Mise à l'échelle des petits LLM avec NVIDIA MPS
Les petits modèles deviennent rapidement plus performants et applicables à une grande variété de cas d'utilisation en entreprise. Dans le même temps, chaque nouvelle génération de GPU offre considérablement plus de compute et de bande passante mémoire. Les résultats Même avec des charges de travail à high concurrency, les petits LLM laissent souvent une grande partie du compute et de la bande passante mémoire du GPU inutilisée.
Avec des cas d'utilisation tels que la complétion de code, la recherche d'informations, la correction grammaticale ou les modèles spécialisés, nos clients professionnels servent de nombreux petits modèles de langage de ce type sur Databricks, et nous poussons constamment les GPU à leurs limites. Le service Multi-Process (MPS) de NVIDIA semblait être un outil prometteur : il permet à plusieurs processus d'inférence de partager un seul contexte GPU, autorisant le chevauchement de leurs Opérations de mémoire et de compute, ce qui permet d'exploiter bien plus efficacement le même matériel.
Nous avons entrepris de tester rigoureusement si MPS offre un throughput plus élevé par GPU dans nos environnements de production. Nous avons constaté que MPS offre des gains de débit significatifs dans les cas suivants :
- Modèles de langage de très petite taille (≤ 3 milliards de paramètres) avec un contexte court à moyen (<2k tokens)
- Très petits modèles de langage (<3B) dans des charges de travail de pré-remplissage uniquement
- Moteurs avec une surcharge CPU importante
L'explication principale, basée sur nos études d'ablation, est double : au niveau du GPU, le MPS permet un chevauchement significatif des noyaux (kernels) lorsque les moteurs individuels sous-utilisent le compute ou la bande passante mémoire (en particulier pendant les phases où l'attention prédomine dans les petits modèles) ; et, comme effet secondaire utile, il peut également atténuer les goulots d'étranglement du CPU comme la surcharge du planificateur ou du traitement d'images dans les charges de travail multimodales en partitionnant le batch total entre les moteurs, ce qui réduit la charge CPU par moteur.
Qu'est-ce que le MPS ?
Le Multi-Process Service (MPS) de NVIDIA est une fonctionnalité qui permet à plusieurs processus de partager un seul GPU plus efficacement en multiplexant leurs noyaux CUDA sur le matériel. Comme le dit la documentation officielle de NVIDIA :
Le service multi-processus (MPS) est une implémentation alternative et binaire compatible de l'interface de programmation d'applications (API) CUDA. L'architecture d'exécution MPS est conçue pour permettre de manière transparente des applications CUDA multi-processus coopératives.
En termes plus simples, le MPS fournit une implémentation CUDA binaire compatible au sein du pilote, qui permet à plusieurs processus (comme les moteurs d'inférence) de partager le GPU plus efficacement. Au lieu que les processus sérialisent l'accès (laissant le GPU inactif entre les tours), leurs noyaux et leurs opérations de mémoire sont multiplexés et superposés par le serveur MPS lorsque les ressources sont disponibles.
Le paysage de la mise à l'échelle : quand MPS est-il utile ?
Sur une configuration matérielle donnée, l'utilisation effective dépend fortement de la taille du modèle, de son architecture et de la longueur du contexte. Comme les grands modèles de langage récents tendent à converger vers des architectures similaires, nous utilisons la famille de modèles Qwen2.5 comme exemple représentatif pour explorer l'impact de la taille du modèle et de la longueur du contexte.
Les expériences ci-dessous ont comparé deux moteurs d'inférence identiques s'exécutant sur le même GPU NVIDIA H100 (avec MPS activé) par rapport à une référence à instance unique, en utilisant des charges de travail homogènes parfaitement équilibrées.
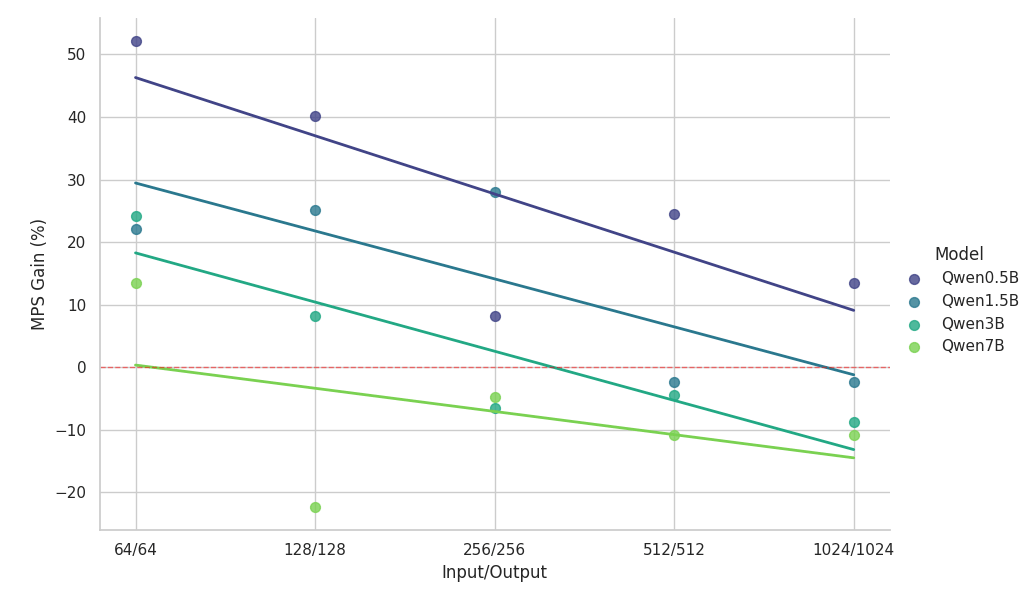
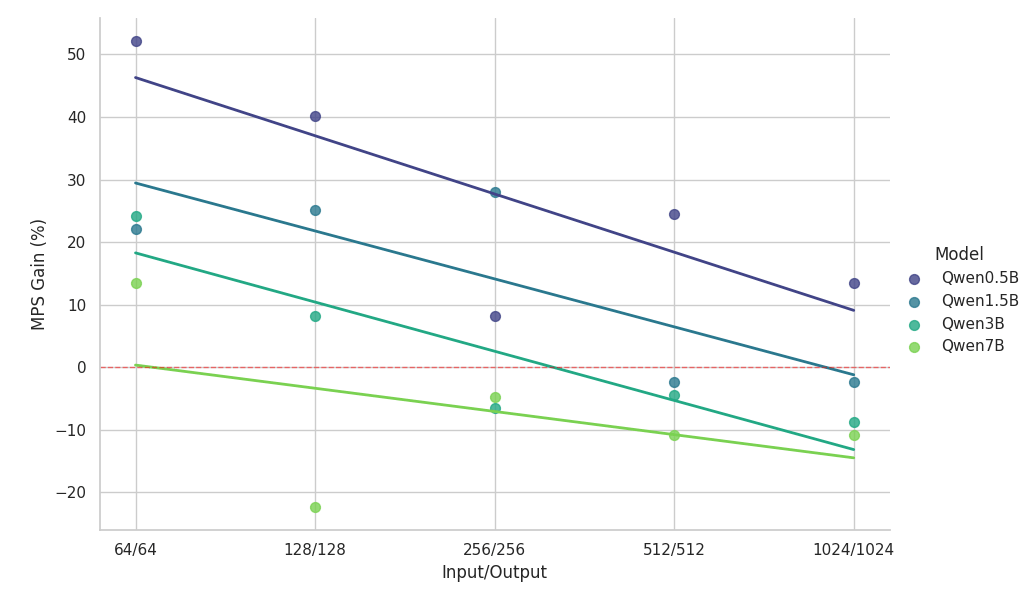{kind=link}
Principales observations de l'étude de mise à l'échelle :
- Le MPS offre une augmentation du débit de >50 % pour les petits modèles avec des contextes courts
- Les gains diminuent de manière log-linéaire à mesure que la longueur du contexte augmente, pour une même taille de modèle.
- Les gains diminuent également rapidement à mesure que la taille du modèle augmente, même dans des contextes courts.
- Pour le modèle 7B ou le contexte 2k, le bénéfice tombe en dessous de 10 % et finit par entraîner un ralentissement.
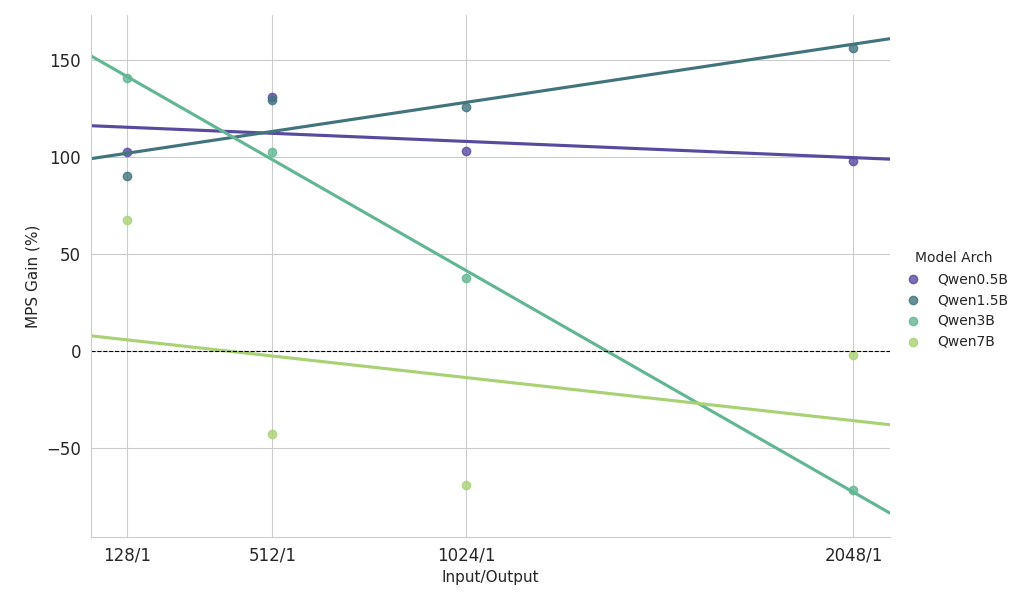
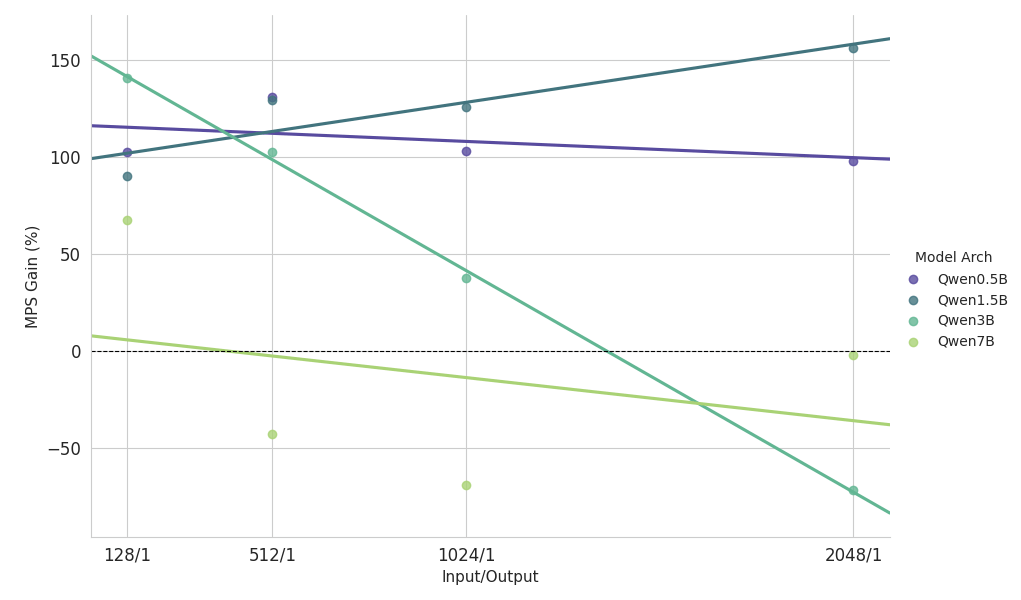{kind=link}
Principales observations de l'étude de mise à l'échelle sur une charge de travail lourde en pré-remplissage
- Petits modèles (<3B) : MPS offre systématiquement une amélioration du débit de plus de 100 %.
- Modèles de taille moyenne (~3B) : les avantages diminuent à mesure que la longueur du contexte augmente, ce qui finit par entraîner une régression des performances.
- Grands modèles (>3B) : MPS n'apporte aucun avantage en termes de performance pour ces tailles de modèles.
Les résultats de mise à l'échelle ci-dessus montrent que les avantages du MPS sont plus prononcés pour les configurations à faible utilisation du GPU, les petits modèles et les contextes courts, ce qui facilite une superposition efficace.
Analyse des gains : d'où viennent réellement les avantages du MPS ?
Pour déterminer exactement pourquoi, nous avons décomposé le problème en deux blocs de construction principaux des transformateurs modernes : les couches MLP (perceptron multicouche) et le mécanisme d'attention. En isolant chaque composant (et en supprimant d'autres facteurs de confusion comme la surcharge du processeur), nous avons pu attribuer les gains de manière plus précise.
Ressources GPU nécessaires | |||
| N = longueur du contexte | Pré-remplissage (compute) | Décodage (bande passante mémoire) | Décodage (compute) |
| MLP | O(N) | O(1) | O(1) |
| Attn | O(N^2) | O(N) | O(N) |
Les transformateurs se composent de couches d'attention et de MLP avec un comportement de mise à l'échelle différent :
- MLP : Charge les poids une seule fois ; traite chaque jeton indépendamment -> Bande passante mémoire et compute constants par jeton.
- Attention : charge le cache KV et calcule le produit scalaire avec tous les jetons précédents → Bande passante mémoire et calcul linéaires par jeton.
En gardant cela à l'esprit, nous avons effectué des ablations ciblées.
Modèles MLP uniquement (Attention supprimé)
Pour les petits modèles, la couche MLP pourrait ne pas saturer le compute, même avec plus de jetons par batch. Nous avons isolé l'impact du MLP en retirant le bloc d'attention du modèle.
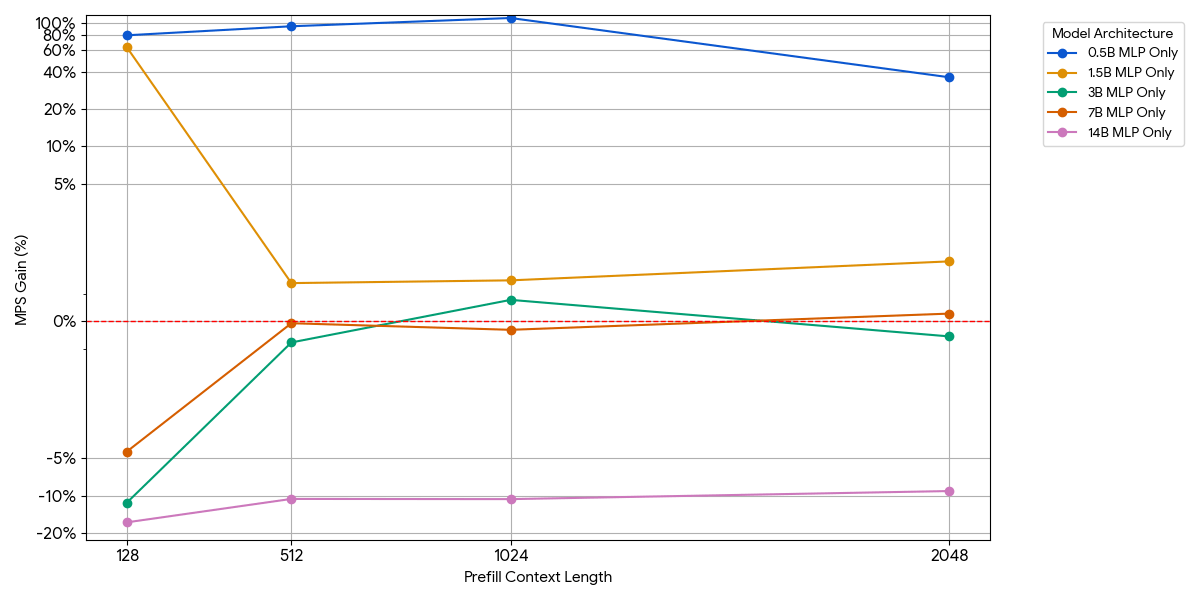
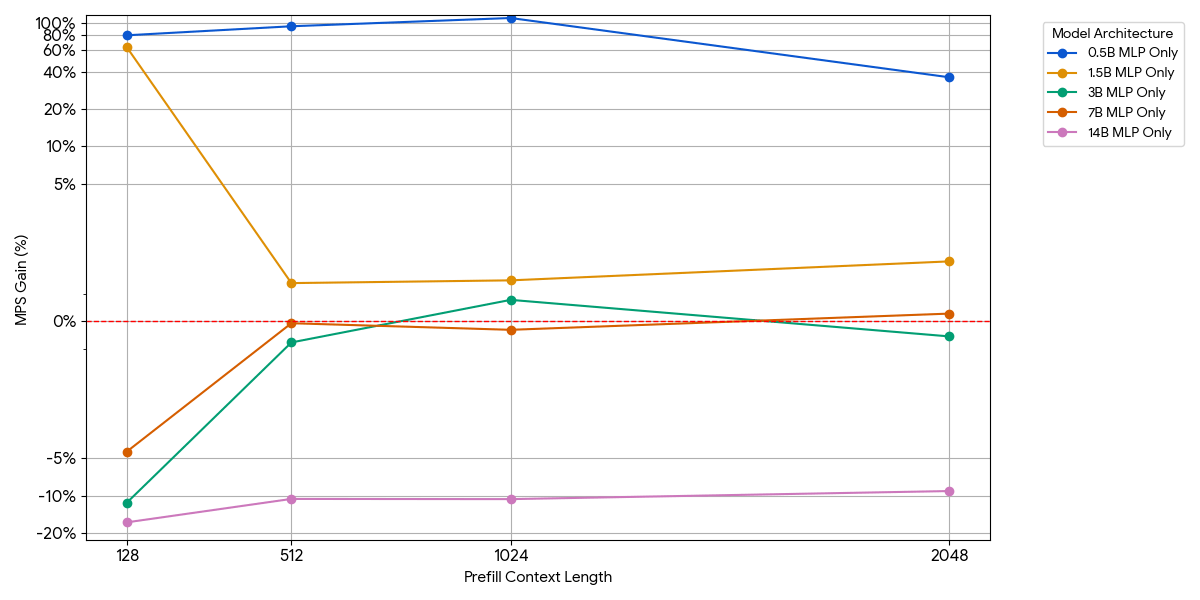{kind=link}
Comme le montre la figure ci-dessus, les gains sont modestes et disparaissent rapidement. À mesure que la taille du modèle ou la longueur du contexte augmente, un seul moteur sature déjà le compute (plus de FLOPs par jeton dans les MLP plus grands, plus de jetons avec des séquences plus longues). Une fois qu'un moteur est limité par la capacité de calcul, l'exécution de deux moteurs saturés n'apporte presque aucun avantage : 1 + 1 <= 1.
Modèles à attention seule (MLP supprimé)
Après avoir constaté des gains limités avec le MLP, nous avons utilisé Qwen2.5-3B et a mesuré la configuration d'attention seule de manière analogue.
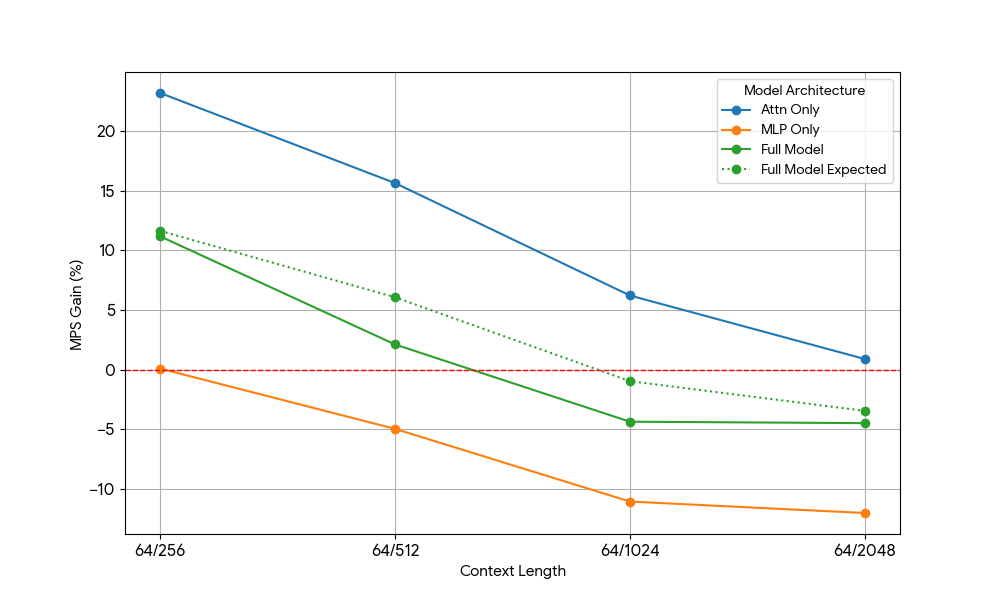
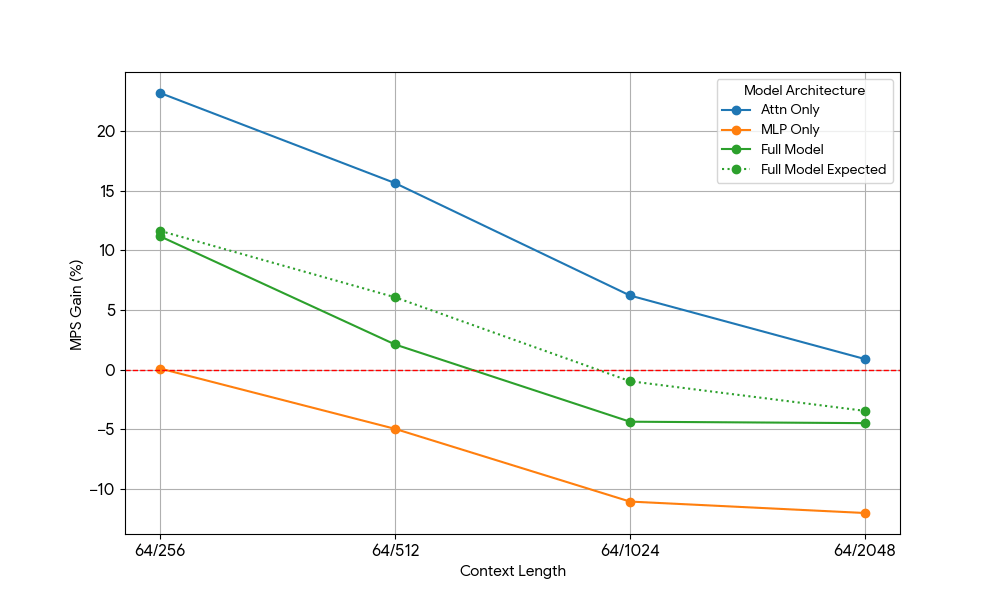{kind=link}
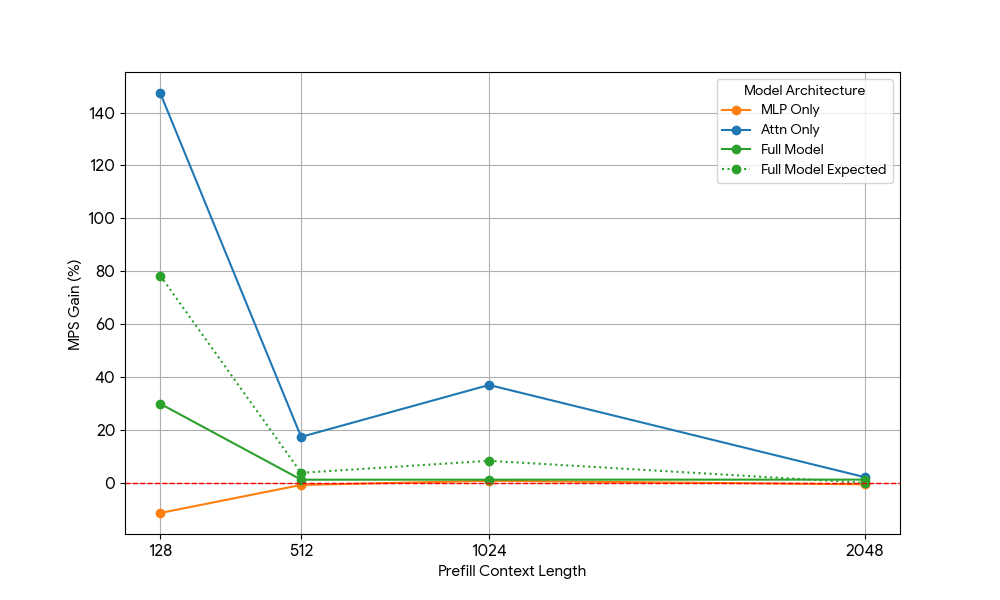
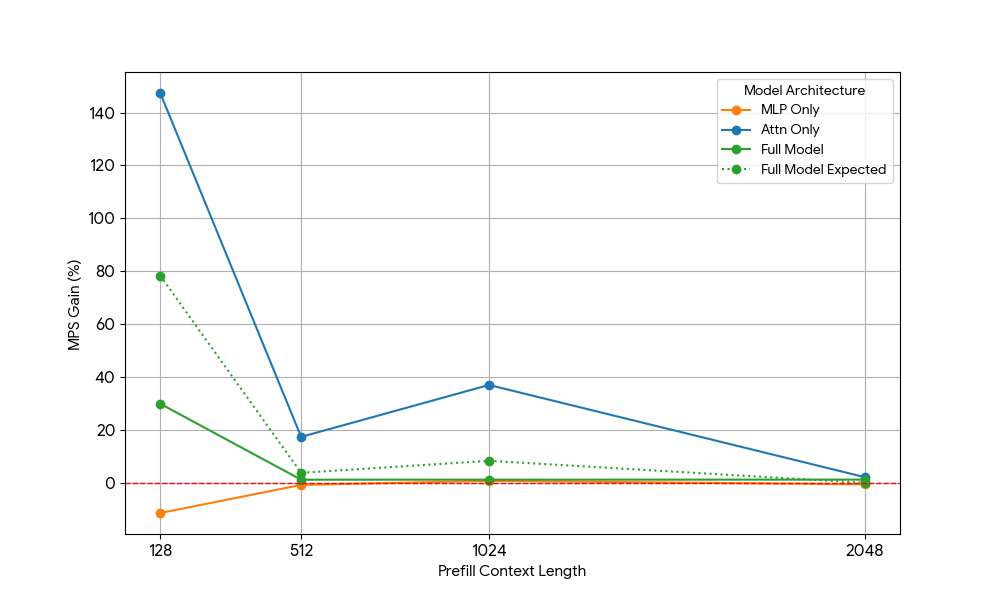{kind=link}
Les résultats étaient frappants :
- Les charges de travail uniquement basées sur l'attention montrent des gains MPS significativement plus importants que le modèle complet, tant pour le pré-remplissage que pour le décodage.
- Pour le décodage, les gains diminuent de façon linéaire avec la longueur du contexte, ce qui correspond à nos attentes selon lesquelles, à l'étape de décodage, les besoins en ressources pour l'attention augmentent avec la longueur du contexte.
- Pour le pré-remplissage, les gains ont diminué plus rapidement que pour le décodage.
Le gain MPS provient-il uniquement des gains d'attention, ou y a-t-il un effet de chevauchement entre l'attention et le MLP ? Pour étudier cela, nous avons calculé le gain attendu du modèle complet comme étant une moyenne pondérée de l'attention seule et du MLP seul, les poids étant leur contribution au temps d'horloge. Ce gain attendu du modèle complet correspond essentiellement aux gains provenant uniquement des chevauchements Attn-Attn et MLP-MLP, tandis qu'il ne tient pas compte du chevauchement Attn-MLP.
Pour la charge de travail de décodage, le gain attendu pour le modèle complet est légèrement supérieur au gain réel, ce qui indique un impact limité du chevauchement Attn-MLP. De plus, pour la charge de travail de pré-remplissage, le gain réel du modèle complet est bien inférieur aux gains attendus pour une séquence de 128. Une explication hypothétique pourrait être qu'il y a moins de possibilités pour que le noyau d'attention non saturé soit chevauché, car l'autre moteur consacre une part importante de son temps à des calculs MLP saturés. Par conséquent, la majorité du gain de MPS provient de 2 moteurs dont l'attention n'est pas saturée.
Avantage bonus : récupération du temps GPU perdu à cause de la surcharge du CPU
Les études d'ablation ci-dessus se sont concentrées sur les charges de travail limitées par le GPU, mais la forme la plus grave de sous-utilisation se produit lorsque le GPU reste inactif en attendant le travail du CPU, comme le planificateur, la tokenisation ou le prétraitement d'images dans les modèles multimodaux.
Dans une configuration à moteur unique, ces blocages du CPU gaspillent directement des cycles GPU. Avec le MPS, un deuxième moteur peut prendre le relais sur le GPU dès que le premier est bloqué par le CPU, transformant ainsi le temps mort en compute productif.
Pour isoler cet effet, nous avons délibérément choisi un régime où les gains précédents au niveau du GPU avaient disparu : Gemma-4B (une taille et une longueur de contexte où l'attention et le MLP sont déjà bien saturés, de sorte que les avantages du chevauchement des noyaux sont minimes).
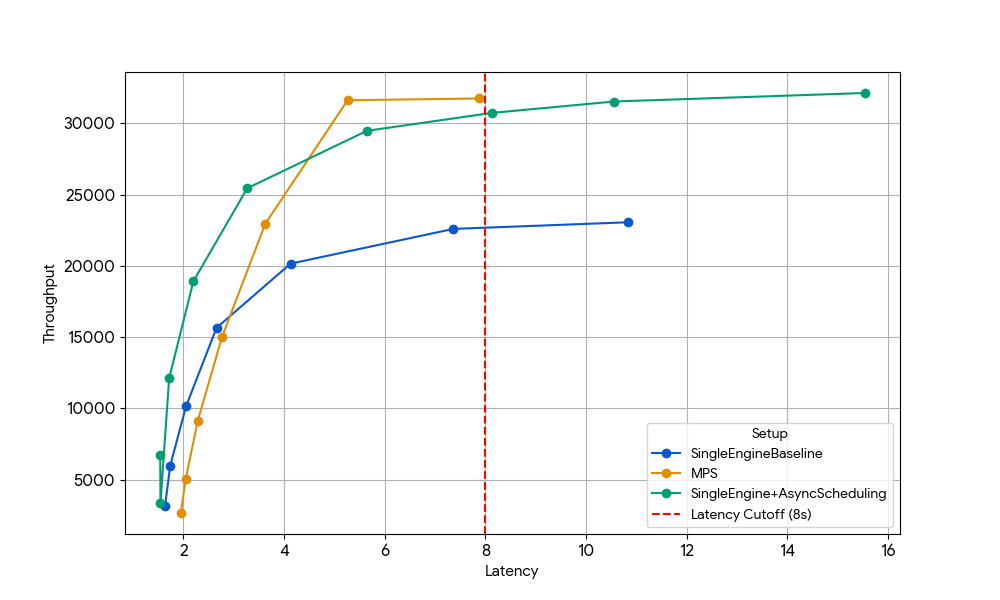
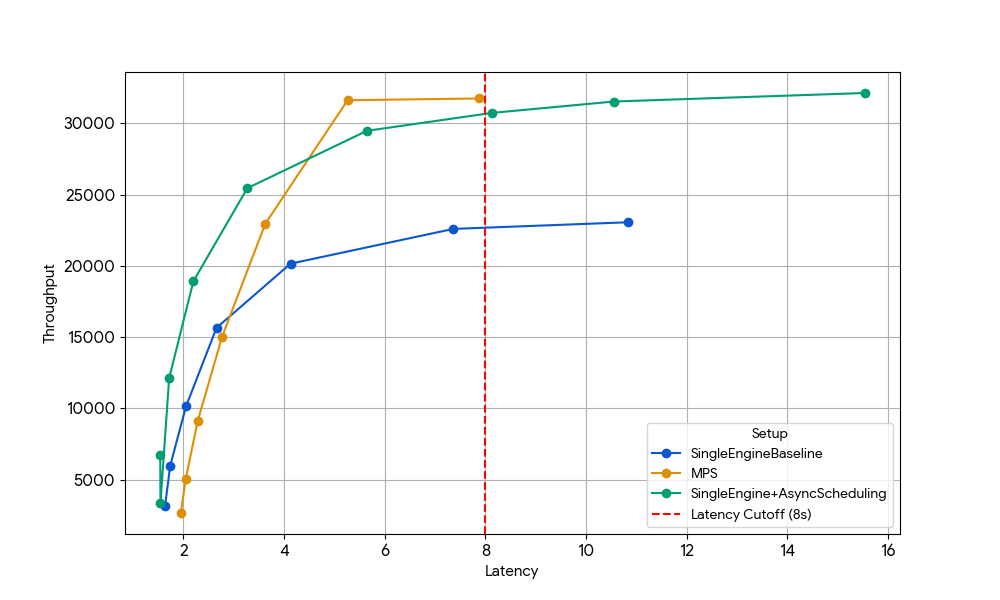{kind=link}
Avec une latence de 8 s, le moteur unique de référence (en bleu) est limité par la surcharge CPU de l'ordonnanceur, limitation qui peut être levée soit en activant l'ordonnancement asynchrone dans vLLM (ligne verte, +33 % throughput), soit en exécutant deux moteurs avec MPS sans ordonnancement asynchrone (ligne jaune, +35 % throughput). Ce gain quasi identique confirme que, dans les scénarios limités par le CPU, MPS peut récupérer essentiellement le même temps d'inactivité du GPU que celui que l'ordonnancement asynchrone élimine. MPS peut être utile, car la version de base de vLLM v1.0 présente toujours une surcharge CPU au niveau de la couche d'ordonnancement, où les optimisations telles que l'ordonnancement asynchrone ne sont pas entièrement disponibles.
Une balle, pas une balle d'argent
D'après nos expérimentations, le MPS peut apporter des gains significatifs pour l'inférence sur de petits modèles dans quelques zones de fonctionnement :
- Moteurs avec une surcharge CPU importante
- Modèles de langage de très petite taille (≤ 3 milliards de paramètres) avec un contexte court à moyen (<2k tokens)
- Très petits modèles de langage (<3B) dans les charges de travail lourdes en pré-remplissage (prefill)
En dehors de ces cas d'utilisation optimaux (par exemple, les modèles 7B+, les contextes longs >8k ou les charges de travail déjà limitées par le compute), les avantages au niveau du GPU ne peuvent pas être facilement exploités par MPS.
D'un autre côté, le MPS a également introduit une complexité opérationnelle :
- Composants supplémentaires : démon MPS, configuration de l'environnement client et un routeur/répartiteur de charge pour répartir le trafic entre les moteurs
- Complexité de débogage accrue : pas d'isolation entre les moteurs → une fuite de mémoire ou une erreur OOM dans un moteur peut corrompre ou arrêter tous les autres partageant le GPU
- Charge de monitoring : nous devons maintenant surveiller l'état du démon, l'état de la connexion client, l'équilibrage de charge entre les moteurs, etc.
- Modes de défaillance fragiles : parce que tous les moteurs partagent un seul contexte CUDA et un seul démon MPS, un seul client au comportement anormal peut corrompre ou monopoliser l'ensemble du GPU, affectant instantanément chaque moteur colocalisé.
En bref : MPS est un outil précis et spécialisé, extrêmement efficace dans les régimes étroits décrits ci-dessus, mais rarement un avantage à usage général. Nous avons vraiment apprécié de repousser les limites du partage de GPU et de découvrir où se situent les véritables chutes de performance. Il reste un énorme potentiel de performance et de rentabilité inexploité sur toute la pile d'inférence. Si vous êtes passionné(e) par les systèmes de service distribués, ou par l'idée de rendre les LLM 10 fois moins chers en production, nous recrutons !
Auteurs : Xiaotong Jiang
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.