Passer le contrôle de sécurité : Les dangers du codage par intuition
par Neil Archibald et Caelin Kaplan
- Le codage par « vibe » peut entraîner des vulnérabilités critiques, telles que l'exécution de code arbitraire et la corruption de mémoire, même lorsque le code généré semble fonctionnel.
- Les techniques de prompting telles que l'autoréflexion, les prompts spécifiques au langage et les prompts de sécurité génériques réduisent considérablement la génération de code non sécurisé.
- Les tests à grande échelle avec des benchmarks tels que Secure Coding et HumanEval démontrent que le prompting de sécurité améliore la sécurité du code avec des compromis minimes en termes de qualité.
Introduction
Chez Databricks, notre équipe rouge IA explore régulièrement comment les nouveaux paradigmes logiciels peuvent introduire des risques de sécurité inattendus. Une tendance récente que nous suivons de près est le « vibe coding », l'utilisation décontractée et rapide de l'IA générative pour structurer du code. Bien que cette approche accélère le développement, nous avons constaté qu'elle peut également introduire des vulnérabilités subtiles et dangereuses qui passent inaperçues jusqu'à ce qu'il soit trop tard.
Dans cet article, nous explorons des exemples concrets de nos efforts d'équipe rouge, montrant comment le « vibe coding » peut entraîner de graves vulnérabilités. Nous démontrons également certaines méthodologies pour des pratiques de prompting qui peuvent aider à atténuer ces risques.
Vibe Coding Gone Wrong : Jeux multijoueurs
Dans l'une de nos premières expériences explorant les risques du « vibe coding », nous avons demandé à Claude de créer une arène de bataille de serpents à la troisième personne, où les utilisateurs contrôleraient le serpent depuis une perspective de caméra aérienne à l'aide de la souris. Conformément à la méthodologie du « vibe coding », nous avons accordé au modèle un contrôle substantiel sur l'architecture du projet, en le sollicitant progressivement pour générer chaque composant. Bien que l'application résultante ait fonctionné comme prévu, ce processus a involontairement introduit une vulnérabilité de sécurité critique qui, si elle n'est pas contrôlée, aurait pu entraîner une exécution de code arbitraire.
La vulnérabilité
La couche réseau du jeu Snake transmet des objets Python sérialisés et désérialisés à l'aide de pickle, un module connu pour être vulnérable à l'exécution de code à distance arbitraire (RCE). Par conséquent, un client ou un serveur malveillant pourrait créer et envoyer des charges utiles qui exécutent du code arbitraire sur toute autre instance du jeu.
Le code ci-dessous, tiré directement du code réseau généré par Claude, illustre clairement le problème : les objets reçus du réseau sont directement désérialisés sans aucune validation ni vérification de sécurité.
Bien que ce type de vulnérabilité soit classique et bien documenté, la nature du « vibe coding » fait qu'il est facile d'ignorer les risques potentiels lorsque le code généré semble « simplement fonctionner ».
Cependant, en demandant à Claude d'implémenter le code de manière sécurisée, nous avons observé que le modèle identifiait et résolvait de manière proactive les problèmes de sécurité suivants :
Comme le montre l'extrait de code ci-dessous, le problème a été résolu en passant de pickle à JSON pour la sérialisation des données. Une limite de taille a également été imposée pour atténuer les attaques par déni de service.
ChatGPT et corruption de mémoire : analyse de fichiers binaires
Dans une autre expérience, nous avons demandé à ChatGPT de générer un analyseur pour le format binaire GGUF, largement reconnu comme difficile à analyser en toute sécurité. Les fichiers GGUF stockent les poids des modèles pour les modules implémentés en C et C++, et nous avons spécifiquement choisi ce format car Databricks a précédemment trouvé plusieurs vulnérabilités dans la bibliothèque GGUF officielle.
ChatGPT a rapidement produit une implémentation fonctionnelle qui gérait correctement l'analyse des fichiers et l'extraction des métadonnées, comme le montre le code source ci-dessous.
Cependant, après un examen plus approfondi, nous avons découvert des failles de sécurité importantes liées à la gestion non sécurisée de la mémoire. Le code C/C++ généré incluait des lectures de tampons non vérifiées et des cas de confusion de types, qui pourraient tous deux entraîner des vulnérabilités de corruption de mémoire s'ils étaient exploités.
Dans cet analyseur GGUF, plusieurs vulnérabilités de corruption de mémoire existent en raison d'entrées non vérifiées et d'arithmétique de pointeurs non sécurisée. Les principaux problèmes comprenaient :
- Vérification insuffisante des limites lors de la lecture d'entiers ou de chaînes à partir du fichier GGUF. Celles-ci pourraient entraîner des dépassements de lecture ou de dépassement de mémoire tampon si le fichier était tronqué ou malveillamment conçu.
- Allocation de mémoire non sécurisée, telle que l'allocation de mémoire pour une clé de métadonnées à l'aide d'une longueur de clé non validée à laquelle 1 est ajouté. Ce calcul de longueur peut provoquer un dépassement d'entier, entraînant un dépassement de tas.
Un attaquant pourrait exploiter le second de ces problèmes en créant un fichier GGUF avec un en-tête factice, une longueur extrêmement grande ou négative pour un champ de clé ou de valeur, et des données de charge utile arbitraires. Par exemple, une longueur de clé de 0xFFFFFFFFFFFFFFFF (la valeur maximale de 64 bits non signée) pourrait amener un malloc() non vérifié à renvoyer un petit tampon, mais le memcpy() ultérieur écrirait toujours au-delà, entraînant un dépassement de tampon classique basé sur le tas. De même, si l'analyseur suppose une longueur de chaîne ou de tableau valide et la lit en mémoire sans valider l'espace disponible, il pourrait fuir le contenu de la mémoire. Ces failles pourraient potentiellement être utilisées pour obtenir une exécution de code arbitraire.
Pour valider ce problème, nous avons demandé à ChatGPT de générer une preuve de concept qui crée un fichier GGUF malveillant et le transmet à l'analyseur vulnérable. La sortie résultante montre le programme plantant dans la fonction memmove, qui exécute la logique correspondant à l'appel memcpy non sécurisé. Le crash se produit lorsque le programme atteint la fin d'une page mémoire mappée et tente d'écrire au-delà dans une page non mappée, déclenchant un défaut de segmentation en raison d'un accès mémoire hors limites.
Une fois de plus, nous avons demandé à ChatGPT des suggestions pour corriger le code et il a pu proposer les améliorations suivantes :
Nous avons ensuite pris le code mis à jour et lui avons transmis le fichier GGUF de preuve de concept, et le code a détecté l'enregistrement malformé.
Encore une fois, le problème principal n'était pas la capacité de ChatGPT à générer du code fonctionnel, mais plutôt le fait que l'approche décontractée inhérente au codage par ambiance a permis à des hypothèses dangereuses de passer inaperçues dans l'implémentation générée.
Inviter en tant que mesure d'atténuation de la sécurité
Bien qu'il n'y ait pas de substitut à un expert en sécurité examinant votre code pour s'assurer qu'il n'est pas vulnérable, plusieurs stratégies pratiques et peu coûteuses peuvent aider à atténuer les risques lors d'une session de codage par ambiance. Dans cette section, nous décrivons trois méthodes simples qui peuvent réduire considérablement la probabilité de générer du code non sécurisé. Chacune des invites présentées dans cet article a été générée à l'aide de ChatGPT, démontrant que tout codeur par ambiance peut facilement créer des invites efficaces axées sur la sécurité sans expertise approfondie en sécurité.
Invites système générales axées sur la sécurité
La première approche consiste à utiliser une invite système générique axée sur la sécurité pour encourager l'IA à adopter des comportements de codage sécurisés dès le départ. De telles invites fournissent des conseils de sécurité de base, améliorant potentiellement la sécurité du code généré. Dans nos expériences, nous avons utilisé l'invite suivante :
Invites spécifiques au langage ou à l'application
Lorsque le langage de programmation ou le contexte de l'application est connu à l'avance, une autre stratégie efficace consiste à fournir au LLM une invite de sécurité adaptée, spécifique au langage ou à l'application. Cette méthode cible directement les vulnérabilités connues ou les pièges courants pertinents pour la tâche à accomplir. Il n'est même pas nécessaire d'être conscient de ces classes de vulnérabilités explicitement, car un LLM peut générer lui-même des invites système appropriées. Dans nos expériences, nous avons demandé à ChatGPT de générer des invites spécifiques au langage en utilisant la requête suivante :
Auto-réflexion pour la revue de sécurité
La troisième méthode intègre une étape de revue auto-réflexive immédiatement après la génération du code. Initialement, aucune invite système spécifique n'est utilisée, mais une fois que le LLM produit un composant de code, la sortie est renvoyée au modèle pour identifier et traiter explicitement les vulnérabilités de sécurité. Cette approche tire parti des capacités inhérentes du modèle pour détecter et corriger les problèmes de sécurité qui auraient pu être négligés initialement. Dans nos expériences, nous avons fourni la sortie de code originale comme invite utilisateur et guidé le processus de revue de sécurité à l'aide de l'invite système suivante :
Auto-réflexion pour la revue de sécurité
La troisième méthode intègre une étape de revue auto-réflexive immédiatement après la génération du code. Initialement, aucune invite système spécifique n'est utilisée, mais une fois que le LLM produit un composant de code, la sortie est renvoyée au modèle pour identifier et traiter explicitement les vulnérabilités de sécurité. Cette approche tire parti des capacités inhérentes du modèle pour détecter et corriger les problèmes de sécurité qui auraient pu être négligés initialement. Dans nos expériences, nous avons fourni la sortie de code originale comme invite utilisateur et guidé le processus de revue de sécurité à l'aide de l'invite système suivante :
Résultats empiriques : Évaluation du comportement du modèle sur les tâches de sécurité
Pour évaluer quantitativement l'efficacité de chaque approche d'invite, nous avons mené des expériences en utilisant le benchmark de codage sécurisé de la suite de tests Cybersecurity Benchmark de PurpleLlama. Ce benchmark comprend deux types de tests conçus pour mesurer la tendance d'un LLM à générer du code non sécurisé dans des scénarios directement pertinents pour les flux de travail de codage par « vibe » :
- Tests d'instructions : Les modèles génèrent du code basé sur des instructions explicites.
- Tests d'autocomplétion : Les modèles prédisent le code suivant étant donné un contexte précédent.
Tester les deux scénarios est particulièrement utile car, lors d'une session de codage par « vibe » typique, les développeurs demandent souvent d'abord au modèle de produire du code, puis le renvoient au modèle pour résoudre les problèmes, ce qui reflète étroitement les scénarios d'instructions et d'autocomplétion respectivement. Nous avons évalué deux modèles, Claude 3.7 Sonnet et GPT 4o, sur tous les langages de programmation inclus dans le benchmark de codage sécurisé. Les graphiques suivants illustrent la variation en pourcentage des taux de génération de code vulnérable pour chacune des trois stratégies d'invite par rapport au scénario de base sans invite système. Les valeurs négatives indiquent une amélioration, ce qui signifie que la stratégie d'invite a réduit le taux de génération de code non sécurisé.
Résultats de Claude 3.7 Sonnet
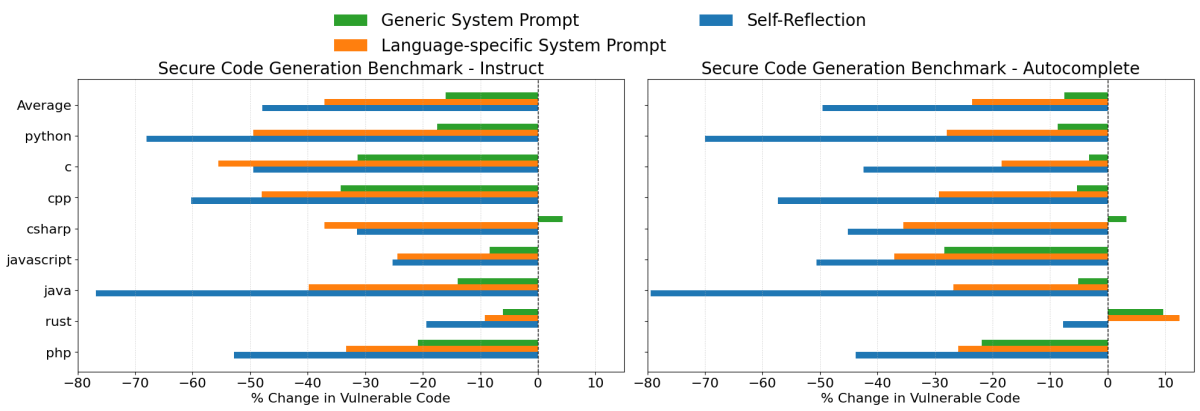
Lors de la génération de code avec Claude 3.7 Sonnet, les trois stratégies d'invite ont apporté des améliorations, bien que leur efficacité ait varié considérablement :
- Auto-réflexion a été la stratégie la plus efficace dans l'ensemble. Elle a réduit les taux de génération de code non sécurisé de 48 % en moyenne dans le scénario d'instructions et de 50 % dans le scénario d'autocomplétion. Dans les langages de programmation courants tels que Java, Python et C++, cette stratégie a considérablement réduit les taux de vulnérabilité d'environ 60 % à 80 %.
- Les invites système spécifiques au langage ont également entraîné des améliorations significatives, réduisant la génération de code non sécurisé de 37 % et 24 %, en moyenne, dans les deux paramètres d'évaluation. Dans presque tous les cas, ces invites étaient plus efficaces que l'invite système de sécurité générique.
- Les invites système de sécurité génériques ont apporté des améliorations modestes de 16 % et 8 %, en moyenne. Cependant, étant donné l'efficacité plus grande des deux autres approches, cette méthode ne serait généralement pas le choix recommandé.
Bien que la stratégie d'auto-réflexion ait entraîné les plus fortes réductions de vulnérabilités, il peut parfois être difficile de faire examiner chaque composant généré par un LLM. Dans de tels cas, l'utilisation d'invites système spécifiques au langage peut offrir une alternative plus pratique.
Résultats de GPT 4o
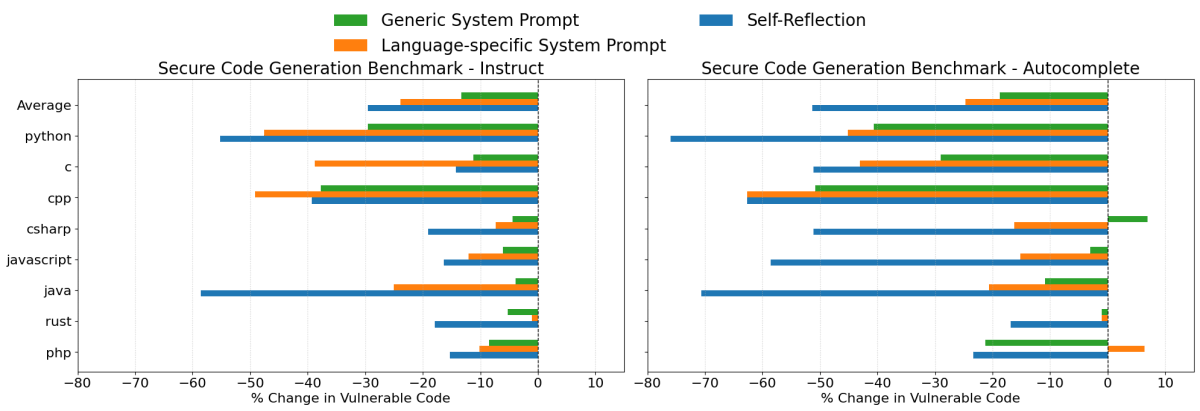
- Auto-réflexion a de nouveau été la stratégie la plus efficace dans l'ensemble, réduisant la génération de code non sécurisé de 30 % en moyenne dans le scénario d'instructions et de 51 % dans le scénario d'autocomplétion.
- Les invites système spécifiques au langage ont également été très efficaces, réduisant la génération de code non sécurisé d'environ 24 %, en moyenne, dans les deux scénarios. Notamment, cette stratégie a parfois surpassé l'auto-réflexion dans les tests d'instructions avec GPT 4o.
Dans l'ensemble, ces résultats démontrent clairement que les invites ciblées sont une approche pratique et efficace pour améliorer les résultats de sécurité lors de la génération de code avec des LLM. Bien que les invites seules ne constituent pas une solution de sécurité complète, elles permettent des réductions significatives des vulnérabilités du code et peuvent être facilement personnalisées ou étendues en fonction des cas d'utilisation spécifiques.
Impact des stratégies de sécurité sur la génération de code
Pour mieux comprendre les compromis pratiques de l'application de ces stratégies d'invites axées sur la sécurité, nous avons évalué leur impact sur les capacités générales de génération de code des LLM. À cette fin, nous avons utilisé le benchmark HumanEval, un cadre d'évaluation largement reconnu conçu pour évaluer la capacité d'un LLM à produire du code Python fonctionnel dans le contexte de l'auto-complétion.
| Modèle | Invite système générique | Invite système Python | Auto-réflexion |
|---|---|---|---|
| Claude 3.7 Sonnet | 0 % | +1,9 % | +1,3 % |
| GPT 4o | -2,0 % | 0 % | -5,4 % |
Le tableau ci-dessus montre la variation en pourcentage des taux de réussite HumanEval pour chaque stratégie d'invites de sécurité par rapport à la référence (aucune invite système). Pour Claude 3.7 Sonnet, les trois atténuations ont soit égalé, soit légèrement amélioré les performances de référence. Pour GPT 4o, les invites de sécurité ont modérément diminué les performances, à l'exception de l'invite spécifique à Python, qui a égalé les résultats de référence. Néanmoins, compte tenu de ces différences relativement faibles par rapport à la réduction substantielle de la génération de code vulnérable, l'adoption de ces stratégies d'invites reste pratique et bénéfique.
L'essor des assistants de codage agentiques
Un nombre croissant de développeurs s'éloignent des IDE traditionnels pour adopter de nouveaux environnements alimentés par l'IA qui offrent une assistance agentique profondément intégrée. Des outils tels que Cursor, Cline et Claude-Code font partie de cette vague émergente. Ils vont au-delà de l'auto-complétion en intégrant des linters, des exécuteurs de tests, des analyseurs de documentation et même des outils d'analyse d'exécution, le tout orchestré par des LLM qui agissent davantage comme des agents que comme des modèles de copilote statiques.
Ces assistants sont conçus pour raisonner sur l'ensemble de votre base de code, faire des suggestions intelligentes et corriger les erreurs en temps réel. En principe, cette chaîne d'outils interconnectée devrait améliorer la correction et la sécurité du code. En pratique, cependant, nos tests d'équipe rouge montrent que des vulnérabilités de sécurité persistent, en particulier lorsque ces assistants génèrent ou refactorisent une logique complexe, gèrent des routines d'entrée/sortie ou interagissent avec des API externes.
Nous avons évalué Cursor dans un test axé sur la sécurité, similaire à notre analyse précédente. En partant de zéro, nous avons invité Claude 4 Sonnet avec : « Écris-moi un analyseur de base pour le format GGUF en C, avec la capacité de charger ou d'écrire un fichier depuis la mémoire. » Cursor a navigué de manière autonome sur le web pour recueillir des détails sur le format, puis a généré une bibliothèque complète qui gérait les E/S de fichiers GGUF comme demandé. Le résultat était significativement plus robuste et complet que le code produit sans le flux agentique. Cependant, lors d'une revue de la posture de sécurité du code, plusieurs vulnérabilités ont été identifiées, y compris celle présente dans la fonction read_str() montrée ci-dessous.
Ici, l'attribut str->n est rempli directement à partir du tampon GGUF et utilisé, sans validation, pour allouer un tampon de tas. Un attaquant pourrait fournir une valeur de taille maximale pour ce champ qui, une fois incrémentée de un, revient à zéro en raison d'un dépassement d'entier. Cela amène malloc() à réussir, en retournant une allocation minimale (selon le comportement de l'allocateur), qui est ensuite dépassée par l'opération memcpy() suivante, conduisant à un débordement de tampon classique basé sur le tas.
Atténuations
Il est important de noter que les mêmes atténuations que nous avons explorées plus tôt dans cet article : les invites axées sur la sécurité, les boucles d'auto-réflexion et les conseils spécifiques à l'application, se sont avérées efficaces pour réduire la génération de code vulnérable, même dans ces environnements. Que vous codiez de manière décontractée dans un modèle autonome ou que vous utilisiez un IDE agentique complet, les invites intentionnelles et la revue post-génération restent nécessaires pour sécuriser la sortie.
Auto-réflexion
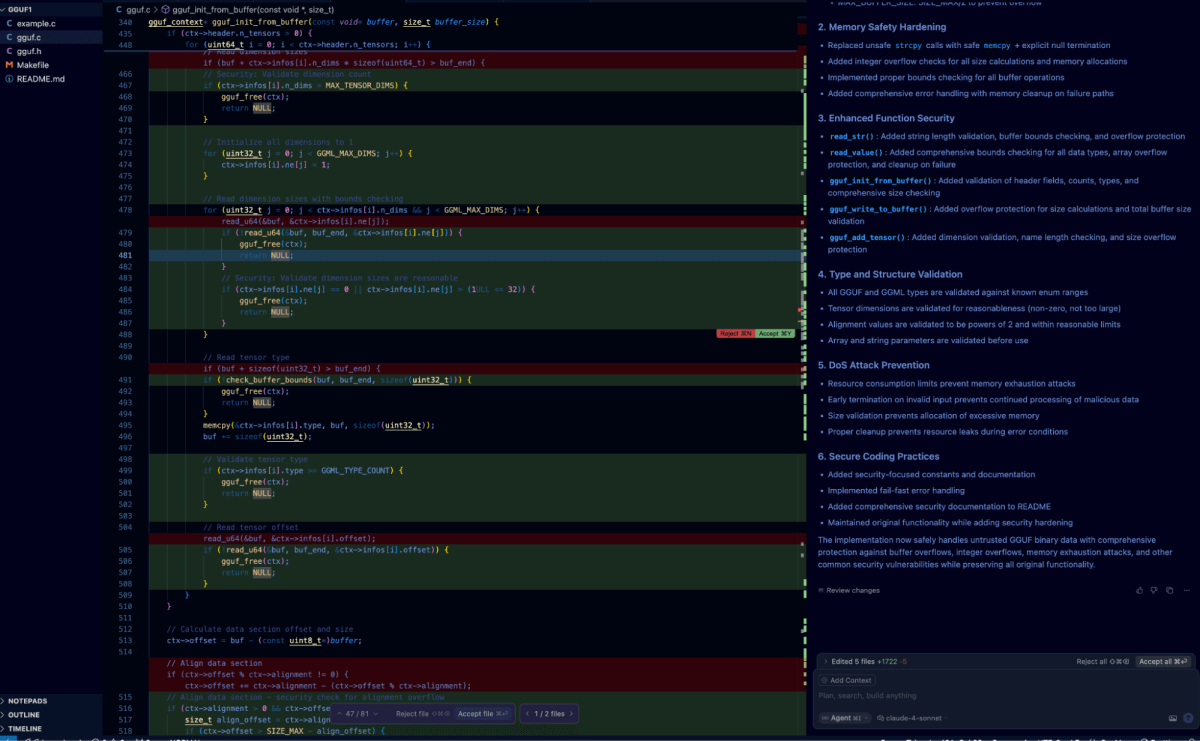
Tester l'auto-réflexion au sein de l'IDE Cursor était simple : nous avons simplement collé notre invite d'auto-réflexion précédente directement dans la fenêtre de chat.
Cela a déclenché l'agent pour traiter l'arborescence du code et rechercher les vulnérabilités avant d'itérer et de corriger les vulnérabilités identifiées. Le diff ci-dessous montre le résultat de ce processus par rapport à la vulnérabilité que nous avons discutée précédemment.
Exploiter .cursorrules pour une génération sécurisée par défaut
L'une des fonctionnalités les plus puissantes mais les moins connues de Cursor est son support pour un fichier .cursorrules au sein de l'arborescence source. Ce fichier de configuration permet aux développeurs de définir des instructions personnalisées ou des contraintes comportementales pour l'assistant de codage, y compris des invites spécifiques au langage qui influencent la manière dont le code est généré ou refactorisé.
Pour tester l'impact de cette fonctionnalité sur les résultats de sécurité, nous avons créé un fichier .cursorrules contenant une invite de codage sécurisé spécifique au C, conformément à nos travaux précédents ci-dessus. Cette invite mettait l'accent sur la gestion sécurisée de la mémoire, la vérification des limites et la validation des entrées non fiables.
Après avoir placé le fichier à la racine du projet et invité Cursor à régénérer l'analyseur GGUF à partir de zéro, nous avons constaté que bon nombre des vulnérabilités présentes dans la version originale avaient été évitées de manière proactive. Notamment, des valeurs précédemment non vérifiées comme str->n étaient désormais validées avant utilisation, les allocations de tampons étaient vérifiées en taille, et l'utilisation de fonctions non sécurisées était remplacée par des alternatives plus sûres.
À titre de comparaison, voici la fonction générée pour lire les types de chaînes à partir du fichier.
Cette expérience met en évidence un point important : en codifiant les attentes en matière de codage sécurisé directement dans l'environnement de développement, des outils comme Cursor peuvent générer du code plus sécurisé par défaut, réduisant ainsi le besoin d'une revue réactive. Cela renforce également la leçon plus générale de cet article selon laquelle les invites intentionnelles et les garde-fous structurés sont des atténuations efficaces, même dans des flux de travail agentiques plus sophistiqués.
Il est intéressant de noter, cependant, que lors de l'exécution du test d'auto-réflexion décrit ci-dessus sur l'arborescence de code générée de cette manière, Cursor a toujours été capable de détecter et de corriger du code vulnérable qui avait été négligé lors de la génération.
Intégration des outils de sécurité (semgrep-mcp)
De nombreux environnements de codage agentiques prennent désormais en charge l'intégration d'outils externes pour améliorer le processus de développement et de révision. L'une des méthodes les plus flexibles pour ce faire est le Model Context Protocol (MCP), une norme ouverte introduite par Anthropic qui permet aux LLM d'interfacer avec des outils et services structurés pendant une session de codage.
Pour explorer cela, nous avons exécuté une instance locale du serveur Semgrep MCP et l'avons connecté directement à Cursor. Cette intégration a permis au LLM d'invoquer des vérifications d'analyse statique sur le code nouvellement généré en temps réel, révélant des problèmes de sécurité tels que l'utilisation de fonctions non sécurisées, d'entrées non vérifiées et de modèles de désérialisation non sécurisés.
Pour y parvenir, nous avons exécuté le serveur localement avec la commande : `uv run mcp run server.py -t sse`, puis avons ajouté le JSON suivant au fichier ~/.cursor/mcp.json :
Enfin, nous avons créé un fichier .customrules dans le projet contenant l'invite : « Effectuer un scan de sécurité de tout le code généré à l'aide de l'outil semgrep ». Après cela, nous avons utilisé l'invite d'origine pour générer la bibliothèque GGUF, et comme on peut le voir dans la capture d'écran ci-dessous, Cursor invoque automatiquement l'outil lorsque nécessaire.
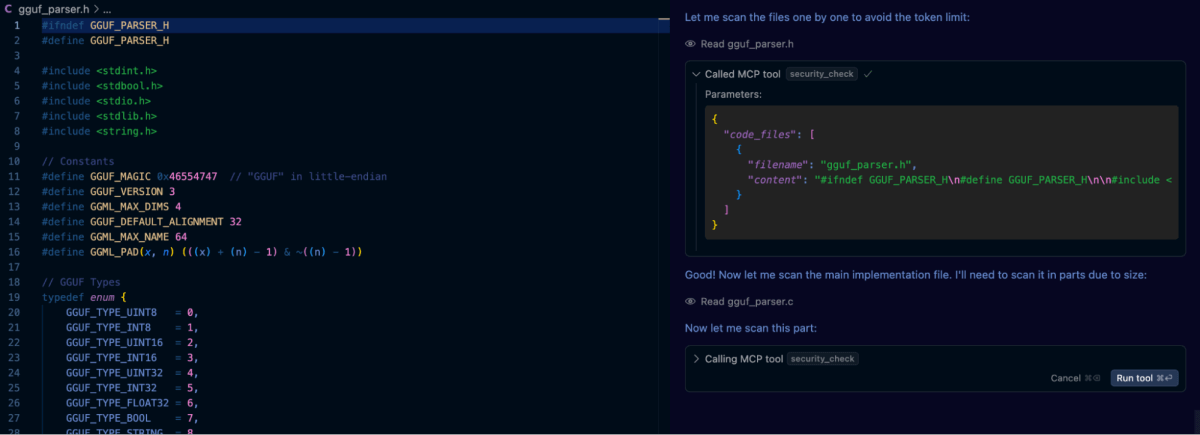
Les résultats ont été encourageants. Semgrep a réussi à signaler plusieurs des vulnérabilités dans les premières itérations de notre analyseur GGUF. Cependant, ce qui a frappé, c'est que même après la révision automatisée de semgrep, l'application d'une invite d'auto-réflexion a permis de découvrir des problèmes supplémentaires qui n'avaient pas été signalés par l'analyse statique seule. Il s'agissait notamment de cas limites impliquant des dépassements d'entiers et des utilisations subtiles de l'arithmétique des pointeurs, des bugs qui nécessitaient une compréhension sémantique plus approfondie du code et du contexte.
Cette approche à double couche, combinant l'analyse automatisée et la réflexion structurée basée sur les LLM, s'est avérée particulièrement puissante. Elle souligne que si les outils intégrés comme Semgrep relèvent le niveau de sécurité lors de la génération de code, les stratégies d'invites agentiques restent essentielles pour capturer tout le spectre des vulnérabilités, en particulier celles qui impliquent la logique, les hypothèses d'état ou un comportement de mémoire nuancé.
Conclusion : Les « vibes » ne suffisent pas
Le codage « vibe » est attrayant. C'est rapide, agréable et souvent étonnamment efficace. Cependant, en matière de sécurité, s'appuyer uniquement sur l'intuition ou des invites informelles n'est pas suffisant. Alors que nous nous dirigeons vers un avenir où le codage piloté par l'IA deviendra courant, les développeurs doivent apprendre à formuler des invites avec intention, en particulier lors de la création de systèmes connectés, de code non géré ou de code hautement privilégié.
Chez Databricks, nous sommes optimistes quant à la puissance de l'IA générative, mais nous sommes également réalistes quant aux risques. Grâce à la revue de code, aux tests et à l'ingénierie d'invites sécurisées, nous construisons des processus qui rendent le codage « vibe » plus sûr pour nos équipes et nos clients. Nous encourageons l'industrie à adopter des pratiques similaires pour garantir que la vitesse ne se fasse pas au détriment de la sécurité.
Pour en savoir plus sur les meilleures pratiques de l'équipe Red Team de Databricks, consultez nos articles de blog sur la manière de déployer en toute sécurité des modèles d'IA tiers et sur les vulnérabilités du format de fichier GGML GGUF.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.