Patching sans interruption de service dans Lakebase, partie 1 : Pré-amorçage
La première de plusieurs fonctionnalités qui rendent les redémarrages de calcul invisibles
par Hans Norheim
- La maintenance planifiée cause plus de perturbations que les défaillances imprévues pour la plupart des bases de données, car les correctifs sont plus fréquents que les défaillances matérielles. L'objectif est de rendre les mises à jour de version et les correctifs de sécurité totalement imperceptibles.
- Le problème principal des redémarrages de bases de données est que les caches en mémoire sont effacés, entraînant une dégradation du débit allant jusqu'à 70 % pendant que les données se rechargent depuis le stockage. Sous une charge de travail intensive, cela peut passer d'un problème de performance à un problème de disponibilité.
- Lakebase résout ce problème en démarrant un nouveau nœud de calcul en arrière-plan avant un redémarrage planifié, en pré-amorçant son cache à l'aide de la liste des pages du primaire actuel et du flux WAL, puis en le promouvant en primaire sans coût supplémentaire ni surcharge de réplique.
Assurer la disponibilité constante des bases de données clients est l'une des choses les plus importantes que nous faisons dans Lakebase. Nous avons conçu le système avec une redondance à tous les niveaux, basculant et récupérant automatiquement votre base de données en cas de défaillances matérielles ou logicielles.
Dans un système à grande échelle, de telles défaillances imprévues sont une attente statistique, mais pour une base de données individuelle, elles ne sont pas si fréquentes. Pour une base de données individuelle, la maintenance planifiée tend à causer plus de perturbations de charge de travail. Après tout, une base de données typique est patchée plus fréquemment qu'elle ne subit de défaillance matérielle.
Aujourd'hui, presque tous les fournisseurs de bases de données fonctionnent avec des fenêtres de maintenance : des périodes pendant lesquelles votre base de données coupe toutes les connexions actives et est mise à jour et redémarrée dans un processus qui peut prendre de quelques secondes à quelques minutes. Bien que Lakebase vous permette de planifier les mises à jour à un moment qui vous convient le mieux, il s'agit toujours d'une brève interruption lorsqu'elle se produit.
Nous pensons pouvoir faire mieux. Ce billet de blog est le premier d'une série sur la façon dont nous exploitons l'architecture lakebase pour éliminer complètement l'impact de la maintenance planifiée. Notre objectif : rendre les mises à jour de version et les correctifs de sécurité totalement imperceptibles.
Dans ce billet, nous aborderons le pré-amorçage : une technique qui empêche toute dégradation des performances qui suit un redémarrage de base de données. Dans les prochains billets, nous discuterons des améliorations du processus de basculement lui-même et des optimisations supplémentaires qui nous rapprochent d'un véritable patching sans interruption de service.
Le problème des redémarrages à froid
Le défi avec le redémarrage de PostgreSQL est que les caches en mémoire (en particulier le cache tampon et le cache de fichiers local) sont perdus. Même si la base de données est de retour en ligne très rapidement (1 seconde @ P99), la charge de travail peut connaître un ralentissement dans les premières minutes après le redémarrage – nous avons constaté une réduction d'environ 70 % du TPS pgbench. Ceci est dû à un faible taux de succès du cache pendant que les données sont relues depuis le stockage et que le cache se pré-chauffe. Bien que cela puisse sembler être uniquement un problème de performance, cela peut devenir un problème de disponibilité si le ralentissement est suffisamment grave pour que la base de données ne puisse pas suivre la charge de travail et que des délais d'attente se produisent.
Des techniques pour résoudre ce problème existent dans Postgres : pg_prewarm peut être utilisé pour pré-amorcer les caches tampons. Cependant, cela s'exécute après un redémarrage, lorsque la charge de travail est déjà impactée. La réplication en flux peut être utilisée pour configurer une réplique, qui peut être pré-amorcée avant de basculer dessus (la promouvant en primaire). Cependant, cela nécessite la création d'une réplique complète et une orchestration minutieuse du pré-amorçage avant le basculement.
Pré-amorçage sur l'architecture Lakebase
Dans l'architecture lakebase, nous combinons des nœuds de calcul sans état et élastiques avec un stockage partagé et désagrégé. Les nœuds de calcul utilisent des caches locaux pour offrir des performances maximales sans sacrifier les propriétés serverless. Bien que le cache soit confronté aux mêmes problèmes de démarrage à froid décrits ci-dessus, nous avons plus d'options avec l'architecture Lakebase.
Étant donné que les répliques de calcul Postgres de Lakebase sont sans état, nous pouvons les démarrer et les arrêter à la demande. Nous utilisons cela et le combinons avec un pré-amorçage automatique lors des redémarrages planifiés pour minimiser l'impact sur les performances de la charge de travail. Voici comment cela fonctionne :
- Une nouvelle version de l'image de calcul Postgres de Lakebase devient disponible. Vous recevez une notification et pouvez planifier le redémarrage à un moment qui vous convient.
- Peu de temps avant l'heure prévue, notre plan de contrôle démarre un nouveau calcul Postgres en arrière-plan. Vous ne le voyez pas et vous n'êtes pas facturé pour cela. La charge de travail du primaire actuel n'est pas affectée.
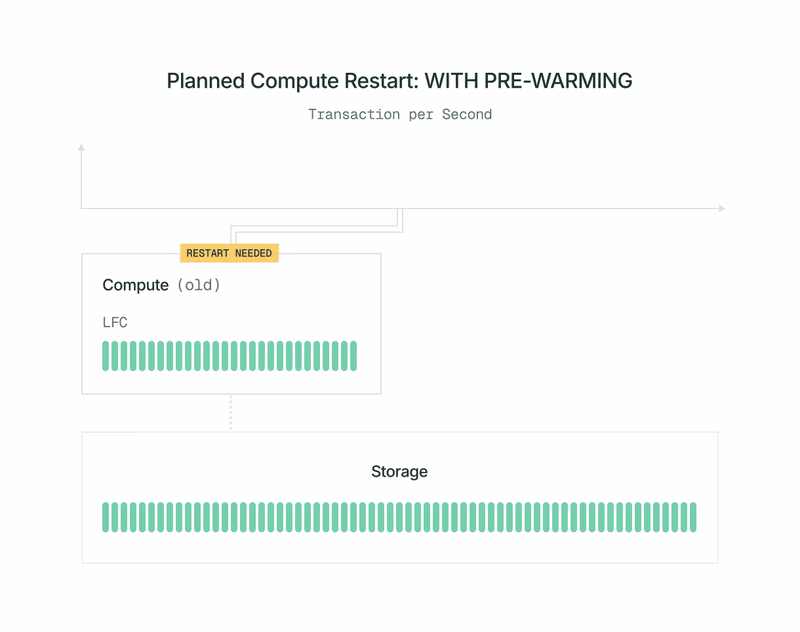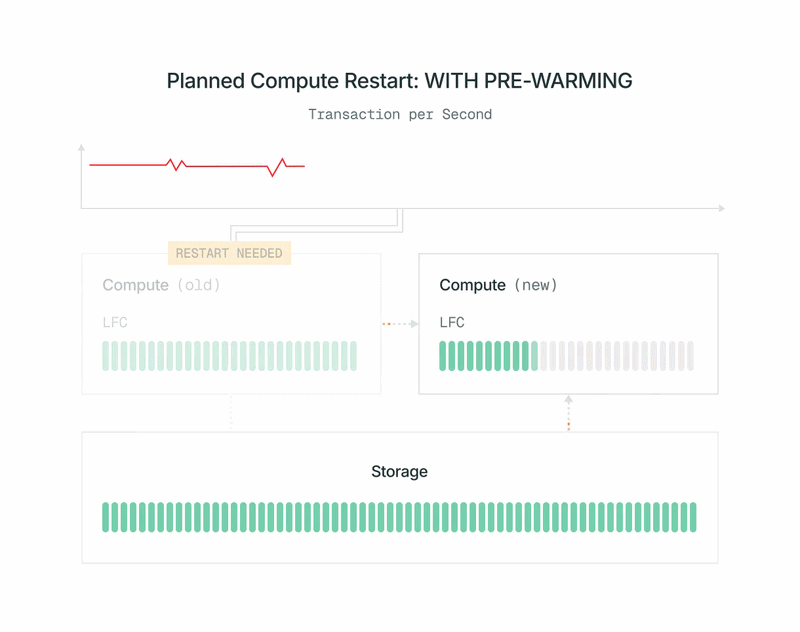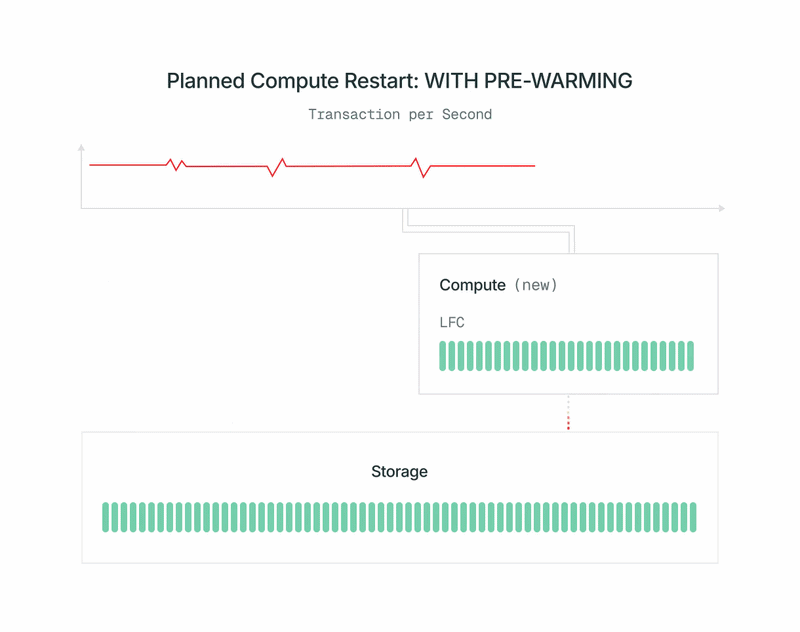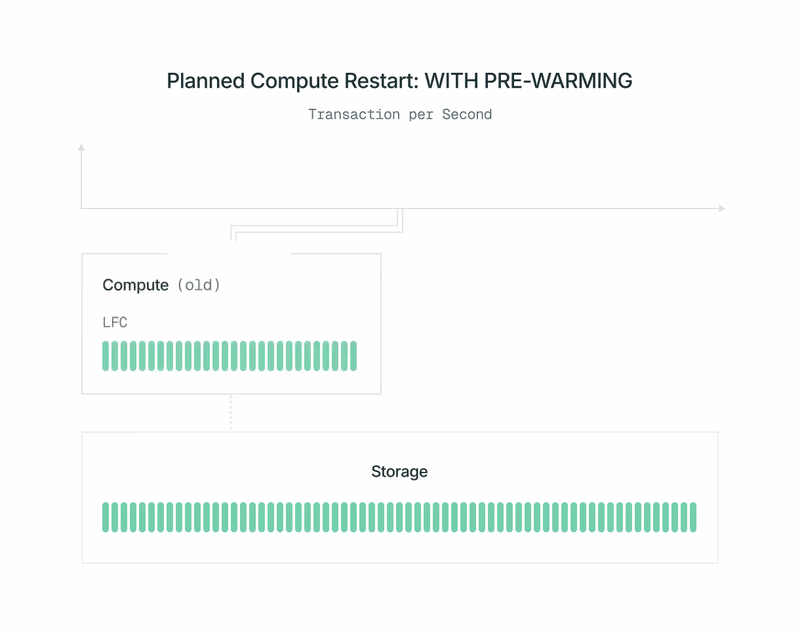
- Une liste des pages dans le cache du primaire actuel est envoyée au nouveau calcul. Le nouveau calcul charge ces pages dans le cache depuis notre niveau de stockage partagé sans impacter le primaire.
- Le nouveau calcul s'abonne au WAL (write-ahead log) pour maintenir son cache à jour. Pour plus d'efficacité, contrairement à une réplique Postgres normale, il peut ignorer tous les enregistrements WAL qui n'affectent pas son cache. Il obtient le WAL de nos Safekeepers, sans imposer de charge supplémentaire au calcul primaire.
- Lorsque le pré-amorçage est terminé, nous arrêtons rapidement l'ancien primaire, promouvons le nouveau calcul en primaire et le mettons en service. La promotion utilise le pg_promote standard de l'OSS Postgres et ne redémarre pas le serveur de base de données.
Avant :

Après :
Avec l'architecture lakebase, vous bénéficiez de cela sans coût supplémentaire, sans payer pour des répliques additionnelles. À ce jour, tous les redémarrages planifiés des points de terminaison en lecture/écriture sont effectués de cette manière sans que vous ayez à faire quoi que ce soit. Bientôt, nous l'étendrons également aux points de terminaison en lecture seule.
Résultats
Pour mesurer l'impact des caches froids, nous avons exécuté pgbench sur 10 Go (facteur d'échelle 670) sur une base de données tout en la redémarrant – d'abord avec le pré-amorçage activé, puis sans pré-amorçage. Le premier graphique montre une charge de travail en lecture seule (pgbench « select only »), tandis que le second montre une charge de travail en lecture-écriture (pgbench « simple update »).


Dans les deux cas, nous constatons que le débit récupère presque instantanément avec le pré-amorçage. Sans pré-amorçage, la récupération est beaucoup plus lente pendant que le cache froid se réchauffe. La différence est la plus frappante pour la charge de travail en lecture seule car le pré-amorçage améliore le taux de succès du cache, ce qui aide davantage les lectures que les écritures.
(Cet article de blog a été traduit à l'aide d'outils basés sur l'intelligence artificielle) Article original
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.