Simplifiez les tests PySpark avec les fonctions d’égalité DataFrame
Présentation des fonctions de test d’égalité PySpark DataFrame, pourquoi elles sont importantes et comment les utiliser.
par Haejoon Lee, Allison Wang et Amanda Liu
Les fonctions de test d’égalité DataFrame ont été introduites dans Apache Spark™ 3.5 et Databricks Runtime 14.2 afin de simplifier les tests unitaires PySpark. L’ensemble complet des fonctionnalités décrites dans ce billet de blogue sera disponible à partir des prochaines versions d’Apache Spark 4.0 et de Databricks Runtime 14.3.
Écrivez des transformations DataFrame plus fiables grâce aux fonctions de test d’égalité DataFrame
L’utilisation de données dans PySpark implique l’application de transformations, d’agrégations et de manipulations aux DataFrames. À mesure que les transformations s’accumulent, comment pouvez-vous être sûr que votre code fonctionne comme prévu? Les fonctions utilitaires de test d’égalité PySpark offrent un moyen efficace de vérifier vos données par rapport aux résultats attendus, ce qui vous aide à identifier les différences inattendues et à détecter les erreurs au début du processus d’analyse. De plus, elles renvoient des informations intuitives indiquant précisément les différences afin que vous puissiez agir immédiatement sans perdre beaucoup de temps à déboguer.
Utilisation des fonctions de test d’égalité DataFrame
Deux fonctions de test d’égalité pour les DataFrames PySpark ont été introduites dans Apache Spark 3.5 : assertDataFrameEqual et assertSchemaEqual. Examinons comment utiliser chacune d’elles.
assertDataFrameEqual : cette fonction vous permet de comparer deux DataFrames PySpark pour vérifier leur égalité avec une seule ligne de code, en vérifiant si les données et les schémas correspondent. Elle renvoie des informations descriptives en cas de différences.
Prenons un exemple. Tout d’abord, nous allons créer deux DataFrames, en introduisant intentionnellement une différence dans la première ligne :
Ensuite, nous allons appeler assertDataFrameEqual avec les deux DataFrames :
La fonction renvoie un message descriptif indiquant que la première ligne des deux DataFrames est différente. Dans cet exemple, les premiers montants indiqués pour Alfred dans cette ligne ne sont pas les mêmes (attendu : 1500, réel : 1200) :
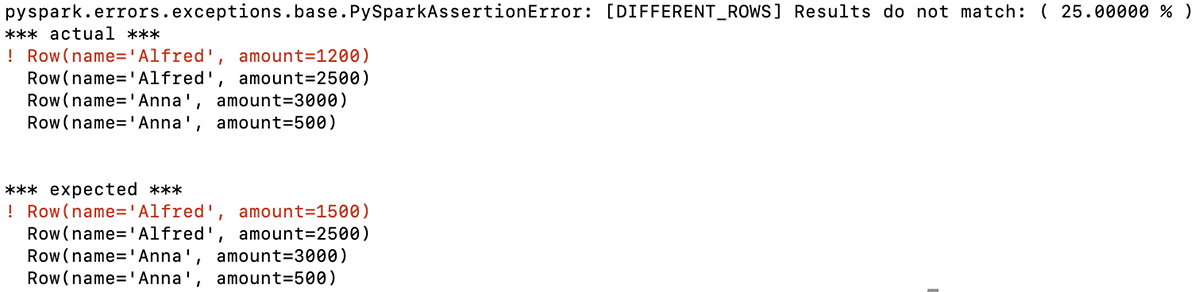
Grâce à ces informations, vous connaissez immédiatement le problème lié au DataFrame généré par votre code et vous pouvez cibler votre débogage en fonction de cela.
La fonction propose également plusieurs options pour contrôler la rigueur de la comparaison DataFrame afin que vous puissiez l’ajuster en fonction de vos cas d’utilisation spécifiques.
assertSchemaEqual : cette fonction compare uniquement les schémas de deux DataFrames; elle ne compare pas les données des lignes. Elle vous permet de valider si les noms de colonnes, les types de données et la propriété Nullable sont les mêmes pour deux DataFrames différents.
Prenons un exemple. Tout d’abord, nous allons créer deux DataFrames avec des schémas différents :
Maintenant, appelons assertSchemaEqual avec ces deux schémas DataFrame :
La fonction détermine que les schémas des deux DataFrames sont différents, et la sortie indique où ils divergent :

Dans cet exemple, il existe deux différences : le type de données de la colonne amount est LONG dans le DataFrame réel, mais DOUBLE dans le DataFrame attendu, et comme nous avons créé le DataFrame attendu sans spécifier de schéma, les noms de colonnes sont également différents.
Ces deux différences sont mises en évidence dans la sortie de la fonction, comme illustré ici.
assertPandasOnSparkEqual n’est pas abordé dans ce billet de blogue, car il est déconseillé depuis Apache Spark 3.5.1 et sa suppression est prévue dans la prochaine version d’Apache Spark 4.0.0. Pour tester l’API Pandas sur Spark, consultez API Pandas sur les fonctions de test d’égalité Spark.
Sortie structurée pour le débogage des différences dans les DataFrames PySpark
Bien que les fonctions assertDataFrameEqual et assertSchemaEqual soient principalement destinées aux tests unitaires, où vous utilisez généralement des ensembles de données plus petits pour tester vos fonctions PySpark, vous pouvez les utiliser avec des DataFrames contenant plus que quelques lignes et colonnes. Dans de tels cas, vous pouvez facilement récupérer les données de ligne pour les lignes qui sont différentes afin de faciliter davantage le débogage.
Voyons comment faire cela. Nous allons utiliser les mêmes données que celles que nous avons utilisées précédemment pour créer deux DataFrames :
Et maintenant, nous allons récupérer les données qui diffèrent entre les deux DataFrames à partir des objets d’erreur d’assertion après avoir appelé assertDataFrameEqual :
La création d’un DataFrame basé sur les lignes qui sont différentes et son affichage, comme nous l’avons fait dans cet exemple, illustre la facilité d’accès à ces informations :

Comme vous pouvez le constater, les informations sur les lignes qui sont différentes sont immédiatement disponibles pour une analyse plus approfondie. Vous n’avez plus besoin d’écrire de code pour extraire ces informations des DataFrames réels et attendus à des fins de débogage.
Cette fonctionnalité sera disponible à partir des prochaines versions d’Apache Spark 4.0 et de DBR 14.3.
API Pandas sur les fonctions de test d’égalité Spark
En plus des fonctions permettant de tester l’égalité des DataFrames PySpark, les utilisateurs de l’API Pandas sur Spark auront accès aux fonctions de test d’égalité DataFrame suivantes :
assert_frame_equalassert_series_equalassert_index_equal
Les fonctions offrent des options pour contrôler la rigueur des comparaisons et sont idéales pour tester unitairement votre API Pandas sur les DataFrames Spark. Elles fournissent exactement la même API que les fonctions utilitaires de test pandas, vous pouvez donc les utiliser sans modifier le code de test pandas existant que vous souhaitez exécuter à l’aide de l’API Pandas sur Spark.
Voici quelques exemples illustrant l’utilisation de assert_frame_equal avec différents paramètres, comparant l’API Pandas sur les DataFrames Spark :
Dans cet exemple, les schémas des deux DataFrames sont différents. La sortie de la fonction répertorie les différences, comme indiqué ici :

Nous pouvons spécifier que nous voulons que la fonction compare les données de colonne même lorsque les colonnes n’ont pas le même type de données à l’aide de l’argument check_dtype, comme dans cet exemple :
Étant donné que nous avons spécifié que assert_frame_equal doit ignorer les types de données de colonne, il considère maintenant les deux DataFrames comme égaux.
Ces fonctions permettent également des comparaisons entre l’API Pandas sur les objets Spark et les objets pandas, ce qui facilite les vérifications de compatibilité entre différentes bibliothèques DataFrame, comme illustré dans cet exemple :
L’utilisation des nouvelles fonctions de test d’égalité DataFrame PySpark et API Pandas sur Spark est un excellent moyen de s’assurer que votre code PySpark fonctionne comme prévu. Ces fonctions vous aident non seulement à détecter les erreurs, mais aussi à comprendre exactement ce qui n’a pas fonctionné, ce qui vous permet d’identifier rapidement et facilement l’origine du problème. Consultez la page Testing PySpark pour plus d’informations.
Ces fonctions seront disponibles à partir de la prochaine version d’Apache Spark 4.0. DBR 14.2 le prend déjà en charge.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.