Qu'est-ce que l'écosystème Hadoop ?
Une suite complète d'outils open source comprenant HDFS, MapReduce, YARN, Hive et Spark qui fonctionnent ensemble pour stocker, traiter et analyser des ensembles de données massifs.
- HDFS assure un stockage distribué tolérant aux pannes grâce à son architecture NameNode/DataNode, tandis que YARN gère les ressources du cluster et MapReduce le traitement parallèle des données.
- Apache Hive propose des requêtes de type SQL via HiveQL pour les opérations d'entrepôt de données, et Apache Spark fournit un traitement en mémoire pour l'analyse en temps réel et l'apprentissage automatique.
- L'écosystème comprend des outils complémentaires tels que Pig pour le scripting, HBase pour le stockage NoSQL, Oozie pour la planification des flux de travail et Sqoop pour le transfert de données entre Hadoop et les bases de données relationnelles.
Qu’est-ce que l’écosystème Hadoop ?
L’écosystème Apache Hadoop désigne les différents composants de la bibliothèque logicielle Apache Hadoop ; il comprend des projets open source ainsi qu’une gamme complète d’outils complémentaires. Parmi les outils les plus connus de l’écosystème Hadoop figurent HDFS, Hive, Pig, YARN, MapReduce, Spark, HBase, Oozie, Sqoop, Zookeeper, etc. Voici les principaux composants de l’écosystème Hadoop fréquemment utilisés par les développeurs :
Qu’est-ce que HDFS ?
Le système de fichiers distribué Hadoop (HDFS) est l’un des plus grands projets Apache. Il constitue le principal système de stockage de Hadoop. Il utilise une architecture NameNode et DataNode. HDFS est un système de fichiers distribué capable de stocker des fichiers volumineux et fonctionnant au sein d’un cluster installé sur du matériel générique.
Qu’est-ce que Hive ?
Hive est un outil ETL et d’entreposage des données utilisé pour effectuer des requêtes ou analyser de grands datasets stockés au sein de l’écosystème Hadoop. Hive a trois fonctions principales : la synthèse des données, les requêtes et l’analyse des données non structurées et semi-structurées dans Hadoop. Il est doté d’une interface de type SQL et d’un langage HQL qui fonctionne de manière similaire à SQL. De plus, il traduit automatiquement les queries en jobs MapReduce.
Qu’est-ce qu’Apache Pig ?
Il s’agit d’un langage de script de haut niveau utilisé pour exécuter les requêtes des datasets plus importants utilisés dans Hadoop. Le langage de script simple de Pig est semblable à SQL. Il est connu sous le nom de Pig Latin. Son objectif principal est d’effectuer les opérations requises et d’organiser la sortie finale dans le format souhaité.
Le guide pratique de l'IA agentique pour l'entreprise

Qu’est-ce que MapReduce ?

Il s’agit d’une autre couche de traitement des données de Hadoop. MapReduce est capable de traiter de grandes quantités de données structurées et non structurées. Il peut aussi gérer de très grands fichiers de données en parallèle, en divisant le job en un ensemble de tâches indépendantes (sous-jobs).
Qu’est-ce que YARN ?
YARN signifie « Yet Another Ressources Negotiator ». En général, il est uniquement désigné par son acronyme. Il s’agit de l’un des principaux composants de l’application open source Apache Hadoop, destiné à la gestion des ressources. Il est chargé de la gestion des charges de travail, du monitoring et de la mise en œuvre des contrôles de sécurité. De plus, YARN alloue des ressources système aux différentes applications fonctionnant au sein d’un cluster Hadoop, tout en attribuant les tâches à chaque nœud du cluster. Les deux composantes principales de YARN sont :
- Un gestionnaire des ressources
- Un gestionnaire de nœuds
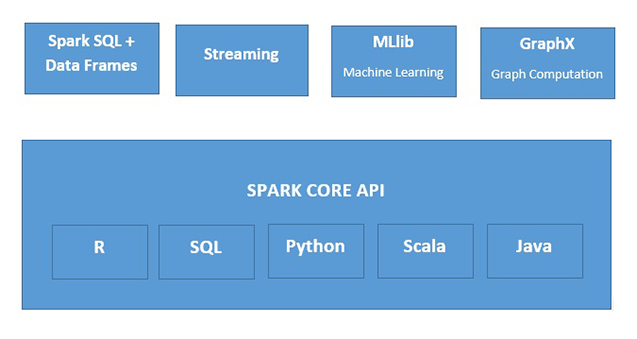
Qu'est-ce qu'Apache Spark ?
Apache Spark est un moteur de traitement de données en mémoire, rapide et utilisable dans de nombreuses circonstances. Spark peut être déployé de plusieurs manières. Il intègre plusieurs langages de programmation (Java, Python, Scala et R). Il prend aussi en charge SQL, les données de streaming, le machine learning et le traitement graphique. Toutes ces fonctionnalités peuvent être utilisées conjointement au sein d’une même application.
Ressources complémentaires
- Guide détaillé de la migration : Hadoop vers Databricks
- Modernisation du cloud avec Databricks et AWS
- Centre de migration de Databricks
- Livre blanc sur la valeur cachée de la migration Hadoop
- Il est temps de faire le point sur votre relation avec Hadoop
- Delta Lake et l'ETL
- Améliorer Apache Spark™ grâce à Delta Lake
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.