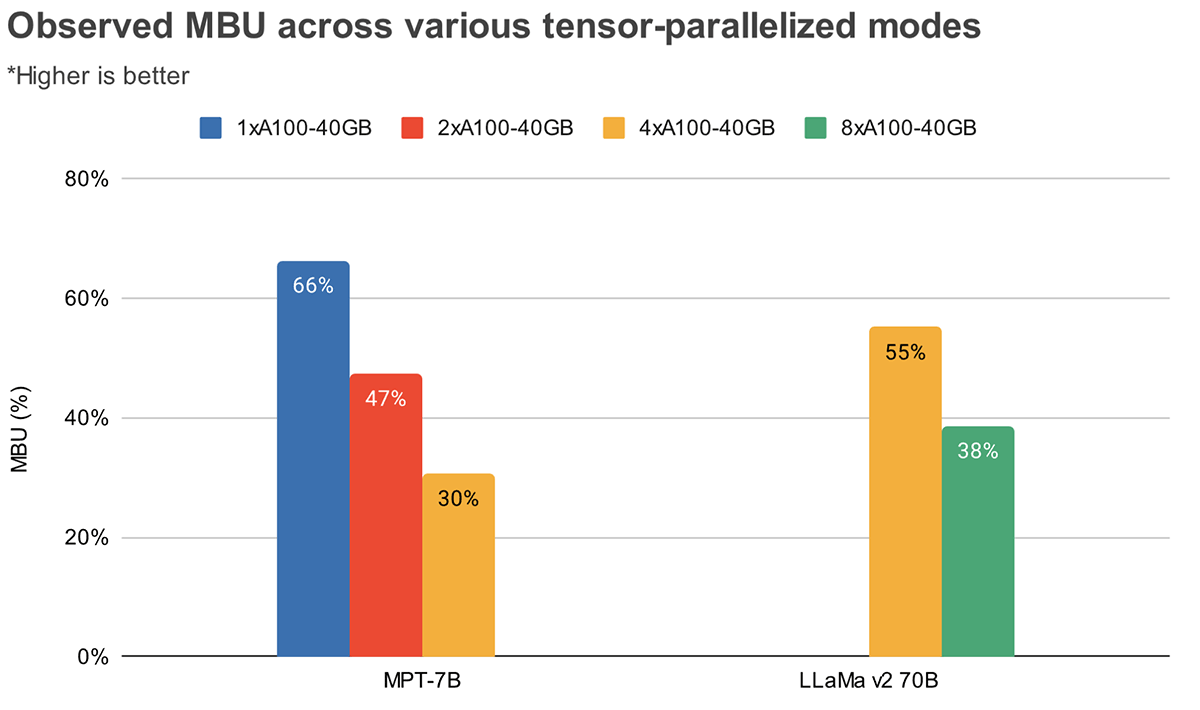
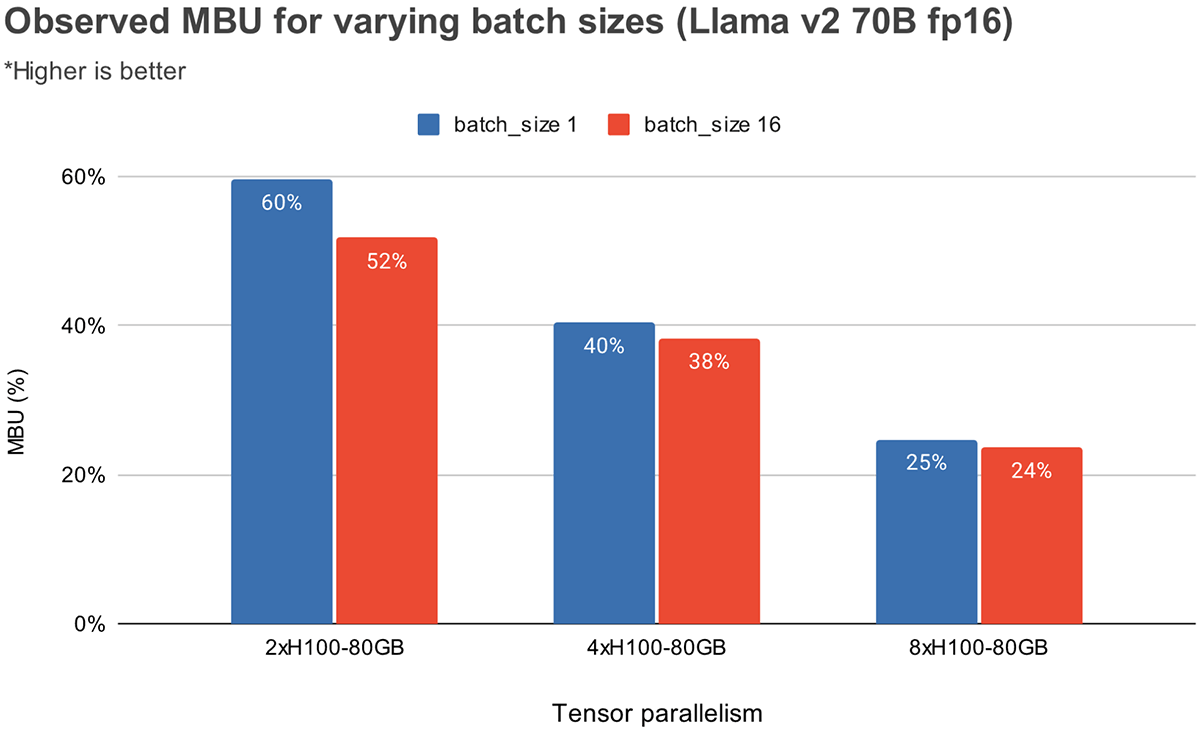
La figure 3 montre le MBU observé empiriquement pour différents degrés de parallélisme tensoriel et différentes tailles de lot sur les GPU NVIDIA H100. Le MBU diminue à mesure que la taille du lot augmente. Cependant, lorsque nous augmentons le nombre de GPU, la diminution relative du MBU est moins significative. Il convient également de noter que le choix de matériel avec une bande passante mémoire plus élevée peut améliorer les performances avec moins de GPU. À une taille de lot de 1, nous pouvons atteindre un MBU plus élevé de 60 % sur 2xH100-80 Go par rapport à 55 % sur 4xA100-40 Go (Figure 2).
Résultats de benchmark
Latence
Nous avons mesuré le temps du premier token (TTFT) et le temps par token de sortie (TPOT) pour différents degrés de parallélisme tensoriel pour les modèles MPT-7B et Llama2-70B. À mesure que les invites d'entrée s'allongent, le temps de génération du premier token commence à consommer une part substantielle de la latence totale. La parallélisation tensorielle sur plusieurs GPU aide à réduire cette latence.
Contrairement à l'entraînement de modèles, la mise à l'échelle vers plus de GPU offre des rendements décroissants significatifs pour la latence d'inférence. Par exemple, pour Llama2-70B, passer de 4x à 8x GPU ne diminue la latence que de 0,7x pour de petites tailles de lot. Une raison à cela est que le parallélisme plus élevé a un MBU plus faible (comme discuté précédemment). Une autre raison est que le parallélisme tensoriel introduit une surcharge de communication entre les nœuds GPU.
| Temps du premier token (ms) | ||||
|---|---|---|---|---|
| Modèle | 1xA100-40Go | 2xA100-40Go | 4xA100-40Go | 8xA100-40Go |
| MPT-7B | 46 (1x) | 34 (0,73x) | 26 (0,56x) | - |
| Llama2-70B | Ne rentre pas | 154 (1x) | 114 (0,74x) | |
Tableau 1 : Temps du premier token pour des requêtes d'entrée de 512 tokens de longueur avec une taille de lot de 1. Les modèles plus grands comme Llama2 70B nécessitent au moins 4 GPU A100-40B pour tenir en mémoire
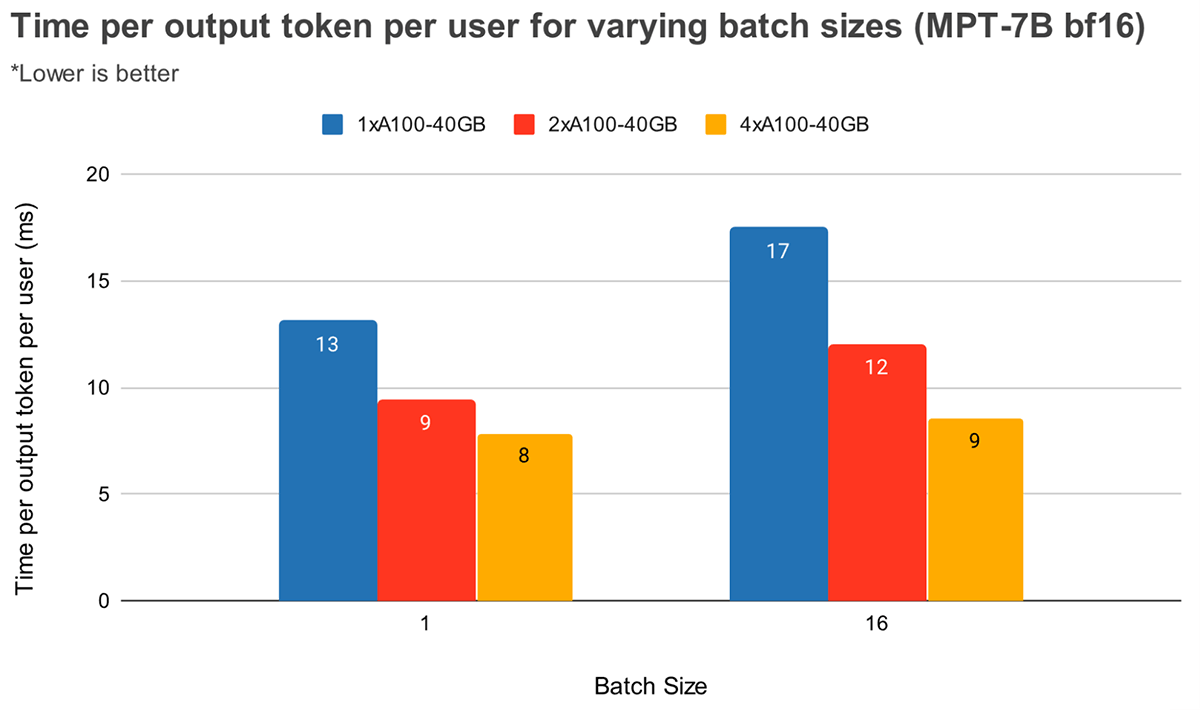
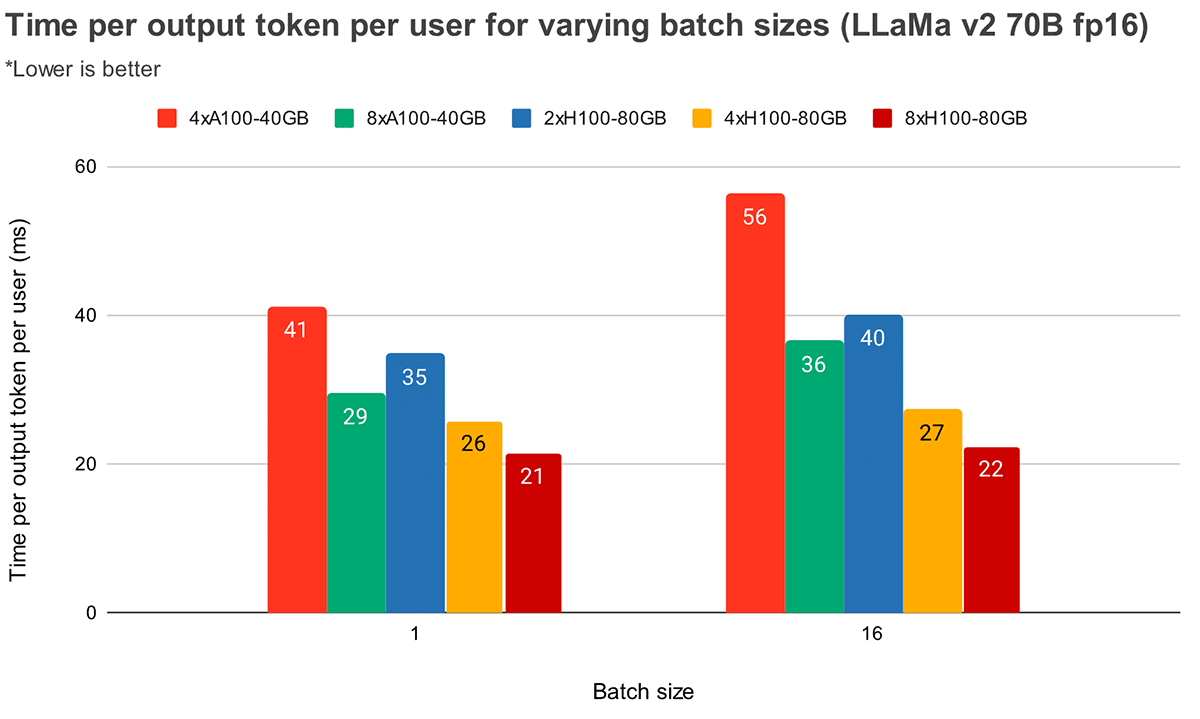
Pour les tailles de lot plus importantes, un parallélisme tensoriel plus élevé entraîne une diminution relative plus significative de la latence par token. La figure 4 montre comment le temps par token de sortie varie pour MPT-7B. Pour une taille de lot de 1, passer de 2x à 4x ne réduit la latence des tokens que d'environ 12 %. Pour une taille de lot de 16, la latence avec 4x est 33 % plus faible qu'avec 2x. Cela correspond à notre observation précédente selon laquelle la diminution relative du MBU est plus faible pour des degrés de parallélisme tensoriel plus élevés pour une taille de lot de 16 par rapport à une taille de lot de 1.
La figure 5 montre des résultats similaires pour Llama2-70B, sauf que l'amélioration relative entre 4x et 8x est moins prononcée. Nous comparons également la mise à l'échelle des GPU sur deux matériels différents. Parce que H100-80 Go a une bande passante mémoire GPU 2,15 fois supérieure à celle de A100-40 Go, nous pouvons voir que la latence est 36 % plus faible à une taille de lot de 1 et 52 % plus faible à une taille de lot de 16 pour les systèmes 4x.
Débit
Nous pouvons échanger le débit et le temps par token en regroupant les requêtes. Le regroupement des requêtes pendant l'évaluation GPU augmente le débit par rapport au traitement séquentiel des requêtes, mais chaque requête prendra plus de temps à se terminer (en ignorant les effets de mise en file d'attente).
Il existe plusieurs techniques courantes pour le traitement par lots des requêtes d'inférence :
- Batching statique : Le client regroupe plusieurs invites dans des requêtes et une réponse est renvoyée une fois que toutes les séquences du lot ont été terminées. Nos serveurs d'inférence prennent en charge cela mais ne l'exigent pas.
- Batching dynamique : Les invites sont regroupées à la volée à l'intérieur du serveur. Généralement, cette méthode est moins performante que le batching statique, mais peut s'en approcher si les réponses sont courtes ou de longueur uniforme. Ne fonctionne pas bien lorsque les requêtes ont des paramètres différents.
- Batching continu : L'idée de regrouper les requêtes au fur et à mesure de leur arrivée a été introduite dans cet excellent article et constitue actuellement la méthode SOTA. Au lieu d'attendre que toutes les séquences d'un lot se terminent, elle regroupe les séquences au niveau de l'itération. Elle peut atteindre un débit 10 à 20 fois supérieur au batching dynamique.
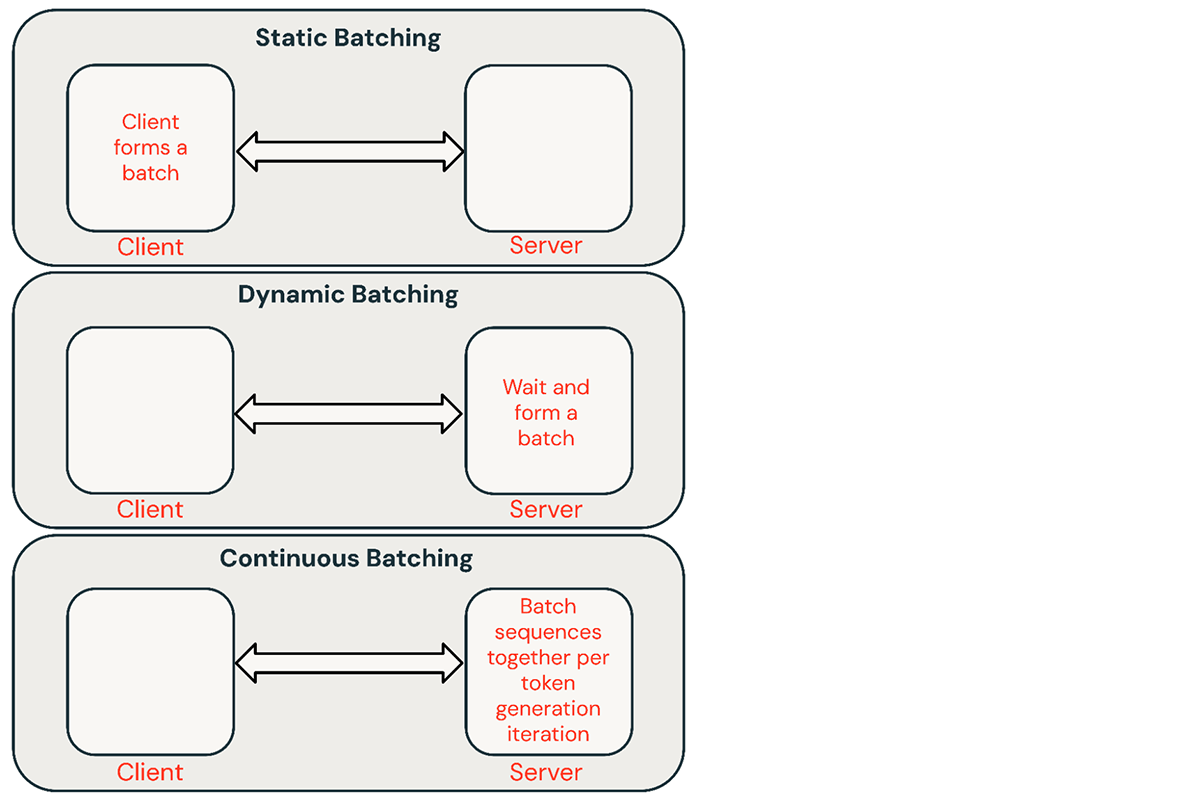
Le batching continu est généralement la meilleure approche pour les services partagés, mais il existe des situations où les deux autres peuvent être meilleures. Dans les environnements à faible QPS, le batching dynamique peut surpasser le batching continu. Il est parfois plus facile d'implémenter des optimisations GPU de bas niveau dans un cadre de batching plus simple. Pour les charges de travail d'inférence par lots hors ligne, le batching statique peut éviter des surcharges importantes et obtenir un meilleur débit.
Taille du lot
L'efficacité du traitement par lots dépend fortement du flux de requêtes. Cependant, nous pouvons obtenir une limite supérieure de ses performances en comparant le traitement par lots statique avec des requêtes uniformes.
| Taille du lot | |||||||
|---|---|---|---|---|---|---|---|
| Matériel | 1 | 4 | 8 | 16 | 32 | 64 | 128 |
| 1 x A10 | 0.4 (1x) | 1.4 (3.5x) | 2.3 (6x) | 3.5 (9x) | Erreur OOM (Out of Memory) | ||
| 2 x A10 | 0.8 | 2.5 | 4.0 | 7.0 | 8.0 | ||
| 1 x A100 | 0.9 (1x) | 3.2 (3.5x) | 5.3 (6x) | 8.0 (9x) | 10.5 (12x) | 12.5 (14x) | |
| 2 x A100 | 1.3 | 3.0 | 5.5 | 9.5 | 14.5 | 17.0 | 22.0 |
| 4 x A100 | 1.7 | 6.2 | 11.5 | 18.0 | 25.0 | 33.0 | 36.5 |
Tableau 2 : Débit maximal MPT-7B (requêtes/sec) avec traitement par lots statique et un backend basé sur FasterTransformers. Requêtes : 512 tokens d'entrée et 64 tokens de sortie. Pour des entrées plus grandes, la limite OOM sera atteinte avec des tailles de lot plus petites.
Compromis latence
La latence des requêtes augmente avec la taille du lot. Avec un seul GPU NVIDIA A100, par exemple, si nous maximisons le débit avec une taille de lot de 64, la latence augmente de 4x tandis que le débit augmente de 14x. Les services d'inférence partagés choisissent généralement une taille de lot équilibrée. Les utilisateurs qui hébergent leurs propres modèles doivent décider du compromis latence/débit approprié pour leurs applications. Dans certaines applications, comme les chatbots, une faible latence pour des réponses rapides est la priorité absolue. Dans d'autres applications, comme le traitement par lots de PDF non structurés, nous pourrions vouloir sacrifier la latence pour traiter un document individuel afin de les traiter tous rapidement en parallèle.
La Figure 7 montre la courbe débit vs latence pour le modèle 7B. Chaque ligne de cette courbe est obtenue en augmentant la taille du lot de 1 à 256. Ceci est utile pour déterminer la taille maximale du lot, sous différentes contraintes de latence. En rappelant notre graphique roofline ci-dessus, nous constatons que ces mesures sont cohérentes avec ce que nous attendrions. Après une certaine taille de lot, c'est-à-dire lorsque nous passons dans le régime limité par le calcul, chaque doublement de la taille du lot augmente la latence sans augmenter le débit.
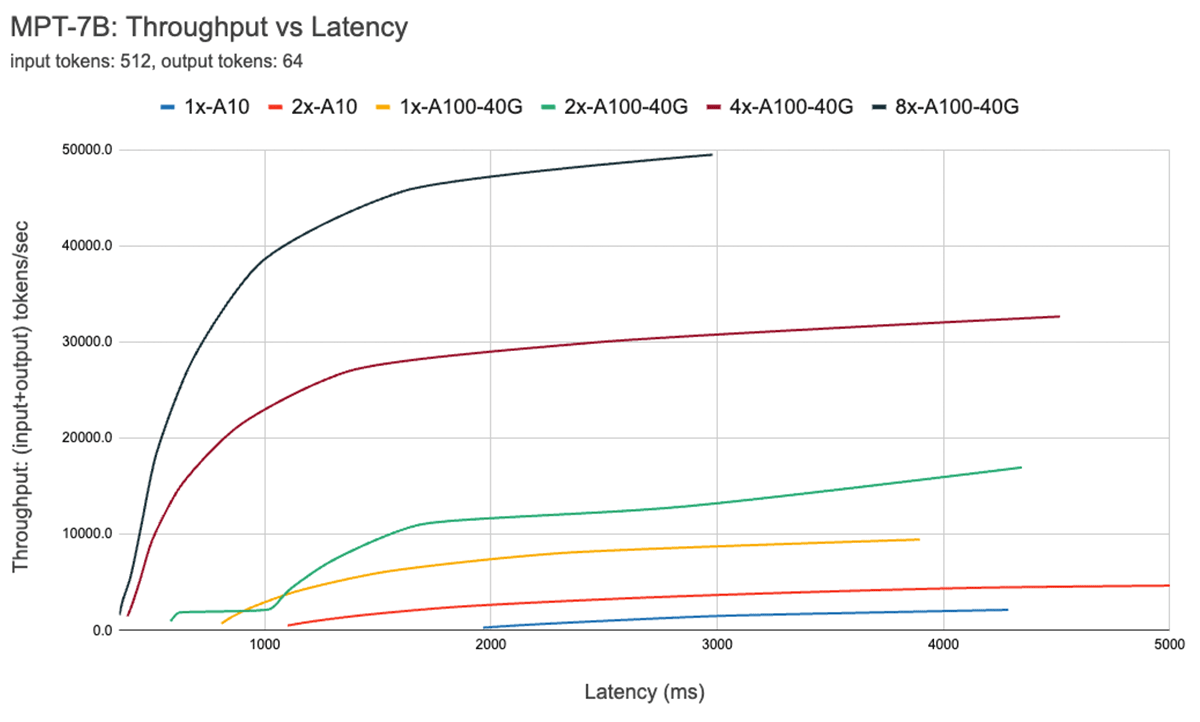
Lors de l'utilisation du parallélisme, il est important de comprendre les détails du matériel de bas niveau. Par exemple, toutes les instances 8xA100 ne sont pas identiques entre les différents clouds. Certains serveurs ont des connexions à bande passante élevée entre tous les GPU, d'autres associent des GPU et ont des connexions à bande passante plus faible entre les paires. Cela pourrait introduire des goulots d'étranglement, faisant dévier les performances réelles de manière significative par rapport aux courbes ci-dessus.
Étude de cas d'optimisation : Quantification
La quantification est une technique courante utilisée pour réduire les exigences matérielles pour l'inférence LLM. La réduction de la précision des poids et des activations du modèle pendant l'inférence peut considérablement réduire les exigences matérielles. Par exemple, passer de poids 16 bits à des poids 8 bits peut diviser par deux le nombre de GPU requis dans les environnements à mémoire limitée (par exemple, Llama2-70B sur A100). Descendre à des poids 4 bits permet d'exécuter l'inférence sur du matériel grand public (par exemple, Llama2-70B sur des Macbooks).
D'après notre expérience, la quantification doit être mise en œuvre avec prudence. Les techniques de quantification naïves peuvent entraîner une dégradation substantielle de la qualité du modèle. L'impact de la quantification varie également selon les architectures (par exemple, MPT vs Llama) et les tailles des modèles. Nous explorerons cela plus en détail dans un futur article de blog.
Lors de l'expérimentation de techniques telles que la quantification, nous recommandons d'utiliser un benchmark de qualité LLM tel que le Mosaic Eval Gauntlet pour évaluer la qualité du système d'inférence, et pas seulement la qualité du modèle isolément. De plus, il est important d'explorer des optimisations système plus approfondies. En particulier, la quantification peut rendre les caches KV beaucoup plus efficaces.
Comme mentionné précédemment, dans la génération de tokens autorégressive, les clés/valeurs (KV) passées des couches d'attention sont mises en cache au lieu d'être recalculées à chaque étape. La taille du cache KV varie en fonction du nombre de séquences traitées à la fois et de la longueur de ces séquences. De plus, lors de chaque itération de la génération du token suivant, de nouveaux éléments KV sont ajoutés au cache existant, le rendant plus grand à mesure que de nouveaux tokens sont générés. Par conséquent, une gestion efficace de la mémoire du cache KV lors de l'ajout de ces nouvelles valeurs est essentielle pour de bonnes performances d'inférence. Les modèles Llama2 utilisent une variante de l'attention appelée Grouped Query Attention (GQA). Veuillez noter que lorsque le nombre de têtes KV est de 1, GQA est identique à Multi-Query-Attention (MQA). GQA aide à réduire la taille du cache KV en partageant les clés/valeurs. La formule pour calculer la taille du cache KV est
taille_du_lot * longueur_seq * (d_model/n_tetes) * n_couches * 2 (K et V) * 2 (octets par Float16) * n_tetes_kv
Le Tableau 3 montre la taille du cache KV GQA calculée pour différentes tailles de lot à une longueur de séquence de 1024 tokens. La taille des paramètres pour les modèles Llama2, en comparaison, est de 140 Go (Float16) pour le modèle 70B. La quantification du cache KV est une autre technique (en plus de GQA/MQA) pour réduire la taille du cache KV, et nous évaluons activement son impact sur la qualité de génération.
| Taille du lot | Mémoire cache KV GQA (FP16) | Mémoire cache KV GQA (Int8) |
|---|---|---|
| 1 | 0.312 Gio | 0.156 Gio |
| 16 | 5 Gio | 2.5 Gio |
| 32 | 10 Gio | 5 Gio |
| 64 | 20 Gio | 10 Gio |
Tableau 3 : Taille du cache KV pour Llama-2-70B à une longueur de séquence de 1024
Comme mentionné précédemment, la génération de tokens avec les LLM à de petites tailles de lot est un problème limité par la bande passante de la mémoire GPU, c'est-à-dire que la vitesse de génération dépend de la rapidité avec laquelle les paramètres du modèle peuvent être déplacés de la mémoire GPU vers les caches sur puce. La conversion des poids du modèle de FP16 (2 octets) à INT8 (1 octet) ou INT4 (0,5 octet) nécessite de déplacer moins de données et accélère donc la génération de tokens. Cependant, la quantification peut avoir un impact négatif sur la qualité de la génération du modèle. Nous évaluons actuellement l'impact sur la qualité du modèle à l'aide de Model Gauntlet et prévoyons de publier bientôt un article de suivi à ce sujet.
Conclusions et résultats clés
Chacun des facteurs que nous avons décrits ci-dessus influence la manière dont nous construisons et déployons les modèles. Nous utilisons ces résultats pour prendre des décisions basées sur les données qui tiennent compte du type de matériel, de la pile logicielle, de l'architecture du modèle et des modèles d'utilisation typiques. Voici quelques recommandations tirées de notre expérience.
Identifiez votre cible d'optimisation : Vous souciez-vous des performances interactives ? De maximiser le débit ? De minimiser les coûts ? Il existe des compromis prévisibles ici.
Portez attention aux composantes de la latence : Pour les applications interactives, le temps jusqu'au premier token détermine la réactivité de votre service, et le temps par token de sortie détermine sa rapidité.
La bande passante mémoire est essentielle : La génération du premier token est généralement limitée par le calcul, tandis que le décodage ultérieur est une opération limitée par la mémoire. Étant donné que l'inférence LLM fonctionne souvent dans des environnements limités par la mémoire, le MBU est une métrique utile à optimiser et peut être utilisée pour comparer l'efficacité des systèmes d'inférence.
Le traitement par lots est essentiel : Le traitement de plusieurs requêtes simultanément est essentiel pour atteindre un débit élevé et pour utiliser efficacement les GPU coûteux. Pour les services en ligne partagés, le traitement par lots continu est indispensable, tandis que les charges de travail d'inférence par lots hors ligne peuvent atteindre un débit élevé avec des techniques de traitement par lots plus simples.
Optimisations approfondies : Les techniques d'optimisation d'inférence standard sont importantes (par exemple, la fusion d'opérateurs, la quantification des poids) pour les LLM, mais il est important d'explorer des optimisations de systèmes plus approfondies, en particulier celles qui améliorent l'utilisation de la mémoire. Un exemple est la quantification du cache KV.
Configurations matérielles : Le type de modèle et la charge de travail attendue doivent être utilisés pour décider du matériel de déploiement. Par exemple, lors de la mise à l'échelle sur plusieurs GPU, le MBU chute beaucoup plus rapidement pour les modèles plus petits, tels que MPT-7B, que pour les modèles plus grands, tels que Llama2-70B. Les performances ont également tendance à augmenter de manière sous-linéaire avec des degrés plus élevés de parallélisme tensoriel. Cela dit, un degré élevé de parallélisme tensoriel peut toujours être judicieux pour les modèles plus petits si le trafic est élevé ou si les utilisateurs sont prêts à payer un supplément pour une latence supplémentaire faible.
Décisions basées sur les données : Comprendre la théorie est important, mais nous recommandons de toujours mesurer les performances globales du serveur. Il existe de nombreuses raisons pour lesquelles un déploiement d'inférence peut être moins performant que prévu. Le MBU pourrait être étonnamment faible en raison d'inefficacités logicielles. Ou des différences matérielles entre les fournisseurs de cloud pourraient entraîner des surprises (nous avons observé une différence de latence de 2x entre des serveurs 8xA100 de deux fournisseurs de cloud).
Pour commencer avec l'inférence LLM, essayez Databricks Model Serving. Consultez la documentation pour en savoir plus.
Voir tous les articles précédents de MosaicML
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.