Qu'est-ce qu'un système de fichiers distribué Hadoop (HDFS) ?
Stockage distribué divisant les fichiers en blocs répliqués sur les nœuds du cluster, offrant tolérance aux pannes, capacité évolutive et accès à haut débit
- Le système de fichiers distribué Hadoop (HDFS) est un système de stockage qui divise les fichiers en blocs et les distribue sur de nombreuses machines pour assurer la scalabilité et la tolérance aux pannes.
- HDFS a été conçu pour stocker de très grands ensembles de données sur des clusters de matériel standard et maintenir les données disponibles même lorsque des nœuds individuels échouent.
- Bien que de nombreuses organisations utilisent désormais le stockage objet cloud avec des architectures lakehouse, la compréhension de HDFS aide à expliquer les fondements des premiers systèmes de big data.
HDFS
HDFS (Hadoop Distributed File System) est le système de stockage principal utilisé par les applications Hadoop. Ce framework open source fonctionne en transférant rapidement des données entre les nœuds. Il est souvent utilisé par les entreprises qui ont besoin de gérer et de stocker de grandes quantités de données. HDFS est un composant clé de nombreux systèmes Hadoop, car il fournit un moyen de gérer les grandes données, ainsi que de prendre en charge l'analyse des grandes données.
Il existe de nombreuses entreprises dans le monde qui utilisent HDFS, alors qu'est-ce que c'est exactement et pourquoi est-ce nécessaire ? Plongeons dans ce qu'est HDFS et pourquoi il peut être utile pour les entreprises.
Qu'est-ce que HDFS ?
HDFS signifie Hadoop Distributed File System. HDFS fonctionne comme un système de fichiers distribué conçu pour fonctionner sur du matériel standard.
HDFS est tolérant aux pannes et conçu pour être déployé sur du matériel standard peu coûteux. HDFS offre un accès à haut débit aux données des applications et convient aux applications qui ont de grands ensembles de données et permet un accès en streaming aux données du système de fichiers dans Apache Hadoop.
Alors, qu'est-ce que Hadoop ? Et en quoi diffère-t-il de HDFS ? Une différence fondamentale entre Hadoop et HDFS est que Hadoop est le framework open source qui peut stocker, traiter et analyser des données, tandis que HDFS est le système de fichiers de Hadoop qui fournit l'accès aux données. Cela signifie essentiellement que HDFS est un module de Hadoop.
Jetons un coup d'œil à l'architecture HDFS :
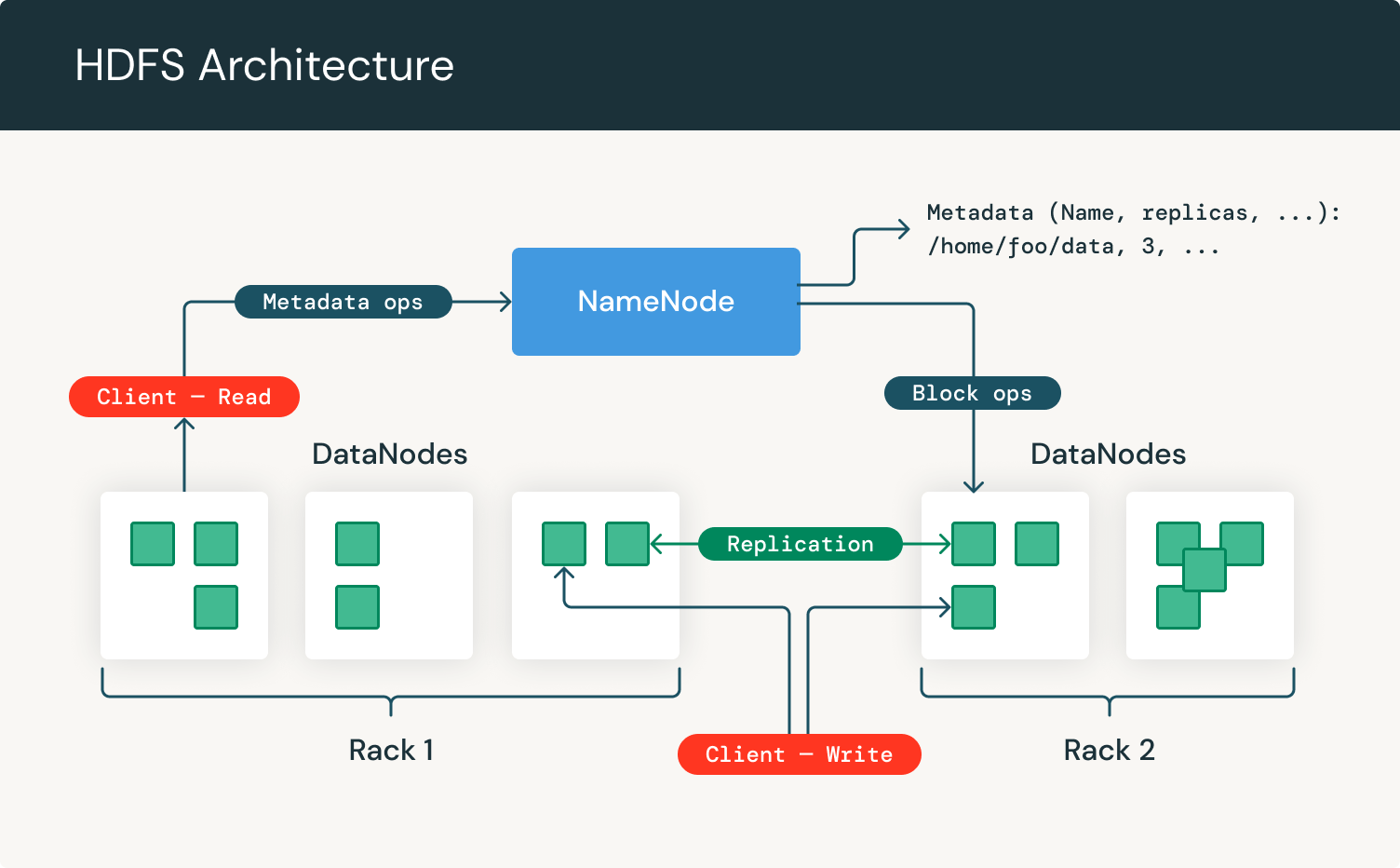
Comme nous pouvons le voir, il se concentre sur les NameNodes et les DataNodes. Le NameNode est le matériel qui contient le système d'exploitation et les logiciels GNU/Linux. Le système de fichiers distribué Hadoop agit comme le serveur maître et peut gérer les fichiers, contrôler l'accès d'un client aux fichiers et superviser les processus d'exploitation des fichiers tels que le renommage, l'ouverture et la fermeture des fichiers.
Un DataNode est un matériel possédant le système d'exploitation GNU/Linux et le logiciel DataNode. Pour chaque nœud d'un cluster HDFS, vous trouverez un DataNode. Ces nœuds aident à contrôler le stockage des données de leur système car ils peuvent effectuer des opérations sur les systèmes de fichiers si le client le demande, et également créer, répliquer et bloquer des fichiers lorsque le NameNode l'instruit.
La signification et le but de HDFS sont d'atteindre les objectifs suivants :
- Gérer de grands ensembles de données - L'organisation et le stockage de grands ensembles de données peuvent être une tâche difficile à gérer. HDFS est utilisé pour gérer les applications qui doivent traiter d'énormes ensembles de données. Pour ce faire, HDFS doit avoir des centaines de nœuds par cluster.
- Détection des pannes - HDFS doit disposer d'une technologie pour analyser et détecter les pannes rapidement et efficacement, car il comprend un grand nombre de matériels standards. La défaillance des composants est un problème courant.
- Efficacité matérielle - Lorsque de grands ensembles de données sont impliqués, cela peut réduire le trafic réseau et augmenter la vitesse de traitement.
L'histoire de HDFS
Quelles sont les origines de Hadoop ? La conception de HDFS était basée sur le Google File System. Il a été initialement construit comme infrastructure pour le projet de moteur de recherche Web Apache Nutch, mais est depuis devenu un membre de l'écosystème Hadoop.
Dans les premières années d'Internet, les robots d'exploration Web ont commencé à apparaître comme un moyen pour les gens de rechercher des informations sur les pages Web. Cela a créé divers moteurs de recherche tels que Yahoo et Google.
Cela a également créé un autre moteur de recherche appelé Nutch, qui voulait distribuer des données et des calculs sur plusieurs ordinateurs simultanément. Nutch a ensuite été transféré à Yahoo, et a été divisé en deux. Apache Spark et Hadoop sont maintenant leurs propres entités distinctes. Là où Hadoop est conçu pour gérer le traitement par lots, Spark est conçu pour gérer efficacement les données en temps réel.
Aujourd'hui, la structure et le framework de Hadoop sont gérés par la fondation de logiciels Apache, qui est une communauté mondiale de développeurs de logiciels et de contributeurs.
HDFS est né de cela et est conçu pour remplacer les solutions de stockage matériel par une méthode meilleure et plus efficace - un système de fichiers virtuel. Lorsqu'il est apparu sur la scène, MapReduce était le seul moteur de traitement distribué capable d'utiliser HDFS. Plus récemment, des composants de services de données Hadoop alternatifs comme HBase et Solr utilisent également HDFS pour stocker des données.
Qu'est-ce que HDFS dans le monde du Big Data ?
Alors, qu'est-ce que le Big Data et comment HDFS s'y intègre-t-il ? Le terme "Big Data" fait référence à toutes les données qui sont difficiles à stocker, traiter et analyser. Les Big Data HDFS sont des données organisées dans le système de fichiers HDFS.
Comme nous le savons maintenant, Hadoop est un framework qui fonctionne en utilisant le traitement parallèle et le stockage distribué. Cela peut être utilisé pour trier et stocker de grandes quantités de données, car elles ne peuvent pas être stockées de manière traditionnelle.
En fait, c'est le logiciel le plus couramment utilisé pour gérer les Big Data, et il est utilisé par des entreprises telles que Netflix, Expedia et British Airways qui ont une relation positive avec Hadoop pour le stockage de données. HDFS dans le Big Data est vital, car c'est ainsi que de nombreuses entreprises choisissent désormais de stocker leurs données.
Il existe cinq éléments clés des Big Data organisés par les services HDFS :
- Vélocité - La vitesse à laquelle les données sont générées, collectées et analysées.
- Volume - La quantité de données générées.
- Variété - Le type de données, qui peut être structuré, non structuré, etc.
- Véracité - La qualité et l'exactitude des données.
- Valeur - Comment vous pouvez utiliser ces données pour apporter un aperçu de vos processus métier.
Avantages du Hadoop Distributed File System
En tant que sous-projet open source au sein de Hadoop, HDFS offre cinq avantages clés lors du traitement des Big Data :
- Tolérance aux pannes. HDFS a été conçu pour détecter les pannes et récupérer automatiquement rapidement, assurant la continuité et la fiabilité.
- Vitesse, grâce à son architecture de cluster, il peut maintenir 2 Go de données par seconde.
- Accès à plus de types de données, en particulier les données en streaming. En raison de sa conception pour gérer de grandes quantités de données pour le traitement par lots, il permet des débits de données élevés, ce qui le rend idéal pour prendre en charge les données en streaming.
Compatibilité et portabilité. HDFS est conçu pour être portable sur une variété de configurations matérielles et compatible avec plusieurs systèmes d'exploitation sous-jacents, offrant finalement aux utilisateurs la possibilité d'utiliser HDFS avec leur propre configuration personnalisée. Ces avantages sont particulièrement significatifs lorsqu'il s'agit de Big Data et ont été rendus possibles par la manière particulière dont HDFS gère les données.
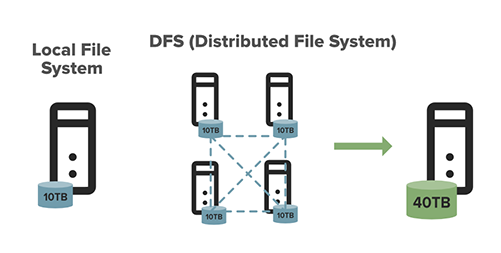
Ce graphique démontre la différence entre un système de fichiers local et HDFS.
- Évolutivité. Vous pouvez adapter les ressources à la taille de votre système de fichiers. HDFS comprend des mécanismes d'évolutivité verticale et horizontale.
- Localité des données. En ce qui concerne le système de fichiers Hadoop, les données résident dans les DataNodes, par opposition au déplacement des données vers l'unité de calcul. En raccourcissant la distance entre les données et le processus de calcul, cela réduit la congestion du réseau et rend le système plus efficace.
- Rentabilité. Initialement, lorsque nous pensons aux données, nous pouvons penser à du matériel coûteux et à une bande passante saturée. Lorsque la défaillance matérielle survient, elle peut être très coûteuse à réparer. Avec HDFS, les données sont stockées à moindre coût car elles sont virtuelles, ce qui peut réduire considérablement les métadonnées du système de fichiers et les coûts de stockage des données de l'espace de noms du système de fichiers. De plus, comme HDFS est open source, les entreprises n'ont pas à se soucier de payer de frais de licence.
- Stocke de grandes quantités de données. Le stockage de données est ce dont HDFS est fait - c'est-à-dire des données de toutes variétés et tailles - mais en particulier de grandes quantités de données provenant d'entreprises qui ont du mal à les stocker. Cela comprend les données structurées et non structurées.
- Flexibilité. Contrairement à certaines autres bases de données de stockage plus traditionnelles, il n'est pas nécessaire de traiter les données collectées avant de les stocker. Vous pouvez stocker autant de données que vous le souhaitez, avec la possibilité de décider exactement ce que vous voulez en faire et comment les utiliser plus tard. Cela inclut également les données non structurées comme le texte, les vidéos et les images.
Comment utiliser HDFS
Alors, comment utiliser HDFS ? Eh bien, HDFS fonctionne avec un NameNode principal et plusieurs autres DataNodes, le tout sur un cluster de matériel standard. Ces nœuds sont organisés au même endroit dans le centre de données. Ensuite, il est divisé en blocs qui sont distribués parmi les plusieurs DataNodes pour le stockage. Pour réduire les risques de perte de données, les blocs sont souvent répliqués sur les nœuds. C'est un système de sauvegarde en cas de perte de données.
Examinons les NameNodes. Le NameNode est le nœud du cluster qui sait ce que contiennent les données, à quel bloc elles appartiennent, la taille du bloc et où elles doivent aller. Les NameNodes sont également utilisés pour contrôler l'accès aux fichiers, y compris quand quelqu'un peut écrire, lire, créer, supprimer et répliquer des données sur les différents DataNodes.
Le cluster peut également être adapté en temps réel si nécessaire, en fonction de la capacité du serveur - ce qui peut être utile en cas de pic de données. Des nœuds peuvent être ajoutés ou supprimés si nécessaire.
Passons maintenant aux DataNodes. Les DataNodes sont en communication constante avec les NameNodes pour identifier s'ils doivent commencer et terminer une tâche. Ce flux de collaboration constant signifie que le NameNode est parfaitement conscient du statut de chaque DataNode.
Lorsqu'un DataNode est identifié comme ne fonctionnant pas correctement, le NameNode est capable de réassigner automatiquement cette tâche à un autre nœud fonctionnel dans le même bloc de données. De même, les DataNodes sont également capables de communiquer entre eux, ce qui leur permet de collaborer lors des opérations standard sur les fichiers. Comme le NameNode est au courant des DataNodes et de leurs performances, ils sont cruciaux pour le maintien du système.
Les blocs de données sont répliqués sur plusieurs DataNodes et accessibles par le NameNode.
Pour utiliser HDFS, vous devez installer et configurer un cluster Hadoop. Il peut s'agir d'une configuration à nœud unique, plus adaptée aux utilisateurs débutants, ou d'une configuration de cluster pour les grands clusters distribués. Vous devez ensuite vous familiariser avec les commandes HDFS, telles que celles ci-dessous, pour exploiter et gérer votre système.
| Commande | Description |
| -rm | Supprime un fichier ou un répertoire |
| -ls | Liste les fichiers avec les permissions et d'autres détails |
| -mkdir | Crée un répertoire nommé chemin dans HDFS |
| -cat | Affiche le contenu du fichier |
| -rmdir | Supprime un répertoire |
| -put | Télécharge un fichier ou un dossier d'un disque local vers HDFS |
| -rmr | Supprime le fichier identifié par chemin ou le dossier et ses sous-dossiers |
| -get | Déplace un fichier ou un dossier d'HDFS vers un fichier local |
| -count | Compte le nombre de fichiers, le nombre de répertoires et la taille des fichiers |
| -df | Affiche l'espace libre |
| -getmerge | Fusionne plusieurs fichiers dans HDFS |
| -chmod | Modifie les permissions des fichiers |
| -copyToLocal | Copie des fichiers vers le système local |
| -Stat | Affiche des statistiques sur le fichier ou le répertoire |
| -head | Affiche le premier kilooctet d'un fichier |
| -usage | Retourne l'aide pour une commande individuelle |
| -chown | Attribue un nouveau propriétaire et groupe à un fichier |
Comment fonctionne HDFS ?
Comme mentionné précédemment, HDFS utilise des NameNodes et des DataNodes. HDFS permet le transfert rapide de données entre les nœuds de calcul. Lorsque HDFS ingère des données, il est capable de décomposer les informations en blocs, en les distribuant à différents nœuds d'un cluster.
Les données sont décomposées en blocs et distribuées aux DataNodes pour le stockage, ces blocs peuvent également être répliqués sur les nœuds, ce qui permet un traitement parallèle efficace. Vous pouvez accéder, déplacer et visualiser les données via diverses commandes. Les options HDFS DFS telles que "-get" et "-put" vous permettent de récupérer et de déplacer des données selon vos besoins.
De plus, HDFS est conçu pour être très réactif et peut détecter rapidement les pannes. Le système de fichiers utilise la réplication des données pour garantir que chaque élément de donnée est sauvegardé plusieurs fois, puis l'attribue à des nœuds individuels, garantissant qu'au moins une copie se trouve sur un rack différent des autres copies.
Cela signifie que lorsqu'un DataNode n'envoie plus de signaux au NameNode, celui-ci retire le DataNode du cluster et fonctionne sans lui. Si ce nœud de données revient, il peut être alloué à un nouveau cluster. De plus, comme les blocs de données sont répliqués sur plusieurs DataNodes, la suppression d'un seul ne provoquera aucune corruption de fichier.
Composants HDFS
Il est important de savoir qu'il existe trois composants principaux de Hadoop. Hadoop HDFS, Hadoop MapReduce et Hadoop YARN. Examinons ce que ces composants apportent à Hadoop :
- Hadoop HDFS - Hadoop Distributed File System (HDFS) est l'unité de stockage de Hadoop.
- Hadoop MapReduce - Hadoop MapReduce est l'unité de traitement de Hadoop. Ce framework logiciel est utilisé pour écrire des applications afin de traiter de grandes quantités de données.
- Hadoop YARN - Hadoop YARN est un composant de gestion des ressources de Hadoop. Il traite et exécute des données pour le traitement par lots, en flux, interactif et graphique - le tout stocké dans HDFS.
Comment créer un système de fichiers HDFS
Vous voulez savoir comment créer un système de fichiers HDFS ? Suivez les étapes ci-dessous qui vous guideront sur la façon de créer le système, de le modifier et de le supprimer si nécessaire.
Lister votre HDFS
Votre liste HDFS devrait être /user/yourUserName. Pour afficher le contenu de votre répertoire personnel HDFS, entrez :
Comme vous débutez, vous ne pourrez rien voir à ce stade. Lorsque vous souhaitez afficher le contenu d'un répertoire non vide, entrez :
Vous pourrez alors voir les noms des répertoires personnels de tous les autres utilisateurs Hadoop.
Créer un répertoire dans HDFS
Vous pouvez maintenant créer un répertoire de test, appelons-le testHDFS. Il apparaîtra dans votre HDFS. Entrez simplement ce qui suit :
Vous devez maintenant vérifier que le répertoire existe en utilisant la commande que vous avez entrée lors de la liste de votre HDFS. Vous devriez voir le répertoire testHDFS listé.
Vérifiez à nouveau en utilisant le chemin d'accès complet HDFS à votre HDFS. Entrez :
Vérifiez bien que cela fonctionne avant de passer aux étapes suivantes.
Copier un fichier
Pour copier un fichier de votre système de fichiers local vers HDFS, commencez par créer un fichier que vous souhaitez copier. Pour ce faire, entrez :
Cela va créer un nouveau fichier appelé testFile, y compris les caractères HDFS test file. Pour vérifier cela, entrez :
ls
Et ensuite, pour vérifier que le fichier a été créé, entrez :
Vous devrez ensuite copier le fichier vers HDFS. Pour copier des fichiers de Linux vers HDFS, vous devez utiliser :
Notez que vous devez utiliser la commande "-copyFromLocal" car la commande "-cp" est utilisée pour copier des fichiers au sein d'HDFS.
Il vous suffit maintenant de confirmer que le fichier a bien été copié. Faites-le en entrant ce qui suit :
Déplacer et copier des fichiers
Lors de la copie du testfile, il a été placé dans le répertoire personnel de base. Vous pouvez maintenant le déplacer dans le répertoire testHDFS que vous avez déjà créé. Utilisez ce qui suit :
La première partie a déplacé votre testFile du répertoire personnel HDFS vers celui que vous avez créé. La deuxième partie de cette commande nous montre ensuite qu'il n'est plus dans le répertoire personnel HDFS, et la troisième partie confirme qu'il a maintenant été déplacé vers le répertoire test HDFS.
Pour copier un fichier, entrez :
Vérifier l'utilisation du disque
La vérification de l'espace disque est utile lorsque vous utilisez HDFS. Pour ce faire, vous pouvez entrer la commande suivante :
Cela vous permettra ensuite de voir l'espace que vous utilisez dans votre HDFS. Vous pouvez également voir l'espace disponible dans HDFS sur l'ensemble du cluster en entrant :
Supprimer un fichier/répertoire
Il peut arriver que vous ayez besoin de supprimer un fichier ou un répertoire dans HDFS. Cela peut être réalisé avec la commande :
Vous verrez que vous avez toujours le répertoire testHDFS et le fichier testFile2 restants que vous avez créés. Supprimez le répertoire en entrant :
Il affichera alors un message d'erreur - mais ne paniquez pas. Il lira quelque chose comme "rmdir : testhdfs : Le répertoire n'est pas vide". Le répertoire doit être vide avant de pouvoir être supprimé. Vous pouvez utiliser la commande "rm" pour contourner cela et supprimer un répertoire, y compris tous les fichiers qu'il contient. Entrez :
Le guide pratique de l'IA agentique pour l'entreprise

Comment installer HDFS
Pour installer Hadoop, vous devez vous rappeler qu'il existe un nœud unique et un nœud multiple. Selon vos besoins, vous pouvez utiliser un cluster à nœud unique ou à nœuds multiples.
Un cluster à nœud unique signifie qu'un seul DataNode est en cours d'exécution. Il comprendra le NameNode, le DataNode, le gestionnaire de ressources et le gestionnaire de nœuds sur une seule machine.
Pour certaines industries, c'est tout ce qui est nécessaire. Par exemple, dans le domaine médical, si vous menez des études et avez besoin de collecter, trier et traiter des données en séquence, vous pouvez utiliser un cluster à nœud unique. Celui-ci peut facilement gérer les données à plus petite échelle, par rapport aux données distribuées sur des centaines de machines. Pour installer un cluster à nœud unique, suivez ces étapes :
- Téléchargez le package Java 8. Enregistrez ce fichier dans votre répertoire personnel.
- Extrayez le fichier Tar Java.
- Téléchargez le package Hadoop 2.7.3.
- Extrayez le fichier Tar Hadoop.
- Ajoutez les chemins Hadoop et Java dans le fichier bash (.bashrc).
- Modifiez les fichiers de configuration Hadoop.
- Ouvrez core-site.xml et modifiez la propriété.
- Modifiez hdfs-site.xml et modifiez la propriété.
- Modifiez le fichier mapred-site.xml et modifiez la propriété.
- Modifiez yarn-site.xml et modifiez la propriété.
- Modifiez hadoop-env.sh et ajoutez le chemin Java.
- Accédez au répertoire personnel Hadoop et formatez le NameNode.
- Accédez au répertoire hadoop-2.7.3/sbin et démarrez tous les démons.
- Vérifiez que tous les services Hadoop sont en cours d'exécution.
Et voilà, vous devriez maintenant avoir un HDFS installé avec succès.
Comment accéder aux fichiers HDFS
Il n'est pas surprenant que la sécurité soit stricte en ce qui concerne HDFS, étant donné que nous traitons des données. HDFS étant techniquement un stockage virtuel, il s'étend sur le cluster, vous ne pouvez donc voir que les métadonnées sur votre système de fichiers, vous ne pourrez pas afficher les données spécifiques réelles.
Pour accéder aux fichiers HDFS, vous pouvez télécharger le fichier "jar" depuis HDFS vers votre système de fichiers local. Vous pouvez également accéder à HDFS en utilisant son interface utilisateur Web. Ouvrez simplement votre navigateur et tapez "localhost:50070" dans la barre de recherche. De là, vous pouvez voir l'interface utilisateur Web d'HDFS et passer à l'onglet utilitaires sur le côté droit. Cliquez ensuite sur "browse file system", cela vous montrera une liste complète des fichiers situés sur votre HDFS.
Exemples HDFS DFS
Voici quelques-uns des exemples de commandes Hadoop les plus courants.
Exemple A
Pour supprimer un répertoire, vous devez appliquer ce qui suit (remarque : cela ne peut être fait que si les fichiers sont vides) :
Ou
Exemple B
Lorsque vous avez plusieurs fichiers dans un HDFS, vous pouvez utiliser une commande "-getmerge". Celle-ci fusionnera plusieurs fichiers en un seul fichier, que vous pourrez ensuite télécharger sur votre système de fichiers local. Vous pouvez le faire avec ce qui suit :
Ou
Exemple C
Lorsque vous souhaitez télécharger un fichier d'HDFS vers le local, vous pouvez utiliser la commande "-put". Vous spécifiez d'où copier et sur quel fichier copier sur HDFS. Utilisez ce qui suit :
Ou
Exemple D
La commande count est utilisée pour suivre le nombre de répertoires, de fichiers et la taille des fichiers sur HDFS. Vous pouvez utiliser ce qui suit :
Ou
Exemple E
La commande "chown" peut être utilisée pour changer le propriétaire et le groupe d'un fichier. Pour l'activer, utilisez ce qui suit :
Ou
Qu'est-ce que le stockage HDFS ?
Comme nous le savons maintenant, les données HDFS sont stockées dans quelque chose appelé blocs. Ces blocs sont la plus petite unité de données que le système de fichiers peut stocker. Les fichiers sont traités et décomposés en ces blocs, qui sont ensuite distribués sur le cluster - et également répliqués pour la sécurité. Généralement, chaque bloc peut être répliqué trois fois. Ce diagramme montre le big data et comment il peut être stocké avec HDFS.
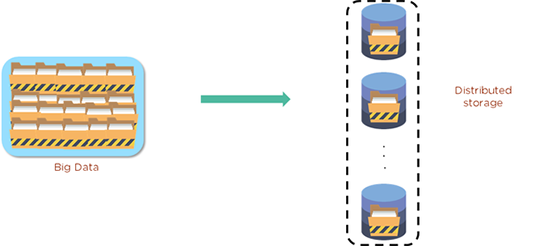
Le premier se trouve sur le DataNode, le second est stocké sur un DataNode séparé au sein du cluster, et un troisième est stocké sur un DataNode dans un cluster différent. C'est comme une étape de sécurité de triple protection. Ainsi, si le pire devait arriver et qu'une réplique échoue, les données ne sont pas perdues définitivement.
Le NameNode conserve des informations importantes, telles que le nombre de blocs et l'emplacement des répliques. En comparaison, un DataNode stocke les données réelles et peut créer, supprimer et répliquer des blocs sur commande. Cela ressemble à ceci :
Cela détermine où les DataNodes doivent stocker ses blocs.
Comment HDFS stocke-t-il les données ?
Le système de fichiers HDFS se compose d'un ensemble de services maîtres (NameNode, secondary NameNode et DataNodes). Le NameNode et le secondary NameNode gèrent les métadonnées HDFS. Les DataNodes hébergent les données HDFS sous-jacentes.
Le NameNode suit quels DataNodes contiennent le contenu d'un fichier donné dans HDFS. HDFS divise les fichiers en blocs et stocke chaque bloc sur un DataNode. Plusieurs DataNodes sont connectés au cluster. Le NameNode distribue ensuite des répliques de ces blocs de données à travers le cluster. Il indique également à l'utilisateur ou à l'application où trouver les informations souhaitées.
À quoi le système de fichiers distribué Hadoop (HDFS) est-il conçu pour gérer ?
En termes simples, lorsque l'on demande "à quoi le système de fichiers distribué Hadoop est-il conçu pour gérer ?", la réponse est avant tout le big data. Cela peut être inestimable pour les grandes entreprises qui auraient autrement du mal à gérer et à stocker les données de leurs activités et de leurs clients.
Avec Hadoop, vous pouvez stocker et unifier des données, qu'elles soient transactionnelles, scientifiques, issues des médias sociaux, publicitaires ou de machine learning. Cela signifie également que vous pouvez revenir à ces données et obtenir des informations précieuses sur les performances et l'analyse de l'entreprise.
Comme il a été conçu pour stocker des données, HDFS peut également gérer des données brutes qui sont couramment utilisées par les scientifiques ou les personnes du domaine médical qui cherchent à analyser de telles données. Ce sont ce que l'on appelle des data lakes. Cela leur permet de résoudre des problèmes plus difficiles sans contraintes.
De plus, comme Hadoop a été principalement conçu pour gérer d'énormes volumes de données de diverses manières, il peut également être utilisé pour exécuter des algorithmes à des fins d'analyse. Cela signifie qu'il aide les entreprises à traiter et analyser les données plus efficacement, leur permettant de découvrir de nouvelles tendances et anomalies. Certains ensembles de données sont même retirés des entrepôts de données et déplacés vers Hadoop. Cela rend simplement plus facile le stockage de tout dans un endroit facilement accessible.
En ce qui concerne les données transactionnelles, Hadoop est également équipé pour gérer des millions de transactions. Grâce à ses capacités de stockage et de traitement, il peut être utilisé pour stocker et analyser les données clients. Vous pouvez également approfondir les données pour découvrir les tendances et les modèles émergents afin d'aider à atteindre les objectifs commerciaux. N'oubliez pas que Hadoop est constamment mis à jour avec de nouvelles données, et vous pouvez comparer les données nouvelles et anciennes pour voir ce qui a changé et pourquoi.
Considérations relatives à HDFS
Par défaut, HDFS est configuré avec une réplication 3x, ce qui signifie que les ensembles de données auront deux copies supplémentaires. Bien que cela améliore la probabilité de données localisées pendant le traitement, cela introduit des coûts de stockage supplémentaires.
- HDFS fonctionne mieux lorsqu'il est configuré avec un stockage localement attaché. Cela garantit les meilleures performances pour le système de fichiers.
- Augmenter la capacité de HDFS nécessite l'ajout de nouveaux serveurs (calcul, mémoire, disque), pas seulement de supports de stockage.
HDFS vs. Stockage objet Cloud
Comme mentionné ci-dessus, la capacité HDFS est étroitement liée aux ressources informatiques. L'augmentation de la capacité de stockage implique l'augmentation des ressources CPU, même si ces dernières ne sont pas nécessaires. Lorsque vous ajoutez des nœuds de données supplémentaires à HDFS, une opération de rééquilibrage est nécessaire pour distribuer les données existantes aux serveurs nouvellement ajoutés.
Cette opération peut prendre un certain temps. La mise à l'échelle d'un cluster Hadoop dans un environnement sur site peut également être difficile en termes de coûts et d'espace. HDFS utilise un stockage localement attaché qui peut offrir des avantages en termes de performances IO, à condition que YARN puisse provisionner le traitement sur les serveurs qui stockent les données à traiter.
Dans les environnements fortement utilisés, il est possible que la plupart des opérations de lecture/écriture de données se fassent sur le réseau plutôt qu'en local. Le stockage objet Cloud comprend des technologies telles qu'Azure Data Lake Storage, AWS S3 ou Google Cloud Storage. Il est indépendant des ressources informatiques qui y accèdent et les clients peuvent donc stocker beaucoup plus de données dans le cloud.
Les clients qui cherchent à stocker des pétaoctets de données peuvent facilement le faire dans le stockage d'objets cloud. Cependant, toutes les opérations de lecture et d'écriture sur le stockage cloud se feront sur le réseau. Il est donc important que les applications qui accéderont à ses données tirent parti de la mise en cache lorsque cela est possible ou incluent une logique pour minimiser les opérations d'E/S.
Ressources supplémentaires
- Guide de migration de Hadoop vers Lakehouse
- Hub de migration
- Ebook de modernisation cloud : un guide commercial sur la valeur cachée de la migration depuis Hadoop
- Démonstrations rapides à la demande de la plateforme Databricks Lakehouse
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.