Prise de décision en temps réel pour les agents d'IA : Pourquoi vous avez d'abord besoin d'une couche de contexte client
Une perspective Snowplow sur "The New Martech Stack for the AI Age" de Scott Brinker
par Alex Dean
- Scott Brinker a récemment publié un rapport de recherche avec Databricks, The New Martech “Stack” for the AI Age, qui a décrit un passage de 3 à 5 ans des architectures rigides à une toile composable et fluide pour l'architecture marketing.
- Alex Dean, co-fondateur et PDG de Snowplow, partage sa perspective sur la façon dont la couche de contexte client capture les données comportementales en temps réel que les agents IA utilisent pour les décisions instantanées.
- La boucle de rétroaction des agents transforme le marketing en un volant : collectez et unifiez les comportements humains et IA en temps réel, activez-les pour la prise de décision, puis fermez la boucle afin que les agents apprennent et s'améliorent continuellement en fonction des résultats.
Le nouveau rapport de Scott Brinker avec Databricks expose quelque chose que j'observe se concrétiser depuis des années : le "stack" martech, cet arrangement familier de blocs façon Tetris, commence à se dissoudre. Ce qui émerge à sa place est ce que Scott appelle une toile composable : une architecture fluide et centrée sur les données, où les agents IA et les logiciels personnalisés opèrent sur des données partagées plutôt que de se battre à travers des pipelines d'intégration.
En le lisant, j'ai hoché la tête plus d'une fois. Pas parce que c'est une thèse facile à formuler (c'est en fait un ré-encadrement assez radical de la façon dont les entreprises pensent la technologie marketing), mais parce qu'elle décrit une direction architecturale à laquelle nous, chez Snowplow, nous sommes engagés il y a longtemps, souvent avant qu'il y ait un vocabulaire partagé pour cela.
Je voulais partager quelques réactions : là où le rapport résonne fortement, comment nous pensons que Snowplow s'intègre dans l'architecture qu'il décrit, et une dimension que j'ajouterais au modèle et qui, je pense, devient plus importante à mesure que les agents IA assument un rôle plus important dans les interactions client.
La plateforme de données est désormais le centre de gravité pour la prise de décision en temps réel
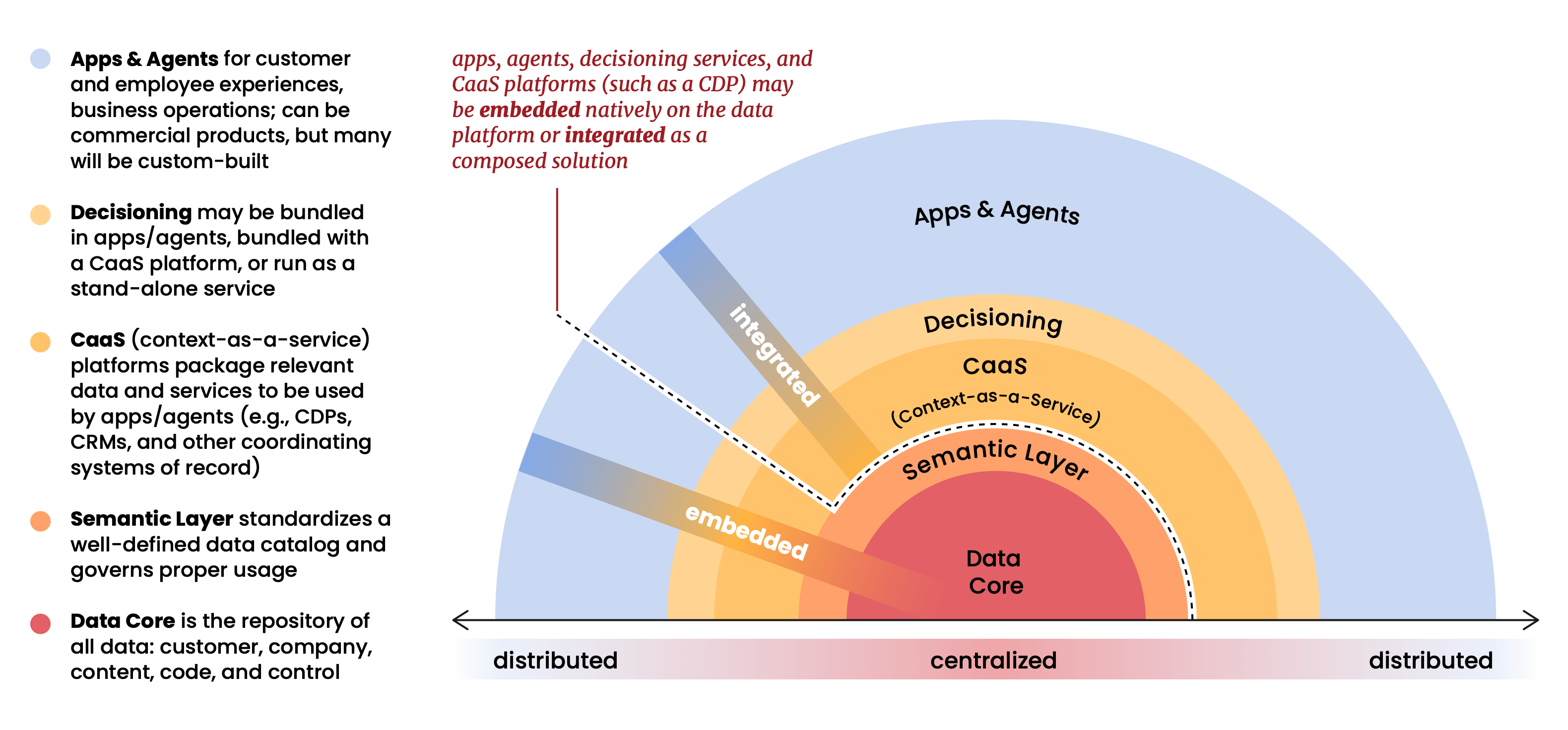
L'argument structurel central du rapport est que la plateforme de données (Databricks, Snowflake, BigQuery, etc.) est devenue le centre de gravité de l'ensemble du stack martech. Les applications, les agents et les analyses ne reposent plus sur les données ; ils opèrent à l'intérieur. La plateforme de données n'est plus un dépôt au bas du stack. C'est le stack.
C'est une vision que nous avons chez Snowplow depuis longtemps, et elle a façonné de nombreuses décisions initiales sur la façon dont nous avons construit notre produit. Lorsque nous avons assemblé Snowplow pour la première fois en 2012, le modèle dominant était d'accumuler les données client dans les systèmes des fournisseurs et de fournir un accès géré. Nous avons adopté la position opposée : vos données appartiennent à votre infrastructure, régies par vos règles, interrogeables par l'outil de votre choix. À l'époque, cela semblait être une position architecturale de principe, peut-être même un peu à contre-courant. Comme ce rapport le montre clairement, c'est maintenant la seule architecture qui a du sens à grande échelle.
Qu'est-ce que la couche de contexte client ? Et pourquoi la prise de décision en temps réel en dépend
Qu'est-ce que la couche de contexte client ? La couche de contexte client est l'infrastructure comportementale en temps réel qui se situe entre votre fondation de données et vos systèmes orientés client. Elle est directement connectée aux expériences numériques afin que les agents IA puissent comprendre ce qu'un client fait en ce moment, en plus de son parcours historique complet.
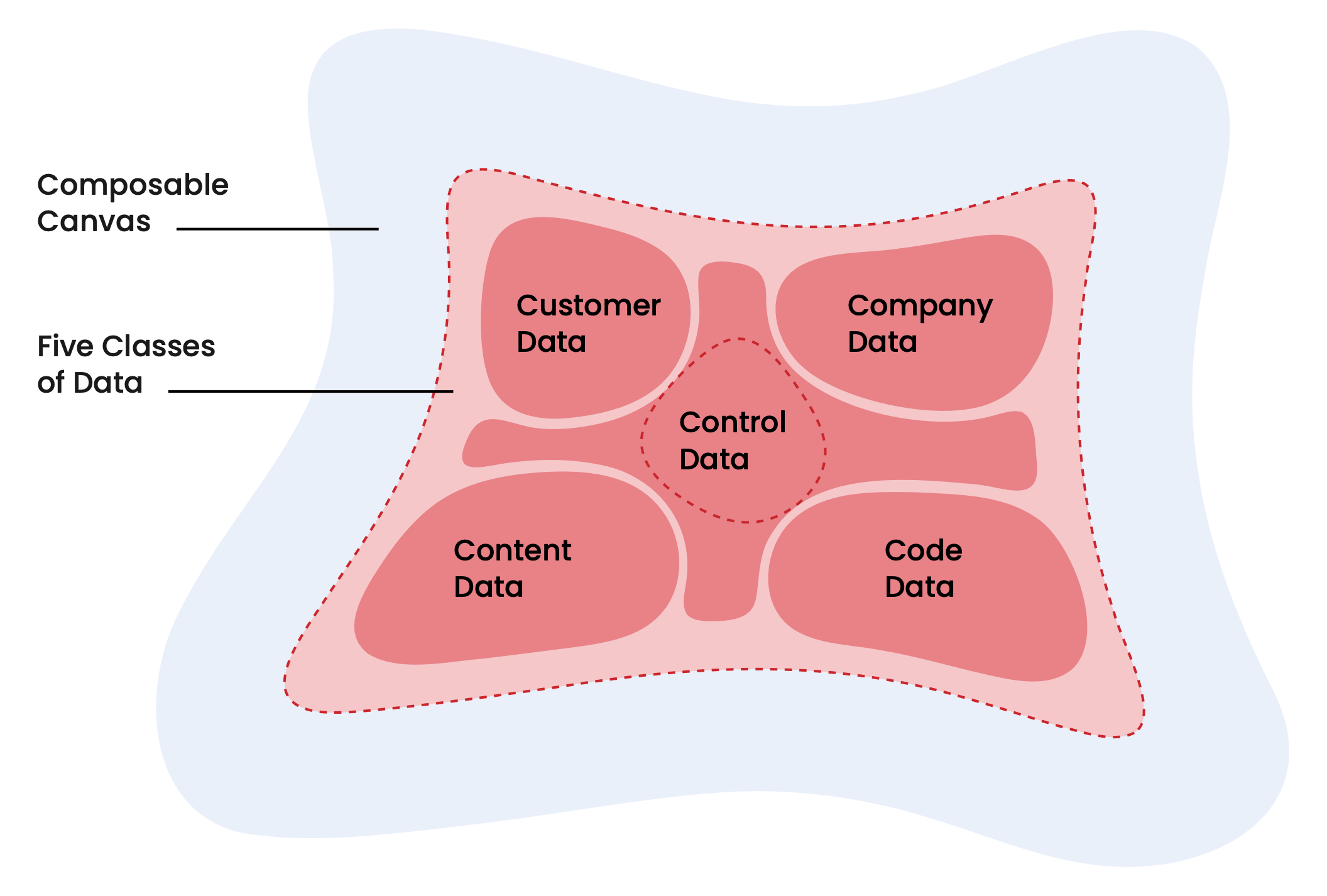
Le rapport décrit cinq classes de données convergeant sur la fondation unifiée : données client, données d'entreprise, données de contenu, données de code et données de contrôle. Les données client : "profils individuels et de compte, historiques de transactions, signaux comportementaux (visites web, utilisation du produit)" sont au cœur de tout cela.
C'est là que Snowplow opère. Mais je pousserais le cadrage légèrement plus loin que le rapport.
Il y a une différence significative entre les enregistrements client et le contexte client. Les CRM et les CDP gèrent depuis longtemps bien le premier : qui est le client, quelles affaires il a, à quels segments il appartient. Ce qui a toujours été plus difficile à fournir, c'est le second, c'est-à-dire : que fait-il en ce moment, et que vous dit ce comportement sur son intention ?
Les flux d'événements comportementaux, l'enregistrement continu et granulaire de la manière dont les clients interagissent avec votre produit, votre site web, votre application, sont le signal en temps réel le plus riche disponible pour tout agent IA essayant de prendre une décision. Et ils sont notoirement difficiles à bien réaliser. Les événements doivent être structurés au point de collecte, validés par rapport à un schéma, et enrichis avant d'atteindre la fondation de données. Si les données comportementales entrant dans votre plateforme unifiée sont bruitées, incohérentes ou mal modélisées, les agents IA qui les utilisent amplifieront ces erreurs à grande échelle.
Snowplow est la couche de contexte client. Nous nous situons entre le moment où un client fait quelque chose (un clic, un événement produit, une recherche, un défilement) et la plateforme de données qui doit agir en conséquence. Notre travail consiste à garantir que les données comportementales sont structurées, bien gouvernées et sémantiquement cohérentes dès leur création.
Et le contexte sans identité est du bruit. Un flux comportemental riche n'est utile que dans la mesure où vous pouvez le relier à un individu connu et résolu à travers les points de contact, les appareils et les sessions, y compris les transitions entre les états anonymes et authentifiés. Les identités de Snowplow effectuent ce travail au niveau de la collecte, avant que les données n'atterrissent dans la plateforme. Le résultat n'est pas juste un flux d'événements. C'est une image résolue et continue du parcours de chaque client sur laquelle votre plateforme de données, vos analystes et vos agents IA peuvent tous opérer en toute confiance.
La composabilité a toujours été l'architecture, pas la fonctionnalité
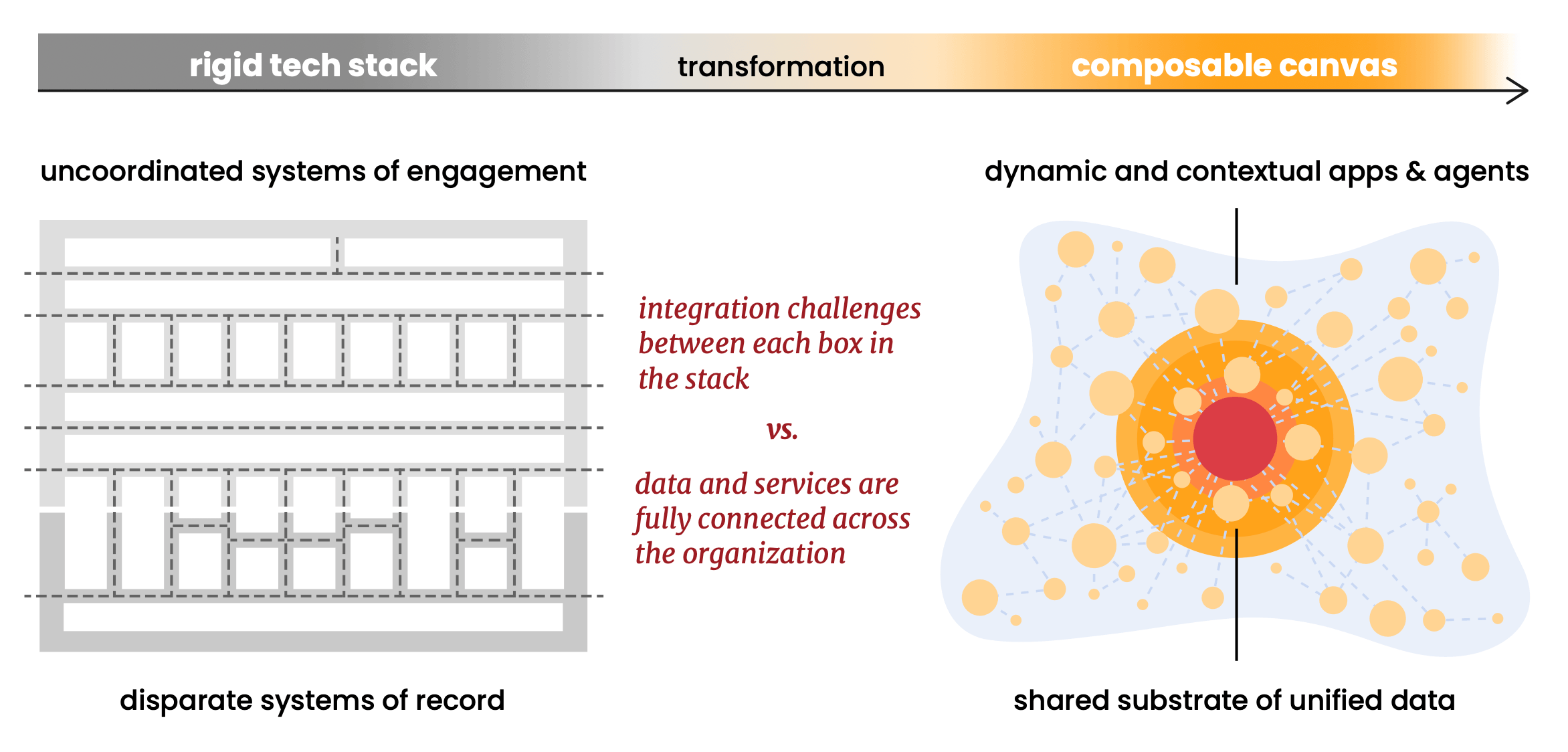
L'argument de la composabilité du rapport est l'un de ses plus forts. Il préconise les formats de données ouverts (Linux Foundation Delta Lake, Apache Iceberg), les protocoles ouverts (MCP pour les agents) et les standards ouverts comme précondition à une toile véritablement composable. Le principe : standardiser la fondation pour pouvoir diversifier tout ce qui fonctionne dessus.
Nous croyons profondément en cela, et nous avons construit Snowplow autour dès le début. Nous croyons aux standards ouverts de base. Nos structures de données fonctionnent nativement sur Apache Iceberg et Linux Foundation Delta Lake. Nous fonctionnons à l'intérieur de votre compte cloud (référencé comme hyperscalers dans l'article de Scott : AWS, GCP ou Azure), ce qui signifie que vos données comportementales ne quittent jamais votre environnement. Il n'y a pas de magasin de données Snowplow propriétaire qui devienne une dépendance ou un risque de migration. Lorsque vous souhaitez remplacer ou étendre une partie du stack, les données comportementales sont déjà là où elles doivent être : dans votre plateforme, dans des formats ouverts, prêtes à être composées.
Le rapport note que les "CDP composables" inversent le modèle traditionnel en apportant les capacités CDP aux données plutôt qu'en tirant les données vers le CDP. Snowplow faisait cela avant que la catégorie n'ait de nom, car pour nous, la composabilité n'a jamais été une fonctionnalité que nous avons ajoutée. C'était le principe fondateur sur lequel le produit a été construit.
La couche sémantique commence avant la plateforme
L'une des idées les plus importantes que le rapport développe est le rôle de la couche sémantique, en particulier ce qu'il appelle "le gardien de la cohérence". C'est le vocabulaire partagé qui rend les données significatives et cohérentes à travers tous les agents et applications qui les touchent. Ce que "client" signifie à travers les équipes. Comment la "conversion" est calculée. Ce qui constitue un "lead qualifié".
De notre point de vue, j'ajouterais une observation pratique : la plupart de ces questions doivent être répondues avant que les données n'entrent dans la plateforme, pas après. Les données comportementales en particulier sont remarquablement faciles à collecter mal. Les événements arrivent avec une dénomination incohérente, des propriétés manquantes, des schémas non définis. Au moment où les données atteignent la plateforme, elles sont déjà incohérentes. Vous pouvez construire une couche sémantique au-dessus de données médiocres, mais vous masquez un problème structurel au lieu de le résoudre.
Le registre de schémas de Snowplow et la validation des événements via notre Event Studio imposent la cohérence sémantique au point de collecte. Nous rejetons ou signalons les événements qui ne sont pas conformes aux structures définies avant qu'ils n'atterrissent dans la plateforme de données. Dans la toile composable que le rapport décrit — où des dizaines d'agents et d'applications puisent tous dans les mêmes données comportementales — la qualité de ces données à la source détermine si vous pouvez faire confiance à tout ce qui est construit dessus.
La boucle de rétroaction agentique : Comment la prise de décision en temps réel se clôture
Le rapport soulève un point qui, je pense, mérite encore plus d'emphase : les agents IA sont "affamés de contexte". Ils n'ont pas seulement besoin d'enregistrements client ; ils doivent comprendre ce qui se passe en ce moment, c'est-à-dire les signaux comportementaux qui indiquent l'intention, l'urgence et l'opportunité.
J'ajouterais quelque chose au modèle que Scott a présenté ici. Le rapport présente les données comme s'écoulant vers les agents — une fondation sur laquelle les agents s'appuient pour prendre des décisions. Ce qu'il ne développe pas entièrement, c'est la boucle qui se produit après que l'agent a agi, et pourquoi la clôture de cette boucle est de plus en plus le problème de données le plus stratégiquement important en martech. C'est quelque chose auquel nous réfléchissons beaucoup chez Snowplow, et c'est central dans la façon dont la toile composable fonctionne réellement en pratique.
La boucle a quatre étapes :
- L'étape de collecte capture les événements comportementaux des interactions humaines et pilotées par l'IA sous forme de données structurées et validées par schéma, qui affluent en continu vers la plateforme de données. Mais la définition de "données comportementales" doit s'élargir pour inclure une deuxième catégorie d'activité que la plupart des architectures ne capturent pas encore bien. Cette deuxième catégorie a deux visages distincts. Le premier est l'analyse des agents IA : lorsqu'un client interagit avec un agent conversationnel, reçoit une recommandation personnalisée ou voit son parcours façonné par un système de décision automatisé, ces interactions pilotées par l'agent sont elles-mêmes des événements qui doivent être collectés avec la même rigueur que tout comportement humain. Le second est l'analyse agentique : les agents IA effectuant des recherches au nom d'un utilisateur. Lorsqu'une IA parcourt vos pages produits, lit votre documentation ou compare des options en tant que proxy d'un client, ce trafic est une intention, exprimée uniquement par un acteur non humain. Le traiter comme du bruit de bot à filtrer revient à écarter un signal qui vous renseigne sur ce qu'un client évalue réellement. Snowplow distingue et capture les deux comme des événements comportementaux structurés, distincts de l'interaction humaine directe mais tout aussi significatifs pour comprendre l'intention et éclairer la prise de décision.
- L'étape de résolution et d'enrichissement transforme les flux d'événements bruts en une image cohérente du client grâce à la résolution d'identité, en reliant les sessions, les appareils et les points de contact à un individu connu. C'est là que le flux comportemental devient une image cohérente : pas "un utilisateur a visité trois pages" mais "ce compte, actuellement en phase d'évaluation avancée, a eu trois cadres effectuant des recherches sur les prix au cours des dernières 48 heures".
- L'étape de diffusion fournit le contexte comportemental enrichi dans deux modes simultanés : en temps réel pour la personnalisation en session, et combiné temps réel plus historique pour la prise de décision par les agents IA. Pour la personnalisation en session, c'est en temps réel : la plateforme de données expose les signaux comportementaux suffisamment rapidement pour que l'expérience rendue à ce client en ce moment même reflète ce qu'il a fait dans cette session. Pour la prise de décision par les agents IA, c'est à la fois en temps réel et historique : un agent coordonnant la meilleure action suivante pour un compte s'appuie sur le flux comportemental en direct et sur l'historique complet du client. La question n'est pas seulement "que fait ce client ?" mais "que signifie ce comportement, compte tenu de tout ce que nous savons sur des clients similaires ?"
- L'étape d'apprentissage ferme la boucle de rétroaction en acheminant les résultats de chaque décision d'agent vers la base de données sous forme d'événements comportementaux de première classe. Le résultat de chaque décision d'agent, de chaque expérience personnalisée, de chaque action automatisée est lui-même un événement comportemental. Le produit recommandé a-t-il été ajouté au panier ? L'e-mail personnalisé a-t-il été ouvert ? L'intervention en session a-t-elle modifié la trajectoire de la session ? La session de recherche de l'agent IA a-t-elle finalement abouti à une conversion ? Ces résultats doivent être renvoyés vers la même base de données qui a alimenté la décision initiale. Sans cette rétroaction, les agents IA opèrent sur des données historiques qui deviennent de plus en plus obsolètes chaque jour. Avec elle, le système s'améliore véritablement de manière autonome.
C'est là que l'analyse des agents IA et l'analyse agentique bouclent la boucle. Vous avez collecté les événements comportementaux des agents IA en tant que données de première classe ; vous pouvez maintenant les analyser avec la même rigueur que vous appliqueriez au comportement humain. Quels agents sont performants ? Quels modèles de décision se dégradent ? Où le trafic de recherche généré par l'IA convertit-il, et où abandonne-t-il ? Ces questions ne peuvent être répondues que si la collecte a été correcte dès le départ. L'analyse des agents IA et l'analyse agentique ne sont pas une couche de reporting que vous ajoutez plus tard. Elles sont une conséquence de la manière dont vous avez collecté les données en premier lieu.
C'est la boucle de rétroaction unique à la bonne infrastructure de données comportementales. Ce n'est pas un pipeline. C'est un volant d'inertie.
De l'analyse à la prise de décision : les bons outils pour la prise de décision en temps réel
Quelque chose que le rapport effleure et qui, je pense, mérite plus d'attention, en particulier pour les responsables du marketing et des données qui réfléchissent à ce que l'IA exige réellement de leur pile technologique : le passage de l'utilisation des données comportementales pour l'analyse à leur utilisation pour la prise de décision est un changement architectural significatif, pas simplement une expansion des cas d'utilisation.
L'analyse est rétrospective. Vous collectez des événements, vous les modélisez et vous interrogez les résultats. Une latence de quelques minutes ou heures est acceptable. Les données éclairent un humain qui prend une décision.
La prise de décision est prospective et en temps réel. Un agent IA a besoin d'un contexte comportemental en quelques millisecondes pour déterminer quelle expérience servir à ce client, dans cette session, en ce moment même. Les exigences en matière d'infrastructure sont différentes. Les exigences en matière de qualité des données sont plus élevées car les erreurs ne se manifestent pas comme une anomalie de tableau de bord que quelqu'un repère la semaine suivante ; elles se manifestent comme une mauvaise expérience client livrée instantanément, à grande échelle.
Malheureusement, la plupart des pipelines de données imposent un compromis. Certains optimisent la vitesse, mais vous font perdre la profondeur historique. D'autres optimisent la richesse, mais vous font perdre la marge de latence dont la prise de décision en temps réel a besoin.
Le canevas composable exige les deux en même temps, sur les mêmes données. C'est un problème d'infrastructure plus difficile qu'il n'y paraît, et qui vaut la peine d'être résolu à la base plutôt que d'essayer de le corriger plus tard, lorsqu'un agent prend des décisions à la vitesse de la milliseconde et que vous réalisez que votre contexte historique se trouve dans un magasin séparé.
Sur les graphes de contexte et les données comportementales
Le rapport introduit un concept que j'ai trouvé vraiment intéressant : le graphe de contexte — un enregistrement vivant des traces de décision qui capture non seulement ce qui s'est passé, mais pourquoi cela a été autorisé. La logique de décision, les octrois d'exception, les chaînes d'approbation. Le type de mémoire institutionnelle qui vit actuellement dans les fils Slack et dans la tête des gens.
Je dirais que les flux d'événements comportementaux sont la matière première naturelle des graphes de contexte du côté client. Chaque action d'agent impliquant un client (une recommandation faite, un segment déclenché, un message envoyé) doit être traçable jusqu'aux signaux comportementaux qui l'ont provoquée. Le modèle d'événements de Snowplow est structuré pour capturer précisément cette causalité : quel signal a été déclenché, quelles données ont été observées, quel seuil a été franchi.
À mesure que les graphes de contexte mûrissent en tant que modèle architectural, la couche de données comportementales sera fondamentale pour eux. Le "ce qui s'est passé" et le "pourquoi cela s'est passé" sont tous deux encodés dans le flux d'événements, si vous le collectez correctement dès le départ.
Comment construire une base de prise de décision en temps réel qui évolue
Pour toute organisation construisant le canevas composable décrit dans le rapport, la mise en place correcte de l'infrastructure de données comportementales est le premier investissement le plus rentable : non pas parce qu'il est le plus excitant, mais parce que tout le reste repose dessus.
Cela signifie bien faire quatre choses dès le départ :
- Collecte structurée avec validation de schéma intégrée dès le premier jour
- Résolution d'identité au niveau de la couche de collecte, non pas ajoutée après coup
- Un pipeline conçu pour la prise de décision en temps réel et l'analyse historique sur les mêmes données
- La discipline de collecter les résultats des interactions des agents IA en tant qu'événements comportementaux de première classe, afin que la boucle de rétroaction se ferme dès le début
L'architecture composable signifie également que les décisions concernant les fournisseurs que vous prenez aujourd'hui doivent être réversibles. Si votre pipeline de données comportementales écrit dans des formats ouverts sur votre propre infrastructure cloud, vous conservez des options. Si elle écrit dans un magasin propriétaire, vous avez créé une dépendance qui limitera toutes les décisions futures concernant la pile technologique.
Le 3ème Âge est déjà là pour ceux qui ont investi tôt
Le rapport présente le 3ème Âge du Martech comme un horizon de 3 à 5 ans. Pour les clients Snowplow qui ont déjà réalisé les investissements architecturaux décrits ici, c'est-à-dire : les plateformes de données comme noyau opérationnel, les données comportementales alimentant les agents en temps réel, la boucle complète de rétroaction décision-analyse fonctionnant sur une base composable, ce n'est pas un état futur. C'est déjà ainsi qu'ils opèrent aujourd'hui.
Ce n'est pas une affirmation spécifique à Snowplow. C'est la preuve que l'architecture est réalisable dès maintenant, pour les organisations prêtes à lui donner la priorité. Le canevas composable n'attend pas de nouvelles technologies. Il attend des décisions architecturales et la conviction de les prendre.
Le rapport de Scott est une articulation claire et généreuse de ces décisions. Nous sommes heureux de voir cette conversation se dérouler à ce niveau de profondeur — et heureux d'en faire partie !

Lisez le rapport de recherche complet de Scott Brinker ici : La nouvelle "pile" Martech pour l'ère de l'IA
Webinaire en direct avec Scott Brinker, CMO de Samsara, et le VP de Marketing Data Science de HP sur l'évolution du martech pour l'IA : Inscrivez-vous au webinaire
Si vous souhaitez approfondir ce que la base de données pour l'analyse agentique doit réellement être, l'équipe de Snowplow en a parlé en détail ici : Qu'est-ce que l'analyse agentique ? Un guide pour les leaders de données
FAQ :
Quelle est la différence entre la prise de décision en temps réel et le traitement par lots ? Le traitement par lots collecte et analyse les données à intervalles réguliers, souvent des heures après une interaction. La prise de décision en temps réel traite les signaux comportementaux au moment où ils sont générés et déclenche une action au cours de la même session, souvent en quelques millisecondes. Les exigences en matière d'infrastructure, les normes de qualité des données et les tolérances de latence sont fondamentalement différentes entre les deux approches.
Pourquoi les agents IA ont-ils besoin d'une couche de contexte client ? Les agents IA qui prennent des décisions en cours de session nécessitent un contexte comportemental qui reflète ce qu'un client fait en ce moment, pas ce qu'il a fait hier. La couche de contexte client fournit des flux d'événements comportementaux structurés et résolus par identité que les agents IA peuvent interroger en temps réel. Sans elle, les agents travaillent sur des données obsolètes qui dégradent la qualité des décisions à grande échelle.
Quelle est la différence entre les enregistrements client et le contexte client ? Les enregistrements client décrivent qui est un client : son profil, son historique d'achats, son statut de compte et son appartenance à un segment. Le contexte client décrit ce qu'il fait au moment présent : quelles pages il a visitées, ce qu'il a recherché, combien de temps il s'est engagé, et ce que ce comportement signale quant à son intention. La prise de décision en temps réel nécessite les deux, mais la plupart des piles de données sont meilleures pour le premier que pour le second.
Quelles sont les quatre étapes de la boucle de rétroaction de l'agent ? La boucle de rétroaction de l'agent se déroule en quatre étapes : (1) Collecter — capturer les événements comportementaux des interactions humaines et pilotées par l'IA sous forme de données structurées ; (2) Résoudre et enrichir — relier les événements à une identité connue et construire une image client cohérente ; (3) Servir — fournir le contexte enrichi aux agents IA et aux systèmes de personnalisation en temps réel ; (4) Apprendre — renvoyer les résultats de chaque décision de l'agent à la base de données afin que le système s'améliore continuellement.
Quelle infrastructure de données est requise pour la prise de décision en temps réel ? La prise de décision en temps réel nécessite quatre capacités fondamentales : la collecte d'événements structurés avec validation de schéma au point de capture ; la résolution d'identité au niveau de la couche de collecte plutôt que rétroactivement ; un pipeline de données capable de servir simultanément le contexte en temps réel et historique ; et la discipline de traiter les sorties des interactions des agents IA comme des événements comportementaux de premier ordre qui alimentent le système.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.