Inférence LLM fiable à grande échelle
Leçons tirées de la construction d'une infrastructure d'inférence LLM fiable
par Ying Chen, Wendy Hu, Ankit Mathur, Mike Eastham, Pei-Lun Liao, Wai Wu et Arjun DCunha
- Le service LLM multi-locataire nécessite une réflexion sur la capacité entre les charges de travail. Les « unités de modèle » fournissent une abstraction de type VM qui permet d'allouer, de router et de mettre à l'échelle les ressources GPU par client.
- L'équilibrage de charge et la mise à l'échelle automatique tenant compte des coûts, basés sur les unités de modèle, ont permis d'économiser plus de 80 % sur les coûts GPU par rapport au provisionnement statique tout en respectant les objectifs de latence.
- Les mécanismes de fiabilité d'exécution tels que les vérifications de santé en boîte noire détectent et récupèrent automatiquement les défaillances silencieuses, tandis que le profilage des goulots d'étranglement multimodaux a permis de multiplier le débit par 3.
Chez Databricks, nous avons construit une plateforme d'inférence unique qui dessert tous les modèles de pointe, des modèles open source comme Kimi et Qwen aux modèles propriétaires comme OpenAI, Gemini et Claude. Nous alimentons l'inférence pour certaines des plus grandes applications d'agents au monde, notamment Superhuman, Yipit Data, Fox Sports, et d'autres. Aujourd'hui, nous traitons plus de 120 T de tokens par mois.
Ce qui rend difficile le service LLM à grande échelle, c'est la fiabilité. Alors que les agents deviennent l'interface de notre façon de travailler et de vivre, la demande d'inférence croît de façon exponentielle. Nous constatons des courbes de demande extrêmement fluctuantes qui atteignent leur maximum pendant les heures de travail.
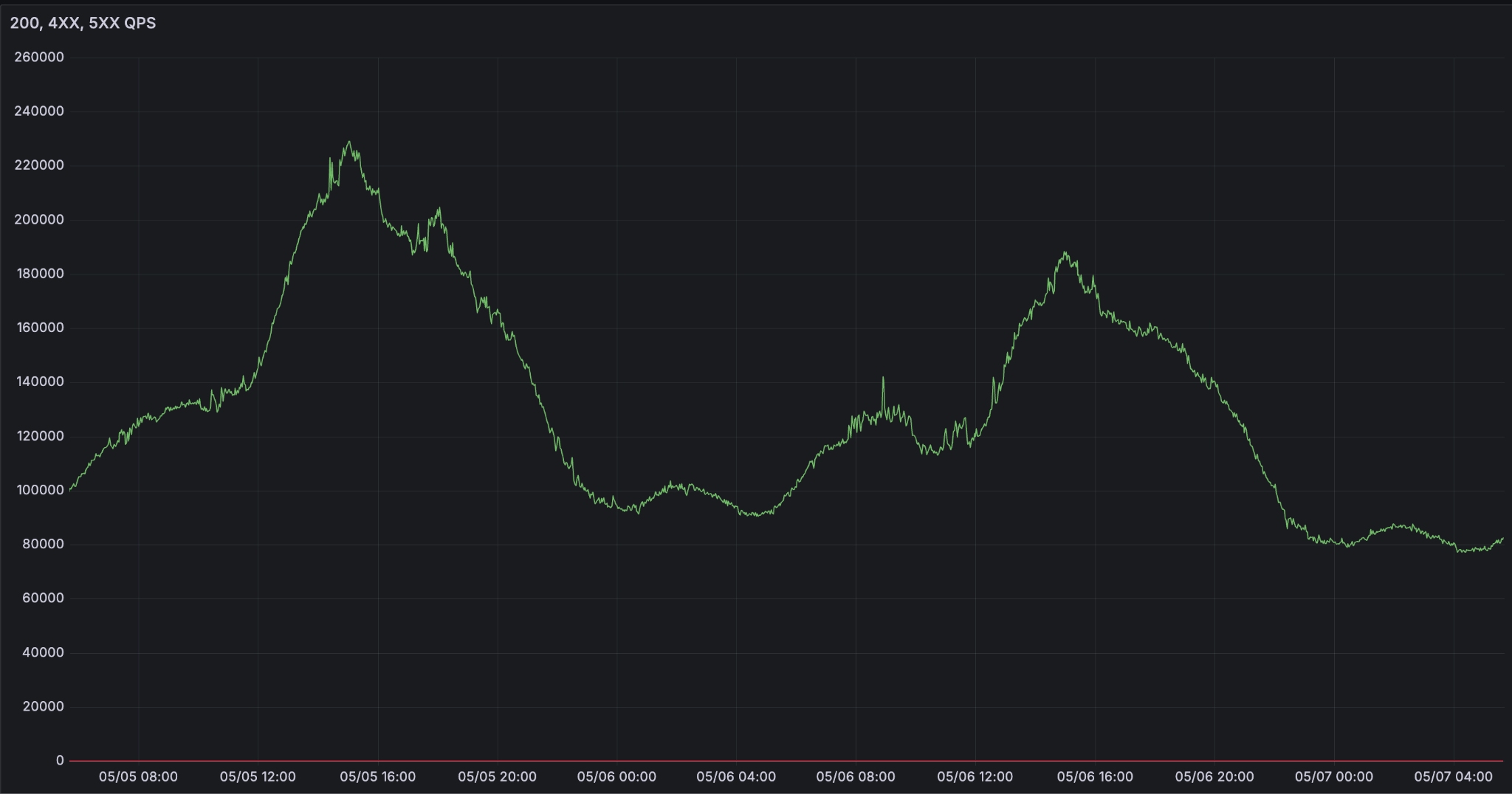
Défis de l'exécution de l'inférence LLM à grande échelle
Qu'est-ce que cela signifie d'être une plateforme d'inférence fiable ? Le contrat semble simple. La disponibilité est la capacité à traiter la requête. Mais, en pratique, différents cas d'utilisation ont des exigences de latence très différentes, et cela influe sur la disponibilité. Les agents les plus avancés ne peuvent pas se permettre une dégradation du temps de premier token (TTFT) p95 et des tokens de sortie par seconde (OPTS).
Dans un système multi-tenant pour le service LLM, atteindre à la fois la fiabilité et la latence est un défi.
Fiabilité
Les performances de pointe nécessitent les derniers GPU avec une interconnexion à large bande passante pour le transfert du cache KV. Ces configurations de calcul sont fondamentalement moins fiables que les systèmes CPU classiques, et elles sont coûteuses. Étant donné que la communication de tous à tous est requise, la panne d'un seul nœud nécessite une reconfiguration pour plusieurs autres nœuds dans des configurations de préremplissage/décodage désagrégées. La mise en réseau à plus large bande passante nécessite une connectivité à spine unique dans un seul rack physique (par exemple, les systèmes NVL72). Cela signifie que les défaillances dans des systèmes spécifiques au sein d'un seul rack de centre de données peuvent créer une panne à large rayon d'impact. Les astuces standard dans les systèmes distribués comme le multi-AZ ou l'utilisation de types d'instances de sauvegarde signifient garder des GPU de sauvegarde coûteux inactifs, une option prohibitive en termes de coût. Le surprovisionnement est une autre astuce classique, mais étant donné que l'approvisionnement en calcul est si limité, il est extrêmement coûteux et peu pratique. Ainsi, les systèmes doivent rester opérationnels sous une forte contrainte.
La vitesse de livraison doit également rester élevée dans ces contraintes - notre demande d'inférence a augmenté de plusieurs ordres de grandeur d'une année sur l'autre, et alimenter cette croissance tout en livrant des fonctionnalités innovantes a été un défi. Des fonctionnalités comme les images, les vidéos et la classification de sécurité nécessitent toutes des systèmes de pré-traitement différents qui doivent tous évoluer indépendamment.
Enfin, atteindre des performances de pointe et prendre en charge de nouvelles architectures de modèles nécessite des optimisations qui couvrent un large éventail, des noyaux personnalisés aux moteurs d'inférence propriétaires. À mesure que les architectures changent subtilement, de nouveaux logiciels de bas niveau sont souvent introduits et peuvent échouer de manière opaque à grande échelle, se manifestant dans des scénarios de débogage difficiles allant des blocages de serveur aux plantages de GPU.
Latence
Garder la latence sous contrôle avec des modèles de charge divers est un défi. En effet, le coût pour servir une requête est très variable et difficile à estimer a priori. Même des serveurs sains sous une charge plus importante traitent toutes les requêtes plus lentement, exposant un compromis entre le débit (et donc l'efficacité des coûts) et la latence la plus rapide que les produits doivent gérer. Cela peut également se manifester comme un problème de fiabilité, car les serveurs peuvent entrer inopinément dans des états non sains très rapidement en fonction du mélange de requêtes qui leur sont attribuées.
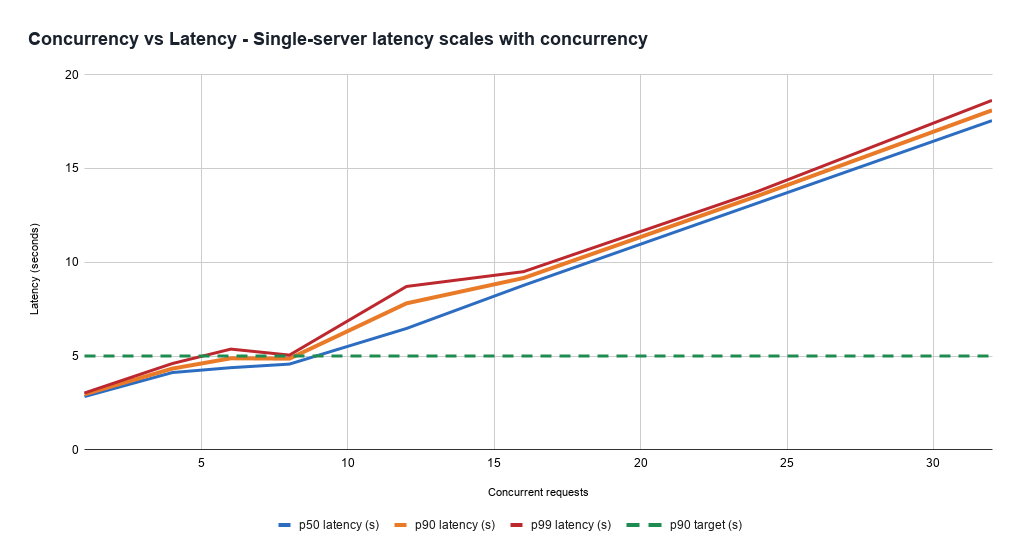
De plus, la latence est dominée par la génération de tokens de sortie, mais l'estimation initiale du coût est difficile, car il est difficile de prédire combien de temps le modèle parlera. Ainsi, le service à faible latence nécessite une gestion complexe de la capacité, un équilibrage de charge et des systèmes de priorisation des requêtes.
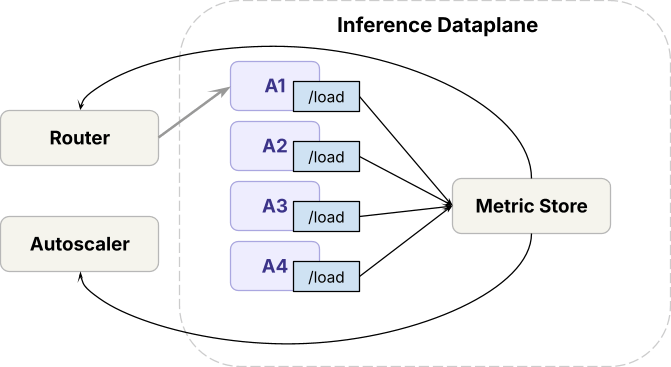
Architecture globale
Avant de plonger dans les détails sur la façon de résoudre ces problèmes, examinons un aperçu général de notre infrastructure de service.
Dans le plan de données,
- Le runtime d'inférence (moteurs open source et propriétaires internes) est déployé sur des GPU de pointe
- Pour gérer le trafic entre les déploiements de modèles, le plan de données exécute un routeur, que nous appelons Axon, qui équilibre la charge entre les répliques du même modèle, et un autoscaler qui ajuste le nombre de répliques.
Dans le plan de contrôle,
- Les requêtes passent par une limitation de débit avant d'atteindre le plan de données.
- Sur la base des métriques de requête, l'algorithme de gestion de la capacité détermine la capacité GPU que chaque charge de travail reçoit, ce que l'autoscaler applique ensuite.
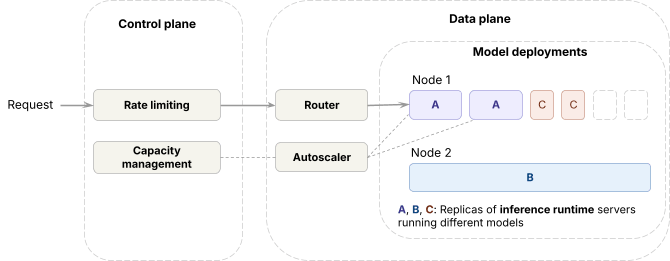
Maîtriser la capacité
Nous devons être capables de raisonner approximativement sur la capacité - combien nous en avons, combien nous en avons vendu, et combien les clients utilisent. Pour ce faire, nous avons introduit une abstraction appelée "unités de modèle". Si nous projetons qu'une réplique peut traiter un nombre fixe d'unités de modèle par minute (par exemple, 100), nous pouvons faire les hypothèses suivantes :
- Les requêtes avec une longue entrée ou sortie consomment plus d'unités de modèle, car moins peuvent être complétées dans la même fenêtre de temps.
- Le préremplissage et le décodage ont des caractéristiques de débit différentes, de sorte que les requêtes avec une longue sortie coûtent plus cher que celles avec une longue entrée.
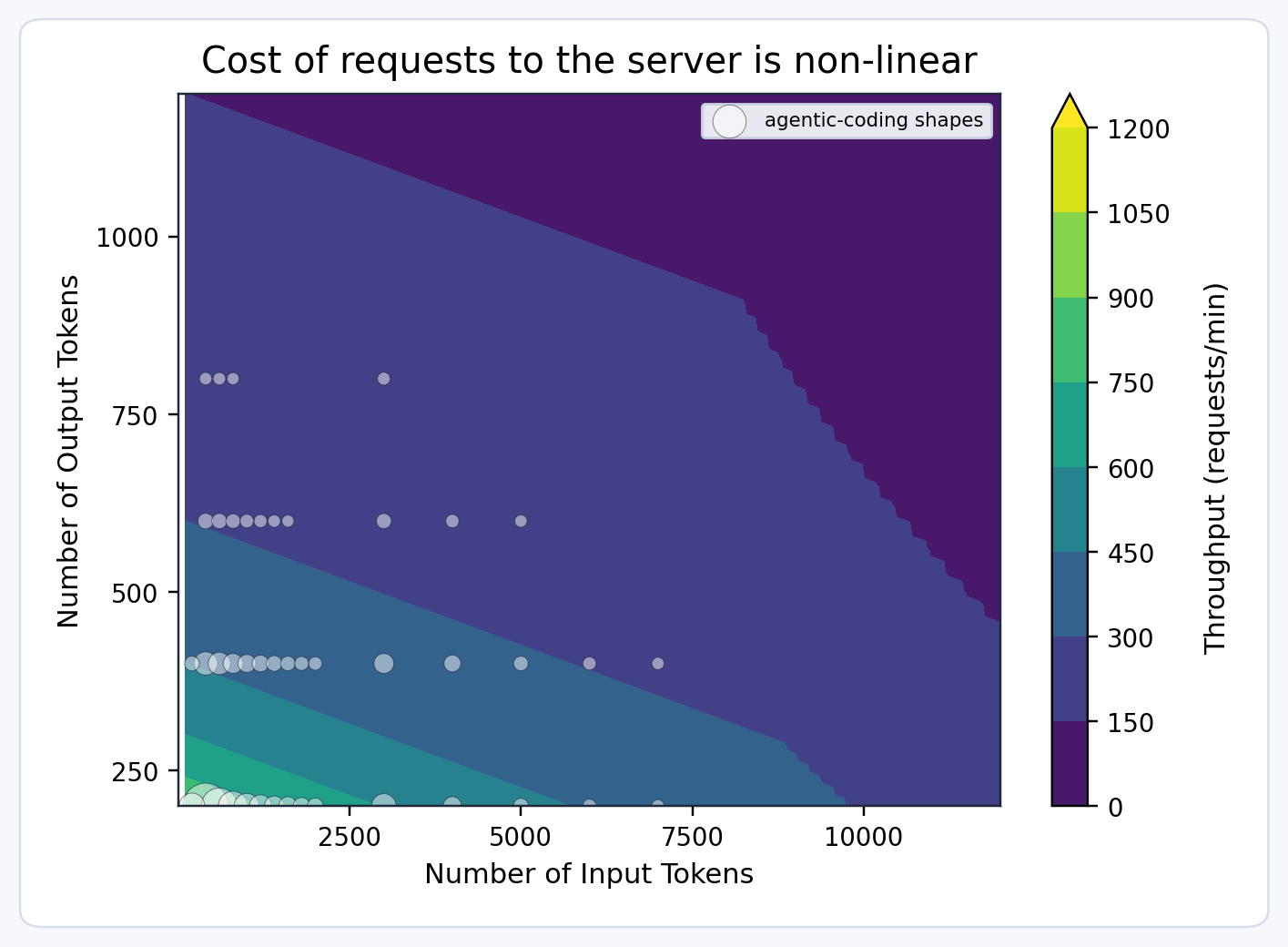
Par conséquent, nous modélisons le coût des requêtes à l'aide d'une fonction multidimensionnelle telle que :
Les coefficients α, β, γ sont déterminés par des benchmarks automatisés pour chaque modèle sur chaque type de matériel. Les unités de modèle peuvent être ajustées davantage pour des optimisations comme le cache de préfixe, et elles doivent tenir compte de fonctionnalités comme la multimodalité.
De telles estimations sont structurellement imparfaites, mais elles nous servent de moyen de décomposer un système multi-tenant en quelque chose de plus gérable qui ressemble à des VM cloud. Les VM ont la propriété souhaitable d'offrir des performances prévisibles qui peuvent être allouées à des clients spécifiques. Pour les charges de travail d'agents de production, il est important d'offrir des garanties de faible latence et de capacité, et sans de tels systèmes d'allocation, le mieux que nous puissions faire est d'offrir une capacité "au mieux" qui pourrait être récupérée si trop de clients utilisent le système.
Équilibrage de charge et autoscaling basés sur les coûts
Étant donné que les requêtes ont un impact très variable sur les serveurs, il est important de prendre des décisions de routage quasi optimales. En général, l'équilibrage de charge a tendance à s'appuyer sur des approches statistiques comme P2C (power of two choices), qui estiment la charge en fonction de la taille de la file d'attente et utilisent l'échantillonnage pour réduire les surcoûts de mémoire et de latence liés à la compréhension de toutes les cibles possibles. Cependant, les latences LLM ont tendance à être élevées, le nombre de serveurs est inférieur à celui des systèmes CPU à grande échelle, et le coût d'un mauvais routage est sévère. Par conséquent, le service LLM nécessite une approche différente.
Aujourd'hui, nous utilisons Dicer, l'auto-sharder de Databricks, pour router dynamiquement les charges de travail entre les serveurs. Sans routage sensible à la charge, les requêtes à contexte long font que des serveurs individuels deviennent des points chauds tandis que d'autres restent sous-utilisés. Nous avons intégré les unités de modèle avec Dicer afin que les décisions de routage soient basées sur la charge du serveur en unités de modèle plutôt que sur des heuristiques traditionnelles basées sur les requêtes. Dicer fournit également des sessions avec état, rendant le routage des requêtes persistant. Les requêtes d'une charge de travail vont vers seulement un sous-ensemble de serveurs, ce qui améliore les taux de succès du cache (crucial pour les charges de travail sensibles à la latence comme les agents de codage) et limite le rayon d'impact.
Nous pouvons également ajuster les métriques de charge et même utiliser des systèmes de routage plus optimaux à l'avenir basés sur des métriques de coût de plus haute fidélité, à mesure que nous en apprenons davantage.
Un problème similaire existe dans l'autoscaling. Les décomptes de requêtes en attente ne reflètent pas la charge réelle. Une augmentation des requêtes à long contexte ressemble à une augmentation des requêtes courtes, et les métriques de CPU et de mémoire sont également peu corrélées à l'utilisation réelle du GPU.
En utilisant des unités de modèle, notre autoscaler peut décider de monter ou de descendre en échelle en fonction du ratio d'utilisation des unités de modèle. Lorsque le moteur d'inférence fonctionne près d'un certain pourcentage de ses unités de modèle maximales (déterminé par le type de matériel et la forme de la charge de travail), il approche du débit maximal, ce qui déclenche une montée en échelle. L'inverse déclenche une descente en échelle. Plutôt que d'ajuster manuellement les règles d'autoscaling pour chaque modèle, cette approche permet une infrastructure de mise à l'échelle indépendante du modèle.
La construction de l'autoscaling sur les modèles d'inférence LLM nous a évité de devoir toujours monter en échelle jusqu'au nombre maximal de répliques. Pour les modèles avec un trafic par rafales, l'autoscaling a maintenu le nombre de répliques proche de la demande réelle, ce qui s'est traduit par plus de 80% d'économies de GPU par rapport à un provisionnement statique au maximum.
Fiabilité d'exécution
Le routage et la mise à l'échelle intelligents ont fourni une base solide, mais ils n'empêchent pas les défaillances au niveau du moteur. Quel que soit le moteur d'inférence que nous déployons (notre moteur interne ou des options open-source populaires), des cas limites et la contention de ressources apparaissent à l'échelle de la production. Nous avons besoin de mécanismes pour détecter et récupérer automatiquement des défaillances.
Détection et récupération des défaillances silencieuses
Un mode de défaillance que nous rencontrons est les blocages silencieux. Les requêtes impliquant des cas limites (sortie structurée, entrées multimodales) peuvent déclencher des erreurs non gérées dans l'architecture multi-processus des moteurs d'inférence, provoquant l'arrêt de la réponse des serveurs sans afficher d'erreurs.
Nous détectons cela avec des vérifications de santé périodiques en boîte noire : des requêtes minimales de bout en bout envoyées lorsqu'aucune requête réelle n'a été complétée récemment. Si une vérification de santé échoue, la sonde de liveness de Kubernetes redémarre le serveur. Cela fonctionne sur tous les moteurs, quelle que soit leur implémentation interne.
Cependant, sous forte charge, les vérifications de santé elles-mêmes peuvent expirer, provoquant la terminaison par la sonde de liveness de serveurs qui sont en réalité sains. Cela risque des défaillances en cascade. Pour résoudre ce problème, nous attribuons aux requêtes de vérification de santé la priorité de planification la plus élevée, garantissant qu'elles se terminent même sous forte charge. Avec des vérifications de santé prioritaires, le cycle complet de détection d'un blocage, de terminaison du serveur non sain et de récupération prend moins de 5 minutes. Les faux échecs de la sonde de liveness sont passés de plusieurs par semaine à zéro.
Gestion de la charge inattendue des requêtes multimodales
Lorsque de grands lots de requêtes multimodales arrivaient, nous avons constaté des pics de taux d'erreur et de délais d'attente provenant d'une source complètement différente.
Les investigations ont révélé que les requêtes n'atteignaient même pas les processus principaux du moteur d'inférence. Le service des requêtes d'images est plus coûteux en ressources que les requêtes textuelles uniquement, non seulement en raison de l'encodeur de vision supplémentaire fonctionnant sur les GPU, mais aussi du traitement d'images intensif en CPU. Pour certains modèles, le traitement d'images était extrêmement lent, bloquant complètement la boucle d'événements.
Le déplacement des opérations bloquantes dans des threads et processus séparés n'a pas résolu le problème ; les requêtes s'accumulaient toujours sous une forte charge d'images. Nous avons donc profilé les processus Python et fait plusieurs découvertes :
- Parmi toutes les opérations CPU pour les images, le traitement d'images (redimensionnement et normalisation) est 10 fois plus lent que d'autres opérations comme le décodage base64.
- Certains modèles Hugging Face utilisent par défaut le processeur d'images basé sur PIL, tandis que d'autres utilisent le processeur basé sur Torchvision, plus rapide.
- Dans les environnements conteneurisés, OMP_NUM_THREADS (qui contrôle le nombre de threads OpenMP utilisés par Torch pour les opérations CPU) est défini par défaut sur le nombre de vCPUs sur la machine hôte. Dans les configurations multi-locataires, c'est un mauvais réglage par défaut : un hôte peut avoir 192 vCPUs, mais un conteneur n'a accès qu'à 12. Le résultat est un nombre de threads beaucoup plus élevé que de cœurs disponibles. Cela fait dépasser l'utilisation du CPU par la limite du conteneur et déclenche une limitation.
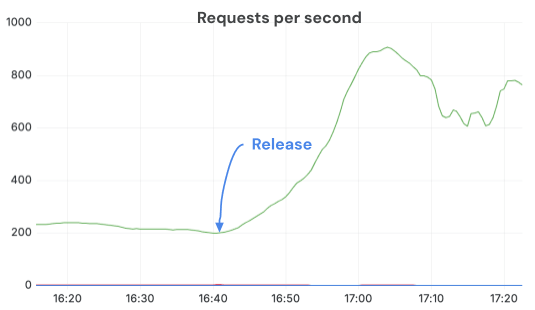
En passant aux processeurs d'images basés sur Torchvision et en configurant correctement OMP_NUM_THREADS, nous avons maintenu un QPS beaucoup plus élevé et exploité pleinement les GPU. Après la mise en production de la correction, les requêtes complétées par seconde ont bondi de plus de 3 fois avec les mêmes répliques et la même charge. La limitation du CPU a disparu et les serveurs fonctionnaient dans un état beaucoup plus sain.
Conclusion
Servir des LLM de manière fiable à grande échelle nécessite un travail sur toutes les couches de la pile d'inférence. Nous avons couvert l'infrastructure d'autoscaling et d'équilibrage de charge conçue autour des charges de travail LLM, ainsi que des mécanismes d'exécution qui restent stables quel que soit le moteur ou la charge de travail. Il y a beaucoup plus à raconter : démarrage rapide des conteneurs, déploiements sûrs sur des flottes de GPU, gestion de la capacité GPU entre les clouds et les régions. Si ce sont le genre de problèmes sur lesquels vous souhaitez travailler, nous recrutons !
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.