La pierre de Rosette de la CPS : la bibliothèque d'IA de Claroty
Comment un système IA multi-agents sur Databricks résout la crise d'identité des CPS
par Ben Hazan, Anton Berlinsky, Ohad Avni, Itay Wagner, Guy Zalcman , Dor Bdolach, Ravid Ariely et Gal Sberro
- La bibliothèque IA de Claroty pour les CPS résout la crise d'identité des actifs - où 88 % des appareils CPS manquent d'un code produit exact - en automatisant la résolution d'entités sur plus de 17 millions d'actifs industriels et de santé.
- Un système IA multi-agents construit sur les Agents personnalisés de Databricks combine des agents NLP et de raisonnement avec un retour d'information humain en boucle, alimenté par une architecture Medallion sur Delta Lake, pour transformer les signaux d'appareils fragmentés en une source de vérité déterministe unique.
- Le résultat : Rien qu'en MVP, nous avons constaté une amélioration de plus de 25 % de la précision de l'attribution des vulnérabilités et plus de 56 % des appareils analysés ont reçu de nouvelles recommandations de sécurité pour des micrologiciels obsolètes auparavant invisibles.
La pierre de Rosette des systèmes cyber-physiques : Au cœur de la bibliothèque révolutionnaire de Claroty basée sur l'IA
Depuis des décennies, le monde des systèmes cyber-physiques (CPS) - les machines qui alimentent nos usines, hôpitaux et infrastructures critiques - souffre d'une "crise d'identité" silencieuse. Alors qu'un administrateur informatique peut facilement identifier chaque ordinateur portable sur son réseau, une équipe de sécurité OT (technologie opérationnelle) a souvent du mal à savoir exactement ce qui fonctionne sur son site de production.
Un récent rapport de l'équipe de recherche Team82 de Claroty a révélé une réalité stupéfiante : 88 % des actifs CPS ne transmettent pas de code produit exact, et 76 % utilisent des codes produit qui diffèrent des enregistrements officiels du fournisseur. Ce manque de "certificat de naissance numérique" rend la gestion des vulnérabilités presque impossible, car les équipes de sécurité sont obligées de rassembler manuellement des informations à partir de ressources incohérentes.
Pour résoudre ce problème, Claroty a récemment dévoilé sa bibliothèque de systèmes cyber-physiques basée sur l'IA, un moteur de cartographie faisant autorité, unique en son genre, conçu pour être le "traducteur universel" du matériel industriel et de santé.
À la base, il s'agit d'un défi de résolution d'entités (ER), et le but du système est de résoudre la crise d'identité en faisant correspondre et en consolidant des données bruitées du monde réel en une source unique de vérité. Pour obtenir une traçabilité déterministe de haute fidélité, nous sommes allés au-delà des algorithmes de correspondance standard, en concevant une architecture hybride qui combine des méthodes ER classiques éprouvées avec la puissance cognitive de l'IA générative.
En réponse à un problème critique de l'industrie, nous nous sommes associés à Databricks dans le cadre de leur programme GenAI MVP. Cette collaboration exploite notre offre spécialisée et les capacités de données et d'IA de Databricks pour apporter une solution définitive au problème.
Ce à quoi cela ressemble en réalité
Imaginez une situation typique dans une usine : le xDome de Claroty trouve un appareil avec un numéro de modèle comme 1769-L36ERMS/B utilisant le protocole CIP. Pour une personne ou un simple outil de sécurité, il ne s'agit que d'un code interne Rockwell Automation - il n'est dans aucune base de données de vulnérabilités et ne suggère pas immédiatement de risque.
Pour sécuriser cet appareil, le personnel devrait normalement déterminer manuellement de quoi il s'agit, ce qui implique :
- Recherche sur le Web : Consulter les catalogues de Rockwell pour découvrir que ce code correspond à un contrôleur Compact GuardLogix 5370.
- Vérification des vulnérabilités : Rechercher les avertissements CISA pour ce nom, ce qui pourrait indiquer CVE-2020-6998 comme risque pour "les versions 33 et antérieures".
- Confirmation des détails : Vérifier la NVD (National Vulnerability Database) pour voir si le CPE (Common Platform Enumeration) spécifique correspond, pour ne trouver qu'une entrée générale pour "CompactLogix 5370 L3" qui peut ou non inclure le sous-type "GuardLogix".
Ce "travail de détective" manuel est souvent le point où la sécurité échoue. La bibliothèque de systèmes cyber-physiques basée sur l'IA automatise l'ensemble de ce processus. Elle reconnaît instantanément le code interne, le relie au nom commercial, identifie les pièces et les versions de firmware spécifiques, et associe les CVE corrects avec une précision absolue, transformant une chaîne de caractères confuse en une configuration claire et sécurisée en quelques millisecondes.
Résoudre la crise d'identité avec une visibilité déterministe
La bibliothèque de systèmes cyber-physiques n'est pas seulement une base de données ; c'est un système d'IA multi-agents qui permet une remédiation "du dernier kilomètre". En partenariat avec des géants de l'industrie, Claroty a construit un graphe de preuves qui réconcilie les données réseau désordonnées en une source unique de vérité.
Avancées clés :
- Traçabilité déterministe : Même lorsqu'un appareil signale des données minimales, la bibliothèque utilise l'inférence statistique et la logique guidée par le domaine pour trianguler son identité exacte.
- Attribution des vulnérabilités : En identifiant des sous-composants et des arbres de firmware spécifiques, la bibliothèque a amélioré de 25 % la précision de l'identification des vulnérabilités.
- Informations exploitables : Lors des premiers tests, 56 % des appareils analysés ont reçu des recommandations de sécurité nouvelles ou mises à jour pour des firmwares obsolètes qui étaient auparavant invisibles pour les équipes de sécurité.
Sous le capot : Le moteur d'intelligence de données Databricks
Pour gérer un catalogue mondial de plus de 17 millions d'actifs et leurs dépendances complexes, Claroty s'appuie sur la plateforme d'intelligence de données Databricks comme colonne vertébrale unifiée. En adoptant une architecture Lakehouse, Claroty élimine les silos de données traditionnels, permettant l'ingestion de divers ensembles de données - des protocoles OT propriétaires et des appels API aux manuels PDF de fournisseurs non structurés - dans un environnement unique et évolutif. Cette base fournit la puissance de calcul haute performance nécessaire pour exécuter des modèles d'inférence statistique complexes sur des millions de points de données, garantissant que chaque CPS-ID (la nouvelle norme industrielle pour l'identité des systèmes cyber-physiques par Claroty) est soutenu par une intégrité des données rigoureuse et une intelligence inter-silos.
Ingénierie des données à grande échelle : Le pipeline Medallion
L'alimentation de cet écosystème est une architecture Medallion robuste construite sur Delta Lake et gouvernée dans Unity Catalog. Le parcours commence dans la couche Bronze, où les charges utiles JSON brutes et hétérogènes sont capturées dans des tables Delta en mode ajout seul. De là, un pipeline de promotion - lisant à partir du Delta Change Data Feed (CDF) - applique dynamiquement un registre de mappage pour transformer les preuves brutes en un schéma canonique gouverné. En utilisant l'évolution de schéma et le voyage dans le temps de Delta Lake, Claroty maintient une chaîne de possession ininterrompue ; chaque enregistrement d'actif est traçable jusqu'à son artefact brut d'origine et la version de mappage spécifique qui l'a classifié, garantissant une auditabilité complète, même dans les environnements industriels les plus sensibles.
Intelligence multi-agents via les agents personnalisés de Databricks
La partie la plus sophistiquée de ce moteur hybride est son utilisation des agents personnalisés de Databricks. Plutôt que de s'appuyer sur un seul modèle monolithique, Claroty a conçu un système multi-agents orchestré, un réseau synchronisé où des agents IA spécialisés collaborent pour interpréter des signaux complexes.
Pour alimenter ces agents avec un contexte fiable, nous combinons l'analyse statistique classique des données structurées collectées à partir de sources propriétaires avec des techniques NLP avancées qui extraient des signaux du bruit inhérent à la documentation des fournisseurs, aux fiches techniques et aux sources Web ouvertes. Unity Catalog de Databricks fournit la base de données gouvernée nécessaire pour unifier ces divers ensembles de données, tandis que les pipelines basés sur Spark traitent et normalisent les informations à grande échelle. Ensemble, ces capacités synthétisent des informations fragmentées et incohérentes en réponses précises et contextualisées dont les agents ont besoin pour fournir des correspondances de résolution d'entités précises.
Le système est construit autour de trois composants principaux :
- Agents NLP : Analysent des données complexes et mixtes, y compris des chaînes de noms dérivées de protocoles et des marqueurs logiciels obscurs que les modèles standard manquent souvent.
- Agents de raisonnement : Appliquent une notation de confiance et des tests statistiques pour peser les preuves, distinguant les signaux de haute fidélité du bruit pour garantir l'intégrité des données.
- Interaction humaine (HITL) : Un mécanisme de rétroaction critique qui signale les correspondances de faible confiance pour examen par un expert. La sortie de ces sessions est réinjectée dans le système, réentraînant les modèles pour des gains de précision continus.
Innovation grâce aux capacités de Databricks
Le succès de cette architecture réside non seulement dans les agents eux-mêmes, mais aussi dans l'écosystème de bout en bout basé sur Databricks qui les alimente. Nous avons exploité toute la portée de la plateforme pour passer du MVP à la production avec rapidité et fiabilité :
1. Intelligence spécifique au domaine via le service de modèles Pour aborder les nuances des soins de santé et de l'OT, les embeddings génériques étaient insuffisants pour le niveau de précision dont nous avons besoin. Nous avons identifié que pour que le "Traducteur Universel" réussisse vraiment, les architectures RAG génériques doivent évoluer vers des cadres spécifiques au domaine. Nous comblons actuellement cet écart en déployant des modèles d'embedding médicaux de pointe en tant que points de terminaison personnalisés à l'aide du service de modèles Databricks. Cependant, en regardant vers l'avenir, nous considérons le fine-tuning de ces modèles comme la prochaine étape logique pour garantir que nos agents comprennent les dialectes industriels les plus obscurs avec une précision déterministe.
2. RAG avancé et extraction d'informations Nous avons exploité le Knowledge Assistant pour construire des systèmes RAG (Retrieval-Augmented Generation) robustes capables d'ingérer de grandes quantités de documentation propriétaire. En utilisant un agent d'extraction d'informations, nous pouvons analyser structurellement des documents propriétaires non structurés, transformant le texte brut en renseignements exploitables pour la bibliothèque de systèmes cyber-physiques.
3. Gestion complète du cycle de vie avec MLflow qui sert de colonne vertébrale à notre cycle de vie de développement ML, fournissant une plateforme unifiée depuis la phase MVP initiale jusqu'à l'évaluation rigoureuse et le déploiement final.
- Évaluation Continue : Nous avons mis en œuvre une stratégie d'évaluation complète utilisant "LLM comme Juge" aux côtés de sessions d'étiquetage manuelles. Les capacités de MLflow nous ont permis d'évaluer constamment les performances du modèle pour prévenir la dérive conceptuelle.
- Observabilité et Surveillance : En production, nous utilisons les fonctionnalités d'observabilité de MLflow pour surveiller la santé des agents en temps réel. Cela inclut le suivi de l'utilisation des jetons et des coûts d'infrastructure, l'identification des goulots d'étranglement de latence et la détection de bugs potentiels avant qu'ils n'affectent les utilisateurs. Un axe stratégique est l'efficacité des coûts de nos index de recherche vectorielle. Bien que les performances soient exceptionnelles, l'absence actuelle d'un modèle "scale-to-zero" pour les points de terminaison vectoriels — une nuance particulièrement pertinente pour la nature intermittente et événementielle des données de sécurité industrielle — nous oblige à concevoir des modèles architecturaux spécifiques pour maintenir un ROI élevé pendant les périodes d'inactivité.
En fusionnant les méthodes classiques de résolution d'entités avec une stratégie multi-agents sophistiquée et orchestrée — soutenue par l'infrastructure robuste de Databricks — nous avons créé une couche d'intelligence auto-améliorante, rentable et hautement précise. Ce système comble enfin le fossé entre les données réseau désordonnées et la source unique de vérité, résolvant la crise d'identité pour la sécurité des CPS.
Automatisation à l'aide des Jobs, Pipelines et LLM
Pour gérer la grande quantité d'informations provenant de diverses sources, Claroty utilise les Jobs Lakeflow pour orchestrer l'ensemble du processus - des données brutes à une table bien structurée.
L'un de nos pipelines orchestre un processus ETL qui analyse CSAF, un avis de sécurité formaté en JSON, dans une structure tabulaire. Dans ce processus, chaque étape lit et écrit des entrées dans une table delta dédiée.
Dans cet ETL, et dans de nombreux autres cas d'utilisation, nous utilisons les LLM pour enrichir les données - des tâches de classification et des fonctions d'IA comme ai_query, en utilisant divers points de terminaison de service et MLflow pour évaluer les réponses que nous obtenons du LLM, en utilisant des métriques statistiques et LLM-as-a-judge, et en surveillant le coût.
Pour maintenir ce pipeline fiable à grande échelle, nous utilisons une approche LLM comme Juge pour évaluer en continu la qualité de nos propres sorties LLM. Au lieu de nous fier uniquement à une vérité terrain entièrement étiquetée — qui est souvent manquante ou ambiguë dans les données CPS du monde réel — nous laissons un modèle juge dédié examiner la réponse d'un autre modèle et décider si elle semble acceptable. Le travail du juge est simple et conservateur : marquer chaque résultat comme réussite, semble correct, échec, semble incorrect, ou inconnu, informations insuffisantes. Tous ces juges sont stockés dans une table Delta. En utilisant cette méthode, nos équipes peuvent charger des échantillons d'évaluation, lancer des juges MLflow GenAI personnalisés et exécuter des évaluations structurées. Les capacités natives de surveillance GenAI de MLflow nous offrent un moyen cohérent de surveiller la qualité, de comparer les versions et de détecter les régressions dans de nombreux cas d'utilisation de LLM — sans avoir à construire une pile d'évaluation personnalisée pour chaque nouveau flux de travail.
Intégrité Transactionnelle avec Lakebase
Pour que la "Bibliothèque" fonctionne, les données doivent être cohérentes et hautement disponibles. Claroty intègre Lakebase, une couche de données transactionnelle entièrement gérée sur Databricks. Lakebase est construit sur Postgres et offre les performances à faible latence requises pour les requêtes en temps réel tout en maintenant un lien transparent avec le Lakehouse plus large pour le traitement analytique, permettant des contraintes strictes pour garantir que nos données conservent leur haute qualité et s'assurer que les correspondances d'actifs restent précises même lorsque les configurations dérivent.
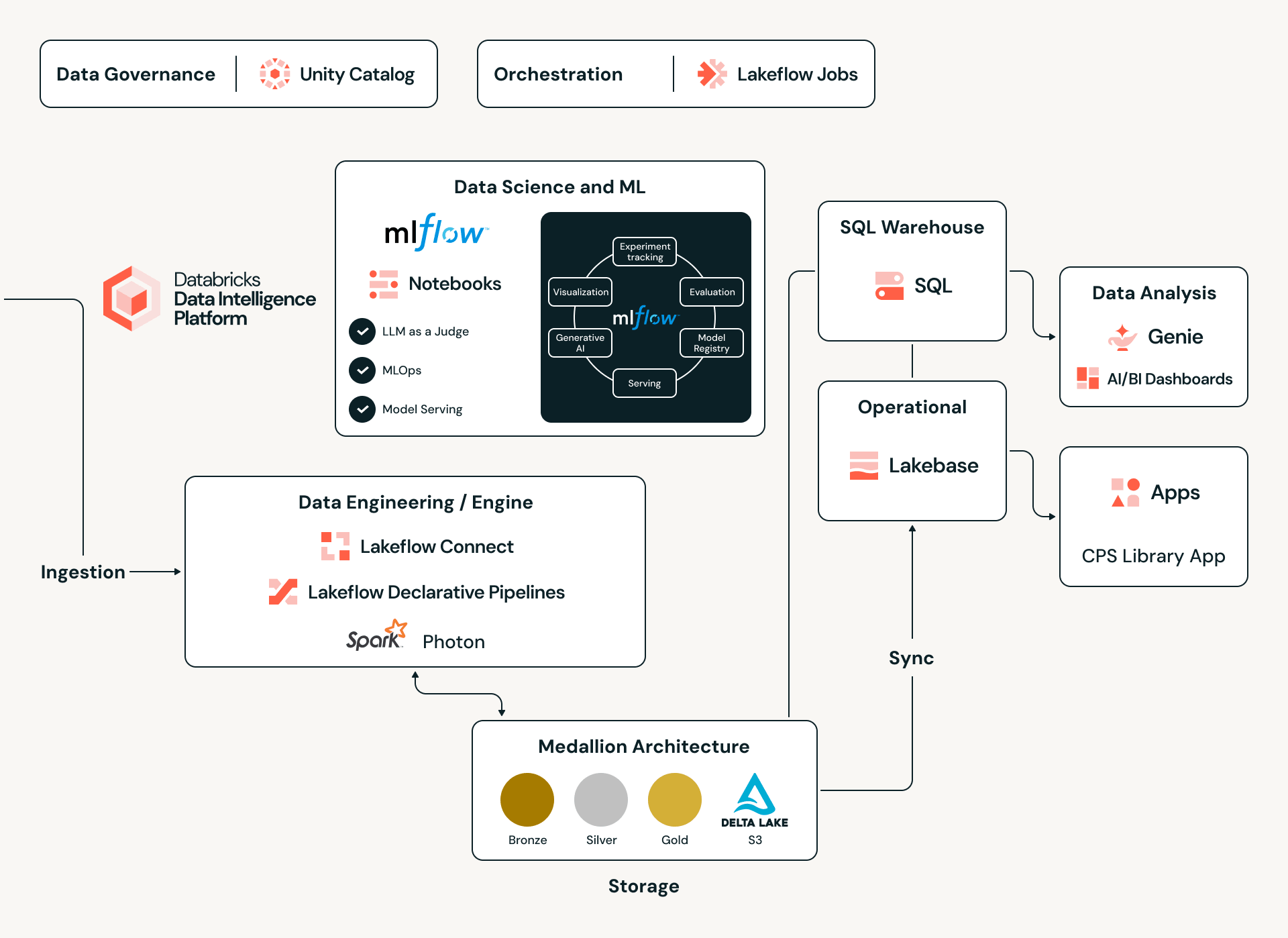
Innovation Rapide avec Databricks Apps
Pour rassembler toutes ces informations, nous utilisons Databricks Apps, une fonctionnalité qui permet à Claroty de créer et de déployer des applications complètes et gourmandes en données directement dans l'environnement Databricks. En utilisant des frameworks d'interface utilisateur modernes (tels que React ou Streamlit) pour le frontend, et Lakebase, la base de données OLTP Postgres entièrement gérée de Databricks, pour les charges de travail transactionnelles, nous pouvons héberger la logique de l'application et les données opérationnelles sur la même plateforme que notre lakehouse. Cela signifie que l'application hérite de la sécurité, de la gouvernance et de l'authentification intégrées de la plateforme (via Unity Catalog et OAuth), tout en éliminant le besoin de serveurs d'applications, de bases de données et de pipelines de déploiement distincts. Ce qui nécessiterait traditionnellement de rassembler plusieurs piles technologiques et services est consolidé en une solution unique, rentable et robuste.
Human-in-the-Loop via Databricks Apps
Bien que nos pipelines d'IA automatisent le gros du travail, le besoin principal sur le terrain pour créer la confiance est le retour d'information des experts métier (SME) via une boucle humaine. Avec Databricks App et Lakebase, nous permettons une vue transparente et un cycle de rétroaction "human-in-the-loop" transparent. Cette interface intuitive permet aux experts du domaine de revoir les classifications, de corriger et d'enrichir les entités, et de renvoyer des données validées de haute fidélité dans nos pipelines MLflow et notre migration R&D, garantissant ainsi que le système devient plus intelligent et plus précis au fil du temps.
L'Avenir de la Résilience
En combinant l'expertise approfondie de Claroty dans les protocoles OT avec la puissance de la plateforme Databricks, la Bibliothèque CPS établit une nouvelle norme. Il ne s'agit plus seulement de voir qu'un appareil existe, il s'agit de savoir exactement ce qu'il est, quels risques il présente et comment le corriger avec une confiance totale.
Le leadership de Claroty dans ce domaine a été récemment validé par sa nomination en tant que Leader dans le Gartner® Magic Quadrant™ 2025 pour les plateformes de protection CPS, positionné le plus haut pour sa "Capacité d'exécution". Alors que l'industrie progresse, cette approche "axée sur l'identité" sera le fondement du renforcement de la résilience dans chaque environnement connecté.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.