Polaires contre Pandas
Comparez le traitement parallèle haute performance de Polars avec l'API polyvalente de Pandas pour la manipulation de données basée sur les DataFrames.
- Comprendre les différences entre Polars et Pandas pour les opérations sur les DataFrames et les flux de travail d'analyse de données.
- Découvrir comment Polars utilise le traitement parallèle basé sur Rust et l'évaluation paresseuse pour des performances supérieures sur les grands ensembles de données.
- Savoir quand privilégier l'écosystème étendu et la flexibilité de Pandas plutôt que la vitesse et l'efficacité mémoire de Polars.
Introduction : Comprendre les options de bibliothèques DataFrame
Les DataFrames sont des structures de données bidimensionnelles, généralement des tableaux, similaires à des feuilles de calcul, qui vous permettent de stocker et de manipuler des données tabulaires en lignes d'observations et en colonnes de variables, ainsi que d'extraire des informations précieuses de l'ensemble de données donné. Les bibliothèques DataFrame sont des boîtes à outils logicielles qui fournissent une structure de type feuille de calcul pour travailler avec des données dans du code. Les bibliothèques DataFrame sont un élément essentiel d'une plateforme d'analyse de données car elles fournissent l'abstraction de base qui facilite le chargement, la manipulation, l'analyse et la compréhension des données, faisant le pont entre le stockage de données brutes et les outils d'analytique de plus haut niveau, de machine learning et de visualisation.
Polars et pandas sont les principales bibliothèques DataFrame de Python pour l'analyse et la manipulation de données, mais elles sont optimisées pour différents cas d'utilisation et échelles de travail.
Il s’agit d’une bibliothèque open source écrite pour le langage de programmation Python qui fournit des structures de données et des outils d’analyse de données rapides et adaptables. C'est la bibliothèque DataFrame la plus utilisée en Python. Elle est mature, riche en fonctionnalités et dispose d'un vaste écosystème avec de nombreuses intégrations. Pandas bénéficie d'une documentation complète, d'un soutien communautaire et de bibliothèques de traçage matures. Il est populaire pour les ensembles de données de petite et moyenne taille et l'analyse exploratoire.
Polars est une bibliothèque de DataFrame en colonnes rapide, basée sur Rust, avec une API Python. Il est conçu pour la vitesse, avec un parallélisme intégré et une « exécution paresseuse » (non exécutée immédiatement) pour les charges de travail qui dépassent la mémoire.
Selon vos besoins en matière de traitement des données, Pandas convient parfaitement à la Data Science sur des datasets contenant jusqu'à quelques millions de lignes. Si vous effectuez de l'ETL, de l'analytique ou si vous travaillez sur des tables volumineuses, Polars est généralement plus efficace.
Quand utiliser pandas pour votre workflow
Pandas excelle lorsque la flexibilité, la vitesse d'itération et la compatibilité avec l'écosystème sont plus importantes que la montée en charge extrême. C'est la bibliothèque DataFrame standard de facto. Elle privilégie la flexibilité et offre des intégrations profondes avec Scikit-learn. NumPy, Matplotlib, statsmodels et de nombreux outils de machine learning.
Elle fonctionne avec les bases de code existantes et est familière aux équipes de traitement de données qui l'utilisent pour l'analyse interactive et le travail exploratoire sur les données où la flexibilité est la plus importante. Son format basé sur les lignes excelle pour les datasets de petite à moyenne taille pour l'analyse ad-hoc, les workflows basés sur des Notebooks et le prototypage rapide.
Avec pandas, vous pouvez exécuter n'importe quelle fonction Python, tandis que Polars déconseille fortement l'exécution arbitraire de code Python. Avec pandas, les modifications en place et l'édition pas à pas sont normales, ce qui permet aux utilisateurs de modifier l'état au fil du temps. Avec Polars, les DataFrames sont de fait immuables.
Vous pouvez exécuter l’API Pandas sur Apache Spark 3.2 pour répartir équitablement les charges de travail et garantir un traitement adéquat des données.
Pour l'analyse exploratoire des données, pandas fournit des opérations rapides et interactives, un slicing/filtrage/regroupement facile et des inspections visuelles rapides. Elle est souvent utilisée pour la validation/l'audit des données et le nettoyage des données brutes pour les valeurs manquantes, les formats incohérents, les doublons ou les types de données mixtes.
Pour l'analytique commerciale et le reporting où les équipes de données doivent générer des métriques sur une échelle de temps définie, pandas simplifie le regroupement et l'agrégation avec un remodelage facile, et exporte directement vers CSV/Excel.
Lorsque les équipes de data science préparent des données pour les modèles de ML, pandas facilite l'expérimentation grâce à une création naturelle de caractéristiques (features) basée sur les colonnes et à une intégration étroite avec scikit-learn. Il est souvent utilisé pour le prototypage rapide et les preuves de concept avant d'écrire la logique dans SQL, Spark ou les pipelines de production.
Même les équipes financières et les équipes commerciales non techniques utilisent pandas pour automatiser les flux de travail basés sur Excel.
En savoir plus :
Travailler avec les DataFrames pandas
Apprendre l'analyse de données avec pandas
Quand utiliser Polars pour votre workflow
Polars brille lorsque les performances, l'évolutivité et la fiabilité sont plus importantes que la flexibilité ad hoc. Grâce à son moteur Rust, au multithreading, au modèle de mémoire en colonnes et au moteur d'exécution différée, Polars peut gérer des charges de travail ETL étonnamment importantes sur une seule machine où l'efficacité de la mémoire est essentielle. L'exécution paresseuse signifie que les opérations ne sont pas exécutées immédiatement, mais sont enregistrées, optimisées et exécutées uniquement lorsqu'un résultat est explicitement demandé. Cela peut entraîner d'énormes gains de performance, car il crée un plan d'exécution optimisé au lieu d'effectuer chaque opération étape par étape. Les transformations de données sont d'abord planifiées, puis exécutées, ce qui permet au système d'optimiser l'ensemble du pipeline pour une vitesse et une efficacité maximales.
Pour les pipelines de données de production nécessitant des performances élevées et constantes et des flux de travail critiques en termes de vitesse, Polars est multithread par default pour tirer parti de tous les cœurs de CPU disponibles et traiter chaque bloc du DataFrame sur un thread différent. Cela le rend considérablement plus rapide que les bibliothèques de DataFrame monothread traditionnelles comme pandas.
Lors de l'exécution de jointures sur des dizaines de millions de lignes, comme la jonction de logs de flux de clics avec des métadonnées utilisateur, les jointures de Polars sont multithread et les données en colonnes réduisent les copies de mémoire inutiles.
Pour les scénarios d'utilisation impliquant des datasets volumineux, des Transformations complexes ou des pipelines à plusieurs étapes, Polars bénéficie du traitement parallèle, où chaque ligne peut être traitée indépendamment, en répartissant les Opérations de jointure sur plusieurs cœurs et en effectuant le partitionnement par hachage en parallèle. Pour les pipelines de query en plusieurs étapes avec de nombreuses Transformations, Polars peut optimiser et exécuter l'ensemble du pipeline en parallèle. L'utilisation du streaming parallèle et de l'évaluation paresseuse permet à Polars de traiter des datasets plus volumineux que la RAM. Le traitement parallèle et l'évaluation paresseuse facilitent également les opérations d'analyse de fichiers volumineux (fichiers CSV/Parquet).
Polars obtient également des avantages de performance majeurs en utilisant le stockage en colonnes basé sur Apache Arrow pour l'optimisation des requêtes. Dans le stockage en colonnes, les données sont stockées colonne par colonne, et non ligne par ligne. Cela permet à Polars de ne lire que les colonnes requises, minimisant les E/S disque et l'accès à la mémoire, ce qui le rend plus efficace pour le traitement analytique. Il peut fonctionner directement sur les tampons de mémoire continue d'Apache Arrow sans copier les données.
Si vous effectuez de la Data Engineering de fonctionnalités ML et de l'exploration sur des datasets extrêmement volumineux, des jointures de grandes tables de faits, de lourdes agrégations et de l'analytique OLAP, des charges de travail sur des séries temporelles, l'analyse de fichiers massifs, du traitement de données plus grandes que la mémoire et du traitement batch avec des SLA stricts, Polars pourrait être le meilleur choix.
- Link: Apache Spark (ancre : traitement distribué des données)
- Lien interne: pipelines de données (ancre : création de pipelines de données évolutifs)
Représentation et architecture des données
Les modèles de représentation des données et les architectures de pandas et de Polars diffèrent intentionnellement. Le stockage par ligne utilisé par pandas stocke des lignes complètes de manière continue en mémoire, tandis que le stockage colonnaire de Polars stocke chaque colonne de manière contiguë. Chaque méthode peut influencer les performances, selon les types de requêtes que vous exécutez.
Pour les requêtes analytiques, le stockage en colonnes offre généralement de meilleures performances, car la requête n'a besoin que d'accéder aux colonnes nécessaires, tandis que les stockages en lignes doivent lire des lignes complètes.
Les colonnes ont des types uniformes, ce qui permet d'obtenir de meilleurs taux de compression, et la vectorisation permet un traitement batch rapide.
Pour les requêtes transactionnelles, telles que les charges de travail OLTP, le stockage basé sur les lignes est préférable, car une ligne entière est stockée ensemble, de sorte que la récupération d'un enregistrement complet ne nécessite qu'une seule lecture et que la mise à jour d'une ligne ne modifie qu'une seule région compacte de la mémoire.
Les graphiques ci-dessous montrent les ratios de performance moyens comparant les bibliothèques de DataFrame orientées lignes et orientées colonnes (dans ce cas, Koalas et Dask).
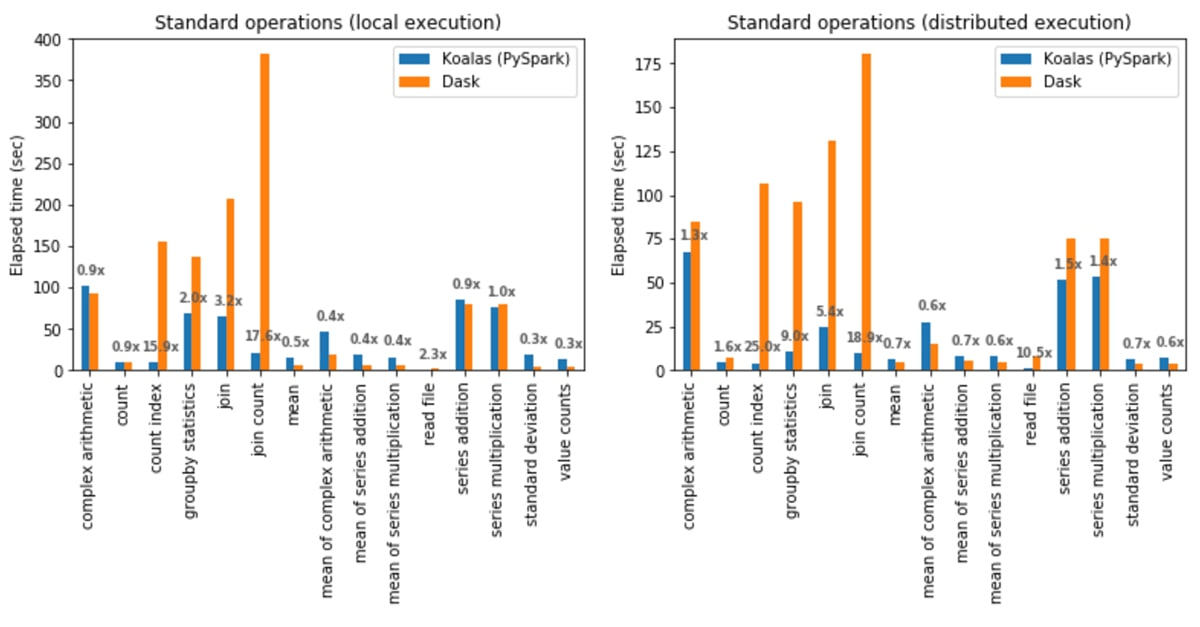
Le format colonnaire de Polars permet des agrégations plus rapides. Comme chaque colonne est stockée de manière contiguë en mémoire, il peut streamer une seule colonne sans analyser les données non liées et il parallélise les agrégations sur les cœurs du processeur. Pour les grands datasets, le stockage en colonnes réduit la pression sur la RAM, car il ne lit que les colonnes nécessaires à la query.
Le layout en colonnes dans Polars permet une exécution vectorisée utilisant Apache Arrow, autorisant le Zero-copy Data Sharing. Polars peut effectuer des filtrages et des découpages sans copier les tampons de données sous-jacents.
Le modèle de stockage en lignes utilisé par pandas signifie que chaque ligne d'un DataFrame est stockée comme une collection d'objets Python regroupés. Ce modèle est optimisé pour les opérations qui récupèrent ou modifient des enregistrements complets. Il peut récupérer toutes les données d'un enregistrement en une seule recherche, ce qui le rend plus adapté à de nombreuses petites opérations à charge de travail mixte plutôt qu'à de grands vecteurs. Il prend en charge les types de données hétérogènes tels que les objets Python, les chaînes de caractères, les nombres, les listes et les données imbriquées. Une telle flexibilité est utile pour les données désordonnées du monde réel, les enregistrements JSON dans des fichiers CSV et les ensembles de caractéristiques de types mixtes.
Pour les queries qui nécessitent d'accéder à de nombreuses ou à toutes les colonnes pour une seule ligne, comme la récupération d'enregistrements au niveau de l'utilisateur et la sérialisation de données au niveau de la ligne pour les APIs, pandas n'a pas besoin de reconstruire la ligne en accédant à plusieurs tampons de colonne. Il est également plus rapide pour les charges de travail avec des mutations fréquentes, car il permet la mutation sur place des cellules du DataFrame.
Lorsque les données tiennent facilement en mémoire, pandas est très pratique et offre des performances suffisamment rapides pour les datasets de petite à moyenne taille.
Performance : Évaluation de la vitesse et de l'utilisation des ressources
Polars est généralement plus rapide et plus économe en Ressources que pandas, en particulier pour le travail de type Data Engineering et à mesure que le volume et la complexité des données augmentent. Polars est colonnaire, multithread par défaut et peut exécuter des plans de requête paresseux/optimisés. Pandas est principalement monothread pour les opérations sur les DataFrames et utilise l'évaluation immédiate où chaque ligne s'exécute immédiatement et matérialise les DataFrames intermédiaires. Pandas peut être plus rapide sur de petits ensembles de données et pour certaines opérations vectorisées simples, et il est plus flexible, mais cette flexibilité peut coûter en CPU/mémoire.
Le Graphe ci-dessous montre comment le nombre de threads peut impacter les performances.
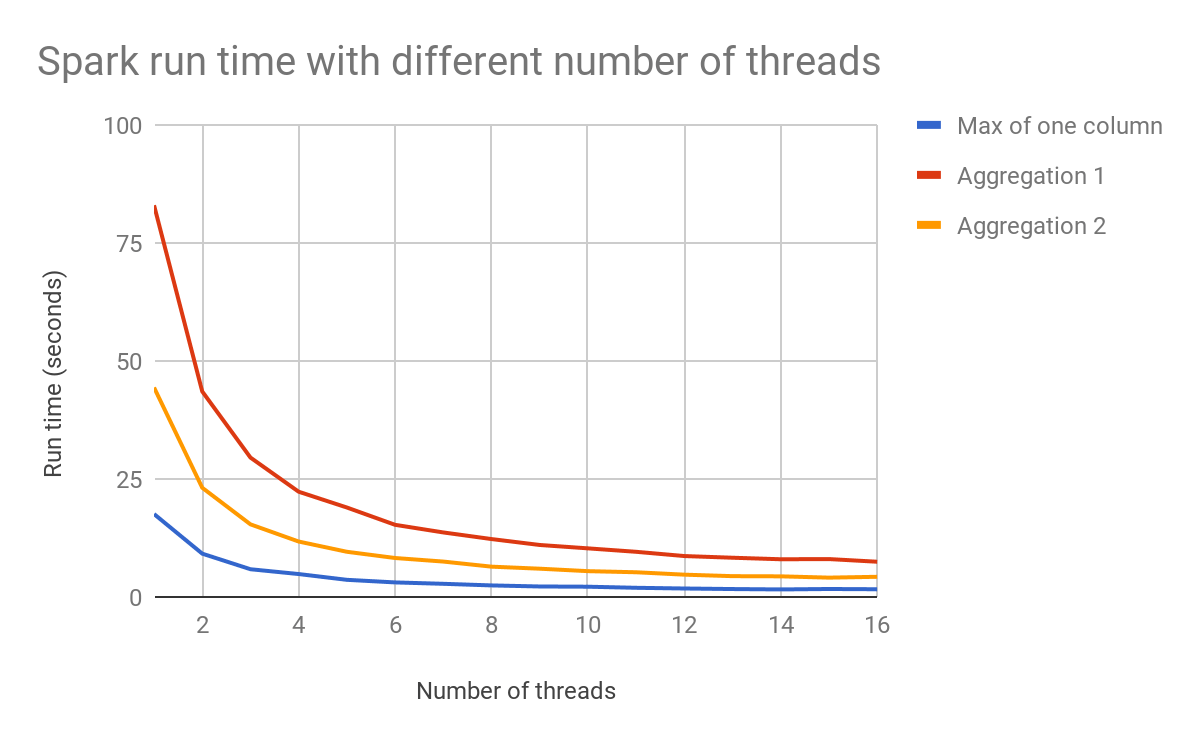
Avec le planificateur de requêtes et l'optimiseur LazyFrame de Polars, votre code crée d'abord un plan de requête, puis Polars optimise le plan et l'exécute lorsque vous le lui demandez. Cela seul explique la plupart des avantages de Polars en matière de vitesse et d'utilisation de la mémoire.
Dans pandas, l'évaluation immédiate (eager evaluation) signifie qu'il calcule immédiatement, crée un objet intermédiaire en mémoire, puis transmet cet intermédiaire à l'étape suivante. Vous perdez donc en vitesse lors de plusieurs passages sur les données (créant souvent plusieurs intermédiaires de taille complète). Comme pandas ne peut pas voir l'ensemble du pipeline, il ne peut pas l'optimiser globalement. Mais pandas est performant lorsque les données tiennent confortablement en mémoire, lorsque les opérations sont petites et interactives, et lorsque vous souhaitez un retour immédiat après chaque ligne. En règle générale, choisissez pandas lorsque :
- vous effectuez une EDA rapide
- les datasets sont de petite ou moyenne taille
- vous souhaitez une inspection et un débogage pas à pas
- votre logique est du Python hautement personnalisé (ligne par ligne)
Choisissez Polars lorsque:
- vous effectuez des pipelines ETL/analytiques reproductibles
- Les datasets sont volumineux ou larges
- vous lisez beaucoup de fichiers Parquet/Arrow
- vous vous souciez de la vitesse, de la mémoire et d'un nombre réduit de copies intermédiaires
En raison de leurs différences philosophiques (pandas est conçu pour la flexibilité et Polars pour la vitesse), les deux bibliothèques gèrent différemment les données manquantes et les valeurs nulles, ce qui peut également avoir un impact sur les performances.
Pandas peut traiter plusieurs valeurs différentes comme « manquantes », ce qui le rend flexible mais parfois incohérent et peut ralentir les opérations en raison de la gestion des objets Python. Polars utilise « null » comme seule valeur manquante pour tous les types de données afin de correspondre étroitement à la sémantique SQL, ce qui est plus rapide et plus économe en mémoire à grande échelle.
Comme le montre le Graphe ci-dessous, qui présente des comparaisons de temps d'exécution pour des flux de travail représentatifs, lorsque pandas est contraint d'effectuer une exécution au niveau de Python (ligne par ligne) sur de grands jeux de données, il crée de nombreuses copies intermédiaires et les Opérations ralentissent.
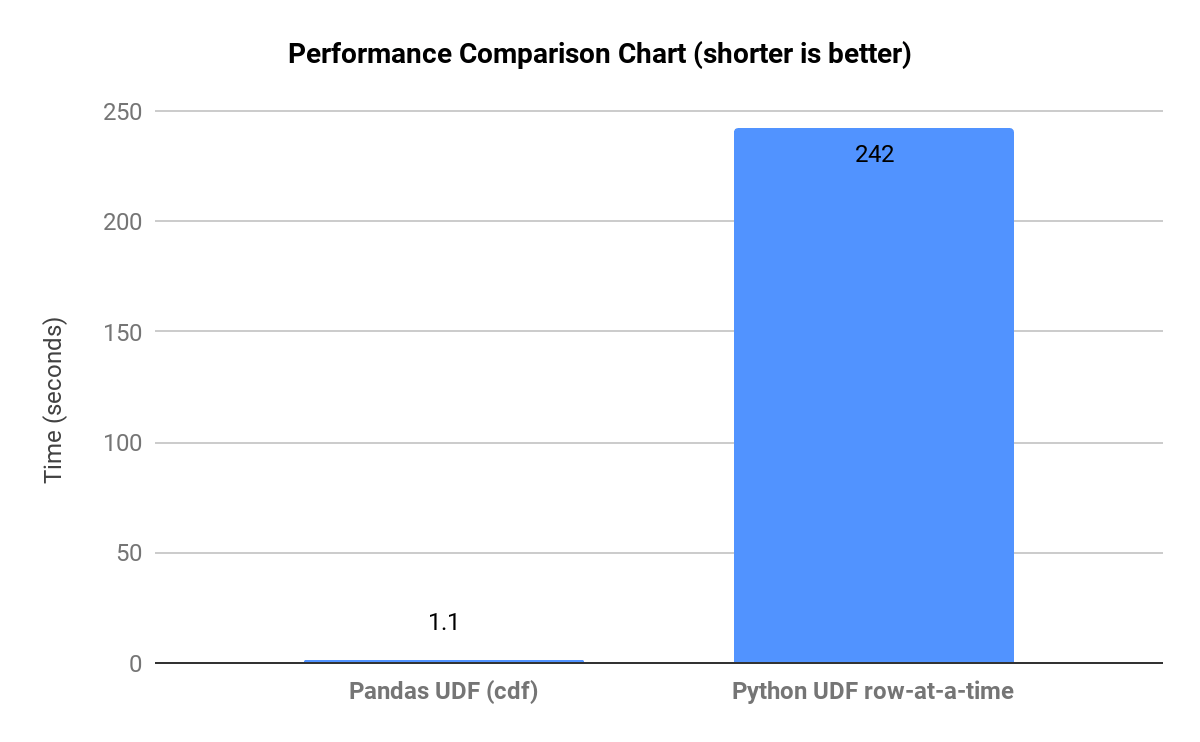
Polars peut également rencontrer des goulots d'étranglement en matière de performances lorsqu'il interrompt la vectorisation et emp�êche l'optimisation des requêtes, ou lorsque le mode paresseux (lazy mode) n'est pas utilisé pour les grands pipelines. L'optimisation de Polars peut également être mise à mal par de très grandes jointures plusieurs-à-plusieurs (many-to-many).
Le Graphe ci-dessous montre la consommation de mémoire de pandas augmentant de manière linéaire avec la taille des données.
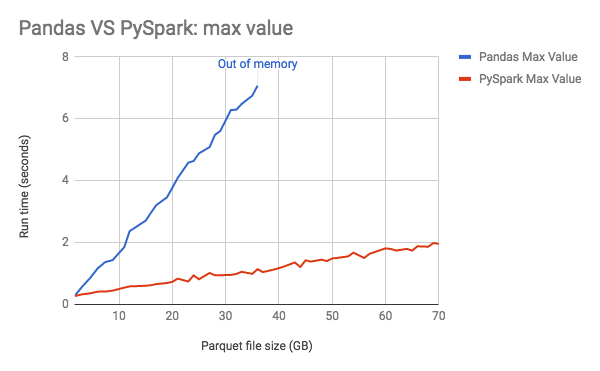
Conseils sur les performances :
- Si votre charge de travail consiste à effectuer des opérations groupby/join/scan sur de gros fichiers Parquet, Polars l'emporte généralement.
- Si votre flux de travail est une EDA interactive avec beaucoup de logique Python personnalisée, pandas est souvent plus pratique.
Benchmarking
Pour comprendre les différences de performances, voici quelques approches de benchmarking que vous pouvez mettre en œuvre :
Ad hoc rapide
- Utilisez
time.perf_counter()pour le temps horloge - Répéter plusieurs fois
- Rapport
médiane/p95
Microbenchmarks reproductibles (pour une équipe / des PR)
- Utilisez
pytest-benchmarkouasv - Exécuter sur une machine stable (ou un runner CI épinglé)
- Enregistrer les résultats entre les commits
Benchmarking de type production (le plus significatif)
- Forme & taille du jeu de données réel
- Exécutions avec cache froid ou chaud
- Chronométrage du pipeline de bout en bout
- Suivi de la mémoire + du CPU
Pour que les comparaisons soient équitables, utilisez le même format d'entrée, faites correspondre les types de données, utilisez les mêmes regroupements, clés, sorties et contrôlez le threading (comportement par défaut ou comparaison cœur à cœur).
- Lorsque les différences de performances sont les plus importantes pour des cas d'utilisation particuliers
- Améliorations moyennes réelles du temps d'exécution avec Polars sur de grands datasets
Gestion des données manquantes et des types de données
La manière dont une bibliothèque DataFrame gère les données manquantes et les types de données affecte l'exactitude, la qualité des données, les performances et la facilité d'utilisation. Pandas offre une gestion flexible mais parfois incohérente des données manquantes et des dtypes, tandis que Polars impose un modèle nul unique avec un typage fort, ce qui conduit à un comportement plus sûr, plus rapide et plus prévisible, en particulier à grande échelle.
Le modèle de données manquantes de pandas traite plusieurs valeurs (NaN (flottant), None, NaT (datetime), pd.NA (scalaire nullable)) comme des valeurs manquantes. Cela favorise la flexibilité, mais peut être incohérent lorsque différents types de données gèrent les données manquantes différemment. Lors du remplissage des valeurs manquantes, pandas peut modifier le type de données de manière inattendue. La sémantique ambiguë des valeurs nulles rend plus difficile pour pandas la détection des problèmes de qualité des données.
Polars utilise une seule valeur manquante (nulle), adopte le même comportement pour tous les types de données, et tous les types de données peuvent être nuls par défaut. Cela produit généralement un comportement prévisible et de meilleures performances. Lors du remplissage avec des valeurs manquantes, Polars est explicite et préserve le type de données. La gestion cohérente des valeurs nulles par Polars entraîne généralement moins d'erreurs de qualité des données.
Il y a également des considérations sur la manière dont les différents modèles de mémoire affectent les conversions de types de données et l'interopérabilité. Historiquement, pandas s'appuie sur NumPy (orienté ligne, objets Python pouvant contenir des types de données mixtes) tandis que Polars est colonnaire natif Arrow, ce qui simplifie son intégration au reste de la stack de données Python.
Voici quelques bonnes pratiques pour maintenir l'intégrité des données lors de l'utilisation des deux bibliothèques de DataFrame :
- Pour les deux bibliothèques…
Appliquez l'unicité et les contraintes clés de la base de données telles que l'unicité de la clé primaire, la validité de la clé étrangère et le nombre de lignes/partitions attendu. Validez les jointures pour éviter les explosions silencieuses de lignes. Utilisez des transformations cohérentes et déterministes : elles sont beaucoup plus faciles à tester et à reproduire. Stockez les données « source de vérité » au format Parquet avec un schéma stable pour préserver les types. Et n'attendez pas la fin pour valider. Validez aux points clés, par exemple après l'ingestion, après les transformations majeures et après la publication.
- Avec pandas…
Définissez explicitement les types de données au moment de la lecture chaque fois que possible, et préférez les types de données pouvant être nuls tels que Int64, boolean, string ou datetime64[ns] afin que pandas ne se rabatte pas sur le type object. Normalisez les valeurs manquantes le plus tôt possible et faites attention aux problèmes silencieux tels que NaN == NaN. Évitez l'indexation en chaîne et les opérations par ligne pour la logique principale.
- Avec Polars…
Définissez explicitement le schéma et les types de données et fiez-vous au typage strict de Polars. Utilisez null de manière cohérente et préférez la gestion des nuls basée sur les expressions.
Transitions de syntaxe et d'API
- Différences fondamentales d'API : chaînage Polars vs opérations pandas
- Avec Polars, vous construisez généralement un seul pipeline chaîné basé sur des expressions, et en mode paresseux, Polars peut optimiser toute la chaîne. Dans pandas, vous écrivez souvent une séquence d'instructions qui mutent selon la méthode « eager » (pas à pas).
- Exemples de code côte à côte : filtrage, regroupement, agrégations
- Filtrage et sélection (chaînage)
- Pandas
- Filtrage et sélection (chaînage)
result = pdf[pdf["country"] == "US"][["user_id", "revenue"]]
- Polars
result = (
pldf
.filter(pl.col("country") == "US")
.select(["user_id", "revenue"])
)
- Regroupement et agrégation :
- Pandas
rev_by_user = (
pdf
.groupby("user_id", as_index=False)["revenue"]
.sum()
)
- Polars
rev_by_user = (
pldf
.group_by("user_id")
.agg(pl.col("revenue").sum())
)
Principes fondamentaux de la syntaxe Polars :
Deux concepts sont particulièrement importants lors de l'apprentissage de Polars : les expressions et l'exécution différée (lazy) par rapport à l'exécution immédiate (eager). Polars est construit autour des expressions, un calcul par colonne (similaire à SQL) qui décrit ce que vous voulez calculer et un moteur qui décide comment le calculer efficacement. Les expressions ne sont pas exécutées immédiatement. Elles sont les éléments de base du mode de fonctionnement « paresseux » où les Opérations construisent un plan de query et les exécutions ne se produisent que lorsque vous les appelez.
Inversement, en mode eager (comportement de pandas), les Opérations s'exécutent immédiatement, ce qui est pratique pour l'exploration et le debugging, mais ralentit les pipelines à grande échelle. Polars peut offrir une exécution eager pour l'interactivité et une exécution lazy pour des pipelines optimisés à grande échelle.
Conversion du code Pandas existant en Polars
La conversion signifie généralement :
- remplacer l'indexation de lignes/colonnes
df[...]par.filter()/.select() - remplacer l'assignation en place par
.with_columns() - remplacer
.apply()avec des expressions natives (chaque fois que possible) - envisagez le mode paresseux pour l'ETL basé sur des fichiers
Exemple de conversion :
Pandas d'origine :
df = pd.read_parquet("events.parquet")
df = df[df["country"] == "US"][["user_id", "revenue", "ts"]]
df["revenue"] = df["revenue"].fillna(0)
df["day"] = pd.to_datetime(df["ts"]).dt.date
)
out = (
df.groupby(["user_id", "day"], as_index=False)
.agg(total_revenue=("revenue", "sum"))
Optimisation lazy de Polars :
import polars as pl
out = (
pl.scan_parquet("events.parquet")
.filter(pl.col("country") == "US")
.select(["user_id", "revenue", "ts"])
.with_columns([
pl.col("revenue").fill_null(0),
pl.col("ts").dt.date().alias("day"),
])
.group_by(["user_id", "day"])
.agg(pl.col("revenue").sum().alias("total_revenue"))
.collect()
)
Lorsqu'une équipe change de bibliothèques de données (par exemple, en passant de pandas à Polars, ou en ajoutant Polars à côté de pandas), la courbe d'apprentissage concerne moins la syntaxe que la mentalité, les flux de travail et la gestion des risques. L'état d'esprit de pandas est impératif, pas à pas, avec des mutations au fur et à mesure et une inspection après chaque ligne. La mentalité de Polars est déclarative, basée sur des expressions où les transformations sont construites comme des pipelines avec des données immuables et qui utilise une planification de requêtes de type SQL.
Le défi d'apprentissage est de start à penser en termes de colonnes (column-wise) et de manière déclarative, plutôt que ligne par ligne (row-by-row). Les habitudes de debugging et d'inspection doivent changer : pensez en termes de Transformations, pas d'états.
Avec Polars, la rigueur des types de données peut sembler hostile lorsqu'elle impose la cohérence du schéma et échoue rapidement sur les problèmes de type de données, mais ces échecs empêchent les bugs silencieux de qualité des données. Le défi est de traiter les erreurs de type de données comme des signaux de qualité des données, et non comme des désagréments.
Les équipes peuvent également ressentir des lacunes en matière d'outillage en passant à Polars, car presque tous les outils de données Python acceptent pandas et il existe un vaste écosystème pandas avec de la documentation. Envisagez une approche hybride lorsque des outils existants sont nécessaires : concentrez-vous sur Polars pour la préparation de données lourdes et sur pandas pour la modélisation et la création de graphiques.
Il existe des couches de compatibilité d'API pour réutiliser du code DataFrame de type pandas par-dessus Polars. Ces adaptateurs prennent en charge les mêmes noms de méthodes/signatures que pandas avec des comportements similaires et peuvent traduire les appels en opérations natives de Polars. Mais attention, une couche d'API n'est pas une conversion, et elle peut introduire des lacunes sémantiques et masquer des pièges de performance.
Voici quelques modèles de refactorisation et stratégies de migration courants lors du passage d'une pile DataFrame à une autre.
Modèles de refactorisation courants (de pandas à Polars) :
Remplacez l'indexation booléenne par .filter() et .select()
- pandas
df2 = df[df["x"] > 0][["id", "x"]]
- Polars
df2 = df.filter(pl.col("x") > 0).select(["id", "x"])
Remplacer la mutation sur place par .with_columns()
- Pandas
df["y"] = df["x"] * 2
- Polars
df = df.with_columns((pl.col("x") * 2).alias("y"))
Remplacer np.where / l'affectation conditionnelle par when/then/otherwise
- Pandas
df["tier"] = np.where(df["revenue"] ">= 100, "high", "low")
- Polars
df = df.with_columns(
pl.when(pl.col("revenue") >= 100).then("high").otherwise("low").alias("tier")
)
- Réécrire les agrégations groupby en .agg(...) basé sur des expressions
- Pandas
out = df.groupby("k", as_index=False).agg(total=("v","sum"), users=("id","nunique"))
- Polars
out = df.group_by("k").agg(
pl.col("v").sum().alias("total"),
pl.col("id").n_unique().alias("users"),
)
Préférez les analyses paresseuses pour l'ETL basé sur des fichiers
- Pandas
df = pd.read_parquet("events.parquet")
- Polars
out = (
.scan_parquet("events.parquet")
.filter(pl.col("country") == "US")
.select(["user_id","revenue"])
.group_by("user_id")
.agg(pl.col("revenue").sum().alias("rev"))
.collect()
)
Remplacer .apply() par des expressions natives (ou isoler les UDF)
- Pandas
La plupart des migrations pandas bloquent sur .apply(axis=1)
- Polars
Essayez de l'exprimer avec les expressions Polars (str.*, dt.*, list.*, when/then).
Si cela est inévitable, isolez une UDF à une petite colonne/un petit sous-ensemble et spécifiez return_dtype.
- Link interne: Programmation Python (ancre : Python pour l'analyse de données)
Le guide pratique de l'IA agentique pour l'entreprise

Intégration et compatibilité de l'écosystème
Polars et pandas sont conçus pour fonctionner ensemble, mais ils sont construits sur des modèles d'exécution et de types différents. L'interopérabilité existe via des points de conversion explicites, et non des composants internes partagés. Comme les deux bibliothèques peuvent utiliser Apache Arrow, Arrow peut être une couche d'interopérabilité clé, permettant un transfert en colonnes efficace et une meilleure préservation du schéma.
- Utiliser les tables Parquet ou Arrow comme format d'échange
- Éviter le format CSV pour les workflows inter-bibliothèques
L'interopérabilité est explicite et intentionnelle. Il n'y a pas de moteur d'exécution partagé ni de sémantique d'index. Il n'y a également aucune garantie de copie zéro (zero-copy). Validez toujours.
Conversion de données entre les formats : to_pandas() et import polars :
- de pandas à Polars
- les colonnes pandas sont converties en types Polars compatibles avec Arrow
- L'Index de pandas est supprimé à moins que vous ne le réinitialisiez.
- les colonnes d'objet sont inspectées et contraintes (souvent en Utf8 ou en erreur)
- Bonnes pratiques
- Appelez
pd_df.reset_index()si l'index est important - Normaliser d'abord les dtypes :
- utiliser string, Int64, boolean
- évitez les colonnes d'objets de types mixtes
- Appelez
- De Polars à pandas
- Les colonnes Polars sont converties en pandas (souvent soutenues par Arrow si disponible)
- Un RangeIndex par défaut est créé
- Les valeurs nulles sont mappées sur les représentations des valeurs manquantes de pandas
- Bonnes pratiques
- Convertissez une seule fois à la frontière, et non de manière répétée
- Valider les dtypes après la conversion (en particulier les entiers et les valeurs nulles)
- Règle générale : convertissez aux limites du workflow, pas à l'intérieur des boucles ou des chemins critiques.
Lors de l'intégration avec des bibliothèques de visualisation et des outils de traçage, la plupart des bibliothèques de traçage Python attendent des objets pandas (ou des tableaux NumPy). Polars s'intègre bien, mais vous devrez souvent convertir en pandas au moment de la création du graphique, ou passer directement des tableaux/colonnes.
Pour la connectivité aux bases de données et la prise en charge des formats de fichiers, pandas est idéal pour les lectures ad hoc et la compatibilité avec l'écosystème. Polars est idéal pour les fichiers volumineux, Parquet et les analytiques centrées sur les fichiers. Pandas prend en charge PostgreSQL, MySQL, SQL Server, Oracle, SQLite et toute base de données dotée d'un driver SQLAlchemy. Polars n'est pas un client de base de données complet. Il s'attend à recevoir les données sous forme de fichiers ou de tables Arrow. Certaines bases de données et certains outils peuvent générer directement des données au format Arrow, que Polars peut ingérer efficacement.
Les deux prennent en charge l'analyse des CSV. Polars est très rapide avec une surcharge mémoire plus faible, tandis que pandas dispose d'une analyse très flexible et gère bien les CSV désordonnés, mais l'analyse a tendance à être gourmande en CPU et l'utilisation de la mémoire peut grimper en flèche.
Polars est meilleur pour Parquet. Pandas peut lire Parquet, mais les opérations sont uniquement immédiates avec une optimisation pushdown limitée par rapport à Polars. Avec l'exécution en streaming et un moteur colonnaire natif Arrow, Polars peut produire des résultats avec des accélérations de plusieurs ordres de grandeur sur de grands datasets.
L'intégration et la compatibilité des bibliothèques de machine learning (ML) sont l'un des facteurs pratiques les plus importants pour choisir entre pandas et Polars ou pour utiliser les deux. La plupart des bibliothèques de ML attendent des tableaux NumPy (X : np.ndarray, y : np.ndarray), des DataFrames/Series pandas (courants dans les flux de travail sklearn) ou Arrow. De nombreuses bibliothèques considèrent pandas comme le conteneur tabulaire par défaut. Donc, si votre stack ML est principalement composée de sklearn et de son écosystème, pandas reste la voie la plus simple.
La plupart des bibliothèques de ML n'acceptent pas encore directement les DataFrames Polars comme entrées de première classe. Polars est excellent pour le feature engineering, mais prévoyez une conversion à la frontière. Il est recommandé d'effectuer la préparation lourde des données dans Polars et de convertir en pandas ou NumPy pour l'entraînement et l'inférence du modèle.
Voici une liste de contrôle rapide pour l'injection de données dans le ML :
- Pas de colonnes de types mixtes
- Toutes les caractéristiques sont numériques ou encodées
- Gestion des valeurs nulles (modèle d'imputation/suppression/prise en compte des valeurs manquantes)
- Ordre des caractéristiques stable
- Noms des caractéristiques préservés (si nécessaire)
- Validation du schéma d'entraînement/d'inférence en place
Considérations pour la production
Lorsque vous déplacez des charges de travail pandas ou Polars des Notebooks vers la production, les pièges concernent généralement moins la syntaxe que l'exécution, le packaging, la prévisibilité des performances et l'opérabilité. Valider le comportement sous les limites réelles de mémoire/CPU de votre cible de déploiement. Choisissez des stratégies comme l'élagage de colonnes, le filtrage précoce et les analyses en streaming/paresseuses pour les charges de travail basées sur des fichiers.
Pour l'exécution et le packaging, assurez-vous que votre version de Python de production correspond à celle que vous testez localement. Polars livre du code natif (Rust) et pandas dépend de NumPy ou de moteurs optionnels comme PyArrow et fastparquet. Parquet/Arrow est généralement la meilleure solution pour la production, offrant une meilleure stabilité de schéma, des lectures plus rapides et moins de surprises au niveau des types de données que le CSV.
Polars utilise le multi-threading par défaut. Envisagez de définir/contrôler l'utilisation des threads via la configuration de l'environnement en production. L'optimisation paresseuse de Polars peut améliorer le throughput, mais les très petits jobs pourraient subir une surcharge de planification.
Les pipelines de production doivent appliquer explicitement les types de données et les attentes de nullité (les deux bibliothèques vous demandent d'affirmer les contraintes). Ajoutez des vérifications autour des jointures pour éviter les explosions silencieuses de lignes.
Pour l'observabilité, suivez le temps d'exécution, le nombre de lignes, le nombre de valeurs nulles pour les colonnes clés et la taille des sorties par exécution. Ajouter des vérifications de type « stop-the-line » aux limites (avant de publier les sorties). Et assurez-vous que les erreurs apparaissent avec un contexte exploitable (quelle partition/fichier/table, quelle vérification a échoué).
Validez les résultats (nombre de lignes, agrégats, taux de nuls) et les budgets de performance (seuils de temps/mémoire). Exécutez les tests dans des conteneurs qui correspondent à l'OS/glibc de production pour éviter les surprises liées aux wheels natifs.
Stratégies de migration pratiques
Stratégies de migration pour faire passer une équipe de pandas à Polars ou pour adopter Polars en parallèle de pandas :
- Strangler pattern – Lorsque vous avez besoin d'un faible risque et d'une livraison continue, remplacez un segment à la fois par Polars tout en gardant l'ancien pandas en cours d'exécution. Convertissez aux limites.
- Utilisez les deux – Lorsque votre goulot d'étranglement est l'ETL/l'agrégation mais que vous dépendez d'outils natifs de pandas en aval, utilisez Polars pour les jointures E/S, les groupbys et le calcul de caractéristiques ; convertissez le résultat final en pandas pour scikit-learn, la création de graphiques et les bibliothèques de statistiques.
- Réécriture complète d'un seul pipeline – Lorsque vous souhaitez une réussite claire et des modèles réutilisables, choisissez un pipeline de bout en bout et réécrivez-le entièrement en Polars pour l'utiliser comme implémentation de référence interne.
- Parité d'exécution double – Lorsque l'exactitude est essentielle, exécutez les versions pandas et Polars côte à côte pendant un certain temps, comparez les sorties, les métriques et les coûts ; basculez une fois la parité prouvée.
Profilage des performances – Pour identifier les opportunités d'optimisation, commencez à suivre le temps d'horloge (le temps d'attente de l'utilisateur), l'utilisation maximale de la mémoire, le nombre de lignes, le nombre de colonnes et l'exactitude des résultats. La plupart des pipelines ont un goulot d'étranglement dans l'une des étapes suivantes : les E/S, les jointures, les regroupements, les tris, l'analyse de chaînes de caractères ou les UDF Python. Ajoutez de simples minuteurs autour de ces étapes. Utilisez les profilers pandas (Python) lorsque vous suspectez un travail au niveau de Python et les profilers Polars pour inspecter un plan de requête paresseux (lazy query plan). Effectuez une modification ciblée et réexécutez le même benchmark pour comparer.
Considérations sur la formation des équipes et le transfert de connaissances
Votre objectif est de réussir sans retarder la livraison ni perdre confiance dans les données. Assurez-vous que l'équipe comprend les motivations et peut les associer à de réels avantages, c'est-à-dire quels problèmes nous résolvons, quelles charges de travail en bénéficient le plus et ce qui ne changera pas. Désignez des responsables (responsable de la migration, réviseurs, décideurs) pour garantir la responsabilité.
Utilisez de véritables pipelines d'entreprise comme exemples pour plus de pertinence et pour susciter l'adhésion. Étant donné que Polars est plus proche de SQL mais avec une syntaxe Python, les plus grands changements sont des changements d'état d'esprit conceptuels :
- De l'impératif au déclaratif
- De ligne par ligne à colonne par colonne
- De l'état mutable aux pipelines immuables
- De l'exécution immédiate à la planification et l'exécution paresseuses
Séquencez la formation par niveaux afin que les équipes se sentent productives rapidement. Commencez peut-être par le filtrage, la sélection et le regroupement avant de passer aux expressions, à la gestion des valeurs nulles et aux différences de types de données. Abordez ensuite l'exécution paresseuse et l'optimisation avant les modèles de migration et de production. Établissez une phase hybride avec des directives claires sur les cas où pandas est autorisé afin de réduire l'anxiété. Pour un transfert de connaissances plus rapide, associez des utilisateurs Polars expérimentés à des utilisateurs intensifs de pandas.
Valider publiquement l'exactitude pour instaurer la confiance, et mesurer et partager les réussites.
FAQ
- Pandas est-il meilleur que Polars ? Aucun n'est universellement meilleur ; le choix dépend des exigences spécifiques du flux de travail, de la taille du dataset et des besoins en matière de performances.
- Lequel est le meilleur, Polars ou pandas ? Pandas excelle dans l'analyse interactive et l'intégration à l'écosystème ; Polars est plus performant pour les pipelines de production à grande échelle.
- Polars remplace-t-il pandas ? Polars complète plutôt qu'il ne remplace pandas ; les deux répondent efficacement à des cas d'utilisation différents.
- Est-ce que ça vaut la peine de passer à Polars ? Cela dépend si vous traitez de grands datasets où le mode paresseux (lazy mode) et l'optimisation des requêtes de Polars apportent des avantages mesurables.
Conclusion
Pour décider quelle bibliothèque de DataFrame est la plus pertinente pour vos équipes, il n'y a pas de réponse universelle. Généralement, pandas est mieux adapté aux datasets de petite à moyenne taille et à l'analyse exploratoire, tandis que Polars, avec son exécution paresseuse, est plus adapté aux hautes performances sur des charges de travail volumineuses (même plus grandes que la mémoire). Selon vos cas d'utilisation, vous pourriez finir par utiliser les deux, alors testez de petites portions pour des workflows spécifiques avec les deux bibliothèques et évaluez en fonction de vos tâches réelles de traitement des données.
Vos équipes doivent comprendre les forces et les faiblesses du stockage en colonnes par rapport au stockage en lignes et leurs implications pour différents modèles de requêtes. Les différences au niveau de l'API principale, de la syntaxe, du format des données et de la connexion aux bases de données nécessiteront une courbe d'apprentissage lors du passage d'une bibliothèque DataFrame à une autre.
Ressources pour approfondir l'apprentissage et l'expérimentation :
Création de pipelines de données évolutifs
Traitement distribué des données
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.