Apache Spark et Hadoop : travailler ensemble
par Ion Stoica
On nous demande souvent comment Apache Spark s'intègre dans l'écosystème Hadoop, et comment exécuter Spark sur un cluster Hadoop existant. Ce blog vise à répondre à ces questions.
Premièrement, Spark est destiné à améliorer, et non à remplacer, la pile Hadoop. Dès le premier jour, Spark a été conçu pour lire et écrire des données depuis et vers HDFS, ainsi que d'autres systèmes de stockage, tels que HBase et S3 d'Amazon. Ainsi, les utilisateurs d'Hadoop peuvent enrichir leurs capacités de traitement en combinant Spark avec Hadoop MapReduce, HBase et d'autres frameworks de big data.
Deuxièmement, nous nous sommes constamment efforcés de permettre à chaque utilisateur Hadoop de tirer parti des capacités de Spark aussi facilement que possible. Peu importe que vous exécutiez Hadoop 1.x ou Hadoop 2.0 (YARN), et que vous disposiez ou non de privilèges administratifs pour configurer le cluster Hadoop, il existe une solution pour exécuter Spark ! Il existe notamment trois manières de déployer Spark dans un cluster Hadoop : en mode autonome, YARN et SIMR.
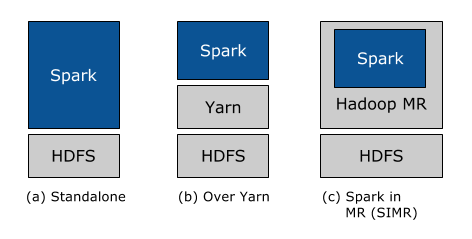
Déploiement autonome: Avec le déploiement autonome, on peut allouer statiquement des ressources sur tout ou partie des machines d'un cluster Hadoop et exécuter Spark côte à côte avec Hadoop MR. L'utilisateur peut alors exécuter des Jobs Spark arbitraires sur ses données HDFS. Sa simplicité en fait le déploiement de choix pour de nombreux utilisateurs d'Hadoop 1.x.
Déploiement Hadoop Yarn : les utilisateurs Hadoop qui ont déjà déployé ou prévoient de déployer Hadoop Yarn peuvent simplement exécuter Spark sur YARN sans pré-installation ni accès administrateur requis. Cela permet aux utilisateurs d'intégrer facilement Spark dans leur pile Hadoop et de tirer parti de toute la puissance de Spark, ainsi que d'autres composants s'exécutant sur Spark.
Spark In MapReduce (SIMR): Pour les utilisateurs Hadoop qui n'exécutent pas encore YARN, une autre option, en plus du déploiement autonome, consiste à utiliser SIMR pour lancer des jobs Spark au sein de MapReduce. Avec SIMR, les utilisateurs peuvent commencer à expérimenter avec Spark et utiliser son shell en quelques minutes après l'avoir téléchargé ! Cela réduit considérablement les obstacles au déploiement et permet à pratiquement tout le monde d'essayer Spark.
Interopérabilité avec d'autres systèmes
Spark interopère non seulement avec Hadoop, mais aussi avec d'autres technologies Big Data populaires.
- Apache Hive: grâce à Shark, Spark permet aux utilisateurs d'Apache Hive d'exécuter leurs requêtes non modifiées beaucoup plus rapidement. Hive est une solution populaire d'entrepôt de données fonctionnant sur Hadoop, tandis que Shark est un système qui permet au framework Hive de fonctionner sur Spark au lieu d'Hadoop. Par conséquent, Shark peut accélérer les requêtes Hive jusqu'à 100 fois lorsque les données d'entrée tiennent en mémoire, et jusqu'à 10 fois lorsqu'elles sont stockées sur disque.
- AWS EC2: les utilisateurs peuvent facilement exécuter Spark (et Shark) sur Amazon EC2 en utilisant soit les scripts fournis avec Spark, soit les versions hébergées de Spark et Shark sur Amazon Elastic MapReduce.
- Apache Mesos: Spark s'exécute sur Mesos, un système de gestion de cluster qui fournit une isolation efficace des ressources entre les applications distribuées, y compris MPI et Hadoop. Mesos permet un partage à granularité fine qui permet à un Job Spark de tirer dynamiquement parti des Ressources inactives du cluster pendant son exécution. Cela se traduit par des améliorations de performances considérables, en particulier pour les Jobs Spark de longue durée.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.