Introduction aux data lakes
Les data lakes fournissent un magasin de données complet et fiable pour toutes les activités d'analytique, de business intelligence et de machine learning.

Introduction aux data lakes
Qu'est-ce qu'un data lake ?
Le data lake est un emplacement central conçu pour accueillir une grande quantité de données dans leur format brut d'origine. Contrairement au data warehouse hiérarchique, qui stocke les données dans des fichiers ou des dossiers, le data lake utilise une architecture plate et le stockage d'objets pour stocker les données. Le stockage d'objets conserve les données avec des balises de métadonnées et un identifiant unique. En plus d'offrir des performances supérieures, ce mécanisme facilite la localisation et la récupération des données d'une région à l'autre. En misant à la fois sur stockage d'objets, peu coûteux, et des formats ouverts, les data lakes se prêtent à de nombreux cas d'utilisation des données.
Les data lakes ont été mis au point pour dépasser les limites des data warehouses. Les data warehouses ont l'avantage d'offrir une prise en charge hautement performante et évolutive de l'analytique. En revanche, ils sont coûteux et propriétaires, et sont difficilement compatibles avec les cas d'utilisation modernes qui intéressent la plupart des entreprises. Les data lakes sont souvent utilisés pour centraliser toutes les données d'une organisation dans un emplacement unique où elles peuvent être enregistrées « en l'état » sans qu'il soit nécessaire de leur appliquer au préalable un schéma (autrement dit, une structure formelle d'organisation des données) comme le ferait un data warehouse. Les données peuvent être stockées dans un data lake, quelle que soit leur étape d'affinement : les données brutes sont ingérées et stockées aux côtés des sources de données structurées et tabulaires (pensez aux tables de base de données), de même que les tables de données intermédiaires générées lors du processus d'affinement des données brutes. Contrairement à la plupart des bases de données et des data warehouses, les data lakes peuvent traiter tous les types de données, y compris celles qui sont non structurées ou semi-structurées comme les images, les vidéos, l'audio et les documents. C'est une caractéristique essentielle pour les applications de machine learning et d'analytique avancée d'aujourd'hui.
Pourquoi utiliser un data lake ?
Tout d’abord, les data lakes sont des formats ouverts, ce qui évite aux utilisateurs d'être tributaires d’un système propriétaire tel qu'un data warehouse. Cet argument pèse de plus en plus lourd dans les architectures de données modernes. Les data lakes sont également très durables et économiques du fait de leur évolutivité et du recours au stockage d'objets. Rappelons également que l'analytique avancée et le machine learning sur les données non structurées font partie des priorités stratégiques des entreprises actuellement. Seuls capables d'ingérer des données brutes dans une variété de formats (structurés, non structurés, semi-structurés), les data lakes, avec tous les avantages que nous avons déjà mentionnés, sont une option privilégiée pour stockage des données.
Lorsqu'ils sont correctement architecturés, les data lakes permettent de :

Alimentez les applications de data science et de machine learning
Les data lakes permettent de transformer des données brutes en données structurées utilisables par vos activités d'analytique SQL, de data science et de machine learning avec une faible latence. Les données brutes peuvent être conservées indéfiniment à bas coût, en vue d'une utilisation ultérieure en machine learning et en analytique.

Centralisez, consolidez et cataloguez vos données
Un data lake centralisé élimine les problèmes liés au cloisonnement des données : duplication, démultiplication des politiques de sécurité, difficultés de collaboration, etc. Le résultat : un emplacement unique où les utilisateurs peuvent consulter toutes les sources de données.

Intégration rapide et transparente d'un large éventail de sources et de formats de données
Tous les types de données, sans exception, peuvent être collectés et conservés indéfiniment dans un data lake : données en batch et en streaming, vidéos, images, fichiers binaires et bien plus encore. Et comme le data lake sert également de destination aux nouvelles données, il est toujours à jour.

Démocratisez l'accès aux données grâce aux outils en libre-service
Incroyablement flexibles, les data lakes permettent à des utilisateurs disposant de compétences, d'outils et de langages très divers d'effectuer simultanément de nombreuses tâches d’analyse.
Les défis des data lakes
Malgré leurs avantages, l'absence de certaines fonctionnalités critiques a empêché les data lakes de tenir leurs promesses : pas de prise en charge des transactions ni d'application des règles de qualité ou de gouvernance des données, optimisation limitée des performances. Ce sont ces défauts qui ont transformé bien des data lakes d'entreprise en véritables marécages.
Problèmes de fiabilité
Sans les outils appropriés, les data lakes souffrent parfois de problèmes de fiabilité qui empêchent les data scientists et les analystes de raisonner efficacement sur les données. Ces problèmes découlent notamment de la difficulté à combiner les données en batch et en streaming et de la corruption des données, entre autres facteurs.
Problèmes de performance
Quand le volume des données d'un data lake augmente, les performances des moteurs de requête traditionnels ont toujours tendu à se dégrader. Parmi les goulets d'étranglement, citons la gestion des métadonnées, les problèmes de partitionnement, etc.
Manque de fonctionnalités de sécurité
Parce qu'ils donnent peu de visibilité et n'offrent pas la possibilité de supprimer ni mettre à jour les données, les data lakes sont difficiles à sécuriser et à gouverner correctement. Ces limites sont très problématiques lorsqu'il faut respecter les obligations des organismes de réglementation.
Pour ces raisons, le data lake traditionnel ne suffit pas à répondre aux besoins des entreprises qui cherchent à innover. Elles se retrouvent ainsi souvent contraintes d'exploiter des architectures complexes où les données sont cloisonnées dans différents systèmes de stockage : data warehouse, bases de données et autres systèmes d'entreprise. Simplifier cette architecture en unifiant toutes les données dans un data lake est donc une première étape pour les entreprises qui aspirent à exploiter la puissance du machine learning et de l'analytique pour assurer leur succès au cours de la prochaine décennie.
Le lakehouse, une réponse à ces défis
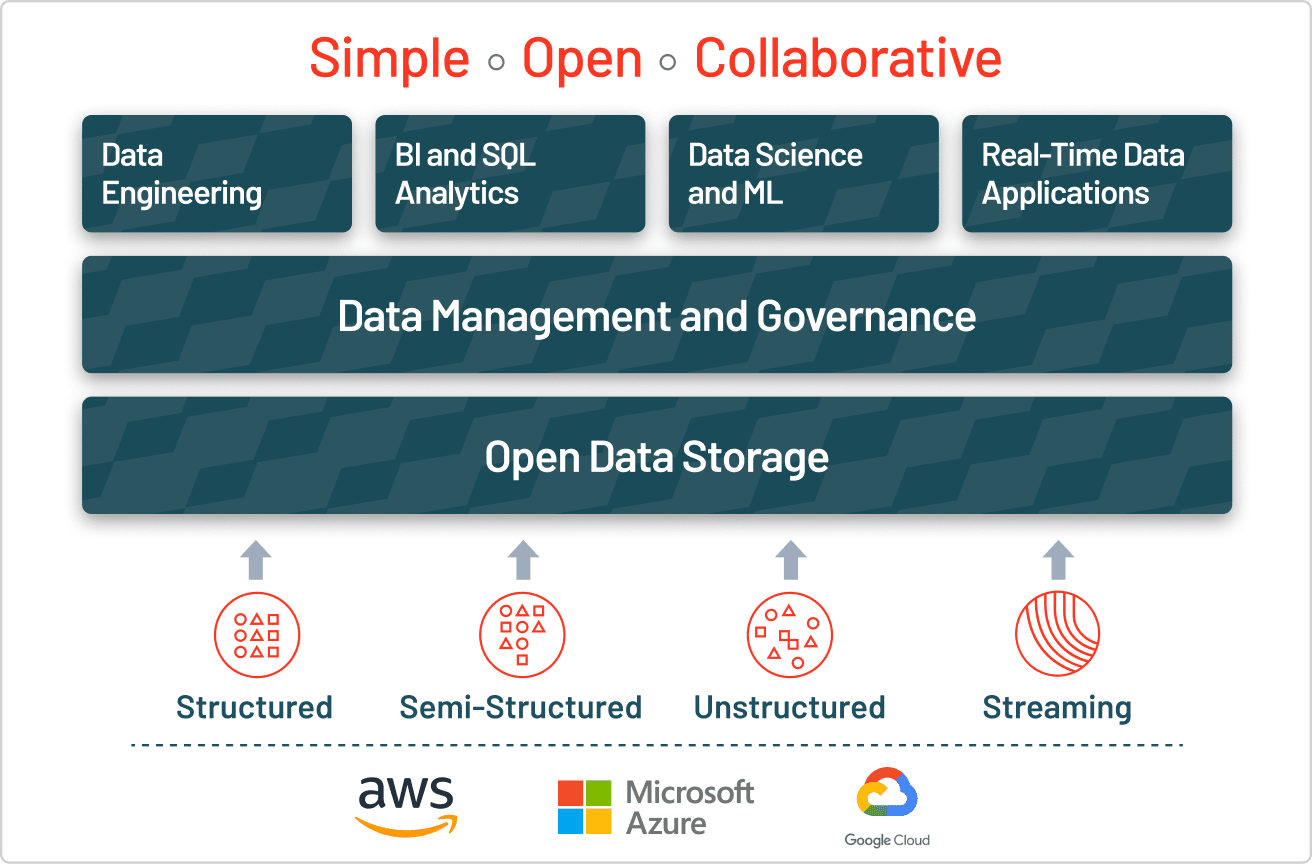
Le lakehouse apporte une solution aux limites du data lake en ajoutant une couche de stockage transactionnel. Un lakehouse utilise des structures de données et des fonctionnalités de gestion de données comparables à celles d'un data warehouse, mais il les exécute directement sur des data lakes dans le cloud. En fin de compte, le lakehouse permet de faire cohabiter l'analytique traditionnelle, la science des données et le machine learning dans le même système, le tout dans un format ouvert.
Un lakehouse ouvre la porte à de nombreux cas d'usage innovants dans le cadre de projets d'analytique, de BI et de machine learning couvrant toute l'entreprise et présentant un potentiel commercial considérable. Les data analysts interrogeront les données du data lake en SQL pour en extraire de précieux insights, les data scientists vont joindre et enrichir des données pour produire des modèles ML toujours plus précis et les data engineers développeront des pipelines ETL automatisés. Quant aux analystes de business intelligence, ils pourront élaborer des tableaux de bord visuels et des outils de reporting plus rapidement et plus facilement qu'auparavant. Ces cas d'utilisation peuvent tous être exécutés simultanément sur le data lake, sans déplacer les données, même avec l'afflux constant de nouvelles données.
Créer un lakehouse avec Delta Lake
Pour créer un lakehouse réussi, les organisations se sont tournées vers Delta Lake, une couche de gestion de données et de gouvernance au format ouvert qui combine le meilleur des data lakes et des data warehouses. Dans tous les secteurs d'activité, des entreprises misent sur Delta Lake pour optimiser la collaboration en l'adossant à une source de vérité unique et fiable. En garantissant la qualité, la fiabilité, la sécurité et les performances de votre data lake, aussi en streaming qu'en batch, Delta Lake élimine les silos de données et met l'analytique à la portée de toute l'entreprise. Avec Delta Lake, les clients peuvent créer un lakehouse économique et hautement évolutif qui libère des silos et offre aux utilisateurs finaux un accès en libre-service à l'analyse.
Data lakes, data lakehouses et data warehouses
| Data lake | Data Lakehouse | data warehouse | |
|---|---|---|---|
| Types de données | Tous les types : données structurées, semi-structurées et non structurées (brutes) | Tous les types : données structurées, semi-structurées et non structurées (brutes) | Données structurées uniquement |
| Coût | $ | $ | $$$ |
| Format | Format ouvert | Format ouvert | Format fermé, propriétaire |
| Évolutivité | Peut accueillir n'importe quelle quantité de données à faible coût, quel que soit leur type | Peut accueillir n'importe quelle quantité de données à faible coût, quel que soit leur type | Le coût de l'évolutivité augmente de façon exponentielle en raison des coûts des fournisseurs |
| Utilisateurs prévus | Limité : data scientists | Unifié : data analysts, data scientists, ingénieurs en machine learning | Limité : data analysts |
| Fiabilité | Faible qualité, « marécages » de données | Données fiables de haute qualité | Données fiables de haute qualité |
| Simplicité d'utilisation | Difficile : l'exploration de données brutes peut être difficile sans outils pour organiser et cataloguer les données | Simple : la simplicité et la structure du data warehouse sont mises au service des cas d'usage plus vastes du data lake | Simple : la structure du data warehouse permet aux utilisateurs d'accéder rapidement et facilement aux données à des fins de rapport et d'analytique |
| Performance | Médiocre | Haute | Haute |
En savoir plus sur les principaux défis des data lakes
Les bonnes pratiques des lakehouses
Utilisez le data lake comme destination pour toutes vos données
Enregistrez toutes vos données dans votre data lake sans les transformer ni les agréger : elles seront intactes pour vos applications de machine learning et de data lineage.
Masquez les données contenant des informations privées avant qu'elles n'entrent dans votre data lake
Les informations personnelles identifiables (IPI) doivent être pseudonymisées pour respecter les obligations du RGPD et permettre leur stockage à long terme.
Sécurisez votre data lake en appliquant des contrôles d'accès basés sur le rôle et les vues
Contrôlez la sécurité de votre data lake à l'aide des listes de contrôle d'accès (ACL), plus précises que le contrôle d'accès basé sur le rôle.
Renforcez la fiabilité et les performances de votre data lake avec Delta Lake.
Jusqu'à présent, il était difficile d'obtenir avec les big data le niveau de fiabilité et de performance offert par les bases de données. Delta Lake ajoute ces fonctionnalités essentielles aux data lakes.
Cataloguez les données de votre data lake
Utilisez les data catalogs et les outils de gestion des métadonnées au point d'ingestion pour mettre la data science et l'analytique en libre-service.