Mise en open source de Dicer : l'auto-sharder de Databricks
Création de services partitionnés à haute disponibilité pour monter en charge pour des performances élevées et un faible coût
par Atul Adya, Colin Meek, Jonathan Ellithorpe, Vivek Jain et Yongxin Xu
- Dicer en open source : nous mettons officiellement en open source Dicer, le système fondamental d'auto-sharding utilisé chez Databricks pour créer des services partitionnés rapides, évolutifs et à haute disponibilité.
- Présentation de Dicer et de sa raison d'être : nous décrivons les problèmes des architectures de service typiques d'aujourd'hui, expliquons pourquoi les auto-sharders sont nécessaires, comment Dicer résout ces problèmes, et nous discutons de ses abstractions principales et de ses cas d'utilisation.
- Exemples de réussite : le système alimente actuellement des composants critiques comme Unity Catalog et notre moteur d'orchestration de requêtes SQL, où il a éliminé avec succès les baisses de disponibilité et maintenu des taux de succès du cache supérieurs à 90 % pendant les redémarrages de pods.
1. Annonce
Aujourd'hui, nous sommes ravis d'annoncer la publication en open source de l'un de nos composants d'infrastructure les plus critiques, Dicer : l'auto-sharder de Databricks, un système fondamental conçu pour créer des services shardés à faible latence, scalables et hautement fiables. Il opère en coulisses de chaque produit majeur de Databricks, nous permettant de fournir une expérience utilisateur toujours rapide, tout en améliorant l'efficacité de la flotte et en réduisant les coûts du cloud. Dicer y parvient en gérant dynamiquement les attributions de sharding pour maintenir la réactivité et la résilience des services, même face à des redémarrages, des pannes et des charges de travail changeantes. Comme détaillé dans ce billet de blog, Dicer est utilisé pour divers cas d'usage, notamment le serving haute performance, le partitionnement du travail, les pipelines de traitement par lots, l'agrégation de données, la multilocation, l'élection de leader souple, l'utilisation efficace des GPU pour les charges de travail d'IA, et bien plus encore.
En mettant Dicer à la disposition de la Communauté au sens large, nous nous réjouissons de collaborer avec l'industrie et le monde universitaire pour faire progresser l'état de l'art en matière de création de systèmes distribués robustes, efficaces et à hautes performances. Dans la suite de cet article, nous abordons la motivation et la philosophie de conception qui sous-tendent Dicer, nous partageons des exemples de réussite de son utilisation chez Databricks et nous fournissons un guide pour installer et expérimenter le système par vous-même.
2. Motivation : dépasser les architectures sans état et à sharding statique
Databricks propose une gamme de produits en pleine expansion pour le traitement des données, l'analytique et l'IA. Pour prendre en charge cela à grande échelle, nous exploitons des centaines de services qui doivent gérer un état massif tout en maintenant leur réactivité. Historiquement, les ingénieurs de Databricks s'appuyaient sur deux architectures courantes, mais toutes deux ont engendré des problèmes importants à mesure que les services se développaient :
2.1. Les coûts cachés des architectures sans état
La plupart des services chez Databricks ont commencé avec un modèle sans état. Dans un modèle sans état typique, l'application ne conserve pas l'état en mémoire entre les requêtes et doit relire les données depuis la base de données à chaque requête. Cette architecture est intrinsèquement coûteuse, car chaque requête entraîne un accès à la base de données, ce qui augmente à la fois les coûts opérationnels et la latence [1].
Pour atténuer ces coûts, les développeurs introduisaient souvent un cache distant (comme Redis ou Memcached) pour soulager la base de données. Bien que cela ait amélioré le throughput et la latence, cela n'a pas permis de résoudre plusieurs inefficacités fondamentales :
- Latence du réseau : Chaque requête paie toujours la « taxe » des sauts de réseau vers la couche de mise en cache.
- Surcharge CPU : Des cycles importants sont gaspillés en (dé)sérialisation lorsque les données se déplacent entre le cache et l'application [2].
- Le problème de la « sur-lecture» : les services sans état récupèrent souvent des objets entiers ou de gros blobs depuis le cache pour n'utiliser qu'une petite fraction des données. Ces sur-lectures gaspillent de la bande passante et de la mémoire, car l'application rejette la majorité des données qu'elle a passé du temps à récupérer [2].
Le passage à un modèle partitionné et la mise en cache de l'état en mémoire ont éliminé ces couches de surcharge en colocalisant l'état directement avec la logique qui l'exploite. Cependant, le partitionnement statique a introduit de nouveaux problèmes.
2.2. La fragilité du partitionnement statique
Avant Dicer, les services partitionnés de Databricks s'appuyaient sur des techniques de partitionnement statique (par ex., le hachage cohérent). Bien que cette approche soit simple et permette à nos services de mettre en cache l'état efficacement en mémoire, elle a introduit trois problèmes critiques en production :
- Indisponibilité pendant les redémarrages et la mise à l'échelle automatique : le manque de coordination avec un gestionnaire de cluster entraînait des temps d'arrêt ou une dégradation des performances lors d'opérations de maintenance telles que les mises à jour progressives ou lors de la mise à l'échelle dynamique d'un service. Les schémas de partitionnement statique ne parvenaient pas à s'ajuster de manière pro-active aux changements de composition du backend, réagissant uniquement après qu'un nœud avait déjà été supprimé.
- Split-brain prolongé et temps d'arrêt pendant les pannes : sans coordination centrale, les clients pouvaient développer des vues incohérentes de l'ensemble des pods backend lorsque les pods plantaient ou devenaient temporairement indisponibles. Cela entraînait des scénarios de « split-brain » (où deux pods pensaient posséder la même clé), voire la perte totale du trafic d'un client (où aucun pod ne pensait posséder la clé).
- Le problème de la « hot key » : par définition, le partitionnement statique ne peut pas rééquilibrer dynamiquement les attributions de clés ni ajuster la réplication en réponse aux variations de charge. Par conséquent, une seule « hot key » pouvait surcharger un pod spécifique, créant un goulot d'étranglement susceptible de déclencher des défaillances en cascade sur l'ensemble du parc.
À mesure que nos services se développaient pour répondre à la demande, le partitionnement statique a fini par apparaître comme une très mauvaise idée. Cela a conduit à la conviction générale parmi nos ingénieurs que les architectures sans état étaient le meilleur moyen de construire des systèmes robustes, même si cela impliquait d'en supporter les coûts en termes de performances et de ressources. C'est à peu près à cette époque que Dicer a été introduit.
2.3. Redéfinir le concept de service fragmenté
Les risques de production liés à la fragmentation statique, par opposition aux coûts du passage à une architecture sans état, ont mis plusieurs de nos services les plus critiques dans une position difficile. Ces services s'appuyaient sur la fragmentation statique pour offrir une expérience utilisateur réactive à nos clients. Leur conversion vers un modèle sans état aurait entraîné une pénalité de performance significative, sans parler des coûts cloud supplémentaires pour nous.
Nous avons développé Dicer pour changer cela. Dicer remédie aux lacunes fondamentales du sharding statique en introduisant un plan de contrôle intelligent qui met à jour en continu et de manière asynchrone les affectations de shards d'un service. Il réagit à un large éventail de signaux, notamment la santé de l'application, la charge, les avis de terminaison et d'autres entrées environnementales. Par conséquent, Dicer maintient les services hautement disponibles et bien équilibrés, même pendant les redémarrages progressifs, les plantages, les événements d'autoscaling et les périodes de forte asymétrie de charge.
En tant que fragmenteur automatique, Dicer s'appuie sur une longue lignée de systèmes antérieurs, notamment Centrifuge [3], Slicer [4] et Shard Manager [5]. Nous présentons Dicer dans la section suivante et décrivons comment il a permis d'améliorer les performances, la fiabilité et l'efficacité de nos services.
3. Dicer : partitionnement dynamique pour des performances et une disponibilité élevées
Nous présentons ici un aperçu de Dicer, de ses abstractions principales, et nous décrivons ses différents cas d'utilisation. Ne manquez pas notre prochain billet de blog pour une analyse technique approfondie de la conception et de l'architecture de Dicer.
3.1 Présentation générale de Dicer
Dicer modélise une application comme traitant des requêtes (ou effectuant une autre tâche) associées à une clé logique. Par exemple, un service qui fournit des profils utilisateur pourrait utiliser les ID utilisateur comme clés. Dicer segmente l'application en générant continuellement une attribution de clés aux pods pour maintenir la haute disponibilité et l'équilibrage de la charge du service.
Pour monter en charge des applications avec des millions ou des milliards de clés, Dicer fonctionne sur des plages de clés plutôt que sur des clés individuelles. Les applications représentent des clés pour Dicer à l'aide d'une SliceKey (un hachage de la clé d'application), et une plage contiguë de SliceKeys est appelée une Slice. Comme le montre la figure 1, une affectation Dicer est un ensemble de Slices qui couvrent ensemble l'intégralité de l'espace de clés de l'application, chaque Slice étant affecté à une ou plusieurs Ressources (c'est-à-dire. pods). Dicer divise, fusionne, réplique et réaffecte dynamiquement les Slices en réponse aux signaux de santé et de charge de l'application, garantissant que l'intégralité de l'espace de clés est toujours affectée à des pods sains et qu'aucun pod ne soit surchargé. Dicer peut également détecter les clés très sollicitées et les diviser dans leurs propres slices, et affecter ces slices à plusieurs pods pour répartir la charge.
La figure 1 montre un exemple d'attribution Dicer sur 3 pods (P0, P1 et P2) pour une application partitionnée par ID utilisateur, où l'utilisateur avec l'ID 13 est représenté par la SliceKey K26 (c'est-à-dire un hachage de l'ID 13) et est actuellement attribué au pod P0. Un utilisateur à fort trafic avec l'ID utilisateur 42 et représenté par la SliceKey K10 a été isolé dans sa propre slice et attribué à plusieurs pods pour gérer la charge (P1 et P2).

{kind=link}
La figure 2 présente une vue d'ensemble d'une application partitionnée intégrée à Dicer. Les pods d'application prennent connaissance de l'affectation actuelle par le biais d'une bibliothèque appelée Slicelet (S pour côté serveur). Le Slicelet conserve un cache local de la dernière affectation en la récupérant auprès du service Dicer et en surveillant les mises à jour. Lorsqu'il reçoit une affectation mise à jour, le Slicelet en informe l'application via une API d'écoute.
Les attributions observées par les Slicelets sont à cohérence éventuelle, un choix de conception délibéré qui privilégie la disponibilité et une récupération rapide par rapport à de fortes garanties de propriété des clés. D'après notre expérience, ce modèle s'est avéré être le bon pour la grande majorité des applications, bien que nous prévoyions de prendre en charge des garanties plus fortes à l'avenir, similaires à Slicer et Centrifuge.
En plus de se tenir à jour sur l'assignation, les applications utilisent également le Slicelet pour enregistrer la charge par clé lors du traitement des requêtes ou de l'exécution d'un travail pour une clé. Le Slicelet agrège ces informations localement et envoie un résumé de manière asynchrone au service Dicer. Notez que, comme pour la surveillance de l'assignation, cela se produit également en dehors du chemin critique de l'application, ce qui garantit des performances élevées.
Les clients d'une application Dicer partitionnée trouvent le pod attribué pour une clé donnée via une bibliothèque appelée le Clerk (C pour côté client). Tout comme les Slicelets, les Clerks maintiennent également activement un cache local de la dernière attribution en arrière-plan afin de garantir des performances élevées pour les recherches de clés sur le chemin critique.

Enfin, l'Assigner Dicer est le service de contrôleur responsable de la génération et de la distribution des affectations en fonction des signaux de santé et de charge de l'application. À la base se trouve un algorithme de fragmentation qui calcule des ajustements minimaux par le biais de divisions de Slices, de fusions, de réplications/déréplications et de déplacements afin de maintenir les clés affectées à des pods sains et l'application globale suffisamment équilibrée en charge. Le service Assigner est multilocataire et conçu pour fournir un service de fragmentation automatique à toutes les applications fragmentées au sein d'une région. Chaque application fragmentée desservie par Dicer est désignée sous le nom de Target.
3.2 Large classe d'applications améliorées par Dicer
Dicer est utile pour un large éventail de systèmes, car la capacité d'affinitiser les charges de travail à des pods spécifiques entraîne des améliorations significatives des performances. Nous avons identifié plusieurs catégories principales de cas d'utilisation en nous basant sur notre expérience en production.
Service en mémoire et sur GPU
Dicer excelle dans les scénarios où un grand corpus de données doit être chargé et servi directement depuis la mémoire. En s'assurant que les requêtes pour des clés spécifiques atteignent toujours les mêmes pods, des services tels que les magasins clé-valeur peuvent atteindre une latence inférieure à la milliseconde et un throughput élevé, tout en évitant la surcharge liée à la récupération des données depuis un stockage distant.
Dicer est également bien adapté aux charges de travail d'inférence des LLM modernes, où le maintien de l'affinité est essentiel. Les exemples incluent des sessions utilisateur avec état qui accumulent du contexte dans un cache KV par session, ainsi que des déploiements qui servent un grand nombre d'adaptateurs LoRA et doivent les partitionner efficacement sur des ressources GPU limitées.
Systèmes de contrôle et de planification
C'est l'un des cas d'utilisation les plus courants chez Databricks. Il inclut des systèmes tels que des gestionnaires de clusters et des moteurs d'orchestration de query qui surveillent en permanence les Ressources pour gérer la mise à l'échelle, la planification des compute et le multi-tenant. Pour fonctionner efficacement, ces systèmes maintiennent un état de monitoring et de contrôle localement, évitant les sérialisations répétées et permettant des réponses rapides aux changements.
Caches distants
Dicer peut être utilis�é pour créer des caches distants distribués à hautes performances, ce que nous avons fait en production chez Databricks. En utilisant les capacités de Dicer, notre cache peut être autoscalé et redémarré de manière transparente sans perte de taux de succès, et éviter le déséquilibre de charge dû aux clés chaudes.
Partitionnement des tâches et travail en arrière-plan
Dicer est un outil efficace pour partitionner les tâches d'arrière-plan et les flux de travail asynchrones sur un parc de serveurs. Par exemple, un service chargé du nettoyage ou de la récupération de la mémoire de l'état dans une table de très grande taille peut utiliser Dicer pour garantir que chaque pod est responsable d'une plage distincte et non chevauchante de l'espace de clés, ce qui évite le travail redondant et les conflits de verrouillage.
Traitement par lots et agrégation
Pour les chemins d'écriture à grand volume, Dicer permet une agrégation efficace des enregistrements. En routant les enregistrements liés vers le même pod, le système peut regrouper les mises à jour par lots en mémoire avant de les commettre dans le stockage persistant. Cela réduit considérablement les opérations d'entrée/sortie par seconde requises et améliore le throughput global du pipeline de données.
Sélection souple du leader
Dicer peut être utilisé pour mettre en œuvre une sélection "souple" de leader en désignant un pod spécifique comme coordinateur principal pour une clé ou un shard donné. Par exemple, un planificateur de service peut utiliser Dicer pour s'assurer qu'un seul pod agisse en tant qu'autorité principale pour la gestion d'un groupe de ressources. Bien que Dicer fournisse actuellement une sélection de leader basée sur l'affinité, il constitue une base solide pour les systèmes qui nécessitent un primaire coordonné sans la lourde surcharge des protocoles de consensus traditionnels. Nous explorons des améliorations futures pour fournir des garanties plus fortes autour de l'exclusion mutuelle pour ces charges de travail.
Rendez-vous et Coordination
Dicer agit comme un point de rendez-vous naturel pour les clients distribués ayant besoin d'une coordination en temps réel. En routant toutes les requêtes pour une clé spécifique vers le même pod, ce pod devient un point de rencontre central où l'état partagé peut être géré dans la mémoire locale sans sauts réseau externes.
Par exemple, dans un service de chat en temps réel, deux clients rejoignant le même "Chat Room ID" sont automatiquement redirigés vers le même pod. Cela permet au pod de synchroniser leurs messages et leur état instantanément en mémoire, en évitant la latence d'une base de données partagée ou d'un back-plane complexe pour la communication.
4. Histoires de succès
De nombreux services chez Databricks ont réalisé des gains significatifs grâce à Dicer, et nous présentons plusieurs de ces réussites ci-dessous.
4.1 Unity Catalog
Unity Catalog (UC) est la solution de gouvernance unifiée pour les actifs de données et d'IA sur la plateforme Databricks. Conçu à l'origine comme un service sans état (stateless), UC a été confronté à d'importants défis de mise à l'échelle au fur et à mesure que sa popularité augmentait, principalement en raison d'un volume de lecture extrêmement élevé. Le traitement de chaque requête nécessitait des accès répétés à la base de données backend, ce qui entraînait une latence prohibitive. Les approches conventionnelles telles que la mise en cache à distance n'étaient pas viables, car le cache devait être mis à jour de manière incrémentielle et conserver une cohérence de type snapshot avec le stockage. De plus, les catalogues des clients peuvent atteindre plusieurs gigaoctets, ce qui rend coûteux le maintien de snapshots partiels ou répliqués dans un cache à distance sans introduire une surcharge (overhead) substantielle.
Pour résoudre ce problème, l'équipe a intégré Dicer afin de créer un cache d'état en mémoire fragmenté. Ce changement a permis à UC de remplacer les coûteux appels réseau distants par des appels de méthode locaux, ce qui a réduit considérablement la charge de la base de données et amélioré la réactivité. La figure ci-dessous illustre le déploiement initial de Dicer, suivi du déploiement de l'intégration complète de Dicer. En utilisant l'affinité d'état de Dicer, UC a atteint un taux de réussite de cache de 90 à 95 %, ce qui a permis de réduire considérablement la fréquence des allers-retours avec la base de données.

{kind=link}
4.2 Moteur d'orchestration de requêtes SQL
Le moteur d'orchestration de requêtes de Databricks, qui gère la planification des requêtes sur les clusters Spark, a été initialement conçu comme un service stateful en mémoire utilisant le sharding statique. À mesure que le service montait en charge, les limites de cette architecture sont devenues un goulot d'étranglement majeur ; en raison de la simplicité de son implémentation, la mise à l'échelle nécessitait un re-sharding manuel extrêmement fastidieux, et le système subissait de fréquentes baisses de disponibilité, y compris lors des redémarrages progressifs.
Après l'intégration avec Dicer, ces problèmes de disponibilité ont ét�é éliminés (voir la figure 4). Dicer a permis d'atteindre zéro temps d'arrêt pendant les redémarrages et les événements de mise à l'échelle, permettant à l'équipe de réduire les tâches répétitives et d'améliorer la robustesse du système en activant la mise à l'échelle automatique partout. De plus, la fonctionnalité d'équilibrage de charge dynamique de Dicer a également résolu le bridage chronique du processeur, se traduisant par des performances plus cohérentes sur l'ensemble du parc.
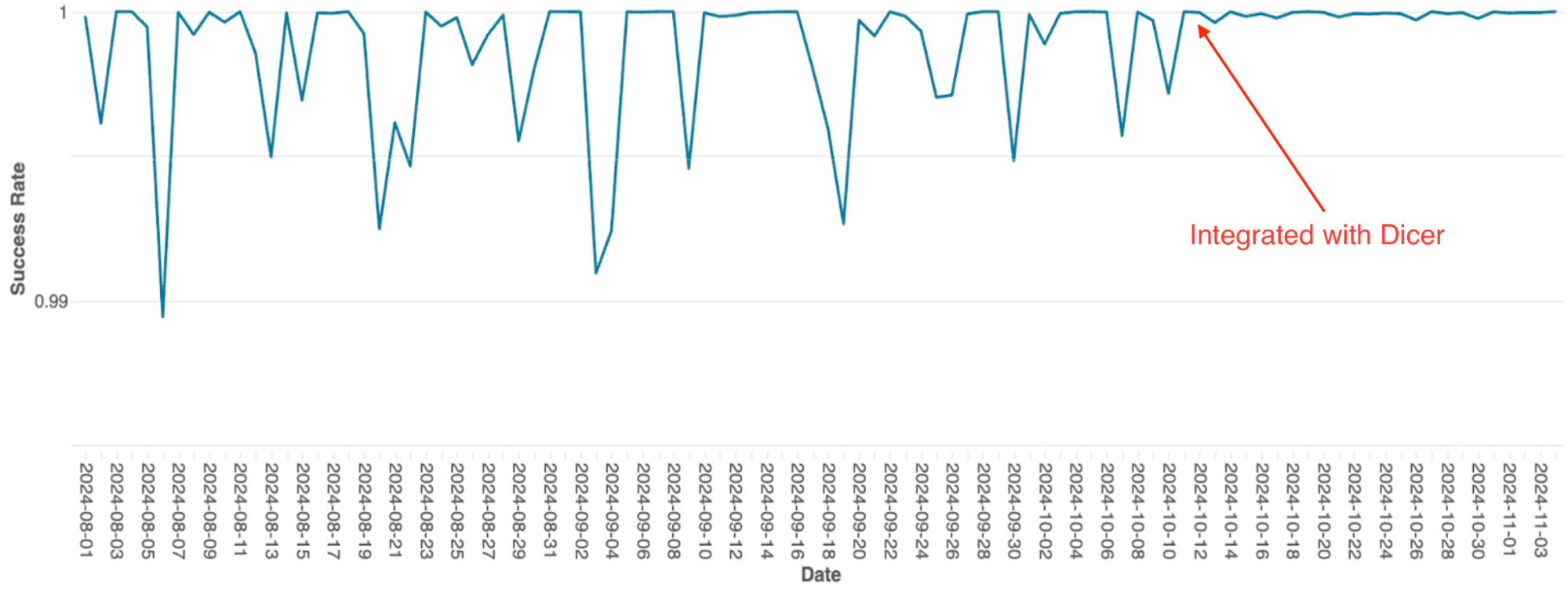
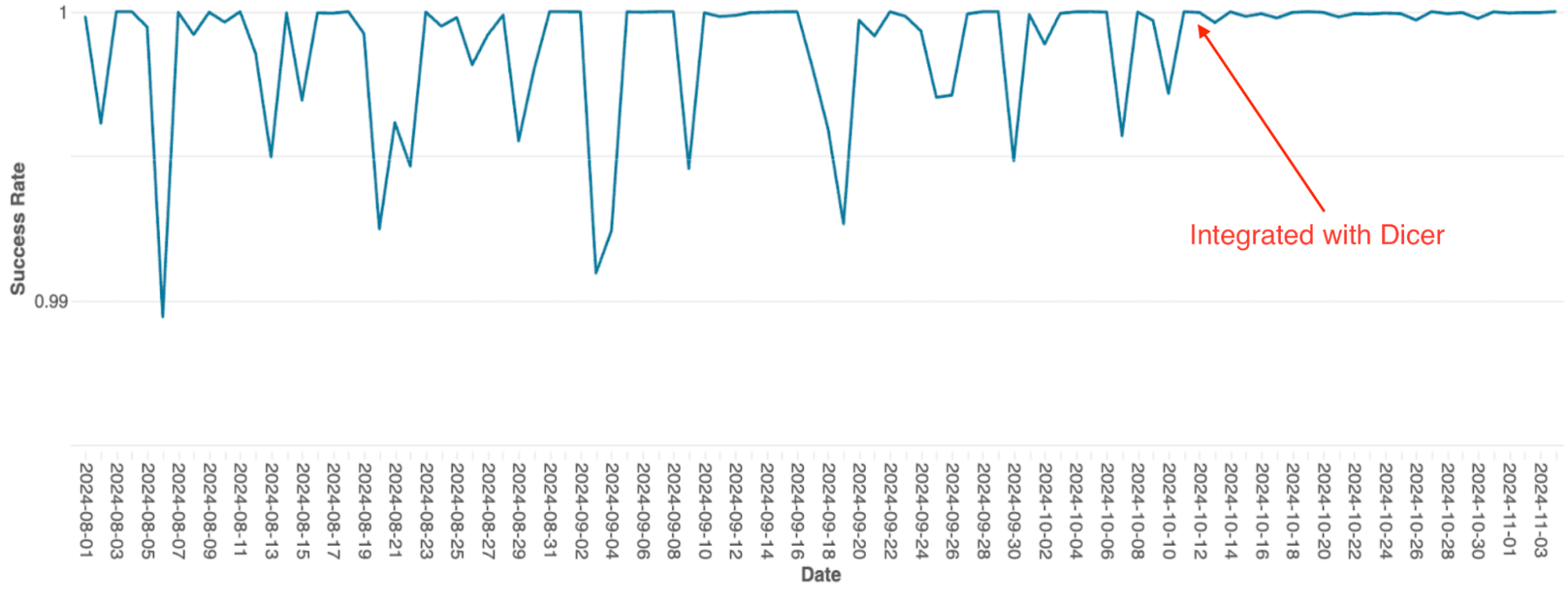{kind=link}
4.3 Cache distant Softstore
Pour les services qui ne sont pas partitionnés, nous avons développé Softstore, un cache clé-valeur distant et distribué. Softstore exploite une fonctionnalité de Dicer appelée transfert d'état, qui migre les données entre les pods pendant le repartitionnement pour préserver l'état de l'application. Ceci est particulièrement important lors des redémarrages progressifs planifiés, où l'espace de clés complet est inévitablement remanié. Dans notre parc de production, les redémarrages planifiés représentent environ 99,9 % de tous les redémarrages, ce qui rend ce mécanisme particulièrement efficace et permet des redémarrages transparents avec un impact négligeable sur les taux de réussite du cache. La figure 5 montre les taux de réussite de Softstore pendant un redémarrage progressif, où le transfert d'état préserve un taux de réussite stable d'environ 85 % pour un cas d'utilisation représentatif, la variabilité restante étant due aux fluctuations normales de la charge de travail.
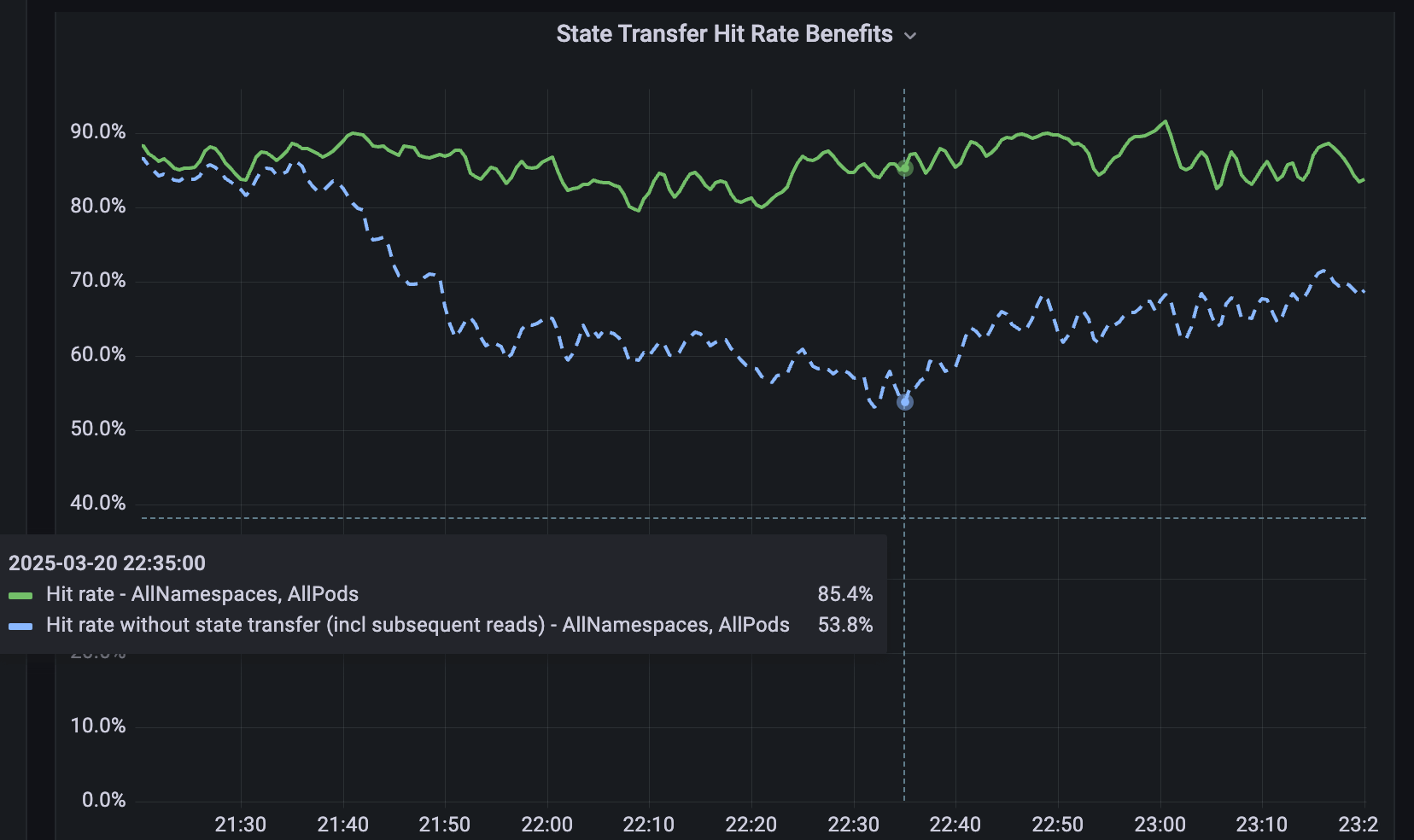
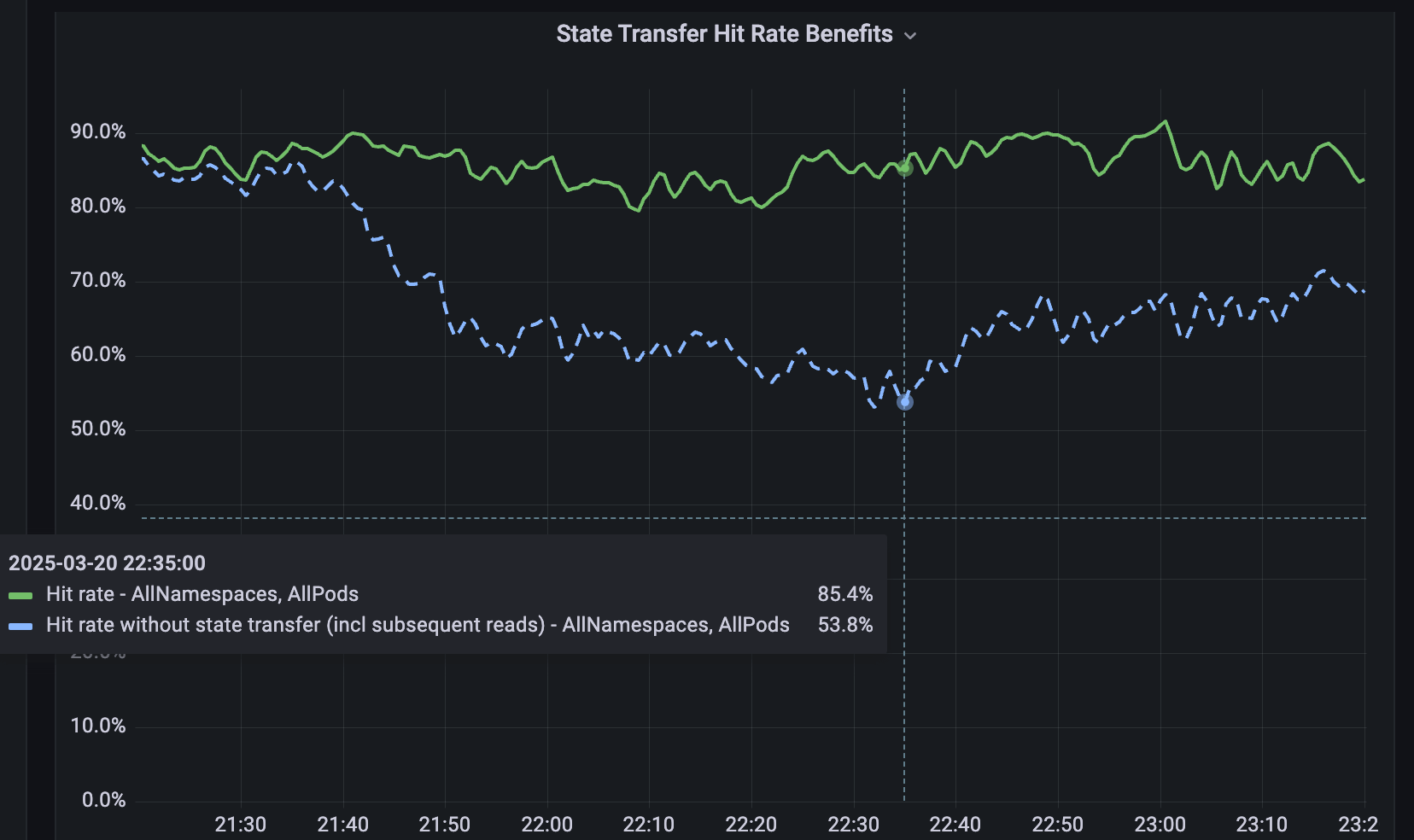{kind=link}
5. Maintenant, vous pouvez l'utiliser aussi !
Vous pouvez essayer Dicer dès aujourd'hui sur votre machine en le téléchargeant ici. Une démonstration simple pour illustrer son utilisation est disponible ici : elle présente un exemple de configuration Dicer avec un client et quelques serveurs pour une application. Veuillez consulter le README et le guide de l'utilisateur de Dicer.
6. Fonctionnalités et articles à venir
Dicer est un service essentiel utilisé au sein de Databricks, et son utilisation augmente rapidement. À l'avenir, nous publierons d'autres articles sur le fonctionnement interne et la conception de Dicer. Nous déploierons également de nouvelles fonctionnalités au fur et à mesure que nous les développons et les testons en interne, par exemple, des bibliothèques Java et Rust pour les clients et les serveurs, et les capacités de transfert d'état mentionnées dans cet article. N'hésitez pas à nous faire part de vos commentaires et restez à l'écoute pour la suite !
Si vous aimez résoudre des problèmes de Data Engineering complexes et que vous souhaitez rejoindre Databricks, rendez-vous sur databricks.com/careers!
7. Références
[1] Ziming Mao, Jonathan Ellithorpe, Atul Adya, Rishabh Iyer, Matei Zaharia, Scott Shenker, Ion Stoica (2025). Repenser le coût des caches distribués pour les services de centre de données. Actes du 24e atelier de l'ACM sur les sujets d'actualité dans les réseaux, 1-8.
[2] Atul Adya, Robert Grandl, Daniel Myers, Henry Qin. Fast key-value stores: An idea whose time has come and gone. Proceedings of the Workshop on Hot Topics in Operating Systems (HotOS ’19), 13–15 mai 2019, Bertinoro, Italie. ACM, 7 pages. DOI: 10.1145/3317550.3321434.
[3] Atul Adya, James Dunagan, Alexander Wolman. Centrifuge: Integrated Lease Management and Partitioning for Cloud Services. Actes du 7e symposium USENIX sur la conception et la mise en œuvre de systèmes en réseau (NSDI), 2010.
[4] Atul Adya, Daniel Myers, Jon Howell, Jeremy Elson, Colin Meek, Vishesh Khemani, Stefan Fulger, Pan Gu, Lakshminath Bhuvanagiri, Jason Hunter, Roberto Peon, Larry Kai, Alexander Shraer, Arif Merchant, Kfir Lev-Ari. Slicer: Auto-Sharding for Datacenter Applications. Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI), 2016, p. 739–753.
[5] Sangmin Lee, Zhenhua Guo, Omer Sunercan, Jun Ying, Chunqiang Tang, et al. Shard Manager: A Generic Shard Management Framework for Geo distributed Applications. Actes du 28e Symposium de l'ACM SIGOPS sur les principes des systèmes d'exploitation (SOSP), 2021. DOI : 10.1145/3477132.3483546.
[6] Atul Adya, Jonathan Ellithorpe. Services avec état (stateful) : faible latence, efficacité, scalabilité — choisissez les trois. High Performance Transaction Systems Workshop (HPTS) 2024, Pacific Grove, Californie, 15-18 septembre 2024.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.