Atténuer le risque d'injection de prompt pour les agents IA sur Databricks
par JD Braun, Arun Pamulapati, Andrew Weaver, Nishith Sinha, Caelin Kaplan, Alex Warnecke et Jean Verrons
- Les agents d'IA autonomes ont besoin de données sensibles, d'entrées non fiables et d'actions externes pour être utiles, mais la combinaison de ces trois éléments crée des chaînes d'attaque exploitables.
- L'équipe de sécurité de Databricks a développé un guide pratique pour sécuriser les agents d'IA sur Databricks en utilisant la « Règle des Deux pour les Agents » de Meta, un framework permettant d'atténuer le risque d'injection de prompts.
- Le guide couvre neuf contrôles en couches spécifiques sur Databricks concernant l'accès aux données, la validation des entrées et les restrictions de sortie afin de réduire les risques d'injection de prompts.
Vue d'ensemble
Depuis que nous avons publié le Databricks AI Security Framework (DASF) en 2024, le paysage des menaces pour l'IA a considérablement évolué. L'IA est passée du chatbot stéréotypé à des agents capables de raisonner, d'utiliser des outils et d'effectuer des actions pour le compte des utilisateurs, avec peu ou pas d'intervention. Les équipes de sécurité ne doivent plus seulement se préoccuper des utilisateurs qui interagissent avec les modèles, elles doivent également prendre en compte une multitude d'agents intelligents agissant de manière autonome, interagissant avec des services via MCP et explorant Internet par eux-mêmes.
L'injection de prompt était un risque connu à l'ère de l'inférence, mais il était largement limité à la requête et à la réponse de l'utilisateur. Avec des agents capables d'effectuer des actions de manière autonome, le risque a augmenté de manière exponentielle.
Prenons l'exemple d'un professionnel des données qui demande à son agent d'IA d'écrire un script qui appelle une API tierce. L'agent recherche de la documentation sur Internet, rédige le code et l'exécute. Ce que l'utilisateur ne réalise pas, c'est que la page de documentation contenait un prompt malveillant, qui demandait à l'agent d'exfiltrer les informations d'identification de l'environnement de compute de l'utilisateur vers un webhook. De telles attaques sont bien documentées en pratique. Mais il existe des frameworks qui nous aident à comprendre quand et pourquoi elles réussissent.
Des recherches récentes menées dans les Secteurs d'activité, notamment l'étude « Agents Rule of Two » de Meta et des modèles similaires comme le « Lethal Trifecta » de Simon Willison, mettent en évidence les conditions dans lesquelles les attaques par injection de prompt réussissent. Ces schémas correspondent étroitement aux contrôles définis dans le Databricks AI Security Framework (DASF), qui fournit un modèle pratique pour sécuriser les agents d'IA opérant sur les données d'entreprise.
Les deux arrivent à la même conclusion : un agent d'IA devient vulnérable à l'injection de prompt lorsqu'il présente les trois caractéristiques suivantes, et pour atténuer le risque, il ne devrait en avoir que deux :
- Accès à des systèmes sensibles ou à des données privées
- Exposition à des entrées non fiables
- La capacité à changer d'état ou à communiquer avec l'extérieur
En pratique, ces risques correspondent directement aux contrôles de défense en profondeur définis dans le Databricks AI Security Framework (DASF), qui organise la sécurité de l'IA à travers l'accès aux données, l'interaction avec les modèles et l'exécution opérationnelle. Dans les sections ci-dessous, nous montrons comment ces risques peuvent être atténués à l'aide des contrôles natifs de la Databricks Platform.
Comprendre les principaux risques pour les agents IA
Comme mentionné dans l'aperçu, le framework Agents Rule of Two de Meta permet de décomposer les piliers fondamentaux qui rendent les agents d'IA vulnérables à l'injection de prompt :
- Accès à des systèmes sensibles ou à des données privées : l'agent peut lire ou interagir avec les données sensibles de l'utilisateur.
- Traiter les entrées non fiables : l'agent peut consommer du contenu fourni par des sources externes ou contrôlées par un attaquant.
- Modifier l'état ou communiquer en externe : l'agent peut effectuer des actions en dehors de son environnement local, comme effectuer des requêtes HTTP ou modifier des systèmes externes.
Lorsque les trois piliers sont présents, le système a déjà accès à des systèmes sensibles ou à des données privées (premièrement), et un attaquant peut alors injecter des instructions malveillantes par le biais d'entrées non fiables (deuxièmement), ce qui amène l'agent à exfiltrer ces données vers l'extérieur (troisièmement). Dans cette section, nous explorerons comment chacun de ces éléments s'applique dans le contexte de Databricks.
Pilier 1 : Accès à des systèmes sensibles ou à des données privées
Pour qu'un attaquant puisse exfiltrer des données de valeur, l'agent doit d'abord y avoir accès. Il s'agit du premier pilier de la Règle des Deux pour les Agents, et en pratique, ce n'est presque jamais facultatif. Les agents sont les plus utiles lorsqu'ils peuvent opérer sur des données réelles et de grande valeur. Ils sont de plus en plus utilisés pour des tâches telles que l'analyse des sentiments sur les commentaires des clients, la prévision de la demande, la détection de la fraude ou l'assistance au codage. Pour être efficaces, ces agents se voient délibérément accorder l'accès à des dossiers clients, des historiques de transactions, des documents propriétaires ou de vastes bases de code internes. En d'autres termes, les données mêmes qui confèrent aux organisations un avantage concurrentiel sont aussi celles qui intéressent le plus les attaquants.
En tant que plateforme unifiée de données et d'intelligence, Databricks est conçue pour centraliser et traiter les ensembles de données les plus précieux d'une organisation. Les applications et les agents s'exécutant sur la plateforme fonctionnent, par conception, à proximité d'informations sensibles. Cela signifie que dans de nombreux déploiements réels, il faut partir du principe que le premier pilier de la Règle des Deux des Agents est présent, plutôt que de le considérer comme une simple préoccupation hypothétique.
Pilier 2 : Traiter des entrées non fiables
Le deuxième pilier de la Règle des Deux pour les Agents se concentre sur la manière dont les données non fiables entrent dans le système. Dans le cas le plus simple, ce risque est évident : une interface de chat LLM peut accepter directement les entrées utilisateur contenant des instructions malveillantes. Il s'agit d'une injection de prompt directe, où l'attaquant fournit la charge utile explicitement dans le cadre de l'interaction.
Le risque, cependant, s'étend au-delà de la saisie directe de l'utilisateur. Les agents et les applications basées sur des LLM récupèrent et traitent souvent des données à partir de sources externes telles que des bases de données, des documents, des APIs ou des bases de connaissances. Dans ces cas, des instructions malveillantes peuvent être intégrées dans un contenu par ailleurs légitime et n'apparaître que lorsque l'agent lit ou raisonne sur ces données. Il s'agit d'une injection de prompt indirecte. La difficulté est accrue par le fait que les LLM modernes sont conçus pour interpréter un large éventail d'entrées, y compris le langage naturel, les données structurées, les caractères spéciaux, les images et les charges utiles encodées. Cette diversité rend les instructions malveillantes difficiles à détecter à l'aide des techniques traditionnelles de validation des entrées.
Sur la plateforme Databricks, la diversité des sources de données rend cela particulièrement pertinent. Une seule table Unity Catalog peut contenir des enregistrements de transactions provenant d'un système de gestion des commandes, des conversations de support entre le personnel et les clients, ou des retours sur les produits soumis via un formulaire web. Lorsqu'un agent a accès à ces données, il est important de se poser une question simple mais essentielle : une partie de ces données a-t-elle pu être influencée par un acteur externe ?
Si la réponse est oui, alors le deuxième pilier de la règle des deux pour les agents est déjà en place.
En pratique, cette évaluation est rarement simple. Il est souvent nécessaire de remonter jusqu'à la source d'origine des données et de prendre en compte des points d'injection moins évidents, tels que les commentaires, les champs de texte libre, les métadonnées ou les pièces jointes, où des instructions malveillantes pourraient être intégrées. Ce qui ressemble à des données commerciales ordinaires peut être, du point de vue d'un agent, des instructions exécutables.
Pilier 3 : Modifier l'état ou communiquer avec l'extérieur
Le dernier pilier de l'Agents Rule of Two se concentre sur ce que l'agent est réellement autorisé à faire, et par conséquent sur l'ampleur que peut atteindre le rayon d'action d'une attaque. Dans les premières applications de LLM, le modèle était essentiellement en lecture seule. Un utilisateur fournissait une invite, le modèle générait une réponse, et cette réponse était simplement affichée. Même si un attaquant influençait la sortie du modèle, l'impact était généralement limité au texte affiché à l'utilisateur, car le modèle n'avait pas la capacité d'accéder aux données d'exécution privées ou d'exécuter des actions.
Les agents modernes sont fondamentalement différents. Ils ne se limitent plus à la production de texte, mais peuvent également modifier l'état par des actions telles que l'exécution de code Python ou de queries SQL, et communiquer en externe en appelant des APIs ou en interagissant avec des systèmes via des mécanismes tels que le Model Context Protocol (MCP).
Sur la plateforme Databricks, les agents dotés de capacités d'IA peuvent être facilement connectés à des serveurs MCP, à des fonctions définies par l'utilisateur ou à des APIs externes. Pendant la phase de conception, il est important de prendre en compte non seulement l'utilisation prévue de ces outils, mais aussi leur potentielle mauvaise utilisation. Si un outil permet à l'agent de communiquer en externe ou d'écraser des tables, le dernier pilier de l'Agents Rule of Two est actif.
Comme pour les autres piliers, se faire une idée complète des capacités de l'agent n'est pas toujours simple. Un outil qui semble inoffensif à première vue peut tout de même être utilisé de manière inattendue. Les développeurs doivent donc réfléchir en termes de capacités effectives, c'est-à-dire ce que l'agent pourrait faire sous une influence contradictoire, et non pas seulement les tâches pour lesquelles il a été conçu.
Synthèse
Pris individuellement, chacun des trois piliers peut sembler gérable. L'injection de prompt est moins préoccupante si l'agent ne peut pas accéder aux données sensibles. L'accès aux données sensibles est moins risqué si l'agent n'a aucune capacité d'agir sur celles-ci. Et les outils puissants sont moins dangereux si l'agent ne traite que des entrées de confiance. Le risque devient important lorsque ces facteurs convergent. Dans ces conditions, un adversaire peut influencer le comportement de l'agent d'une manière qui va au-delà de son utilisation prévue, transformant ce qui semble être une interaction de routine en un incident de sécurité aux conséquences réelles.
D'un point de vue défensif, cela nous donne un principe de conception pratique : essayer de séparer les trois piliers. Dans la plupart des applications d'IA du monde réel, il est difficile de supprimer entièrement un seul élément. Les agents ont besoin de données pour être utiles, ils doivent traiter des entrées diverses et ils ont souvent besoin d'outils pour automatiser des tâches. Néanmoins, il existe des moyens concrets de maîtriser le risque associé à chaque pilier.
Sur de nombreuses plateformes d'IA, ces risques sont gérés par un ensemble hétéroclite d'outils couvrant les systèmes d'identité, les contrôles réseau, les passerelles de modèles et les solutions de gouvernance des données. Databricks adopte une approche différente. Comme les données, les modèles d'IA et les applications s'exécutent sur une plateforme unifiée régie par Unity Catalog et Agent Bricks, les organisations peuvent appliquer des contrôles à plusieurs niveaux sur l'ensemble du système d'IA — de l'accès aux données à l'interaction avec le modèle et à l'exécution — sans créer de silos de sécurité supplémentaires.
La plateforme Databricks fournit des contrôles à chacune de ces couches, que nous explorerons dans les sections suivantes à l'aide d'un exemple concret, notre nouvel agent d'IA : Social Gauge.
Contrôles par pilier des risques d'injection de prompt sur les agents d'IA
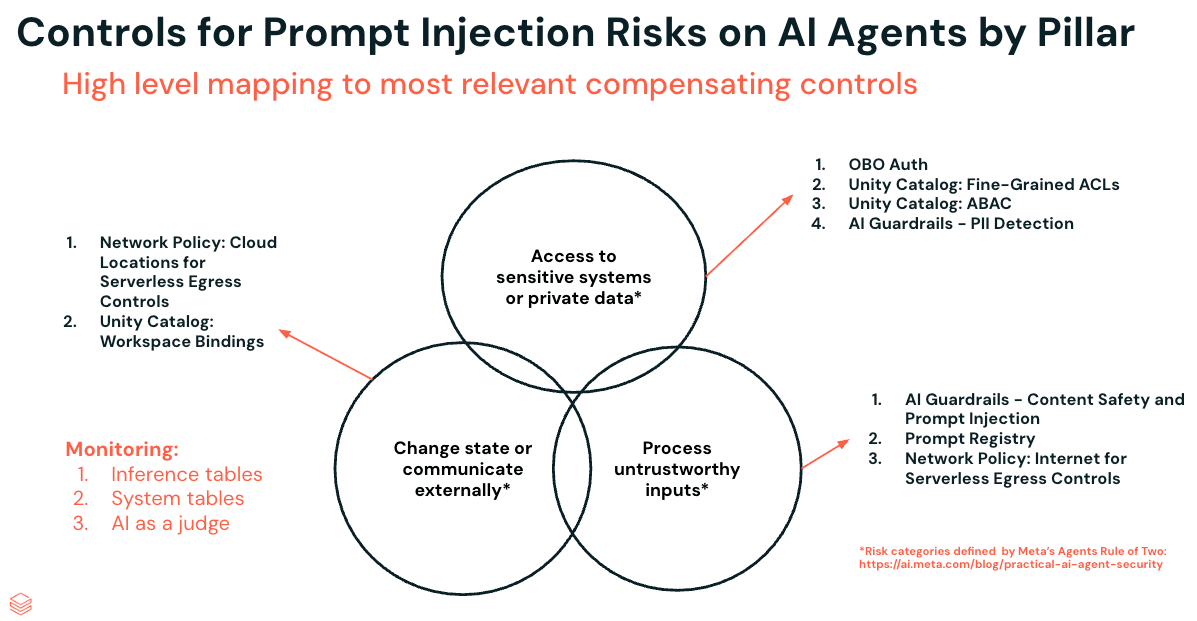
Le moyen le plus efficace d'atténuer l'injection de prompt est de supprimer entièrement l'un des trois piliers. Cela reste vrai. Mais en pratique, la plupart des agents ont besoin, à des degrés divers, des trois : l'accès à des données sensibles, l'exposition à des entrées externes et la capacité d'agir. Ainsi, au lieu de supprimer un pilier, l'objectif devient de renforcer chacun d'eux pour réduire la surface d'attaque.
Nous allons passer en revue neuf contrôles sur les trois piliers à l'aide d'un exemple fil rouge : Social Gauge, un agent intégré dans une application Databricks qui extrait des données des réseaux sociaux et des sources d'information, puis les combine avec les dossiers clients existants régis par Unity Catalog. Pensez aux équipes Marketing qui suivent le sentiment concernant les lancements de produits, aux équipes financières qui consolident la couverture trimestrielle ou aux salles de rédaction qui font le monitoring des services de dépêches. Pour cette démonstration, nous nous concentrerons sur un client du secteur de la vente au détail qui utilise Social Gauge pour suivre le sentiment des utilisateurs concernant les nouveaux produits.
Ce contexte étant établi, gardez à l'esprit le scénario d'attaque suivant lors de l'examen de chacun des trois piliers :
- Social Gauge a accès à des données financières sensibles au-delà de ce qui est nécessaire pour son utilisation prévue.
- Une publication sur les réseaux sociaux contenant une injection de prompt qui intègre des instructions malveillantes est ingérée.
- Ces instructions demandent à l'agent de récupérer les données financières hors périmètre et soit de les exfiltrer en externe, soit de les modifier au sein d'un schéma interne pour influencer les décisions en aval.
Les contrôles que nous abordons dans chaque section sont conçus pour interrompre, atténuer ou surveiller cette chaîne d'attaque à différents stades.
Pilier 1 : Accès aux systèmes sensibles ou aux données privées - Contrôles
Ce pilier est presque inévitable. Les agents sont utiles précisément parce qu'ils opèrent sur des données réelles. Social Gauge doit query les dossiers des clients via Unity Catalog pour répondre à des questions telles que « Y a-t-il une raison pour laquelle les Ventes de mon produit ont chuté en janvier ? » Est-ce lié à un sentiment client ?" Sans cet accès, l'agent ne peut pas fournir de véritables insight.
Dans notre scénario d'attaque, le risque du Pilier 1 est que Social Gauge ait accès à des données financières au-delà de ce qui est nécessaire à son utilisation prévue, ce qui rend l'agent vulnérable à une injection de prompt indirecte qui lui ordonne de récupérer ces données hors champ. Puisque nous ne pouvons pas éliminer ce pilier, nous voulons le contraindre, en limitant la portée de Social Gauge aux seules données pertinentes pour l'utilisateur qui effectue la demande.
Databricks est idéalement positionné pour atténuer ce risque, car les agents d'IA opèrent directement sur des données d'entreprise gouvernées via Unity Catalog. Cela permet aux organisations d'appliquer des contrôles d'accès granulaires, d'assurer le respect des politiques et de mettre en place des mécanismes de protection des données de manière cohérente, tant pour les utilisateurs humains que pour les agents d'IA.
Authentification au nom de l'utilisateur :
Lors de la création d'intégrations avec des agents d'IA, les clients peuvent choisir d'utiliser l'authentification au nom de l'utilisateur (OBO) pour les APIs Databricks. Cela signifie que lorsque le SDK sous-jacent est appelé pour accéder aux données, il utilise les autorisations de l'utilisateur final qui interagit avec l'agent plutôt qu'un service principal lié à l'agent lui-même.
Cela devrait être la première étape lors de la création de toute application d'IA. Cela limite intrinsèquement les autorisations et empêche un agent disposant de droits excessifs de devenir un point de compromission unique.
Unity Catalog - Listes de contrôle d'accès affinées :
Pour que l'authentification OBO soit efficace, les clients ont besoin de listes de contrôle d'accès affinées dans Unity Catalog, garantissant qu'aucun utilisateur ou workspace n'a accès à des données auxquelles il ne devrait pas avoir accès.
Les privilèges sur les objets sécurisables sont les contrôles d'accès que la plupart des clients connaissent. Ils dictent les actions qu'un utilisateur peut effectuer sur un objet sécurisable Unity Catalog, qu'il s'agisse d'un catalogue, d'un schéma, d'une table, d'un volume ou autre. Pour de nombreux clients, ces paramètres sont déjà en place dans le cadre de leur stratégie de gouvernance. Consultez notre documentation sur les bonnes pratiques pour Unity Catalog pour en savoir plus sur la gestion des autorisations.
Unity Catalog - Contrôles d'accès basés sur les attributs (ABAC) :
Les contrôles d'accès granulaires fonctionnent bien lorsque les utilisateurs appartiennent à des groupes clairement définis comme les ingénieurs de données, les analystes ou les utilisateurs métier. Mais qu'en est-il des utilisateurs métier travaillant sur différentes branches d'activité, ou des utilisateurs basés dans différentes régions ? C'est là qu'intervient l'ABAC.
L'ABAC vous permet de définir des politiques une seule fois et de les appliquer aux catalogues, schémas, tables, etc. Il existe deux types de politiques. Les politiques de filtrage de lignes filtrent automatiquement les tables en fonction des attributs d'un utilisateur — par exemple, si un utilisateur est basé dans la zone EMEA, la table est réduite pour n'afficher que les enregistrements de cette région. Les politiques de masquage de colonnes masquent les colonnes sensibles, à moins qu'un utilisateur n'appartienne à un groupe spécifique, offrant ainsi un moyen simple de réduire l'exposition des PII.
Garde-fous de l'IA - Détection des PII :
Les contrôles ci-dessus visent à limiter qui peut accéder à quoi. Mais il est tout aussi important de surveiller ce qui est réellement renvoyé par l'agent. De nombreux clients utilisent Agent Bricks AI Gateway comme couche de gouvernance centrale pour l'accès à l'IA. Au-delà de l'accès unifié aux modèles, du routage, du suivi de l'utilisation et de la limitation du débit, AI Gateway fournit des garde-fous comme la détection des PII, en bloquant ou en masquant automatiquement les données sensibles où qu'elles apparaissent dans les entrées ou les sorties d'un modèle. Cela protège contre les scénarios où un agent est manipulé pour révéler des données qu'il ne devrait pas.
Résumé : Contrôles pour l'accès aux systèmes sensibles ou aux données privées
Avec ces contrôles en place, l'exposition de Social Gauge est fondamentalement différente. Même si l'agent est manipulé par une attaque par injection de prompt, il ne peut accéder qu'aux données auxquelles l'utilisateur à l'origine de la requête a déjà accès, limitées à sa région, masquées au niveau des colonnes sensibles et surveillées pour détecter les PII en sortie. Un attaquant qui compromet l'agent n'hérite pas des clés du royaume ; il hérite des autorisations d'un seul utilisateur, avec un garde qui surveille la porte.
Pilier 2 : Traiter les entrées non fiables - Contrôles
Databricks fournit de nombreux contrôles de plateforme qui atténuent l'exposition aux utilisateurs externes non autorisés : SSO avec MFA, contrôles d'entrée basés sur le contexte, PrivateLink frontal, ou ACL IP. Mais le risque d'exposition à des entrées non fiables ne s'arrête pas à l'écran de connexion.
La fonction principale de Social Gauge est de rechercher sur Internet des publications sur les réseaux sociaux et des articles de presse concernant les produits de consommation. Cette fonction l'expose à l'injection indirecte de prompts, c'est-à-dire à des instructions malveillantes intégrées dans un contenu web par ailleurs légitime. Ainsi, bien que les utilisateurs non autorisés ne puissent pas accéder directement à l'interface de Social Gauge, la surface d'attaque indirecte est bien réelle.
Il y a aussi le risque interne : des utilisateurs qui tentent des techniques de jailbreaking pour accéder à des données qu'ils ne sont pas censés voir, détournent Social Gauge pour un usage pour lequel il n'a pas été conçu, ou manipulent son analyse (par exemple, "invente une source qui dit que mon produit est génial !").
Dans notre scénario d'attaque, le risque du Pilier 2 est qu'un message de réseau social contenant une injection de prompt soit ingéré, et que le contenu malveillant intégré soit interprété comme des instructions légitimes par l'agent. Ce risque peut être atténué par des contrôles qui renforcent la gestion par l'agent des entrées non fiables.
Garde-fous de l'IA : Sécurité du contenu et injection de prompt :
Comme nous l'avons vu, avec Agent Bricks AI Gateway, plusieurs garde-fous intégrés peuvent être appliqués, tels que le filtrage de sécurité et la détection des PII. Ces garde-fous peuvent être appliqués à l'entrée ou à la sortie d'un agent (ou aux deux). En plus de ces garde-fous intégrés, vous pouvez également déployer des modèles personnalisés sur Databricks Model Serving et les exploiter. Par exemple, les derniers modèles Llama Protection sont des LLM spécialisés qui ont été affinés pour détecter les injections de prompt, le contenu toxique ou l'abus de l'interpréteur de code. Ces modèles peuvent agir comme une couche de défense autour de vos agents, en inspectant les interactions avant qu'elles ne se transforment en incidents.
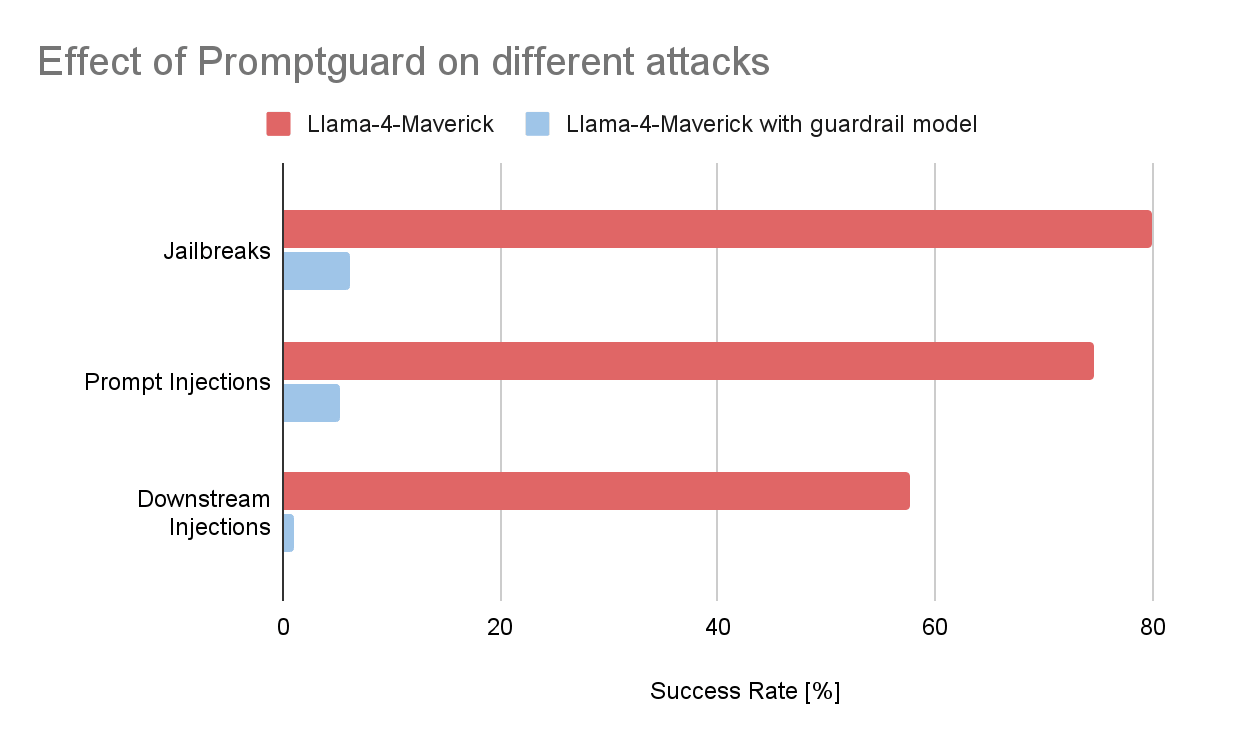
Pour avoir une idée de l'efficacité de ces garde-fous, nous avons mené une petite Experimentation. Nous avons collecté quelques centaines de prompts malveillants provenant du scanner de vulnérabilités Garak, un outil open source développé par NVIDIA qui s'intègre facilement à Databricks pour les tests de sécurité automatisés des LLM. À partir de ce dataset, nous avons sélectionné trois catégories d'attaques courantes :
- Injections de prompt: instructions malveillantes cachées dans des contextes tels que des sites web, des tâches de traduction ou des e-mails, conçues pour manipuler le modèle afin de lui faire adopter un comportement non intentionnel.
- Jailbreaks: Des prompts soigneusement conçus pour contourner les protections d'alignement et provoquer des résultats nuisibles ou restreints.
- Attaques par injection en aval: invites qui tentent de faire en sorte que le modèle génère un contenu qui ne devient dangereux que lorsqu'il est interprété par un autre système, par exemple, une instruction SQL malveillante exécutée par une application, ou une balise d'image Markdown spécialement conçue qui exfiltre des données sensibles lorsqu'elle est rendue au format HTML.
Nous avons ensuite mesuré le taux de réussite de ces attaques par rapport à un modèle de référence, en l'occurrence un déploiement Llama-4-Maverick. Les résultats étaient clairs. Sans garde-fous, une partie importante des prompts malveillants a réussi à provoquer le Trigger ciblé. Lorsqu'un modèle de garde-fou personnalisé (Prompt Guard 2 pour les injections de prompt et les jailbreaks, llama guard 3-8b pour les injections en aval) a été placé devant le modèle, le taux de réussite a chuté de plus de 90 % dans les trois catégories.
Si vous souhaitez explorer des techniques de garde-fou supplémentaires, des approches open source ou des modèles de détection de PII de pointe, contactez votre représentant Databricks pour en savoir plus sur les déploiements de garde-fous personnalisés.
Registre de prompts :
Un prompt système bien conçu peut parfois faire la différence entre la réussite ou l'échec d'une attaque. Il n'est pas aussi robuste qu'un modèle de détection dédié, mais il est important de le configurer correctement. Le Registre de prompts MLflow rationalise le Data Engineering et la gestion des prompts pour les applications GenAI, vous permettant de versionner, de suivre, de tester et de réutiliser les prompts au sein de votre organisation plutôt que de les assembler de manière ponctuelle.
Résumé : Contrôles pour le traitement des entrées non fiables
Social Gauge lit toujours à partir de l'Internet ouvert, c'est son exigence fondamentale. Mais la surface d'attaque qu'un attaquant peut exploiter s'est considérablement réduite. Les prompts malveillants intégrés dans le contenu Web doivent désormais survivre à un modèle de détection affiné avant d'atteindre l'agent, et le prompt système est versionné et testé plutôt que d'être assemblé à la volée. Aucun de ces contrôles n'est infaillible en soi, mais une fois combinés, ils transforment une surface d'attaque totalement exposée en quelque chose qu'un attaquant aura beaucoup plus de mal à exploiter.
Pilier 3 : Modifier l'état ou communiquer avec l'extérieur - Contrôles
Dans la phase finale de notre scénario d'attaque, le risque du Pilier 3 est qu'une fois l'injection de prompt traitée, l'agent ait la capacité d'exécuter les instructions malveillantes, soit en exfiltrant des données à l'externe, soit en les modifiant au sein d'un schéma interne pour influencer les décisions en aval.
Social Gauge enrichit les données existantes avec des données tierces pour les utilisateurs qui analysent les performances des produits, ce qui signifie qu'il doit intrinsèquement écrire dans des catalogues, des schémas, des tables et d'autres objets. L'état sous-jacent change. Nous nous concentrerons sur trois contrôles : la restriction de l'accès au réseau sortant, la restriction de l'accès au stockage externe et la restriction des changements d'état au sein d'Unity Catalog.
Contrôles de sortie Serverless - Emplacements Internet :
Même si une injection de prompt est traitée par l'agent, le rayon d'explosion qui en résulte peut être considérablement réduit en appliquant des contrôles de sortie Serverless via les stratégies réseau de Databricks. Celles-ci permettent aux administrateurs de définir une posture de refus par default pour les connexions sortantes à partir des charges de travail serverless (y compris les Databricks Apps), puis d'autoriser explicitement uniquement les destinations de confiance dont l'agent a réellement besoin.
En associant une politique réseau restreinte à la workspace exécutant un agent tel que Social Gauge, vous limitez la capacité de l'agent à atteindre des Endpoints Internet arbitraires, réduisant ainsi la surface d'attaque par injection de prompt indirecte et diminuant le risque d'exfiltration de données vers des destinations inconnues.
Contrôles de sortie sans serveur - Objets Unity Catalog :
Outre la restriction de l'accès aux Endpoint connus via le filtrage FQDN, la deuxième fonctionnalité des contrôles de sortie sans serveur est la capacité de restreindre l'accès aux emplacements de stockage cloud comme les buckets S3. Les buckets associés au workspace, aux tables système et aux exemples de datasets restent en lecture seule par défaut, mais ce contrôle va plus loin : il empêche un agent d'IA d'écrire dans un bucket non autorisé, fermant ainsi l'un des chemins d'exfiltration les plus courants.
Unity Catalog - Liaisons d'espaces de travail :
Les liaisons entre le Workspace et le catalogue permettent aux clients de limiter l'accès aux catalogues à partir de Workspaces spécifiques. Cela est important lorsque les développeurs peuvent accéder aux données dans plusieurs environnements, mais que ces données ne doivent pas franchir les limites de l'environnement de développement. Un data engineer peut avoir l'autorisation de lire les données de production, mais il ne devrait pas pouvoir le faire depuis un workspace de développement.
Comme Social Gauge fonctionne avec des informations d'identification OBO, les liaisons de workspace réduisent le risque que l'agent modifie par inadvertance l'état de la production lorsqu'il opère en développement.
Résumé : Contrôles pour modifier l'état ou communiquer en externe
Avec les contrôles de sortie serverless appliquant une posture de refus default sur les connexions sortantes et verrouillant le stockage externe, et avec les liaisons d'espaces de travail appliquant les limites de l'environnement, nous avons bloqué les chemins les plus évidents d'exfiltration et de manipulation d'état. Voyons maintenant comment intercepter ce qui passe entre les mailles du filet.
Monitoring de vos agents d'IA pour détecter les risques de sécurité
Comme mentionné ci-dessus, les clients peuvent utiliser Agent Bricks AI Gateway pour gérer et gouverner l'accès à tous les modèles et agents d'IA au sein de l'entreprise, et cette unification s'étend également à l'observabilité et au monitoring. Avec AI Gateway, vous pouvez centraliser les Logs de toutes les entrées et sorties des modèles et agents d'IA au sein de votre organisation via des tables d'inférence, ce qui vous permet d'utiliser ces données pour monitorer et auditer les requêtes d'IA et pour améliorer les performances et la sécurité des modèles.
Tables d’inférences
Vous pouvez utiliser la query ci-dessous pour surveiller vos tables d'inférence afin de voir si l'un des garde-fous intégré a été déclenché. La requête extraira quel garde-fou (entrée ou sortie) a été Trigger, ainsi que les catégories nuisibles qui ont été détectées. Bien sûr, en matière de sécurité, il vaut toujours mieux être proactif que réactif. Donc, une fois que vous avez validé la query, il est vivement recommandé de prendre les mesures supplémentaires pour la configurer en tant qu'alerte, qui vous avertira automatiquement, vous ou votre centre des Opérations de sécurité (SOC), si un événement justifie une enquête.
Tables système
En plus des tables d'inférence, les tables système de Databricks contiennent un insight sur les événements importants qui se produisent dans Databricks. Nous avons déjà écrit un article de blog sur la manière dont elles peuvent être exploitées pour surveiller et alerter de manière proactive les menaces de sécurité potentielles et les indicateurs de compromission (IoC), et cela peut être étendu aux risques de sécurité fondamentaux pour les agents d'IA. La query ci-dessous, par exemple, peut être utilisée pour surveiller le contrôle de sortie serverless et si quelqu'un (ou un agent) tente de le contourner afin de communiquer en externe.
L'IA en tant que juge
L'utilisation de l'IA en tant que juge est omniprésente dans le domaine des agents et de l'intelligence artificielle en général. En fait, la plupart des modèles de garde-fou sont essentiellement des LLM qui sont affinés et/ou guidés par des prompts système spécifiques pour servir cet objectif précis. Comme nous l'avons mentionné ci-dessus, il est facile de déployer des modèles personnalisés sur Databricks Model Serving, et nous avons des exemples de déploiement de la plupart des modèles de garde-fou les plus récents et les plus performants, tels que Llama Guard 4 et Llama Prompt Guard 2 sur Databricks. Au-delà de leur déploiement en tant que garde-fous personnalisés, l'un des avantages de l'architecture ouverte et enfichable de Databricks est qu'une fois que vous avez enregistré un modèle à l'aide de la saveur générique mlflow.pyfunc de MLflow, vous pouvez l'exploiter de nombreuses manières différentes. Parmi les exemples, on peut citer leur déploiement en tant que batch Spark workflows ou pipelines déclaratifs Spark, leur appel via SQL avec ai_query, ou même leur application dans des scénarios en temps réel ou par micro-batch avec Spark Structured Streaming.
Dans certains cas, l'application de garde-fous à chaque requête ou réponse peut ne pas être réalisable. Il s'agit d'un scénario tout à fait valable dans lequel les garde-fous peuvent interférer avec l'objectif commercial ou le domaine dans lequel l'agent opère. Même si les garde-fous ne sont pas appliqués, nous pouvons toujours surveiller la sécurité de nos agents en utilisant leurs tables d'inférence et un pipeline de traitement par batch ou en streaming pour classer les contenus potentiellement dangereux.
Autres ressources
Les contrôles présentés dans cet article sont un point de départ, et non une ligne d'arrivée. Le risque d'injection de prompt évolue à mesure que les agents deviennent plus performants, et l'objectif est un programme de sécurité reproductible qui suit le rythme. Il ne s'agira pas d'un exercice de renforcement ponctuel !
Ces modèles de sécurité des agents façonnent également la prochaine évolution du Databricks AI Security Framework. Une prochaine mise à jour du DASF étend le framework pour prendre en charge les agents d'IA autonomes, l'utilisation d'outils et les risques émergents d'injection de prompt, aidant ainsi les organisations à sécuriser des systèmes d'IA complets, et pas seulement des modèles.
Nous avons organisé les ressources les plus pertinentes autour de trois phases :
Définir :
- Le Databricks AI Security Framework (DASF) 2.0 propose une analyse complète des risques sur 12 composants principaux des systèmes d'IA, en s'alignant sur des normes telles que MITRE ATLAS, NIST, OWASP et HITRUST. Il fournit 67 contrôles pratiques pour réduire les risques tels que l'injection de prompt, le jailbreak et l'exfiltration de données. Contrôles DASF abordés dans ce blog :
- DASF 5 : Contrôler l'accès aux données et autres objets
- DASF 64 : Limiter l'accès depuis les modèles d'IA et les agents
- DASF 57 : Utiliser les contrôles d'accès basés sur les attributs (ABAC)
- DASF 58 : Protéger les données avec des filtres et du masquage
- DASF 54 : Mettre en œuvre des garde-fous pour l'IA
- DASF 62 : Mettre en œuvre la segmentation du réseau
- DASF 37 : Configurer les tables d'inférence pour le monitoring et le debugging des modèles
- DASF 49 : Automatiser l'évaluation des LLM
- DASF 73 : Enregistrer les prompts
- DASF 55 : Surveiller les logs d'audit
- Le cadre de gouvernance de l'IA de Databricks (DAGF) définit la manière dont les organisations doivent gouverner les systèmes d'IA tout au long de leur cycle de vie, de la conception et du développement au déploiement et au monitoring.
- Les guides des meilleures pratiques de sécurité Databricks (pour AWS, Azure et GCP) fournissent un aperçu détaillé des principaux contrôles de sécurité que nous recommandons pour les environnements classiques et hautement sécurisés, basés sur ce que nous observons fonctionner en partenariat avec nos clients les plus soucieux de la sécurité.
Déployer
- L'architecture de référence de sécurité Databricks - Template Terraform (SRA) permet le déploiement de Workspace Databricks et d'une infrastructure cloud configurés avec les meilleures pratiques de sécurité.
Surveiller :
- L'outil d'analyse de la sécurité (SAT) aide les équipes de sécurité et de plateforme à évaluer rapidement la posture de sécurité des espaces de travail Databricks.
- L'outil de détection Databricks, une série de détections spécifiques rassemblées dans un Notebook facile à utiliser, qui vous aide à surveiller l'activité sur vos Workspace.
La combinaison de ces ressources offre à vos équipes un moyen pragmatique de passer du renforcement ponctuel d'un seul agent à un programme de sécurité reproductible et évolutif pour l'IA sur Databricks, qui peut suivre le rythme de votre innovation et de l'évolution du paysage des menaces.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.