Qu'est-ce que la virtualisation des données ?
Accédez aux données et interrogez-les à partir de sources multiples sans les déplacer ni les répliquer physiquement, créant ainsi une couche virtuelle unifiée.
- Comprendre la virtualisation des données et comment elle simplifie l'accès aux données entre systèmes hétérogènes grâce à une interface unifiée.
- Découvrir comment la virtualisation réduit les déplacements de données, simplifie l'architecture et offre un accès en temps réel aux sources de données distribuées.
- Explorer des cas d'utilisation tels que les requêtes fédérées, l'intégration de systèmes existants et l'analyse agile sans processus ETL complexes.
Qu'est-ce que la virtualisation des données ?
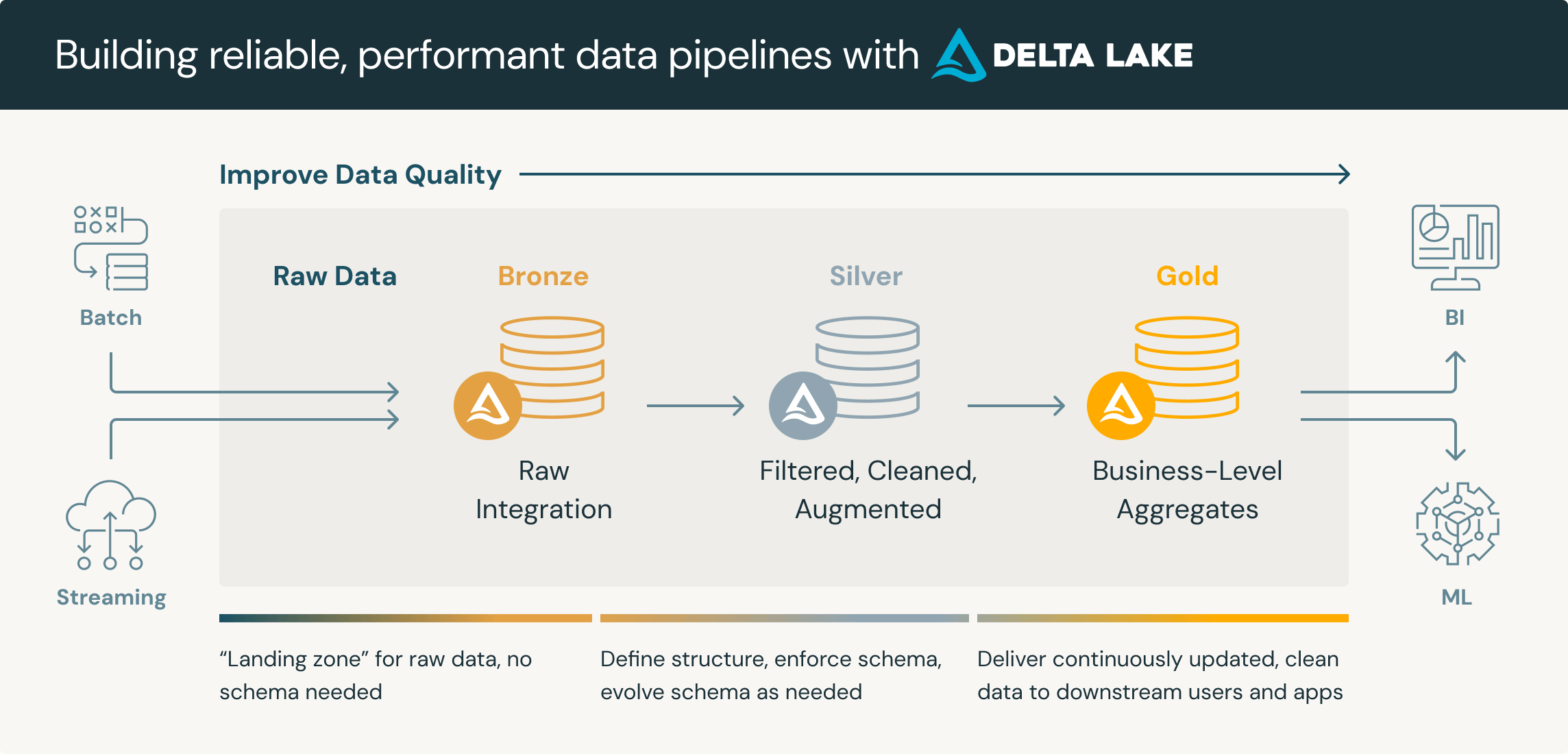
La virtualisation des données est une méthode d'intégration qui permet aux organisations de créer des vues unifiées des informations contenues dans plusieurs sources sans déplacer ni copier physiquement les données. Technologie de virtualisation fondamentale, cette approche de la gestion des données permet aux consommateurs d'accéder aux données de systèmes hétérogènes par le biais d'une seule couche virtuelle. Au lieu d'extraire des données dans un dépôt central, la virtualisation des données place une couche abstraite entre les systèmes sources et les consommateurs. Ceux-ci peuvent ensuite interroger cette couche via une interface centrale, pendant que les données sous-jacentes restent à leur emplacement d'origine.
La virtualisation des données apporte une réponse à un problème fondamental de la gestion moderne des données : aujourd'hui, les données des entreprises sont dispersées sur une pluralité de sources – bases de données, data lakes, es applications cloud et systèmes hérités. Les approches d'intégration traditionnelles reposent sur des pipelines complexes qui déplacent les données vers un warehouse central où elles pourront être analysées. La virtualisation des données élimine cette étape et offre un accès immédiat aux informations, où qu'elles se trouvent.
L'intérêt pour la virtualisation des données s'est accru avec l'adoption des environnements multicloud, des architectures lakehouse et du partage de données entre organisations. Ces tendances ont pour effet d'augmenter le nombre de sources à consulter, et donc de rendre toute consolidation physique de plus en plus difficile. La virtualisation des données offre un moyen d'unifier l'accès sans avoir à unifier le stockage.
La technologie de virtualisation des données introduit une couche de virtualisation entre les consommateurs de données et les systèmes sources. Grâce à cette couche virtuelle, les utilisateurs métier peuvent interroger les données des data lake, des data warehouse et des services de stockage cloud sans avoir à maîtriser les complexités techniques de chaque source. Lorsqu'elles font le choix de la virtualisation des données, les organisations offrent à leurs équipes la possibilité de combiner les données provenant de plusieurs sources en temps réel, et ce, tout en maintenant une gouvernance centralisée.
Prenons un instant pour clarifier une confusion courante : les termes « virtualisation » et « visualisation » des données ont une proximité phonétique, mais ces deux pratiques résolvent des problèmes entièrement différents. La virtualisation des données est une technologie d'intégration qui introduit une couche d'accès à plusieurs sources distribuées. La visualisation des données, quant à elle, est une technologie de présentation qui restitue les informations sous forme de schémas, de graphes et de tableaux de bord à des fins de business intelligence. Les deux sont complémentaires ; la virtualisation des données fournit un accès unifié aux données que les outils de visualisation présentent ensuite dans des formats lisibles.
Pour les organisations qui cherchent à accroître l'agilité de leur gestion des données, la virtualisation offre un bon moyen d'obtenir plus rapidement des insights, sans les lourdeurs d'infrastructure des approches traditionnelles.
Lien connexe : processus ETL et stratégies d'intégration des données
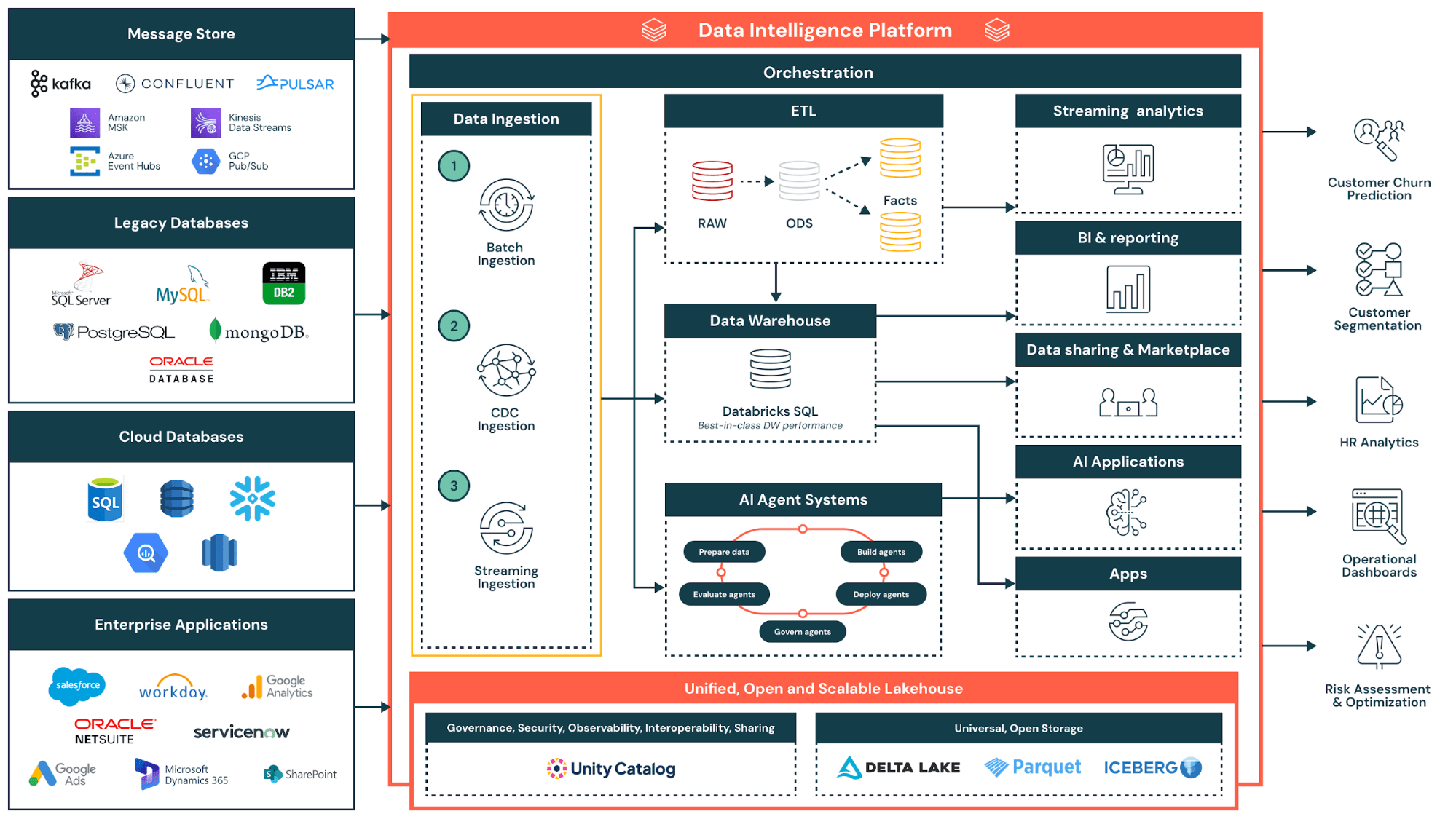
Fonctionnement de la virtualisation des données : architecture et composants
L'architecture de virtualisation des données repose principalement sur trois composants d'infrastructure de gestion : une couche sémantique pour les définitions métier, une couche de virtualisation pour la fédération des requêtes et un mécanisme de gestion des métadonnées pour la gouvernance. En intégrant ces composants, les plateformes modernes créent des environnements de données virtuels complets où data scientists, utilisateurs métier et consommateurs de données peuvent accéder aux sources de données et aux services sans se préoccuper du lieu de résidence des informations.
La couche de virtualisation vient se placer entre les consommateurs de données (analystes, applications et outils de BI) et les sources de données sous-jacentes. Elle abrite des métadonnées décrivant l'emplacement des données, leur structure et les modalités d'accès. La couche elle-même ne stocke aucune donnée ; elle joue le rôle de moteur intelligent de routage et de traduction. Les solutions de gouvernance comme Unity Catalog peuvent centraliser la gestion de ces métadonnées et offrir un point de contrôle unique pour les politiques de découverte d'accès.
Lorsqu'un utilisateur envoie une requête, le moteur de virtualisation détermine quelles sources de données contiennent les informations pertinentes. Il traduit la requête dans le langage natif de chaque système : SQL pour les bases de données relationnelles, appel d'API pour les applications cloud ou protocole d'accès aux fichiers pour les data lakes. Le moteur fédère ensuite la demande sur tous les systèmes et rassemble les résultats pour produire une réponse unifiée.
La virtualisation des données permet la fédération des requêtes, la pratique qui décrit ce modèle d'exécution distribuée. Les requêtes complexes sont décomposées en requêtes secondaires qui sont acheminées vers leur source respective. Les résultats sont renvoyés à la couche de virtualisation qui les joint et les transforme avant de délivrer une réponse unique à l'utilisateur. Lakehouse Federation, par exemple, permet aux utilisateurs de lancer des requêtes sur des bases de données, des warehouses et des applications cloud externes directement depuis le lakehouse, sans avoir à migrer les données. Pour optimiser les performances, il existe des techniques comme le report de prédicat, qui consiste à appliquer la logique de filtrage à la source plutôt que de manière centralisée.
Les plateformes modernes emploient également le report des jointures, l'élagage de colonnes et la mise en cache intelligente. Lorsque les sources ont des temps de réponse différents, le moteur exécute les requêtes en parallèle et gère les délais d'expiration pour éviter que des sources lentes ne bloquent l'arrivée des résultats. Grâce à ces optimisations, les requêtes virtualisées peuvent approcher les niveaux de performance des requêtes effectuées sur des données physiquement consolidées.
La virtualisation des données native au lakehouse offre un avantage supplémentaire : l'unification de la gouvernance des données fédérées et internes. Lorsque Unity Catalog gère les politiques d'accès, les organisations appliquent les mêmes règles de sécurité aux bases de données externes qu'aux tables de lakehouse. Les utilisateurs interrogent les données virtualisées et physiques avec la même instruction SQL, sans avoir tenir compte des différents systèmes et cadres d'autorisation.
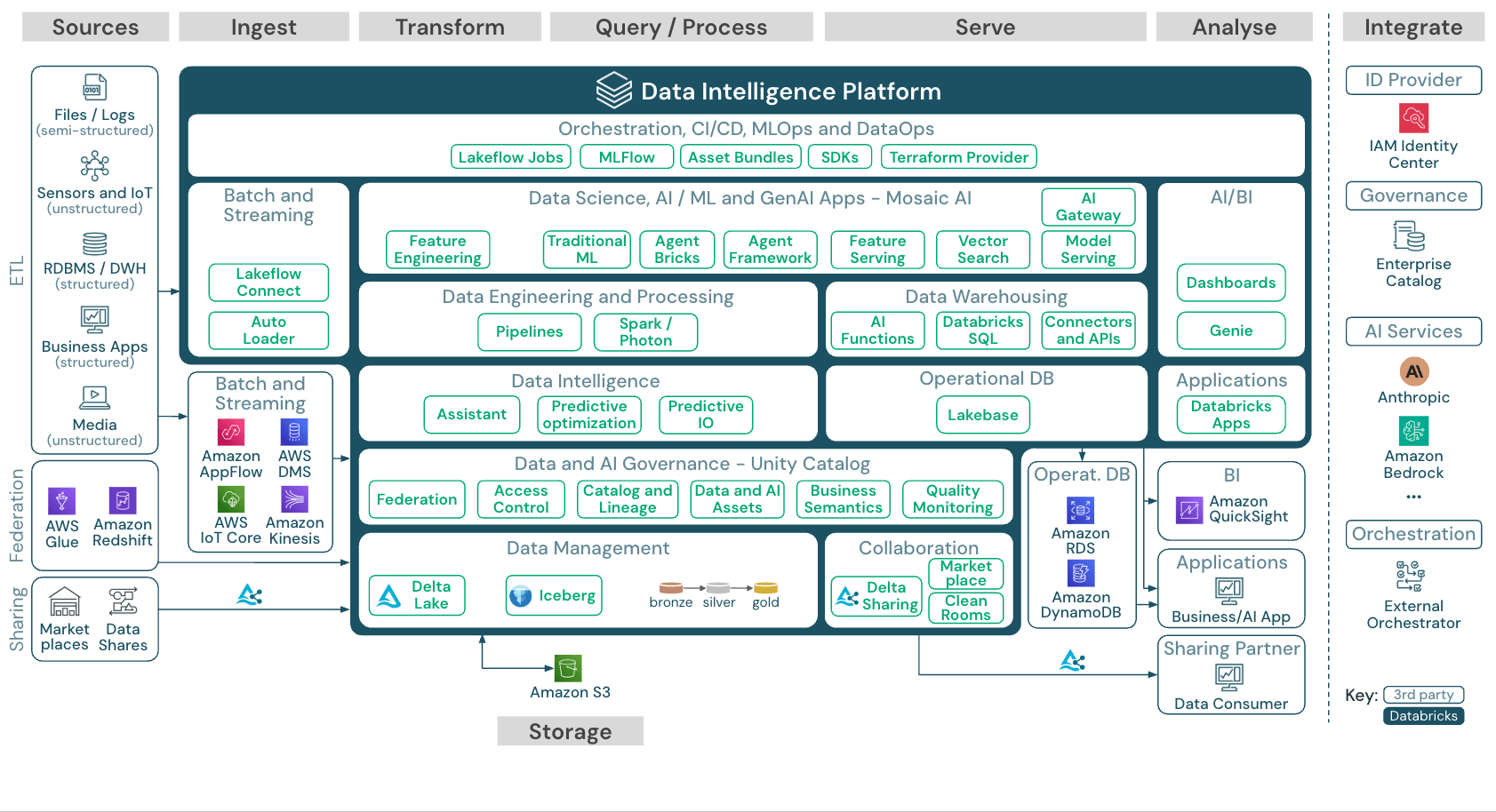
Virtualisation des données et ETL : principales différences
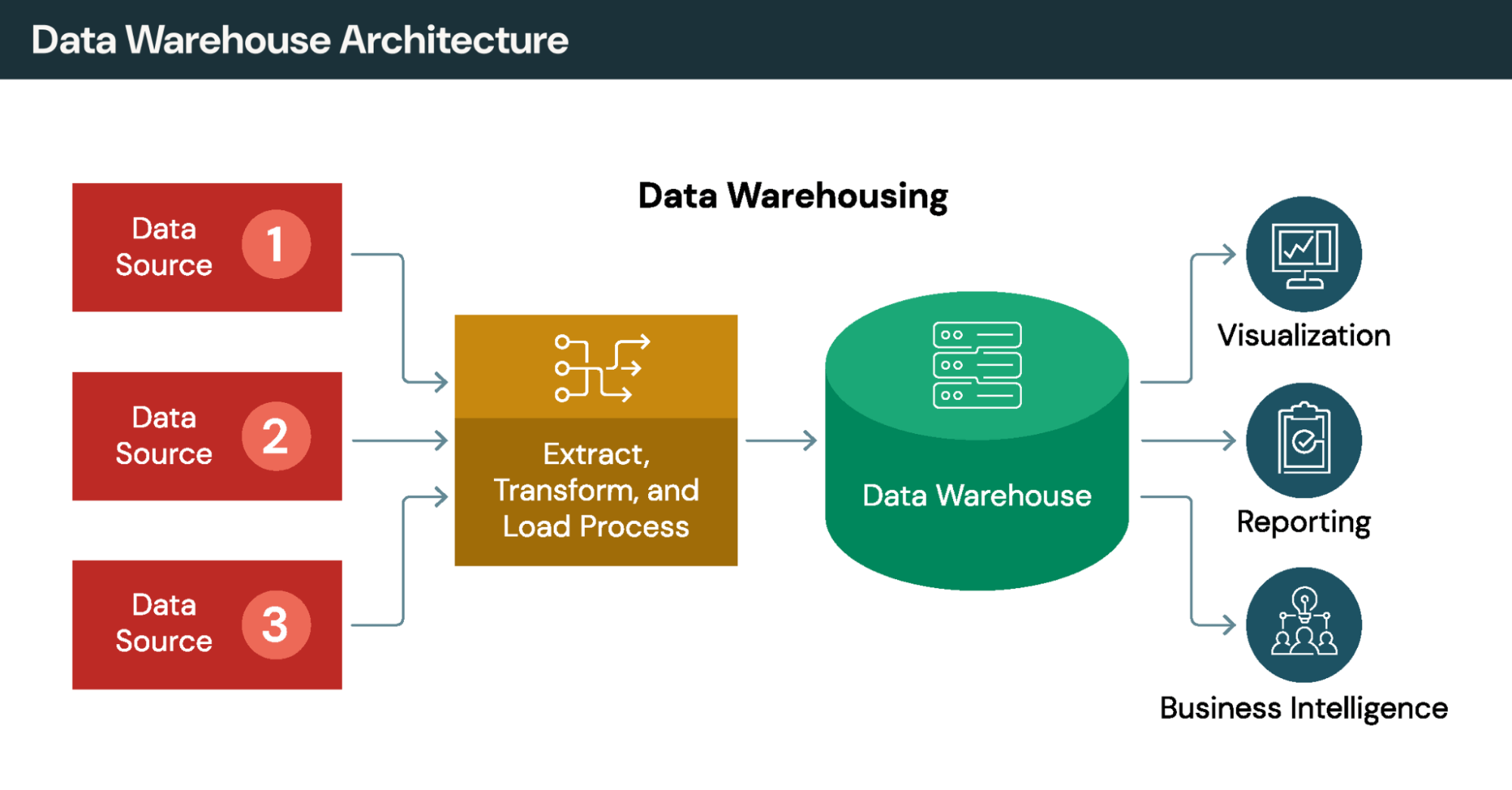
Le processus ETL (extraction, transformation, chargement) traditionnel déplace physiquement les données des systèmes sources vers un warehouse ou un data lake centralisé. Il crée des copies, introduit une latence entre les cycles d'extraction et repose sur un pipeline qui doit être constamment maintenu. La virtualisation des données adopte l'approche inverse : les données restent en place et on y accède sur demande.
Chaque approche répond à des cas d'utilisation spécifiques. Faisons le point sur les principales distinctions :
Déplacement des données : l'ETL copie les données vers un dépôt central. La virtualisation des données interroge les données in situ, sans créer de doublons.
Fraîcheur des données : les données fournies par l'ETL datent nécessairement du dernier cycle d'actualisation, qui peut remonter à plusieurs heures ou jours. La virtualisation des données offre un accès immédiat aux données sources en direct.
Délai d'obtention des insights : dans le cas de l'ETL, l'analyse dépend de la création de pipelines, qui prend souvent des semaines ou des mois. Avec la virtualisation des données, l'accès est immédiat une fois les connexions configurées.
Transformations complexes : l'ETL excelle dans le traitement en plusieurs étapes et l'analyse historique. La virtualisation des données gère les jointures et les filtres, mais n'est pas performante face à une logique de transformation élaborée.
La plupart des organisations utilisent les deux approches conjointement. L'ETL et l'ELT gèrent les transformations complexes, les tendances historiques et les charges par batch aux exigences de performance élevées. La virtualisation des données offre un accès agile et en temps réel pour les analyses ad hoc et les tableaux de bord opérationnels. Le choix dépend davantage des caractéristiques de la charge de travail que de principes philosophiques.
Lien connexe : Unity Catalog pour unifier la gouvernance unifiée et les modèles d'architecture de données
Principaux avantages : un accès en temps réel sans déplacer les données
La virtualisation des données a de nombreux arguments, à commencer par la rapidité, la réduction des coûts et la simplification de la gouvernance. Elle permet en effet aux organisations de réduire les coûts de stockage, de faciliter l'accès aux données pour les utilisateurs métier et de simplifier les infrastructures couvrant des sources disparates.
1. Réduction des coûts de stockage et d'infrastructure
La virtualisation des données apporte une valeur immédiate en réduisant les coûts de réplication des données. En supprimant l'étape de duplication, les organisations cessent de payer pour conserver plusieurs exemplaires des mêmes informations dans des warehouses, des datamarts et des environnements analytiques. Les économies de stockage deviennent plus intéressantes encore lorsque les volumes augmentent. Quant aux équipes, elles évitent les complexités d'infrastructure liées à la synchronisation des copies.
2. Des insights en quasi-temps réel pour les consommateurs de données
Les requêtes interrogent les systèmes en direct plutôt que des copies obsolètes conservées dans des warehouses. Chez les entreprises de services financiers, cette capacité est essentielle pour la détection des fraudes. Les détaillants, quant à eux, assurent le suivi des stocks sur tous les canaux de distribution au fil des transactions, et les systèmes de santé accèdent aux dossiers à jour des patients pendant les épisodes de soins. L'analytique en temps réel devient possible sans pipelines de streaming.
3. Simplification de l'infrastructure
Avec la virtualisation des données, les organisations centralisent les règles d'accès, les politiques de sécurité et les métadonnées dans une couche de données virtuelle. Elles n'ont plus à répliquer la gouvernance sur leurs différents systèmes. Les administrateurs définissent les politiques une fois pour toutes, sans avoir à les maintenir séparément dans chaque source. Et lorsqu'elle est intégrée à une plateforme lakehouse plutôt que déployée en tant qu'infrastructure autonome, c'est un système de moins à gérer pour les équipes.
4. Une rentabilisation plus rapide pour les initiatives commerciales
Les organisations observent une réduction sensible des délais de livraison qui se comptent en jours, voire en heures, plutôt qu'en semaines. Elles s'épargnent en effet les mois de travail généralement indispensables pour concevoir, créer, tester et maintenir des pipelines ETL pour chaque nouveau cas d'usage analytique.
Ces avantages sont particulièrement tangibles dans les scénarios qui impliquent des sources de données diverses, dont les exigences évoluent rapidement et qui privilégient la fraîcheur des données à la profondeur historique.
Comparaison des approches d'intégration
À l'instar de l'ETL, les méthodes d'intégration traditionnelles déplacent physiquement les données dans des dépôts centraux. La virtualisation des données adopte une approche différente : on accède aux données in situ, sans les répliquer. Les organisations combinent souvent les deux stratégies : l'ETL pour les transformations complexes, la virtualisation des données pour des questions d'agilité.
Lien connexe : capacités d'analytique en temps réel et entreposage des données moderne
Le guide pratique de l'IA agentique pour l'entreprise

Cas d'utilisation et applications métier
La technologie de virtualisation des données montre tout son intérêt lorsque les organisations ont besoin d'un accès unifié à leurs systèmes opérationnels, à leurs data lakes et à leurs applications cloud. La virtualisation des données offre un accès en temps réel à plusieurs sources, sans les délais des projets d'intégration de données traditionnels. Voici quelques exemples d'applications courantes.
Vente au détail
Les détaillants exploitent des plateformes de commerce en ligne, des systèmes de magasins physiques, des applications de gestion d'entrepôt, des terminaux de point de vente et des réseaux de fournisseurs. La virtualisation des données apporte une visibilité sur l'ensemble de la chaîne d'approvisionnement en offrant un accès à tous ces systèmes sans qu'il faille créer d'intégrations point à point.
La virtualisation des données est particulièrement utile pour la gestion des stocks en temps réel. Plutôt que de synchroniser chaque nuit les inventaires par batch, les détaillants interrogent directement les données de tous les canaux de distribution pour obtenir des informations de disponibilité précises. Cela leur permet de proposer des services comme l'achat en ligne avec retrait en magasin, qui nécessite de fournir aux clients des informations sur les stocks réels avant qu'ils passent commande. Les organisations qui misent sur la virtualisation des données pour accéder aux données de la chaîne d'approvisionnement font des économies significatives en réduisant les coûts d'inventaire et en améliorant la précision des prévisions de la demande.
Services financiers
Les entreprises de services financiers utilisent des solutions de virtualisation des données pour regrouper les données client provenant des transactions par carte de crédit, des dépôts, des systèmes de prêt, des plateformes CRM et de fournisseurs externes afin d'établir des profils complets. La virtualisation des données assemble ces vues à la demande au lieu de maintenir des enregistrements prédéfinis et potentiellement obsolètes jusqu'à la prochaine mise à jour.
La détection de la fraude en temps réel nécessite de pouvoir accéder en moins d'une seconde aux modèles de transaction de l'ensemble des comptes. Les data warehouses, conçus pour le traitement par batch, ne sont pas à la hauteur de cette exigence de latence. La virtualisation est aussi utile à la conformité réglementaire : il devient possible de produire des rapports consolidés sur l'ensemble des systèmes tout en conservant des pistes d'audit à des fins de contrôle.
Santé
Les données sensibles des patients sont dispersées entre les dossiers médicaux électroniques, les systèmes de facturation, les archives d'imagerie et les systèmes d'information des laboratoires. Grâce à la virtualisation des données, les soignants peuvent consulter des vues unifiées des patients pendant les soins tout en conservant les données dans leur emplacement source. Pour étudier les antécédents d'un patient, un médecin peut consulter les dossiers des soins primaires, les visites de spécialistes et les résultats de laboratoire avec une seule requête, même si chaque système stocke les données indépendamment.
Cette architecture respecte les exigences de confidentialité, car les informations sensibles ne sont jamais centralisées dans un même emplacement vulnérable. Pour coordonner les soins, les hôpitaux et les systèmes de santé peuvent partager certains accès sans transférer physiquement de données d'une organisation à l'autre.
Quand la virtualisation des données n'est pas la meilleure approche
La virtualisation des données a des limites claires. Le traitement par batch de grands volumes nécessite toujours un déplacement physique : traiter des millions de lignes n'est pas plus avantageux, en termes de performances, que de déplacer des données une fois. Un processeur de paiement qui traite des millions de transactions par heure, par exemple, n'aurait aucun intérêt à virtualiser cette charge de travail. L'analyse historique, qui repose sur des instantanés ponctuels, a besoin d'un warehouse pour enregistrer l'état des données au fil du temps, car la virtualisation ne donne accès qu'aux données actuelles. Les transformations complexes multi-étapes dépassent les capacités de la virtualisation, qui se limitent aux jointures, aux filtres et aux agrégations typiques des bases de données.
Les warehouses de très grande envergure, les opérations couvrant plusieurs centres de données et les charges de travail qui exigent une faible latence garantie justifient généralement un déplacement physique par le biais de pipelines de data engineering.
Lien connexe : data lakes et applications de business intelligence
Un point sur la gouvernance, la sécurité et la qualité
La virtualisation des données renforce la gouvernance en centralisant le contrôle dans la couche de virtualisation. Grâce aux outils de virtualisation, les administrateurs définissent les politiques de sécurité une fois pour toutes, plutôt que de les gérer séparément sur des sources hétérogènes.
Les plateformes modernes incluent de nombreuses fonctionnalités de sécurité : contrôle d'accès basé sur le rôle, sécurité à l'échelle des lignes et des colonnes, et masquage des données pour les champs sensibles. Avec le contrôle d'accès basé sur les attributs, qui est lié à des balises de classification, les politiques accompagnent les données, quelles que soient les modalités d'accès. Que les analystes se connectent via des requêtes SQL, des API REST ou des outils de BI, les mêmes règles de sécurité s'appliquent partout.
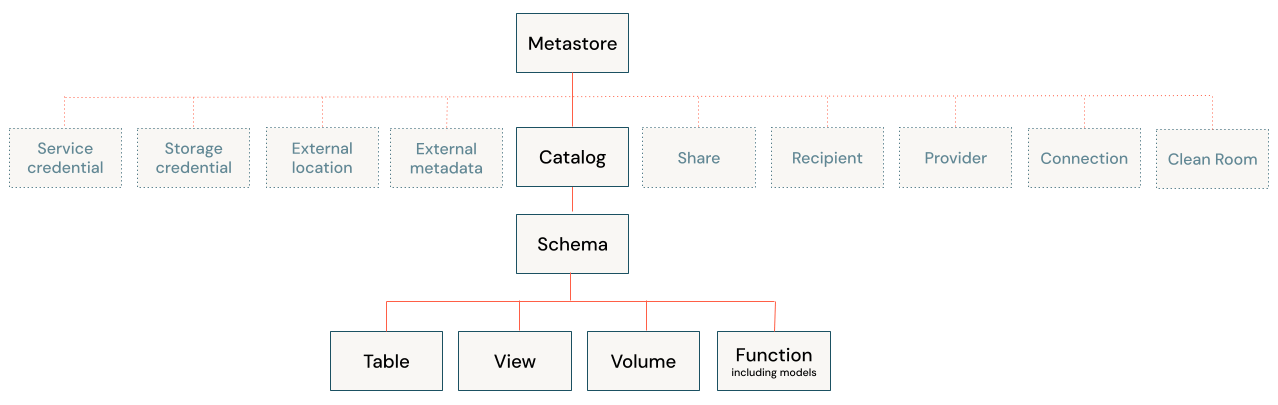
Le suivi d'audit et de traçabilité des données consigne qui a accédé à quelles données, quand et depuis quelle application. Unity Catalog délivre des journaux d'audit au niveau de l'utilisateur et assure une traçabilité dans tous les langages à des fins de conformité. Cette visibilité est conforme au RGPD, à l'HIPAA, au CCPA et aux réglementations financières qui exigent de pouvoir apporter la preuve de la gouvernance.
Avec la virtualisation, les données sont nécessairement récentes, car les requêtes interrogent directement les sources. Mais cela soulève des questions de qualité des données : si les systèmes contiennent des erreurs ou des incohérences, la virtualisation des données transfère ces problèmes aux consommateurs. Les implémentations efficaces associent la virtualisation à une supervision de la qualité des données pour garantir l'intégrité de la vue unifiée.
L'autre défi est celui de la cohérence sémantique. Les différents systèmes n'emploient pas tous les mêmes termes pour désigner des concepts, les mêmes types de données dans des champs équivalents, ni les mêmes définitions métier pour des métriques similaires. La couche de virtualisation doit appliquer des conventions de nommage cohérentes pour associer les données client du CRM au bon client dans le système de facturation, même si chaque système étiquette et formate les données différemment. Certaines organisations ajoutent une couche sémantique pour définir des termes et des calculs métier canoniques applicables à toutes les sources virtualisées. Les analystes ont ainsi l'assurance de voir des définitions cohérentes, quel que soit le système sous-jacent qui héberge les données.
Lien connexe : gouvernance des données avec Unity Catalog et bonnes pratiques de gestion de données
Bonnes pratiques de mise en œuvre et choix des outils
Les organisations qui mettent en œuvre la virtualisation des données ont tout intérêt à suivre les modèles éprouvés pour réussir leur déploiement. Commencez modestement : les implémentations réussies ont souvent pour point de départ des projets spécifiques à forte valeur ajoutée, menés par une petite équipe. Ce n'est qu'une fois l'intérêt de la démarche démontré aux parties prenantes que l'initiative est élargie. Donnez la priorité à la gouvernance en déterminant les responsabilités, les modèles de sécurité et les normes de développement avant de déployer la technologie. Surveillez régulièrement les performances pour identifier les requêtes lentes, optimiser les vues virtuelles fréquemment consultées et ajuster les connexions au fil de l'évolution des usages.
La virtualisation des données en pratique : mise en œuvre dans le monde réel
Prenons un exemple concret. Une entreprise de vente au détail souhaite analyser la valeur vie client. Le problème : les données client se trouvent dans Salesforce CRM, l'historique des transactions, dans une base de données PostgreSQL, le comportement web, dans Google Analytics et les données sur les retours restent confinées à un vieux système Oracle.
L'approche traditionnelle de l'intégration nécessite la création de pipelines ETL pour extraire, transformer et charger toutes ces données dans un warehouse. Ce projet demande des mois. Avec la virtualisation des données, un administrateur crée des connexions à chaque source et publie une vue virtuelle qui combine les données des différents systèmes. Les analystes interrogent cette vue en SQL, un langage qu'ils connaissent bien, ou connectent directement des outils de BI. Ils peuvent consulter les données actuelles de toutes les sources dans un schéma unifié. Par la suite, lorsque l'entreprise ajoute une application mobile avec sa propre base de données, quelques jours suffisent à ajouter cette source à la vue virtuelle, sans refonte du warehouse.
Ce modèle soutient également les stratégies du type « virtualiser d'abord, migrer plus tard ». Les équipes commencent par fédérer les requêtes portant sur des sources externes, puis identifient les données les plus fréquemment consultées. Les datasets les plus sollicités deviennent candidats à la migration physique vers Delta Lake, qui améliore les performances des requêtes et peut faire baisser les coûts de stockage. Les données moins utilisées restent virtualisées afin d'éviter un effort de migration inutile.
Évaluation des outils et outils de virtualisation des données
Pour bien choisir votre outil de virtualisation des données, intéressez-vous en priorité à trois critères.
Prise en charge de la diversité des sources : la plateforme peut-elle se connecter à toutes vos sources actuelles et à venir (bases de données relationnelles, applications cloud, API, stockage basé sur des fichiers, etc.) ? Vérifiez si elle prend en charge les data services dont vous avez besoin. Les lacunes dans la connectivité contraignent à utiliser des solutions de contournement qui dégradent l'accès unifié promis par la virtualisation des données.
Fonctionnalités de sécurité : recherchez des fonctions de sécurité à l'échelle des lignes et des colonnes, de masquage, de chiffrement et de journalisation d'audit complète. Ces fonctionnalités doivent s'appliquer de manière cohérente, quelle que soit la manière dont les utilisateurs accèdent aux données virtualisées.
Fonctions de libre-service : les utilisateurs métier peuvent-ils découvrir et accéder aux données virtualisées sans devoir faire appel à l'IT à la moindre demande ? La valeur de la virtualisation des données diminue si chaque nouvelle requête nécessite l'intervention d'un administrateur.
Au-delà de ces trois critères, tenez compte des exigences de performance des requêtes, des préférences en matière de modèle de déploiement et du coût total de possession.
Lien connexe : LakeFlow pour l'intégration de données et les fonctionnalités de couche sémantique
Conclusion : quand choisir la virtualisation des données
La virtualisation des données excelle dans l'analytique opérationnelle en temps réel, l'exploration régulière de sources diverses, le développement de preuves de concept et les scénarios où la fraîcheur des données l'emporte sur les performances des requêtes. Elle permet aux organisations d'accéder aux données de plusieurs sources sans pipelines complexes. Les approches traditionnelles, qui reposent quant à elles sur des data warehouses, restent à privilégier pour les transformations complexes, l'analyse des tendances historiques, le traitement batch de grands volumes et les charges de travail analytiques urgentes.
La question n'est pas de choisir définitivement une approche plutôt que l'autre, mais de comprendre la place de chacune dans une architecture complète. Les organisations sont de plus en plus nombreuses à déployer les deux technologies : la virtualisation des données pour l'agilité de l'accès et l'expérimentation, et l'intégration physique lorsque les caractéristiques de la charge de travail l'exigent. En adoptant le modèle « virtualiser d'abord, migrer plus tard », les équipes peuvent obtenir une valeur immédiate avec les requêtes fédérées, tout en s'appuyant sur des données d'utilisation réelles pour identifier les sources qui justifient d'investir dans une migration physique vers Delta Lake ou un autre stockage de type lakehouse.
Commencez par identifier les cas où un accès en temps réel à des données distribuées aurait un intérêt commercial manifeste. Utilisez-les pour créer un projet pilote de virtualisation des données, mesurez les résultats et étendez l'initiative en fonction des succès obtenus.
Lien connexe : Cadre décisionnel : ETL ou ELT
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.