Que sont les pipelines de ML ?
Découvrez comment les pipelines d'apprentissage automatique automatisent et rationalisent le flux de travail d'apprentissage automatique, du prétraitement des données à la validation du modèle.
- Comprenez ce que sont les pipelines de ML et comment ils intègrent le prétraitement, l'extraction de caractéristiques, l'entraînement du modèle et la validation dans un flux de travail unifié.
- Apprenez à distinguer les Transformers des Estimateurs, les deux types d'étapes fondamentales d'un pipeline.
- Explorez comment les pipelines Spark ML permettent un apprentissage automatique distribué et évolutif grâce à la création et à l'optimisation natives des pipelines.
En règle générale, l’exécution d’algorithmes de machine learning implique une séquence de tâches comprenant le prétraitement, l’extraction de fonctionnalités, l’ajustement du modèle et les étapes de validation. Par exemple, la classification de documents textuels peut impliquer la segmentation et le filtrage du texte, l’extraction de fonctionnalités et l’entraînement d’un modèle de classification avec validation croisée. Bien qu’il existe de nombreuses bibliothèques utilisables à chaque étape, établir un lien entre les points n’est pas aussi facile qu’il y paraît, en particulier avec des datasets de grande taille. La plupart des bibliothèques ML ne sont pas conçues pour le calcul distribué ou ne fournissent pas de support natif pour la création et le réglage des pipelines.
Le guide pratique de l'IA agentique pour l'entreprise

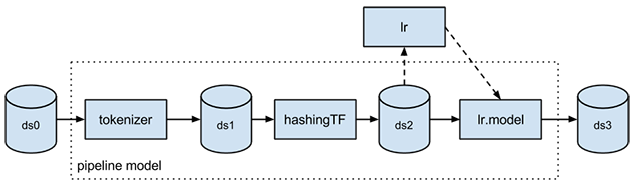
Le Pipelines de ML est une API de haut niveau pour MLlib qui se trouve dans le package « spark.ml ». Un pipeline est une séquence d’étapes. Un pipeline est essentiellement constitué de deux sous-pipelines : un pipeline de transformation et un pipeline d’estimation. Un pipeline de transformation prend un dataset en entrée et produit un dataset augmenté en sortie. Par exemple, un tokenizer est un pipeline qui transforme un dataset contenant du texte en un dataset contenant des mots tokenisés. Un pipeline d’estimation doit d’abord être ajusté sur le dataset d’entrée pour produire un modèle, qui est un pipeline de transformation dédié au dataset d’entrée. Par exemple, la régression logistique est un pipeline d’estimation qui s’entraîne sur un dataset avec des étiquettes et des fonctionnalités, et qui produit un modèle de régression logistique.
Ressources complémentaires
Recevez les derniers articles dans votre boîte mail
Abonnez-vous à notre blog et recevez les derniers articles directement dans votre boîte mail.