Migration d'Oracle vers Databricks : Conseils pour une transition en douceur
Stratégies, outils et meilleures pratiques pour la transition vers l'architecture Lakehouse
par Laurent Léturgez
- Comprendre comment l'architecture Lakehouse se compare au modèle traditionnel d'entrepôt de données relationnelles d'Oracle.
- Découvrir comment inventorier les objets de base de données et traduire les schémas spécifiques à Oracle dans des formats pris en charge par Databricks.
- Exécuter les étapes post-migration pour valider l'intégrité des données, exécuter des systèmes parallèles pour les tests métier et optimiser les performances.
Alors que de plus en plus d'organisations adoptent des architectures lakehouse, la migration depuis des entrepôts de données traditionnels comme Oracle vers des plateformes modernes comme Databricks est devenue une priorité courante. Les avantages — meilleure évolutivité, performance et efficacité des coûts — sont clairs, mais le chemin pour y parvenir n'est pas toujours simple.
Dans cet article, je partagerai des stratégies pratiques pour naviguer dans la migration d'Oracle vers Databricks, y compris des conseils pour éviter les pièges courants et assurer le succès à long terme de votre projet.
Comprendre les différences clés
Avant de discuter des stratégies de migration, il est important de comprendre les différences fondamentales entre Oracle et Databricks — non seulement en termes de technologie, mais aussi en termes d'architecture.
Le modèle relationnel d'Oracle vs l'architecture lakehouse de Databricks
Les entrepôts de données Oracle suivent un modèle relationnel traditionnel optimisé pour les charges de travail structurées et transactionnelles. Databricks est une solution parfaite pour héberger des charges de travail d'entrepôt de données, quel que soit le modèle de données utilisé, similaire à d'autres systèmes de gestion de bases de données comme Oracle. En revanche, Databricks est construit sur une architecture lakehouse, qui fusionne la flexibilité des data lakes avec la performance et la fiabilité des entrepôts de données.
Ce changement modifie la manière dont les données sont stockées, traitées et accessibles — mais ouvre �également des possibilités entièrement nouvelles. Avec Databricks, les organisations peuvent :
- Prendre en charge des cas d'utilisation modernes comme le machine learning (ML), l'IA traditionnelle et l'IA générative
- Tirer parti de la séparation du stockage et du calcul, permettant à plusieurs équipes de lancer des entrepôts indépendants tout en accédant aux mêmes données sous-jacentes
- Briser les silos de données et réduire le besoin de pipelines ETL redondants
Dialectes SQL et différences de traitement
Les deux plateformes prennent en charge SQL, mais il existe des différences de syntaxe, de fonctions intégrées et d'optimisation des requêtes. Ces variations doivent être traitées lors de la migration pour garantir la compatibilité et les performances.
Traitement des données et mise à l'échelle
Oracle utilise une architecture basée sur les lignes, mise à l'échelle verticalement (avec une mise à l'échelle horizontale limitée via Real Application Clusters). Databricks, quant à lui, utilise le modèle distribué d'Apache Spark™, qui prend en charge la mise à l'échelle horizontale et verticale sur de grands ensembles de données.
Databricks fonctionne également nativement avec Delta Lake et Apache Iceberg, des formats de stockage colonnaires optimisés pour l'analytique à grande échelle et haute performance. Ces formats prennent en charge des fonctionnalités telles que les transactions ACID, l'évolution des schémas et le voyage dans le temps, qui sont essentielles pour construire des pipelines résilients et évolutifs.
Étapes de pré-migration (communes à toutes les migrations d'entrepôts de données)
Quel que soit votre système source, une migration réussie commence par quelques étapes critiques :
- Inventaire de votre environnement : Commencez par cataloguer tous les objets de base de données, les dépendances, les modèles d'utilisation et les flux de travail ETL ou d'intégration de données. Cela fournit la base pour comprendre la portée et la complexité.
- Analyse des modèles de flux de travail : Identifiez comment les données circulent dans votre système actuel. Cela inclut les charges de travail par lots vs en flux continu, les dépendances de charges de travail et toute logique spécifique à la plateforme qui pourrait nécessiter une refonte.
- Priorisation et phasage de votre migration : Évitez une approche de type « big bang ». Au lieu de cela, divisez votre migration en phases gérables en fonction du risque, de l'impact commercial et de la préparation. Collaborez avec les équipes Databricks et les partenaires d'intégration certifiés pour construire un plan réaliste et à faible risque qui correspond à vos objectifs et à vos délais.
Stratégies de migration des données
Une migration de données réussie nécessite une approche réfléchie qui aborde à la fois les différences techniques entre les plateformes et les caractéristiques uniques de vos actifs de données. Les stratégies suivantes vous aideront à planifier et à exécuter un processus de migration efficace tout en maximisant les avantages de l'architecture de Databricks.
Traduction et optimisation des schémas
Évitez de copier directement les schémas Oracle sans repenser leur conception pour Databricks. Par exemple, le type de données NUMBER d'Oracle prend en charge une précision supérieure à celle autorisée par Databricks (précision et échelle maximales de 38). Dans de tels cas, il peut être plus approprié d'utiliser des types DOUBLE plutôt que d'essayer de conserver des correspondances exactes.
Traduire les schémas de manière réfléchie garantit la compatibilité et évite les problèmes de performance ou d'exactitude des données à long terme.
Pour plus de détails, consultez le Guide de migration Oracle vers Databricks.
Approches d'extraction et de chargement des données
Les migrations Oracle impliquent souvent le déplacement de données depuis des bases de données sur site vers Databricks, où la bande passante et le temps d'extraction peuvent devenir des goulots d'étranglement. Votre stratégie d'extraction doit correspondre au volume de données, à la fréquence des mises à jour et à la tolérance à l'interruption de service.
Les options courantes incluent :
- Connexions JDBC – utiles pour les petits ensembles de données ou les transferts à faible volume
- Lakehouse Federation – pour répliquer les data marts directement vers Databricks
- Azure Data Factory ou AWS Database Migration Services – pour le mouvement de données orchestré à grande échelle
- Outils d'exportation natifs Oracle :
- DBMS_CLOUD.EXPORT_DATA (disponible sur Oracle Cloud)
- Exportation SQL Developer (pour une utilisation locale ou sur site)
- Configuration manuelle de DBMS_CLOUD sur les déploiements sur site Oracle 19.9+
- Options de transfert en masse – telles que AWS Snowball ou Microsoft Data Box, pour déplacer de grandes tables historiques vers le cloud
Le choix de l'outil approprié dépend de la taille de vos données, des limites de connectivité et des besoins de récupération.
Optimisation des performances
Les données migrées doivent souvent être remodelées pour bien performer dans Databricks. Cela commence par une réflexion sur la manière dont les données sont partitionnées.
Si votre entrepôt de données Oracle utilisait des partitions statiques ou déséquilibrées, ces stratégies peuvent ne pas bien se traduire. Analysez vos modèles de requêtes et restructurez les partitions en conséquence. Databricks offre plusieurs techniques pour améliorer les performances :
- Liquid Clustering automatique pour une optimisation continue sans réglage manuel
- Z-Ordering pour le clustering sur des colonnes fréquemment filtrées
- Liquid Clustering pour organiser dynamiquement les données
De plus :
- Compressez les petits fichiers pour réduire la surcharge
- Séparez les données chaudes et froides pour optimiser les coûts et l'efficacité du stockage
- Évitez le sur-partitionnement, qui peut ralentir les analyses et augmenter la surcharge de métadonnées
Par exemple, le partitionnement basé sur des dates de transaction qui entraîne une distribution inégale des données peut être rééquilibré à l'aide du Liquid Clustering automatique, améliorant ainsi les performances des requêtes basées sur le temps.
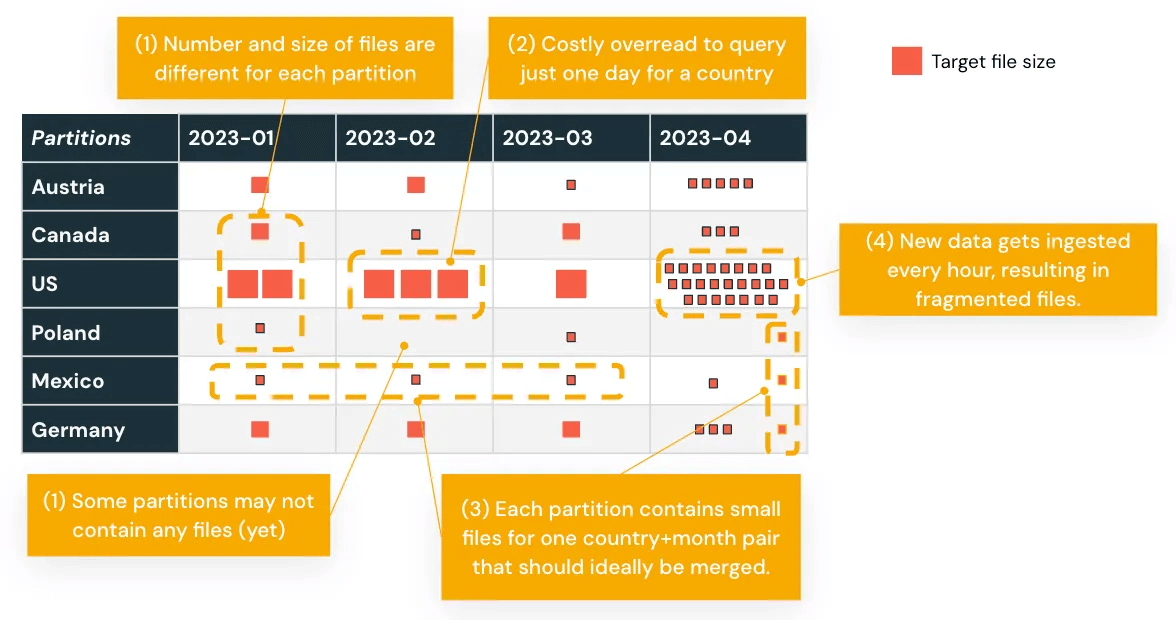
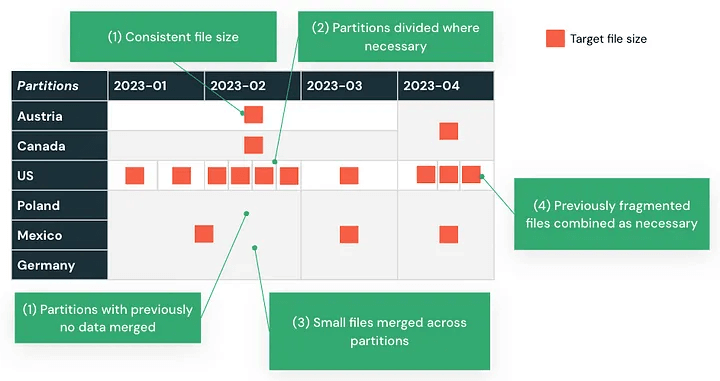
Concevoir en tenant compte du modèle de traitement de Databricks garantit que vos charges de travail évoluent efficacement et restent maintenables après la migration.
Migration du code et de la logique
Bien que la migration des données constitue la base de votre transition, le déplacement de votre logique applicative et de votre code SQL représente l'un des aspects les plus complexes de la migration d'Oracle vers Databricks. Ce processus implique la traduction de la syntaxe et l'adaptation à différents paradigmes de programmation et techniques d'optimisation qui s'alignent sur le modèle de traitement distribué de Databricks.
Stratégies de traduction SQL
Convertissez Oracle SQL en Databricks SQL en utilisant une approche structurée. Des outils automatisés comme BladeBridge (maintenant partie de Databricks) peuvent analyser la complexité du code et effectuer une traduction en masse. Selon la base de code, les taux de conversion typiques sont d'environ 75 % ou plus.
Ces outils aident à réduire l'effort manuel et à identifier les domaines qui nécessitent une retouche ou des changements architecturaux après la migration.
Migration des procédures stockées
Évitez d'essayer de trouver des remplacements exacts un pour un pour les constructions Oracle PL/SQL. Les packages comme DBMS_X, UTL_X, et CTX_X n'existent pas dans Databricks et nécessiteront de réécrire la logique pour l'adapter à la plateforme.
Pour les constructions courantes telles que :
- Curseurs
- Gestion des exceptions
- Boucles et instructions de contrôle de flux
Databricks propose désormais le Scripting SQL, qui prend en charge le SQL procédural dans les notebooks. Alternativement, envisagez de convertir ces flux de travail en Python ou Scala au sein de Databricks Workflows ou des pipelines DLT, qui offrent une plus grande flexibilité et une meilleure intégration avec le traitement distribué.
BladeBridge peut aider à traduire cette logique en notebooks Databricks SQL ou PySpark dans le cadre de la migration.
Transformation des flux de travail ETL
Databricks offre plusieurs approches pour construire des processus ETL qui simplifient les ETL Oracle hérités :
- Notebooks Databricks avec paramètres – pour des tâches ETL simples et modulaires
- DLT – pour définir des pipelines de manière déclarative avec prise en charge du traitement par lots et en flux continu, du traitement incrémental et des contrôles de qualité de données intégrés
- Databricks Workflows – pour la planification et l'orchestration au sein de la plateforme
Ces options offrent aux équipes la flexibilité nécessaire pour refactoriser et exploiter les flux ETL post-migration tout en s'alignant sur les modèles modernes d'ingénierie des données.
Post-migration : validation, optimisation et adoption
Valider avec des tests techniques et métier
Après la migration d'un cas d'utilisation, il est essentiel de valider que tout fonctionne comme prévu, tant sur le plan technique que fonctionnel.
- La validation technique doit inclure :
- La réconciliation du nombre de lignes et des agrégats entre les systèmes
- Des vérifications de complétude et de qualité des données
- La comparaison des résultats des requêtes entre les plateformes source et cible
- La validation métier consiste à exécuter les deux systèmes en parallèle et à faire confirmer par les parties prenantes que les sorties correspondent aux attentes avant le basculement.
Optimiser pour le coût et la performance
Après la validation, évaluez et ajustez l'environnement en fonction des charges de travail réelles. Les domaines d'intervention comprennent :
- Les stratégies de partitionnement et de clustering (par exemple, Z-Ordering, Liquid Clustering)
- L'optimisation de la taille et du format des fichiers
- La configuration des ressources et les politiques de mise à l'échelle. Ces ajustements permettent d'aligner l'infrastructure sur les objectifs de performance et les cibles de coûts.
Transfert de connaissances et préparation organisationnelle
Une migration réussie ne s'arrête pas à l'implémentation technique. Il est tout aussi important de s'assurer que les équipes peuvent utiliser efficacement la nouvelle plateforme.
- Planifier la formation pratique et la documentation
- Permettre aux équipes d'adopter de nouveaux flux de travail, y compris le développement collaboratif, la logique basée sur les notebooks et les pipelines déclaratifs
- Attribuer la responsabilité de la qualité des données, de la gouvernance et de la surveillance des performances dans le nouveau système
La migration est plus qu'un changement technique
Migrer d'Oracle vers Databricks n'est pas seulement un changement de plateforme, c'est une évolution dans la manière dont les données sont gérées, traitées et consommées.
Une planification minutieuse, une exécution par phases et une coordination étroite entre les équipes techniques et les parties prenantes métier sont essentielles pour réduire les risques et assurer une transition en douceur.
Il est tout aussi important de préparer votre organisation à travailler différemment : adopter de nouveaux outils, de nouveaux processus et un nouvel état d'esprit autour de l'analytique ou de l'IA. En mettant l'accent sur l'implémentation et l'adoption, votre équipe peut libérer toute la valeur d'une architecture lakehouse moderne.
Conseils pratiques de Deloitte
Deloitte a partagé des conseils pratiques pour la migration d'un entrepôt de données hérité vers Databricks dans ce webinaire. Regardez-le pour découvrir comment la migration s'est déroulée dans une entreprise mondiale de financement automobile ! Les points forts incluent :
- la mise en œuvre et la modernisation de la plateforme d'analyse cloud avec des contrôles de confidentialité cyber et PII
- l'exploitation du framework piloté par les métadonnées de Databricks Unity Catalog pour configurer les pipelines ELT afin de stocker les données dans le lakehouse
- l'intégration de Databricks Workflows avec ServiceNow pour une surveillance et une gestion des erreurs simplifiées
Prochaines étapes
La migration est rarement simple. Les compromis, les retards et les défis imprévus font partie du processus, surtout lorsqu'il s'agit d'aligner les personnes, les processus et la technologie.
C'est pourquoi il est important de travailler avec des équipes qui ont déjà effectué ce type de migration. Databricks Professional Services et nos partenaires de migration certifiés apportent une expérience approfondie dans la réalisation de migrations de haute qualité, dans les délais et à grande échelle. Contactez-nous pour démarrer votre évaluation de migration.
Vous cherchez plus de conseils ? Téléchargez le Guide de migration Oracle vers Databricks complet pour des étapes pratiques, des informations sur les outils et des modèles de planification pour vous aider à avancer en toute confiance.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.